

https://blog.csdn.net/weixin_44771532/article/details/105495755
优先看
https://my.oschina.net/u/4581492/blog/4371683
yolov3-aconda-python
https://blog.csdn.net/maweifei/article/details/81204702
yolov4-ubuntu-c
https://www.cnblogs.com/monologuesmw/p/13035442.html
yolov4-win0-c
https://blog.csdn.net/john_bh/article/details/80625220
https://blog.csdn.net/u012135425/article/details/80294884
外网
https://pysource.com/2020/04/02/train-yolo-to-detect-a-custom-object-online-with-free-gpu/
详细
https://blog.csdn.net/weixin_41010198/article/details/106072347
详细
https://www.cnblogs.com/xieqi/p/9818056.html
4)下载预训练的参数(卷积权重)
“darknet53.conv.74”是使用 Imagenet 数据集进行预训练:
|
1
|
wget https://pjreddie.com/media/files/darknet53.conv.74 # 下载预训练的网络模型参数 |
获取其他模型类似 darknet53.conv.74 的预训练权重
Ⅰ. 下载官方预训练模型的权重
https://pjreddie.com/darknet/yolo/ //COCO数据集训练的
https://pjreddie.com/darknet/imagenet/ //Imagenet数据集训练的
eg: wget https://pjreddie.com/media/files/yolov3-tiny.weights
Ⅱ. 转换为类似darknet.conv.74的预训练权重
eg: ./darknet partial cfg/yolov3-tiny yolov3-tiny.weights yolov-tiny.conv.15 15
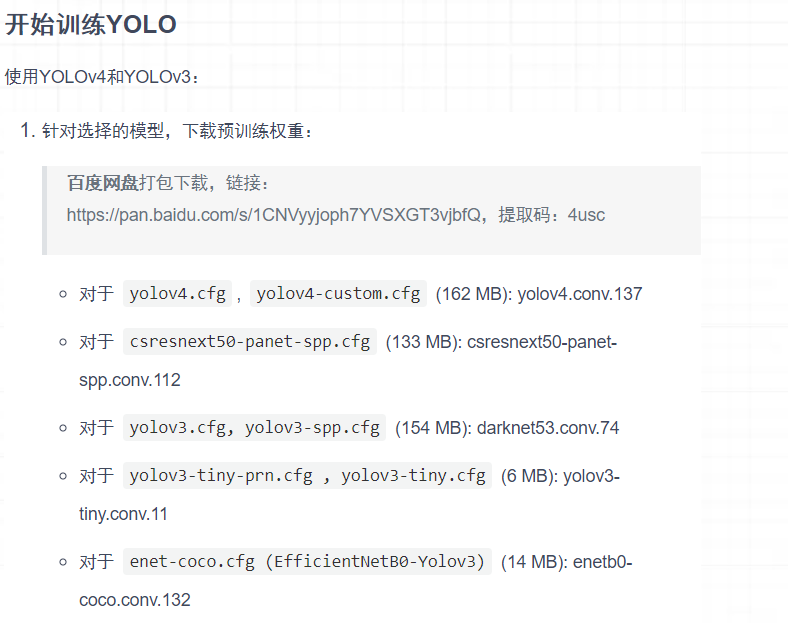
开始训练YOLO
使用YOLOv4和YOLOv3:
1. 针对选择的模型,下载预训练权重:
百度网盘打包下载,链接:https://pan.baidu.com/s/1CNVyyjoph7YVSXGT3vjbfQ,提取码:4usc
o 对于 yolov4.cfg, yolov4-custom.cfg (162 MB): yolov4.conv.137
o 对于 csresnext50-panet-spp.cfg (133 MB): csresnext50-panet-spp.conv.112
o 对于 yolov3.cfg, yolov3-spp.cfg (154 MB): darknet53.conv.74
o 对于 yolov3-tiny-prn.cfg , yolov3-tiny.cfg (6 MB): yolov3-tiny.conv.11
o 对于 enet-coco.cfg (EfficientNetB0-Yolov3) (14 MB): enetb0-coco.conv.132
5)训练模型:
Ⅰ. 单GPU训练: ./darknet detector train <data_cfg> <train_cfg> <weights> -gpu <gpu_id>
|
1
|
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -i 1 |
Ⅱ. 多GPU训练: ./darknet detector train <data_cfg> <model_cfg> <weights> -gpus <gpu_list>
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpus 0,1,2,3
Ⅲ. 从checkpoint继续训练
|
1
|
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup -gpus 0,1,2,3 |
https://my.oschina.net/u/4581492/blog/4371683
7. 训练结束,结果保存在darknet\backup\yolo-obj_final.weights
-
如果训练中断,可以选择一个保存的权重继续训练,使用
./darknet detector train data/obj.data yolo-obj.cfg backup\yolo-obj_2000.weights
yoloV3参数理解及注释
https://blog.csdn.net/qq_33485434/article/details/80907040
[net] # Testing #batch=1 #subdivisions=1 # Training batch=64 一批训练样本的样本数量,每batch个样本更新一次参数 subdivisions=64 batch/subdivisions作为一次性送入训练器的样本数量 如果内存不够大,将batch分割为subdivisions个子batch 上面这两个参数如果电脑内存小,则把batch改小一点,batch越大,训练效果越好 subdivisions越大,可以减轻显卡压力 width=416 height=416 channels=3 以上三个参数为输入图像的参数信息 width和height影响网络对输入图像的分辨率, 从而影响precision,只可以设置成32的倍数,提高 cfg中指定的分辨率, 比如 height = 608, width = 608 或者更高的32的倍数 momentum=0.9 DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值得速度 decay=0.0005 权重衰减正则项,防止过拟合 angle=0 通过旋转角度来生成更多训练样本 saturation = 1.5 通过调整饱和度来生成更多训练样本 exposure = 1.5 通过调整曝光量来生成更多训练样本 hue=.1 通过调整色调来生成更多训练样本 learning_rate=0.001 学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。 如果仅靠人为干预调整参数,需要不断修改学习率。刚开始训练时可以将学习率设置的高一点, 而一定轮数之后,将其减小 在训练过程中,一般根据训练轮数设置动态变化的学习率。 刚开始训练时:学习率以 0.01 ~ 0.001 为宜。 一定轮数过后:逐渐减缓。 接近训练结束:学习速率的衰减应该在100倍以上。 学习率的调整参考https://blog.csdn.net/qq_33485434/article/details/80452941 burn_in=1000 在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式 max_batches = 500200 训练达到max_batches后停止学习 policy=steps 这个是学习率调整的策略,有policy:constant, steps, exp, poly, step, sig, RANDOM,constant等方式 参考https://nanfei.ink/2018/01/23/YOLOv2%E8%B0%83%E5%8F%82%E6%80%BB%E7%BB%93/#more steps=40000,45000 下面这两个参数steps和scale是设置学习率的变化,比如迭代到40000次时,学习率衰减十倍。 scales=.1,.1 45000次迭代时,学习率又会在前一个学习率的基础上衰减十倍 [convolutional] batch_normalize=1 ? filters=32 输出特征图的数量 size=3 卷积核的尺寸 stride=1 做卷积运算的步长 pad=1 如果pad为0,padding由 padding参数指定。 如果pad为1,padding大小为size/2,padding应该是对输入图像左边缘拓展的像素数量 activation=leaky 激活函数的类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号