目标分割核心原理

分割演示
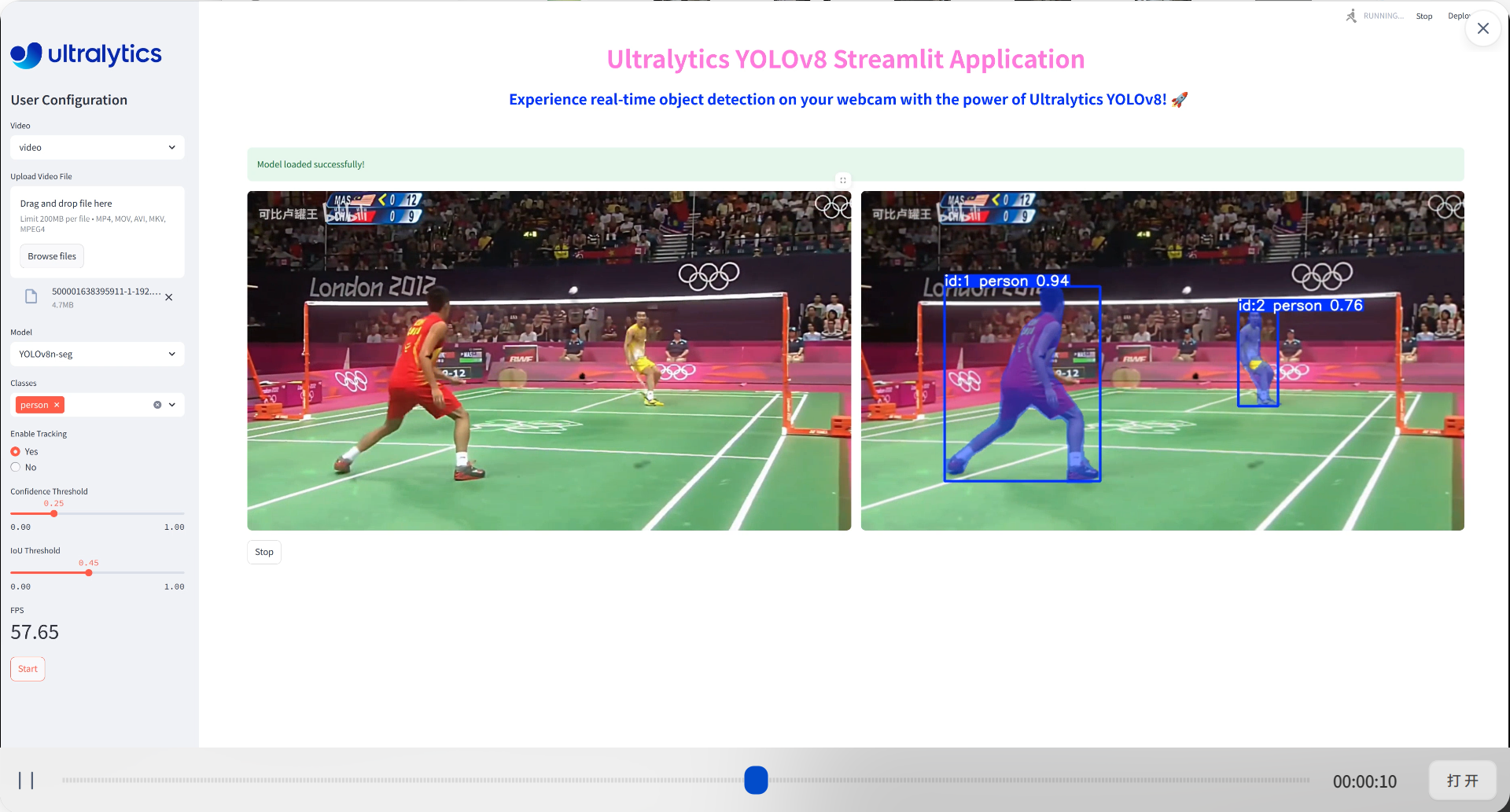
目标检测输出是:矩形框 + 类别 + 置信度
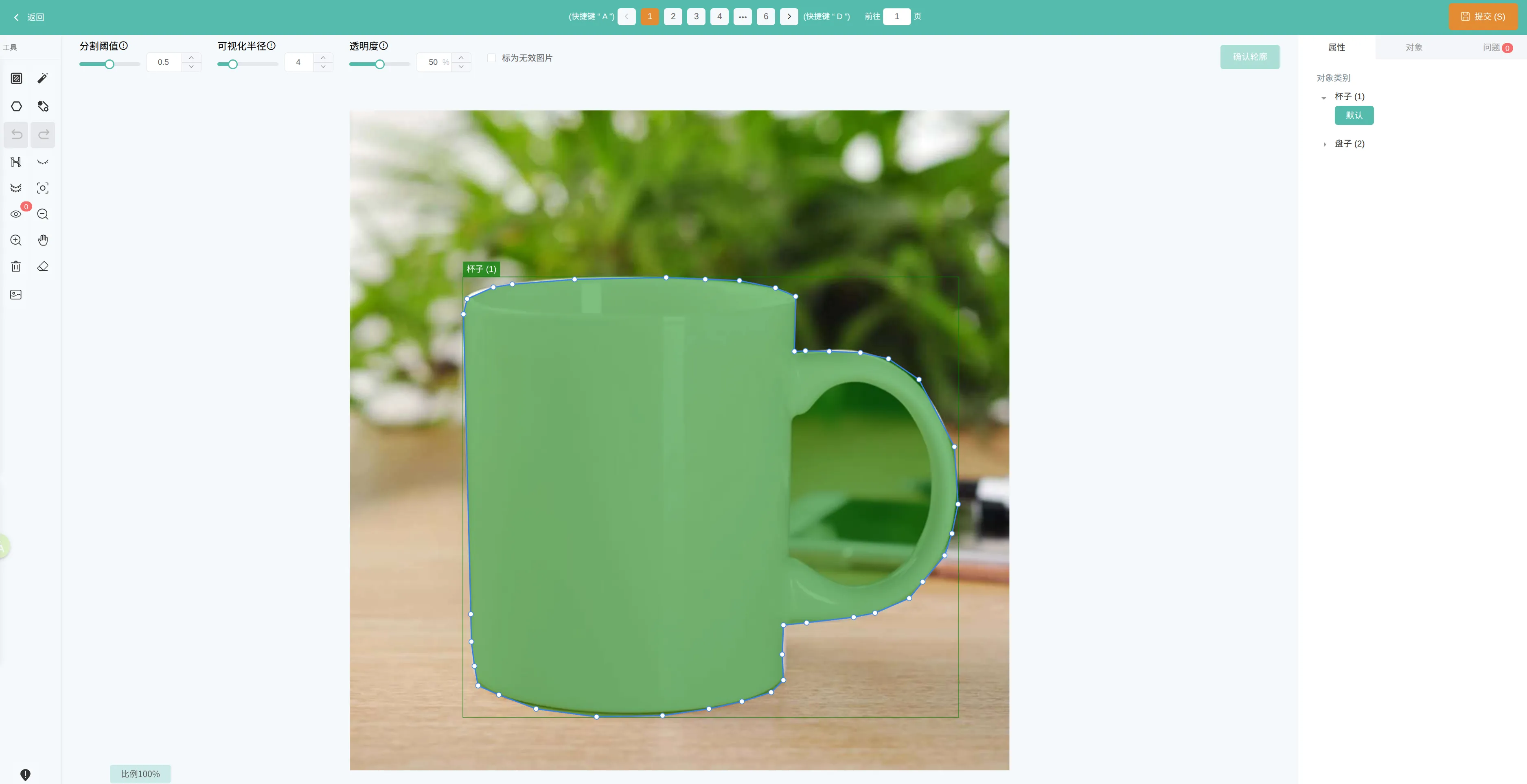
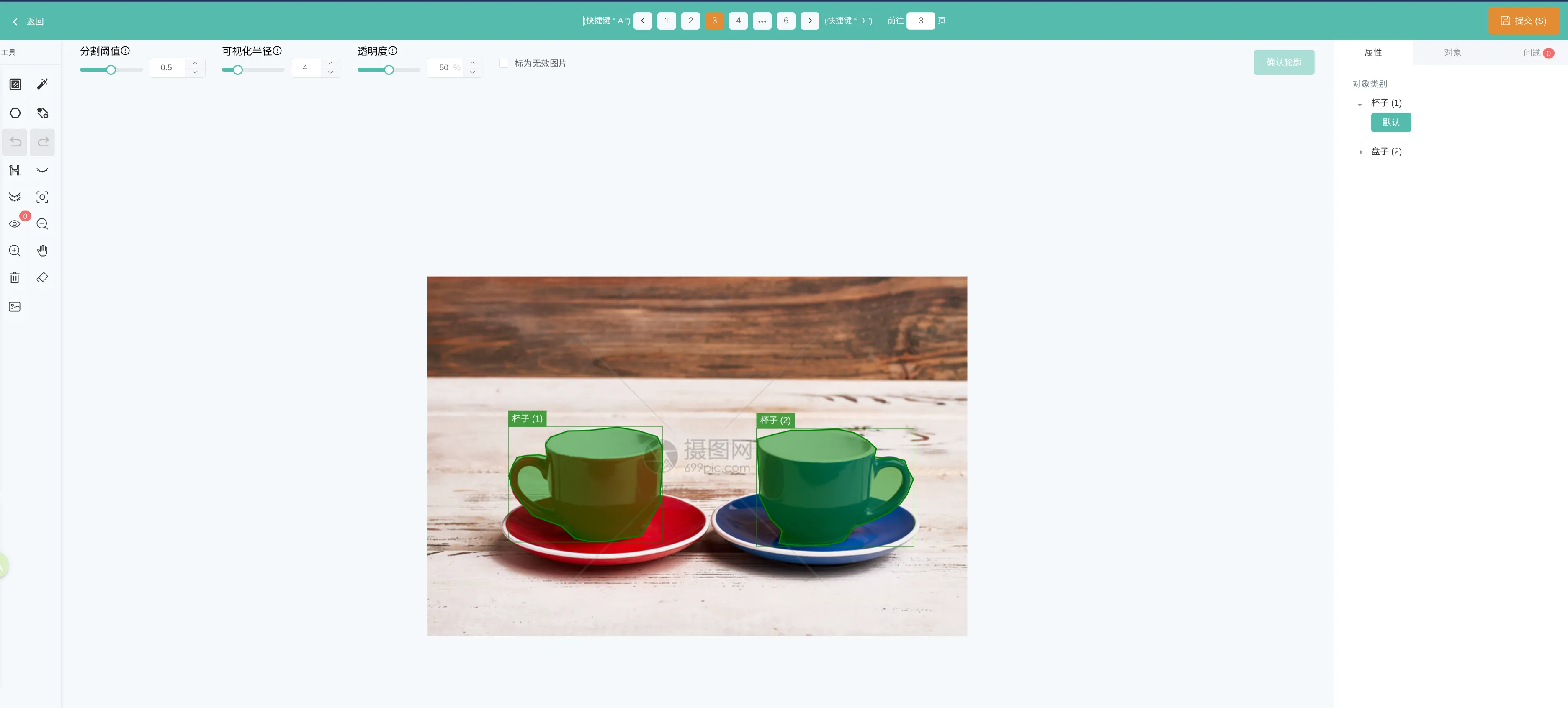
目标分割输出:分割掩码 + 矩形框 + 类别 + 置信度

ultrylytics 自带的演示页面:
视觉颗粒度
从“颗粒度”(Granularity)的视角来理解计算机视觉的四大核心任务,可以帮助我们清晰地把握它们的内在联系和演进逻辑。
这四种任务的颗粒度从粗到细可以排列为:分类 < 检测 < 分割 ≈ 姿态估计。

下面进行详细分解:
- 图像分类(Image Classification)
- 颗粒度:图像级( Image-Level) - 最粗的颗粒度。
- 任务描述: 回答“这张图像是什么?”的问题。为整张图像分配一个或多个标签。
- 关注点: 图像的全局内容和语义信息。它不关心物体在哪里、有多少个、具体形状如何。
- 输出形式: 一个概率向量,如
[0.1, 0.8, 0.1](对应[猫, 狗, 汽车])。 - 可视化: 整个图像被“粗暴”地归类为一个标签。
- 目标检测(Object Detection)
- 颗粒度:对象级( Object-Level) - 中等颗粒度。
- 任务描述: 回答“图像里有什么?它们在哪儿?”的问题。不仅要识别出物体类别,还要用矩形框(Bounding Box) 定位出每个物体的位置。
- 关注点: 离散的物体实例及其粗略的 spatial extent(空间范围)。
- 输出形式: 一组列表,每个列表项为
[x_min, y_min, x_max, y_max, confidence, class_id]。 - 可视化: 图像上画出多个矩形框和标签。
- 语义分割(Semantic Segmentation) & 实例分割(Instance Segmentation)
- 颗粒度:像素级( Pixel-Level) - 细颗粒度。
- 任务描述: 回答“图像的每一个像素属于什么?”的问题。
- 语义分割: 为每个像素分类,不区分同一类别的不同实例(所有狗都是同一个标签)。
- 实例分割: 在语义分割的基础上,区分开同一类别的不同个体(狗A、狗B、狗C有不同的标签)。
- 关注点: 物体的精确形状、轮廓和边界。
- 输出形式: 一张与输入图像同尺寸的分割掩码图(Mask),其中每个像素的值代表其类别或实例ID。
- 可视化: 不同类别或实例的区域被涂上不同的颜色。
- 姿态估计(Pose Estimation)
- 颗粒度:关键点级 (Keypoint-Level) - 最细的颗粒度之一。
- 任务描述: 回答“物体的关键骨骼点在哪里?它们是如何连接的?”的问题。通常用于人体、动物、车辆等。
- 关注点: 物体内部的结构性关键点及其拓扑关系(连接方式)。
- 输出形式: 一组关键点的坐标
[x, y, visibility]以及它们之间的连接关系。 - 可视化: 在图像上标出点并连成线,形成“骨骼图”。
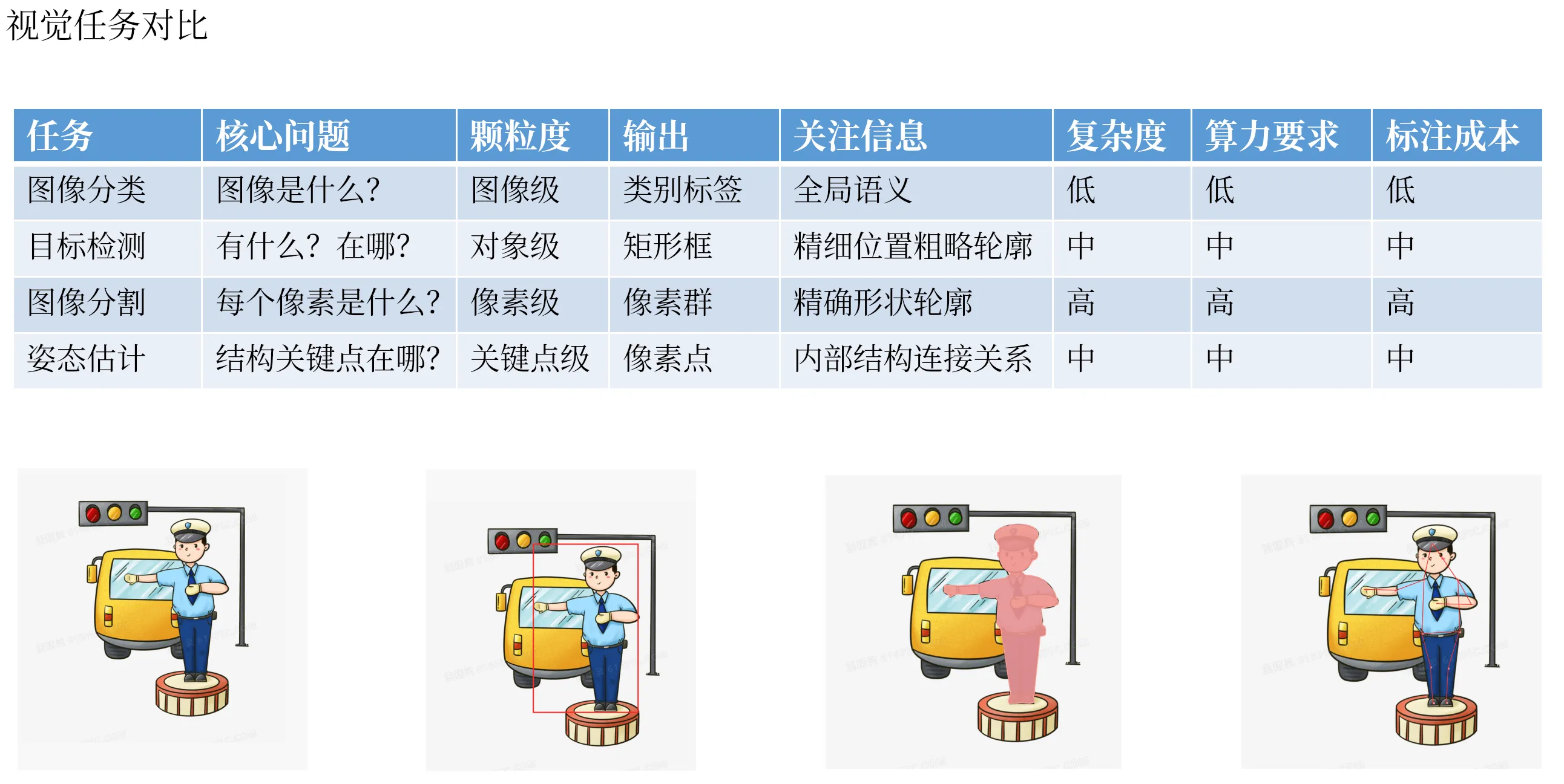
颗粒度演进总结与对比
| 任务 | 核心问题 | 颗粒度 | 输出单位 | 关注信息 |
|---|---|---|---|---|
| 图像分类 | 图像是什么? | 图像级 | 整张图片 | 全局语义 |
| 目标检测 | 有什么?在哪? | 对象级 | 矩形框 | 实例、粗略位置 |
| 图像分割 | 每个像素是什么? | 像素级 | 像素 | 精确形状、轮廓 |
| 姿态估计 | 结构关键点在哪? | 关键点级 | 点坐标 | 内部结构、连接关系 |
内在逻辑与关系
- 层层递进,逐步细化:这个排序展示了一条清晰的技术发展路径:从理解整张图(分类),到找到物体(检测),再到精确描绘物体(分割),最后到解析物体的内部结构(姿态估计)。后一个任务往往以前一个任务为基础(例如,要先检测到人,才能做人的姿态估计)。
- 信息量与任务复杂度:通常,颗粒度越细,需要模型处理的信息量就越大,任务也越复杂。例如,分割需要为成千上万个像素做预测,而检测只需要为几十个对象做预测。因此,分割和姿态估计模型通常比分类和检测模型更慢、计算成本更高。
- 标注成本:颗粒度也直接决定了数据标注的成本。颗粒度越细,标注成本呈指数级上升。标一张分类图片只需一个标签;标检测需要画框;标分割需要精确勾勒轮廓;标姿态需要准确点出几十个关键点。
因此,按照颗粒度从粗到细的分类顺序为:分类 → 检测 → (语义/实例)分割 → 姿态估计。
分割基础
https://zhuanlan.zhihu.com/p/696216736
图像分割主要分为三大领域:语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)、全景分割(Panoptic Segmentation):
•语义分割:每个像素对应一个类标签。同一类会被定义成一个区域块,不区分其中单个物体。
•实例分割:每个对象的掩码和类标签。区分单个物体以及单个物体所属的类型,无法识别的都作为背景。
•全景分割:每像素类+实例标签。相当于在语义分割的基础上,增加单个实例的区分。


分割数据类型
https://blog.csdn.net/weixin_44966641/article/details/123171026
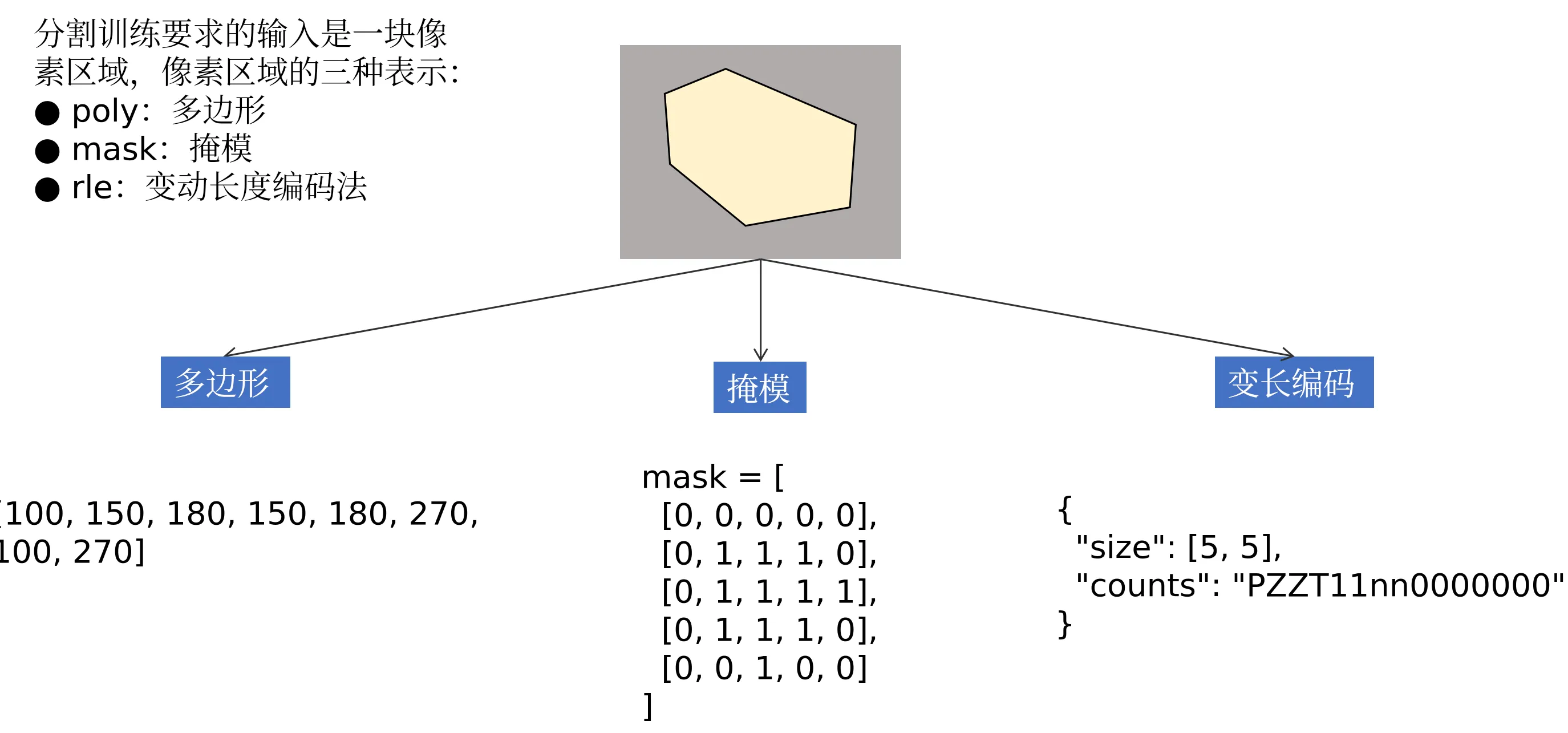
分割标签的三种表示:
- poly:多边形
- mask:掩模
- rle:变动长度编码法
标注:
分割任务只要求模型输出像素级(或点级)标签,至于原始真值是怎么来的,可以是
- 逐像素手绘掩膜(pixel-wise mask)
- 多边形(polygon)
- 涂色刷(brush)
- 交互式点击/ scribble
- 3D 点云里直接给每个点一个类别 ID
只要最终能还原成与图像尺寸一一对应的单通道 mask(或 RLE、COCO 的 counts 游程编码),就算合格的分割标注。
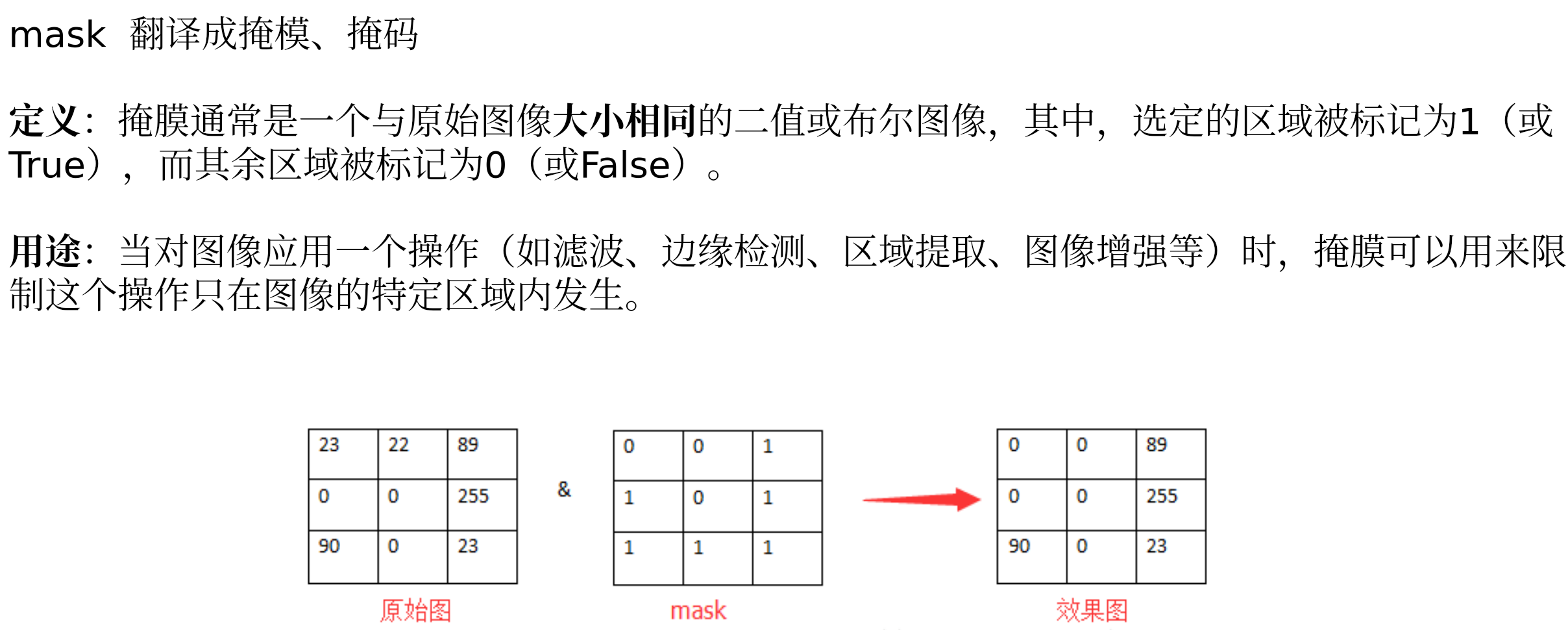
mask 掩模介绍:
涂色刷:
https://blog.csdn.net/qq_44840741/article/details/127692071#
交互式点击:
https://blog.csdn.net/qq_46226356/article/details/128790541
https://paddlecv-sig.github.io/PaddleLabel/CN/ML/interactive_segmentation.html
分割标注
分割任务只要求模型输入掩模,至于标注数据是怎么来的,可以是:
- 多边形(polygon)
- 涂色刷(brush)
- 交互式点击/ scribble
只要最终能还原成与图像尺寸一一对应的 mask,就算合格的分割标注。可以使用的工具有如下:

通过 Label Studio 来绘制分割数据集
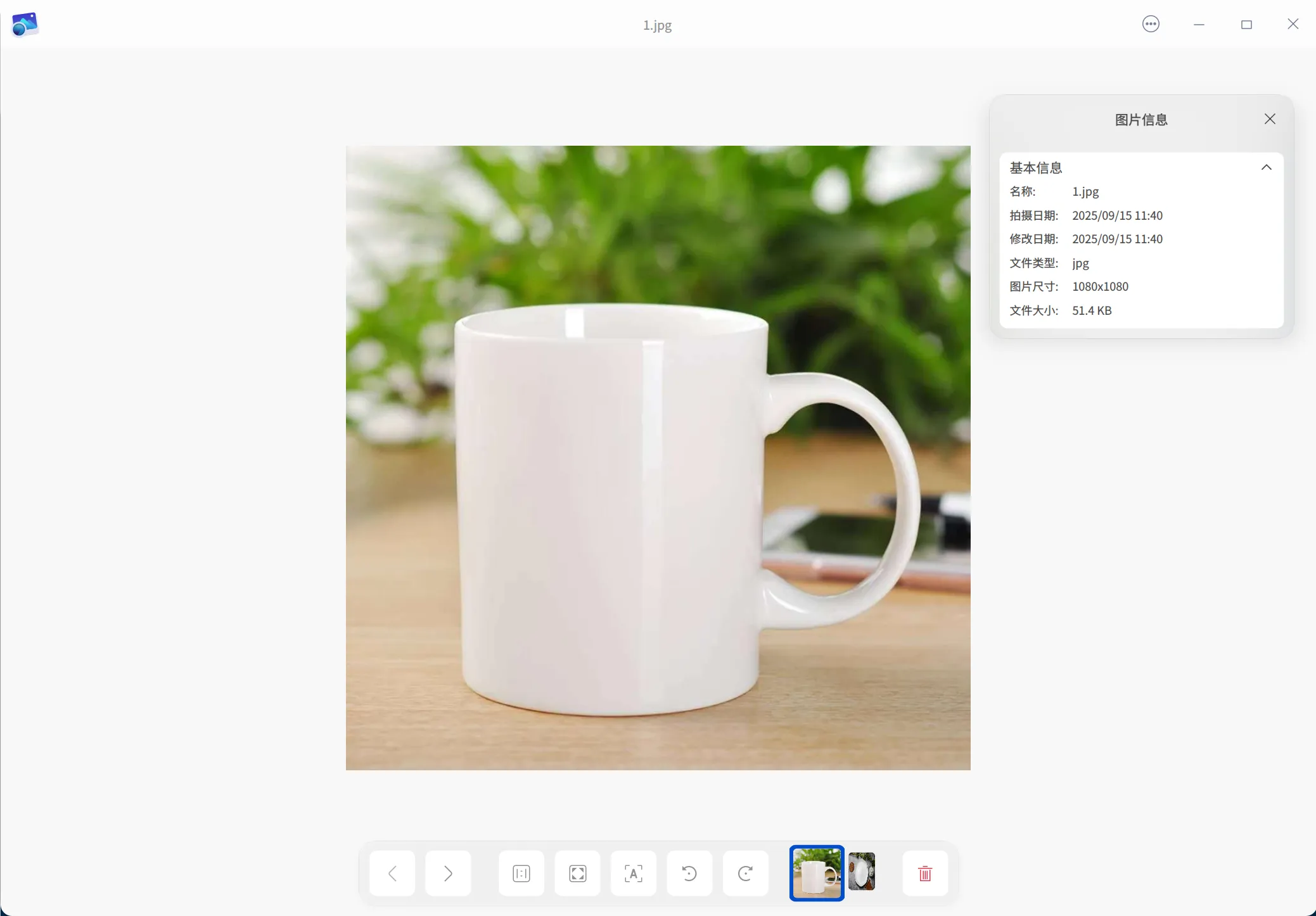
多边形:


mask 图:
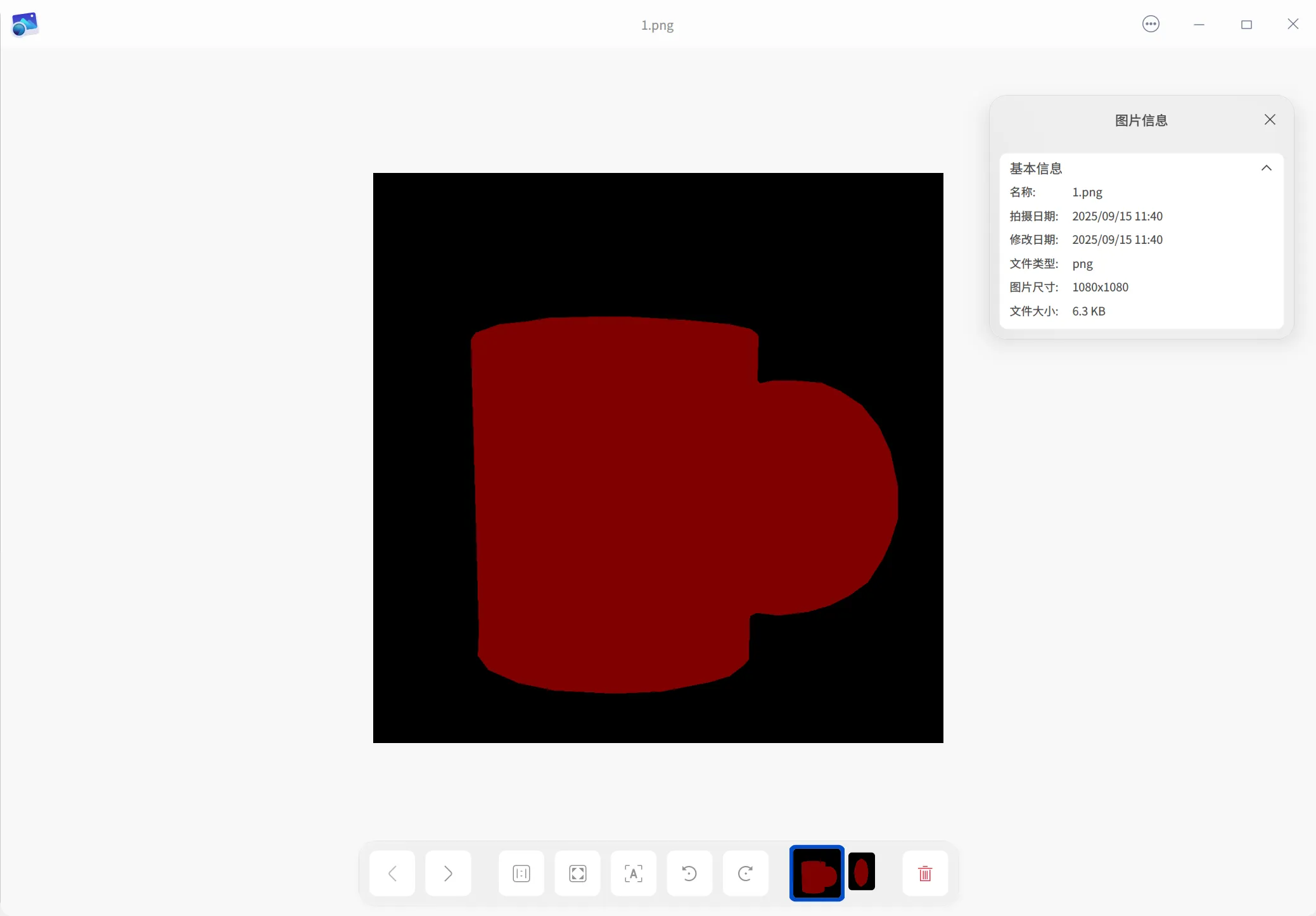
>>> import numpy
>>>
>>>
>>> a = numpy.load("1.npy")
>>> a
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int32)
>>> a.shape
(1080, 1080)
不同格式的数据集表示:

更多可以参考:https://blog.csdn.net/u011425939/article/details/149912539
分割经典网络
分割网络包括:

FCN(Fully Convolutional Network,2015)
首次把分类网络改成全卷积结构,用转置卷积做上采样,端到端输出像素级标签。
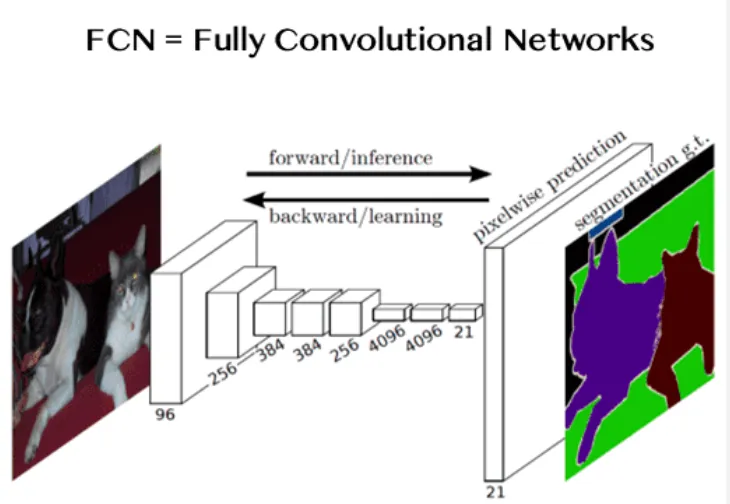
U-Net
U-Net 是一个经典的图像分割模型,最初设计用于生物医学图像分割。其架构采用编码器-解码器结构,通过跳跃连接将低级特征传递到更高级别,从而保留更详细的信息。
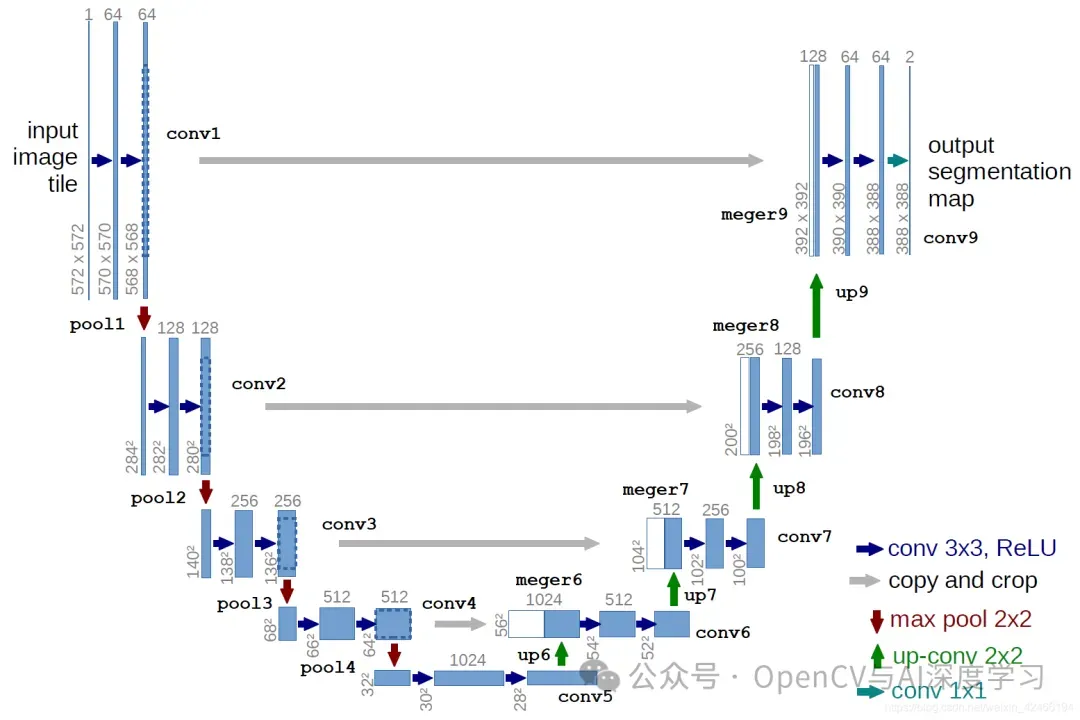
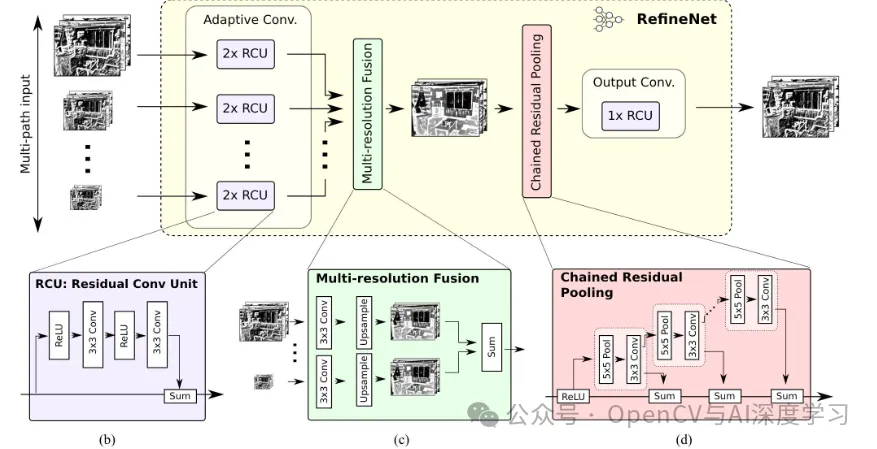
RefineNet
RefineNet 是一个多路径细化网络,它通过多路径细化模块逐步细化特征图,从而提高分割精度。
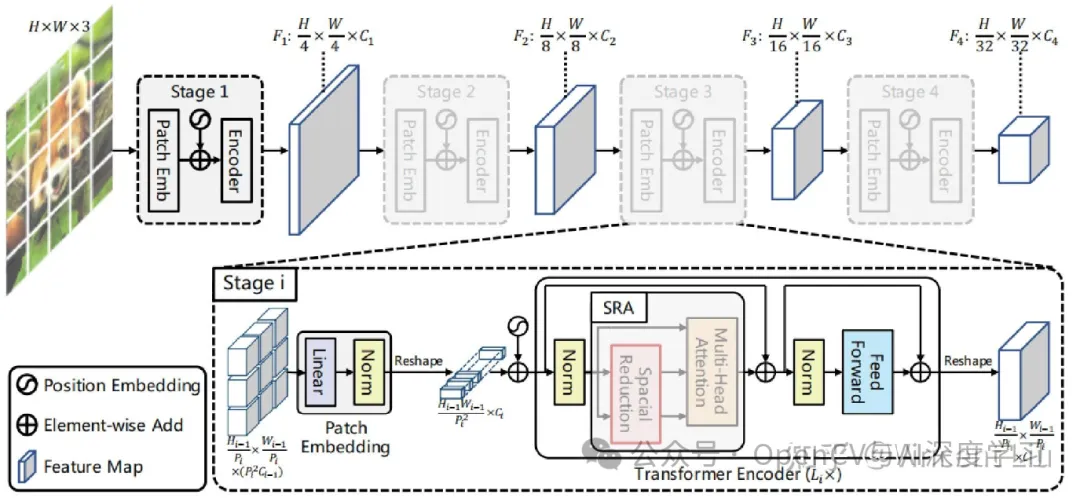
Swin Transformer
Swin Transformer 是一个基于 Transformer 架构的图像分割模型,通过分层自注意力机制捕捉长距离依赖关系,提高分割准确率。
yolov8 分割任务
输出
from ultralytics import YOLO
model = YOLO("yolov8n-seg.pt")
model.predict("/home/xxx/Desktop/tmp/分割/seg_images/1.jpg", save=True, imgsz=640, conf=0.5)

输出类型包括:
- 多边形
- 归一化多边形
- mask图 掩模
示例:
import cv2 as cv
from ultralytics import YOLO
model = YOLO("yolov8n-seg.pt")
image_path = "/home/lijinkui/Desktop/tmp/分割/seg_images/1.jpg"
image = cv.imread(image_path)
print(image.shape)
res = model.predict(
image_path,
imgsz=640,
conf=0.3,
iou=0.4,
device="cuda:0",
verbose=True
)
for item in res:
xy = item.masks.xy # 多边形结果
print("-----------xy-----------")
print(xy)
xyn = item.masks.xyn # 归一化的多边形结果
print("-------------xyn-----------")
print(xyn)
masks = item.masks.data # 掩模
print("-------------masks-----------")
print(masks)
print("-------------numpy------------")
print(masks.cpu().numpy()) # numpy 掩模
输出:
-----------xy-----------
[array([[ 276.75, 273.38],
[ 276.75, 278.44],
[ 275.06, 280.12],
[ 271.69, 280.12],
[ 270, 281.81],
[ 263.25, 281.81],
[ 261.56, 283.5],
[ 254.81, 283.5],
[ 253.12, 285.19],
[ 244.69, 285.19],
[ 243, 286.88],
[ 234.56, 286.88],
[ 232.88, 288.56],
[ 226.12, 288.56],
[ 224.44, 290.25],
[ 219.38, 290.25],
[ 217.69, 291.94],
[ 212.62, 291.94],
-------------xyn-----------
[array([[ 0.25625, 0.25313],
[ 0.25625, 0.25781],
[ 0.25469, 0.25938],
[ 0.25156, 0.25938],
[ 0.25, 0.26094],
[ 0.24375, 0.26094],
[ 0.24219, 0.2625],
-------------masks-----------
tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]], device='cuda:0')
-------------numpy------------
[[[ 0 0 0 ... 0 0 0]
[ 0 0 0 ... 0 0 0]
[ 0 0 0 ... 0 0 0]
...
[ 0 0 0 ... 0 0 0]
[ 0 0 0 ... 0 0 0]
[ 0 0 0 ... 0 0 0]]]
----------输入尺寸-----------
(1080, 1080, 3)
-------------输出尺寸------------
torch.Size([1, 640, 640])
YOLOv8 分割基本原理

经典使用场景
自动驾驶:精准识别道路中的行人、车辆及障碍物,为路径规划提供支持。
医学影像分析:分割肿瘤区域、器官轮廓,辅助医生诊断与手术规划。
工业质检:检测产品表面缺陷并定位异常区域,提升质检效率。
遥感图像处理:区分地表建筑、植被等地物类型,支持环境监测与城市规划。
一、自动驾驶
在自动驾驶场景中,汽车通过摄像头实时捕捉周围场景,利用图像语义分割技术判断每个像素的预测类别,对周围的其他汽车、行人等进行避让,或者识别车道线以判断行驶方向

二、医学影像分析
对人体不同器官部位进行图像语义分割可以辅助医师更好地判断医学影像中可能出现的病灶
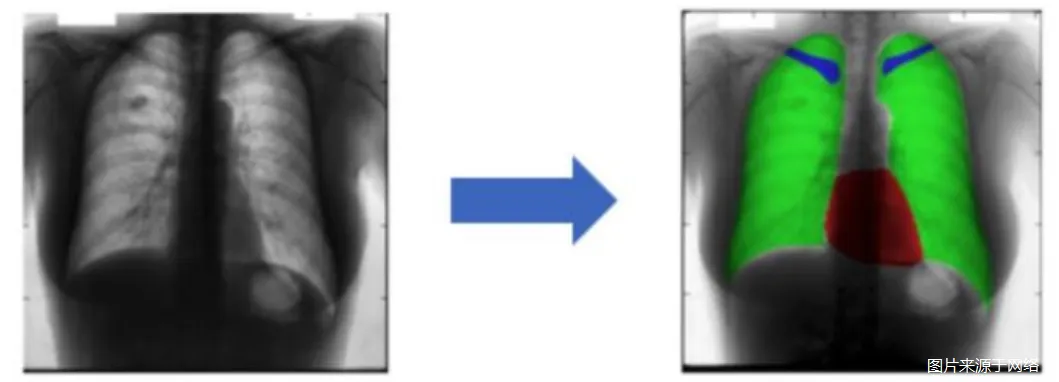
三、扣图算法

四、遥感图像处理
遥感图像处理:区分地表建筑、植被等地物类型,支持环境监测与城市规划

五、工业质检
检测产品表面缺陷并定位异常区域,提升质检效率。

六、社区工地在贴近公司业务的社区场景和工地场景中,分割可以完成的任务也有很多,包括:渣土车覆盖检测:分割出车厢与渣土区域,判断绿网是否100%覆盖。运动相机:无法画区域,需要通过分割检测出区域,如铁轨入侵


 浙公网安备 33010602011771号
浙公网安备 33010602011771号