

高性能网络通讯笔记
前几天看了下阿里巴巴 RPC 框架 Dubbo 作者的内部分享,这里记下笔记。
传统rpc的问题
- java序列化,性能低
- 每连接每线程,BIO有性能问题
- jdk代理性能低
数据协议
- 应用层协议
- header字段:
- magic high
- magic low — 端口复用,多协议支持;兼容其他协议。
- 序列化方式
- event
- 是否双向
- 请求还是响应
- status
- id – futureMap保存所有发送的请求,响应中携带请求id,实现一一对应
- 使用int id替换long,实现id轮转+超时(??)
- 剩下来的位数可以用来扩展,存储服务器状态
- 使用future机制把客户端的同步调用转成异步的
- data length
- 序列化协议
- web应用cpu负载低,网络负载高。数据包大小比压缩时间更重要。网络传输的时间远远大于cpu压缩时间,过于追求低压缩时间没有意义。
- 发送前压缩数据包。
- 另一个考虑的因素:工具使用的方便程度、适用场景是否广泛。protobuf用起来麻烦、hession/fastjson有些情况会序列化失败、java serialize最安全和普适。如果这里不是一个明显的瓶颈,可以直接使用java内置的序列化方式。
- 序列化策略
- chunk stream
- 一个连接上承载多个请求发送。如果一个请求过大发送时间过长会造成其他请求不能及时得到处理,容易出现超时。— 将这些大的数据包拆分成多片,穿插发送。server端自己拼装。
IO模型
- Unix的5种IO模型
- IO的两个阶段
- 是否阻塞 – 异步、同步
- Blocking IO、Non-Blocking IO(non-blocking的意义:当需要睡眠当前线程时才能完成请求时,不睡眠,只做部分操作并返回;从内核拷贝数据到用户空间时依然会阻塞)、IO multiplexing(事件驱动,一般和non blocking IO搭配使用)、Signal-Driven IO
- Asynchronous IO
- NIO的优势
- 避免多线程
- 基于block的传输比基于流的传输更高效
- 基于mmap的zero-copy
- TCP的调优
- 正确设置socket缓冲区,接收/发送缓冲区大小应该至少 = Bandwidth Delay Product = 带宽 * 往返时间,这样才能把两端之间的通信链路填满数据,充分利用带宽。
- 减少进程读写缓冲区的系统调用;
- 充分利用带宽
- 关闭nagle算法,RPC 调用不允许延迟
- 在应用层做心跳检测,关闭tcp的keep-alive(这是全局设置)
- 网卡中断负载均衡
- 正确设置socket缓冲区,接收/发送缓冲区大小应该至少 = Bandwidth Delay Product = 带宽 * 往返时间,这样才能把两端之间的通信链路填满数据,充分利用带宽。
线程模型
- MainReactor * 1负责接受连接 + SubReactor * N (thread pool,“IO线程”, 负责监听读写事件. 一个线程负责多个连接)的方式,和Netty一样。
- 业务处理时也引入线程池
-
codec(数据收集/拼装)/serialize(序列化/反序列化)在什么线程里做
- Netty中codec直接在IO线程中做,dubbo也一样;
-
Serialize/deserialize 分开了,在业务线程(池)中做;
原因原文没说,猜测:- serialize是比较耗时的,所有耗时的操作都应该放在业务线程中做,IO线程必须快速返回以便处理下一个连接,否则容易造成后续连接过很久才能得到处理,易超时;
- codec为什么不放在业务线程中做?一是职责分离,业务线程的输入是有意义的完整数据包;二是在数据包不完整时,业务线程基本上会快速退出继续阻塞,这会导致业务线程池的不稳定和频繁的线程切换。
任务的合理切分。
在NIO的客户端,接受数据的事件将会写得很轻量级,但是接受到数据然后分析数据还原成业务对象,之后则会通过线程池的方式来分别处理。就好比监听连接到来,和实际的去建立连接分成了两个阶段的任务,让事件型的任务单纯,快速执行,让与业务相关的部分通过多线程并行的方式提高处理效率。总的来说就是把任务划分成为 系统性的任务 和 业务性的任务,前者消耗时间少,设计尽量简单高效,采用单线程处理即可,后者通常情况下在处理流程和资源上不冲突的情况可以通过多线程并行提高效率。(后者IO bound时多线程可以提高效率[依赖],CPU bound时均分计算资源,要慢一起慢,不会出现一个任务耗时导致别的任务超时,此时处理总时间由于线程切换的开销反而会更大)
— 放翁 《优化杂谈》
- 多线程的目的: 1. 阻塞时可以利用CPU; 2. 均分计算资源, 让多个任务都得以推进
-
业务线程池应该多大?
这一部分来自淘宝的《前台系统性能调优》- 根据业务的CPU/IO类型不同,充分利用IO阻塞与CPU执行的overlapping(交错执行)
- 公式 — 从CPU角度:
- 鸵鸟策略:设置多线程数,保证能充分利用CPU;线程切换开销假装没有,的确是瓶颈时再调。
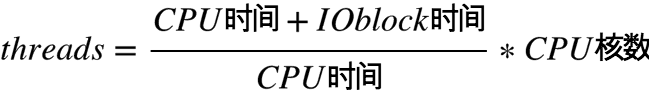
参考资料:
植物大战僵尸破解版: http://www.pvzbaike.com/archives/pvz_pojie/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号