

python数据挖掘第二周作业
一、描述性统计分析
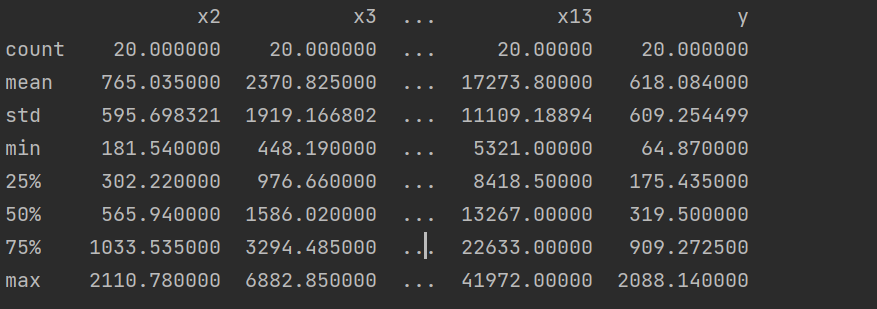
#导入数据处理模块 import pandas as pd import numpy as np #导入绘图模块 import matplotlib.pyplot as plt # 导入绘图模块 import matplotlib.pyplot as plt import numpy as np import pandas as pd df = pd.read_csv(r"D:\python_data\data_caizhengshouru.csv",encoding='gbk',index_col=0).reset_index(drop=True) print(df.describe())
运行结果:
二、相关性热力图
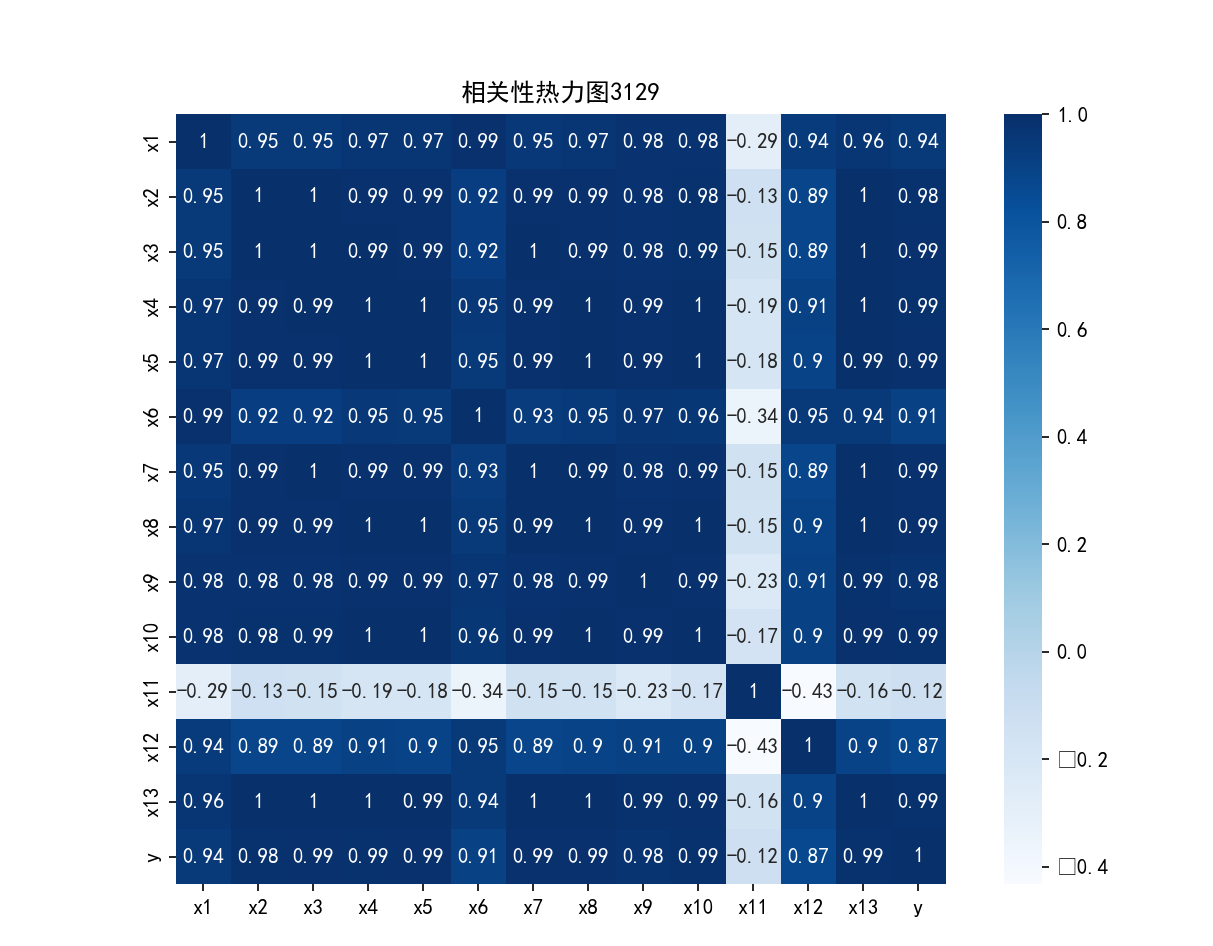
#相关性热力图 corr2=np.corrcoef(df.T) import seaborn as sns plt.subplots(figsize=(10,10)) sns.heatmap(corr2,annot=True,vmax=1,square=True,cmap="Blues") plt.show() plt.close()
运行结果:
三、读取相关系数数据
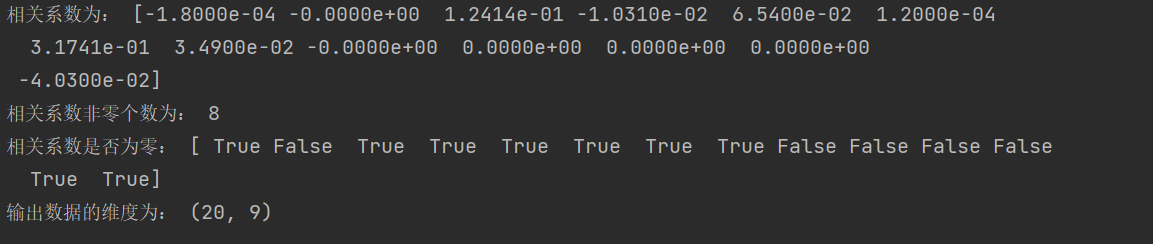
import numpy as np import pandas as pd from sklearn.linear_model import Lasso inputfile = "D:\python_data\data_caizhengshouru.csv" data = pd.read_csv(inputfile) #读取数据 lasso = Lasso(1000) #调用Lasso()函数,设置λ的值为1000 lasso.fit(data.iloc[:,0:13],data['y']) print('相关系数为:',np.round(lasso.coef_,5)) #输出结果,保留五位小数 print('相关系数非零个数为:',np.sum(lasso.coef_ !=0)) #计算相关系数非零的个数 mask = lasso.coef_ !=0 #返回一个相关系数是否为零的布尔数组 mask = np.append(mask,True) #将mask的元素补齐到14个 print('相关系数是否为零:',mask) outputfile = "D:\python_data\_new_reg_data.csv" #输出的数据文件 new_reg_data = data.iloc[:,mask] #返回相关系数非零的数据 new_reg_data.to_csv(outputfile) #存储数据 print('输出数据的维度为:',new_reg_data.shape) #查出输出数据的维度
运行结果:
四、GM11灰色预测
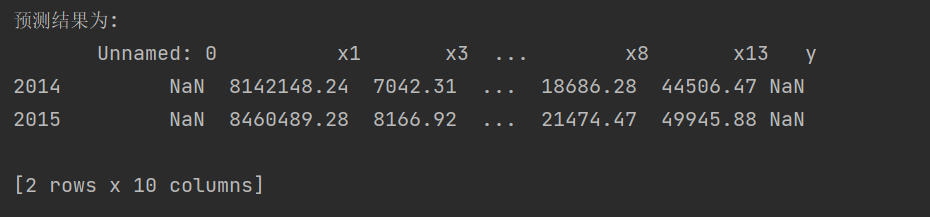
import sys sys.path.append("D:/python_data/GM11.py") import numpy as np import pandas as pd from GM11 import GM11 #引入自编的灰色预测函数 inputfile1 = "D:\python_data\_new_reg_data.csv" inputfile2 = "D:\python_data\data_caizhengshouru.csv" new_reg_data = pd.read_csv(inputfile1) #读取经过属性选择后的数据 data = pd.read_csv(inputfile2) #读取总的数据 new_reg_data.index = range(1994,2014) new_reg_data.loc[2014] = None new_reg_data.loc[2015] = None cols = ['x1','x3','x4','x5','x6','x7','x8','x13'] for i in cols: f = GM11(new_reg_data.loc[range(1994, 2014),i].values)[0] new_reg_data.loc[2014,i] = f(len(new_reg_data)-1) #2014年预测结果 new_reg_data.loc[2015,i] = f(len(new_reg_data)) #2015年预测结果 new_reg_data[i] = new_reg_data[i].round(2) #保留两位小数 outputfile = ("D:\python_data\_new_reg_data_GM11.xls") #灰色预测后保存的路径 y = list(data['y'].values) #提取财政收入列,合并至新数据框中 y.extend([np.nan,np.nan]) new_reg_data['y'] = y new_reg_data.to_excel(outputfile) #结果输出 print('预测结果为:\n',new_reg_data.loc[2014:2015,:]) #预测展示
运行结果:
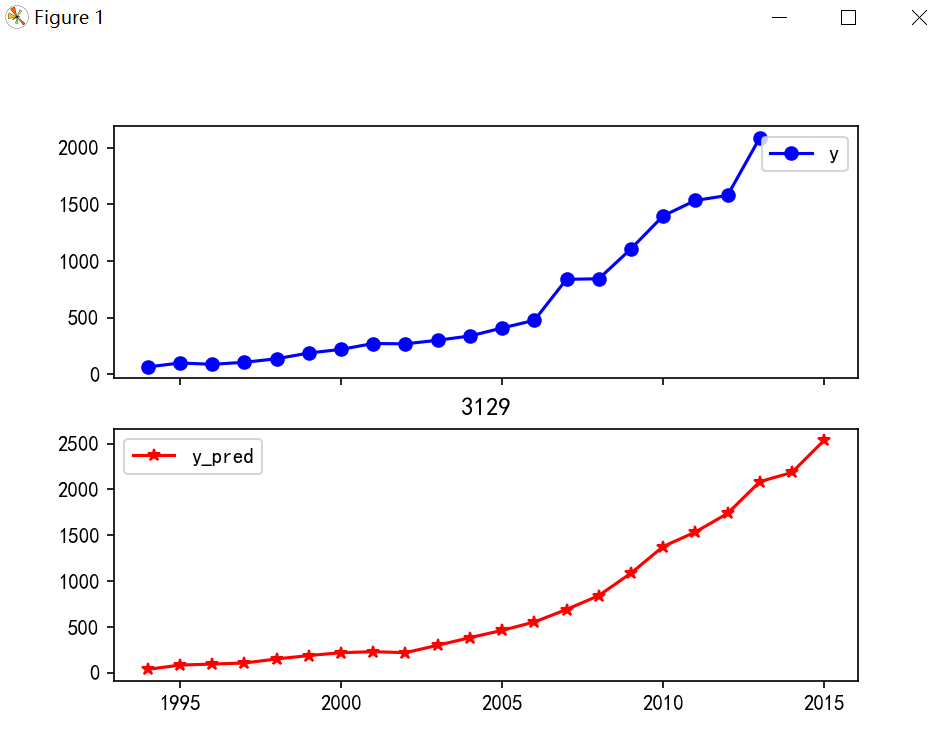
五、读取真实值与预测值并绘图
inputfile = "D:\python_data\_new_reg_data_GM11.xls" # 灰色预测后保存的路径 data = pd.read_excel(inputfile) # 读取数据 feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] # 属性所在列 data.index = range(1994, 2016) data_train = data.loc[range(1994, 2014)].copy() # 取2014年前的数据建模 data_mean = data_train.mean() data_std = data_train.std() data_train = (data_train - data_mean)/data_std # 数据标准化 x_train = data_train[feature].to_numpy() # 属性数据 y_train = data_train['y'].to_numpy() # 标签数据 linearsvr = LinearSVR() # 调用LinearSVR()函数 linearsvr.fit(x_train,y_train) x = ((data[feature] - data_mean[feature])/data_std[feature]).to_numpy() # 预测,并还原结果。 data['y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y'] outputfile ="D:\python_data\_new_reg_data_GM11_revenue.xls" # SVR预测后保存的结果 data.to_excel(outputfile) print('真实值与预测值分别为:\n',data[['y','y_pred']]) fig = data[['y','y_pred']].plot(subplots = True, style=['b-o','r-*']) # 画出预测结果图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加这条可以让图形显示中文 plt.title('3129') plt.show()
运行结果:
真实值与预测值分别为:
y y_pred
1994 64.87 38.358913
1995 99.75 84.956733
1996 88.11 95.916787
1997 106.07 107.421261
1998 137.32 151.802166
1999 188.14 188.766988
2000 219.91 220.039171
2001 271.91 230.888608
2002 269.10 220.073604
2003 300.55 300.779653
2004 338.45 383.573030
2005 408.86 463.047347
2006 476.72 554.507819
2007 838.99 690.745900
2008 843.14 842.297875
2009 1107.67 1086.386807
2010 1399.16 1377.409929
2011 1535.14 1535.140000
2012 1579.68 1737.773468
2013 2088.14 2083.957258
2014 NaN 2185.221330
2015 NaN 2535.841355
六、时间序列预测
#ARIMA时间序列预测 import pandas as pd import numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm from pylab import mpl # 画图中文 mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] = False data_df = pd.read_csv("D:\python_data\_new_reg_data.csv") #data_df.columns = ["时间", "电量"] print(data_df.head())
print(data_df["y"].plot())
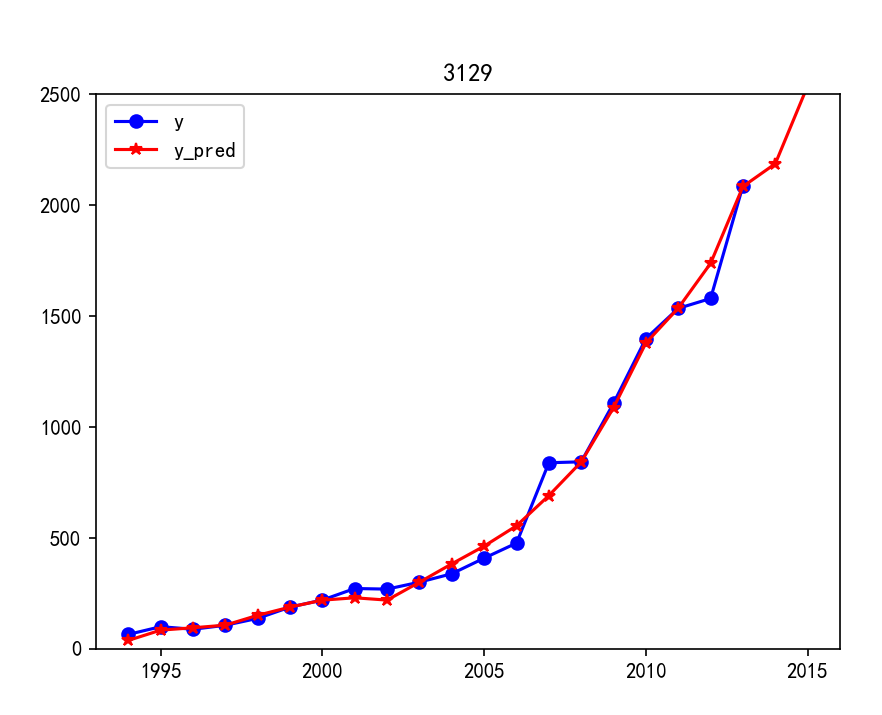
七、预测值与真实值重合图
#真实值与预测值重合图 import matplotlib.pyplot as plt p = data[['y', 'y_pred']].plot(style=['b-o', 'r-*']) p.set_ylim(0, 2500) p.set_xlim(1993, 2016) plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加这条可以让图形显示中文 plt.title('3129') plt.show()
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号