


https://arxiv.org/html/2402.04555v2
关注点
1
在单个图像帧中,由于遮挡,RAM 生成的标签可能会遗漏一些物体。这些缺失的标签进一步导致 GroundingDINO 无法正确检测物体。这是在单个图像上运行基础模型的固有局限性。为了解决这个问题,我们将相邻帧中检测到的标签编码到文本提示中。
2数据关联与集成
具体来说,首先查询观察到的实例体素。可以通过将深度图像投影到所有实例的体素网格图中来搜索。如果观察到一个实例,则将其体素投影到当前 RGB 帧。
3
Fusion++
4
合并过度分割
尽管 SAM 在单幅图像上表现出色,但它会在视角变化时生成不一致的实例掩码,如图5所示。

抽象的
基于监督目标检测器的语义映射对图像分布敏感。
在实际环境中,目标检测和分割性能可能会大幅下降,从而阻碍语义映射在更广泛领域的应用。
另一方面,视觉语言基础模型的发展展现出强大的跨数据分布零样本迁移能力。这为构建可泛化的实例感知语义图谱提供了机会。
因此,本研究探索如何从基础模型生成的目标检测数据中提升实例感知语义映射的性能。
我们提出了一种概率标签融合方法,用于从开集标签测量值中预测闭集语义类别。
实例细化模块用于合并由不一致分割导致的过度分割实例。
我们将所有模块集成到一个统一的语义映射系统中。通过读取RGB-D序列输入,我们的工作逐步重建了一个实例感知语义图谱。
我们在ScanNet和SceneNN数据集上评估了该方法的零样本性能。
我们的方法在 ScanNet 语义实例分割任务上实现了 40.3 的平均精度 (mAP),显著优于传统的语义映射方法。代码可从https://github.com/HKUST-Aerial-Robotics/FM-Fusion获取。
介绍
室内环境中的实例感知语义地图是自主系统实现更高智能水平的关键模块。
基于语义地图,移动机器人可以更稳健地检测环路。
1]并高效地[2]。当前的方法依赖于监督物体检测器,如 Mask R-CNN [3]来检测语义实例并将其融合到实例级语义图中。
然而,监督目标检测器是在特定的数据分布上训练的,缺乏泛化能力。在未对网络进行微调的情况下将其部署到其他实际场景中时,其性能会严重下降。因此,在目标环境中重建的语义图质量也很差。
另一方面,基础模型在视觉语言模态方面发展迅速[4] [5]。
多个基础模型相结合,检测和分割物体。GroundingDINO [6]是最新的 SOTA 开放集目标检测网络,它读取文本提示并执行视觉-语言模态融合。它使用边界框和开放集标签来检测目标。开放集标签是开放词汇语义类别。GroundingDINO 在零样本 COCO 目标检测基准上实现了 52.5 mAP,高于大多数监督目标检测器。
此外,该图像标记模型可以识别任何内容(RAM)[7]预测图像中的语义标签。这
些标签可以编码为文本提示并发送到 GroundingDINO。
视觉基础模型 SAM [4]根据几何提示(包括边界框提示)生成精确的零样本图像分割结果。SAM 可以为 GroundingDINO 的检测结果生成高质量的掩码。
RAM、GroundingDINO 和 SAM 可以组合使用,在开放集标签和高质量掩码中检测目标。所有这些基础模型均使用大规模数据进行训练,并在各种图像分布中展现出强大的零样本泛化能力。它们为自主系统提供了一种构建可泛化的实例感知语义图谱的新方法。本文探讨了如何将基础模型中的目标检测融合到实例感知语义图谱中。
要融合基础模型中的目标检测,需要解决两个挑战。
首先,基础模型生成开放集标签或标记。
然而,语义映射任务要求将每个构造的实例归类到封闭集语义类别中。
需要一种标记融合方法,从观察到的开放集标签序列中预测实例的语义类别。
其次,SAM 在单个图像上运行。在密集的室内环境中,SAM 经常在变化的视点处生成不一致的实例掩码。
这会导致实例体积过度分割和噪声。从不一致的实例分割结果中细化集成的实例体积是一个挑战。
然而,传统的语义映射工作并未考虑这些挑战。
如果在传统的语义映射系统中直接使用基础模型,它们重建的语义实例的质量不太令人满意。
为了应对这些挑战,我们提出了一种基于贝叶斯滤波算法的概率标签融合方法。
同时,我们通过合并过分割来细化实例体积,并将实例体积与全局体积图融合。
标签融合和实例细化模块在我们的系统中以增量方式运行。
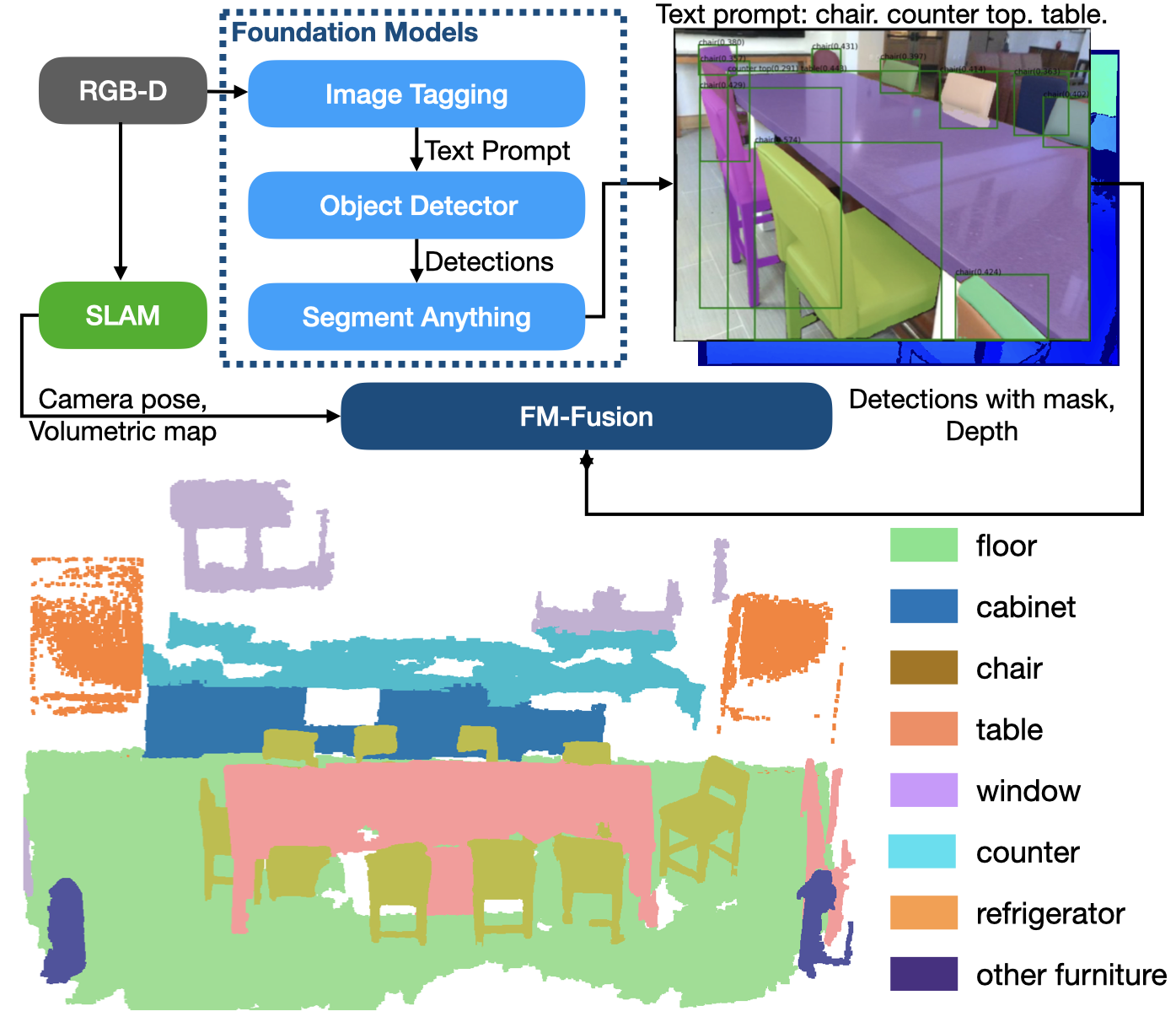
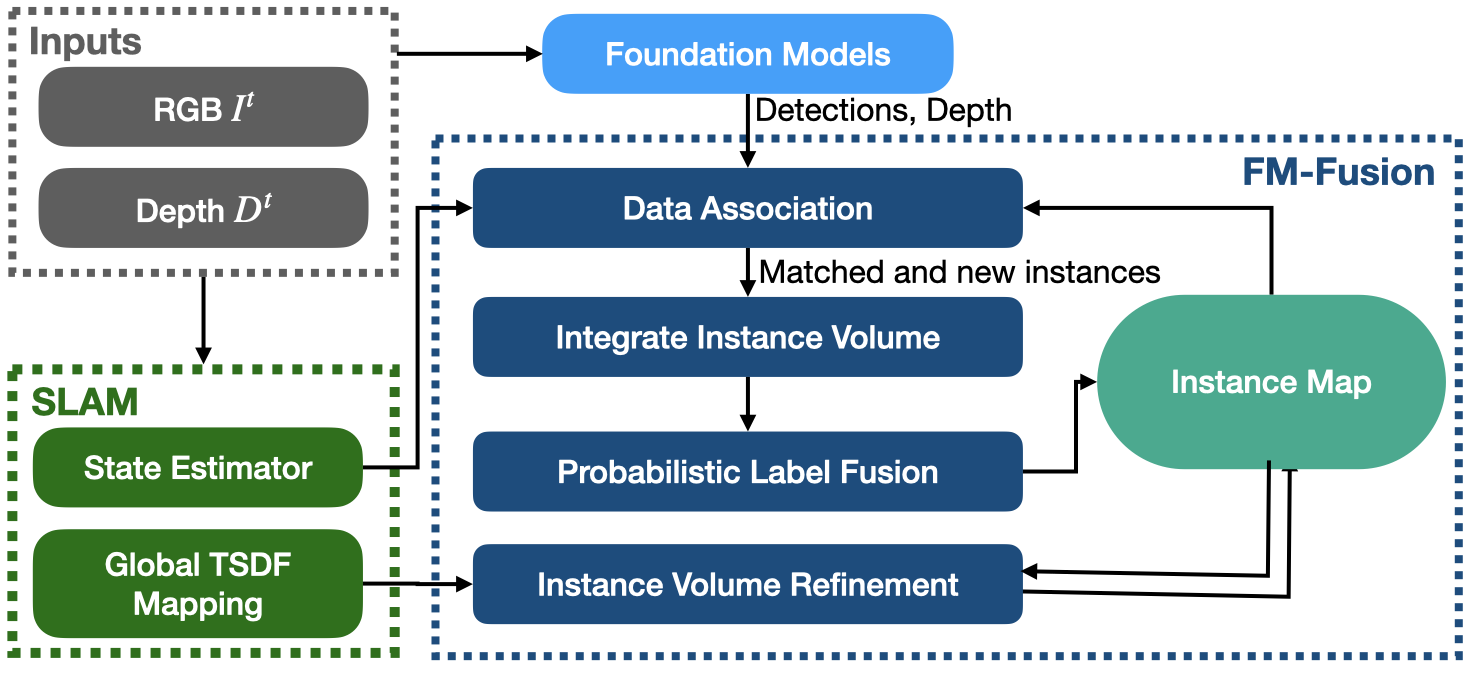
如图1所示,FM-Fusion 读取一系列 RGB-D 帧,融合基础模型的检测结果,并与传统 SLAM 系统同步运行。
我们的主要贡献如下:
-
一种将视觉语言基础模型中的目标检测结果融合到实例感知语义图谱中的方法。基础模型无需进行微调即可使用。
-
一种概率标签融合方法,可根据开放集标签测量预测封闭集语义类别。
-
实例经过改进,解决了视点改变时不一致的掩码问题。
二相关作品
II-A视觉语言基础模型
图像标记基础模型 RAM [7],识别图像中的语义类别并生成相关标签。
开放集物体检测器,例如 GLIP [10]和 GroundingDINO [6],读取文本提示来检测物体。
文本提示可以是一个句子,也可以是一系列语义标签。它提取区域图像嵌入,并通过基础方案将图像嵌入与文本提示的短语进行匹配。该
网络使用对比学习进行训练,以对齐图像嵌入和文本嵌入。检测结果包含一个边界框和一组开放集标签测量值。
SAM [4]可以精确分割任何具有几何提示的物体。它使用 1100 万张图像进行训练,并在零样本基准测试中进行评估。
SAM 无需微调即可在数据分布中展现出强大的泛化能力。
组合的基础模型读取图像并使用开放集标签和掩码检测物体。我们将它们称为 RAM-Grounded- SAM。1。
II-B语义映射
语义融合[14]是语义映射领域的一项先驱工作。它训练了一个基于 CNN 的轻量级语义分割网络[15]在 NYUv2 数据集上。
SemanticFusion 会将语义标签(忽略实例级信息)逐步融合到全局体积图的每个面元中。
在贝叶斯融合标签测量中,语义概率由目标检测器直接提供。
Kimera 依靠在 COCO 数据集上预训练的 Mask R-CNN,[16]使用类似的方法将语义标签融合到体素图中。
它将具有相同语义标签的邻近体素聚类为实例。
Kimera 进一步构建了场景图,这是一种分层的地图表示。
基于 Kimera,Hydra [2]利用场景图更有效地检测循环。
另一方面,Fusion++ [17]直接检测图像上的语义实例,并将它们融合到实例体积图中。这进一步证明了语义地标可以用于回环检测。
Voxblox++ 不是像面元图或体素图这样的纯稠密图,[19]首先在每个深度帧上生成几何片段[20如果目标检测遮盖了实例的完整区域,它可以合并几何分割产生的破碎片段。然后,通过数据关联策略,将合并后的片段及其标签融合成全局片段图。
当前语义映射方法的主要局限性在于缺乏泛化能力。
监督目标检测网络的训练源数据有限。
考虑到大多数目标 SLAM 场景不提供带注释的语义数据,目标检测无法针对目标分布进行微调。
为了避免泛化问题,Kimera 必须在合成数据集上进行实验[16],包括一些依赖于真实分割的实验。
Lin等[1]设置了一个包含稀疏分布对象的环境来重建语义地图。
Voxblox++ 在 10 次扫描中评估了 9 个语义类别中的几个。
尽管他们提出了新颖的语义 SLAM 方法,但语义映射模块阻碍了他们的方法在其他现实世界场景中的应用。
为了增强分布偏移的鲁棒性,我们的方法融合了基础模型中的目标检测,以重建实例感知语义图。
我们在 ScanNet 语义实例分割基准上评估了其零样本性能。
该方法涉及 NYUv2 标签集中的 20 个类别,并评估了它们在 3D 空间中的平均精度 (AP)。
我们还展示了在多个 SceneNN 扫描中的定性结果,这些扫描已被之前的语义映射研究使用。
三融合多帧检测



 浙公网安备 33010602011771号
浙公网安备 33010602011771号