

在美团金服负责过稳定性相关事宜,最近在百人助贷研发团队也负责了稳定性相关工作,我对百人研发团队稳定性的认知有了部分迭代:
- 百人研发团队的技术基建能力比起大厂,要差很多,而且不能全面覆盖,只能搞重点建设。
- 稳定性认知,或者标准需要看齐大厂,否则不以为是,频繁出大事故,谁也受不了。
- 现在AI能力很强,可以借助AI做改动风险分析巡检,把普通研发的能力提升起来。
一、稳定性能力建设
能力建设要围绕下面两方面来展开:
-
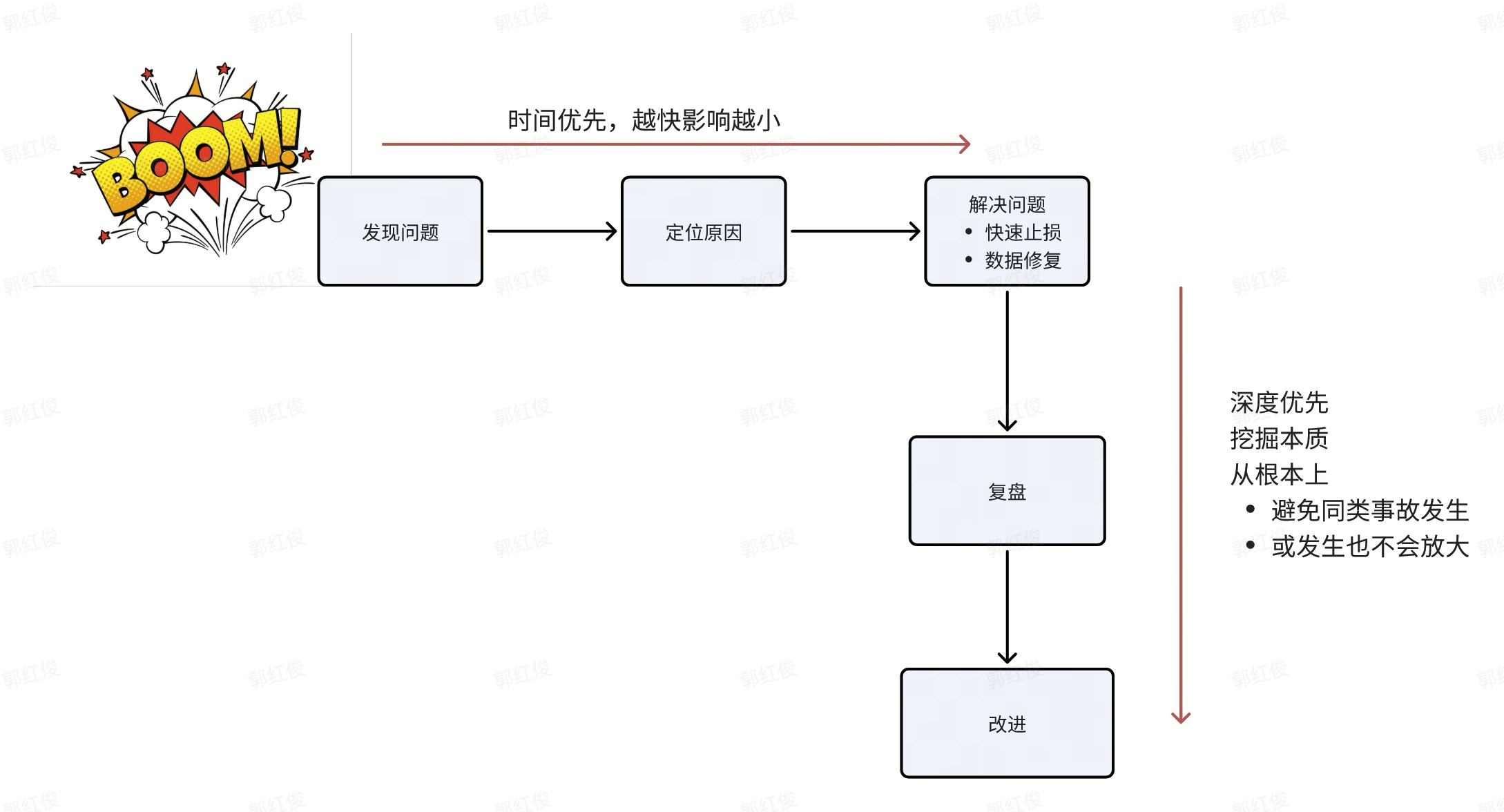
避免大事故:加强快速止损能力建设,快速发现、快速止损预案、演练..,这些能力建设有个先后顺序,一般是先把发现能力补上去,至于发现后的操作,短期可以靠人来顶。
-
根因分析:定时分析最近一段时间本团队发生过的事故,从更高维度上,看研发流程、团队管理等是否有改进点?当然前提条件这些事故是在视野中,这也是P5级别存在的价值。
为什么是这两点:从事故发生的应对流程,以及关注点就可以看出:
要建设的能力,是分级别的:
稳定性保障能力体系

分了四个级别:
- L1:初始级(被动救火)
- L2:已管理级(主动防控)
- L3:已定义级(体系化)
- L4:卓越级(自适应)
图中的带背景,是大多数百人研发团队的现状。
一共分了8个能力维度来看。
1、故障发现
L1 靠用户报障
- 监控覆盖不全
- 业务监控缺失
L2 分钟级主动发现
- 核心指标监控覆盖
- 统一告警平台,但存在噪音
L3 秒级/实时预测
- 基于AI的异常检测
- 智能降噪与关联
L4 业务影响前瞻预判
- 根因预测与规避
- 故障自愈前预警
2、故障定位
L1 靠经验猜测
- 日志、指标、链路孤岛
- 需多人拉会排查
L2 具备基础可观测性
- 核心链路追踪
- 关键指标仪表盘
L3 自动定位根因
- 智能根因分析
- 拓扑自动发现与影响分析
L4 预测性定位
- 潜在风险点主动标识
- 性能瓶颈预测
3、快速止损
L1 手动操作,无预案
- 恢复依赖个人
- “救火”状态
L2 有预案,但未充分演练
- 关键场景有预案文档
- 回滚、隔离等手动执行
L3 经过演练的可靠预案
- 预案平台化、可执行
- 定期演练,恢复时间可控
L4 自动化/智能化自愈
- 预案流程自动化
- 基于AI决策的智能止损
4、复盘改进
L1 流于形式
- 会议聚焦追责
- 改进项无法闭环
L2 避免同类问题
- 无指责复盘文化初步建立
- 有跟踪机制确保改进项落地
L3 制度/规范层面优化
- 复盘产出驱动流程/规范/代码修改
- 经验沉淀为组织资产
L4 系统性风险消除
- 通过架构/流程优化根治一类问题
- 形成正向反馈的学习型组织
5、变更管控
L1 流程松散
- 发布无卡点
- 配置变更“裸奔”
L2 基础流程管控
- 关键操作审批流
- 具备自动化回滚能力
L3 渐进式发布与质量门禁
- 灰度、蓝绿发布
- CI/CD中集成自动化性能/安全测试
L4 数据驱动的精准交付
- 基于错误预算控制发布节奏
- 交付全过程可观测与风险量化
6、架构韧性
L1 脆弱且未知
- 大量单点、强依赖
- 容量黑洞
L2 具备基础容错能力
- 识别并治理核心单点
- 实施超时、重试、熔断策略
L3 主动注入故障验证
- 常态化混沌工程
- 通过故障注入验证预案与架构
L4 天生免疫与自适应
- 系统设计具备容错、自恢复能力
- 架构能根据流量与故障自动调整
7、容量规划
L1 响应式扩容
- 容量问题靠故障触发
- 资源规划凭经验
L2 主动性容量管理
- 通过压测明确系统容量基线
- 建立业务流量预测模型
L3 精细化与弹性
- 全链路压测
- 具备弹性伸缩能力
L4 成本与性能最优
- 容量与成本联动优化
- 自适应弹性伸缩
8、组织文化
L1 英雄主义
- 稳定性是运维的责任
- 恐惧、回避故障
L2 共同责任雏形
- 开发开始参与On-call与复盘
- 初步建立对稳定性的敬畏心
L3 数据驱动的协同
- 推行SLO与错误预算机制
- 稳定性成为各团队共识目标
L4 韧性工程文化
- 稳定性是核心业务特征
- 主动寻求失败以持续学习优化
监控指标
随着业务发展,之前的凭人品和运气的事故管理是解决不了避免大事故发生的,提升主动发现能力,精细化的覆盖必须的监控是势在必行。
从人员角色的视角,我们需要监控下面三类指标
- 产品视角:业务指标大盘走势,这个是事故发生的兜底监控,大盘掉地了,肯定有事故发生。
- 研发视角:接口处理能力、耗时、错误、异常数量,Google的典型4类黄金指标
- SRE视角:机器负载,资源利用率,设备故障
研发需要关注的指标又可以分下面四类,每类都有一些特点:
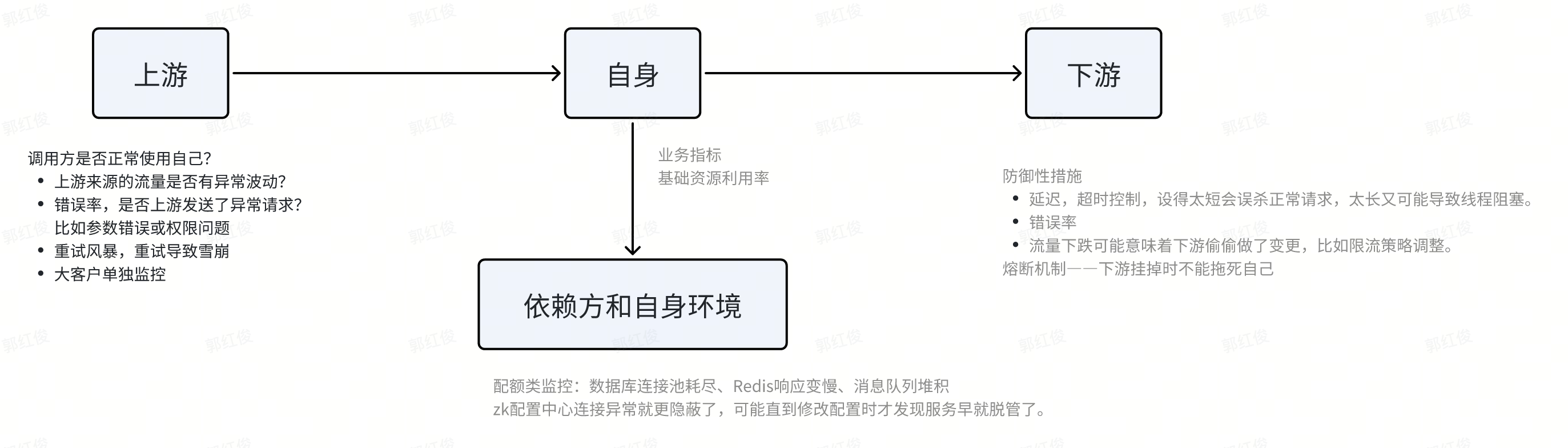
- 错误率、延迟、流量、饱和度(资源利用率)是监控的四大黄金信号,适用于所有层面。
- 指标需要分层查看(全局、集群、服务、实例)和聚合(求和、平均、分位数)。
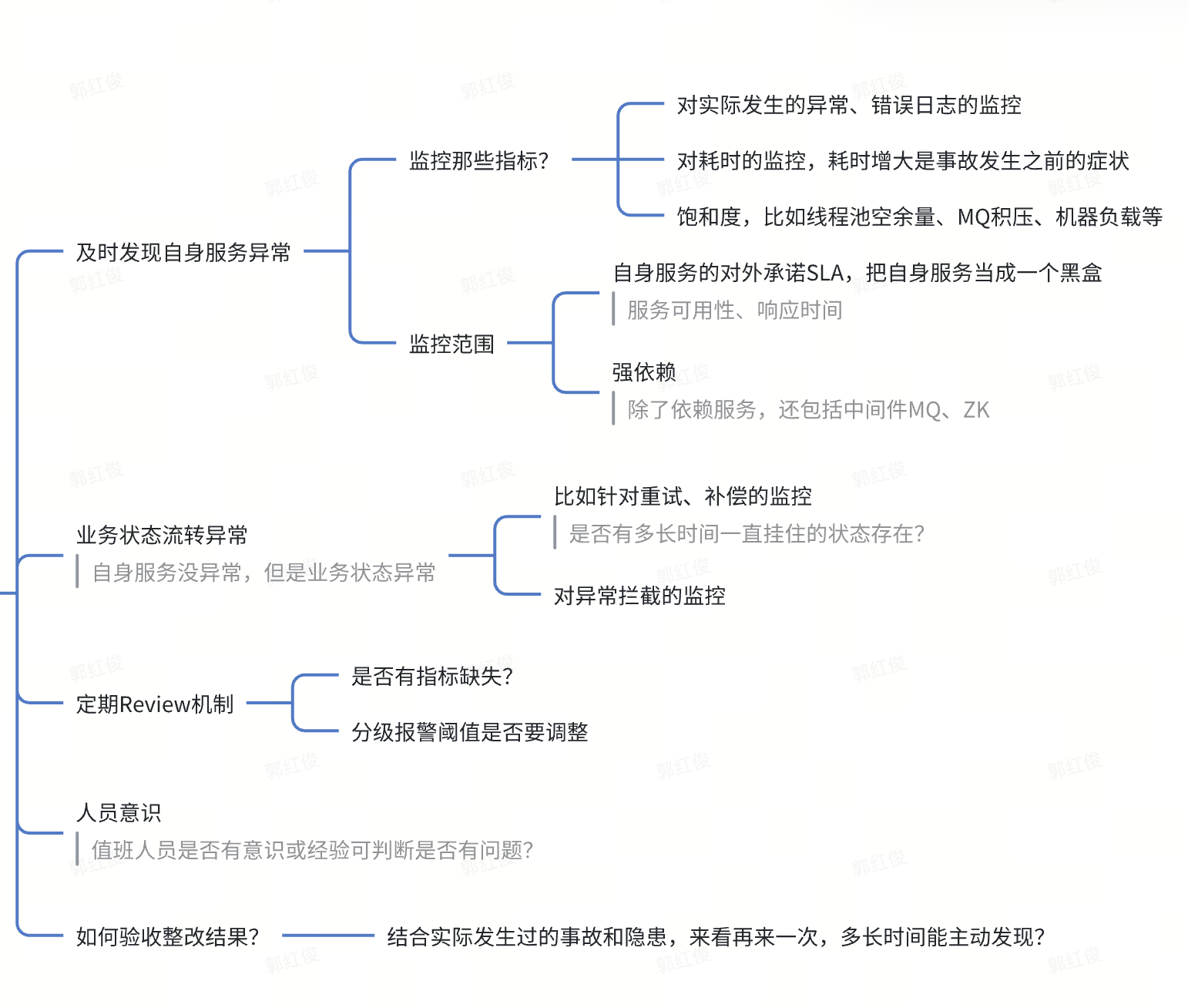
要能做到防大事故的监控体系
需要考虑:
二、稳定性认知标准对齐
稳定性认知要跟大厂对齐,不能因为人少,就降低标准,或者有侥幸心理。
按照海恩法则,每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。侥幸心理的存在,就会在轻微事故阶段,关注不够,继而酝酿出大事故。
所以我们在事故定级中,有个P5,指的业务有实际损失,但达不到P4标准,或业务零损失但值得复盘的事件。
期望鼓励更多的提前发现隐患,防患于未然。
针对所有视野里的事故,都要做深入的根因分析,可以看我之前整理的 5Whys分析法
定级原则:
- 按损失结果定级,事故有多种不同损失结果时,按照定级最高的结果进行认定。
- 综合考虑事故对用户的影响(包括但不限于服务可用性降低,服务内容不正确引起客诉,用户收到直接经济损失等)和公司的损失(包括但不限于业务损失,经济损失和商誉损失)。
- 事故导致上下游业务受影响时,取众多受影响业务的最高事故等级作为最终定级。如果事故影响到所有接入的上下游(非局部),则按照故障服务的损失做为最终定级。
主要是下面几个观点对齐:
1、将“可追回损失”作为定级依据不合理
作为一个 技术事故定级规范,“公司运营损失”只是用来作为“评估此次技术事故的影响大小”的依据。 基于这个原因,运营损失可否追回,在技术事故定级时不应考虑。
特例是:
- 在承诺的SLA时间内,自动兜底重跑修正的,下游没感知的,可以不算损失。
需要人介入的,超过承诺SLA时间的,状态异常变化下游有感知的,这些任何一个满足,都算损失。
Q:打款错误在可追回的情况下,并没有产生损失,是否可以不计入损失?
A:不可以。是否可追回是公司运营侧的工作,站在技术角度看,已经造成了损失。
Q:错误打款是指什么意思?多打了?少打了?还是打错商家了?
A:错误打款是指:因技术原因导致打款关联信息错误,包括金额、账户、周期等?
Q:延迟打款,少打款并没有产生实质上的损失,是否可以不进行定级?
A:这种情况,会因为技术原因导致公司的名誉收到影响,所以仍然需要定级。
Q:如果仅按照回捞之前发生的损失来计算的话,是否会影响遇到事故后回捞的积极性呢?
事故定级是衡量事件严重性的客观标尺,而积极回捞是团队必须履行的基本责任。
-
定级标准的作用是真实反映事故对业务/用户造成的伤害(如数据丢失量、服务不可用时长、直接经济损失),这是改进预防措施的根本依据。
-
回捞积极性是组织执行力与责任心的体现,应通过明确职责、流程保障、正向激励(而非操纵定级)来解决。这个对应的考核指标是:“MTTR(平均恢复时间)”。
Q:异常时,有自动补偿任务在跑,这部分在定级时,算不算损失?
看上下游是否能感知到这个异常?
- 不能感知到,不算损失。
- 能感知到,意味着补偿任务不合理,算损失。
Q:损失统计时,是否只统计超出SLA外的损失?
A:是的,前提是SLA需要事先跟受影响方达成一致。
链路中各服务需要依据被依赖方提供的SLA来建设自身服务的可靠性。
2、涉及到损失金额的,直接按照金额大小定级
涉及损失的事故定级:
| 级别 | 损失金额 |
|---|---|
| P0 | 损失金额>50万元 |
| P1 | 损失金额>10万元 |
| P2 | 损失金额>5万元 |
| P3 | 损失金额>1万元 |
| P4 | 损失金额>1千元 |
| P5 | 损失金额>0或值得复盘的 |
备注:
- 损失金额:指罚款、成本损失、赔付、支付等,这部分损失需要公司付出也是这么多。比如:技术事故导致运营活动成本损失或资金赔付或公司被罚款,支付系统错误导致用户支付失败等等。
- 这部分跟业务大小没关系,直接看损失金额。
3、仅靠业务占比、业务中断时间等指标对不同体量业务不公平
要解决这个问题,会同时看 占比值、绝对值 都满足才会对应定级。这样可以避免小业务定级太高,大业务定级太低的问题。
如下图,就是一个同时考虑的定级标准:
| 级别 | 仅涉及非核心业务用户 | 涉及核心业务的订单或用户 | 错误金额 | 日pv损失 |
|---|---|---|---|---|
| P0 | 影响比例 >20% 且日损失+日错误绝对值 >1W | 影响比例 >10% 且日损失+日错误绝对值 >1W | 金额达到200万元以上,且错误金额占日均金额的10%以上 | 日PV损失>=5%,且绝对值>=100万 |
| P1 | 影响比例 >10% 且日损失+日错误绝对值 >5K | 影响比例 >5% 且日损失+日错误绝对值 >5K | 金额达到100万元以上,且错误金额占日均金额的5%以上 | 日PV损失>=1%,且绝对值>=50万 |
| P2 | 影响比例 >5% 且日损失+日错误绝对值 >2K | 影响比例 >1% 且日损失+日错误绝对值 >2K | 金额达到50万元以上,且错误金额占日均金额的1%以上 | 日PV损失>=0.1%,且绝对值>=5万 |
| P3 | 影响比例 >1% 且日损失+日错误绝对值 >500 | 影响比例 >0.1% 且日损失+日错误绝对值 >500 | 金额达到10万元以上,且错误金额占日均金额的0.1%以上 | 日PV损失>=0.04%,且绝对值>=5千 |
| P4 | 影响比例 >0.1% 且日损失+日错误绝对值 >100 | 影响比例 >0.05% 且日损失+日错误绝对值 >100 | 金额达到5万元以上,且错误金额占日均金额的 0.04%以上 | 日PV损失>=0.01%,且绝对值>=1千 |
| P5 | 值得复盘的 | 值得复盘的 | 金额达到1万元以上,且错误金额占日均金额的 0.01%以上 或值得复盘的 |
值得复盘的 |
说明:
- 日错误订单:指订单成功生成,但订单属性存在错误。比如:存在价格错误,地址错误等
- 日错误用户:指错误触达或受影响的用户数
- 错误金额:并不会让公司损失对应的金额,而是这部分资金用错地方了,实际成本损失并没这么多。授信金额/用信金额这些就是典型。
- 日PV损失:指错误流量,比如:基础中间件不符合SLA承诺的请求数,前端业务错误的被展示PV次数。 统计范围是应用的所有渠道(前端包含所有App, PC版,小程序,鸿蒙端等;基础中间件包含所有来源)
- 影响比率的分母取最近三十天平均,比如:日平均用户,日平均订单数。
- 某些业务由于行业特点,会出现对特定供应商的外部强制强依赖(如:支付业务对应的三方通道)。此种情況下,所强依赖的外部供应商技术故障时,业务侧及时进行降级(通道切换、限流、暂时关闭业务入口等),因此带来的订单或GMV下跌,不计入损失。但由于业务侧无监控,收到监控后无处理动作或处理不当,导致大量客诉,或者错误订单、错误打款等,仍然需要按损失进行定级。
- 故障由于没有及时修复(包括没有及时发现)导致跨天,或者虽然临时修复了但根因未消除,导致第2天仍然存在故障的(必须是严格意义上的同一根因),可以认定为一个事故,其造成的跨天损失累计计算,作为定级比例的分子(也是定级中的绝对值),分母为该业务在故障期间的日订单量均值。
- 事故造成延迟出券等,比承诺SLA时间延迟超过5分钟的,在定级中,可等同订单损失来作为定级参考。
4、内部使用的生产力工具,按照故障时长+重要程度+影响用户比例来判断定级
适用于供内部员工使用的生产力工具,比如ops、跳板机、办公环境、大数据生成数据延迟等场景。
按照故障时长+重要程度+影响用户比例来判断。
| 级别 | 核心 | 非核心 |
|---|---|---|
| P0 | 影响 > 60人日 | 影响 > 200人日 |
| P1 | 影响 > 30人日 | 影响 > 60人日 |
| P2 | 影响 > 15人日 | 影响 > 30人日 |
| P3 | 影响 > 7人日 | 影响 > 15人日 |
| P4 | 影响 > 3人日 | 影响 > 7人日 |
| P5 | 值得复盘的 | 值得复盘的 |
目前公司研发150,总人数500 ,上面表格细化后的部分区间情况。
| 公司>=40%的人受影响 | >= 24小时 | >= 8小时 | >= 4小时 | >=2小时 | >=1小时 | >=30分钟 | >= 6分钟 |
|---|---|---|---|---|---|---|---|
| 核心 | P0 | P0 | P1 | P2 | P3 | P4 | P5 |
| 非核心 | P0 | P1 | P2 | P3 | P4 | P5 | |
| 公司>=20%的人受影响 | >= 24小时 | >= 8小时 | >= 4小时 | >=2小时 | >=1小时 | >=30分钟 | >= 6分钟 |
| 核心 | P0 | P1 | P2 | P3 | P4 | P5 | |
| 非核心 | P1 | P2 | P3 | P4 | P5 |
大数据部分定级
由于影响人数不太好量化,大数据定级按关键服务延误时长来量化,延迟时长是指正常承诺的时间(比如:早9:00)之后的延迟。
| 延迟时间 | 定级 |
|---|---|
| <2小时 | P4 |
| >=2小时 and <6小时 | P3 |
| >=6小时 | P2 |
| 如果大数据数据延迟或数据错误导致影响其他团队的,按照定级最高的结果进行认定(业务影响定级或大数据延迟定级)。 |
其他定级FAQ
Q:基础技术类产品的故障,如何定级?
A: 基础技术产品发生事故,如影响业务,按照影响的业务损失定级即可。
如未影响业务,但影响效能,按照效能定级。
三、巡检、治理能力
可以通过建设巡检治理平台,提升提前发现风险的能力:
- 风险集中管控,避免数据不及时等偏差,减少技术运营的人力投入成本。
- 巡检可以是基于规则的巡检,现在也可以让AI分析代码,发现其中的各种风险。
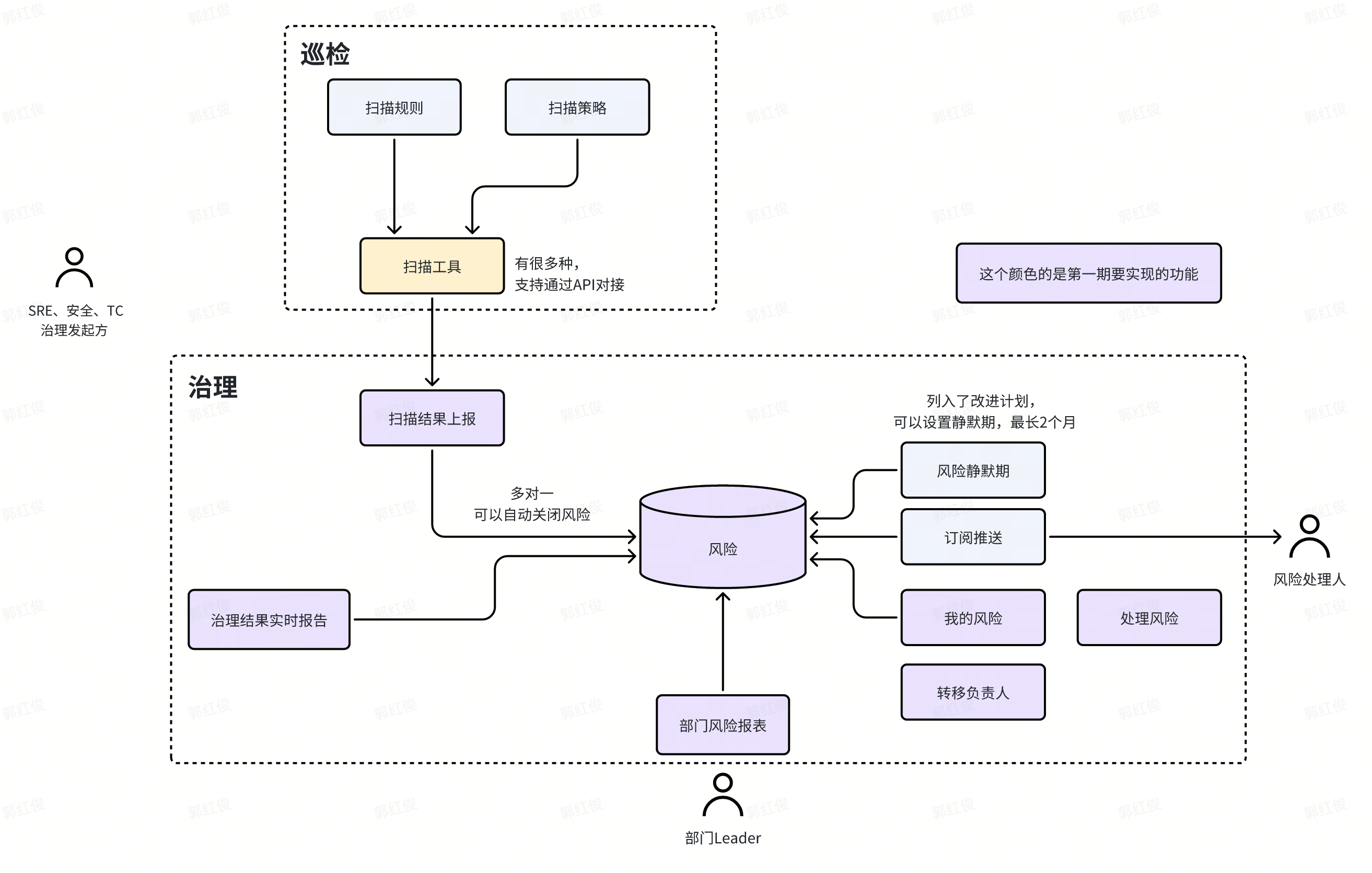
通过上面巡检各种风险,带来的好处如下:
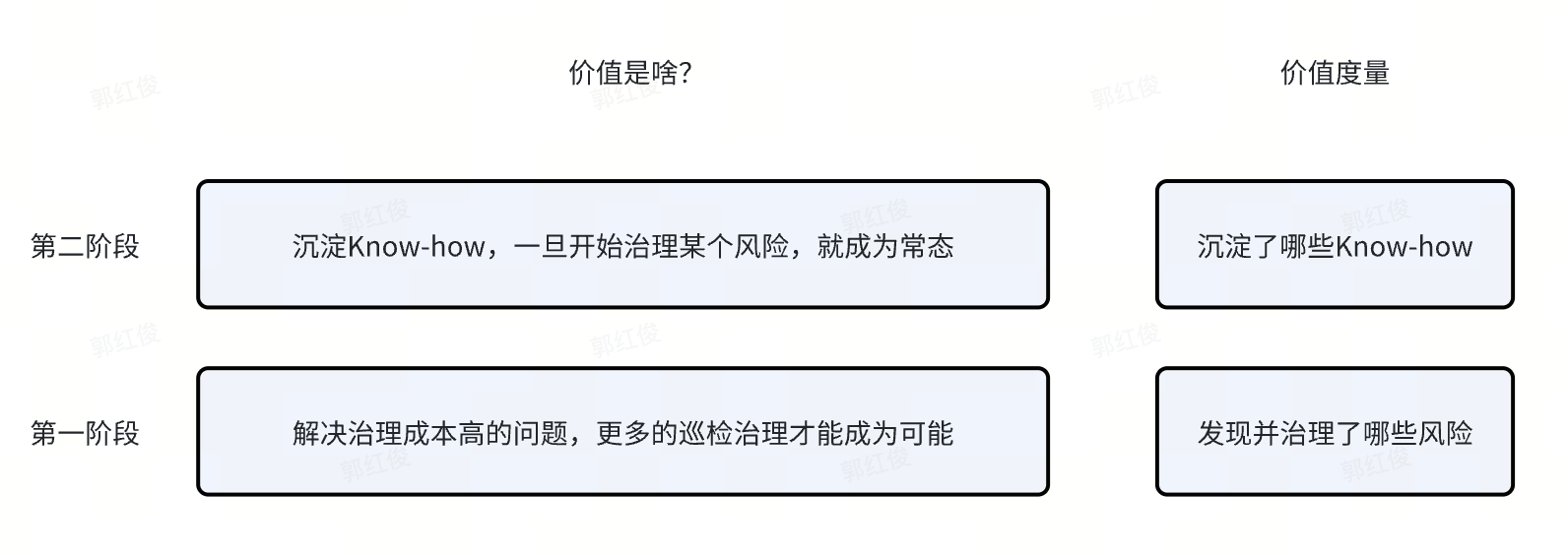
- 解决治理成本高的问题,更多的巡检治理才能成为可能,这阶段的价值度量是:发现并治理了哪些风险。
- 沉淀Know-how,一旦开始治理某个风险,就成为常态,这阶段的价值度量是:沉淀了哪些Know-how。
由于是要沉淀风险Know-how的,对风险的定义要清晰,可以落地。
缺失监控报警的风险定义示例
下面是一个缺失监控报警的风险定义示例
1、基本信息
| 事项 | 详情 | 备注说明 |
|---|---|---|
| 风险名称 | 缺失监控报警 | |
| 风险类型 | ☑TC、☐DB、☐SRE、☐安全 | 简单期间,谁发起治理的,算谁下面 |
| 风险规则提出人 | 挑战为啥要巡检这个风险,找这个人 | |
| 风险规则负责人 | 实际的巡检程序负责人 问这个风险的巡检策略,找这个人 |
|
| 风险描述 | 缺乏监控的服务,当事故发生时,无法主动提前发现,发现时间过久,会导致事故放大。 | 介绍此风险的背景,简要说明风险可能造成的故障现象和影响。 |
2、风险监测逻辑
| 事项 | 详情 | 备注说明 |
|---|---|---|
| 检测方法 | 覆盖范围: - 所有服务 巡检逻辑: - 如何判断是在用服务? 读取ops5数据库应用配置表获取 - 如何判断没有接入argus? 请求prometheus api接口(k8s及cvm两套prom),查询jvm指标中app标签值分组(比如内存指标是接入后才默认上报的) - cat的是如何排除的? 未找到cat提供应用列表相关接口,目前手动将app写进配置里 |
说明风险监测的主要逻辑 |
| 风险粒度 | 服务级别 | 比如数据库的全表扫描风险 可以是下面几个粒度的:集群,DB,表 在做静默时,到底静默到哪个维度的需要考虑 |
| 风险事件内容 | 实际扫描出来的,报的信息 | |
| 代码地址 | 扫描代码的git地址 | |
| 风险等级评估方法 | - L1级服务,高风险 - L2级服务,中风险 - 其他服务,低风险 |
扫出来,如何判断这个风险等级? |
| 风险事件更新时间 | 周期:每7天上报一次 时间:7点上报风险事件 |
|
3、用户治理规则
| 事项 | 详情 | 说明 |
|---|---|---|
| 风险事件负责人说明 | 对应应用的第一个技术负责人 | |
| 是否接受RD配置永久静默? | ☑ 是 ☐ 否 |
|
| RD配置静默时提示信息 | 配置静默代表您已经知悉风险内容并对该风险引发的事故负责,请仔细评估后再操作: 1、缺失报警会导致长时间事故得不到处理,继而放大事故,过去一个季度,P0,P1的事故好几个都是这样导致的。 |
RD在配置静默时提示的警示文案。 示例:配置静默代表您已经知悉风险内容并对该风险引发的事故负责,请仔细评估后再操作 |
4、严重程度
| 事项 | 详情 | 说明 |
|---|---|---|
| 可用性影响 | ||
| 故障恢复时间 | ||
| 严重程度详细说明 | ☑ 灾难性影响,核心业务大面积中断 ☐严重影响,核心业务功能严重降级或部分丧失 ☐中度影响,非核心功能不可用,或核心/非核心功能出现体验下降。 ☐可忽略/无影响 |
描述风险出发后,可能产生最严重的事故影响,单选 |
5、发生概率
| 事项 | 详情 |
|---|---|
| 相关历史事故 | |
| 故障发生预计概率 | 目前每个季度都有几次发现不及时,导致放大事故的情况出现 |
6、风险解决方法
| 分类 | 方法 | 预计耗时(单位小时) | 解决步骤及详细说明 |
|---|---|---|---|
| 调整服务等级 | 5分钟 | 在OPS上调整服务等级 | |
| 推荐 | 接入Argus埋点 | 如果只有一条监控告警,顶多10分钟 | 详细方法看 |
| 使用cat监控埋点 | 不推荐,后续公司监控会统一到Argus,cat这里不再维护,只有不维护的系统,才可以用这个方法 |
7、风险项运营
记录风险定义和运营变更的信息
7.1、开启范围及时间
| 时间 | 范围 | |
|---|---|---|
| 2024-09-18 | 全公司技术团队 | |
7.2、规则的变更记录
| 时间 | 进展 | 说明 |
|---|---|---|
| 2024-11-06 | 完成第一版巡检规则确定 | |
7.3、运营数据
通过上面的模版,我们在治理风险前,就对风险形成清晰的定义,并多方征求意见,把风险定义变成一个可落地,有清晰解决方案的治理方案,这才能真正的形成 Know-How 。
总结
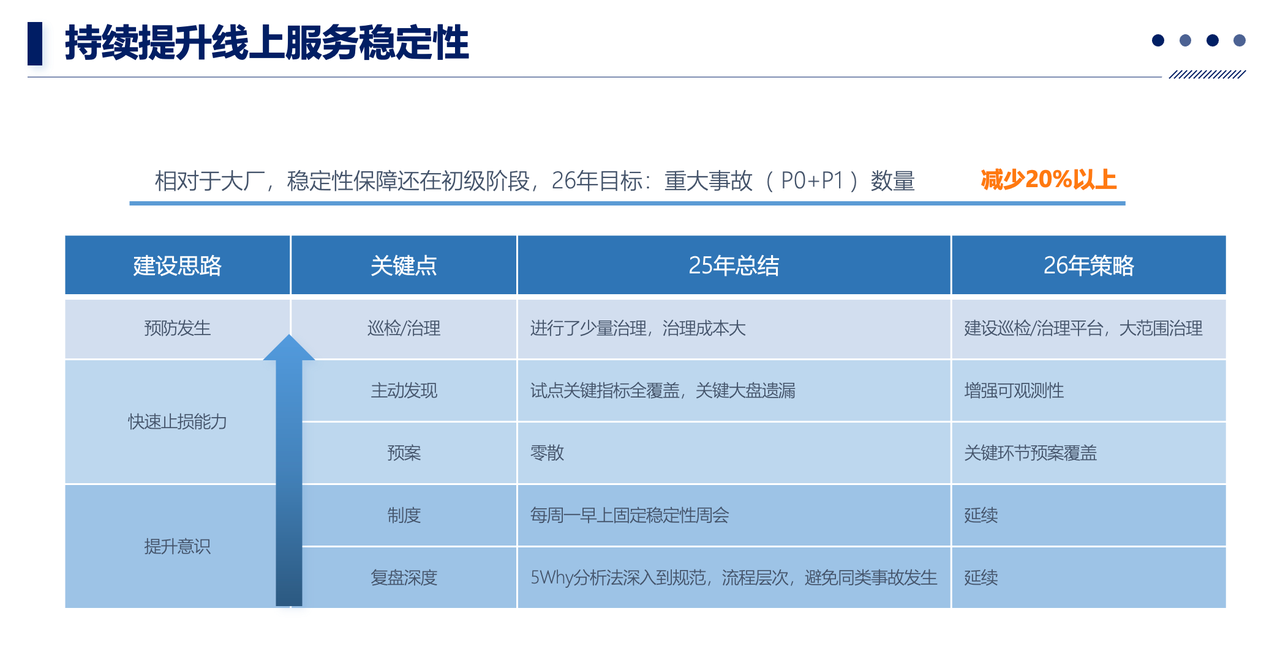
对百人团队来说,更具体要干的事情,就是
- 事故发生前,建设巡检/治理能力,提前发现隐患,并治理
- 事故中,要具备快速止损能力,这个主动发现、预案能力要提前检查,并保障覆盖关键环节
- 事故后,要深度复盘,形成一种持续的工作机制,提升大家的风险意识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号