




非常好的追问!这两个问题直击SG-PGM方法的核心细节。我们来深入探讨一下。
一、 SG-PGM 与 SGAligner 的关系
这是一个关键问题,因为它们都是处理3D场景图对齐的重要工作。它们的关系是继承、发展、与侧重不同。
- SGAligner 是开创者:
- SGAligner 是较早系统性地提出并解决3D场景图对齐问题的论文之一。
- 它奠定了这个任务的基本框架:输入两个3D场景图,输出节点对应关系。
- 它的核心是图神经网络(GNN)。它通过多层GNN来聚合邻居信息,学习节点的上下文感知嵌入,然后计算节点相似性矩阵,最后通过匈牙利算法或Sinkhorn算法进行匹配。
- SG-PGM 是发展与深化:
- SG-PGM 可以看作是在 SGAligner 基础上的一次重要演进。它认识并解决了 SGAligner 存在的一些局限性。
主要区别与 SG-PGM 的改进:
| 特性 | SGAligner | SG-PGM (本文) | SG-PGM 的优势 |
|---|---|---|---|
| 匹配类型 | 主要关注完全匹配,对部分匹配处理能力较弱。 | 明确设计用于部分匹配。 | 更符合现实世界的应用场景,因为两个场景图很少完全一致。 |
| 匹配算法 | 使用匈牙利算法(需要一一对应)或Sinkhorn算法(软匹配)。 | 采用最优传输理论,显式引入“空节点”来处理不匹配的点。 | 最优传输为部分匹配提供了更严格、更优雅的数学框架,结果更鲁棒。 |
| 信息融合 | 将节点的语义和几何特征简单拼接后输入GNN。 | 提出了语义-几何融合编码器,使用交叉注意力进行深度融合。 | 不再是“早期融合”,而是“中期融合”,允许语义和几何模态在编码过程中进行更精细的交互,学习到的联合特征更具判别性。 |
| 特征编码重点 | 主要强调拓扑结构(通过GNN的消息传递)。 | 同时强调拓扑结构和形状特征(见第二部分详解),并对两者进行了更精细的处理。 | 表征能力更强,尤其能更好地区分几何外观相似但类别不同的物体(如“垃圾桶” vs “花盆”)。 |
关系总结:SG-PGM 是在 SGAligner 开创的道路上,针对其不足(尤其是部分匹配和特征融合方面)提出的一个更强大、更完善的解决方案。如果说 SGAligner 是“从0到1”,那么 SG-PGM 就是“从1到1.5”,在模型架构和问题定义的严谨性上做出了重要推进。
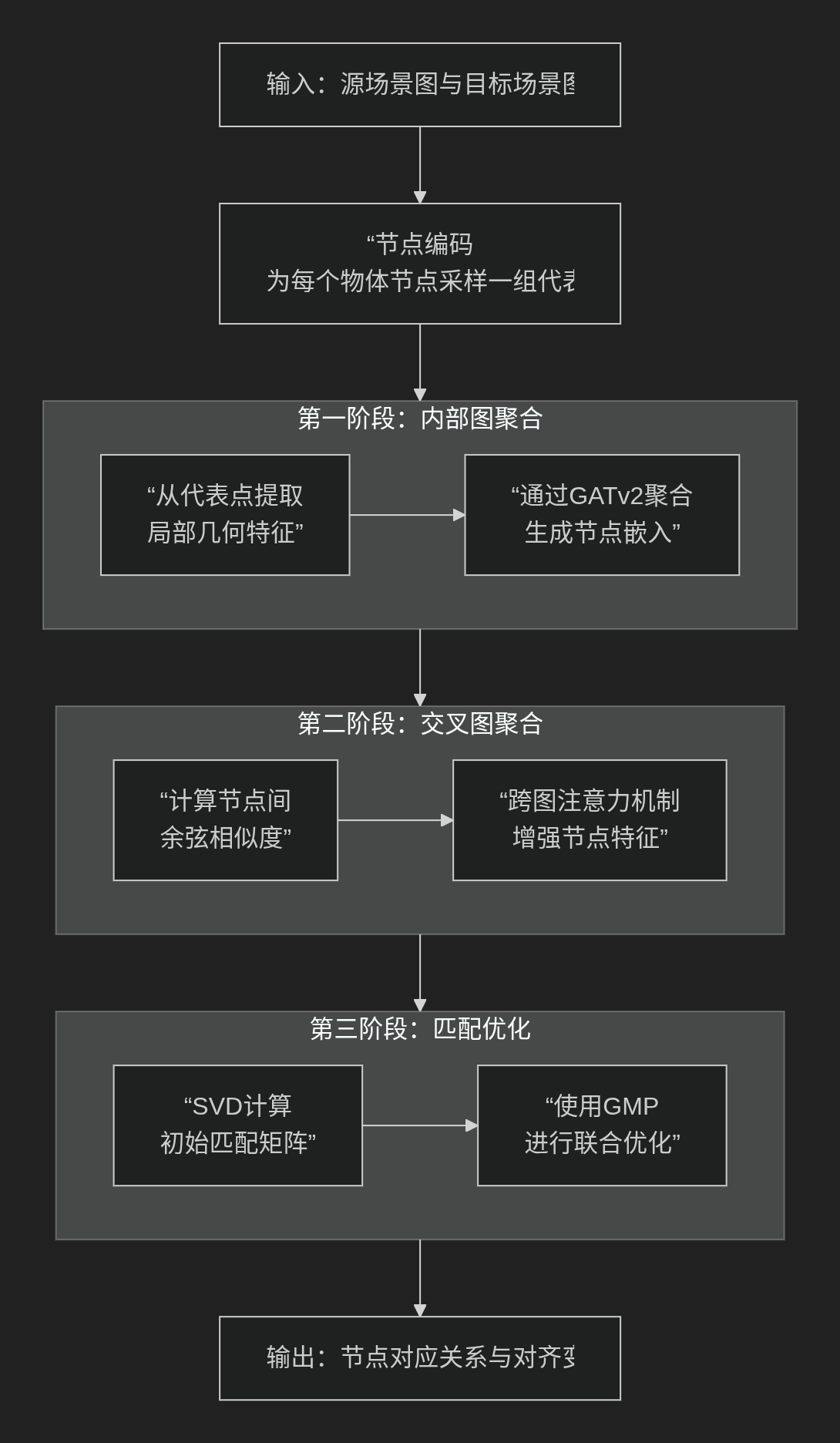
二、 形状特征与拓扑特征的编码方式
这是SG-PGM模型的核心创新——语义-几何融合编码器。我们需要拆解“形状特征”和“拓扑特征”是如何被编码和融合的。在论文的语境中:
- 形状特征 更偏向于节点的内在、局部几何属性。例如,一个物体的尺寸、比例、点云形状。
- 拓扑特征 更偏向于节点的外在、全局关系结构。例如,一个物体与其他物体的相对位置、连接关系。
SG-PGM 通过一个双流网络结构来分别捕捉这两种特征,并进行融合。
1. 拓扑特征的编码
拓扑特征主要通过图神经网络来捕获。
- 输入图的构建:
- 节点特征:初始节点特征已经包含了基础的语义和几何信息。
- 边构建:这是编码拓扑的关键。论文中通常会构建两种边:
- 空间邻近边: 如果两个物体的3D边界框在空间上足够近(如IoU大于某个阈值或距离小于某值),则在他们之间建立一条边。这捕获了物体的局部空间排列。
- 语义关系边: 根据预定义的关系(如“支撑”、“相邻”)建立边。
- 编码过程:
- 使用多层GNN(如图注意力网络GAT或图卷积网络GCN)对图进行处理。
- 在每一层,每个节点通过聚合其直接邻居的信息来更新自己的表示。经过多层之后,每个节点的特征就包含了其多跳邻居的信息。
- 这就编码了拓扑结构: 一个节点的最终表示,蕴含了它在整个图结构中的“位置”和“角色”。例如,一个被许多“椅子”节点包围的节点,更可能被推断为“桌子”。
2. 形状特征的编码
形状特征的编码更侧重于物体本身。
- 点云编码: 对于每个物体节点,将其对应的3D点云(或其从场景中裁剪出的部分)输入一个轻量级的PointNet 或Point Transformer 网络中。
- 输出: PointNet会输出一个全局特征向量,这个向量捕捉了该物体的几何形状、大小、姿态等内在几何属性。
- 作用: 这个形状特征对于区分语义相同但几何外形不同的物体(如“办公椅” vs “餐桌椅”)以及排除语义拓扑的歧义(如区分四个相同的“椅子”中具体是哪一把)至关重要。
3. 核心创新:语义-几何融合(实为形状与拓扑的融合)
SG-PGM没有简单地将形状特征和拓扑特征拼接起来。它的融合编码器工作流程如下:
- 初始化:
- 几何流初始特征 H_geo^(0): 主要包含节点的坐标、形状特征(来自PointNet)等。
- 语义流初始特征 H_sem^(0): 主要包含节点的语义标签嵌入。
- 交叉注意力融合层(迭代进行L次):这是最关键的一步。在第
l层:- 几何流更新: 每个节点的几何特征
h_geo_i^(l)会作为一个查询向量。- 它会去计算与所有节点的语义特征
H_sem^(l)的注意力分数。 - 这意味着,一个物体的几何特征会主动去“寻找”那些在语义上与它相关的其他物体,并用这些语义信息来更新自己。
- 例如: 一个几何形状像“圆柱体”的物体,如果它关注到头顶有一个“灯”的语义节点,那么它的几何特征就会融入“可能是一个灯柱”的语义上下文。
- 它会去计算与所有节点的语义特征
- 语义流更新: 同理,每个节点的语义特征
h_sem_i^(l)作为查询,去计算与所有节点的几何特征H_geo^(l)的注意力分数。- 例如: 一个“椅子”的语义节点,如果它关注到其几何特征与一个“非常低”的物体很接近,那么它可能会强化自己作为“脚凳”而非“餐椅”的语义理解。
- 自注意力: 在交叉注意力之后,每个流内部还会进行标准的图注意力,以进一步强化节点在各自模态内的拓扑关系。
- 几何流更新: 每个节点的几何特征
- 输出:
- 经过L层这样的交叉融合,两个流的特征被拼接起来,形成每个节点的最终联合嵌入。
- 这个最终嵌入是形状感知的(因为包含PointNet特征和几何交互),也是拓扑感知的(因为通过了GNN和交叉注意力聚合了邻域信息),并且是语义-几何深度融合的。
总结
SG-PGM通过一个精巧的双流交叉注意力网络,将代表物体内在属性的形状特征和代表物体间全局关系的拓扑特征进行了深度的、迭代式的融合。它不是简单的合并,而是让两种信息在编码过程中持续地、双向地相互引导和增强,从而学习到对3D场景图部分匹配任务来说判别力极强的节点表示。这正是它性能超越SGAligner等先前工作的根本原因。
好的,我们来对这篇名为 《SG-PGM: Partial Graph Matching Network with Semantic Geometric Fusion for 3D Scene Graph Alignment and Its Downstream Tasks》 的论文进行一次详细的解读。这篇论文的核心贡献在于,它提出了一种新颖的、专门用于处理3D场景图部分匹配问题的神经网络方法。3D场景图对齐是机器人感知和推理中的一个关键且具有挑战性的任务。
一、 论文要解决的核心问题
想象一个机器人进入一个之前只见过一次的环境(比如一个公寓)。它之前构建了一个这个公寓的3D场景图,其中节点代表物体(如“桌子”、“椅子”),边代表物体之间的关系(如“桌子上有”、“椅子旁边是”)。现在,机器人再次进入这个环境,但视角、光照可能不同,有些物体可能被移动了,甚至出现了新物体或消失了旧物体。3D场景图对齐的目标就是:将当前观察到的(目标)场景图与记忆中的(源)场景图进行匹配,找出哪些节点是对应的(例如,匹配“当前的这张桌子”和“记忆中的那张桌子”)。挑战在于,这种匹配往往是“部分的”:
- 非一一对应: 两个图的节点数量可能不同,不是所有节点都能找到匹配。
- 歧义性: 多个同类物体(如四把一样的椅子)可能导致匹配模糊。
- 多模态信息融合: 3D场景图节点同时包含语义信息(物体的类别标签)和几何信息(物体的3D位置)。如何有效融合这两种信息是提升匹配精度的关键。
现有的图匹配方法大多为通用图设计,没有充分利用3D场景图的独特结构(语义+几何),并且在处理部分匹配时表现不佳。
好的,我们来对这篇名为 《SG-PGM: Partial Graph Matching Network with Semantic Geometric Fusion for 3D Scene Graph Alignment and Its Downstream Tasks》 的论文进行一次详细的解读。这篇论文的核心贡献在于,它提出了一种新颖的、专门用于处理3D场景图部分匹配问题的神经网络方法。3D场景图对齐是机器人感知和推理中的一个关键且具有挑战性的任务。
一、 论文要解决的核心问题
想象一个机器人进入一个之前只见过一次的环境(比如一个公寓)。它之前构建了一个这个公寓的3D场景图,其中节点代表物体(如“桌子”、“椅子”),边代表物体之间的关系(如“桌子上有”、“椅子旁边是”)。现在,机器人再次进入这个环境,但视角、光照可能不同,有些物体可能被移动了,甚至出现了新物体或消失了旧物体。3D场景图对齐的目标就是:将当前观察到的(目标)场景图与记忆中的(源)场景图进行匹配,找出哪些节点是对应的(例如,匹配“当前的这张桌子”和“记忆中的那张桌子”)。挑战在于,这种匹配往往是“部分的”:
- 非一一对应: 两个图的节点数量可能不同,不是所有节点都能找到匹配。
- 歧义性: 多个同类物体(如四把一样的椅子)可能导致匹配模糊。
- 多模态信息融合: 3D场景图节点同时包含语义信息(物体的类别标签)和几何信息(物体的3D位置)。如何有效融合这两种信息是提升匹配精度的关键。
现有的图匹配方法大多为通用图设计,没有充分利用3D场景图的独特结构(语义+几何),并且在处理部分匹配时表现不佳。
二、 方法概述:SG-PGM 的创新点
SG-PGM 的全称是 Semantic-Geometric Partial Graph Matching network。其核心创新可以概括为以下几点:
1. 语义-几何融合编码器
这是SG-PGM的核心组件。传统方法可能只是简单地将语义特征和几何特征拼接起来。而SG-PGM设计了一个更精巧的融合机制:
- 输入特征:
- 语义特征: 每个节点的类别标签(如“椅子”),通过词嵌入模型(如GloVe)转换为向量。
- 几何特征: 每个节点的3D边界框的中心坐标、尺寸等。
- 融合过程:
- 独立编码: 使用图神经网络分别对语义子图和几何子图进行编码,得到初步的节点嵌入。
- 交叉注意力融合: 使用一个交叉注意力模块,让语义流和几何流进行“对话”。
- 语义节点会去“关注”那些在几何上与自己接近的节点,从而用几何信息来丰富自己的语义表达(例如,“椅子”节点会关注其下方的“地板”和上方的“桌子”)。
- 同样,几何节点也会去“关注”那些在语义上相关的节点。
- 输出: 经过多层这样的交叉融合,每个节点最终获得一个既包含丰富语义上下文,又包含精确几何关系的联合特征表示。这个表示比简单的特征拼接要强大得多。
-
2. 基于最优传输的部分匹配层
为了解决“部分匹配”问题,论文没有采用常见的贪婪匹配或匈牙利算法(这些算法要求一一对应),而是采用了最优传输理论。
- 将匹配视为运输问题: 将源图的节点视为“供应商”,目标图的节点视为“消费者”。匹配的任务就是将“供应”(对应关系)以最小的“成本”从供应商运输到消费者。
- 匹配矩阵: 算法会计算一个软分配矩阵,其中每个元素表示一个源节点与一个目标节点匹配的概率。
- 处理不匹配节点: 最优传输框架天然地支持设置一个“空节点”(或称为“蓄水池”)。如果一个节点与所有其他节点的匹配成本都太高,那么它的大部分匹配概率就会被分配给这个“空节点”,从而被标记为不匹配点。
- 优势: 这种方法可以一次性、整体地计算出所有节点的匹配概率,结果是可微的,便于端到端训练,并且能优雅地处理部分匹配。
3. 端到端训练
整个网络(编码器+匹配层)是端到端训练的。损失函数通常由两部分组成:
- 匹配损失: 鼓励正确节点对的匹配概率接近1,错误节点对的概率接近0。
- 特征学习损失: 鼓励匹配的节点在特征空间中的距离更近,不匹配的节点距离更远。
三、 整体流程
SG-PGM 的工作流程可以总结为以下几步:
- 输入: 两个3D场景图(源图 G_s 和目标图 G_t)。
- 特征提取与融合: 将两个图输入到语义-几何融合编码器中,得到每个节点的增强后特征向量。
- 计算相似性矩阵: 计算源图和目标图所有节点对之间的特征相似性矩阵。
- 最优传输匹配: 将相似性矩阵(取负后作为成本)输入到最优传输层,求解出软分配矩阵。
- 输出: 可以通过简单的阈值处理(如取最大值)从软分配矩阵中得到硬的、离散的匹配结果,并识别出不匹配的节点。
四、 下游任务与应用
论文不仅展示了SG-PPGM在场景图对齐任务上的优越性,还验证了其在重要下游任务中的价值:
- 3D场景图注册:
- 任务: 将对齐的节点作为对应点,估计两个场景之间的刚体变换(旋转和平移)。
- 应用: 机器人重定位、多视角场景融合。
- SG-PGM的作用: 提供了高质量、准确的节点对应关系,从而可以应用鲁棒的配准算法(如RANSAC)来精确计算变换矩阵。
- 3D场景图辅助点云配准:
- 任务: 当两个场景的点云只有少量重叠或视角差异极大时,传统的ICP等方法容易失败。
- SG-PGM的作用: 先通过场景图对齐找到一个粗略的变换初值,然后用这个初值来初始化精细的点云配准算法(如ICP),大大提高了配准的成功率和精度。
五、 总结与评价
核心贡献总结:
- 问题定义: 明确并形式化了3D场景图的部分匹配问题。
- 方法创新: 提出了SG-PGM模型,其核心是语义-几何融合编码器和基于最优传输的匹配层。
- 应用验证: 证明了其在场景图对齐及其下游任务(如重定位、点云配准)中的有效性和优越性。
重要意义:这项工作将3D场景图的研究从“表示”推进到了“推理”层面。它使得机器人能够进行更高级的空间推理,例如:
- 长期语义SLAM: 在不同的时间访问同一环境时,能够识别出环境的变化(哪些物体被移动、添加或移除)。
- 人机交互: 能够理解“请把我昨天放在沙发旁边的杯子拿过来”这样的指令。
- 具身AI: 为在复杂、动态的3D环境中执行任务的智能体提供了强大的感知和记忆关联能力。
简而言之,SG-PGM为处理真实世界中不完美、动态变化的3D环境提供了一个强大而实用的工具。




========================













 浙公网安备 33010602011771号
浙公网安备 33010602011771号