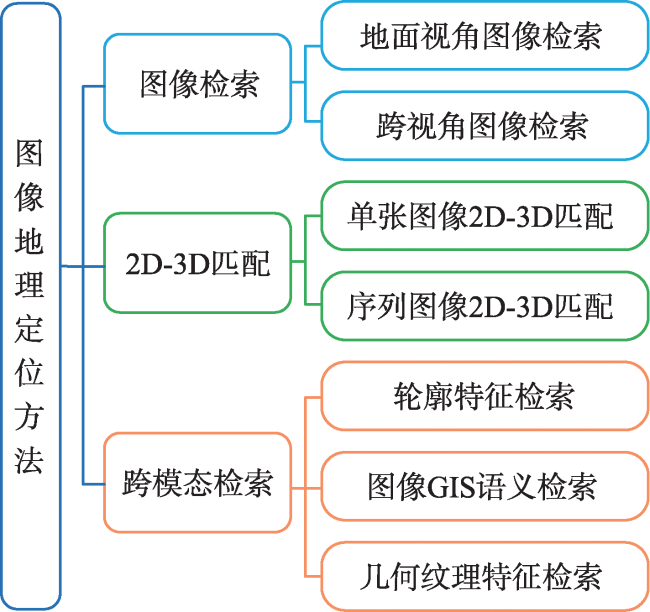
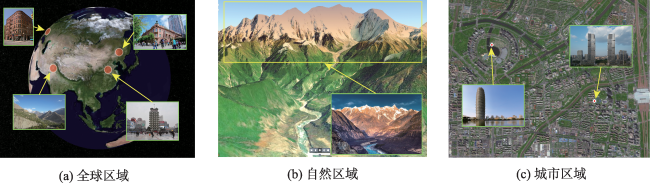
https://www.dqxxkx.cn/CN/10.12082/dqxxkx.2023.230073
Zhang和kosecka[15]首先提取图像的SIFT特征建立图像特征数据库,暴力全局检索数据库图像,利用随机采样一致性(RANdom SAmple Consensus, RANSAC)算法对前5张候选图像进行验证与排序,并利用前3张图像通过三角测量获得待查询图像的地理位置。Zamir 和 Shah[16]则提取图像的SIFT特征向量建立数据库,采用近邻树检索方式来提高检索效率,并采用修剪平滑的操作来提高准确性。随后Zamir和Shah[4] 又通过修剪离群值和使用广义最小团问题(Generalized Minimum Clique Problem, GMCP)结合近似特征匹配来进一步改进最近邻匹配,定位精度比之前的工作[16]提高了5%。
全球地标识别也是全球地理定位的一种方式。由于地标建筑与普通场景相比辨识度比较高,所以通常采用聚类、分类的思想来实现地标图像检索。Li等[30]使用基于SIFT特征的BoW技术与多类SVM分类器相结合的方法,定位精度与执行相同任务的人类相当。Johns和Yang[31]通过将20万张图像数据库聚类到视觉上相似的地标场景模型来改进BoW技术[32],但与标准的BoW技术相比改进不大。Avrithis等[33]利用核矢量量化方法(Kernal Vector Quantization, KVQ)对视觉上一致的图像进行聚类分组,来压缩大量图像,同时仍然能保证单一、非地标性的图像的检索。
不同季节、不同光照、移动的物体等不断变化的环境,以及相机视角的变化等因素,对图像地理定位形成了挑战,针对此问题一些学者提出了相应的解决方法。
Mishkin等[
34]采用了一种带有多个检测器、描述符、视图合成和自适应阈值的BoW方法来应对环境的巨大视觉变化。
仇晓松等[
35]采用预训练的CNN网络模型提取图像描述符,该模型能较好地描述图像的局部与全局特征,对视角变化和外观变化具有较高的鲁棒性。
Relja等[
36]受到VLAD启发,设计了可训练的NetVLAD层。NetVLAD提供了较为优秀的池化机制,可以轻松插入到其他CNN结构中,从而更好地提取图像特征,提高图像检索精度。
刘耀华[
37]提出了基于对抗判别网络的域自适应算法和基于批量标准化的域自适应算法,从而增强网络模型的域自适应能力。
王红君等[
38]提出一种基于SENet改进的ResNet的视觉位置识别网络PlaceNet,实验精确度和查询效率比NetVLAD更高。
利用多种方法融合实现图像检索。
Kang等[
39]将空间分析与图像检索相结合,即利用二值支持向量机对数据集进行“有”“无”地理信息的预处理,提高训练效率,并利用GIS反向视域分析来减少图像潜在搜索区域,最后以埃菲尔铁塔区域图像为例验证了该方法的准确性与有效性。
Cheng等[
40-
41]将三维重建与图像检索相结合,即采用三步法的策略由粗到精逐步细化地理位置,包括通过图像检索粗略地理定位,通过图像配准选择可靠匹配图像,最后通过三维重建获得图像的精确地理位置。
不同季节、不同光照、移动的物体等不断变化的环境,以及相机视角的变化等因素,对图像地理定位形成了挑战,针对此问题一些学者提出了相应的解决方法。Mishkin等[
34]采用了一种带有多个检测器、描述符、视图合成和自适应阈值的BoW方法来应对环境的巨大视觉变化。仇晓松等[
35]采用预训练的CNN网络模型提取图像描述符,该模型能较好地描述图像的局部与全局特征,对视角变化和外观变化具有较高的鲁棒性。Relja等[
36]受到VLAD启发,设计了可训练的NetVLAD层。NetVLAD提供了较为优秀的池化机制,可以轻松插入到其他CNN结构中,从而更好地提取图像特征,提高图像检索精度。刘耀华[
37]提出了基于对抗判别网络的域自适应算法和基于批量标准化的域自适应算法,从而增强网络模型的域自适应能力。王红君等[
38]提出一种基于SENet改进的ResNet的视觉位置识别网络PlaceNet,实验精确度和查询效率比NetVLAD更高。
利用多种方法融合实现图像检索。Kang等[
39]将空间分析与图像检索相结合,即利用二值支持向量机对数据集进行“有”“无”地理信息的预处理,提高训练效率,并利用GIS反向视域分析来减少图像潜在搜索区域,最后以埃菲尔铁塔区域图像为例验证了该方法的准确性与有效性。Cheng等[
40-
41]将三维重建与图像检索相结合,即采用三步法的策略由粗到精逐步细化地理位置,包括通过图像检索粗略地理定位,通过图像配准选择可靠匹配图像,最后通过三维重建获得图像的精确地理位置。

Shi等[69]提出了一种跨视角特征传输模块 (Cross-View Feature Transport, CVFT),以促进地面与俯视图像之间的特征匹配。CVFT模块通过将特征从一个域转换到另一个域,有效地减少了视角差异过大带来的影响。Zhu等[70]发现在研究中一般会默认待查询图像的地理位置位于俯视图像中心,但这不符合实际情况。因此,作者通过检索粗略获得图像地理位置,然后通过回归预测偏移量来细化图像地理位置。Zhu等[71]针对跨视角图像匹配信息被忽略的问题,提出了全局挖掘策略和二项式损失来解决该问题。Rodrigues等[72]提出了一种语义驱动的数据增强技术,来模拟时间变化场景中消失和新出现的对象特性,使神经网络具有推理并生成未知物体的能力。使用增强图像来训练具有多尺度注意力主干的网络,以产生无法匹配的图像区域的内容。Zeng等[73]利用无人机视角图像作为地面视角和卫星视角之间的桥梁,提出了一个同伴学习和交叉扩散(Peer Learning and Cross Diffusion, PLCD)框架。Wang等[74]提出了一种局部模式网络LPN (Local Pattern Network),其采用方形回环的特征划分策略,根据到图像中心的距离来学习空间特征。由于方形回环分区的设计,LPN网络对旋转变化具有良好的适应性。Lin等[75]提出了一种名为RK-Net的框架,该框架探索了跨视角地理定位的关键点检测和表示学习中的联合学习,主要思想是找到显著区域来区分不同的位置,与人类视觉系统保持一致。

使用SfM技术从大规模图像中建立3D模型用于图像地理定位。Heinly等[
76]在一台计算机上用6天时间从YFCC100M数据集[
77]的1亿张照片中自动创建了全球多地的3D模型,用来定位城市地区或地标建筑图像。
Irschara等[
78]用几百张图像为维也纳最著名的地标建立了一个SfM模型。SfM模型中的相关图像通过BoW方法进行搜索。
有研究通过增加相关约束来提高定位精度。Svarm等[
85]在待检索图像中加入了重力传感器获得的重力方向的数据,处理了高达99%的离群值,从而可以更好地估计出拍摄图像时相机的姿态。Zeisl等[
86]解决了使用SfM模型进行大规模地理定位中的大量离群匹配的问题,并在Svarm等[
85]的基础上,将相机上的重力方向约束以及其他约束纳入相机姿势估计。Iwami等[
87]提出了一种利用大量带有地理位置标记的图像来纠正位置漂移的框架。该框架集成了增量SfM和利用地理标记图像的位置漂移的方法。
由于单目SLAM只能计算出视频帧之间的相对位置关系,无法定位出地理位置,因此一些研究将单个视频帧与带有地理坐标的图像进行匹配,从而获得单个视频帧的地理坐标,并计算出连续视频帧的绝对运动轨迹。Hakeem等[
90]使用一组具有已知GPS坐标的图像匹配关键帧,从最佳匹配中计算出基本矩阵以恢复相机姿态,并利用三角测量的方法来统一尺度,同时使用B-splines对位置进行插值,以获得平滑的轨迹。Conte和Doherty[
91]将惯性传感器、视觉测量和车载视频与地理参考俯视图像的配准相结合,能够为无人机自主导航提供快速和无漂移的地理位置估计。Vaca-Castano等[
92]利用图像检索的方法获得各个视频帧与街景图像的最佳匹配,然后利用贝叶斯跟踪来估计视频帧的地理位置及随时间的变化,最后利用轨迹重建算法以消除轨迹噪声,从而获得高精度的相机轨迹。
还有研究在单目SLAM中引入DEM、3D模型和3D点云等数据,来达到定位视频帧地理位置的目的。Larnaout等[
93]利用DEM校正摄像机轨迹,利用3D建筑模型约束重建的3D点云,可以实现30 Hz频率的在线实时地理定位。Middelberg等[
94]在移动设备上利用关键帧构建SLAM模型,并将关键帧与服务器内的SfM模型进行匹配,将移动设备轨迹转换到SfM模型坐标系中,从而获得移动设备的轨迹与姿态。

2.3.3 基于几何纹理特征的跨模态检索
图像中往往包含了大量的几何关系和建筑纹理特征,这为图像地理定位提供了新方向,即利用几何和纹理特征进行跨模态检索。Schindler等[
110]提出了一种通过检测和匹配重复模式来自动对城市图像进行地理定位的方法。该方法利用了城市环境的高度重复性,检测图像中多个透视扭曲的重复性2D图案,并通过推理每种图案的基本范式,将它们与纹理立面的3D数据库相匹配,通过多个2D-3D模式对应关系可获得的查询图像的位置与姿态。由于建筑纹理信息通常依附于建筑物而存在,所以该方法只适用于建筑物密集的城市区域,地理定位精度受待查询图像的质量影响较大。Lalonde等[
111]分析了图像序列中天空部分的太阳位置与天空外观特征,并将天空模型与图像序列的天空区域进行拟合,来提取图像序列焦距、天顶角、方位角等参数。在已知相机参数的高画质图像序列上测试了该方法,获得的焦距误差小于1 %,方位角和天顶角的误差分别为1°和3°,并用低画质摄像头进行测试,平均定位误差为110 km。该方法通常用于网络摄像头的地理定位,但定位精度不高,实用性较差。Baatz等[
112]解决了城市区域图像中的大规模兴趣点识别问题。作者利用3D建筑信息和大量的街景图像来建立数据库,利用灭点将查询图像进行矫正,从而消除3D旋转对特征识别带来的影响。将特征不变性简化为纯同位问题,比经典SIFT特征具有更好的判别能力。Zhang和Matthew[
113]提出了一种无监督跨尺度视觉特征表达方法。作者将二维地图编码为信念图,提取出无人机所拍摄图像的特征,并与信念图几何特征相匹配获得无人机地理位置。该方法拓展了地图模态的范围,为无人机地理定位提供了一种新思路。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号