
第二次作业:卷积神经网络 part 1
展望学习
GoogLeNet是2014年ILSVRC14的冠军算法,它的参数个数为500万个(比起VGG和AlexNet的参数个数相当低),能够极大降低计算复杂度。为了提升网络性能,GoogLeNet在增加网络深度和宽度的同时减少参数——将全连接变为稀疏连接。
Inception模块的最大作用:让计算机自己确定参数来加强更合适的卷积核的使用。
Inception V1
-
Inception v1是一个网络结构,可以作为子模块运用在神经网络中
-
底层用传统卷积,高层用Inception结构
-
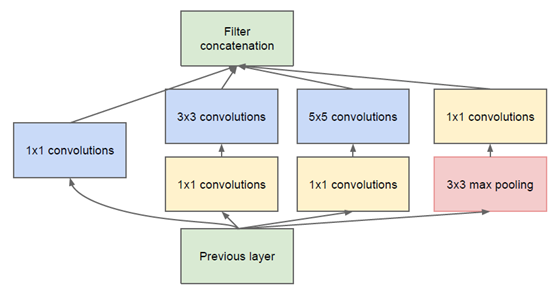
具体的网络结构如下:
![]()
-
蓝色框(1*1, 3*3, 5*5):增加网络的宽度;对尺度的适应性,得到不同尺度的特征
- 5*5的卷积核:针对相关性隔的较远的输入图像来学习特征
-
粉色框(3*3):池化操作,减少空间大小,降低过拟合
-
黄色框(1*1):降维,降低参数量(特色)
-
例:(100*100*128)——>(100*100*256) 卷积层:5*5*256
其中:(kernel_size=5,stride=1,padding=2)
则:参数量 = 128*5*5*256 = 819200
-
例:(100*100*128)——>(100*100*256) 卷积层:1*1*32,5*5*256
其中:(kernel_size=1,stride=1)—— 参数量 = 128*1*1*32= 4096
(kernel_size=5,stride=1,padding=2)—— 参数量 = 32*5*5*256= 204800
则:参数量 = 4096 + 204800 << 819200
-
-
Inception V2 / V3
-
论文:Rethinking the Inception Architecture for Computer Vision
-
设计原则
-
Avoid representational bottlenecks(避免特征描述的瓶颈)
- 不要进行较大比例的压缩(如pooling)和降维
-
Spatial aggregation can be done over lower dimension
-
利用1*1卷积降维
-
不同维度的信息有相关性,降维可以理解为无损或低损压缩
-
Balance the width and depth of the network
-
-
实现规则
- Factorizing Convolutions with Large Filter Size (分解卷积核)
- 使用两个(3*3)的卷积层代替单个(5*5)的卷积层——感受野保证了,参数量减少(减少如Inception-V1)
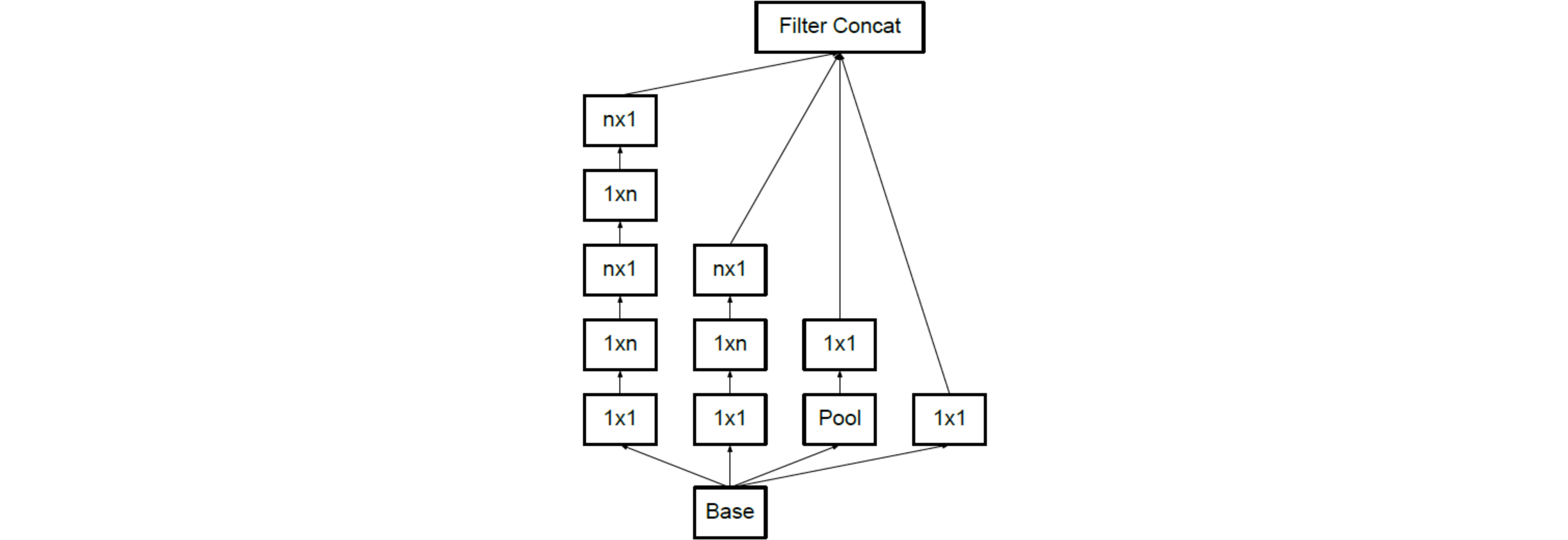
- Spatial Factorization into Asymmetric Convolutions (非对称卷积)
- 用(3*1)和(1*3)的卷积层代替单个(3*3)的卷积层
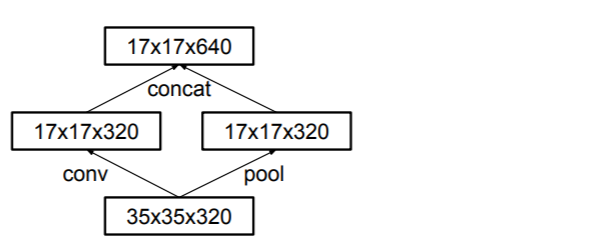
- 使用并行结构优化pooling:一路pooling,一路conv,最后拼接
- 如图:
![]()
- 如图:
- Factorizing Convolutions with Large Filter Size (分解卷积核)
-
网络结构如下:
![Inception-v2]()
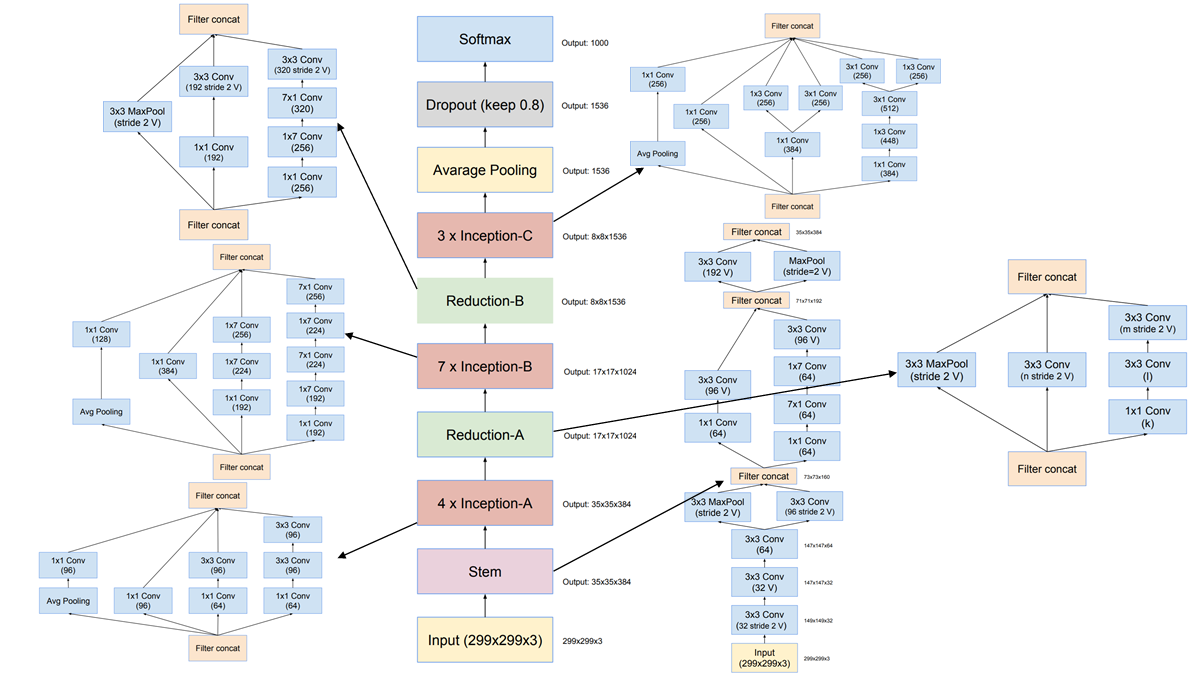
Inception V4
- 论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- Inception模块与残差模块结合——Inception-Resnet v1/v2
- 加入残差模块可以加速训练,效果略微提升
- 加入残差可以避免梯度为零
- 原因:反向传播的时候,求偏导,可以看到梯度一直存在:
![sgd]()
- 原因:反向传播的时候,求偏导,可以看到梯度一直存在:
- Inception-v4 网络结构:
![Inception-v4]()
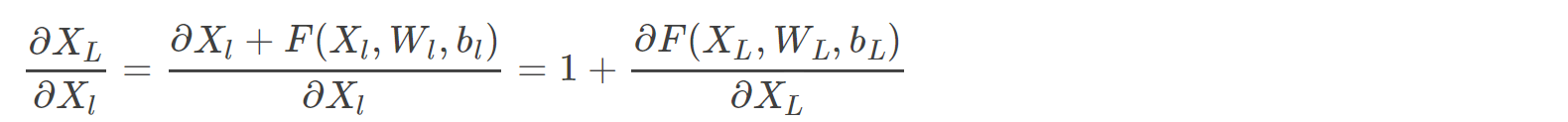
MobileNets
- 论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 参考博客:https://www.jianshu.com/p/0ca4434b1850
- 轻量级、一种用于移动和嵌入式视觉应用的高效模型
- 深度可分离卷积(对于 H*W*D 的输入)
- 深度上进行卷积,即:在每个通道的二维矩阵(H*W*1)上分别进行卷积,卷积核的深度 = 1,卷积核的个数= 网络层的通道数
- 乘法次数 A(设卷积核大小是Dk * Dk * D)= Dk * Dk * D * H * W
![multiMobile]()
- 乘法次数 A(设卷积核大小是Dk * Dk * D)= Dk * Dk * D * H * W
- 点上进行卷积:在某一层图像的某个点(1*1*D)上对所有的通道进行卷积
- 乘法次数 B = 1 * 1 * D * Num(卷积核的个数) H * W
![dotMobile]()
- 乘法次数 B = 1 * 1 * D * Num(卷积核的个数) H * W
- 总的乘法次数 Multi_num = A + B = Dk * Dk * D * H * W + 1 * 1 * D * Num * H * W
- 传统的卷积运算乘法次数 Tra_num = Dk * Dk * D * Num * H * W
- Multi_num / Tra_num = 1 / Num + 1 / Dk²
- 深度上进行卷积,即:在每个通道的二维矩阵(H*W*1)上分别进行卷积,卷积核的深度 = 1,卷积核的个数= 网络层的通道数


缺陷检测
1、观察数据集,可以发现图像明显分为10个类别。将其训练集和测试集按分好的10个类别保存,且训练集和测试集的类别名一一对应:

2、将colab平台连接Google Drive,并将AIyanxishe80文件夹压缩并上传到云端解压:
# 连接colab平台,方便上传数据集
import os
from google.colab import drive
drive.mount('/content/drive')
path = "/content/drive/My Drive"
os.chdir(path)
os.listdir(path)
3、加载python 模块
# 加载python模块
import numpy as np # linear algebra
import pandas as pd
import os
print(os.listdir("/content/drive/My Drive/AIyanxishe80"))
import cv2
import json
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from collections import Counter
from PIL import Image
import math
import seaborn as sns
from collections import defaultdict
from pathlib import Path
import cv2
from tqdm import tqdm
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
4、查看训练集和测试集的文件数
data_dir = '/content/drive/My Drive/AIyanxishe80'
datas = {x: datasets.ImageFolder(os.path.join(data_dir, x))
for x in ['Train', 'Test']}
data_sizes = {x: len(datas[x]) for x in ['Train', 'Test']}
data_classes = datas['Train'].classes
# 通过下面代码可以查看 datas 的一些属性
print('data_sizes: ', data_sizes)
print('data_classes: ', data_classes)
5、查看训练集各类别的图像数量
# 统计训练集各类别数量
for i in data_classes:
path = data_dir + '/Train/' + str(i)
dirs = os.listdir(path)
print('No.', i, ' : ', len(dirs))
6、查看缺陷文件情况——以第一张图片为例:
# 读取train.csv文件
import pandas as pd
path = data_dir + '/train.csv'
df = pd.read_csv(path)
filename = df['filename'].tolist() # 文件名
label = df['label'].tolist() #defect[i][j]:第i个图像的所有缺陷数据
defect = []
for line in label:
l = list(map(int, line.split()))
defect.append(l)
import numpy as np
from google.colab.patches import cv2_imshow
import cv2
# 读取一张照片0.png
img = '/content/drive/My Drive/AIyanxishe80/Train/1/0.png'
src = cv2.imread(img, 0)
image_num = 0
def imshow_defect():
x = 0
for i in range(512):
for j in range(512):
num = i*512+j
if x >= len(defect[image_num]):
return
if num in range(defect[image_num][x], defect[image_num][x]+defect[image_num][x+1]):
src[j][i]=255
if num == defect[image_num][x]+defect[image_num][x+1]-1:
x += 2
imshow_defect()
cv2_imshow(src)
如图:

7、剩下的暂时还没有头绪,,,明显椭圆区域要比真正的缺陷区域大,直接分块训练显然不合理,,就算直接训练后不知道缺陷如何用椭圆框表示
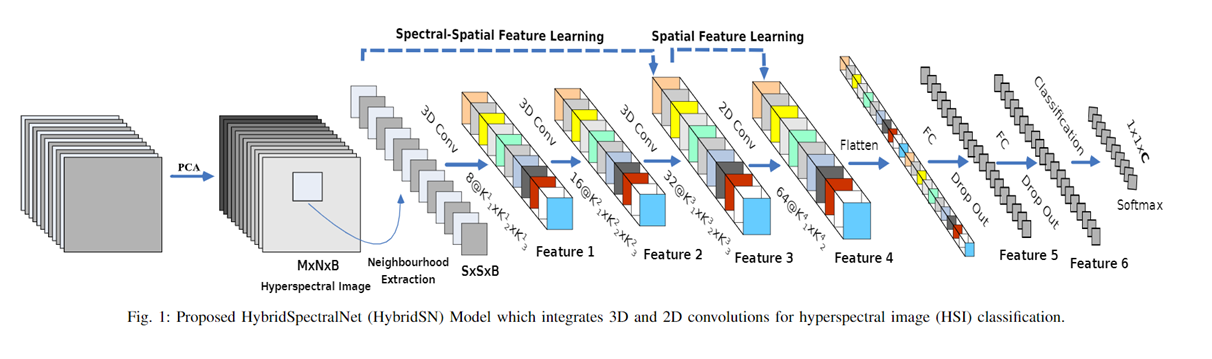
补充——HybridSN:
-
论文:HybridSN: Exploring 3D-2D CNN Feature Hierarchy for Hyperspectral Image Classification
-
网络结构:
![]()
- 三层 3D CNN 和一层 2D CNN :2D CNN输入时光谱通道受到限制,训练好的模型一般仅用于输入普通图片;3D CNN训练好后对不同光谱通道的图片的应用更加广泛,一般用于医学图像、高光谱图像等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号