大数据概述
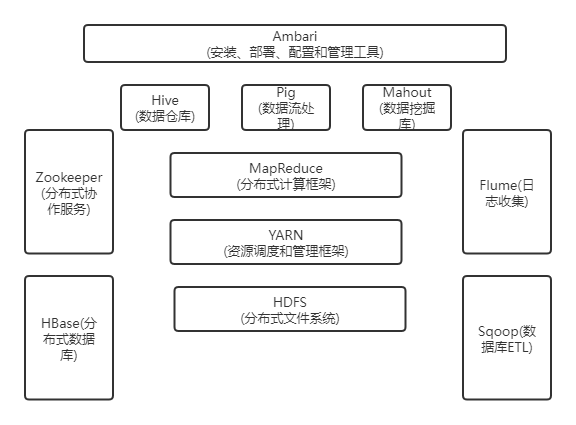
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
生态系统就是很多组件组成的一个生态链,经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包括了多个子项目,除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括要ZoopKer、HBase、Hive、Pig、Mahout、Sqoop、Flume、Ambari等功能组件。这些组件几乎覆盖了目前业界对数据处理的所有场景。
2.对比Hadoop与Spark的优缺点。
1.Spark对标于Hadoop中的计算模块MR,但是速度和效率比Hadoop要快;
2.Spark可以使用基于HDFS的HBase数据库,也可以使用HDFS的数据文件,还可以通过jdbc连接使用Mysql数据库数据;Spark可以对数据库数据进行修改删除,而HDFS只能对数据进行追加和全表删除;
3.Spark处理数据的设计模式与MR不一样,Hadoop是从HDFS读取数据,通过MR将中间结果写入HDFS;然后再重新从HDFS读取数据进行MR,再刷写到HDFS,这个过程涉及多次落盘操作,多次磁盘IO,效率并不高;而Spark的设计模式是读取集群中的数据后,在内存中存储和运算,直到全部运算完毕后,再存储到集群中;
4.Spark中RDD一般存放在内存中,如果内存不够存放数据,会同时使用磁盘存储数据;通过RDD之间的血缘连接、数据存入内存中切断血缘关系等机制,可以实现灾难恢复,当数据丢失时可以恢复数据;这一点与Hadoop类似,Hadoop基于磁盘读写,天生数据具备可恢复性;
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号