试了下速度最快的KenLM
〔KenLM〕〔kenlm的训练及使用〕〔图解N-gram语言模型的原理〕
先下载编译KenLM
wget -O - https://kheafield.com/code/kenlm.tar.gz | tar xz # 7z最大压缩后 315K libboost-program-options-dev libboost-system-dev libboost-thread-dev libboost-test-dev # 需要下载14.2MB。解压后占据185MB。
# 作者推荐libboost-all-dev,我没装也编译出来了。 mkdir kenlm/build cd kenlm/build cmake .. make -j2 # make -j 2路编译,make只是慢点而已
再写个分字程序:


enum { YI = 0x4E00 }; // 第1个汉字的编码是U+4E00,“一” void do_file (FILE* f) { static char buf[4 * 1024 * 1024]; setvbuf(f, buf, _IOFBF, sizeof(buf)); for (wint_t b = 0, c;;) { int n = 0; while ((c = getwc(f)) != WEOF && c != '\n' && c < YI) ++n; if (c == WEOF) return; else if (c == '\n') putwc(c, stdout); else { if (n || b >= YI) putwc(' ', stdout); putwc(c, stdout); } b = c; } } int main (int argc, char** argv) { static char buf[4 * 1024 * 1024]; setvbuf(stdout, buf, _IOFBF, sizeof(buf)); setlocale(LC_CTYPE, ""); for (int i = 1; i < argc; i++) { if (FILE* f = fopen(argv[i], "r")) do_file(f), fclose(f); } } #include <stdio.h> #include <locale.h> #include <wchar.h>
然后分字,seg *.txt | lmplz -o 2 >slm.arpa
lmplz默认从stdin读,写到stdout.
- --arpa file Write ARPA to a file instead of stdout
- --text file Read text from a file instead of stdin
接着build_binary slm.arpa slm.bin. 它默认使用mmap: map a file into memory.
不带输出文件名的build_binary给出将要使用多大空间的信息。
然后准备q.txt for query,它和seg的输出都是用一个空格把汉字分开,如:
三 亚 市
四 亚 县
$ query slm.bin <q.txt This binary file contains probing hash tables. 三=94 2 -2.183814 亚=222 2 -2.062365 市=61 2 -1.069804 </s>=2 2 -0.59742165 Total: -5.9134045 OOV: 0 四=116 2 -2.7783926 亚=222 1 -4.9270372 县=13 1 -1.9410045 </s>=2 2 -1.3998605 Total: -11.046295 OOV: 0 </s>=2 1 -2.6049278 Total: -2.6049278 OOV: 0 Perplexity including OOVs: 149.2270280712436 Perplexity excluding OOVs: 149.2270280712436 OOVs: 0 Tokens: 9 Name:query VmPeak:7196 kB VmRSS:4332 kB RSSMax:5188 kB
user:0.004243 sys:0 CPU:0.00431801 real:0.000905842
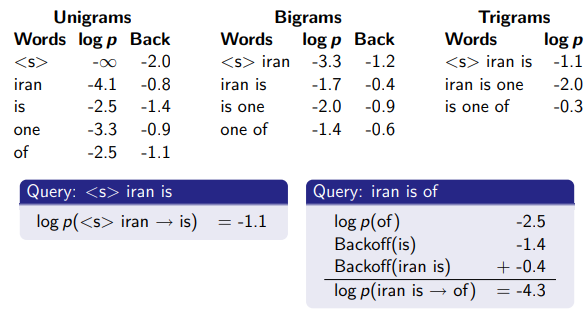
里面的概率是以10为底的对数,所以算概率时用+而不是*。<s>是句首,</s>是句尾。
-2.183814 <s> 三
-2.062365 三 亚
-1.069804 亚 市
-0.59742165 市 </s>
把它们加起来得到-5.9134045。再看个例子:
-2.7783926 <s> 四 # 有bi-gram
-4.9270372 四 亚 # 无
-1.9410045 亚 县 # 无
-1.3998605 县 </s> # 有
没有的概率如何计算?
-2.6125543 四 -0.95765805
-3.969379 亚 -0.2033539
-1.7376506 县 -1.2394043
-3.969379 + -0.95765805 = -4.92703705
-1.7376506 + -0.2033539 = -1.9410045
-0.95765805和-0.2033539叫做backoff penality. 不能因为“四”和“亚”都出现了很多次,就认为“四亚”出现很多次(把它俩的概率乘起来)——它俩不一定挨着。
〔困惑度〕
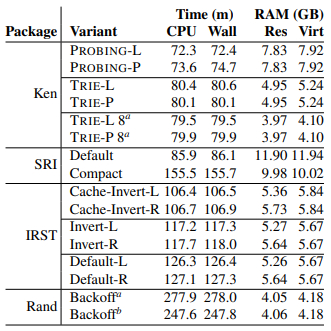
Ken是NB的;我是对的:Hash确实比Trie快。
- L: Linear; P: Polynomial, 用多项式函数计算探测序列。不妨想像用探针乱戳
- trie不考虑字符集大小是耍流氓
- 也无非hash或sorted array;鄙人处理拼音时搞了个16叉的, half-byte :-)
统计好后进入大小固定、只读阶段,二分就不错。能用Perfect Hash么?数据库呢?
We built an unpruned model on 126 billion tokens. Estimation used a machine with 140 GB RAM and six hard drives in a RAID5 configuration (sustained read: 405 MB/s). It took 123 GB RAM, 2.8 days wall time, and 5.4 CPU days -- Scalable Modified Kneser-Ney Language Model Estimation, Kenneth Heafield et al.
- 2.8的两倍可是5.6,勉强双核?还是说大部分时间I/O?
所谓ARPA格式,恐怕没有标准except \n-grams:。那么多字符,它非用\,我们就得"\\"。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号