

自己的答案

class Solution {
public:
std::map<char,int> GetStringMap(string msg_){
std::map<char,int> charMap;
for(char c : msg_)
{
charMap[c]++;
}
// std::cout<< "单词组成: "<< msg_ << " || ";
// for(auto &pair:charMap){
// std::cout<<pair.first <<'/' <<pair.second << " " ;
// }
// std::cout << std::endl;
return charMap;
}
vector<vector<string>> groupAnagrams(vector<string>& strs) {
std::multimap<std::map<char,int>, std::string> m_map;
// for (const auto& element : vec) {
// std::cout << element << " ";
// }
for (auto i=0;i< strs.size();++i){
string mgs_=strs[i];
std::map<char,int> map_i = GetStringMap(mgs_);
auto it= m_map.find(map_i);
// if(it !=m_map.end()){
// std::cout<< "存在" <<std::endl;
// }
// else{
// std::cout<< "不存在" <<std::endl;
// }
// m_map.insert(std::make_pair(map_i,mgs_));
m_map.insert({map_i,mgs_});
}
//std::multimap<std::map<char,int>, std::string> m_map;
std::vector<std::vector<string>> result;
for(auto mmap_i = m_map.begin(); mmap_i != m_map.end();){
// for( auto &mmap_i : m_map){
//std::cout<< "字符:"<< mmap_i.second <<std::endl;
auto range = m_map.equal_range(mmap_i->first);
std::vector<string> i_string;
for (auto rangeIt = range.first; rangeIt != range.second; ++rangeIt) {
//std::cout<< "字符:"<< rangeIt->second <<' ';
i_string.push_back(rangeIt->second);
}
// std::cout <<std::endl;
result.push_back(i_string);
mmap_i=range.second;
}
return result;
}
};
改进版
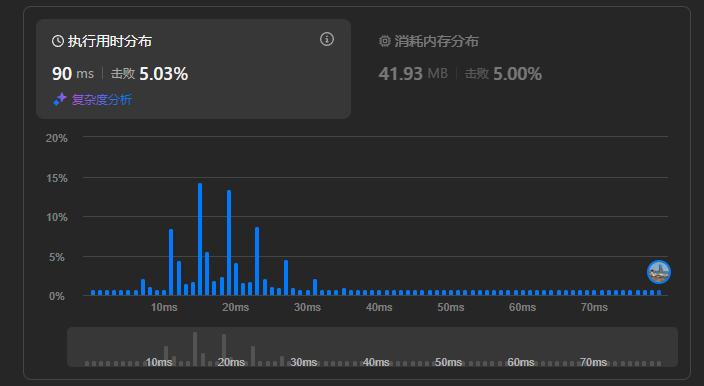
class Solution { public: std::map<char,int> GetStringMap(string msg_){ std::map<char,int> charMap; for(char c : msg_) { charMap[c]++; } return charMap; } vector<vector<string>> groupAnagrams(vector<string>& strs) { std::map<std::map<char,int>, vector<string>> m_map; for (auto i=0;i< strs.size();++i){ string mgs_=strs[i]; std::map<char,int> map_i = GetStringMap(mgs_); //m_map.insert({map_i,mgs_}); m_map[map_i].emplace_back(mgs_); } //std::multimap<std::map<char,int>, std::string> m_map; std::vector<std::vector<string>> result; for(auto it = m_map.begin(); it!=m_map.end();++it){ result.emplace_back(it->second); } return result; } };
官方答案 1排序
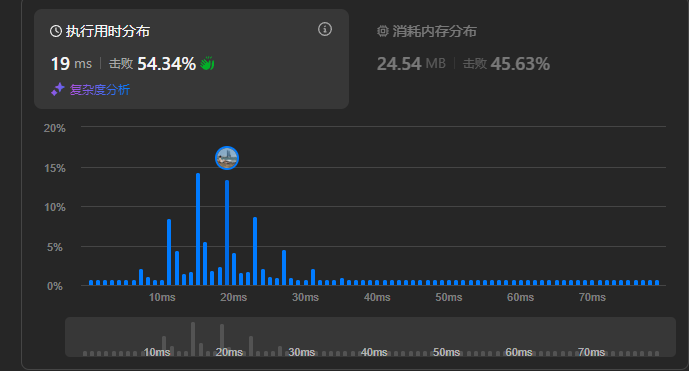
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> mp;
for (string& str: strs) {
string key = str;
sort(key.begin(), key.end());
mp[key].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};
作者:力扣官方题解
链接:https://leetcode.cn/problems/group-anagrams/solutions/520469/zi-mu-yi-wei-ci-fen-zu-by-leetcode-solut-gyoc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
方法二:计数
由于互为字母异位词的两个字符串包含的字母相同,因此两个字符串中的相同字母出现的次数一定是相同的,故可以将每个字母出现的次数使用字符串表示,作为哈希表的键。
由于字符串只包含小写字母,因此对于每个字符串,可以使用长度为 26 的数组记录每个字母出现的次数。需要注意的是,在使用数组作为哈希表的键时,不同语言的支持程度不同,因此不同语言的实现方式也不同。
作者:力扣官方题解
链接:https://leetcode.cn/problems/group-anagrams/solutions/520469/zi-mu-yi-wei-ci-fen-zu-by-leetcode-solut-gyoc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
// 自定义对 array<int, 26> 类型的哈希函数
auto arrayHash = [fn = hash<int>{}] (const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {
return (acc << 1) ^ fn(num);
});
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
for (string& str: strs) {
array<int, 26> counts{};
int length = str.length();
for (int i = 0; i < length; ++i) {
counts[str[i] - 'a'] ++;
}
mp[counts].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};
作者:力扣官方题解
链接:https://leetcode.cn/problems/group-anagrams/solutions/520469/zi-mu-yi-wei-ci-fen-zu-by-leetcode-solut-gyoc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号