人人能看懂的智能拼音输入法·C++源码200来行·带文本文件格式的数据
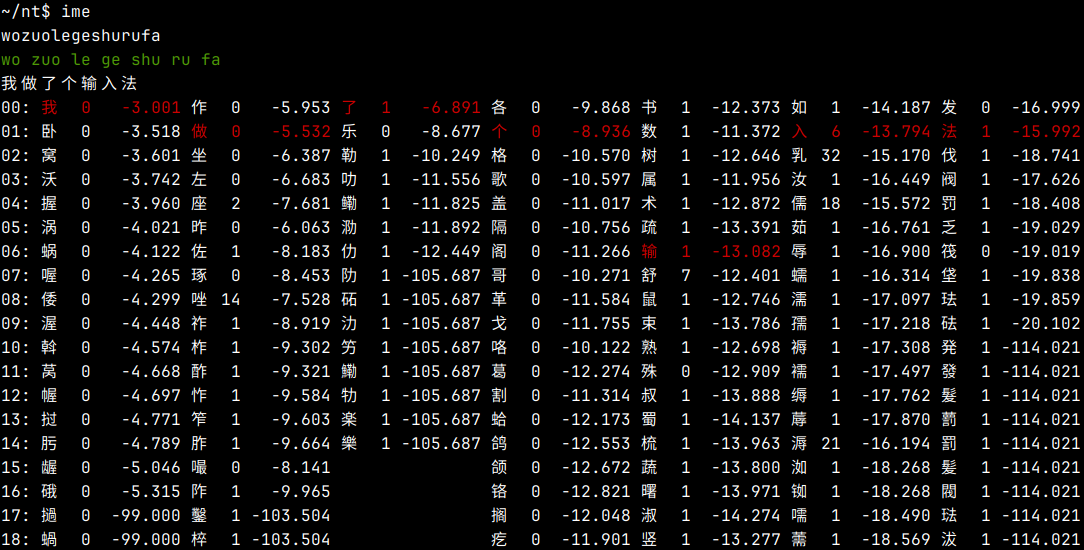
全部文件的行数
720 gb2312.utf8 这些是数据
16463 hz-py.utf8
2894733 slm.arpa 文本文件格式的语言模型
15 h.h 这些是程序
125 ime.cpp
109 pinyin.cpp
44 seg.cpp
17 Makefile
63 mk-bin.py
〔百度网盘下载〕提取码: e3ig
NT何意?No Threshold; Nuclear/No Threat; New Technology/Thought,都与我不再有关。
- -lsqlite3 -lreadline (一般已有)
- seg *.txt 分字(把字用空格隔开)。输出到stdout,可 > 或 | 给KenSLM
- mk-bin.py 把 hz-py.utf8 和 slm.arpa 转成 slm.bin (SQLite版)
ime用slm.bin或slm.1和slm.2。源码摘抄:
int main () { for (string s; (s = input()).size(); _slm.predict(s)); } void SLM::predict (const string& s) { for (const auto& py : break_pystr(s.c_str())) _m.emplace_back(get_column(py)); viterbi(); 第70~第92行,我程序比别人长得时候不多 :-)
}
struct SLM { vector<vector<Token>> _m; matrix (lattice) vector<int> _path; vector<Token> get_column(const string& py); 根据拼音得到一“列”汉字 double bigram(int x, int y, int y2); (x,y) 和 (x+1,y2) }; struct Token { Token (const uint8_t* s) { memcpy(hz, s, 4); } bool operator< (const Token& that) const { return prob > that.prob; } char hz[4]; UTF-8 double prob, bop; 1-gram; backoff probability/penalty double max; int from; 从from到此的最佳路径的概率是max };
非SQLite版(nt2),hz是uint16_t. nt2还处理了用'分隔拼音。
《统计自然语言处理基础:国外计算机科学教材系列》〔简介维特比算法〕
不用把400万词加入词典,20多万词就有50多个 shi ji 了。这个方法很有潜力:比如 shu ru,儒 的路径的前一个是 18:竖 。可搭配个8万词以下的高频词典;非高频词隐藏在语言模型里。用户参与选择,选了头一个字后,后面一串都对,然后进入用户词典。刚开始有一点不爽然后非常爽。
getwc和getc都是函数;seg提速空间巨大〔详请〕
52M的txt格式的arpa,起码可以把负号-都去掉,减少2,894,733字节。精度好像是float.
KenSLM的build_binary生成的.bin文件50M; 它是通用工具,默认100万词汇。
- 英文以词为token,所以中文也是?食古不化。梁实秋和钱歌川的书里经常提到“这个字…”
- 英文的词形还原等也挺烦
我们可以:含有GBK/GB18030字的作为词,LM里只放GB2312的字,那么 ID < 8192,两个ID 26位,概率量化为6位,每个2-gram 32位,共约 11M. 排序后二分,最多比较两个int 约22次。
- 如果你要隐藏一滴水,把它藏在大海里。如果你要隐藏corpse,把它藏在corpus里。
- ⛈ 词将无词。功若成,不必有我。
- 输入法,宁其难乎?大乎?!
- 微信输入法最早正式版本1.0.0发布于2023年11月1日
查全拼SQLite速度足够,遇到简拼tttt就傻了。
声母是t的汉字有747个,3 * (747 ** 2) = 1,674,027. 要在约300万很短的有索引的行里进行160多万次select
数据库111M,不回表139M,速度也不快。放进内存盘还不快。
改用数组和二分后,也不能飞速查tttttt,还是箍了下,只处理常用字。含生僻字的靠词典。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号