计算多个文档之间的文本相似程度
首先我们上代码:
from sklearn.feature_extraction.text import CountVectorizer corpus = [ 'UNC played Duke in basketball', 'Duke lost the basketball game', 'I ate a sandwich' ] vectorizer = CountVectorizer(binary=True,stop_words='english')#设置停用词为英语,这样就会过滤掉 #过滤掉a an the 等不必要的冠词,同时设定英语里的同种词的形式,单复数,过去式等为同样的词语 print(vectorizer.fit_transform(corpus).todense()) print(vectorizer.vocabulary_)
输出:
[[0 1 1 0 0 1 0 1]
[0 1 1 1 1 0 0 0]
[1 0 0 0 0 0 1 0]]
{'unc': 7, 'played': 5, 'duke': 2, 'basketball': 1, 'lost': 4, 'game': 3, 'ate': 0, 'sandwich': 6}
前面三行的矩阵只有0和1两个值,每一个矩阵都有8个0或者1,这里说明了我们的词库当中一共有8个不同的英语词汇,由于之前我们使用了代码:
vectorizer = CountVectorizer(binary=True,stop_words='english')#设置停用词为英语,这样就会过滤掉 #过滤掉a an the 等不必要的冠词,同时设定英语里的同种词的形式,单复数,过去式等为同样的词语
因此我们已经过滤掉了a an the 这种英语里的冠词,每一个名次的单复数,动词的过去,过去完成时等词,比如说我们的play和played计算机就会默认为是同一个词了,真的神奇。
后面的输出0和1表示了所有词库当中的某一个词是否出现,我们所有的词汇的所对应的数值已经计算出:
{'unc': 7, 'played': 5, 'duke': 2, 'basketball': 1, 'lost': 4, 'game': 3, 'ate': 0, 'sandwich': 6}
在每一句话当中,出现就记为1,不出现则记为0,这就是上述矩阵的含义了。最后我们通过sklearn库当中的函数来计算这三个句子特征向量的欧式距离,其实就是把我们的矩阵拿来计算,计算的公式如下: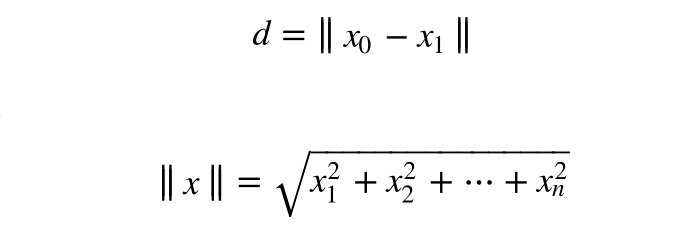
代码如下:
from sklearn.metrics.pairwise import euclidean_distances
counts = vectorizer.fit_transform(corpus).todense()
for x,y in [[0,1],[0,2],[1,2]]:
dist = euclidean_distances(counts[x],counts[y])
print('文档{}与文档{}的距离{}'.format(x,y,dist))
因此我们有输出:
文档0与文档1的距离[[2.]] 文档0与文档2的距离[[2.44948974]] 文档1与文档2的距离[[2.44948974]]
说明文档2和文档1、0的相似程度是一样的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号