

文本嵌入模型是将文本数据转化为机器可理解的数值向量的关键技术,这些模型能够捕捉文本的语义信息,使得计算机可以有效地进行文本相似度计算、信息检索、文本分类和聚类等任务。
MTEB 排行榜
问题:从哪里看有哪些嵌入模型,综合排行榜?
Hugging Face 上提供了包含250+个嵌入模型的排行榜 MTEB。
https://hf.co/spaces/mteb/leaderboard
MTEB 是 Massive Text Embedding Benchmark 的缩写,意为“大规模文本嵌入基准测试”。
MTEB 涵盖 7 类任务,包括文本检索、分类、聚类、语义相似度(STS)等,通过多样化的测试场景全面衡量模型的通用性,并根据任务得分进行排序。
MTEB 评测代码:
https://github.com/embeddings-benchmark/mteb
MTEB 是当前最全面的嵌入模型评估基准,尤其适合需要通用性模型的场景,需要注意的是部分模型(如 Linq 的 Linq-Embed-Mistral)针对金融、法律等专业领域优化,可能未在 MTEB 的所有任务中体现优势。
排行榜使用技巧
这个页面默认显示的所有嵌入模型的排名,如果你只想看特定领域排名情况,需要过滤:
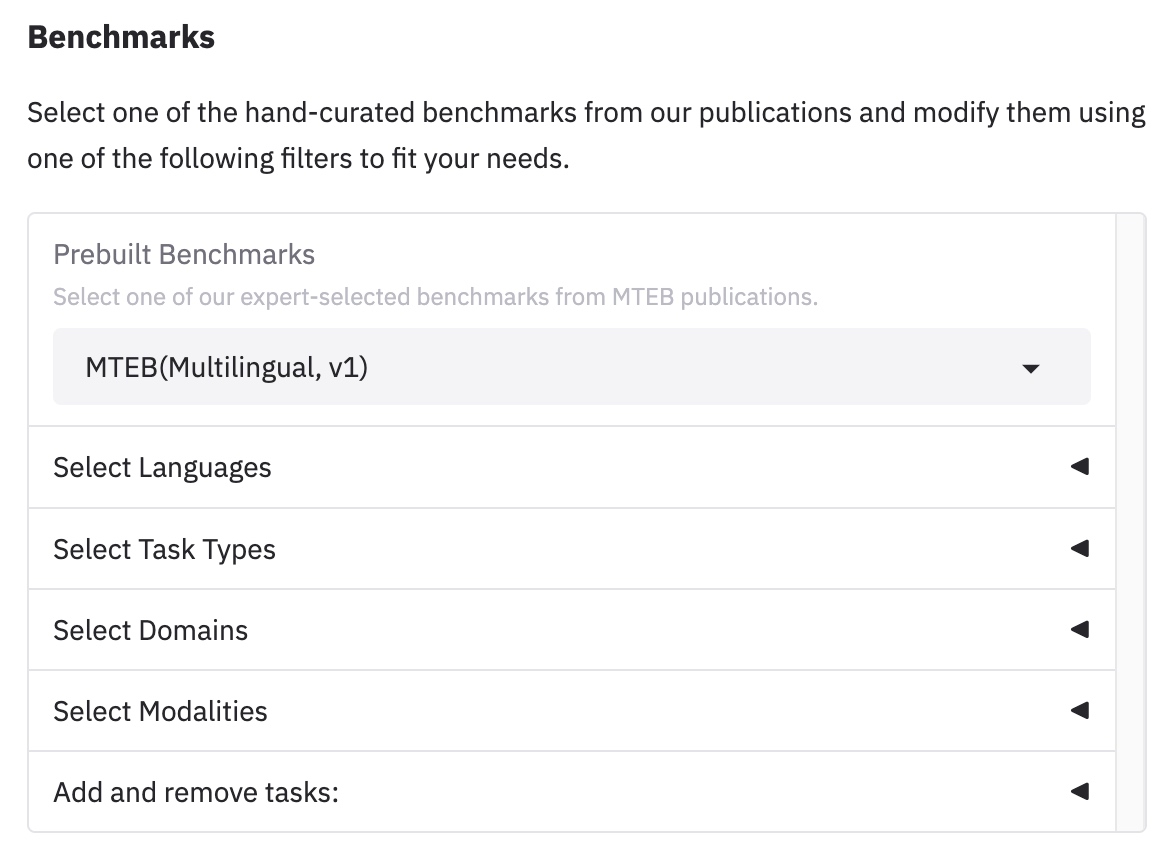
在Prebuilt Benchmarks 这里过滤:
- MTEB(Multilingual, v1) 这是最核心、最全面的多语言基准,覆盖多种语言和多种任务类型(分类、检索、STS 等)。如果你想全面评估模型的多语言通用能力,这是首选。
- 特定单一语言基准测试,中文是cmn、eng 英语、rus 俄语 ...
- 特定领域:Code 编程、Law 法律 ...
- 特定任务:BEIR 侧重信息检索、MIEB 侧重指令遵循 ...
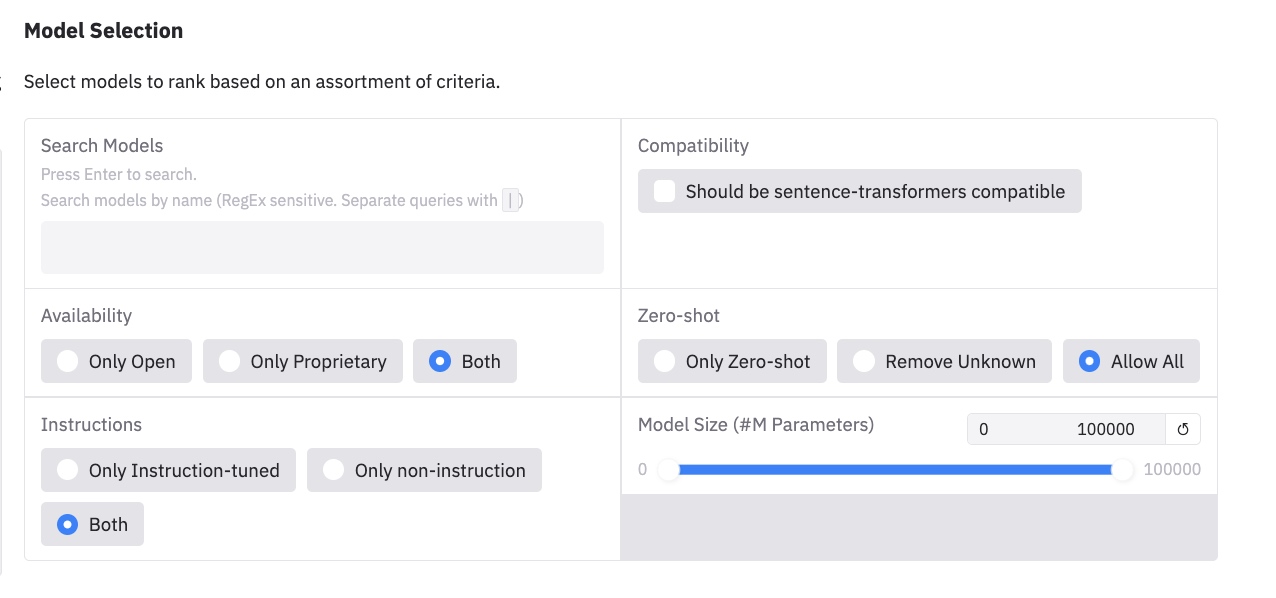
Availability (可用性)
- Only Open (仅开源): 只显示那些代码、权重公开可用,通常具有宽松许可证的开源模型。
- Only Proprietary (仅专有): 只显示那些闭源的、需要付费或通过特定 API 才能使用的商业/专有模型(例如 OpenAI 的模型)。
- Both (两者皆可): 显示所有模型,不论是开源还是专有(默认选项)。
Instructions (指令)
- Only Instruction-tuned (仅指令微调): 只显示那些经过特别训练或微调,能够理解并遵循自然语言指令的模型。这类模型通常在理解用户意图方面表现更好。
- Only non-instruction (仅非指令): 只显示那些没有经过指令微调的标准预训练模型或嵌入模型。
- Both (两者皆可): 显示所有类型的模型,无论是否经过指令微调(默认选项)。
通过组合使用这些筛选器,你可以根据自己的具体需求来缩小模型列表的范围,从而更容易地比较和选择合适的模型。
热门介绍:Gemini-Embedding-exp-03-07
谷歌开发的最新嵌入模型,基于Gemini模型进行训练。
https://developers.googleblog.com/en/gemini-embedding-text-model-now-available-gemini-api/
该模型超越了谷歌之前的文本嵌入模型,并在MTEB多语言排行榜上名列第一。
支持8K tokens的输入长度,并生成3K维度的高质量embedding。
https://ai.google.dev/gemini-api/docs/embeddings?hl=zh-cn
该模型还采用了Matryoshka Representation Learning (MRL)技术,允许用户根据存储成本需求截断embedding维度。
热门介绍:BGE - 智源
智源 BGE(BAAI General Embedding)包括bge-m3、bge-large-zh-v1.5和bge-large-en-v1.5等,由BAAI(北京智源人工智能研究院)开发。
https://huggingface.co/collections/BAAI/bge-66797a74476eb1f085c7446d
https://github.com/FlagOpen/FlagEmbedding
| 模型名 | 维度 | 序列长度 | 介绍 |
|---|---|---|---|
| BAAI/bge-m3 | 1024 | 8192 | 多语言,基于统一的微调(密集、稀疏、ColBERT) |
| BAAI/bge-large-en-v1.5 | 1024 | 512 | 英文模型 |
| BAAI/bge-base-en-v1.5 | 768 | 512 | 英文模型 |
| BAAI/bge-small-en-v1.5 | 384 | 512 | 英文模型 |
我们只看下最新的这个。
BAAI/bge-m3
https://huggingface.co/BAAI/bge-m3
bge-m3基于XLM-RoBERTa架构,通过自知识蒸馏进行训练,使其在多功能性、多语言性和多粒度方面表现出色。该模型能够同时执行稠密检索、多向量检索和稀疏检索三种常见的检索功能,支持超过100种语言,并能处理短句到长达8192个tokens的文档。
ollama 也有支持:
https://ollama.com/library/bge-m3
在 Cherry Studio 中,目前用的最多的是这个模型。
热门介绍:GTE - 阿里Qwen
GTE 模型,也称为 General Text Embeddings,是阿里巴巴达摩院推出的文本 Embedding 技术。
包括 gte-Qwen2-7B-instruct 和 gte-Qwen2-1.5B-instruct。
Alibaba-NLP/gte-Qwen2-7B-instruct
gte-Qwen2-7B-instruct 拥有70亿参数,embedding维度为3584,最大输入长度达到32000个tokens。
https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct
Alibaba-NLP/gte-Qwen2-1.5B-instruct
gte-Qwen2-1.5B-instruct 是7B模型的较小版本,参数量为15亿,embedding维度为1536,同样支持32000个tokens的长输入。
https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct
热门介绍:text-embedding-3系列 - OpenAI
OpenAI的text-embedding-3系列,包括small和large版本,以其强大的性能和易用性而闻名,但属于闭源模型。
https://platform.openai.com/docs/guides/embeddings
嵌入向量的长度:
- text-embedding-3-small 1536
- text-embedding-3-large 3072
热门介绍:nomic-embed-text
这是Ollama平台上排名第一的嵌入模型,很多本地化部署用的都是它。
https://ollama.com/library/nomic-embed-text
使用场景推荐
根据语言需求、任务类型和资源条件,以下是推荐场景和模型选择:
多语言任务
推荐:gemini-embedding-exp-03-07(性能最佳,支持 100+ 语言)、BGE-m3(多语言长文档)。
场景:国际化语义搜索、跨语言 RAG。
资源受限环境
推荐:gte-Qwen2-1.5B-instruct(轻量高效)、nomic-embed-text(本地部署优)。
场景:小型项目、低配服务器。
本地部署
推荐:nomic-embed-text(Ollama 平台最早支持,下载最多)、bge-m3 (智源的,Ollama也支持)。
场景:离线环境、隐私敏感任务。
长文档处理
推荐:BGE-m3(8192 标记)、gemini-embedding-exp-03-07(8K 输入)。
场景:法律文档、学术论文检索。
总结
文本嵌入模型作为连接自然语言与机器理解的桥梁,其选择需要综合考虑任务需求、语言支持、计算资源和部署环境等多方面因素。
MTEB 作为最全面的嵌入模型评估平台,提供了多语言、多任务的标准化评测,是模型选型的重要参考依据。
实际选型时应该考虑:
-
优先考虑模型与业务场景的匹配度,而非单纯追求排行榜名次
-
注意平衡模型性能与计算成本,特别是在大规模应用中
-
对于专业领域(如法律、医疗),需要关注领域适配性
-
隐私敏感场景建议选择可本地部署的开源方案
随着AI技术的快速发展,文本嵌入模型正朝着更智能、更高效的方向演进。建议开发者持续关注模型更新,定期评估现有方案的适用性,同时也要注意实际业务需求与技术能力的匹配,选择最适合的解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号