自动化评测答疑机器人的表现
2.4 自动化评测答疑机器人的表现
🚄 前言
新人答疑机器人在实际使用中可能会有一些问题。例如,当新人提问“如何请假”时,机器人可能给出通用的回答,而不是基于制度文件内容进行回答。
和常规的软件开发需要测试一样,你也应该在你的答疑机器人项目中建立一套评测体系,确保在类似的问题都能快速定位原因,并且在每次针对一个问题优化后,能对一批问题进行测试,确保此次优化的对答疑机器人的整体效果是正向的。
🍁 课程目标
学完本节课程后,你将能够:
- 如何自动化大模型应用评测。
- 如何通过 Ragas 对 RAG 应用进行评测。
- 如何通过 Ragas 分数来定位并解决问题。
1. 评估 RAG 应用表现
1.1 答疑机器人存在的问题
在前面的章节中,你完成了一个答疑机器人开发,但你发现它目前在员工查询类的问题上表现不佳。
比如,张伟是员工信息表里的第一个员工,但是在你的答疑机器人中却无法回答「张伟是哪个部门的」。

import os
from config.load_key import load_key
load_key()
print(f'''你配置的 API Key 是:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}''')from chatbot import rag
query_engine = rag.create_query_engine(rag.load_index())
print('提问:张伟是哪个部门的')
response = query_engine.query('张伟是哪个部门的')
print('回答:', end='')
response.print_response_stream()1.2. 查看 RAG 检索结果排查问题
为了解决这个问题,你需要确认在你的答疑机器人回答问题前,召回的参考资料里是否有张伟的相关资料。
通过下面的代码,可以获取到答疑机器人回答这次问题时检索到的参考信息。
contexts = [node.get_content() for node in response.source_nodes]contexts由此可见,这一问题是检索效果不佳造成的。
这一章节将专注于建立自动化测试,本身这一检索效果问题将会在后续章节学习中解决。
1.3. 尝试建立自动化测试机制
尽管你总是能想办法定位到问题,但是如果每次都要这样去确认是检索出错、还是检索正确但模型生成答案出错,会非常耗时。你应该建立一个测试机制,能够自动地对你准备的一批问题进行测试。
在前面的学习中,你已经知道大模型可以用来回答问题、检查错误。同样的,大模型也可以用于检测答疑机器人的回复是否准确回答了问题,只要在提示词中提供参考信息并限制回答样式即可。
下边的test_answer 函数可以用来检测答疑机器人的回答是否有效回答了问题,你需要在提示词中传入问题与答疑机器人的回答,并限制回答样式为:“只能是:有效回答 或者 无效回答”。
传入的回答没有有效地回复“张伟是哪个部门的”这个问题,大模型回复的“无效回答”符合预期。
在RAG应用中,除了回答的有效性,你还需要确保检索到的参考信息是否有用。下边的test_contexts 函数可以用来检测检索到的参考信息是否有效,你需要在提示词中传入问题与检索到的参考信息,并限制回答样式为:“只能是:参考信息有用 或者 参考信息无用”。
def test_contexts(question, contexts): prompt = ("你是一个测试人员。\n" "你需要检测下面的这些参考资料是否能对回答问题有帮助。\n" "回复只能是:参考信息有用 或者 参考信息无用。请勿给出其他信息。\n" "------" f"参考资料是 {contexts}" "------" f"问题是: {question}" ) return llm.invoke(prompt,model_name="qwen-max")test_contexts("张伟是哪个部门的", "核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 \n⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034 qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布,\n\n⽀持。 \n绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源 绩效专员 13800000041 hanshan@educompany.com 建⽴并维护员⼯绩效档案,定期组织绩效评价会议,协调各部⻔反馈,制定考核流程与标准,确保绩效")有了上面的两个方法,你已经初步搭建好了一个大模型测试工程的雏形。但截至目前的实现还并不完善,比如:
- 因为大模型有时候会捏造事实(幻觉),其给出的答案看起来就像是真的一样,对于这种情况
test_answer方法并不能很好的检测出来。 - 检索召回的参考信息中相关的信息占比越多越好(信噪比),但目前我们的测试方法还比较简单,没有考虑这些。
你可以考虑使用一些成熟的测试框架来进一步完善你的测试工程,比如 Ragas,它是一个专门设计用于评估 RAG 应用表现的测试框架。
2. RAG 自动化评测体系
为了系统化地评测RAG系统,业界出现了一些非常实用的开源自动化评测框架,这些框架通常会从以下几个维度进行评估:
- 召回质量 (Retrieval Quality): RAG系统是否检索到了正确且相关的文档片段?
- 答案忠实度 (Faithfulness): 生成的答案是否完全基于检索到的上下文,没有“胡编乱造”(幻觉)?
- 答案相关性 (Answer Relevance): 生成的答案是否准确地回答了用户的问题?
- 上下文利用率/效率 (Context Utilization/Efficiency): 大模型是否有效地利用了所有提供给它的上下文信息?(这与我们之前提到的“Lost in the Middle”和“知识浓度”密切相关) 这里介绍几个当前比较流行且功能强大的RAG评测框架:
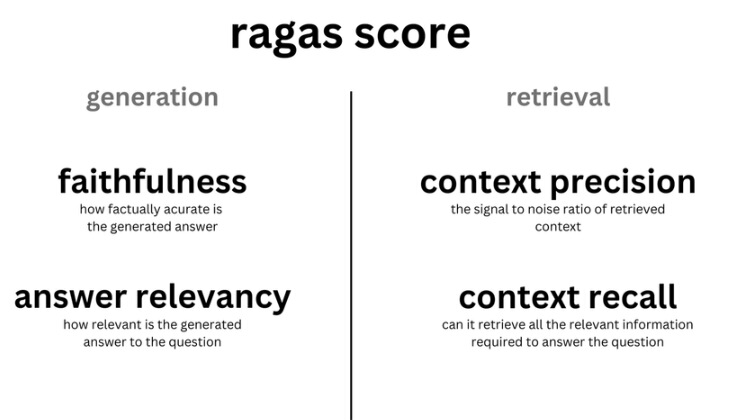
2.1 Ragas
这是领域里非常出名的一个框架,它的核心思想是“让大模型来帮助你评估RAG系统”。在评测时,Ragas 会调用一个大模型作为评测专家来阅读你的问题、RAG检索到的上下文和生成的答案,然后根据预设的指标给出分数。Ragas的评估指标高度契合RAG系统的痛点,主要包括:
- 整体回答质量的评估:
- Answer Correctness,用于评估 RAG 应用生成答案的准确度。
- 生成环节的评估:
- Answer Relevancy,用于评估 RAG 应用生成的答案是否与问题相关。
- Faithfulness,用于评估 RAG 应用生成的答案和检索到的参考资料的事实一致性。
- 召回阶段的评估:
- Context Precision,用于评估 contexts 中与准确答案相关的条目是否排名靠前、占比高(信噪比)。
- Context Recall,用于评估有多少相关参考资料被检索到,越高的得分意味着更少的相关参考资料被遗漏。
该框架提供了Python库,只需几行代码就能集成到你的RAG工作流中,也是本章后续介绍的重点。
2.2 TruLens
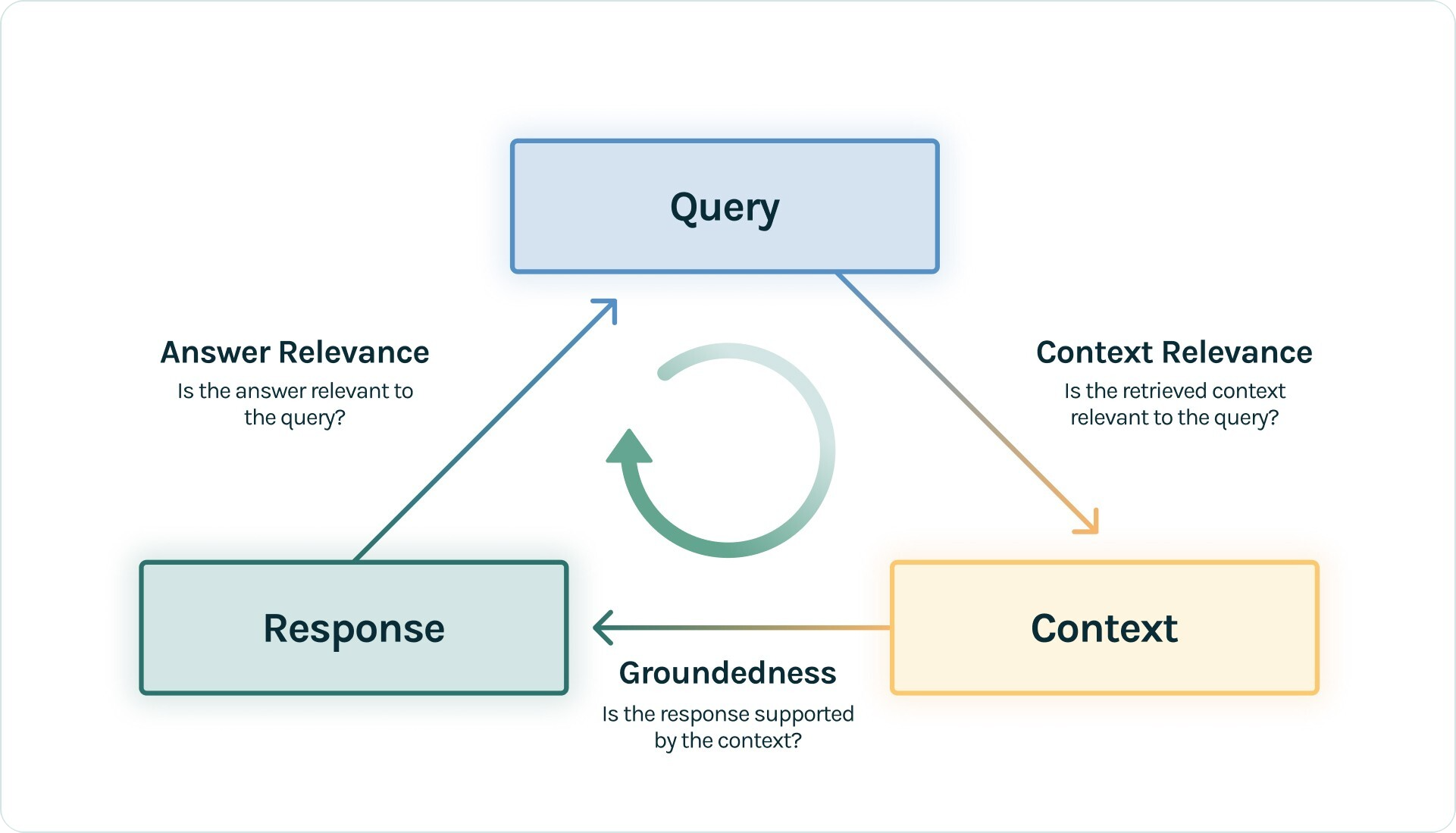
这个框架专注于评估的可观测性,它不仅仅告诉你RAG哪里可能有问题,它还能帮你追溯RAG的整个运行过程。包括每次运行的输入、输出、中间步骤、调用的大模型、检索召回的上下文等等,并提供一系列“反馈函数”来自动化评估这些运行。 TruLens 框架可以与LangChain、LlamaIndex等框架无缝集成,并提供了一套可视化工具,展示每次RAG调用的详细过程。同时,TruLens 提供了细粒度的反馈函数,从多个角度评估RAG性能,帮助你快速定位问题。其主要评估指标包括:
- Groundedness:生成的答案是否是来自于检索召回的知识
- Answer Relevance:生成的答案是否与问题相关
- Context Relevance:评估召回的知识是否跟问题相关。
你也可以访问 TruLens官网了解其他评估指标如(User sentiment、Fairness and bias)等等。
2.3 DeepEval
DeepEval 则将传统软件开发的测试理念引入到RAG应用中。它鼓励你采用单元测试和测试驱动开发(TDD)的思想,在RAG功能开发前就编写评估测试,确保应用性能从一开始就符合预期。 为此,DeepEval提供了一个专门的测试框架,让你能够像编写传统软件的单元测试一样,为RAG系统创建LLM评估测试。它支持为每个测试用例设置明确的通过/失败(Pass/Fail)阈值,这使得DeepEval能轻松集成到你的持续集成/持续部署(CI/CD)流程中,从而实现自动化回归测试。 DeepEval 的主要评测指标类似Ragas,也支持Faithfulness, Answer Relevance, Context Relevance, Context Recall等。
你可以访问DeepEval官网了解更多内容。
2.4 自定义评测框架
除了前面介绍的Ragas、TruLens、DeepEval等专业评测框架,你可能也接触过其他的开源评测工具,比如LlamaIndex和LangChain这些主流RAG开发框架本身也有内置评估工具。这些评估工具能让你在构建RAG流程的同时,方便地进行性能评估,实现无缝衔接。但是,在某些特定场景下,你可能需要更灵活、更贴合业务的评估方式,这时你也可以选择自定义评测框架。
对于评测一个智能客服系统而言,你不仅仅想知道RAG有没有“瞎说”(Faithfulness)或者答案是否“相关”(Relevance),你更想知道它是否符合你业务的特定规则,或者提供的答案是否真正解决了用户的痛点。
- 案例一:当用户询问“报销的流程是什么?”,你们的业务专家可能会要求“好的报销答案,必须明确包含报销单链接和二级主管审批信息。”或者“好的答案,必须引导用户到费用系统提交报销申请。”,这样才能满足“流程合规”的要求。
- 案例二:当用户询问“订单延迟了怎么办?”,更好的回答可能是先要“安抚用户的情绪,再给出物流状态,预期送达时间、延误原因(如果已知)、以及后续处理(如退款/投诉)的指引。”而不仅仅是回答“您的订单正在派送中,请耐心等待”。
因此,你可以把“流程可操作性”、“政策合规性”、“情绪安抚度”、“问题解决完备性”等指标,加入你的自定义评测框架。
请注意:领域专家的深度参与是评测系统乃至AI应用成功的关键。使用自动化评测框架并非要让机器彻底取代人工判断,而是旨在为评测提效。前面介绍的许多自动化框架(如Ragas)会利用大模型来充当“评委”,对RAG表现进行初步判断。然而,只有领域专家才能提供那些最宝贵的、真正反映业务需求的高价值“正确答案”(Ground Truth),并对用户提问和RAG回答的正确性进行权威性的审定。
因此,我们必须让领域专家深度参与到评测集的构建和系统性评估中。自动化评测的真正价值,在于它能将专家提供的这些宝贵Ground Truth或评估标准,转化为大规模、可重复的日常评测任务,从而解放专家的时间,让他们聚焦于更具挑战性的问题分析和优化策略制定,而非陷入重复性的判断劳动中。
3. 使用 Ragas 来评估应用表现
你可以使用Ragas来做全链路评测,这只需要在你的Python项目中加入几行代码。
3.1 评估 RAG 应用回答质量
3.1.1 快速上手
在评估 RAG 应用整体回答质量时,使用 Ragas 的 Answer Correctness 是一个很好的指标。为了计算这个指标,你需要准备以下两种数据来评测 RAG 应用产生的 answer 质量:
- question(输入给 RAG 应用的问题)
- ground_truth(你预先知道的正确的答案)
为了便于展示不同回答的评测指标差异,我们针对问题「张伟是哪个部门的」准备了三组 RAG 应用回答:
| question | ground_truth | answer |
|---|---|---|
| 张伟是哪个部门的 | 张伟是教研部的。 | 根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。(无效答案) |
| 张伟是哪个部门的 | 张伟是教研部的。 | 张伟是人事部门的。(幻觉) |
| 张伟是哪个部门的 | 张伟是教研部的。 | 张伟是教研部的。(正确) |
然后我们就可以运行下面的代码,来计算回答准确度(即 Answer Correctness)的得分。
from langchain_community.llms.tongyi import Tongyifrom langchain_community.embeddings import DashScopeEmbeddingsfrom datasets import Datasetfrom ragas import evaluatefrom ragas.metrics import answer_correctnessdata_samples = { 'question': [ '张伟是哪个部门的?', '张伟是哪个部门的?', '张伟是哪个部门的?' ], 'answer': [ '根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。', '张伟是人事部门的', '张伟是教研部的' ], 'ground_truth':[ '张伟是教研部的成员', '张伟是教研部的成员', '张伟是教研部的成员' ]}dataset = Dataset.from_dict(data_samples)score = evaluate( dataset = dataset, metrics=[answer_correctness], llm=Tongyi(model_name="qwen-plus"), embeddings=DashScopeEmbeddings(model="text-embedding-v3"))score.to_pandas()| question | answer | ground_truth | answer_correctness | |
|---|---|---|---|---|
| 0 | 张伟是哪个部门的? | 根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。 | 张伟是教研部的成员 | 0.175227 |
| 1 | 张伟是哪个部门的? | 张伟是人事部门的 | 张伟是教研部的成员 | 0.193980 |
| 2 | 张伟是哪个部门的? | 张伟是教研部的 | 张伟是教研部的成员 | 0.994619 |
可以看到,Ragas 的 Answer Correctness 指标准确的反映出了三种回答的表现,越符合事实的answer得分越高。
3.1.2 了解 answer correctness 的计算过程
从直观感受上 Answer correctness 的打分确实与你的预期相符。它在打分过程使用到了大模型(代码中的llm=Tongyi(model_name="qwen-plus"))与 embedding 模型(代码中的embeddings=DashScopeEmbeddings(model="text-embedding-v3")),由 answer 和 ground_truth 的语义相似度和事实准确度计算得出。
语义相似度
语义相似度是通过 embedding 模型得到 answer 和 ground_truth 的文本向量,然后计算两个文本向量的相似度。向量相似度的计算有许多种方法,如余弦相似度、欧氏距离、曼哈顿距离等, Ragas 使用了最常用的余弦相似度。
事实准确度
事实准确度是衡量 answer 与 ground_truth 在事实描述上差异的指标。比如以下两个描述:
- answer:张伟是教研部负责大模型课程的同事。
- ground_truth:张伟是教研部负责大数据方向的同事。
answer 和 ground_truth 在事实描述上存在差异(工作方向),但也存在一致的地方(工作部门)。这样的差异很难通过大模型或 embedding 模型的简单调用来量化。Ragas 通过大模型将 answer 与 ground_truth 分别生成各自的观点列表,并对观点列表中的元素进行比较与计算。
下图可以帮助你理解 Ragas 衡量事实准确度的方法:
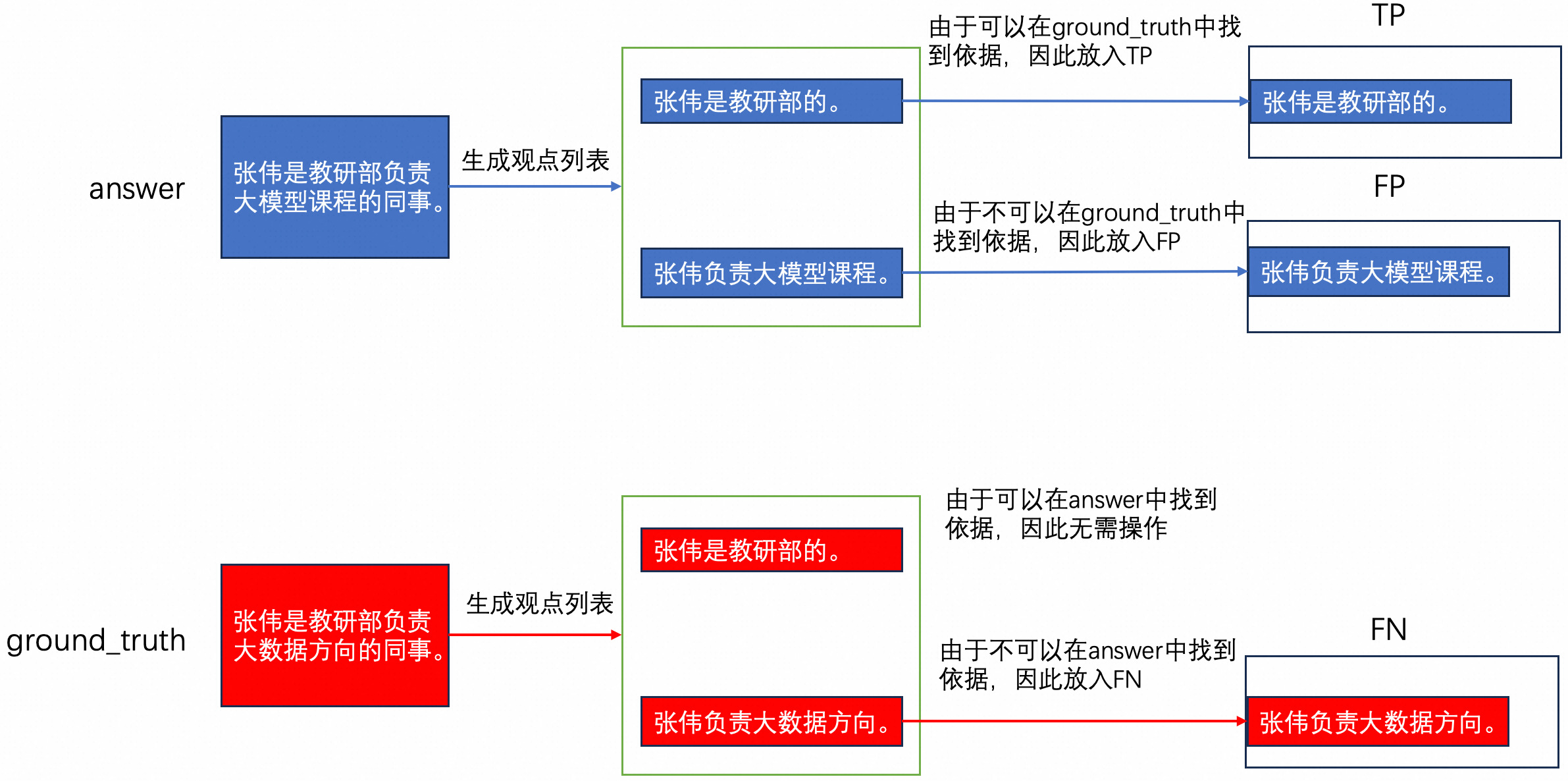
-
通过大模型将answer、ground_truth分别生成各自的观点列表。比如:
- 生成 answer 的观点列表: 张伟是教研部负责大模型课程的同事。 —> [“张伟是教研部的”, “张伟负责大模型课程”]
- 生成 ground_truth 的观点列表:张伟是教研部负责大数据方向的同事。—> [“张伟是教研部的”, “张伟负责大数据方向”]
-
遍历answer与ground_truth列表,并初始化三个列表,TP、FP与FN。
- 对于由answer生成的观点:
- 如果该观点与ground_truth的观点相匹配,则将该观点添加到TP列表中。比如:「张伟是教研部的」。
- 如果该观点在 ground_truth 的观点列表中找不到依据,则将该观点添加到FP列表中。比如:「张伟负责大模型课程」。
- 对于ground_truth生成的观点:
- 如果该观点在 answer 的观点列表中找不到依据,则将该陈述添加到FN列表中。比如:「张伟负责大数据方向」。
该步骤的判断过程均由大模型提供。
- 对于由answer生成的观点:
-
统计TP、FP与FN列表的元素个数,并按照以下方式计算f1 score分数:
f1 score = tp / (tp + 0.5 * (fp + fn)) if tp > 0 else 0以上文为例:f1 score = 1/(1+0.5*(1+1)) = 0.5
分数汇总
得到语义相似度和事实准确度的分数后,对两者加权求和,即可得到最终的 Answer Correctness 的分数。
Answer Correctness 的得分 = 0.25 * 语义相似度得分 + 0.75 * 事实准确度得分3.2 评估检索召回效果
3.2.1 快速上手
Ragas 中的 context precision 和 context recall 指标可以用于评估 RAG 应用中的检索的召回效果。
- Context precision 会评估检索召回的参考信息(contexts)中与准确答案相关的条目是否排名靠前、占比高(信噪比),侧重相关性。
- Context recall 则会评估 contexts 与 ground_truth 的事实一致性程度,侧重事实准确度。
实际应用时,可以将两者结合使用。
为了计算这些指标,你需要准备的数据集应该包括以下信息:
- question,输入给 RAG 应用的问题。
- contexts,检索召回的参考信息。
- ground_truth,你预先知道的正确的答案。
你可以继续使用「张伟是哪个部门的」这个问题,准备三组数据,运行下面的代码,来同时计算 context precision 和 context recall 的得分。
from langchain_community.llms.tongyi import Tongyifrom datasets import Datasetfrom ragas import evaluatefrom ragas.metrics import context_recall,context_precisiondata_samples = { 'question': [ '张伟是哪个部门的?', '张伟是哪个部门的?', '张伟是哪个部门的?' ], 'answer': [ '根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。', '张伟是人事部门的', '张伟是教研部的' ], 'ground_truth':[ '张伟是教研部的成员', '张伟是教研部的成员', '张伟是教研部的成员' ], 'contexts' : [ ['提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ', '绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源'], ['李凯 教研部主任 ', '牛顿发现了万有引力'], ['牛顿发现了万有引力', '张伟 教研部工程师,他最近在负责课程研发'], ],}dataset = Dataset.from_dict(data_samples)score = evaluate( dataset = dataset, metrics=[context_recall, context_precision], llm=Tongyi(model_name="qwen-plus"))score.to_pandas()| question | answer | ground_truth | contexts | context_recall | context_precision | |
|---|---|---|---|---|---|---|
| 0 | 张伟是哪个部门的? | 根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。 | 张伟是教研部的成员 | [提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 , 绩效管理部 韩杉 李⻜ I902 041 ... | 0.0 | 0.0 |
| 1 | 张伟是哪个部门的? | 张伟是人事部门的 | 张伟是教研部的成员 | [李凯 教研部主任 , 牛顿发现了万有引力] | 0.0 | 0.0 |
| 2 | 张伟是哪个部门的? | 张伟是教研部的 | 张伟是教研部的成员 | [牛顿发现了万有引力, 张伟 教研部工程师,他最近在负责课程研发] | 1.0 | 0.5 |
由上面的数据可以看到:
- 最后一行数据的回答是准确的
- 过程中检索到的参考资料(contexts)中也包含了正确答案的观点,即「张伟是教研部的」。这一情况体现在了 context recall 得分为 1。
- 但是 contexts 中并不是每一条都是和问题及答案相关的,比如「牛顿发现了万有引力」。这一情况体现在了 context precision 得分为 0.5。
3.2.2 了解 context recall 和 context precision 的计算过程
Context recall
你已经从上文了解到 context recall 是衡量 contexts 与 ground_truth 是否一致的指标。
在Ragas 中,context recall 用来描述 ground_truth 中有多少比例的观点可以得到 contexts 的支持,计算过程如下:
-
由大模型将 ground_truth 分解成 n 个观点(statements)。
比如,可以由ground_truth「张伟是教研部的成员」生成观点列表 [张伟是教研部的"]。
-
由大模型判断每个观点能在检索到的参考资料(contexts)中找到依据,或者说 context 是否能支撑 ground_truth 的观点。
比如,这个观点在第三行数据的 contexts 中能找到依据「张伟 教研部工程师,他最近在负责课程研发」。
-
然后 ground_truth 观点列表中,能在 contexts 中找到依据的观点占比,作为 context_recall 分数。
这里的得分为 1 = 1/1。
Context precision
在Ragas 中,context precision 不仅衡量了 contexts 中有多少比例的 context 与 ground_truth 相关,还衡量了 contexts 中 context 的排名情况。计算过程比较复杂:
-
按顺序读取 contexts 中的 contexti ,根据 question 与 ground_truth,判断 contexti 是否相关。相关为 1 分,否则为 0 分。
比如上面第三行数据中,context1(牛顿发现了万有引力) 是不相关的,context2 相关。
-
对于每一个 context,以该 context 及之前 context 的分数之和作为分子,context 所处排位作为分母,计算 precision 分。
对于上面第三行数据,context1 precision 分为 0/1 = 0,context2 precision 分为 1/2 = 0.5。
-
对每一个 context 的 precision 分求和,除以相关的 context 个数,得到 context_precision。
对于上面第三行数据,context_precision = (0 + 0.5) / 1 = 0.5。
如果你暂时无法理解上面的计算过程也没有关系,你只需知道该指标衡量了 contexts 中 context 的排名情况。如果你感兴趣,我们鼓励你去阅读 Ragas 的源码。
3.3 其他推荐了解的指标
Ragas 还提供了很多其他的指标,这里就不一一介绍,你可以访问 Ragas 的文档来查看更多指标的适用场景和工作原理。
Ragas 支持的指标可以访问:https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/
4.如何根据 Ragas 指标进行优化
做评测的最终目的不是为了拿到分数,而是根据这些分数确定优化的方向。你已经学习到了answer correctness、context recall、context precision三个指标的概念与计算方法,当你观察到某几个指标的分数较低时,应该制定相应的优化措施。
4.1 上下文是 RAG 的生命线
当用户提出一个问题时,大模型通过阅读理解你提供的 上下文(Context) 来给出回答。上下文决定了大模型能否给出准确、完整的答案。如果上下文缺失重要知识点,或存在错误、无关的内容,大模型就无法给出正确的结论。正如你在前面看到的问题一样:如果上下文(Context)里缺少了“张伟部门”的内容,大模型自然无法给出正确答案。
于是,为了不丢失有效知识,有人提出把全部可用资料“一股脑全部灌给大模型”,让大模型来做甄别,结果产生了一个更复杂的问题:即使某个关键线索确实存在于你提供的大量资料中,但如果它被埋藏在海量的无关信息里,大模型也很可能会“视而不见”,这便是 RAG 系统中常说的“Lost in the Middle”现象。试想,关于“张伟部门”的有效信息,可能只是一句简单的“张伟,技术部,工号XXXX”,如果这句话被夹杂在几百页的员工考勤记录、会议纪要甚至公司食堂菜单里,大模型很可能就会在这些冗余信息中迷失,导致最终无法给出正确的答案。它的“注意力”被分散了,关键信息被“淹没”了。

所以,RAG 精度的瓶颈,往往不在于大模型本身是否足够“聪明”,而在于你提供给它的上下文(Context)的“知识浓度”。一个高质量的上下文,理应具有较高的知识浓度,意味着其中的相关信息密度高、噪音少、与问题直接关联。能让大模型准确地专注问题核心,得出正确结论。因此,你提供的上下文质量,直接决定了 RAG 系统的上限。
在 Ragas 中 Context Recall 和 Context Precision 就是来衡量召回的上下文的有效性的。你可以通过分析这两个指标来确认你的RAG系统召回上下文的质量有没有提升。
4.2 context recall
context recall指标评测的是RAG应用在检索阶段的表现。如果该指标得分较低,你可以尝试从以下方面进行优化:
-
检查知识库

知识库是RAG应用的源头,如果知识库的内容不够完备,则会导致召回的参考信息不充分,从而影响context recall。你可以对比知识库的内容与测试样本,观察知识库的内容是否可以支持每一条测试样本(这个过程你也可以借助大模型来完成)。如果你发现某些测试样本缺少相关知识,则需要对知识库进行补充。
-
更换embedding模型
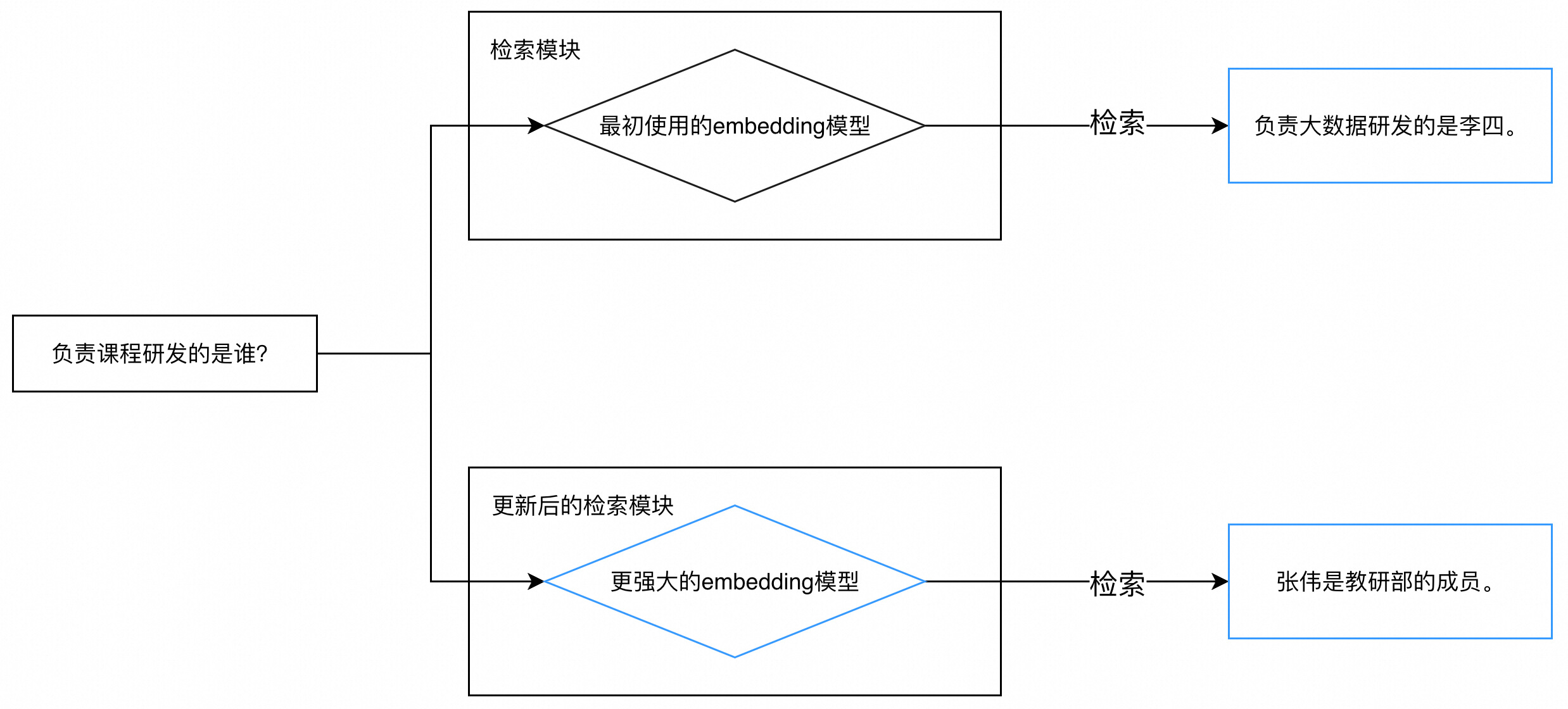
如果你的知识库内容已经很完备,则可以考虑更换embedding模型。好的embedding模型可以理解文本的深层次语义,如果两句话深层次相关,那么即使“看上去”不相关,也可以获得较高的相似度分数。比如提问是“负责课程研发的是谁?”,知识库对应文本段是“张伟是教研部的成员”,尽管重合的词汇较少,但优秀的embedding模型仍然可以为这两句话打出较高的相似度分数,从而将“张伟是教研部的成员”这一文本段召回。
-
query改写

作为开发者,对用户的提问方式做过多要求是不现实的,因此你可能会得到这样缺少信息的问题:“教研部”、“请假”、“项目管理”。如果直接将这样的问题输入RAG应用中,大概率无法召回有效的文本段。你可以通过对员工常见问题的梳理来设计一个prompt模板,使用大模型来改写query,提升召回的准确率。
4.3 context precision
与context recall一样,context precision指标评测的也是RAG应用在检索阶段的表现,但是更注重相关的文本段是否具有靠前的排名。如果该指标得分较低,你可以尝试context recall中的优化措施,并且可以尝试在检索阶段加入rerank(重排序),来提升相关文本段的排名。
4.4 answer correctness
answer correctness指标评测的是RAG系统整体的综合指标。如果该指标得分较低,而前两项分数较高,说明RAG系统在检索阶段表现良好,但是生成阶段出了问题。你可以尝试前边教程学到的方法,如优化prompt、调整大模型生成的超参数(如temperature)等,你也可以更换性能更加强劲的大模型,甚至对大模型进行微调(后边的教程会介绍)等方法来提升生成答案的准确度。
5. 打造卓越的评测运营体系
自动化评测虽然能有效提升评测效率,但是更大的挑战来自于构建高质量的评测样本以及如何凝练、积累深厚的领域知识。因此,你还需要结合自身业务特点,建立一套完善的评测运营体系。你可以从“找到最懂业务的人,用科学的方法,深度参与评测”入手:
- 让业务专家参与 AI 评测:评测的最终目的是提升业务效果,因此需要设定合理的业务目标,驱动业务专家来参与评测并沉淀评测方法。例如:让电商客服主管评测促销规则回复准确性,让物流专员评测运费时效回复准确性,让售后专家验证退换货流程回复准确性,等等。
- 从最终用户视角出发构建评测体系:首先,基于真实用户对话样本评估答疑机器人是否有效解答了用户问题,从用户视角评判答案的正确性、简洁性与可操作性。其次,综合线上用户满意度统计与抽样答准率确立核心评测指标。最后,将评测体系细化为具体的算法指标,如意图识别准确率、问题改写准确率、知识召回准确率、知识库覆盖率及模型生成准确率等。
- 持续运营评测体系:你需要将评测答疑机器人的工作融入业务体系。你可以同时利用标注平台构建专家评测机制,并开发自动化评测工具,实现两者的协同运作。更重要的是,你需要在工作流程中建立“发现问题 -> 改进优化 -> 跟踪效果 -> 迭代指标”的闭环机制,让评测持续驱动业务系统改进,最终形成良性循环。
- 维护覆盖用户意图的高质量评测集:除了采集真实用户对话作为评测样本,你也可以收集用户反馈的错误案例(bad case),统计客服记录中的高频问题。你还可以通过知识图谱、对知识做语义化结构化处理,来建立知识库,让领域专家们根据知识库来构建标准评测集,或者通过 AI 辅助生成一些样本。你的目标是构建一个能覆盖用户意图的标准评测集。
当你引入业务领域专家帮助你解决了认知问题,同时持续运营评测标准体系确保评测指标的稳定性之后,你就可以考虑如何将这些知识沉淀到你的自动化评测中。通过自动化提升工作效率,你就可以更好地贯彻执行评测标准。例如,根据用户问答及时发现问题,修订和补充用户需要的内容,或者根据业务目标的变化来调整评测指标的计算口径等等。
最终目标:让这个“答疑机器人”像贴心店员,准确理解您的需求,用您听得懂的话解决问题。
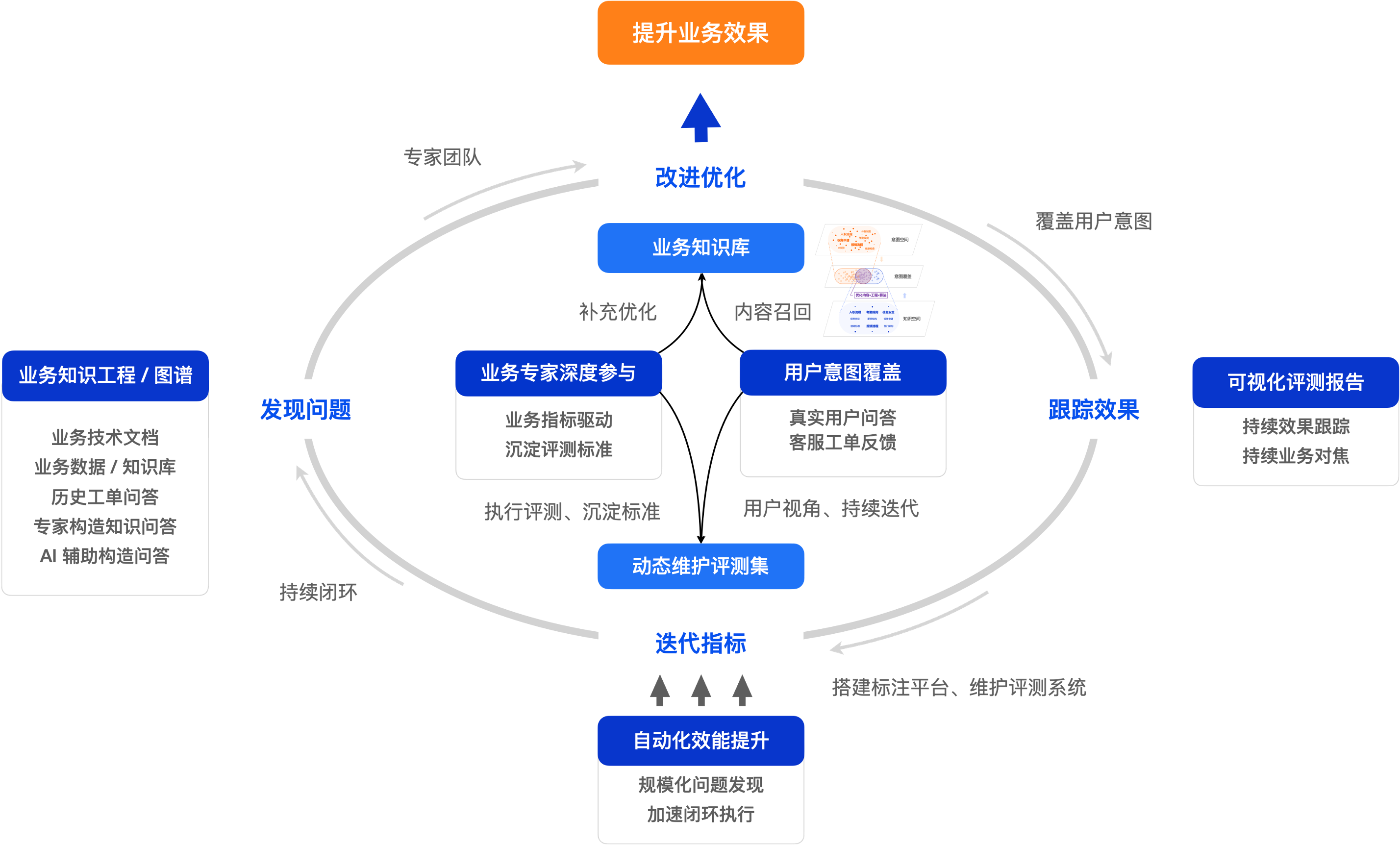
评测运营体系架构图
✅ 本节小结
通过本节内容的学习,你已经学会了怎么为RAG应用建立自动化测试了。
自动化测试是工程优化的重要手段。借助量化的自动化测试,可以帮你在改进 RAG 应用时,从感觉变好了,转变为指标量化显示应用表现更好。这不仅可以帮助你更快地评估RAG应用的问答质量、找到优化方向,还能将你所作出的优化结果量化出来。
当然,有了自动化测试并不意味着你就完全不需要人工评估了,建议在实际应用时,邀请 RAG 应用对应的领域专家一起构建能反映真实场景问题分布的测试集,并且持续更新测试集。
同时,由于大模型并不能总是做到 100% 准确,也建议你在实际使用时,定期抽样评估自动化测试结果的精度,并且尽量不要频繁更换大模型与 embedding 模型。对于 Ragas,你可以通过调整默认评测方法中的提示词(比如补充和你的业务领域相关的参考样例),来改善其表现(详情请参考拓展阅读)。
拓展阅读
更换 Ragas 的提示词模板
Ragas 的许多评测指标是基于大模型来实现的。与 LlamaIndex 一样,Ragas 的默认提示词模板是英文的,同时允许自定义修改。你可以将 Ragas 各指标的默认提示词翻译成中文,使得评测的结果更符合中文问答场景。
我们在ragas_prompt文件夹中提供了中文的提示词模板,你可以参考以下代码将中文提示词适配到 Ragas 的不同指标中。
Ragas 会在提示词中向大模型提供一些示例,来帮助大模型理解应该如何进行判断、生成观点列表等操作,因此你也可以更改示例来适配到你的业务场景。
| Ragas 自带 prompt 模板 |
|---|
 |
| 更改 prompt 模板之后 |
|---|
 |
# 导入中文提示词模板from ragas_prompt.chinese_prompt import ContextRecall,ContextPrecision,AnswerCorrectness# 进行各指标的自定义 prompt 设置context_recall.context_recall_prompt.instruction = ContextRecall.context_recall_prompt["instruction"]context_recall.context_recall_prompt.output_format_instruction = ContextRecall.context_recall_prompt["output_format_instruction"]context_recall.context_recall_prompt.examples = ContextRecall.context_recall_prompt["examples"]context_precision.context_precision_prompt.instruction = ContextPrecision.context_precision_prompt["instruction"]context_precision.context_precision_prompt.output_format_instruction = ContextPrecision.context_precision_prompt["output_format_instruction"]context_precision.context_precision_prompt.examples = ContextPrecision.context_precision_prompt["examples"]answer_correctness.correctness_prompt.instruction = AnswerCorrectness.correctness_prompt["instruction"]answer_correctness.correctness_prompt.output_format_instruction = AnswerCorrectness.correctness_prompt["output_format_instruction"]answer_correctness.correctness_prompt.examples = AnswerCorrectness.correctness_prompt["examples"]data_samples = { 'question': [ '张伟是哪个部门的?', '张伟是哪个部门的?', '张伟是哪个部门的?' ], 'answer': [ '根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。', '张伟是人事部门的', '张伟是教研部的' ], 'ground_truth':[ '张伟是教研部的成员', '张伟是教研部的成员', '张伟是教研部的成员' ], 'contexts' : [ ['提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ', '绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源'], ['李凯 教研部主任 ', '牛顿发现了万有引力'], ['牛顿发现了万有引力', '张伟 教研部工程师,他最近在负责课程研发'], ],}dataset = Dataset.from_dict(data_samples)score = evaluate( dataset = dataset, metrics=[answer_correctness,context_recall,context_precision], llm=Tongyi(model_name="qwen-plus"), embeddings=DashScopeEmbeddings(model="text-embedding-v3"))score.to_pandas()| question | answer | ground_truth | contexts | answer_correctness | context_recall | context_precision | |
|---|---|---|---|---|---|---|---|
| 0 | 张伟是哪个部门的? | 根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。 | 张伟是教研部的成员 | [提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 , 绩效管理部 韩杉 李⻜ I902 041 ... | 0.175227 | 0.0 | 0.0 |
| 1 | 张伟是哪个部门的? | 张伟是人事部门的 | 张伟是教研部的成员 | [李凯 教研部主任 , 牛顿发现了万有引力] | 0.193980 | 0.0 | 0.0 |
| 2 | 张伟是哪个部门的? | 张伟是教研部的 | 张伟是教研部的成员 | [牛顿发现了万有引力, 张伟 教研部工程师,他最近在负责课程研发] | 0.994619 | 1.0 | 0.5 |
更多评价指标
除了RAG外,还有许多种大模型或者自然语言处理(NLP)的应用或任务,如Agent、NL2SQL、机器翻译、文本摘要等。Ragas提供了许多可以评测这些任务的指标。
| 评价指标 | 使用场景 | 指标含义 |
|---|---|---|
| ToolCallAccuracy | Agent | 评估 LLM 在识别和调用完成特定任务所需工具方面的表现,该参数由参考工具调用与大模型做出的工具调用比较得到,取值范围是0-1。 |
| DataCompyScore | NL2SQL | 评估大模型生成的SQL语句在数据库检索后得到的结果与正确结果的差异性,取值为0-1。 |
| LLMSQLEquivalence | NL2SQL | 相比于上者,无需真正在数据库中进行检索,只评估大模型生成的SQL语句与正确的SQL语句的区别,取值为0-1。 |
| BleuScore | 通用 | 基于 n-gram 评估响应与正确答案之间的相似性。最初被设计用于评估机器翻译系统,评测时无需使用大模型,取值为0-1。在2.7教程中,你会学习到如何对大模型进行微调,BleuScore就可以用来评测微调带来的收益。 |
🔥 课后小测验
🔍 单选题
Context Precision 指标检测的是❓
- A. 整体回答质量的评估
- B. 评估与提问相关的召回文本段是否排名靠前
- C. 生成的答案与召回文本段是否相关
- D. 生成的答案是否与提问相关
【点击查看答案】
✅ 参考答案:B
📝 解析:
- Context Precision 衡量检索结果的排序质量,而非内容本身的相关性或最终答案质量。
🚄 前言
🍁 课程目标
学完本节课程后,你将能够:
- 进一步了解 RAG 的实现原理与技术细节
- 了解 RAG 应用常见的问题与处理方式建议
- 通过案例,动手改进 RAG 应用效果
1. 前文回顾
在上一章节,你发现答疑机器人不能很好的回答「张伟是哪个部门的?」。你可以通过这段代码复现问题:
# 导入所需的依赖包import osos.environ["TRANSFORMERS_VERBOSITY"] = "error"# 本章不使用transformer库,我们可以只关注transformer库中error级别的报警信息from config.load_key import load_keyimport loggingfrom llama_index.core import Settings, SimpleDirectoryReader, VectorStoreIndex, PromptTemplatefrom llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModelsfrom llama_index.llms.openai_like import OpenAILikefrom llama_index.core.node_parser import ( SentenceSplitter, SemanticSplitterNodeParser, SentenceWindowNodeParser, MarkdownNodeParser, TokenTextSplitter)from llama_index.core.postprocessor import MetadataReplacementPostProcessorfrom langchain_community.llms.tongyi import Tongyifrom langchain_community.embeddings import DashScopeEmbeddingsfrom datasets import Datasetfrom ragas import evaluatefrom ragas.metrics import context_recall, context_precision, answer_correctnessfrom chatbot import ragfrom IPython.display import display# 设置日志级别logging.basicConfig(level=logging.ERROR)# 加载API密钥load_key()# 生产环境中请勿将 API Key 输出到日志中,避免泄露print(f'''你配置的 API Key 是:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}''')# 配置通义千问大模型和文本向量模型Settings.llm = OpenAILike( model="qwen-plus", api_base="https://dashscope.aliyuncs.com/compatible-mode/v1", api_key=os.getenv("DASHSCOPE_API_KEY"), is_chat_model=True)# 配置文本向量模型,设置批处理大小和最大输入长度Settings.embed_model = DashScopeEmbedding( model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3, embed_batch_size=6, embed_input_length=8192)# 定义问答函数def ask(question, query_engine): # 更新提示模板 rag.update_prompt_template(query_engine=query_engine) # 输出问题 print('=' * 50) # 使用乘法生成分割线 print(f'🤔 问题:{question}') print('=' * 50 + '\n') # 使用乘法生成分割线 # 获取回答 response = query_engine.query(question) # 输出回答 print('🤖 回答:') if hasattr(response, 'print_response_stream') and callable(response.print_response_stream): response.print_response_stream() else: print(str(response)) # 输出参考文档 print('\n' + '-' * 50) # 使用乘法生成分割线 print('📚 参考文档:\n') for i, source_node in enumerate(response.source_nodes, start=1): print(f'文档 {i}:') print(source_node) print() print('-' * 50) # 使用乘法生成分割线 return responsequery_engine = rag.create_query_engine(rag.load_index())response = ask('张伟是哪个部门的', query_engine)你会发现,产生问题的原因是检索阶段没有召回到正确的参考信息(文档切片)。如何改进这个问题呢?你可以参考几个简单的改进策略,初步优化检索效果。
2. 初步优化检索效果
正如前言提到的,你需要让大模型拿到正确的"参考书",才能给出正确的"答案"。因此,你可以尝试增加每次拿到"参考书"的数量(增加召回的文档切片数量),或者将"参考书中的知识点"整理成结构化的表格(文档内容结构化)。你可以先从前者入手:
2.1 让大模型获取到更多参考信息
既然知识库中存在张伟的任职信息,那么你可以通过增加一次性召回的文档切片数量的方式,从而扩大检索范围,提升找到相关信息的概率。在之前的代码里,你只召回了2个文档切片,现在,你可以将召回数量增加至5个,再次观察召回效果是否得到了提升。
2.1.1 调整代码
你可以通过以下设置,让检索引擎召回前5个最相关的文档切片。
index = rag.load_index()query_engine = index.as_query_engine( streaming=True, # 一次检索出 5 个文档切片,默认为 2 similarity_top_k=5)response = ask('张伟是哪个部门的', query_engine)可以看到:在调整了召回数量后,你的答疑机器人能够回答「张伟是哪个部门?」了,这是因为召回的文档切片中已经包含了张伟和他的部门信息。
不过,单纯增加召回的切片数量并不是一个好方法。想想看,如果这种方法能解决问题,那么不如召回整个知识库,这样不会遗漏任何的信息……可是这不仅会超出大模型的输入长度限制,过多的无关信息还会降低大模型回答的效率和准确性。
而且,事实上你们公司可能有很多叫张伟的同事,这会导致一个问题:当用户问"张伟是哪个部门的"时,系统无法确定用户想问的是哪一个张伟。如果只是简单地增加召回数量,可能会召回到多个张伟的信息,但系统仍然无法准确判断应该返回哪个张伟的信息。因此,我们还需要用其他方法来进一步改进 RAG 效果。
2.1.2 评估改进效果
为了在接下来的改进中,能够量化改进效果,你可以继续使用上一章节中的 Ragas 来进行评测。假设你们公司有三名叫张伟的同事,他们分别在教研部、课程开发部、IT部。
# 定义评估函数def evaluate_result(question, response, ground_truth): # 获取回答内容 if hasattr(response, 'response_txt'): answer = response.response_txt else: answer = str(response) # 获取检索到的上下文 context = [source_node.get_content() for source_node in response.source_nodes] # 构造评估数据集 data_samples = { 'question': [question], 'answer': [answer], 'ground_truth':[ground_truth], 'contexts' : [context], } dataset = Dataset.from_dict(data_samples) # 使用Ragas进行评估 score = evaluate( dataset = dataset, metrics=[answer_correctness, context_recall, context_precision], llm=Tongyi(model_name="qwen-plus"), embeddings=DashScopeEmbeddings(model="text-embedding-v3") ) return score.to_pandas()question = '张伟是哪个部门的'ground_truth = '''公司有三名张伟,分别是:- 教研部的张伟:职位是教研专员,邮箱 zhangwei@educompany.com。- 课程开发部的张伟:职位是课程开发专员,邮箱 zhangwei01@educompany.com。- IT部的张伟:职位是IT专员,邮箱 zhangwei036@educompany.com。'''evaluate_result(question=question, response=response, ground_truth=ground_truth)可以看到,当前的RAG系统还无法高效地运行,召回的文档切片中存在无关信息,且有效信息也没有被完全召回,最终形成的答案并不正确。你还需要考虑其他改进策略。
2.2 给大模型结构更清晰的参考信息
在实际应用中,文档的组织结构对检索效果有着重要影响。想象一下,同样的信息,放在一个结构清晰的表格中和散落在一段普通文字里,哪个更容易查找和理解?显然是前者。
大语言模型也是如此。当把原本在表格中的信息转换成普通文本时,虽然信息本身没有丢失,但结构性却降低了。这就像是把一个整齐的抽屉变成了一堆散乱的物品,虽然东西都在,但查找起来就没那么方便了。
2.2.1 重建索引
Markdown格式是一个很好的选择,因为它:
- 结构清晰,层次分明
- 语法简单,易于阅读和维护
- 特别适合RAG(检索增强生成)场景下的文档组织
为了验证结构化文档的效果,课程准备了一份经过优化的Markdown格式文件。接下来,你将:
- 把这份Markdown文件添加到docs目录
- 重新建立索引
- 测试检索效果的提升
# 将 markdown 格式的员工信息文档复制到 ./docs 目录下! mkdir -p ./docs/2_5! cp ./resources/2_4/内容公司各部门职责与关键角色联系信息汇总.md ./docs/2_5print('=' * 50)print('📂 正在加载文档...')print('=' * 50 + '\n')# 加载文档documents = SimpleDirectoryReader('./docs/2_5').load_data()print(f'✅ 文档加载完成。\n')print('=' * 50)print('🛠️ 正在重建索引...')print('=' * 50 + '\n')# 重建索引index = VectorStoreIndex.from_documents( documents)print('✅ 索引重建完成!')print('=' * 50)query_engine = index.as_query_engine( streaming=True, similarity_top_k=5)response = ask('张伟是哪个部门的', query_engine)2.2.2 评估改进效果
可以看到,你的答疑机器人能够准确回答这个问题。你可以再运行一次 Ragas 评测,评测数据同样显示:回答准确度更高了。
evaluate_result(question=question, response=response, ground_truth=ground_truth)3. 熟悉 RAG 的工作流程
截至目前,你已经完成了一些改进,让答疑机器人的问答准确度更高了。但在实际生产环境中,你可能会遇到的问题远不止于此。之前你已经了解了一些 RAG 的工作流程,在这里你可以回顾一下重要的步骤,方便你发现新的改进点:
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的技术,能够在生成答案时利用外部知识库中的相关信息。它的工作流程可以分为几个关键步骤:解析与切片、向量存储、检索召回、生成答案等。具体的概念你可以回顾"扩展答疑机器人的知识范围"这一节。
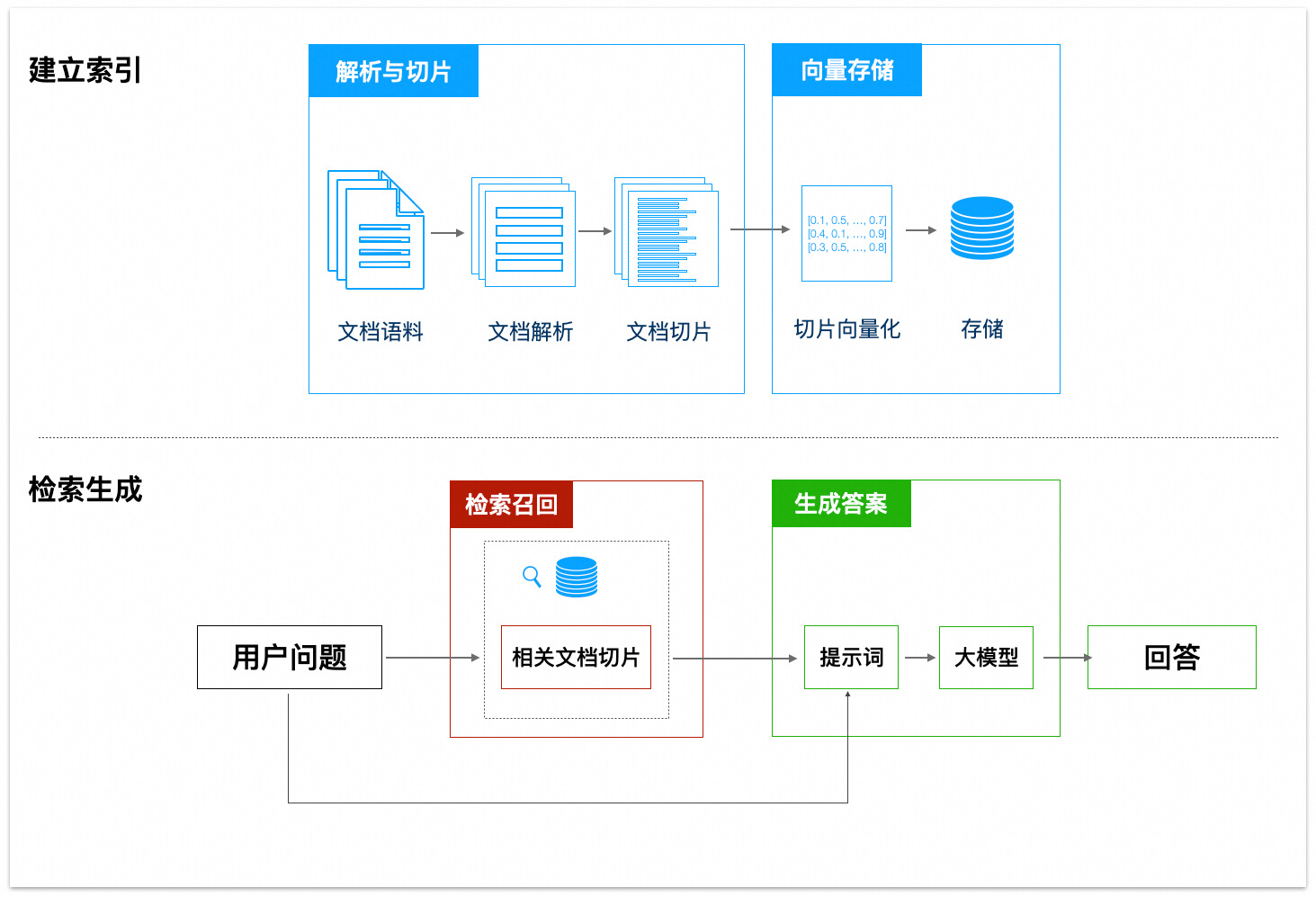
接下来,将从 RAG 中的每一个环节入手,尝试优化 RAG 的效果。
4. RAG 应用各个环节与改进策略
4.1 文档准备阶段
在传统的客服系统中,客服人员会根据用户所提问题,积累知识库,并共享给其他客服人员参考。在构建 RAG 应用时,这一过程同样不可缺少。
- 意图空间:我们可以把用户提问背后的需求绘制成点,这些点组成了一个用户意图空间。
- 知识空间:而你沉淀在知识库文档中的知识点,则构成了组成一个知识空间。这里的知识点,可以是一个段落、或者一个章节。
当我们将意图空间和知识空间投影到一起,会发现两个空间存在交集与差异。这些区域分别对应了我们后续的三个优化策略:
- 重叠区域:
- 即可以依靠知识库的内容来回答用户问题的部分,这是 RAG 应用效果保障的基础。
- 对于这部分用户意图,你可以通过优化内容质量、优化工程和算法,不断地提升回答质量。
- 未被覆盖的意图空间:
- 因为缺乏知识库内容的支撑,大模型容易输出“幻觉”回答。例如,公司新增了一个"数据分析部",但知识库中没有相关文档,不论如何改进工程算法,RAG 应用都无法准确回答这一问题。
- 你需要做的是主动补充缺漏的知识,不断跟进用户意图空间的变化。
- 未被利用的知识空间:
- 召回不相关知识点可能会干扰大模型的回答。
- 因此,需要你优化召回算法避免召回无关内容。此外,你还需要定期查验知识库,剔除无关内容。
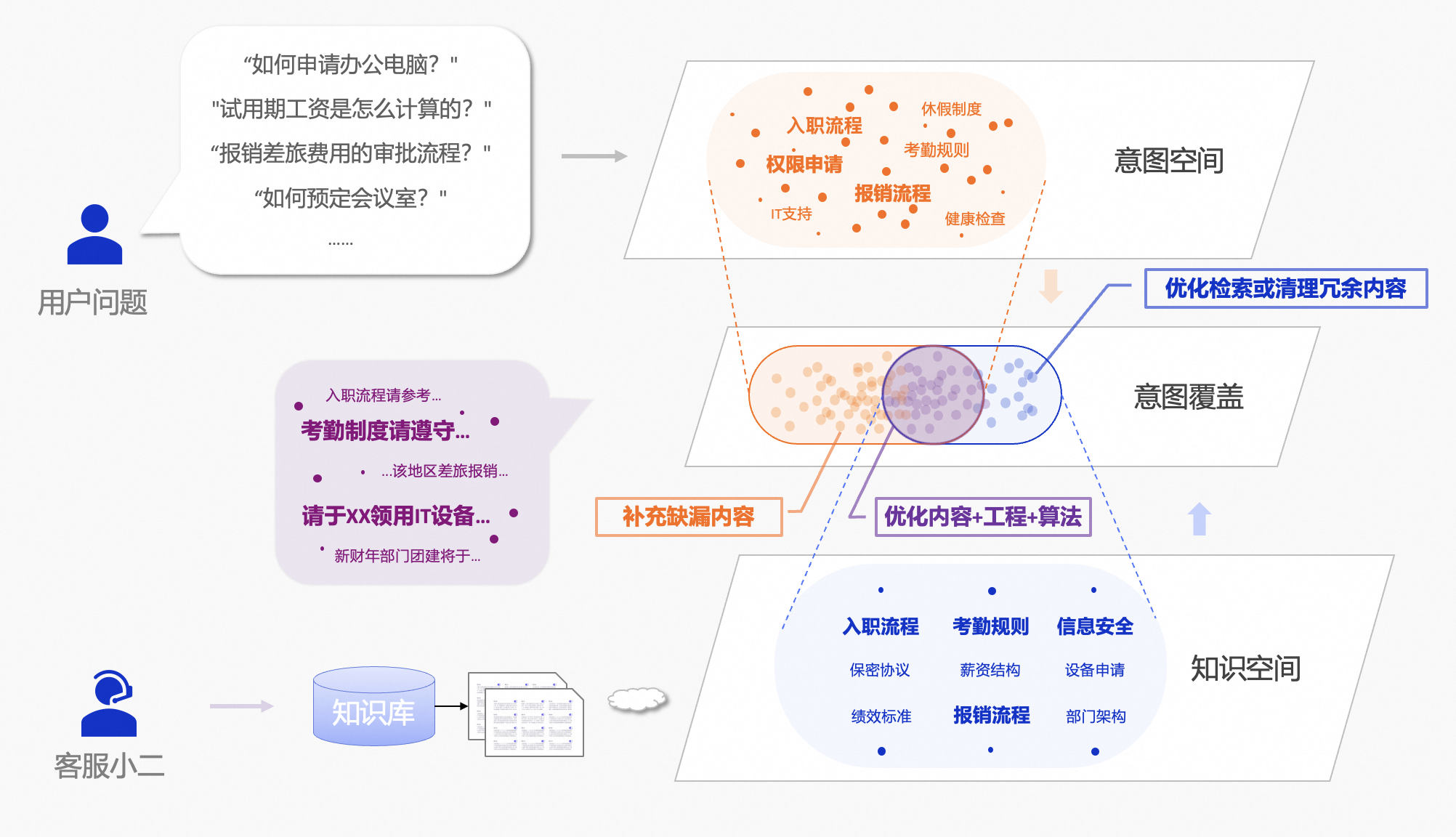
在尝试优化工程或算法之前,你应该优先构建一套可以持续收集用户意图的机制。通过系统化采集真实用户需求来完善知识库内容,并邀请对用户意图有深刻理解的领域专家参与效果评估,形成"数据采集-知识更新-专家验证"的闭环优化流程,保障 RAG 应用的效果。
当你准备好这些,就可以进一步优化 RAG 应用的各个环节了。
4.2 文档解析与切片阶段
首先,RAG 应用会解析你的文档内容,然后对文档内容进行切片。
大模型在回答问题时拿到的文档切片如果缺少关键信息,会回答不准确;如果拿到的文档切片非关联信息过多(噪声),也会影响回答质量。即过少或过多的信息,都会影响模型的回答效果。
因此,在对文档进行解析与切片时,需要确保最终的切片信息完整,但不要包含太多干扰信息。
4.2.2 借助百炼解析 PDF 文件
在前面的学习过程中,为了让你更快地看到格式转换带来的效果,本课程直接提供了一份从 PDF 转换的 Markdown 格式文档。但在实际工作中,编写代码将 PDF 妥善地转为 Markdown 并非易事。
实际工作中,你也可以借助百炼提供的 DashScopeParse 来完成 PDF、Word 等格式的文件解析。DashScopeParse 背后使用了阿里云的文档智能服务,能够帮助你从 PDF、Word 等格式的文件中识别文档中的图片、提取出结构化的文本信息。
from llama_index.readers.dashscope.utils import ResultTypefrom llama_index.readers.dashscope.base import DashScopeParseimport osimport jsonimport nest_asyncionest_asyncio.apply()# 使用环境变量os.environ['DASHSCOPE_API_KEY'] = os.getenv('DASHSCOPE_API_KEY')# 创建一个静默的日志记录器来替换原始的 loggersilent_logger = logging.getLogger(__name__)# 设置日志级别为 ERROR,以避免输出无关信息。如果您需要查看更详细的日志信息,请设置为 INFOsilent_logger.setLevel(logging.ERROR)class SilentDashScopeParse(DashScopeParse): def __init__(self, *args, **kwargs): # 替换所有相关模块的 logger import llama_index.readers.dashscope.base as base_module import llama_index.readers.dashscope.domain.lease_domains as lease_domains_module import llama_index.readers.dashscope.utils as utils_module base_module.logger = silent_logger lease_domains_module.logger = silent_logger utils_module.logger = silent_logger # 调用父类初始化 super().__init__(*args, **kwargs)# 文件通过DashScopeParse接口解析为程序与大模型易于处理的markdown文本def file_to_md(file, category_id): parse = SilentDashScopeParse( result_type=ResultType.DASHSCOPE_DOCMIND, category_id=category_id ) documents = parse.load_data(file_path=file) # 初始化一个空字符串来存储Markdown内容 markdown_content = "" for doc in documents: doc_json = json.loads(json.loads(doc.text)) for item in doc_json["layouts"]: if item["text"] in item["markdownContent"]: markdown_content += item["markdownContent"] else: # DashScopeParse处理时,会将文档图片内的文本信息也解析到初始markdown文本中(类似OCR),这对于本文示例文件中的命令行截图、文本截图是足够的,示例无需深层次解析图片。 # 实际场景中的知识库文档,如果涉及不规则、复杂信息的图片并且需要深层次理解图片内容,您可以调用视觉模型进一步理解图片含义。 # (DashScopeParse返回的数据结构中,针对图片数据,markdownContent字段是图片url,text字段是解析出的文本) # if ".jpg" in item["markdownContent"] or ".jpeg" in item["markdownContent"] or ".png" in item["markdownContent"]: # image_url = re.findall(r'\!\[.*?\]\((https?://.*?)\)', item["markdownContent"])[0] # print(image_url) # markdown_content = markdown_content + parse_image_to_text(image_url)+"\n" # else: # markdown_content = markdown_content + item["text"]+"\n" markdown_content = markdown_content + item["text"]+"\n" return markdown_content### 调用示例# 1、可选配置。# 百炼平台上,可以对不同项目配置不同的业务空间,默认情况下是使用默认业务空间。# 如果需要使用非默认空间,可以前往[百炼控制台-业务空间管理](https://bailian.console.aliyun.com/?admin=1#/efm/business_management),配置业务空间并获取Workspace ID。# 完成后,取消注释并修改这段代码为实际值:# os.environ['DASHSCOPE_WORKSPACE_ID'] = "<Your Workspace id, Default workspace is empty.>"# 2、可选配置。# 文件通过DashScopeParse进行解析时,需要配置上传的数据目录id。可以前往[百炼控制台-数据管理](https://bailian.console.aliyun.com/#/data-center),配置类目并获取IDcategory_id="default" # 建议修改为自定义的类目ID,以便分类管理文件md_content = file_to_md(['./docs/内容公司各部门职责与关键角色联系信息汇总.pdf'], category_id)print("解析后的Markdown文本:")print("-"*100)print(md_content)由于pdf/docx等多种文件格式来源的多样性,文件解析到markdown过程中可能存在一些格式上的小问题,比如 PDF 里的跨页表格行可能被解析为多行。
可以使用大模型对生成的markdown文本进行润色,修正目录层级、缺失信息等。
from dashscope import Generationdef md_polisher(data): messages = [ {'role': 'user', 'content': '下面这段文本是由pdf转为markdown的,格式和内容可能存在一些问题,需要你帮我优化下:\n1、目录层级,如果目录层级顺序不对请以markdown形式补全或修改;\n2、内容错误,如果存在上下文不一致的情况,请你修改下;\n3、如果有表格,注意上下行不一致的情况;\n4、输出文本整体应该与输入没有较大差异,不要自己制造内容,我是需要对原文进行润色;\n4、输出格式要求:markdown文本,你的所有回答都应该放在一个markdown文件里面。\n特别注意:只输出转换后的 markdown 内容本身,不输出任何其他信息。\n需要处理的内容是:' + data} ] response = Generation.call( model="qwen-plus", messages=messages, result_format='message', stream=True, incremental_output=True ) result = "" print("润色后的Markdown文本:") print("-"*100) for chunk in response: print(chunk.output.choices[0].message.content, end='') result += chunk.output.choices[0].message.content return(result)md_polisher(md_content)通过上面的步骤,你已经成功地将 PDF 转成了 Markdown,并且做了一些格式修正。与此同时,即使文档中存在图片,图片中的信息也能被提取出来,以便构建更有利于检索效果的知识库。
4.2.3 使用多种文档切片方法
在文档切片的过程中,切片方式会影响检索召回的效果。让我们通过具体例子来了解不同切片方法的特点。首先创建一个通用的评测函数
def evaluate_splitter(splitter, documents, question, ground_truth, splitter_name): """评测不同文档切片方法的效果""" print(f"\n{'='*50}") print(f"🔍 正在使用 {splitter_name} 方法进行测试...") print(f"{'='*50}\n") # 构建索引 print("📑 正在处理文档...") nodes = splitter.get_nodes_from_documents(documents) index = VectorStoreIndex(nodes, embed_model=Settings.embed_model) # 创建查询引擎 query_engine = index.as_query_engine( similarity_top_k=5, streaming=True ) # 执行查询 print(f"\n❓ 测试问题: {question}") print("\n🤖 模型回答:") response = query_engine.query(question) response.print_response_stream() # 输出参考片段 print(f"\n📚 {splitter_name} 召回的参考片段:") for i, node in enumerate(response.source_nodes, 1): print(f"\n文档片段 {i}:") print("-" * 40) print(node) # 评估结果 print(f"\n📊 {splitter_name} 评估结果:") print("-" * 40) display(evaluate_result(question, response, ground_truth))接下来,让我们看看各种切片方法的特点和示例:
4.2.3.1 Token 切片
适合对 Token 数量有严格要求的场景,比如使用上下文长度较小的模型时。
示例文本: “LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需要选择合适的方法。”
使用Token切片(chunk_size=10)后可能的结果:
- 切片1: “LlamaIndex是一个强大的RAG”
- 切片2: “框架。它提供了多种文”
- 切片3: “档处理方式。用户可以”
token_splitter = TokenTextSplitter( chunk_size=1024, chunk_overlap=20)evaluate_splitter(token_splitter, documents, question, ground_truth, "Token")4.2.3.2 句子切片
这是默认的切片策略,会保持句子的完整性。
同样的文本使用句子切片后:
- 切片1: “LlamaIndex是一个强大的RAG框架。”
- 切片2: “它提供了多种文档处理方式。”
- 切片3: “用户可以根据需求选择合适的方法。”
sentence_splitter = SentenceSplitter( chunk_size=512, chunk_overlap=50)evaluate_splitter(sentence_splitter, documents, question, ground_truth, "Sentence")4.2.3.3 句子窗口切片
每个切片都包含周围的句子作为上下文窗口。
示例文本使用句子窗口切片(window_size=1)后:
- 切片1: “LlamaIndex是一个强大的RAG框架。” 上下文: “它提供了多种文档处理方式。”
- 切片2: “它提供了多种文档处理方式。” 上下文: “LlamaIndex是一个强大的RAG框架。用户可以根据需求选择合适的方法。”
- 切片3: “用户可以根据需求选择合适的方法。” 上下文: “它提供了多种文档处理方式。”
sentence_window_splitter = SentenceWindowNodeParser.from_defaults( window_size=3, window_metadata_key="window", original_text_metadata_key="original_text")# 注意:句子窗口切片需要特殊的后处理器query_engine = index.as_query_engine( similarity_top_k=5, streaming=True, node_postprocessors=[MetadataReplacementPostProcessor(target_metadata_key="window")])evaluate_splitter(sentence_window_splitter, documents, question, ground_truth, "Sentence Window")4.2.3.4 语义切片
根据语义相关性自适应地选择切片点。
示例文本: “LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需求选择合适的方法。此外,它还支持向量检索。这种检索方式非常高效。”
语义切片可能的结果:
- 切片1: “LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需求选择合适的方法。”
- 切片2: “此外,它还支持向量检索。这种检索方式非常高效。” (注意这里是按语义相关性分组的)
semantic_splitter = SemanticSplitterNodeParser( buffer_size=1, breakpoint_percentile_threshold=95, embed_model=Settings.embed_model)evaluate_splitter(semantic_splitter, documents, question, ground_truth, "Semantic")4.2.3.5 Markdown 切片
专门针对 Markdown 文档优化的切片方法。
示例 Markdown 文本:
# RAG框架
LlamaIndex是一个强大的RAG框架。
## 特点
- 提供多种文档处理方式
- 支持向量检索
- 使用简单方便
### 详细说明
用户可以根据需求选择合适的方法。Markdown切片会根据标题层级进行智能分割:
- 切片1: “# RAG框架\nLlamaIndex是一个强大的RAG框架。”
- 切片2: “## 特点\n- 提供多种文档处理方式\n- 支持向量检索\n- 使用简单方便”
- 切片3: “### 详细说明\n用户可以根据需求选择合适的方法。”
markdown_splitter = MarkdownNodeParser()evaluate_splitter(markdown_splitter, documents, question, ground_truth, "Markdown")在实际应用中,选择切片方法时不必过于纠结,你可以这样思考:
- 如果你刚开始接触 RAG,建议先使用默认的句子切片方法,它在大多数场景下都能提供不错的效果
- 当你发现检索结果不够理想时,可以尝试:
- 处理长文档且需要保持上下文?试试句子窗口切片
- 文档逻辑性强、内容专业?语义切片可能会有帮助
- 模型总是报 Token 超限?Token 切片可以帮你精确控制
- 处理 Markdown 文档?别忘了有专门的 Markdown 切片
没有最好的切片方法,只有最适合你场景的方法。你可以尝试不同的切片方法,观察 Ragas 评估结果,找到最适合你需求的方案。学习的过程就是不断尝试和调整的过程!
4.3 切片向量化与存储阶段
文档切片后,你还需要对其建立索引,以便后续检索。一个常见的方案是使用嵌入(Embedding)模型将切片向量化,并存储到向量数据库中。
在这一阶段,你需要选择合适的 Embedding 模型以及向量数据库,这对于提升检索效果至关重要。
4.3.1 了解 Embedding 与向量化
Embedding 模型可以将文本转换为高维向量,用于表示文本语义,相似的文本会映射到相近的向量上,检索时可以根据问题的向量找到相似度高的文档切片。
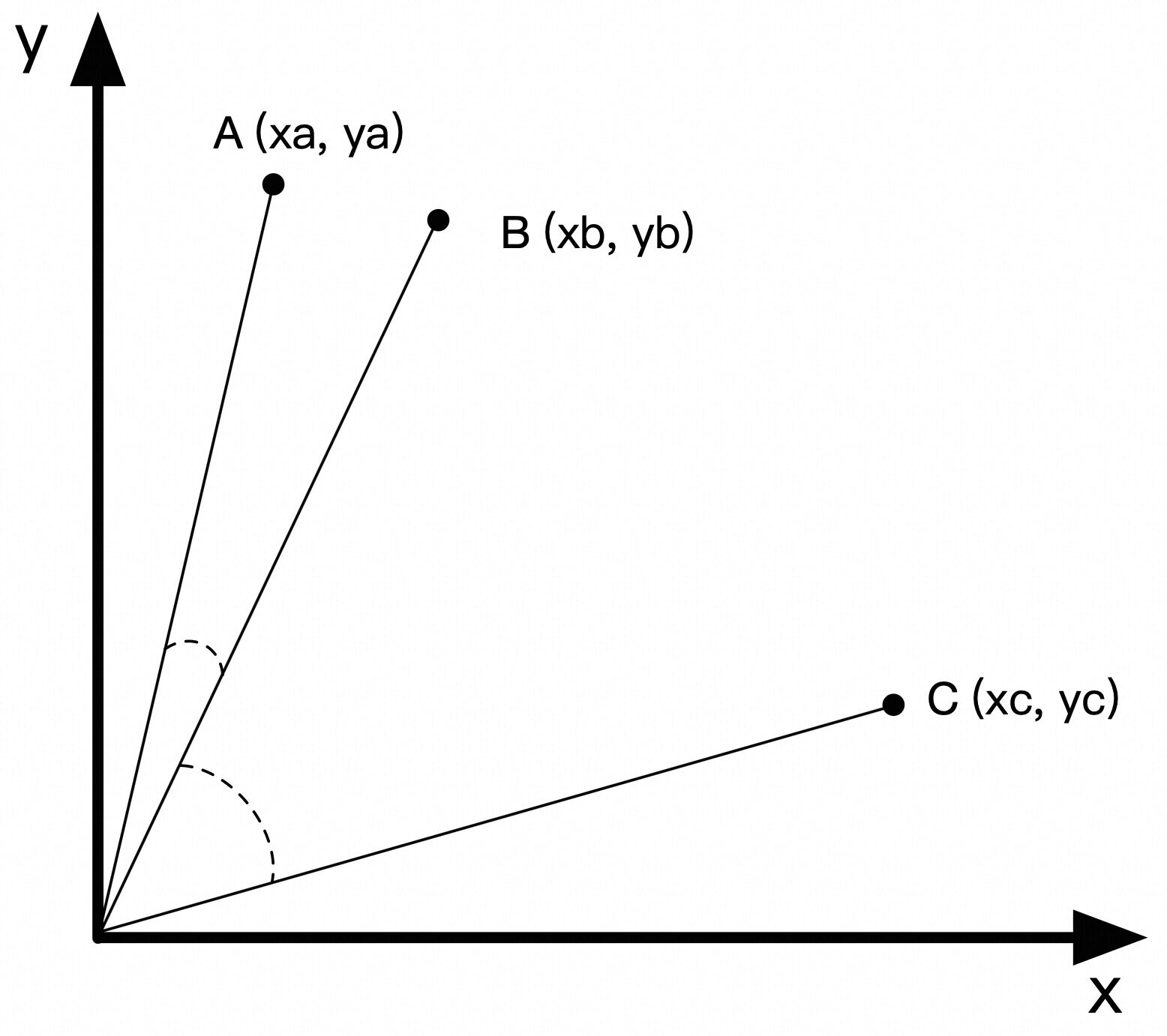
平面坐标系中的有向线段是 2 维向量。例如,从原点 (0, 0) 到 A (xa, ya) 的有向线段可以称为向量 A。向量 A 与向量 B 之间的夹角越小,也就意味着其相似度越高。
import numpy as npdef cosine_similarity(a, b): """余弦相似度""" return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))# 示例向量a = np.array([0.2, 0.8])b = np.array([0.3, 0.7])c = np.array([0.8, 0.2])print(f"A 与 B 的余弦相似度: {cosine_similarity(a, b)}")print(f"B 与 C 的余弦相似度: {cosine_similarity(b, c)}")4.3.2 选择合适的 Embedding 模型
不同的 Embedding 模型对相同的几段文字进行计算时,得到的向量可能会完全不同。通常越新的 Embedding 模型,其表现越好。例如前文中使用的是阿里云百炼上提供的 text-embedding-v2。如果换成更新的版本 text-embedding-v3 你会发现即使不去做前面的优化,检索效果也会有一定的提升。
比如运行下面的代码可以看到,不同版本的 Embedding 模型,对于「张伟是哪个部门的」这个问题和不同文档切片的相似度也是不同的。
def compare_embeddings(query, chunks, embedding_models): """比较不同嵌入模型的文本相似度 Args: query: 查询文本 chunks: 待比较的文本片段列表 embedding_models: 嵌入模型字典,格式为 {模型名称: 模型实例} """ # 打印输入文本 print(f"查询: {query}") for i, chunk in enumerate(chunks, 1): print(f"文本 {i}: {chunk}") # 计算并显示每个模型的相似度结果 for model_name, model in embedding_models.items(): print(f"\n{'='*20} {model_name} {'='*20}") query_embedding = (model.get_query_embedding(query) if hasattr(model, 'get_query_embedding') else model.get_text_embedding(query)) for i, chunk in enumerate(chunks, 1): chunk_embedding = model.get_text_embedding(chunk) similarity = cosine_similarity(query_embedding, chunk_embedding) print(f"查询与文本 {i} 的相似度: {similarity:.4f}")# 准备测试数据query = "张伟是哪个部门的"chunks = [ "核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034 qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布", "组织公司活动的前期准备与后期评估,确保公司各项⼯作的顺利进⾏。 IT部 张伟 ⻢云 H802 036 IT⽀撑 IT专员 13800000036 zhangwei036@educompany.com 进⾏公司⽹络及硬件设备的配置"]# 定义要测试的嵌入模型embedding_models = { "text-embedding-v2": DashScopeEmbedding(model_name="text-embedding-v2"), "text-embedding-v3": DashScopeEmbedding(model_name="text-embedding-v3")}# 执行比较compare_embeddings(query, chunks, embedding_models)除了通过相似度对比来评估不同 Embedding 模型的效果,你还可以从实际应用的角度来评测。下面你将使用 Ragas 评测工具来对比 text-embedding-v2 和 text-embedding-v3 两个模型在 RAG 系统中的实际表现。
通过运行以下代码,你可以清晰地看到在相同的 RAG 策略下,text-embedding-v3 模型的整体效果要优于 text-embedding-v2。一起来看看具体的评测过程和结果:
def compare_embedding_models(documents, question, ground_truth, sentence_splitter): """比较不同嵌入模型在RAG中的表现 Args: documents: 文档列表 question: 查询问题 ground_truth: 标准答案 sentence_splitter: 文本分割器 """ # 文档分割 print("📑 正在处理文档...") nodes = sentence_splitter.get_nodes_from_documents(documents) # 定义要测试的嵌入模型配置 embedding_models = { "text-embedding-v2": DashScopeEmbedding( model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2 ), "text-embedding-v3": DashScopeEmbedding( model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3, embed_batch_size=6, embed_input_length=8192 ) } # 测试每个模型 for model_name, embed_model in embedding_models.items(): print(f"\n{'='*50}") print(f"🔍 正在测试 {model_name}...") print(f"{'='*50}") # 构建索引和查询引擎 index = VectorStoreIndex(nodes, embed_model=embed_model) query_engine = index.as_query_engine(streaming=True, similarity_top_k=5) # 执行查询 print(f"\n❓ 测试问题: {question}") print("\n🤖 模型回答:") response = query_engine.query(question) response.print_response_stream() # 显示召回的文档片段 print(f"\n📚 召回的参考片段:") for i, node in enumerate(response.source_nodes, 1): print(f"\n文档片段 {i}:") print("-" * 40) print(node) # 评估结果 print(f"\n📊 {model_name} 评估结果:") print("-" * 40) evaluation_score = evaluate_result(question, response, ground_truth) display(evaluation_score)# 准备测试数据documents = SimpleDirectoryReader('./docs/2_5').load_data()sentence_splitter = SentenceSplitter( chunk_size=1000, chunk_overlap=200,)# 执行比较compare_embedding_models( documents=documents, question=question, ground_truth=ground_truth, sentence_splitter=sentence_splitter)你可以看到:
-
新版本的Embedding模型通常能带来更好的效果(如text-embedding-v3比v2表现更好)
-
在实践中,单纯升级Embedding模型就可能显著提升检索质量
-
建议你首先尝试最新的 text-embedding-v3 模型,它在大多数任务上都能取得不错的效果。同时可以持续关注 DashScopeEmbedding 新模型的进展,根据实际需求选择升级到性能更好的版本。
4.3.3 选择合适的向量数据库
在构建 RAG 应用时,你有多种向量存储方案可以选择,从简单到复杂依次是:
4.3.3.1 内存向量存储
最简单的方式是使用 LlamaIndex 内置的内存向量存储。只需安装 llama-index 包,无需额外配置,就能快速开发和测试 RAG 应用:
from llama_index.core import VectorStoreIndex# 创建内存向量索引index = VectorStoreIndex.from_documents(documents)优点是快速上手,适合开发测试;缺点是数据无法持久化,且受限于内存大小。
4.3.3.2 本地向量数据库
当数据量增大时,可以使用开源的向量数据库,如 Milvus、Qdrant 等。这些数据库提供了数据持久化和高效检索能力
优点是功能完整、可控性强;缺点是需要自行部署维护。
4.3.3.3 云服务向量存储
对于生产环境,推荐使用云服务提供的向量存储能力。阿里云提供了多种选择:
-
向量检索服务(DashVector):按量付费、自动扩容,适合快速启动项目。详细功能请参考向量检索服务(DashVector)。
-
向量检索服务 Milvus 版:兼容开源 Milvus,便于迁移已有应用。详细功能请参考向量检索服务 Milvus 版。
-
已有数据库的向量能力:如果已使用阿里云数据库(RDS、PolarDB等),可直接使用其向量功能
云服务的优势在于:
-
无需关注运维,自动扩容
-
提供完善的监控和管理工具
-
按量付费,成本可控
-
支持向量 + 标量的混合检索,提升检索准确性
选择建议:
-
开发测试时使用内存向量存储
-
小规模应用可以使用本地向量数据库
-
生产环境推荐使用云服务,可根据具体需求选择合适的服务类型

4.4 检索召回阶段
检索阶段会遇到的主要问题就是,很难从众多文档切片中,找出和用户问题最相关、且包含正确答案信息的片段。
从切入时机来看,可以将解法分为两大类:
- 在执行检索前,很多用户问题描述是不完整、甚至有歧义的,你需要想办法还原用户真实意图,以便提升检索效果。
- 在执行检索后,你可能会发现存在一些无关的信息,需要想办法减少无关信息,避免干扰下一步的答案生成。
| 时机 | 改进策略 | 示例 |
|---|---|---|
| 检索前 | 问题改写 | 「附近有好吃的餐厅吗?」=> 「请推荐我附近的几家评价较高的餐厅」 |
| 问题扩写 通过增加更多信息,让检索结果更全面 | 「张伟是哪个部门的?」=> 「张伟是哪个部门的?他的联系方式、职责范围、工作目标是什么?」 | |
| 基于用户画像扩展上下文 结合用户信息、行为等数据扩写问题 | 内容工程师提问「工作注意事项」=> 「内容工程师有哪些工作注意事项」 项目经理提问「工作注意事项」=> 「项目经理有哪些工作注意事项」 | |
| 提取标签 提取标签,用于后续标签过滤+向量相似度检索 | 「内容工程师有哪些工作注意事项」=>
|
|
| 反问用户 | 「工作职责是什么」=> 大模型反问:「请问你想了解哪个岗位的工作职责」 实现反问的提示词可以参考:10分钟构建能主动提问的智能导购 | |
| 思考并规划多次检索 | 「张伟不在,可以找谁」 => 大模型思考规划: => task_1:张伟的职责是什么, task_2:${task_1_result}职责的人有谁 => 按顺序执行多次检索 | |
| ... | ... | |
| 检索后 | 重排序 ReRank + 过滤 多数向量数据库会考虑效率,牺牲一定精确度,召回的切片中可能有一些实际相关性不够高 | chunk1、chunk2...、chunk10 => chunk 2、chunk4、chunk5 |
| 滑动窗口检索 在检索到一个切片后,补充前后相邻的若干个切片。这样做的原因是:相邻切片之间往往存在语义联系,仅看单个切片可能会丢失重要信息。 滑动窗口检索确保了不会因为过度切分而丢失文本间的语义连接。 | 常见的实现是句子滑动窗口,你可以用下方的简化形式来理解: 假设原始文本为:ABCDEFG(每个字母代表一个句子) 当检索到切片:D 补充相邻切片后:BCDEF(前后各取2个切片) 这里的BC和EF是D的上下文。比如:
|
|
| ... | ... |
4.4.1 问题改写
🤔 为什么需要问题改写?
想象一下你在搜索"找张伟"或者"张伟 部门"这样的关键词。看似简单,但对于RAG系统来说,这样零散的搜索词可能不太好回答。因为在真实场景中,可能存在多个叫张伟的同事,而且用户输入的关键词往往过于简单,缺少必要的上下文信息。
question = "找张伟"✨ 问题改写能带来什么?
问题改写就像是帮助系统更好地理解用户意图。比如当你问"找张伟"时,系统可以把问题改写为更完整的形式,比如"请告诉我公司中所有叫张伟的员工及其所在部门"。这样的改写不仅能提高检索的准确性,还能让回答更加全面。
接下来,你可以通过实际案例来体验不同的问题改写策略。在这个案例中,你将使用以下配置:
- 文档:Markdown格式
- 切片:默认句子切片策略
- 模型:text-embedding-v3
- 存储:默认向量存储
# 配置嵌入模型Settings.embed_model = DashScopeEmbedding( model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3, embed_batch_size=6, embed_input_length=8192)# 加载文档documents = SimpleDirectoryReader('./docs/2_5').load_data()# 配置文档分割器sentence_splitter = SentenceSplitter( chunk_size=1000, chunk_overlap=200,)# 文档分割sentence_nodes = sentence_splitter.get_nodes_from_documents(documents)# 构建索引sentence_index = VectorStoreIndex(sentence_nodes, embed_model=Settings.embed_model)【常规方法:不改写问题,直接检索】
在你尝试问题改写之前,先看看直接使用原始问题进行检索的效果。这样的对比能让你更直观地感受问题改写带来的提升:
# 创建查询引擎query_engine = sentence_index.as_query_engine( streaming=True, similarity_top_k=5)# 执行查询print(f"❓ 用户问题: {question}\n")streaming_response = query_engine.query(question)print("\n💭 AI回答:")print("-" * 40)streaming_response.print_response_stream()print("\n")# 显示参考文档print("\n📚 参考依据:")print("-" * 40)for i, node in enumerate(streaming_response.source_nodes, 1): print(f"\n文档片段 {i}:") print(f"相关度得分: {node.score:.4f}") print("-" * 30) print(node.text)# 评估结果print("\n📊 回答质量评估:")print("-" * 40)evaluation_score = evaluate_result(question, streaming_response, ground_truth)display(evaluation_score)运行完这段代码,你可能会发现结果不太理想。虽然系统召回了5个相关片段,但并没有找到所有"张伟"的信息。这是为什么呢?
问题就出在提问方式上。当用户问"张伟是哪个部门的"时,这个问题对人来说很好理解,但对大模型来说却缺少了重要的上下文 —— 公司里不止一个张伟!这就好比你去一个有多个王老师的学校问"王老师在哪个办公室",别人一定会反问你"你说的是哪个王老师呀?"
那么,如果让问题表达得更完整一些会怎样?比如明确说明你想知道"公司里所有叫张伟的同事的部门信息"。接下来,你可以试试用大模型来改写问题,看看效果会不会更好。
【方法一:使用大模型扩充用户问题】
你可以让大模型充当一个问题改写助手。它会帮你把简单的问题改写得更加完整和清晰。比如,它不仅会考虑到可能存在多个张伟的情况,还会把相关的上下文信息都补充进去。看看具体怎么做:
query_gen_str = """\系统角色设定:你是一个专业的问题改写助手。你的任务是将用户的原始问题扩充为一个更完整、更全面的问题。规则:1. 将可能的歧义、相关概念和上下文信息整合到一个完整的问题中2. 使用括号对歧义概念进行补充说明3. 添加关键的限定词和修饰语4. 确保改写后的问题清晰且语义完整5. 对于模糊概念,在括号中列举主要可能性原始问题:{query}请生成一个综合的改写问题,确保:- 包含原始问题的核心意图- 涵盖可能的歧义解释- 使用清晰的逻辑关系词连接不同方面- 必要时使用括号补充说明输出格式:[综合改写] - 改写后的问题"""query_gen_prompt = PromptTemplate(query_gen_str)def generate_queries(query: str): response = Settings.llm.predict( query_gen_prompt, query=query ) return response# 生成扩展查询print("\n🔍 原始问题:")print(f" {question}")query = generate_queries(question)print("\n📝 扩展查询:")print(f" {query}\n")# 创建查询引擎query_engine = sentence_index.as_query_engine( streaming=True, similarity_top_k=5)# 执行查询response = query_engine.query(query)print("💭 AI回答:")print("-" * 40)response.print_response_stream()print("\n")# 显示参考文档print("\n📚 参考依据:")print("-" * 40)for i, node in enumerate(response.source_nodes, 1): print(f"\n文档片段 {i}:") print(f"相关度得分: {node.score:.4f}") print("-" * 30) print(node.text)# 评估结果print("\n📊 回答质量评估:")print("-" * 40)evaluation_score = evaluate_result(query, response, ground_truth)display(evaluation_score)运行上面的代码,你会发现经过大模型改写后的问题能够获得更好的检索效果。不过,对于某些复杂问题,仅仅改写可能还不够。
【方法二:将单一查询改写为多步骤查询】
除了改写问题,你还可以尝试另一种思路:把复杂的问题拆解成简单的步骤。LlamaIndex 提供了两个强大的工具来实现这个功能:
- StepDecomposeQueryTransform: 这个工具可以帮你把一个复杂问题分解成多个子问题。比如对于"张伟是哪个部门的?",它会先分解为:
- “公司里有几个叫张伟的员工?”
- “这些张伟分别在哪些部门?”
这样可以更全面地获取所有张伟的信息。
- MultiStepQueryEngine: 这个查询引擎会按顺序处理这些子问题。它会先获取公司所有张伟的信息,然后再查询每个张伟的部门信息,最终将答案整合成一个完整的回应,告诉用户"公司有三名张伟,分别在教研部、课程开发部和IT部"。
这种方法就像解决数学题一样 - 把大问题分解成小问题往往更容易得到准确的答案。不过要注意,这种方法会多次调用大模型,所以会消耗更多的token。
from llama_index.core.indices.query.query_transform.base import ( StepDecomposeQueryTransform,)step_decompose_transform = StepDecomposeQueryTransform(verbose=True)# set Logging to DEBUG for more detailed outputsfrom llama_index.core.query_engine import MultiStepQueryEnginequery_engine = sentence_index.as_query_engine(streaming=True,similarity_top_k=5)query_engine = MultiStepQueryEngine( query_engine=query_engine, query_transform=step_decompose_transform, index_summary="公司人员信息")print(f"❓ 用户问题: {question}\n")print("🤖 AI正在进行多步查询...")response = query_engine.query(question)print("\n📚 参考依据:")print("-" * 40)for i, node in enumerate(response.source_nodes, 1): print(f"\n文档片段 {i}:") print("-" * 30) print(node.text)# 评估结果print("\n📊 多步查询评估结果:")print("-" * 40)evaluation_score = evaluate_result(question, response, ground_truth)display(evaluation_score)通过这种方式,系统会先理解问题的整体目标,然后把它分解成几个小步骤来逐一解决。比如对于"张伟是哪个部门的"这个问题,系统可能会先找到所有的张伟,然后再分别查询他们的部门信息。
【方法三:用假设文档来增强检索(HyDE)】
前面的方法都是在调整问题本身,现在让我们换个思路:如果我们先假设一个可能的答案会怎样?这就是HyDE(Hypothetical Document Embeddings)方法的独特之处。
它的工作方式很有趣:
- 先让大模型基于问题编一个"假想的答案文档"
- 用这个假想文档来检索真实文档
- 最后用检索到的真实文档来生成实际答案
这就像你在找一本书时,心里已经有了一个大致的内容轮廓,然后用这个轮廓去图书馆匹配相似的书籍。让我们看看具体怎么实现:
from llama_index.core.indices.query.query_transform.base import ( HyDEQueryTransform,)from llama_index.core.query_engine import TransformQueryEngine# run query with HyDE query transformhyde = HyDEQueryTransform(include_original=True)query_engine = sentence_index.as_query_engine(streaming=True,similarity_top_k=5)query_engine = TransformQueryEngine(query_engine, query_transform=hyde)print(f"❓ 用户问题: {question}\n")print("🤖 AI正在通过 HyDE 分析...")streaming_response = query_engine.query(question)print("\n💭 AI回答:")print("-" * 40)streaming_response.print_response_stream()# 显示参考文档print("\n📚 参考依据:")print("-" * 40)for i, node in enumerate(streaming_response.source_nodes, 1): print(f"\n文档片段 {i}:") print("-" * 30) print(node.text)# 评估结果print("\n📊 HyDE 查询评估结果:")print("-" * 40)evaluation_score = evaluate_result(question, streaming_response, ground_truth)display(evaluation_score)从评测结果可以看到,这种方法确实带来了一些改善。你可能会好奇:系统是如何生成这个"假想文档"的呢?一起来看看这个过程中,AI实际生成了什么内容:
query_bundle = hyde(question)hyde_doc = query_bundle.embedding_strs[0]print(f"🤖 AI生成的假想文档:\n{hyde_doc}\n")有趣的是,虽然这个"假想文档"完全是AI编造的,但它的结构和风格与真实的公司员工信息非常相似。LlamaIndex提供了灵活的控制机制来优化这个过程:
HyDEQueryTransform类允许我们通过以下方式精确控制假想文档的生成:
- 自定义LLM:通过llm参数传入不同的大模型配置,可以选择更适合的语言模型来生成假想文档
- 提示词模板:通过hyde_prompt参数自定义提示词模板,精确控制输出的格式和内容
- 查询策略:使用include_original参数决定是否将原始查询与假想文档结合使用
TransformQueryEngine则作为查询引擎的包装器,它会:
- 先调用HyDEQueryTransform生成假想文档
- 使用假想文档进行向量检索
- 最后返回查询结果
这种架构让我们能在不修改底层查询引擎的情况下,通过调整HyDEQueryTransform的参数来优化检索效果。即使假想文档的具体内容可能不够准确,但通过精心设计的配置,它可以帮助系统更准确地检索相关信息。
4.4.2 提取标签增强检索
在向量检索的基础上,我们还可以添加标签过滤来提升检索精度。这种方式类似于图书馆既有书名检索,又有分类编号系统,能让检索更精准。
标签提取有两个关键场景:
- 建立索引时,从文档切片中提取结构化标签
- 检索时,从用户问题中提取对应的标签进行过滤
让我们看两个例子来理解如何从不同类型的文本中提取标签:
import osfrom openai import OpenAIclient = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")system_message = """你是一个标签提取专家。请从文本中提取结构化信息,并按要求输出标签。---【支持的标签类型】- 人名- 部门名称- 职位名称- 技术领域- 产品名称---【输出要求】1. 请用 JSON 格式输出,如:[{"key": "部门名称", "value": "教研部"}]2. 如果某类标签未识别到,则不输出该类---待分析文本如下:"""def extract_tags(text): completion = client.chat.completions.create( model="qwen-turbo", messages=[ {'role': 'system', 'content': system_message}, {'role': 'user', 'content': text} ], response_format={"type": "json_object"} ) return completion.choices[0].message.content# 示例1:人事文档hr_text = """张明是我们AI研发部的技术主管,他带领团队开发了新一代智能对话平台 ChatMax,在自然语言处理领域有着丰富经验。如果您需要了解项目细节,可以直接联系他。"""print("人事文档标签提取结果:")print(extract_tags(hr_text))# 示例2:技术文档tech_text = """本论文提出了一种基于深度学习的图像识别算法,在医疗影像分析中取得了突破性进展。该算法已在北京协和医院的CT诊断系统中得到应用。"""print("\n技术文档标签提取结果:")print(extract_tags(tech_text))当我们建立索引时,可以将这些标签与文档切片一起存储。这样在检索时,比如用户问"张伟是哪个部门的",我们可以:
- 从问题中提取人名标签 {“key”: “人名”, “value”: “张伟”}
- 先用标签过滤出所有包含"张伟"的文档切片
- 再用向量相似度检索找出最相关的内容
这种"标签过滤+向量检索"的组合方式,能大幅提升检索的准确性。特别是在处理结构化程度较高的企业文档时,这个方法效果更好。
4.4.3 重排序
你可以删除前面构建的 markdown 文件,来复现本章节最开始回答不好「张伟是哪个部门的」的状态。
![ -f ./docs/内容公司各部门职责与关键角色联系信息汇总.md ] && rm ./docs/内容公司各部门职责与关键角色联系信息汇总.md && echo "文件已删除。" || echo "文件不存在,无需删除。"删除文件后,可以执行下面的代码。可以看到,你设置了从向量数据库中检索召回 3 条相关的文档切片。
从结果上来看,这 3 条切片,事实上不够相关,问答机器人无法正确回答「张伟是哪个部门的」。
from llama_index.llms.dashscope import DashScopefrom chatbot import ragindex = rag.create_index('./docs')query_engine = index.as_query_engine( similarity_top_k=3, streaming=True,)response = ask("张伟是哪个部门的", query_engine=query_engine)display(evaluate_result(question, response, ground_truth))你可以调整代码,先从向量数据库中检索召回 20 条文档切片,再借助阿里云百炼提供的文本排序模型进行重排序,并且筛选出其中最相关的 3 条参考信息。
运行代码后你可以看到,同样是 3 条参考信息,这次大模型能够准确回答问题了。
from llama_index.postprocessor.dashscope_rerank import DashScopeRerankfrom llama_index.core.postprocessor import SimilarityPostprocessorquery_engine = index.as_query_engine( # 先设置一个较大的召回切片数量 similarity_top_k=20, streaming=True, node_postprocessors=[ # 在rerank 模型中选择你最终想召回的切片个数,重排模型选择通义实验室的gte-rerank模型 DashScopeRerank(top_n=3, model="gte-rerank"), # 设置一个相似度阈值,低于该阈值的切片会被过滤掉 SimilarityPostprocessor(similarity_cutoff=0.2) ])response = ask("张伟是哪个部门的", query_engine=query_engine)display(evaluate_result(question, response, ground_truth))from llama_index.llms.openai_like import OpenAILikefrom llama_index.core import Settingsimport os# 事实查询场景 - 低温度、高确定性factual_llm = OpenAILike( model="qwen-plus", # 使用通义千问-Plus模型 api_base="https://dashscope.aliyuncs.com/compatible-mode/v1", api_key=os.getenv("DASHSCOPE_API_KEY"), is_chat_model=True, temperature=0.1, # 降低temperature使输出更确定性 max_tokens=512, # 控制输出长度,但是若max_tokens过小,可能会导致输出截断 presence_penalty=0.0, # 默认presence_penalty seed=42 # 固定seed使输出可重现)# 创造性场景 - 高温度、更多样化creative_llm = OpenAILike( model="qwen-plus", api_base="https://dashscope.aliyuncs.com/compatible-mode/v1", api_key=os.getenv("DASHSCOPE_API_KEY"), is_chat_model=True, temperature=0.7, # 提高temperature使输出更有创造性 max_tokens=1024, # 允许更长的输出 presence_penalty=0.6 # 提高presence_penalty减少重复)- 调优大模型:如果上述方法都做了充分的尝试,仍然不及预期,或者希望有更进一步的效果提升,你也可以尝试面向你的场景调优一个模型。在后续的章节中,你将学习和实践这一点。
✅ 本节小结
通过前面的学习,你已经了解了一个简单 RAG 的工作流程,以及常见优化手段。你也可以结合前面学习到的知识,结合实际需求,将不同的问题,路由到不同的 RAG 应用中,以构建一个能力更强大的模块化 RAG 应用。此外,通过前面的学习,你应该也能发现,大模型不只是可以用于构建问答系统。借助大模型识别用户意图、提取结构化信息(比如前面的根据用户问题提取标签),也能在很多其他应用场景中发挥作用。
当然,RAG 的优化手段远不止课程中介绍的这些,业内关于 RAG 的研究和探索也在持续进行,还有很多高级 RAG 课题值得你去学习。从前面的学习可以看到,构建一个完善、表现得足够好的 RAG 应用并不简单。而在实际工作中,你可能需要更快地捕捉业务机会,没有时间投入到这些细节完善中。以下是一些值得探索的方向:
-
GraphRAG 技术巧妙地结合了检索增强生成(RAG)和查询聚焦摘要(QFS)的优点,为处理大规模文本数据提供了一个强大的解决方案。它把两种技术的特长融合在一起:RAG 擅长找出精确的细节信息,而 QFS 则更善于理解和总结文章的整体内容。通过这种结合,GraphRAG 既能准确回答具体问题,又能处理需要深入理解的复杂查询,特别适合用来构建智能问答系统。
如果你想深入了解如何实际运用 GraphRAG,可以参考 LlamaIndex 提供的详细教程:使用 LlamaIndex 构建 GraphRAG 应用。 -
借助百炼,你可以参考 0代码构建私有知识问答应用 这篇文档快速构建一个效果不错的 RAG 应用。
-
如果你的业务流程比较复杂,也可以借助百炼上的 可视化工作流、智能体编排,来构建一个更强大的应用。
-
同时,百炼也提供了一系列 LlamaIndex 组件,方便你充分利用百炼能力的同时,可以继续使用熟悉的 LlamaIndex API 构建 RAG 应用。
🔥 课后小测验
🔍 单选题
在RAG应用中,文档切片的长度和内容对检索效果有很大影响。如果文档切片长度过大,导致引入过多的干扰信息,应该如何处理❓
- A. 增加文档的数量
- B. 减少切片长度,或根据业务特点开发更合理的切片策略
- C. 使用更高级的检索算法
- D. 提升大模型的训练水平
【点击查看答案】
✅ 参考答案:B
📝 解析:
- 文档切片过长会导致单个片段包含过多无关信息(噪声),直接影响检索精度。
- 例如,若一个切片包含多个主题,检索时可能召回与当前问题无关的内容。
- 优化切片策略是解决干扰信息的根本方法,直接控制输入质量,而非依赖后续算法或模型的补偿
# 导入所需的依赖包from config.load_key import load_keyimport os# 加载API密钥load_key()# 生产环境中请勿将 API Key 输出到日志中,避免泄露print(f'''你配置的 API Key 是:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}''')from fontTools.ttLib.tables.ttProgram import instructionsfrom chatbot import rag# 上一章节已经建立了索引,因此这里可以直接加载索引。如果需要重建索引,可以增加一行代码:rag.indexing()index = rag.load_index()query_engine = rag.create_query_engine(index=index)rag.ask('张三的HR明天想请个假', query_engine=query_engine)从上面的示例中你会发现当前大模型只是文本输入输出的问答系统无法和外界交互。

为了解决这个问题,你可以为答疑机器人引入一种新能力:动态解析用户需求并采取相应行动。例如,为了让问答机器人能够帮助用户请假,你需要让大模型解析用户的需求,并调用相应的API(如请假API)。这正是智能体应用的核心思想——通过任务分解和自动化执行,智能体能够高效地响应并完成复杂的操作。
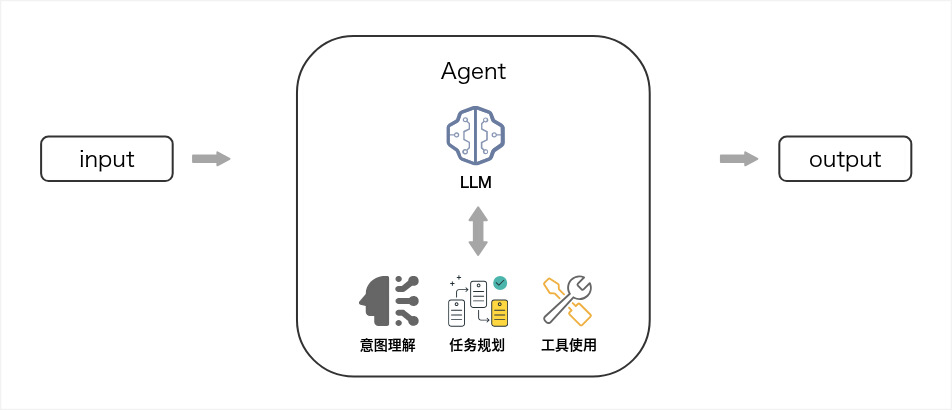
2.如何构建 Agent
通常来说构建一个智能体分为以下步骤,你将如下图所示一步步完成一个智能体的构建。

2.1明确目标
“不谋全局者,不足谋一域。” —— 在任何复杂任务中,明确目标都是迈向成功的第一步。正如绘制一张地图需要先确定目的地,在构建答疑机器人时,你也需要先清晰地定义任务的核心目标。
你想要答疑机器人能够从公司的私有数据库中查询员工信息,并能够帮助用户完成请假申请的同时在数据库中进行记录与更新。
所以你的第一个目标是:将用户所有对公司内人员信息类型的提问转化为数据库查询的工具函数。 具体而言,这包括:
- 将用户输入的自然语言问题转化为对应的 SQL 查询语句(即 NL2SQL,自然语言转 SQL)。
- 使用生成的 SQL 查询语句访问数据库,获取对应的查询结果。
- 将查询结果作为工具函数的输出,最终返回给用户。
2.2定义工具函数
接下来,在配置好环境变量后你就可以开始搭建一个Agent智能体了。
当然,从零来构建一个Agent需要处理复杂的底层实现,这往往需要大量的时间和精力,因此你可以使用 Assistant API 来帮助你更高效地构建 Agent。
Assistant API 是一种简化智能体应用创建过程的接口。它提供了丰富的功能,包括支持多种基础模型、灵活的工具调用、对话管理和高度可扩展性。
通过 Assistant API,你可以专注于智能体的核心功能,而不需要处理繁琐的底层实现。
首先你需要定义一些工具函数,假设你的答疑机器人需要有从数据库查询员工信息的功能。
为了帮助你更多地关注到Agent的内容,你需要模拟一个查询步骤,而不实际去数据库中查询。
假设员工表名为employee,字段包括department(部门)、name(姓名)、HR。
如果你希望继续提升大模型NL2SQL的性能,请前往微调教程学习。
# 导入依赖from llama_index.llms.dashscope import DashScopefrom llama_index.core.base.llms.types import MessageRole, ChatMessageimport re # 导入正则表达式库,用于处理空格def normalize_sql(sql_string): ''' 对SQL语句进行标准化处理,以方便比较。 ''' # 1. 转换为小写 s = sql_string.lower() # 2. 移除首尾空格 s = s.strip() # 3. 移除末尾的分号 if s.endswith(';'): s = s[:-1] # 4. (可选但推荐) 将多个空格替换为单个空格 s = re.sub(r'\s+', ' ', s) return s# 定义一个员工查询函数def query_employee_info(query): ''' 输入用户提问,输出员工信息查询结果 ''' # 1. 首先根据用户提问,使用NL2SQL生成SQL语句 llm = DashScope(model_name="qwen-plus") messages = [ ChatMessage(role=MessageRole.SYSTEM, content='''你有一个表叫employees,记录公司的员工信息,这个表有department(某部门)、name(姓名)、HR三个字段。 你需要根据用户输入生成sql语句进行查询,只生成sql语句,不需要生成sql语句之外的内容,也不要把```sql```这个标签加上。'''), ChatMessage(role=MessageRole.USER, content=query) ] SQL_output_raw = llm.chat(messages).message.content # 对大模型输出的SQL进行标准化 SQL_output_normalized = normalize_sql(SQL_output_raw) # 打印出原始和标准化后的SQL语句 print(f'原始SQL语句为:{SQL_output_raw}') print(f'标准化后SQL语句为:{SQL_output_normalized}') # 2. 根据标准化后的SQL语句去查询数据库(此处为模拟查询),并返回结果 # 注意:我们的比较目标也应该是标准化的字符串 if SQL_output_normalized == "select count(*) from employees where department = '教育部门'": return "教育部门共有66名员工。" if SQL_output_normalized == "select hr from employees where name = '张三'": return "张三的HR是李四。" if SQL_output_normalized == "select department from employees where name = '王五'": return "王五的部门是后勤部。" else: return "抱歉,我暂时无法回答您的问题。"# 测试一下这个函数result = query_employee_info("教育部门有几个人")print(f"查询结果: {result}")result = query_employee_info("张三的HR是谁")print(f"查询结果: {result}")2.3将工具函数与大模型集成进Agent中
你已经定义好了工具函数,接下来就要将它们与大模型通过Assistant API集成到Agent中。
通过Assistants.create方法,你可以创建一个新的Agent,并通过model(模型名称)、name(Agent命名)、description(Agent的描述信息)、instructions(Agent非常重要的参数,用于提示Agent所具有的工具函数能力,同时也可以规范输出格式)、tools(工具函数通过该参数传入)参数来定义Agent。
其中,tools参数中的function.name用于指定工具函数,但需要为字符串格式,因此可以通过一个map方法映射到工具函数上。
# 引入依赖from dashscope import Assistants, Messages, Runs, Threadsimport json# 定义公司小蜜ChatAssistant = Assistants.create( # 在此指定模型名称 model="qwen-plus", # 在此指定Agent名称 name='公司小蜜', # 在此指定Agent的描述信息 description='一个智能助手,能够查询员工信息,帮助员工发送请假申请,或者查询公司规章制度。', # 用于提示大模型所具有的工具函数能力,也可以规范输出格式 instructions='''你是公司小蜜,你的功能有以下三个: 1. 查询员工信息。例如:查询员工张三的HR是谁; 2. 发送请假申请。例如:当员工提出要请假时,你可以在系统里帮他完成请假申请的发送; 3. 查询公司规章制度。例如:我们公司项目管理的工具是什么? 请准确判断需要调用哪个工具,并礼貌回答用户的提问。 ''', # 将工具函数传入 tools=[ { # 定义工具函数类型,一般设置为function即可 'type': 'function', 'function': { # 定义工具函数名称,通过map方法映射到query_employee_info函数 'name': '查询员工信息', # 定义工具函数的描述信息,Agent主要根据description来判断是否需要调用该工具函数 'description': '当需要查询员工信息时非常有用,比如查询员工张三的HR是谁,查询教育部门总人数等。', # 定义工具函数的参数 'parameters': { 'type': 'object', 'properties': { # 将用户的提问作为输入参数 'query': { 'type': 'str', # 对输入参数的描述 'description': '用户的提问。' }, }, # 在此声明该工具函数需要哪些必填参数 'required': ['query']}, } } ])print(f'{ChatAssistant.name}创建完成')# 建立Agent Function name与工具函数的映射关系function_mapper = { "查询员工信息": query_employee_info}print('工具函数与function.name映射关系建立完成')同时,你还可以封装一个辅助函数get_agent_response。
这段代码的功能是:当用户向智能体发出请求时,智能体通过 get_agent_response() 发送请求并获取响应。如果任务需要调用外部工具(如数据库查询),则智能体会根据工具函数的映射执行相应的操作,并将结果返回给用户。这使得智能体能够处理更复杂的任务,而不仅仅是简单的问答。
通过Assistant API获得Agent回复的过程需要涉及到如thread、message、run等概念,如果你对这些概念与细节感兴趣,请参考阿里云Assistant API官方文档。
如果你希望给Agent配备更多的能力,可以添加工具函数,并在function_mapper与tools中建立映射关系。
# 输入message信息,输出为指定Agent的回复def get_agent_response(assistant, message=''): # 创建一个新的会话线程 thread = Threads.create() # 创建一条消息并发送到该会话线程 message = Messages.create(thread.id, content=message) # 创建一个运行实例(运行请求),将会话线程与Assistant(智能体)关联起来 run = Runs.create(thread.id, assistant_id=assistant.id) # 等待运行完成,检查任务是否完成 run_status = Runs.wait(run.id, thread_id=thread.id) # 如果任务运行失败,则输出错误信息 if run_status.status == 'failed': print('run failed:') # 如果需要工具来辅助模型进行操作(如查询数据库、发送请求等) if run_status.required_action: # 获取需要调用的工具函数的详细信息 f = run_status.required_action.submit_tool_outputs.tool_calls[0].function # 获取工具函数的名称(function name) func_name = f['name'] # 获取调用工具函数时需要的输入参数 param = json.loads(f['arguments']) # 打印出工具的名称和参数信息 print("function is", f) # 根据工具函数的名称,通过一个映射(function_mapper)找到对应的实际工具函数 # 这里使用了一个字典映射(function_mapper),它将工具函数名称与具体的函数对应 if func_name in function_mapper: # 使用映射找到实际工具函数并传递参数,获取结果 output = function_mapper[func_name](**param) else: # 如果找不到对应的函数,输出为空 output = "" # 将工具函数的输出(结果)准备提交 tool_outputs = [{ 'output': output }] # 提交工具的输出结果回给运行实例 run = Runs.submit_tool_outputs(run.id, thread_id=thread.id, tool_outputs=tool_outputs) # 等待运行完成 run_status = Runs.wait(run.id, thread_id=thread.id) # 获取最终的运行结果 run_status = Runs.get(run.id, thread_id=thread.id) # 获取消息记录列表 msgs = Messages.list(thread.id) # 返回Agent的回复内容 return msgs['data'][0]['content'][0]['text']['value']2.4尝试对话
你已经完成了一个简单的单Agent系统构建,在正式投入使用之前测试是必不可少的一环,你可以尝试与答疑机器人进行对话:
query_stk = [ "谁是张三的HR?", "教育部门一共有多少员工?", "王五在哪个部门?",]for query in query_stk: print("提问是:") print(query) print("思考过程与最终输出是:") print(get_agent_response(ChatAssistant,query)) print("\n")从测试结果可以看出,拓展了功能之后的答疑机器人达到了你预期的效果。
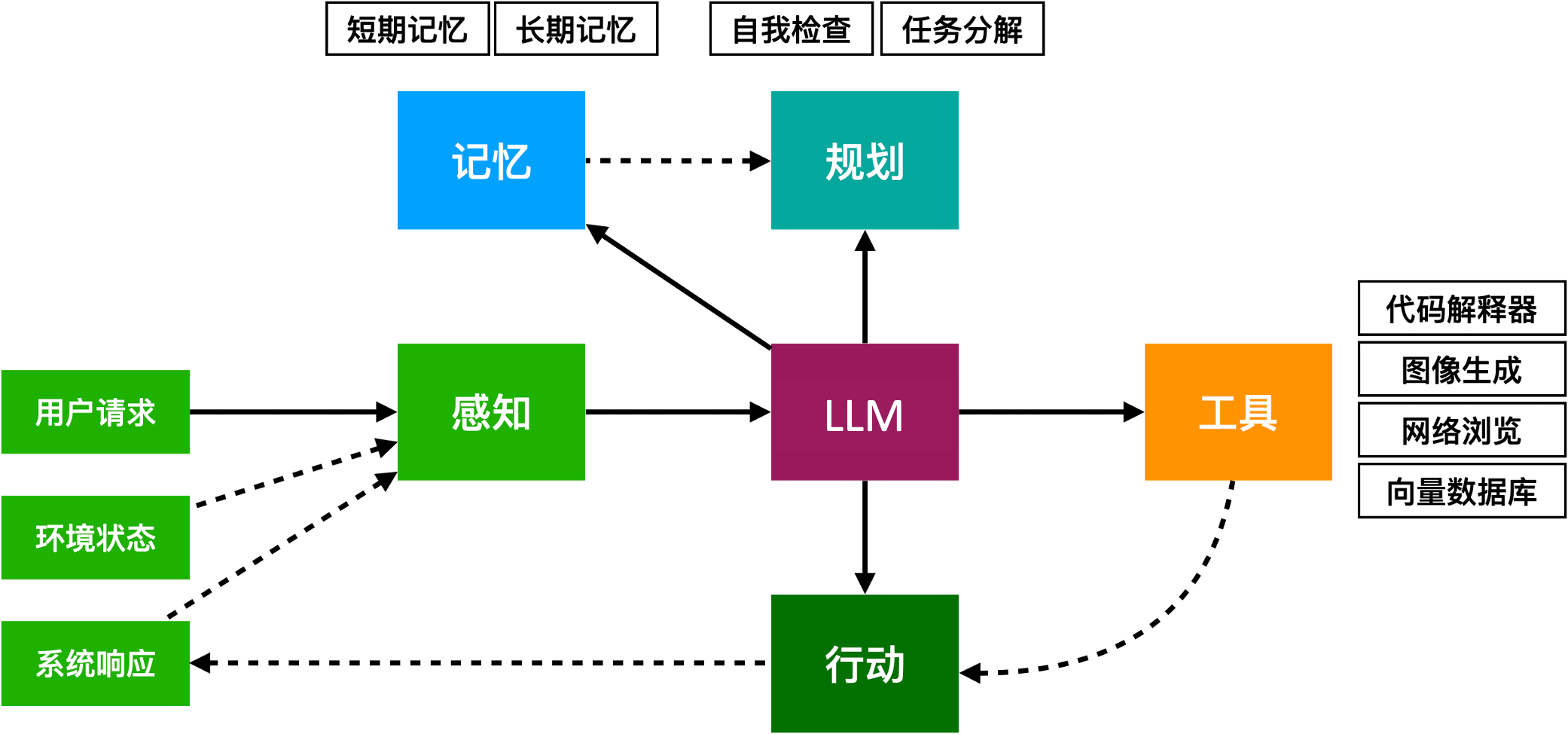
在实际应用中,智能体不仅可以与外界交互,还能通过不同的模块化设计来增强其处理复杂任务的能力。智能体的工作原理可以从以下几个核心模块进行理解:
-
工具模块
工具模块负责定义和管理智能体能够使用的各种工具。包括工具的描述、参数以及功能特性。这一模块确保智能体能够理解并有效使用这些工具来完成任务。
-
记忆模块
记忆模块可以分为长期记忆和短期记忆。
长期记忆用于存储持久的信息和经验,帮助智能体进行模式学习、知识积累和个性化服务。
短期记忆则用于临时存储当前任务相关的信息,以支持智能体在任务执行过程中实时调整决策。
-
计划能力
计划能力模块负责任务的规划。通过智能体的决策能力,这部分帮助智能体分解复杂任务,制定具体的行动步骤和策略,确保任务顺利完成。
-
行动能力
行动能力与工具模块紧密配合,确保智能体能够选择合适的工具,并通过容器执行相应的操作。行动能力是智能体实现任务的核心,确保其能够根据既定计划和决策,有效地实施各项任务。
通过这些模块的协作,智能体能够处理复杂任务,提升任务执行的效率和精准度,突破传统方法的局限。
如果你对这些概念感兴趣,请参考阿里云大模型ACA课程与本章节拓展阅读部分。
3. 使用大模型进行意图识别
在上一节中,你已经成功构建了一个具备使用工具能力的初步智能体(Agent),这比单纯的 RAG 问答机器人又进了一大步。然而,当前的智能体仍然很简单,它只会假定用户的每一个问题都应该由它所拥有的工具(查询员工信息)来处理。如果用户提出了一个完全不同类型的请求,比如,让机器人帮忙检查一句话有没有语病,这时会发生什么呢?
试着做一个直观的实验。假设一位同事想让你开发的机器人帮忙检查一下文档里的某句话有没有语病:
from chatbot import rag# 看看当机器人遇到一个非知识问答类请求时会发生什么rag.ask('请帮我审查下这句话:技术内容工程师需要设计和开发⾼质量的教育教材和课程吗?', query_engine=query_engine)预期输出(示例)
是的,根据提供的上下文信息,技术内容工程师的核心职责之一就是设计和开发高质量的教育教材和课程。这包括撰写教学大纲、制作课件和设计评估工具等,以确保内容符合教育标准和学习目标。
看到这个结果,你可能会感到困惑。机器人并没有“审查”这句话,而是直接“回答”了这个问题。它为什么会犯这样的错误?
还记得 RAG 工作流程吗?机器人会先从知识库里检索与问题相关的内容。在这个例子中,它找到了以下信息:
片段: 内容开发工程师 …
- 内容研究与分析 对最新的教育技术趋势、学习理论和市场需求进行深入研究。这包括分析竞争对手的产品,评估现有教育资源的有效性,并探索如何将新兴技术(如人工智能、虚拟现实等)整合进我们的教育内容中。通过持续的市场调研,我能够确保我们的内容在技术上始终处于前沿,并能够满足教育者和学习者的真实需求。
- 教材和课程开发 根据研究和市场反馈,我将设计和开发高质量的教育教材和课程。这包括撰写教学大纲、制作课件、设计评估工具等。我的职责还包括确保内容符合教育标准和学习目标,以提供全面的学习体验。同时,我会考虑不同学习者的需求,确保内容能够适应各种学习风格和水平。 …
现在,问题清晰了。RAG 流程忠实地完成了它的任务——它在你的问题中看到了“技术内容工程师”这个关键词,并成功地从知识库中检索到了相关的职责描述。然后,大模型基于这些信息,给出了一个内容正确、但完全“答非所问”的答案。
怎么解决这个问题呢?
你可以退一步思考。如果你是这个机器人,你会怎么做?你可能会先判断一下:“用户这次是想让我回答问题,还是想让我检查语法?”
这个“判断”的动作,就是解决问题的关键。你可以让大模型自己来做这个判断!
试试这个最直观的思路:在处理用户请求之前,先用一个简单的提示词让大模型判断用户的意图。
from chatbot import rag, llm# 引入一个“意图判断”步骤question = "请帮我审查下这句话:技术内容工程师需要设计和开发⾼质量的教育教材和课程吗?"# 第一步:判断用户意图# 用一个简单的提示词让大模型做一个二选一的判断intent_prompt = f"""用户的请求是关于“知识库问答”还是“文本审查”?请只回答类别名称。用户请求:{question}"""intent = llm.invoke(intent_prompt)print(f"识别到的用户意图是:{intent}")# 第二步:根据意图选择不同的处理方式# 问题属于文档审查,不使用RAGif "文本审查" in intent: print("意图是文本审查,将不使用 RAG,直接调用大模型进行审查...") llm.invoke_with_stream_log(question)else: print("意图是知识库问答,将使用 RAG...") rag.ask(question, query_engine)预期输出(示例)
识别到的用户意图是:文本审查
意图是文本审查,将不使用 RAG,直接调用大模型进行审查…
这句话基本上是正确的,但可以稍微调整一下,使其更加流畅和准确。你可以这样表达:
“技术内容工程师是否需要设计和开发高质量的教育教材和课程?”
通过这个简单的代码实验,你亲手实现了一个更智能的工作流程。这里并没有引入什么复杂的技术,只是在流程中增加了一个判断步骤,就让机器人学会了“看情况办事”。
这个识别用户真实目的的过程,在行业内有一个专门的术语,叫做 意图识别(Intent Recognition)。
你可以把意图识别想象成一个智能客服前台。当客户走近时,前台不会立刻把公司手册丢给他,而是会先问:“您好,请问有什么可以帮您?” 根据客户的回答(意图),前台再决定是引导他去编辑部、销售部,还是仅仅回答一个简单的问题。
这正是 2.1 章提到的 上下文工程(Context Engineering) 的一个更深层次的应用。回顾一下:
- 通过 RAG 添加知识,是你为大模型填充上下文,解决它“不知道”的问题。
- 通过意图识别,你开始控制上下文,决定在何时、何种情况下、填充什么样的上下文(甚至不填充)。
你正在从一个单纯的“信息投喂员”,转变为一个能够设计和指挥复杂工作流的“总工程师”。通过为不同的意图设计不同的处理流程,你可以让你的应用更高效、更节省成本,并且极大地减少因信息干扰而导致的“答非所问”。
在接下来的内容中,你将了解系统化的思路,构建一个更强大的意图识别路由器,让你的答疑机器人能够处理更多样的任务。
from chatbot import llm # 构建提示词prompt = '''【角色背景】你是一个问题分类路由器,负责判断用户问题的类型,并将其归入下列三类之一:1. 公司内部文档查询2. 内容翻译3. 文档审查【任务要求】你的任务是根据用户的输入内容,判断其意图并仅选择一个最贴切的分类。请仅输出分类名称,不需要多余的解释。判断依据如下:- 如果问题涉及公司政策、流程、内部工具或职位描述与职责等内容,选择“公司内部文档查询”。- 如果问题涉及任意一门非中文的语言,且输入中出现任何外语或“翻译”等字眼,选择“内容翻译”。- 如果问题涉及检查或总结外部文档或链接内容,选择“文档审查”。- 用户的前后输入与问题分类并没有任何关系,请单独为每次对话考虑分类类别。【Few-shot 示例】示例1:用户输入:“我们公司内部有哪些常用的项目管理工具?”分类:公司内部文档查询示例2:用户输入:“请翻译下列句子:How can we finish the assignment on time?”分类:内容翻译示例3:用户输入:“请审查下这个链接下的文档:https://help.aliyun.com/zh/model-studio/user-guide/long-context-qwen-long”分类:文档审查示例4:用户输入:“请审查以下内容:技术内容工程师需要设计和开发⾼质量的教育教材和课程吗?”分类:文档审查示例5:用户输入:“技术内容工程师核心职责是什么?”分类:公司内部文档查询【用户输入】以下是用户的输入,请判断分类:'''# 获取问题的类型def get_question_type(question): return llm.invoke(prompt + question)print(get_question_type('https://www.promptingguide.ai/zh/techniques/fewshot'),'\n')print(get_question_type('That is a big one I dont know why'),'\n')print(get_question_type('作为技术内容工程师有什么需要注意的吗?'),'\n')通过明确的输出格式和 few-shot 示例,答疑机器人可以更准确地识别问题类型并输出符合预期的格式。这种优化让分类任务更加标准化,为接下来添加意图识别到答疑机器人中打下了基础。
3.2 将意图识别应用到答疑机器人中
对用户的问题进行意图识别后,你就可以让答疑机器人先识别问题的类型,再使用不同的提示词和工作流程来回答问题。
def ask_llm_route(question): question_type = get_question_type(question) print(f'问题:{question}\n类型:{question_type}') reviewer_prompt = """ 【角色背景】 你是文档纠错专家,负责找出文档中或网页内容的明显错误 【任务要求】 - 你需要言简意赅的回复。 - 如果没有明显问题,请直接回复没有问题\n 【输入如下】\n""" translator_prompt = """ 【任务要求】 你是一名翻译专家,你要识别不同语言的文本,并翻译为中文。 【输入如下】\n""" if question_type == '文档审查': return llm.invoke(reviewer_prompt + question) elif question_type == '公司内部文档查询': return rag.ask(question, query_engine=query_engine) elif question_type == '内容翻译': return llm.invoke(translator_prompt + question) else: return "未能识别问题类型,请重新输入。"query_engine =rag.create_query_engine(index=rag.load_index())# 问题1print(ask_llm_route('https://www.promptingguide.ai/zh/techniques/fewshot'),'\n')# 问题2print(ask_llm_route('请帮我检查下这段文档:技术内容工程师有需要进行内容优化与更新与跨部门合作吗?'),'\n')# 问题3print(ask_llm_route('技术内容工程师有需要进行内容优化与更新与跨部门合作吗?'),'\n')# 问题4:print(ask_llm_route('A true master always carries the heart of a student.'),'\n')从上述实验中可以看出,通过引入意图识别这一步骤,我们的答疑机器人变得更加智能。这正是上下文工程中“控制流”设计的体现。它不再是一个简单的“提问-检索-回答”的线性流程,而是根据任务类型动态地调整其行为。这样做的好处是显而易见的:
- 节省资源:对于检查文档错误的问题,大模型其实可以直接回复,并不需要检索参考资料,之前的实现存在资源浪费。
- 避免误解:之前的实现每次会检索参考资料,这些被召回的相关文本段可能会干扰大模型理解问题,导致答非所问。
我们刚刚构建的意图识别模块,本质上是一个简单的“路由器”,它决定了用户的请求应该走哪条处理路径。这种路由和规划的思想,是更高级智能体系统的核心。现在你已经了解了如何应对不同类型的任务,让我们回到最初的工具型智能体,看看如何处理需要组合使用多个工具的更复杂的任务。这将引导我们进入多智能体(Multi-Agent)系统的世界。
4.多智能体Multi-Agent
当完成员工信息的查询后,接下来你还需要对员工请假申请进行申请与记录,所以你需要再加一个新的工具函数以满足此需求。
这个工具函数将员工输入的请假日期作为输入参数,并返回一个申请成功的字符串。为了帮助你更多地关注到Agent的内容,下方的示例模拟了请假申请步骤,而没有实际去公司系统中提交请假申请。
def send_leave_application(date): ''' 输入请假时间,输出请假申请发送结果 ''' return f'已为你发送请假申请,请假日期是{date}。'# 测试一下这个函数print(send_leave_application("明后两天"))在确定新的工具函数正常工作后,你需要将这个新函数集成进你之前创建的agent中:
new_tool = {'type': 'function', 'function': { 'name': '发送请假申请', 'description': '当需要帮助员工发送请假申请时非常有用。', 'parameters': { 'type': 'object', 'properties': { # 需要请假的时间 'date': { 'type': 'str', 'description': '员工想要请假的时间。' }, }, 'required': ['date']}, } }ChatAssistant.tools.append(new_tool)function_mapper["发送请假申请"] = send_leave_applicationprint('请假工具函数与function.name映射关系建立完成')在确认集成成功后,你可以来测试一下模型的输出效果以确保一切功能正常运作:
get_agent_response(ChatAssistant,"张三的HR是谁?给他请三天假")通过上面的输出结果,你会发现在处理复杂任务时,特别是当机器人需要在一个请求中执行多个操作时,单个智能体可能无法有效完成所有子任务。
例如,用户请求“张三的HR是谁?给他请三天假”,这就涉及到员工信息查询和请假申请两个操作。单个智能体通常只能处理一种任务,无法同时调动多个工具或API接口来完成所有子任务。
为了克服这种多操作需求的局限性,你可以为答疑机器人引入一种新能力:将任务拆解成多个独立的模块进行处理,而多智能体系统正是为此而生。
多智能体系统通过将任务拆解成多个子任务,并由不同的智能体分别处理这些任务,从而克服了单一智能体无法同时完成多个操作的局限性。每个智能体专注于一个特定任务,像一个团队中的成员,各司其职,最终协作完成整个任务。
这种设计不仅能够提高任务处理的效率,还能增强灵活性,确保每个子任务得到专门的处理。
Multi-Agent系统有多种设计思路,本教程将介绍一个由Planner Agent、若干个负责执行工具函数的Agent,以及一个Summary Agent组成的Multi-Agent系统。
- Planner Agent规划智能体: 根据用户的输入内容,选择要将任务分发给哪个Agent或Agent组合完成任务。
- 执行工具函数的Agent智能体: 根据Planner Agent分发的任务,执行属于自己的工具函数。
- Summary Agent总结智能体: 根据用户的输入,以及执行工具函数的Agent的输出,生成总结并返回给用户。
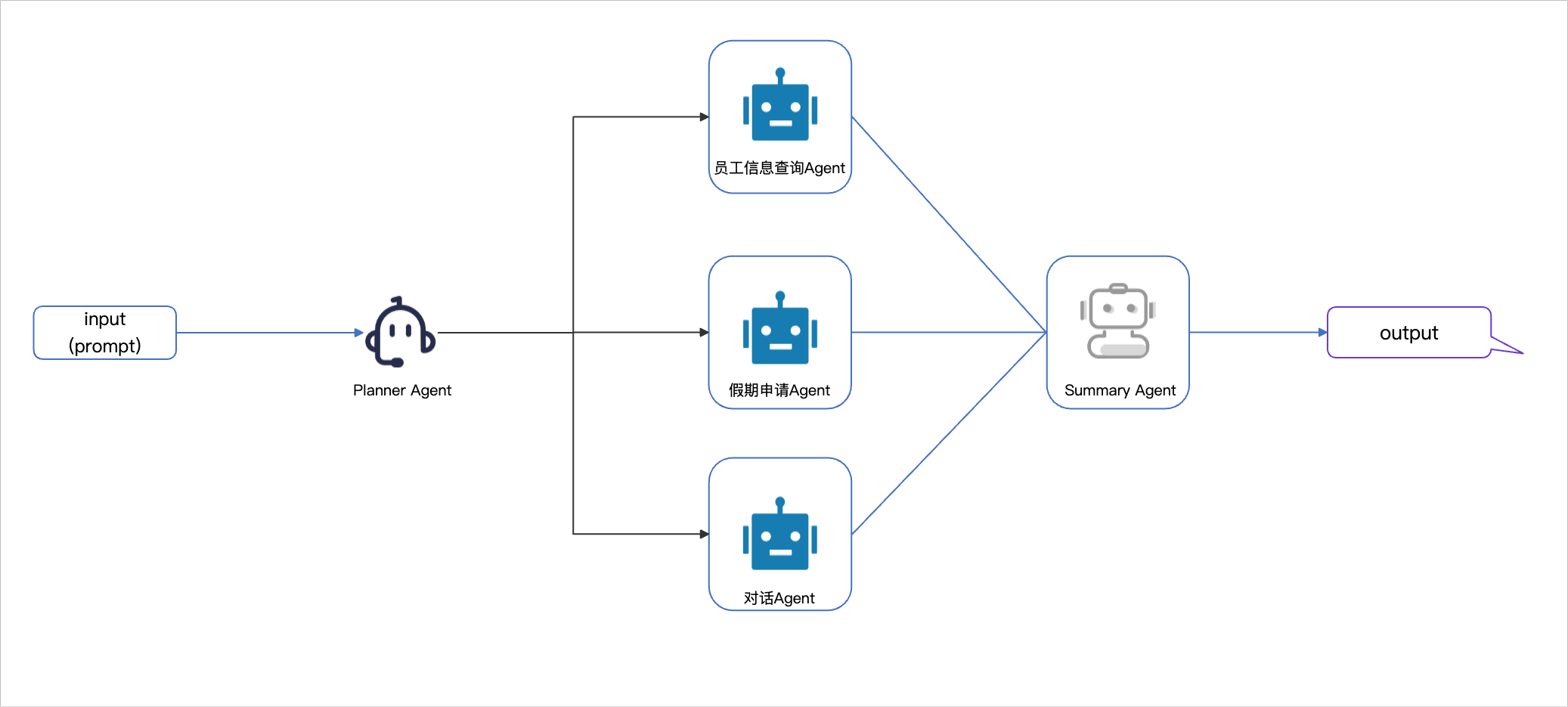
回到之前的示例——“张三的HR是谁?给他请三天假”。在多智能体系统中,这个任务会被拆解成两个子任务:
查询张三的HR信息:由一个Agent负责。
发送请假申请:由另一个Agent负责。
通过多智能体系统,Planner Agent首先分析用户请求并拆解成这两个子任务,然后将每个任务交给对应的执行Agent处理。最后,Summary Agent会将各个Agent的结果汇总,生成最终的响应。
4.1 Planner Agent
Planner Agent 是 Multi-Agent 系统的核心部分,它负责分析问题,并决定将任务分发到哪个Agent或Agent组合上。
首先利用 Assistant API 创建 Planner Agent,此处你可以先不对instructions进行指定:
# 决策级别的agent,决定使用哪些agent,以及它们的运行顺序。planner_agent = Assistants.create( model="qwen-plus", name='流程编排机器人', description='你是团队的leader,你的手下有很多agent,你需要根据用户的输入,决定要以怎样的顺序去使用这些agent')print("Planner Agent创建完成")创建完成后你可以先来看看在未定义instructions时,Planner Agent 的输出是什么样的:
print(get_agent_response(planner_agent,'谁是张三的HR?教育部门一共有多少员工?'))planner_agent=Assistants.update(planner_agent.id,instructions="""你的团队中有以下agent。 employee_info_agent:可以查询公司的员工信息,如果提问中关于部门、HR等信息,则调用该agent; leave_agent:可以帮助员工发送请假申请,如果用户提出请假,则调用该agent; chat_agent:如果用户的问题无需以上agent,则调用该agent。 你需要根据用户的问题,判断要以什么顺序使用这些agent,一个agent可以被多次调用。你的返回形式是一个列表,不能返回其它信息。比如:["employee_info_agent", "leave_agent"]或者["chat_agent"],列表中的元素只能为上述的agent。""")print("Planner Agent 的 instructions 已更新")接下来尝试几个测试问题,看下Planner Agent能否分发到正确的Agent。
query_stk = [ "谁是张三的HR?教育部门一共有多少员工?", "王五在哪个部门?帮我提交下周三请假的申请", "你好"]for query in query_stk: print("提问是:") print(query) print(get_agent_response(planner_agent,query)) print("\n")对于这三个测试问题,Planner Agent都做出了正确的选择。
你可以观察到当Planner Agent返回任务规划结果后,其输出是一个描述任务执行顺序的列表形式字符串,例如:[“employee_info_agent”, “leave_agent”]。为了便于后续处理和执行,你需要将其转换为 Python 原生的列表结构(list)并保留相对应的调用顺序。在这里,你可以使用了 Python的ast.literal_eval方法,它可以安全地将字符串表达式解析为相应的 Python 数据类型,例如列表、字典等。
通过这种方式,你可以将任务规划结果转化为易于操作的列表对象,并逐步解析出每个任务的执行步骤,以简化后续的多智能体协作。
4.2执行工具函数的Agent
上一章节你已经完成了Planner Agent的规划工作。它如同蚁巢中的蚁后,能够统筹规划任务并下达命令。然而,单靠蚁后是不足以让整个蚁巢运转起来的——需要无数的工蚁去执行具体任务,比如搜集食物或修筑巢穴。同样的道理,在你的多智能体系统中,仅有 Planner Agent 还不足以完成任务,必须为其配备执行具体任务的 工具函数Agent,才能真正实现整个系统的高效协作。
以下,你将需要基于上节中的规划结果,为两个不同任务创建独立的 执行工具函数Agent,使它们分别负责具体的操作任务。这种设计不仅让系统更加模块化,还能最大限度地发挥 Planner Agent 的协调作用。
需要确保agent变量名与Planner Agent的instructions中定义的agent变量名一致。
# 员工信息查询agentemployee_info_agent = Assistants.create( model="qwen-plus", name='员工信息查询助手', description='一个智能助手,能够查询员工信息。', instructions='''你是员工信息查询助手,负责查询员工姓名、部门、HR等信息''', tools=[ { 'type': 'function', 'function': { 'name': '查询员工信息', 'description': '当需要查询员工信息时非常有用,比如查询员工张三的HR是谁,查询教育部门总人数等。', 'parameters': { 'type': 'object', 'properties': { 'query': { 'type': 'str', 'description': '用户的提问。' }, }, 'required': ['query']}, } } ])print(f'{employee_info_agent.name}创建完成')# 请假申请agentleave_agent = Assistants.create( model="qwen-plus", name='请假申请助手', description='一个智能助手,能够帮助员工提交请假申请。', instructions='''你是员工请假申请助手,负责帮助员工提交请假申请。''', tools=[ { 'type': 'function', 'function': { 'name': '发送请假申请', 'description': '当需要帮助员工发送请假申请时非常有用。', 'parameters': { 'type': 'object', 'properties': { # 需要请假的时间 'date': { 'type': 'str', 'description': '员工想要请假的时间。' }, }, 'required': ['date']}, } } ])print(f'{leave_agent.name}创建完成')# 功能是回复日常问题。对于日常问题来说,可以使用价格较为低廉的模型作为agent的基座chat_agent = Assistants.create( # 因为该Agent对大模型性能要求不高,因此使用成本较低的qwen-turbo模型 model="qwen-turbo", name='回答日常问题的机器人', description='一个智能助手,解答用户的问题', instructions='请礼貌地回答用户的问题')print(f'{chat_agent.name}创建完成')4.3创建Summary Agent并测试Multi-Agent效果
在完成了Planner Agent和执行工具函数Agent的创建后,你还需要创建Summary Agent,该Agent会根据用户的问题与之前Agent输出的参考信息,全面、完整地回答用户问题。
summary_agent = Assistants.create( model="qwen-plus", name='总结机器人', description='一个智能助手,根据用户的问题与参考信息,全面、完整地回答用户问题', instructions='你是一个智能助手,根据用户的问题与参考信息,全面、完整地回答用户问题')print(f'{summary_agent.name}创建完成')你可以将以上步骤封装为一个get_multi_agent_response函数,这样可以将复杂的多 Agent 协作过程抽象为一个简单接口。通过这种封装方式,用户只需提供输入问题,函数将:
- 调用 Planner Agent,规划任务顺序。
- 根据规划顺序依次调用对应的工具函数 Agent 执行任务。
- 汇总所有任务结果,最后通过 Summary Agent 生成最终回答。
这种设计不仅让主流程更加清晰,还便于复用和扩展。
由于列表中的元素为字符串,因此通过一个agent_mapper方法将字符串格式的Agent映射到定义好的Agent对象。
# 将列表中的字符串映射到Agent对象上# 将字符串格式的Agent名称映射到具体Agent对象agent_mapper = { "employee_info_agent": employee_info_agent, "leave_agent": leave_agent, "chat_agent": chat_agent}def get_multi_agent_response(query): # 获取Agent的运行顺序 agent_order = get_agent_response(planner_agent,query) # 由于大模型输出可能不稳定,因此加入异常处理模块处理列表字符串解析失败的问题 try: order_stk = ast.literal_eval(agent_order) print("Planner Agent正在工作:") for i in range(len(order_stk)): print(f'第{i+1}步调用:{order_stk[i]}') # 随着多Agent的加入,需要将Agent的输出添加到用户问题中,作为参考信息 cur_query = query Agent_Message = "" # 依次运行Agent for i in range(len(order_stk)): cur_agent = agent_mapper[order_stk[i]] response = get_agent_response(cur_agent,cur_query) Agent_Message += f"*{order_stk[i]}*的回复为:{response}\n\n" # 如果当前Agent为最后一个Agent,则将其输出作为Multi Agent的输出 if i == len(order_stk)-1: prompt = f"请参考已知的信息:{Agent_Message},回答用户的问题:{query}。" multi_agent_response = get_agent_response(summary_agent,prompt) print(f'Multi-Agent回复为:{multi_agent_response}') return multi_agent_response # 如果当前Agent不是最后一个Agent,则将上一个Agent的输出response添加到下一轮的query中,作为参考信息 else: # 在参考信息前后加上特殊标识符,可以防止大模型混淆参考信息与提问 cur_query = f"你可以参考已知的信息:{response}你要完整地回答用户的问题。问题是:{query}。" # 兜底策略,如果上述程序运行失败,则直接调用大模型 except Exception as e: return get_agent_response(chat_agent,query)# 此处来用 “王五在哪个部门?帮我提交下周三请假的申请”进行一个测试get_multi_agent_response("王五在哪个部门?帮我提交下周三请假的申请")5.大模型平台的多智能体编排功能
上一小节你了解了Multi-Agent系统的设计理念与实现方法。可以看出,在自主构建一个Multi-Agent系统时,虽然能够提供高度的灵活性,但也伴随着一定的工作量和复杂性。对于许多企业来说,快速实现复杂业务逻辑更为重要。
Dify 是智能体流程画布的开创者之一。Dify的画布工具让用户能够通过可视化的流程图来设计和管理智能体任务的执行逻辑,在业内树立了标杆。其直观的界面设计,为许多开发者提供了参考。
尽管 Dify.ai 在智能体流程编排方面表现出色,但相比之下,百炼平台在以下方面更适合国内企业与开发者使用
百炼平台的多智能体编排功能,依托大模型的强大能力,支持智能体自主决策和任务分工。通过平台内置的画布式编排工具,用户可以轻松实现以下目标:
- 定义智能体的执行逻辑:用户能够直观地通过画布式工具配置各个智能体的执行规则和逻辑链路。
- 编排多个智能体之间的协作:通过模块化设计,各个智能体能够高效配合,完成复杂任务。
- 快速验证业务效果:内置的仿真和测试功能,帮助用户快速验证编排逻辑是否符合预期。
百炼平台支持用户从零开始设计智能体系统,即使没有深厚的技术背景,用户也可以通过其易用的界面快速搭建并验证多智能体协作系统。对于需要快速落地多智能体技术的企业,百炼平台是一个理想的选择。
详情请见百炼智能体应用。
6.本章小结
在本节课程中,你学习了以下内容:
- Agent系统的核心理念
- 多智能体系统的构建原理和实现方法
- 大模型平台的多智能体编排
扩展阅读
你已经了解了如何使用多智能体系统来处理复杂任务,但这种设计不仅仅局限于基础操作。事实上,合理设计多智能体系统,能够帮助你将更为复杂的业务流程自动化处理,提升效率和精度,甚至可以实现一些需要人介入的繁琐操作。
效果展示与流程图解析
下面是一个实际的智能体系统应用案例,假设你需要对一个网页进行内容验证——不仅仅是检查静态内容,还包括与页面元素的交互。此时,多智能体系统的优势就显现出来了。通过分工合作,多个智能体能够共同高效完成任务,而你无需手动干预每个步骤。
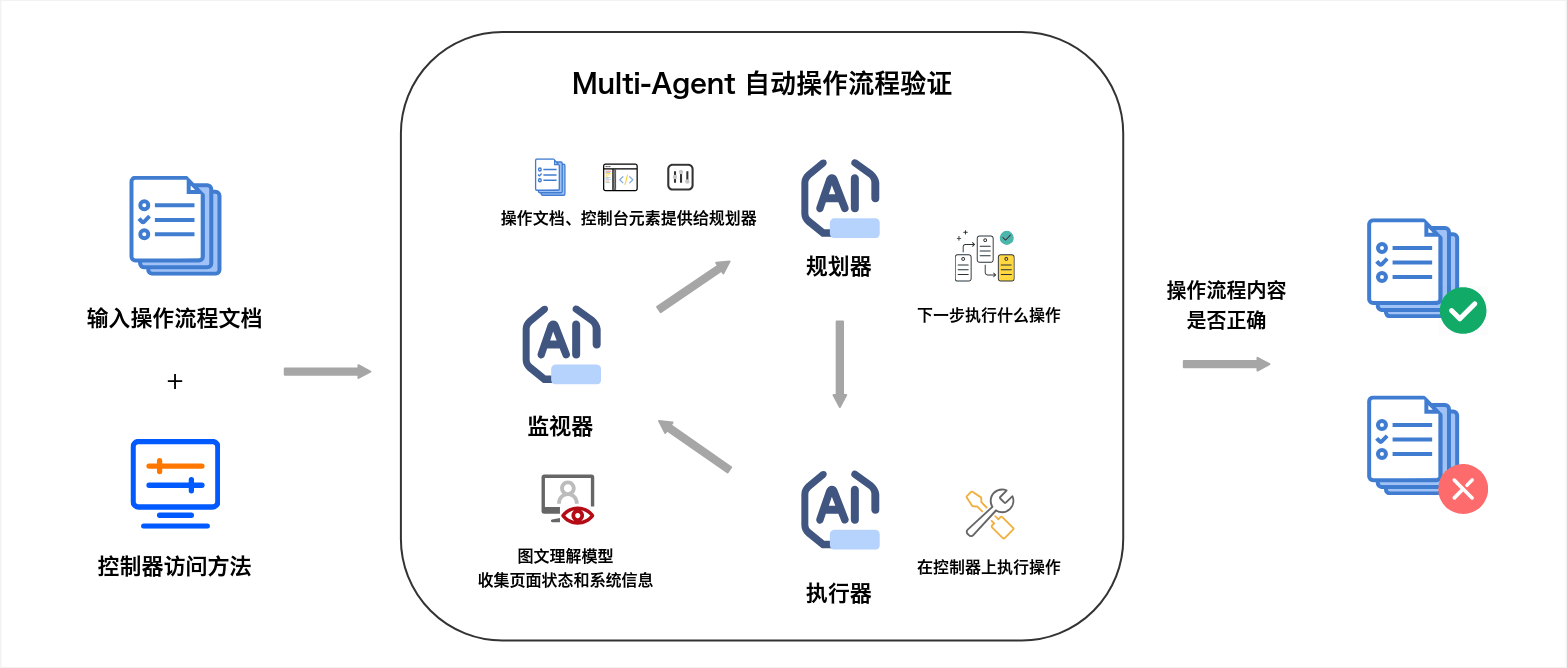
当面对一个需要解析HTML页面并执行特定操作的任务时,多智能体的分工如下:
- Planner Agent规划器:分解任务,例如识别HTML元素中的列表或按钮。
- Selector Agent执行器:负责具体的操作任务,例如选择特定元素并执行点击动作。
- Monitor Agent监视器:实时监控任务的执行,确保流程按计划完成,如检测是否点击正确的按钮。
视觉标注在智能体应用中的结合
在实际项目中,尤其是涉及到网页内容交互时,光靠传统的文本分析能力往往无法精确地识别界面元素,导致智能体的执行效率和准确性下降。为了解决这一问题,视觉标注被应用于自动化测试和控制台界面的元素识别。
在某些场景下,智能体在操作控制台界面时,由于界面元素的复杂性,模型可能难以准确地识别目标。此时,通过引入视觉标注技术,可以提高模型对界面元素的理解和操作准确性。
就像你在使用一款软件时,可能需要通过眼睛去识别按钮、下拉菜单或表单,才能做出正确的操作。如果没有清晰的视觉标识,你可能会找错位置或操作错误。类似地,在智能体执行任务时,界面元素的准确识别至关重要。通过视觉标注,系统可以为这些元素加上“标签”,帮助智能体更准确地“看到”并正确执行操作。
例如,在处理HTML页面的自动化测试时,通过使用视觉标注,系统可以对页面中的按钮、链接或表单进行标记,并指导智能体精确选择和操作这些元素。这种视觉增强的设计大大提高了模型处理复杂界面的能力,使得多智能体系统在面对不同的UI元素时更加灵活高效。
多智能体系统的灵活性与技术结合
通过这个案例,你可以发现多智能体系统的设计并不局限于某一类技术或场景。虽然在这个示例中多智能体系统结合了视觉标注,但实际上,多智能体系统的灵活性使得它能够与各种技术结合,解决不同的需求。
例如,你可以结合机器学习技术优化智能体的决策过程,或者使用图像处理技术提升界面元素的识别能力。
又如,你可以将多智能体系统与自然语言处理结合,使其能够理解和生成更复杂的语言指令,应用于智能客服或文本分析场景。
你可以根据需求自由选择多智能体系统的架构和技术组合,最终为你带来最佳的自动化解决方案。
多智能体系统不仅是一个工具,它更是一种思维方式,能够根据不同任务和场景灵活设计和调整,从而在不同的应用中发挥巨大价值。在今后的应用中,无论是面对页面自动化测试,还是处理更复杂的业务流程,合理设计的多智能体系统都能帮助你提高效率,优化操作,甚至替代部分人类工作,解放你的生产力。
🔥 7.课后小测验
🔍 单选题
在本教程中,Planner Agent的作用是什么❓
- A. 负责执行工具函数
- B. 负责总结Agent的输出内容
- C. 负责分析用户输入,并将任务分发到其它Agent上
- D. 负责打印关键日志
【点击查看答案】
✅ 参考答案:C
📝 解析:
- 在本教程中,Planner Agent 的主要功能是作为任务的分配者。它分析用户的输入内容,并根据具体任务需求,将不同的任务分配给最适合的其他 Agent。
- 因此,Planner Agent在系统中起到路由的作用,确保每个任务能够高效地交由相应的 Agent 处理。
<td>文档切片长度过大,引入过多干扰项</td>
<td>减少切片长度,或结合具体业务开发为更合适的切片策略</td>
<td>例如,某文档的切片长度过大,包含了多个不相关的主题,导致检索时返回了无关信息。可以减少切片长度,确保每个切片只包含一个主题。</td>
</tr>
<tr>
<td>文档切片长度过短,有效信息被截断</td>
<td>扩大切片长度,或结合具体业务开发为更合适的切片策略</td>
<td>例如,某文档中每个切片只有一句话,导致检索时无法获取完整的上下文信息。可以增加切片长度,确保每个切片包含完整的上下文。</td>
<td>已支持解析的文档格式里,存在一些特殊内容 <em>比如文档里嵌入了表格、图片、视频等</em></td>
<td>改进文档解析器</td>
<td>例如,某文档中包含了大量的表格和图片,现有解析器无法正确提取表格中的信息。可以改进解析器,使其能够处理表格和图片。</td>
当面对一个需要解析HTML页面并执行特定操作的任务时,多智能体的分工如下:
- Planner Agent规划器:分解任务,例如识别HTML元素中的列表或按钮。
- Selector Agent执行器:负责具体的操作任务,例如选择特定元素并执行点击动作。
- Monitor Agent监视器:实时监控任务的执行,确保流程按计划完成,如检测是否点击正确的按钮。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号