

大型语言模型支持函数调用核心就是下面三点:
1、函数注册与描述
开发者在API调用时向模型提供函数的名称、参数说明及功能描述(JSON格式)
2、意图识别与参数提取
模型根据用户输入的自然语言,匹配最相关的函数并生成符合要求的参数
3、结构化输出
模型返回函数名称和参数值(JSON格式),由外部系统执行实际调用
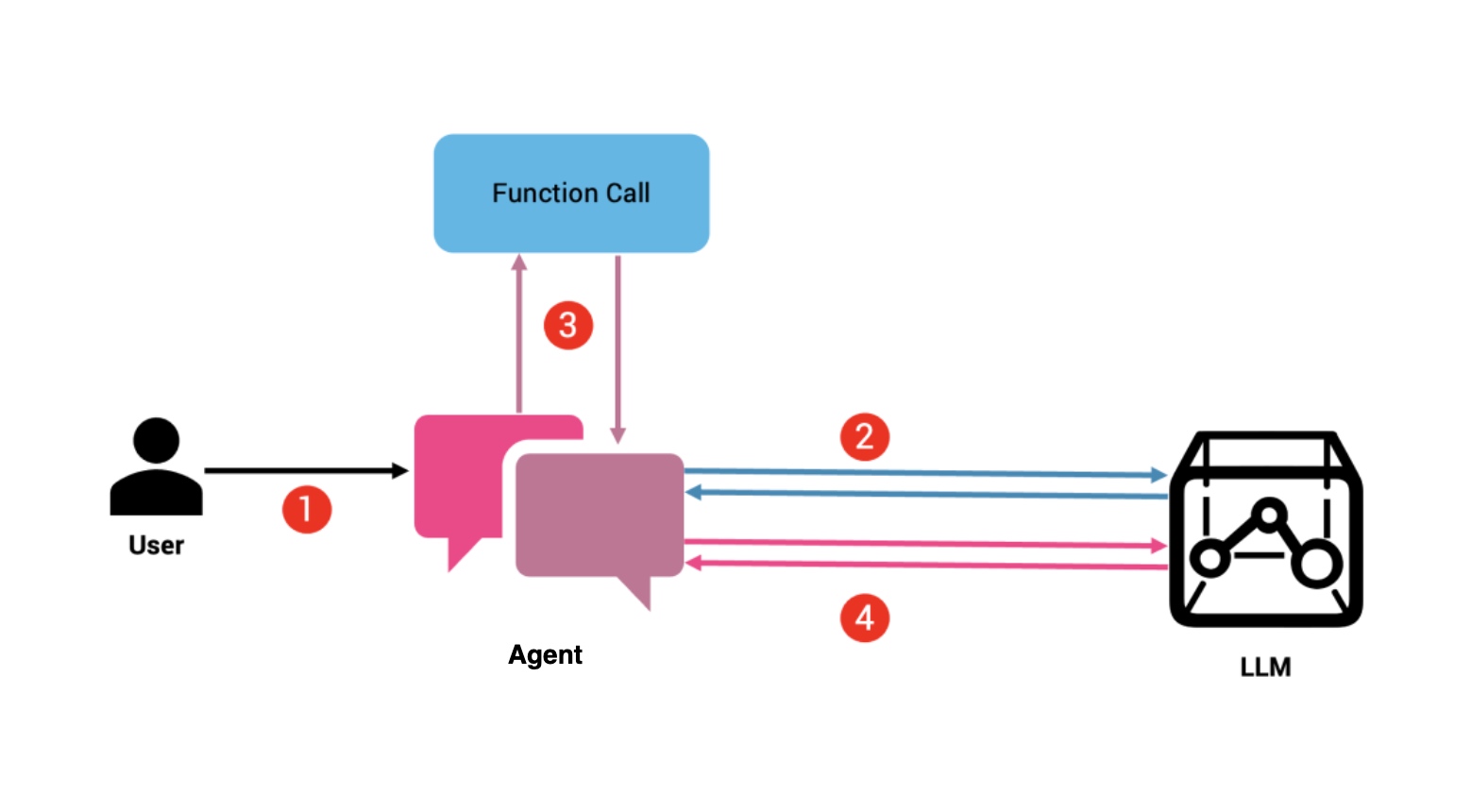
上述三点是一次LLM的调用请求,以问大模型天气预报为例,实际会两次调用LLM(下图步骤2、4),一次调用对应天气API函数(下图步骤3)。
-
用户发送可能需要访问该函数的提示,例如:“北京的当前天气如何?”
-
Agent将提示与所有可用函数一起发送。在我们的示例中,这可能是提示以及函数 get_current_weather(city) 的输入模式。LLM 确定提示是否需要函数调用。如果是,它会查找提供的函数列表及其各自的模式并使用填充有函数集及其输入参数的 JSON 字典进行响应。
-
Agent解析 LLM 响应。如果它包含函数,它将按顺序或并行调用它们。
-
然后将每个函数的输出包含在最终提示中并发送到 LLM。由于模型现在可以访问数据,因此它会根据函数提供的事实数据做出回答。
以目前最火的MCP协议为例,我们实现一个问天气预报的MCP服务和客户端。
服务端
这个API服务是获得北京的天气预报,代码如下:
from mcp.server.fastmcp import FastMCP
import httpx
# Create an MCP server
mcp = FastMCP("WeatherServer")
# Add a tool to fetch weather data
@mcp.tool()
async def fetch_weather(city: str) -> str:
async with httpx.AsyncClient() as client:
response = await client.get(f"https://api.weatherapi.com/v1/current.json?key=YOUR_API_KEY&q={city}")
return response.text
# Add a resource to get Beijing weather
@mcp.resource("weather://beijing")
async def get_beijing_weather() -> str:
return await fetch_weather("Beijing")
if __name__ == "__main__":
mcp.run()
实际用户问北京天气时,这个服务器端会被调用一次。
客户端
我们直接用
https://github.com/modelcontextprotocol/python-sdk/blob/main/examples/clients/simple-chatbot/mcp_simple_chatbot/main.py
这个做客户端,只需要配置下服务器端(servers_config.json)
{
"mcpServers": {
"server1": {
"command": "python",
"args": ["server1.py"]
}
}
}
执行这个程序后,输入我们的问题:北京的天气预报是啥,就会触发相关逻辑执行。
user_input = input("You: ").strip().lower()
if user_input in ["quit", "exit"]:
logging.info("\nExiting...")
break
在这个客户端的代码中,我们可以看到对LLM做了两次调用。
-
第一次调用:初始用户输入被发送到LLM,以获得响应(llm_response) ,
llm_response = self.llm_client.get_response(messages)这一行。 -
第二次调用:如果响应表明应该执行某个工具,则该工具的结果将被发送回 LLM 进行解释 (final_response)。
final_response = self.llm_client.get_response(messages)这一行。

通过这两次调用,完成了用户对北京天气预报的回答。
各种Agent为了简化开发,封装了这个请求过程,实际上还是前面看到的
- 先基于用户输入,问LLM确定要不要用函数,用哪个,参数是啥?
- 然后调用函数,拿到结果后,
- 把结果给LLM,生成最终答案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号