

版本1
https://github.com/facebookresearch/segment-anything?tab=readme-ov-file#model-checkpoints
最新的是2
https://github.com/facebookresearch/sam2
环境 cuda11.8 配置
全图检测

mpu5pm 最好和最差模型 图像原图

mpu5pm 最好和最差模型 图像压缩一倍

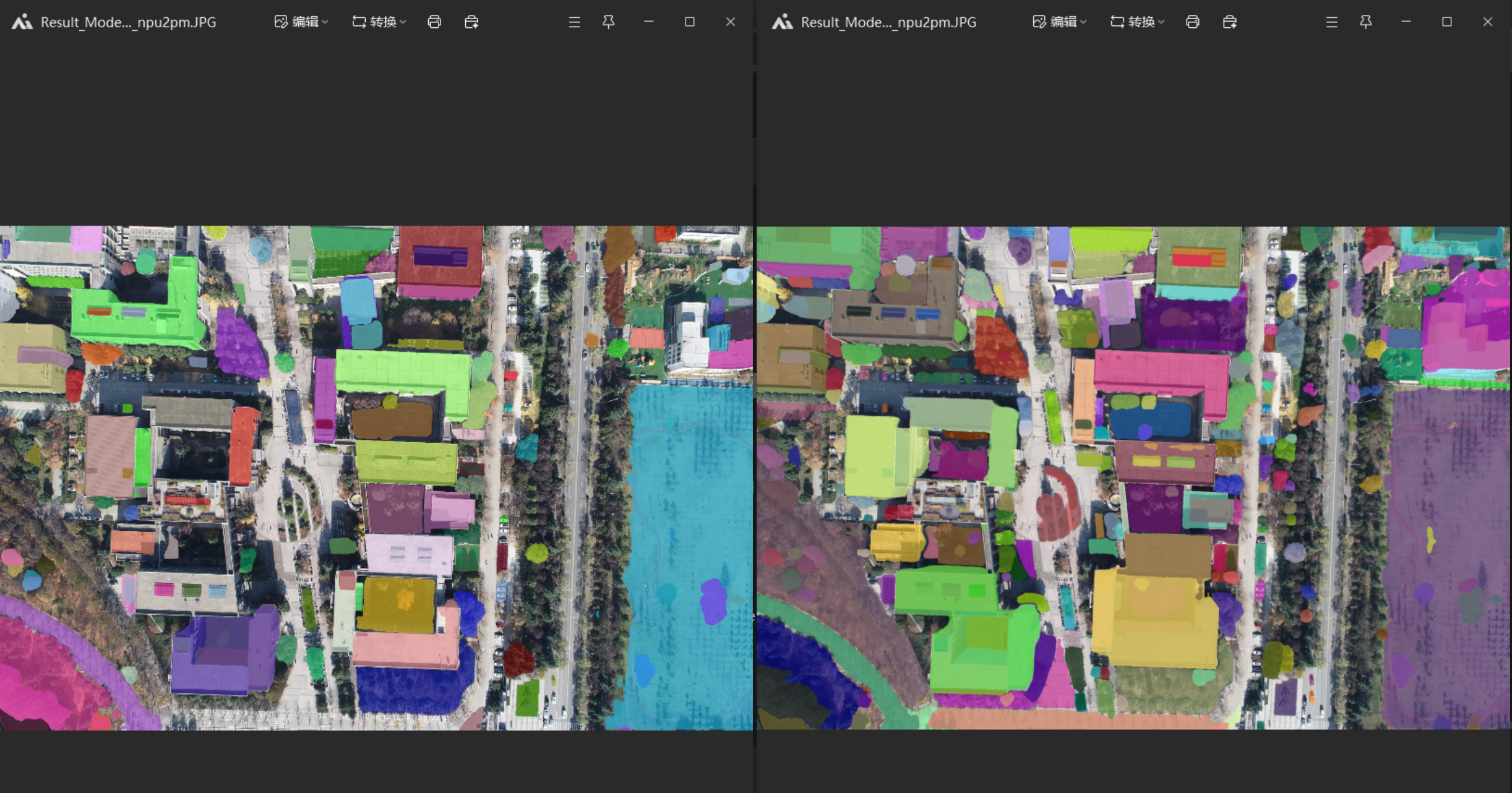
mpu2pm 最好和最差模型 图像压缩一倍

mpu2pm 最好和最差模型 图像原图



import numpy as np
import cv2
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
import torch
import time
'''
环境
win11 coinda - base python12
官方源码
git clone https://github.com/facebookresearch/segment-anything.git
cd segment-anything
权重文件需手动下载
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
PyTorch 需要单独安装
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
依赖库
pip install matplotlib pycocotools opencv-python onnx onnxruntime
# 代码格式工具
pip install flake8 isort black mypy
pip install segment_anything[all]
'''
# 1. 设置设备(GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
def get_model_info(size_key):
"""根据输入返回模型信息"""
return model_mapping.get(size_key, ("未知", "未知"))
# 定义模型映射字典
model_ = {
"Mode2_4g": ("vit_h", "sam_vit_h_4b8939.pth"),
"Mode1_2g": ("vit_l", "sam_vit_l_0b3195.pth"),
"Mode300mb": ("vit_b", "sam_vit_b_01ec64.pth")
}
# 1 图像缩放倍数
scalse=1
# 2 模型选择 最大2_4g 中间1_2g 最小300mb
mode_test='Mode2_4g'
model_type, checkpoint_path = model_.get(mode_test, ("vit_b", "sam_vit_b_01ec64.pth")) # 默认数据
# 3. 加载并预处理图像
image_path = "npu5pm.JPG" # 测试图像路径
image = cv2.imread(image_path)
# 1. 初始化模型
'''
vit_b
vit_l
vit_h
'''
#model_type = "vit_b" # 对应 sam_vit_b_01ec64.pth
'''
sam_vit_b_01ec64 300mb
sam_vit_l_0b3195 1.2g
sam_vit_h_4b8939 2.4g
'''
#checkpoint_path = "./sam_vit_b_01ec64.pth" # 假设权重文件在当前目录
sam = sam_model_registry[model_type](checkpoint=checkpoint_path)
#sam = sam_model_registry[model_type](checkpoint=checkpoint_path).to('cpu')
sam.to(device) # 将模型移至 GPU(如果可用)
# 2. 配置自动分割生成器(参数可根据需求调整)
# mask_generator = SamAutomaticMaskGenerator(
# sam,
# points_per_side=40, # 高空图像需要更密集的点
# pred_iou_thresh=0.9, # 提高质量要求
# min_mask_region_area=200 # 过滤小区域
# )
# #Q2: 分割结果过于碎片化
# # 调整参数
# mask_generator = SamAutomaticMaskGenerator(
# sam,
# points_per_side=20, # 减少点数
# pred_iou_thresh=0.9, # 提高质量阈值
# stability_score_thresh=0.95
# )
mask_generator = SamAutomaticMaskGenerator(
model=sam,
points_per_side=32, # 每边生成的点数
pred_iou_thresh=0.86, # 掩膜质量阈值
stability_score_thresh=0.92, # 稳定性阈值
crop_n_layers=0, # 不使用多层级裁剪
crop_overlap_ratio=0.3, # 裁剪重叠比例
min_mask_region_area=100 # 最小掩膜区域面积(像素)
)
height, width = image.shape[:2]
new_width = int(width // scalse)
new_height = int(height // scalse)
image = cv2.resize(image, (new_width, new_height))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转为RGB格式
# 4. 生成分割掩膜
start_time = time.time()
masks = mask_generator.generate(image)
end_time = time.time()
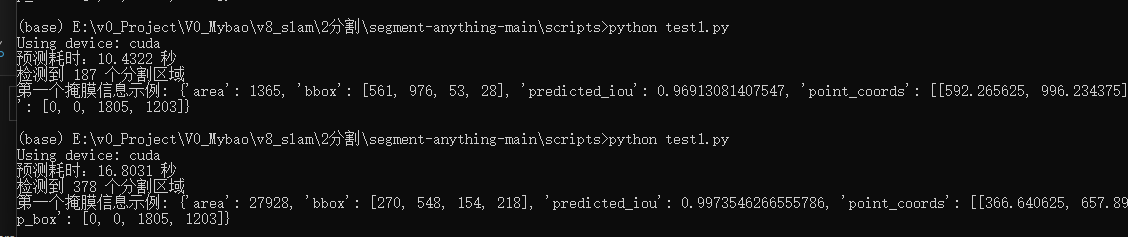
print(f"预测耗时:{end_time - start_time:.4f} 秒") # 保留4位小数
# 5. 可视化结果(可选)
output_image = image.copy()
for mask in masks:
# 为每个掩膜随机生成颜色
color = np.random.randint(0, 256, 3)
# 半透明叠加掩膜区域
output_image[mask['segmentation']] = color * 0.6 + output_image[mask['segmentation']] * 0.4
#Q3: 需要保存掩膜为单独文件
# for i, mask in enumerate(masks):
# cv2.imwrite(f"mask_{i}.png", mask['segmentation'].astype('uint8') * 255)
#提取特定区域的原图内容
# 提取面积最大的前3个对象
# masks_sorted = sorted(masks, key=lambda x: x['area'], reverse=True)[:3]
# for i, mask in enumerate(masks_sorted):
# # 创建透明背景的PNG
# rgba = cv2.cvtColor(image, cv2.COLOR_RGB2RGBA)
# rgba[~mask['segmentation']] = [0,0,0,0] # 非掩膜区域透明
# cv2.imwrite(f"object_{i}.png", rgba)
'''
输出结果解析:
每个 mask包含:
segmentation: 二值掩膜矩阵
area: 区域像素面积
bbox: [x,y,width,height] 边界框
predicted_iou: 模型预测的质量分数
stability_score: 稳定性评分
'''
# 保存结果
cv2.imwrite("Result_"+mode_test+"_"+str(scalse)+"_"+image_path, cv2.cvtColor(output_image, cv2.COLOR_RGB2BGR))
# 打印分割结果统计
print(f"检测到 {len(masks)} 个分割区域")
print("第一个掩膜信息示例:", {k: v for k, v in masks[0].items() if k != 'segmentation'})
后期加速


 浙公网安备 33010602011771号
浙公网安备 33010602011771号