【Hadoop】:HDFS的读写操作
一.HDFS的写(上传)操作
所谓的写操作,那么就是将client的文件(可能是本地)写入到HDFS当中。
写操作的流程如图所示: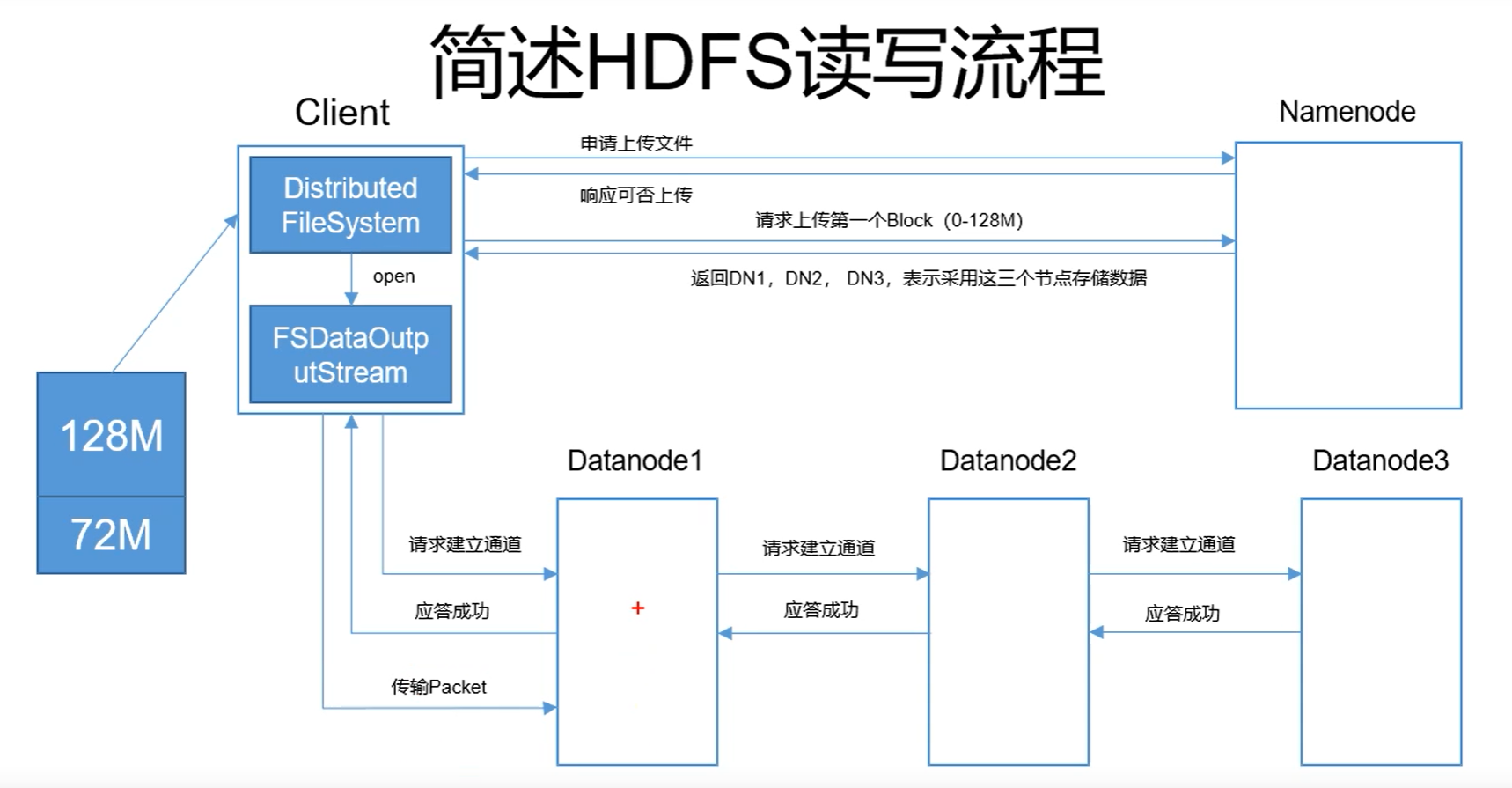
过程概述:
1.我们有一个大小为200mb的文件,在逻辑上将其分为两个block,并不是在实际当中进行分割(这里不知道为什么分为了128mb和72mb两个block,因为HDFS当中最小的block大小为64mb,这个72mb不知是怎么来的,准确来说Hadoop2.7.3开始默认block为128 M,Hadoop2.7.3以下默认为64 M)
2.client向NameNode申请上传文件
3.NameNode返回是否能够进行上传
4.请求上传第一个block(前面只是申请是否能够上传文件,这里是申请上传第一个文件)
5.返回给client,DN1,DN2,DN3,这三个datenode的列表用于上传数据,这样client才知道往哪里上传数据。(看我们配置的datanode有多少个,就返回多少个datanode)
备注:返回的datanode顺序是DN1是距离client最近的datanode,然后DN2/DN3根据DN1进行分配
6.client处开启FSDataOutputStream,根据顺序依次对DN1,DN2,DN3建立通道
备注:如果在建立通道的时候失败,则会抛出异常,然后程序终止
7.如果都建立通道成功,那么所有DataNode将会返回应答成功的信息
8.client开始上传第一个block(128mb)的packet到datanode,packet也是HDFS当中数据的第一个单位
备注:HDFS当中block、packet、chunk都是HDFS中涉及到的数据存储单位。
9.开始下一个block的写入(也就是上传)
第二个block(72mb)进行写入的流程图如下所示: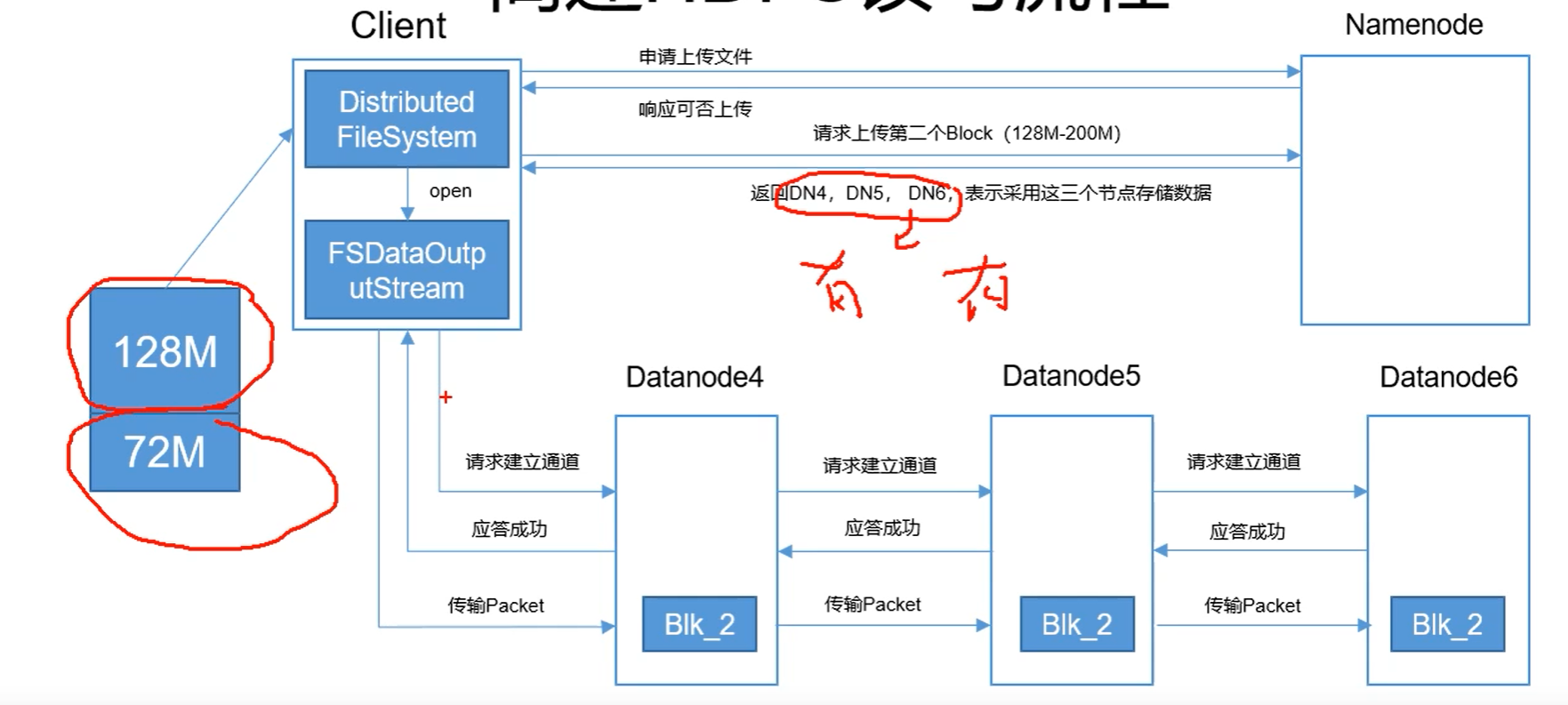
第二个block上传的步骤大致和第一个block相同,唯一不同的点在于:
10.在返回DN4,DN5,DN5的时候,DN4可能是DN1,DN5也有可能是DN3。这个时候会将datanode进行重新分配
二.HDFS的读(下载)操作
HDFS的读操作总体而言和写操作类似,一共可以用三张图片表示,如下所示:
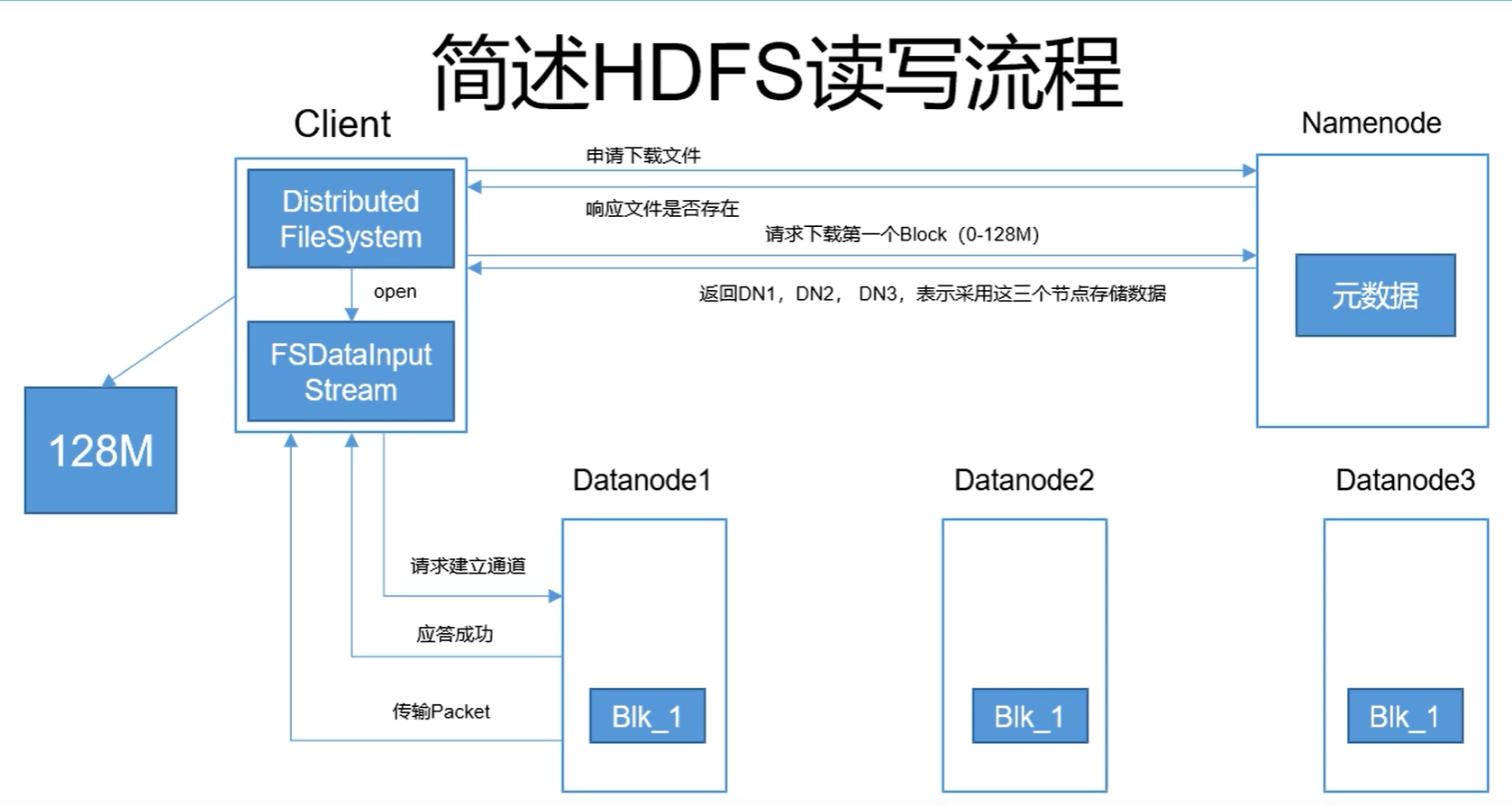
现在DN1,DN2,DN3上面的保留有block1的数据已经全部下载完毕。在下载的过程当中,client在请求建立通道之后,只会下载其中一个datanode的block当中的数据。如果DN1下载失败,才会继续下载DN2或者DN3当中的数据,后面两个DataNode将会作为备胎使用。
下面是第二个block下载的内容:
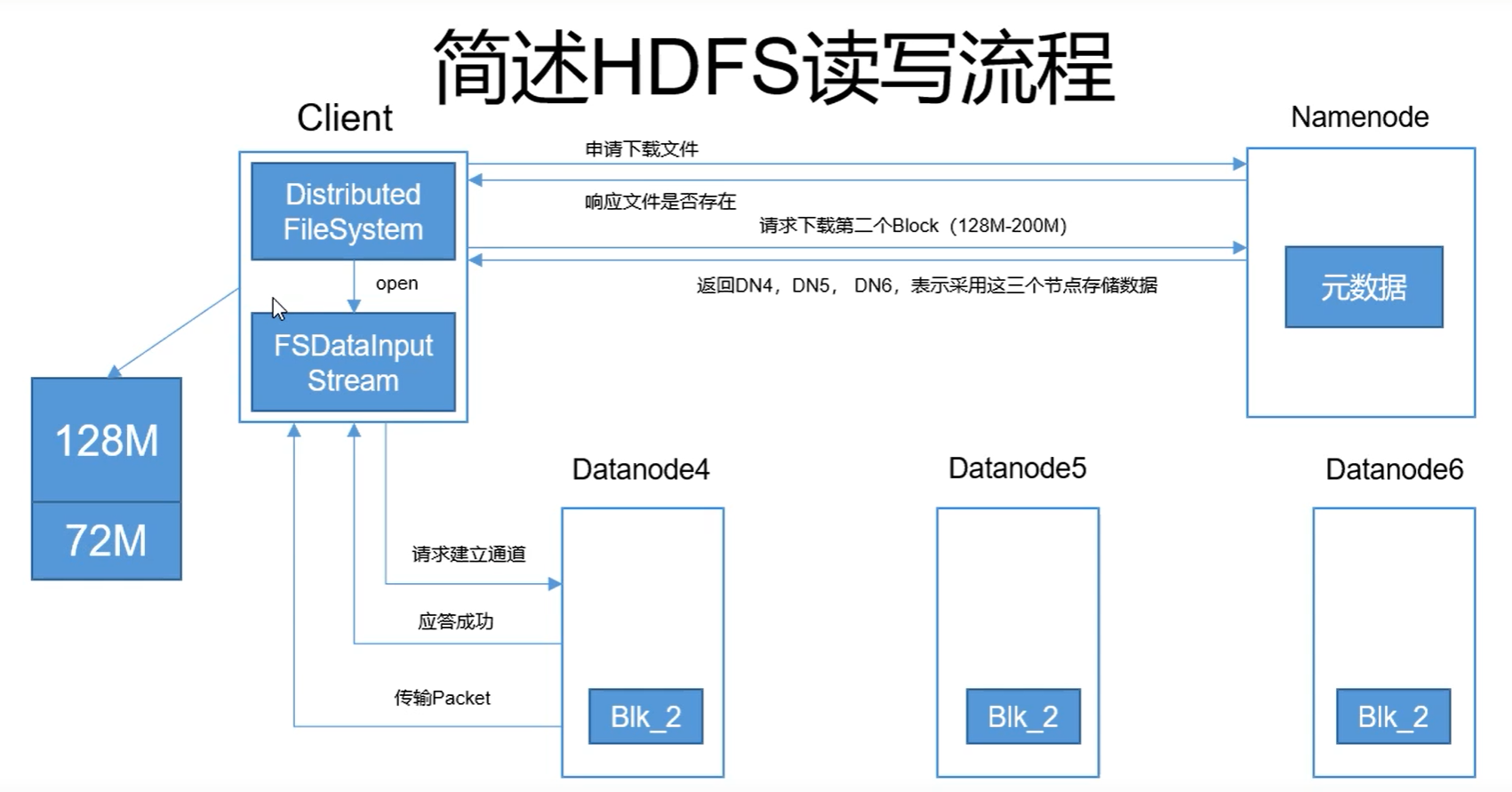
三.网络拓扑—DataNode节点距离计算
我们先来看看一个简单的网络拓扑图:
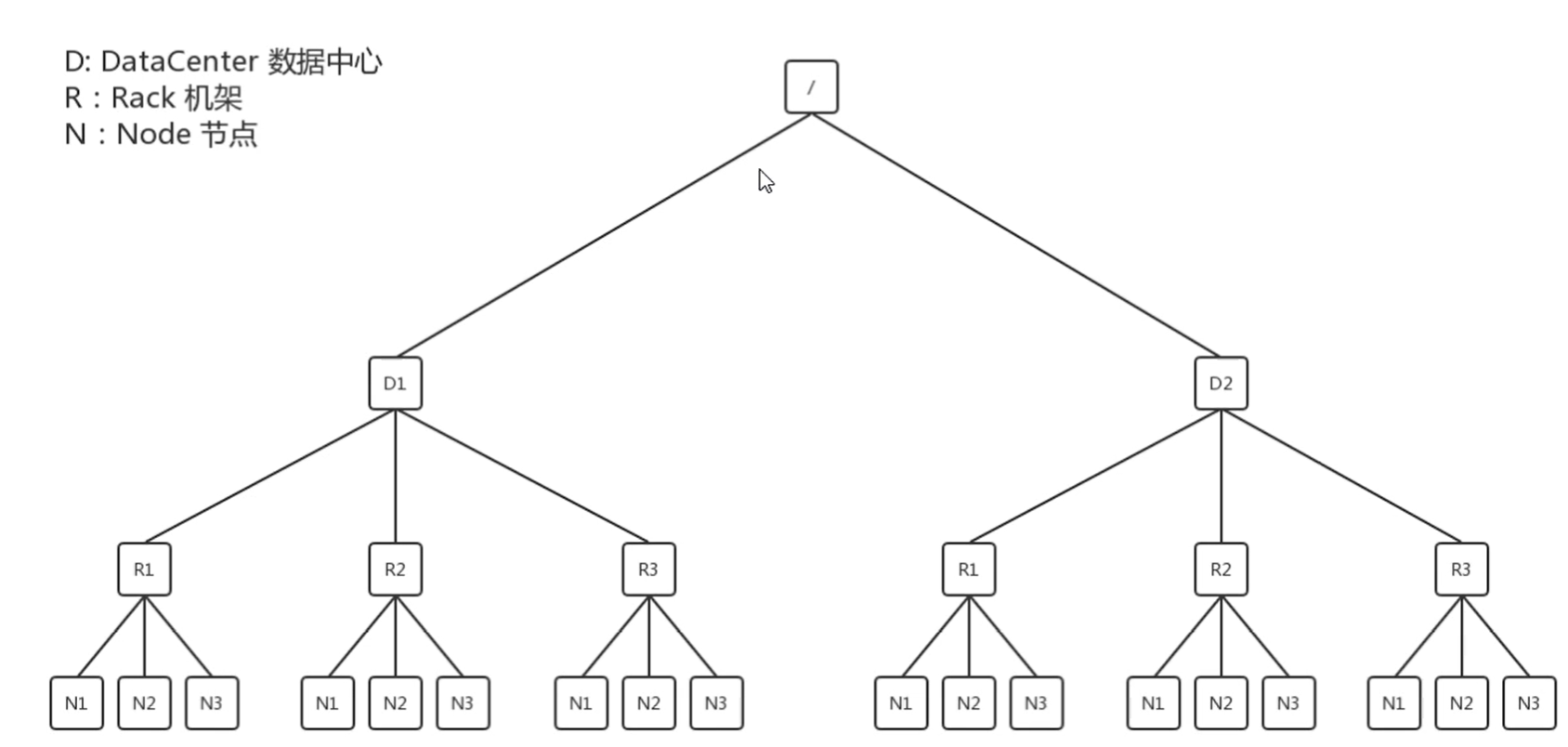
其中D表示:data center数据中心
R表示:机架
N表示:节点Node
其中我们需要上传和下载的数据就在其中的某一个Node当中。假设我们设定副本数量3,那么将会从3个不同的node当中下载或者上传数据。
节点中的距离则为两个节点之间互相相隔了几条线,则为距离,如下图所示
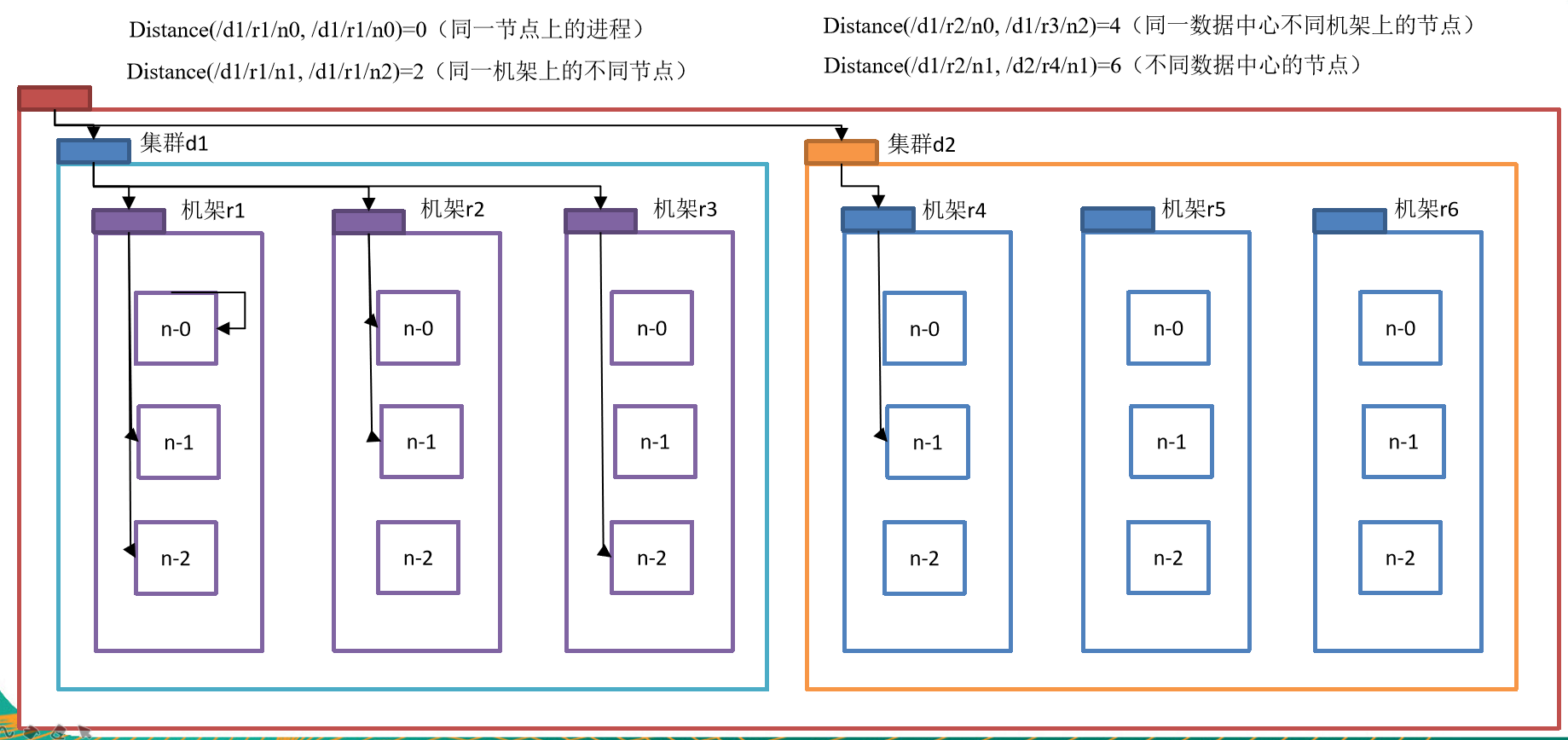
同时,在官方文档中有这么一 句话:
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a different node in the local rack, and the last on a different node in a different rack.
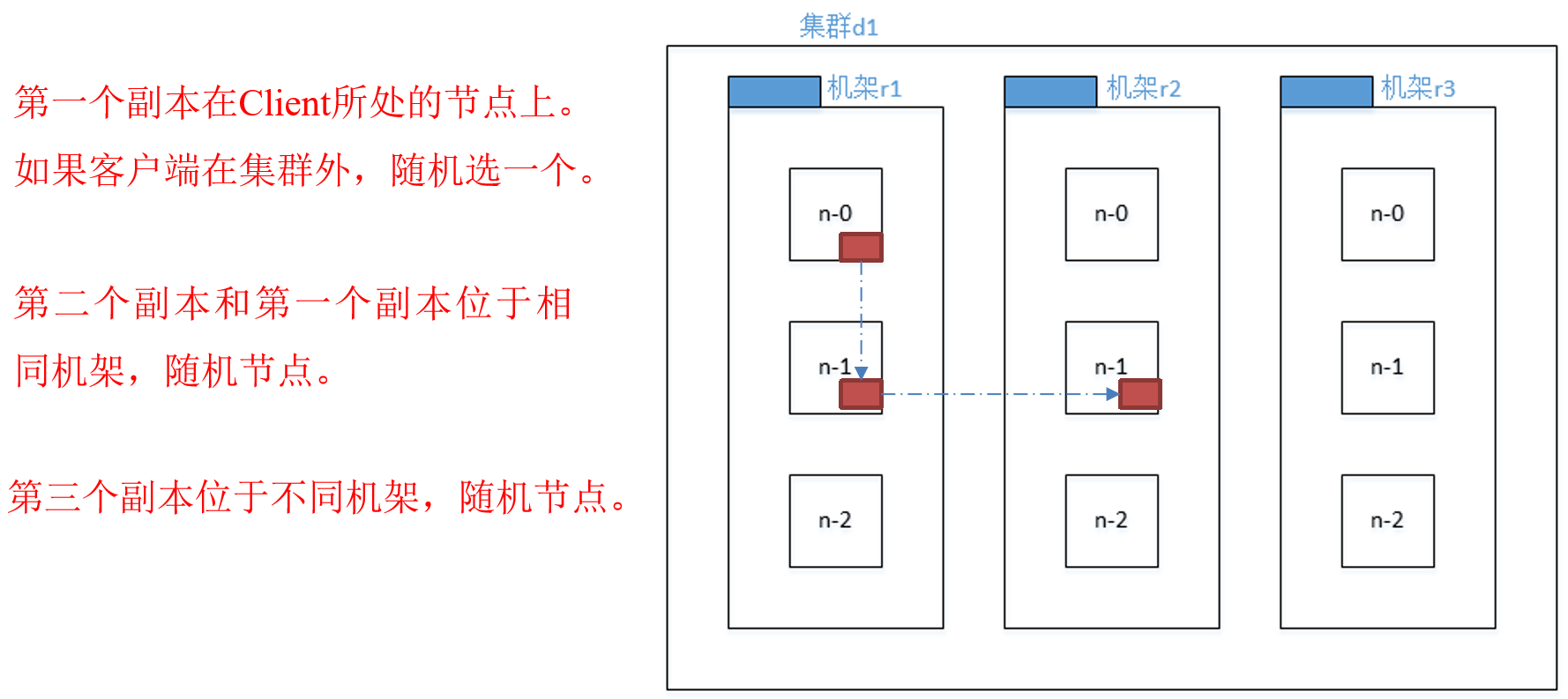
意思就是说如果有三个副本数量时(有多少个副本数量我们可以自己进行调整),就会按照上述英文所属将副本的分布进行相应的调整。如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号