阿里云百炼xAnalyticDB PostgreSQL构建AIGC应用
场景简介
在本实验场景中,将使用Alibaba Cloud AI Containers(AC2)容器镜像服务,通过Docker容器镜像部署Qwen系列大语言模型。本实验场景基于第八代Intel实例,使用Alibaba Cloud Linux 3作为实验系统,使能Intel最新的 AI 加速指令集,提供完整的容器生态支持。
本实验场景无需深奥的AI背景知识,只要了解基本的Linux基础知识,能够使用命令行,就可以轻松完成本实验,体验大语言模型的对话能力,感受AIGC的魅力。
使用AI容器镜像的过程中,有任何疑问和建议,您可以加入钉钉群(群号33605007047)反馈,并获取技术支持。
背景知识
本场景主要涉及以下云产品和服务:
云服务器ECS
云服务器(Elastic Compute Service,简称ECS)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。一台云服务器ECS实例等同于一台虚拟服务器,内含CPU、内存、操作系统、网络配置、磁盘等基础的组件。云服务器ECS免去了您采购IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样便捷、高效地使用服务器,实现计算资源的即开即用和弹性伸缩。阿里云ECS持续提供创新型服务器,解决多种业务需求,助力您的业务发展。
Alibaba Cloud Linux
Alibaba Cloud Linux是阿里云研发的稳定、安全、高性能的服务器操作系统,是目前阿里云上部署规模最大的操作系统之一,可以为用户应用部署在Web服务、云原生应用、大数据、数据库、AI等场景中提供系统软件维护、安全加固、性能优化、多架构支持、内核热补丁等操作系统服务。
阿里云AI容器镜像
阿里云AI容器镜像(Alibaba Cloud AI Containers 简称 AC2)是阿里云提供的对面向AI场景的系列容器镜像,通过提供开箱即用的AI应用环境,包括内置CUDA AI库、AI框架PyTorch,并结合阿里云基础设施进行性能优化、兼容性保障、稳定性保障,让用户可以在阿里云上全容器场景下有更好的使用体验。
前提条件
云起实验室将在您的账号下开通本次实操资源,资源按量付费,需要您自行承担本次实操的云资源费用。
重要
本实验预计产生费用4.61/时,0.8元/G公网流量。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
进入实操前,请确保阿里云账号满足以下条件:
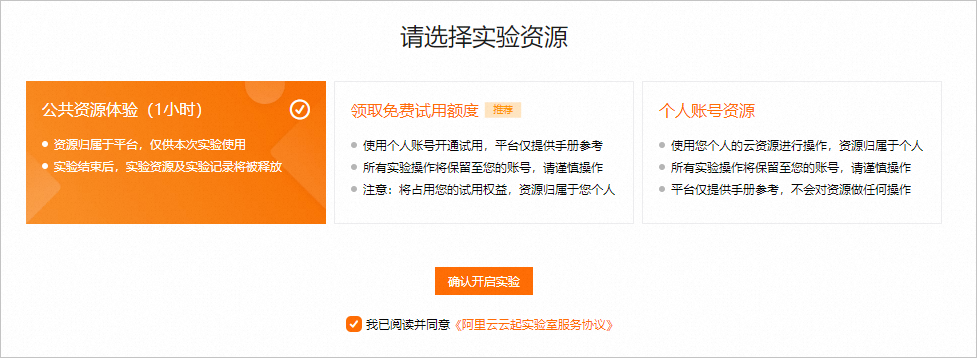
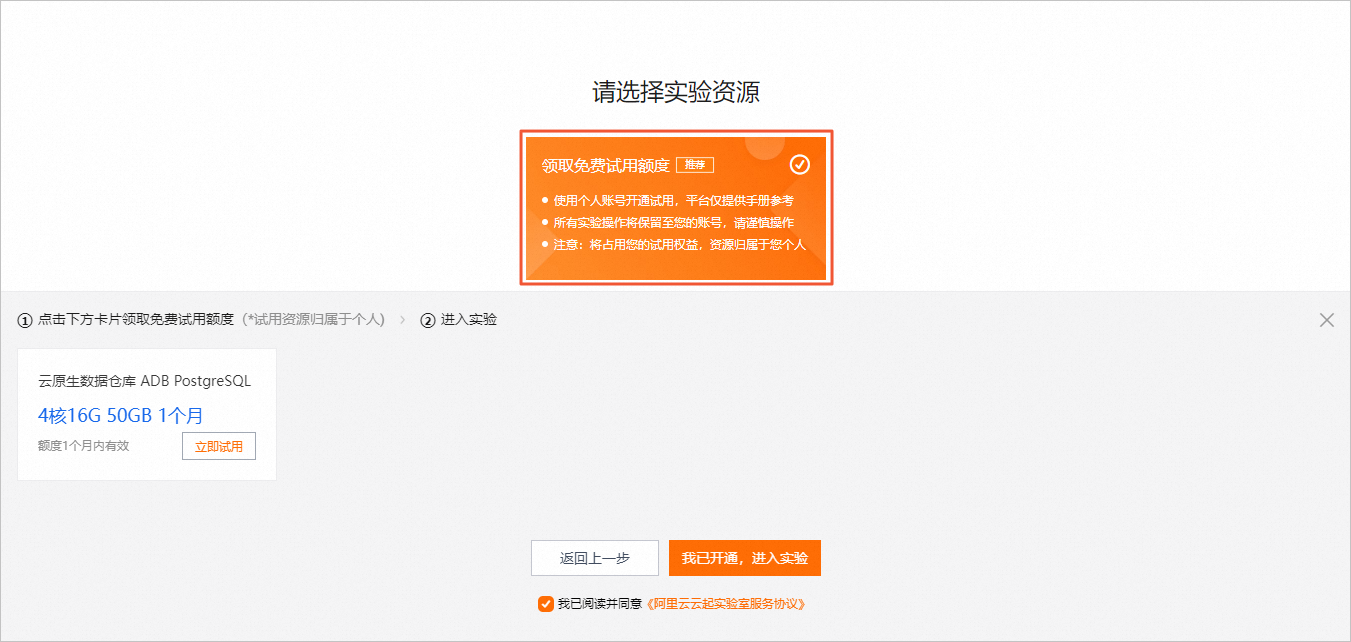
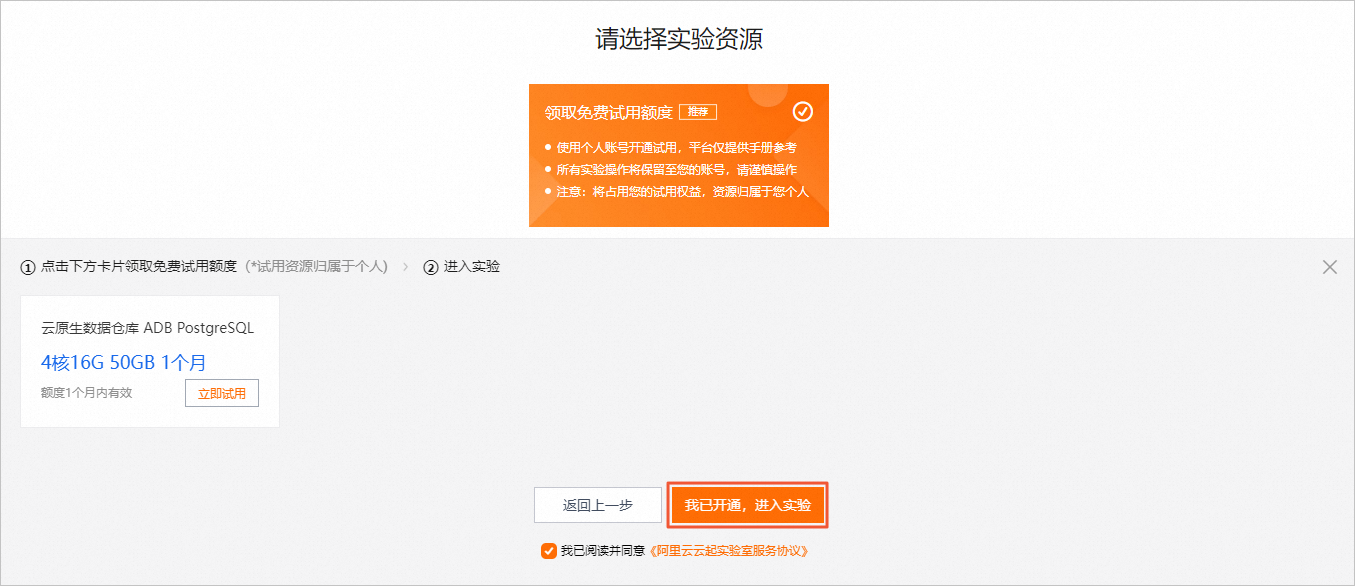
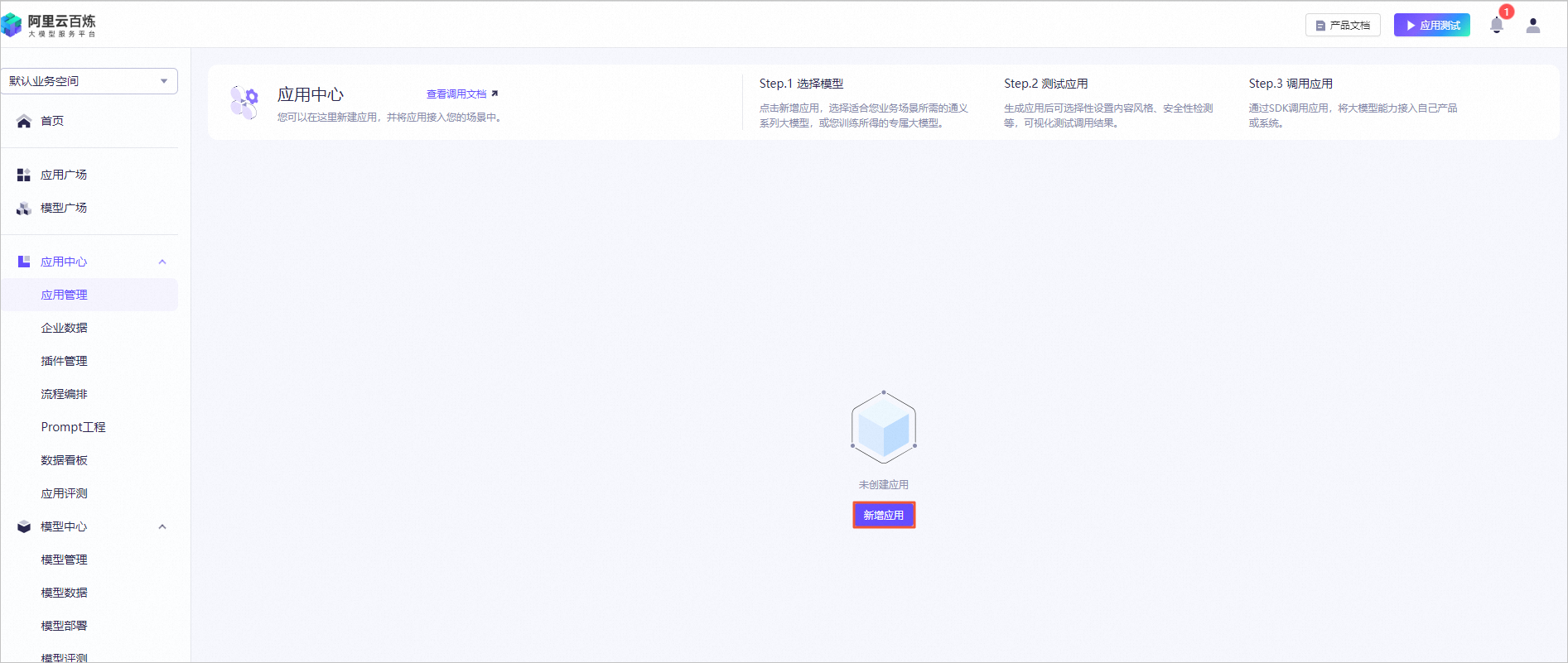
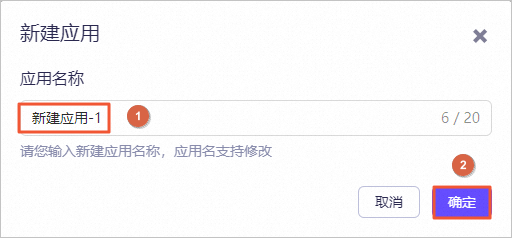
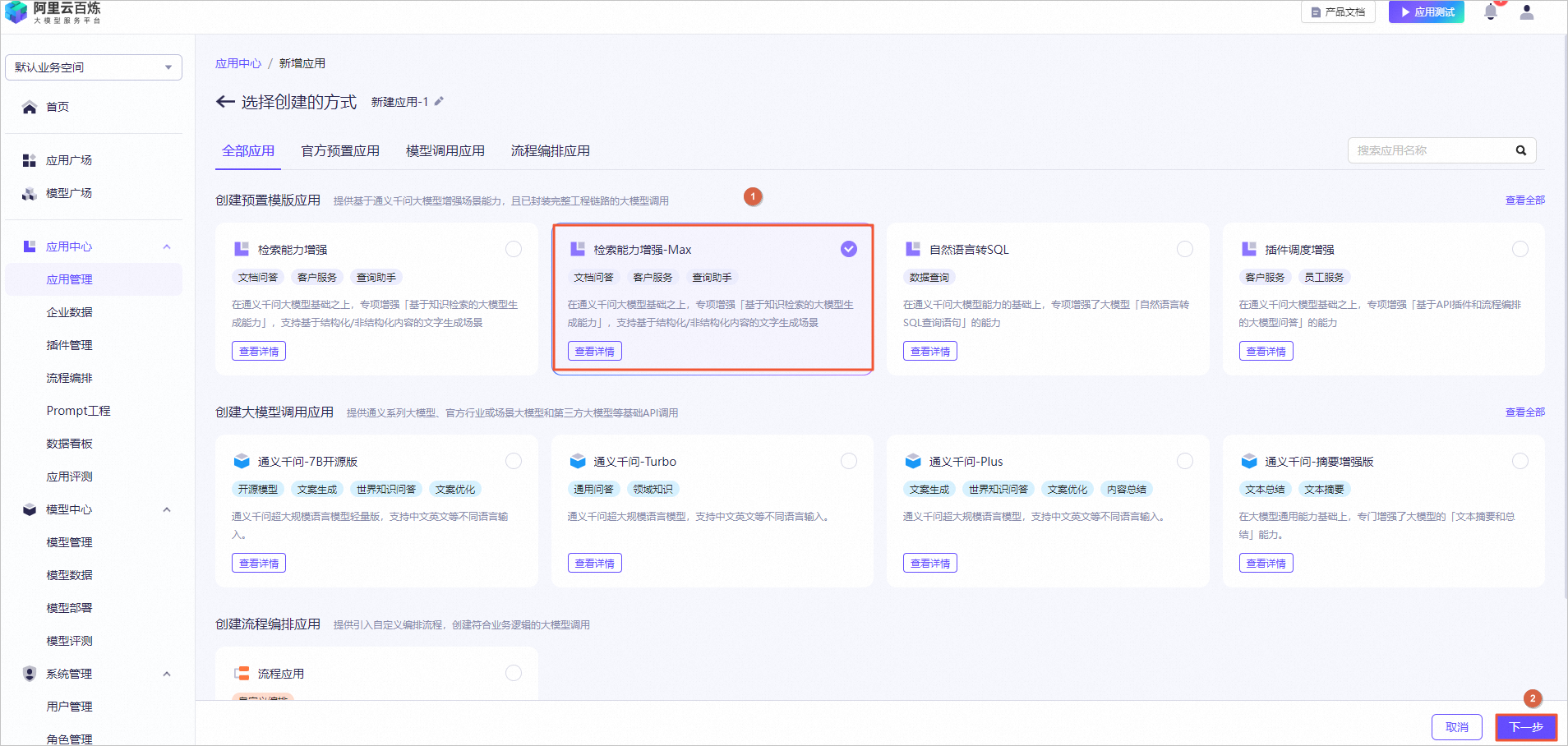
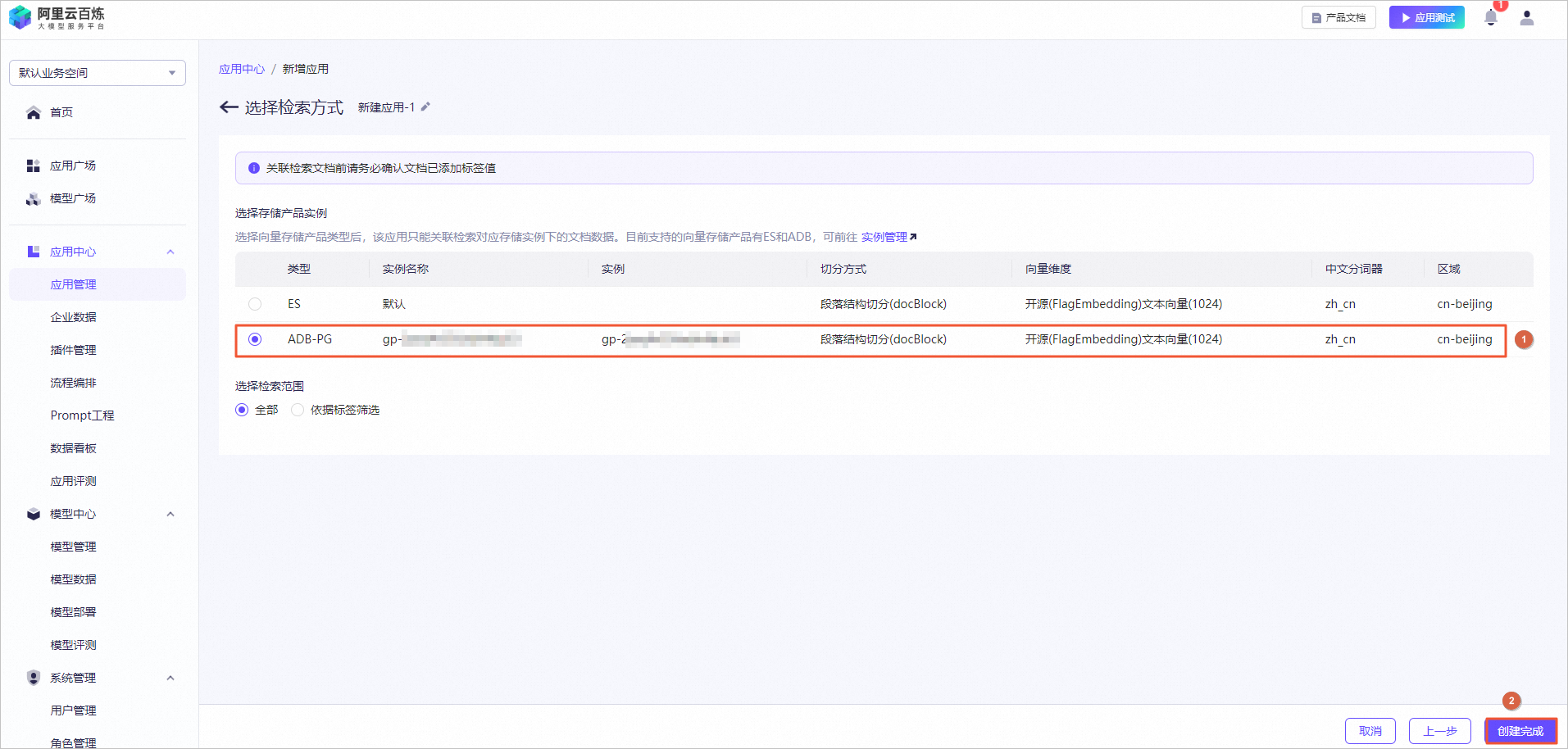
创建实验资源
在实验页面,勾选我已阅读并同意《阿里云云起实践平台服务协议》和我已授权阿里云云起实践平台创建、读取及释放实操相关资源后,单击开始实操。
创建资源需要5分钟左右的时间,请您耐心等待。
在云产品资源列表,您可以查看本场景涉及的云产品资源信息。
安全设置
资源创建完成后,为了保护您阿里云主账号上资源的安全,请您重置云服务器ECS的登录密码、设置安全组端口。
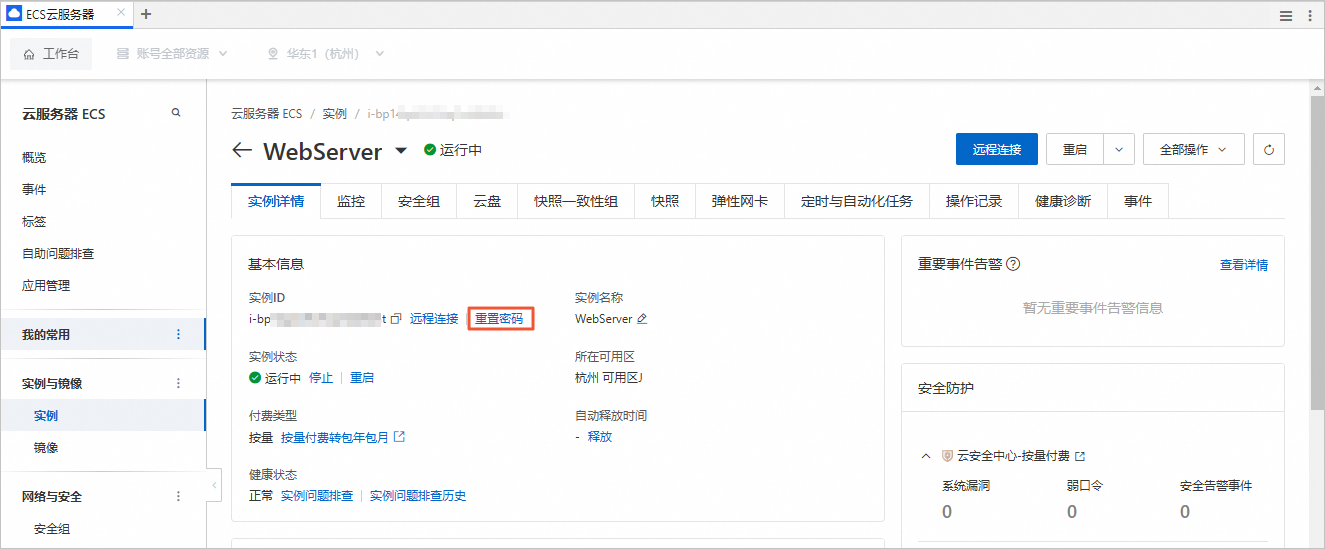
重置云服务器ECS的登录密码。
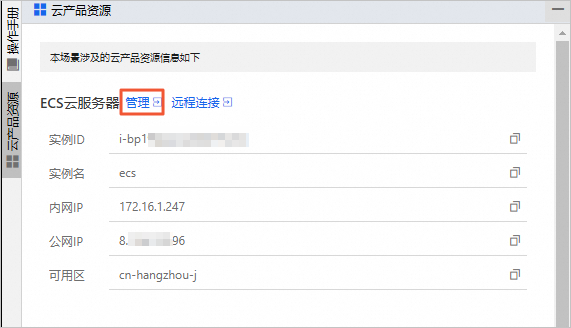
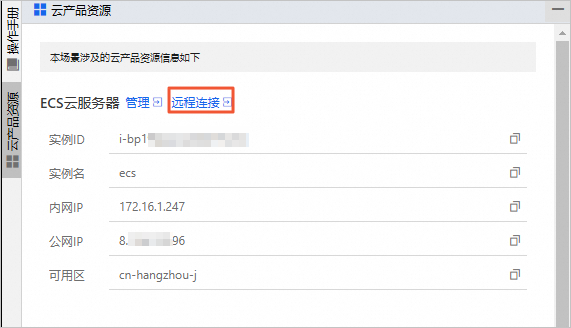
在云产品资源列表的ECS云服务器区域,单击管理。
在实例详情页签的基本信息区域,单击重置密码。
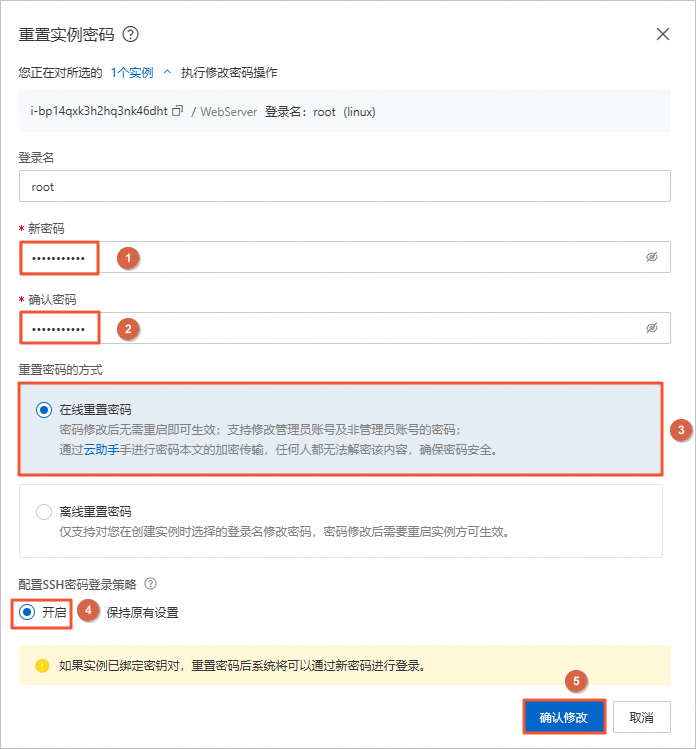
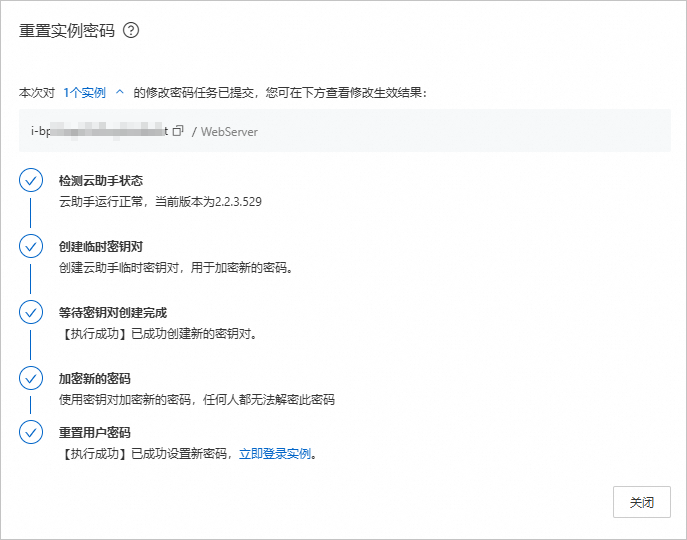
在重置实例密码对话框中,设置新密码和确认密码,重置密码的方式选择在线重置密码,配置SSH密码登录策略选择开启,单击确认修改。
返回如下结果,表示ECS实例root用户的登录密码重置成功。
设置安全组端口。
在云产品资源列表的安全组区域,单击管理。
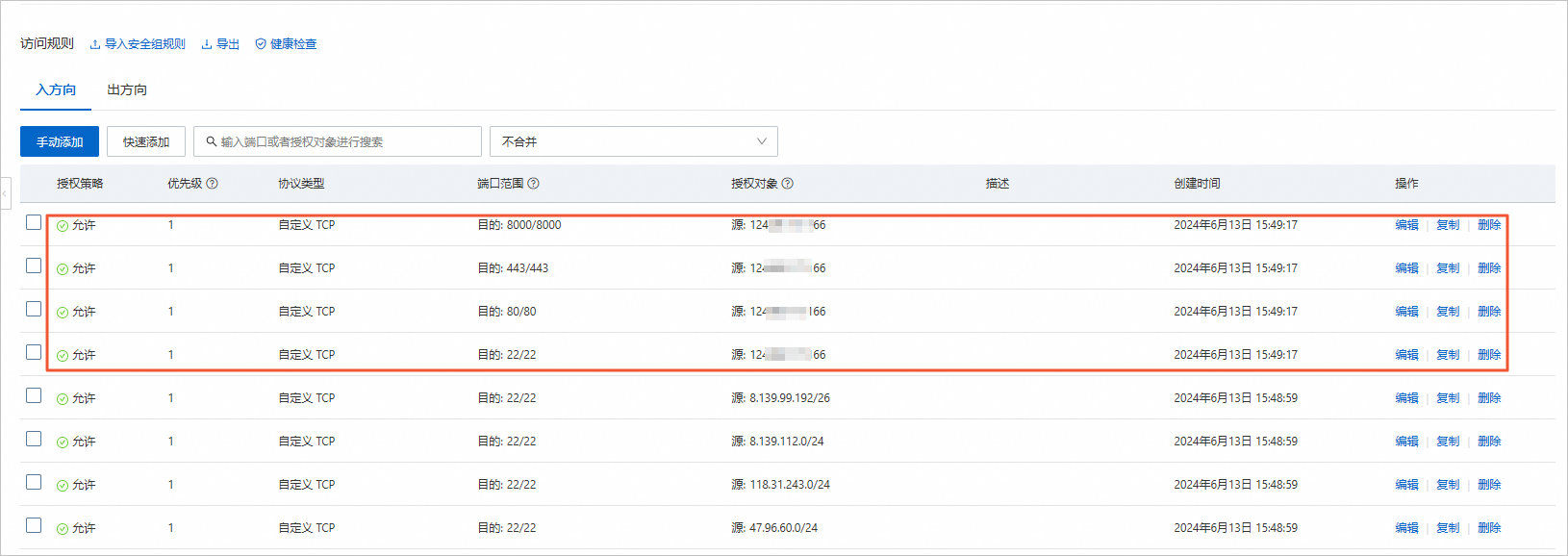
在访问规则区域的入方向中,添加SSH(22)、HTTP(80)、HTTPS(443)和8000端口。
准备系统环境 首先需要添加系统组件,后续需要下载大模型与运行脚本。
在云产品资源列表的ECS云服务器区域,单击远程连接。
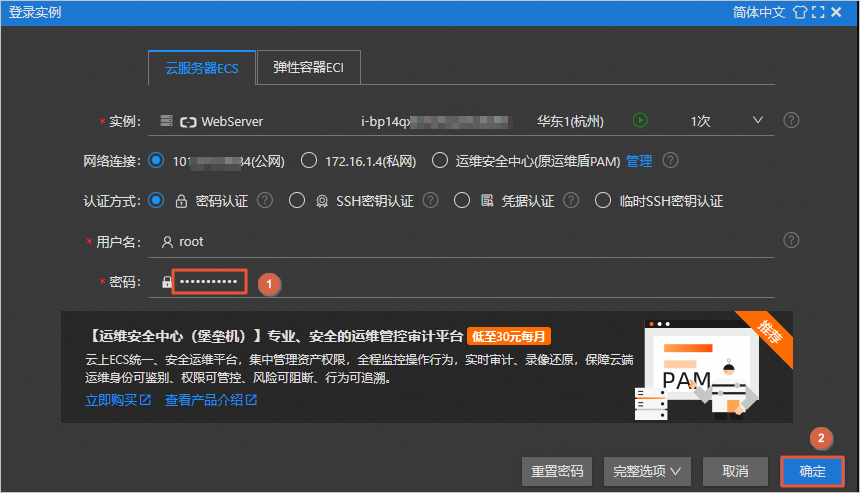
在登录实例对话框中,输入用户自定义密码,单击确定。
执行如下命令,安装Git等必备软件。
sudo dnf install -y git git-lfs wget
执行如下命令,安装Git LFS。
安装Docker
使用AC2需要首先设置Docker运行环境。在Alibaba Cloud Linux 3上可以通过以下步骤安装Docker。
执行如下命令,添加docker-ce软件源,并安装软件源兼容插件。
sudo dnf config-manager --add-repo=https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sudo dnf install -y --repo alinux3-plus dnf-plugin-releasever-adapter
执行如下命令,安装Docker-CE。
sudo dnf install -y docker-ce
执行如下命令,检查Docker是否安装成功。
返回类似信息如下。
执行如下命令,启动Docker服务。
sudo systemctl start docker
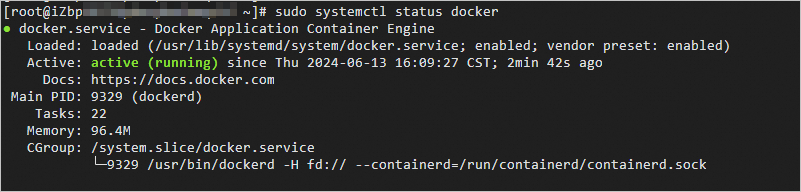
执行如下命令,检查Docker服务运行情况。
sudo systemctl status docker
返回类似信息如下,表示Docker已正常启动,并设置开机自启。
说明
查看Docker服务运行情况后,您可使用Ctrl+C退出查看。
下载Qwen大模型与运行脚本 由于Qwen运行环境镜像中并不包含大模型权重与运行脚本,您需要预先下载到本地。
执行如下命令,下载Qwen-1.8B-Chat模型。
说明
模型下载耗时较长,终端可能会无响应,等待下载完毕即可恢复。
git clone https://www.modelscope.cn/qwen/Qwen-1_8B-Chat.git ~/Qwen-1_8B-Chat
执行如下命令,下载Qwen大模型运行脚本。
说明
脚本通过GitHub托管,若下载失败,请重新执行命令。
wget -O ~/qwen_web_demo.py https://raw.githubusercontent.com/QwenLM/Qwen/8c53f58a673f976f923fc71340b2220293b8052f/web_demo.py
执行如下命令,修改运行脚本,使用BF16精度加载模型,使用Intel AMX加速指令集。
grep "torch.bfloat16" qwen_web_demo.py 2>&1 >/dev/null || sed -i "54i\torch_dtype=torch.bfloat16," qwen_web_demo.py
创建大模型容器
Qwen系列镜像是Alibaba Cloud AI Containers(AC2)容器镜像服务推出的开箱即用大模型镜像。其中包含了运行Qwen系列大模型所需的所有依赖,包括Python运行环境、深度学习框架、模型权重文件以及依赖库。确保Qwen系列大模型能够高效、稳定地在不同环境下部署和服务。
下面将快速拉取AC2 Qwen运行环境镜像,并创建容器。
执行如下命令,拉取Qwen镜像。
sudo docker pull ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/qwen:runtime-pytorch2.2.0.1-alinux3.2304
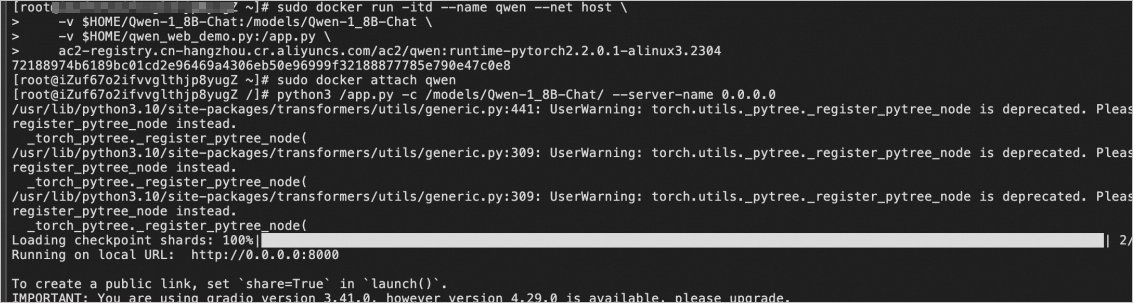
执行如下命令,创建容器,并挂载本地模型文件以及运行脚本。该命令会以分离运行模式创建一个名为qwen的容器,并将本地模型目录与运行脚本挂载到容器中。
sudo docker run -itd --name qwen --net host \
-v $HOME/Qwen-1_8B-Chat:/models/Qwen-1_8B-Chat \
-v $HOME/qwen_web_demo.py:/app.py \
ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/qwen:runtime-pytorch2.2.0.1-alinux3.2304
进入容器运行脚本
接下来将进入容器环境,并运行大模型脚本。
执行如下命令,进入容器环境。
执行如下命令,执行运行脚本,指定模型路径以及监听主机名。
export GRADIO_ANALYTICS_ENABLED=False
python3 /app.py -c /models/Qwen-1_8B-Chat/ --server-name 0.0.0.0
返回如下结果,表示您已成功运行脚本。
与Qwen大模型对话
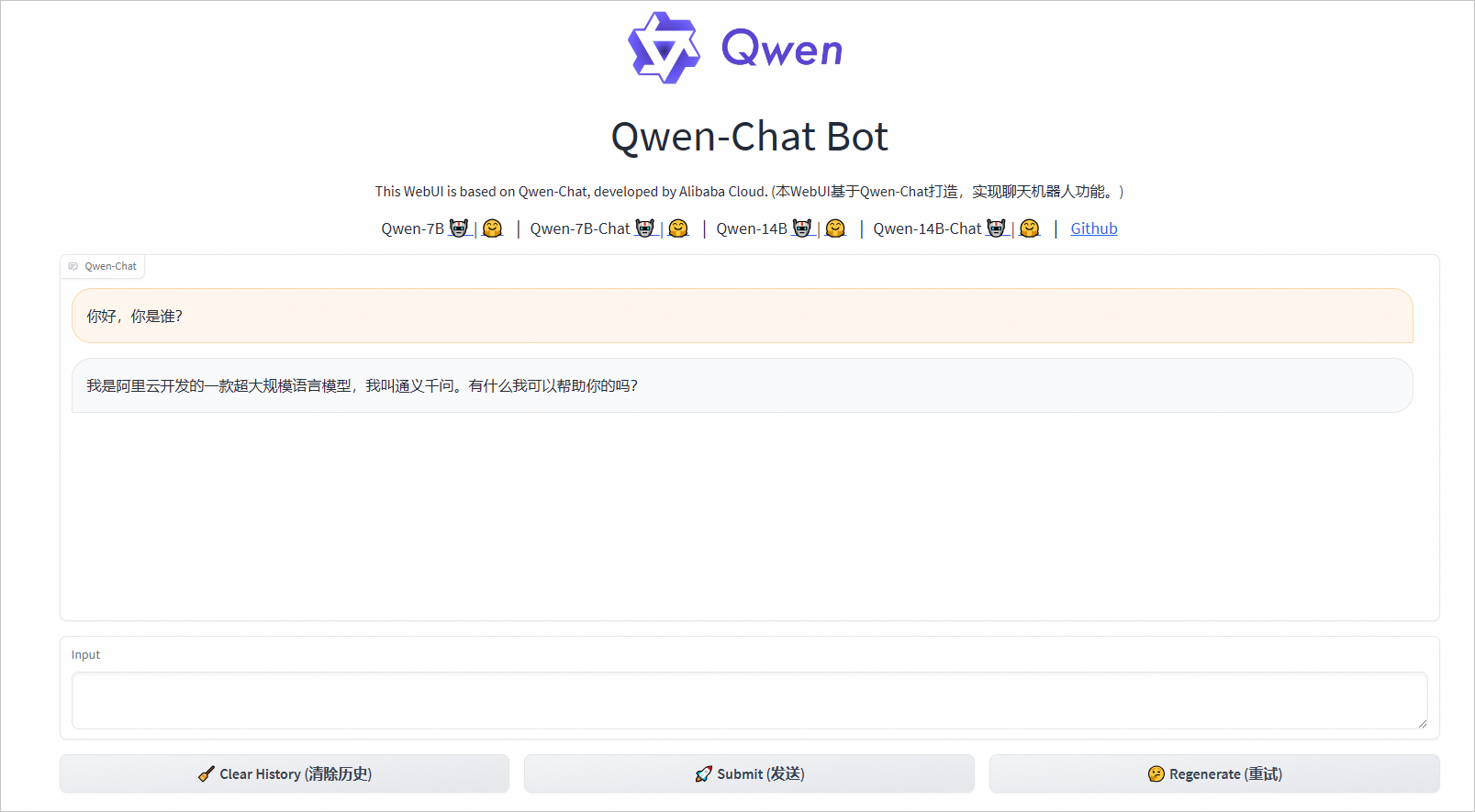
部署完毕后,在本机浏览器地址栏中,输入http://ECS实例公网IP:8000访问服务。
成功部署后可以通过网页Demo与大模型进行对话。您可以在Input输入框中输入您想问的问题,比如“你好,你是谁?”,然后单击Submit (发送),大模型会实时回答输入的问题。
阿里云大模型ACA认证模拟考试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
单选 2.开发围棋AI时,初期用大量历史棋谱训练模型(输入棋盘状态→输出最佳落子位置),后期让AI自我对弈并通过输赢结果优化策略。这两个阶段分别属于什么学习模式? A. 第一阶段是监督学习(用棋谱数据模仿人类),第二阶段是强化学习(通过胜负奖励改进) B. 两阶段均为强化学习(均依赖环境反馈) C. 第一阶段是无监督学习(自动解析棋谱),第二阶段是监督学习(用胜负结果作为标签) D. 两阶段均为监督学习(棋谱和胜负结果均为标注数据) 相关知识点: A. 正确:第一阶段使用标注的棋谱数据(监督学习),第二阶段通过自我对弈和胜负反馈优化策略(强化学习)。B. 错误:第一阶段并非依赖环境反馈,而是基于标注数据。C. 错误:第一阶段不是无监督学习,因为有明确的标签;第二阶段不是监督学习,因为没有显式标签。D. 错误:第二阶段不依赖标注数据,而是通过环境反馈学习。
单选 3.你所在的医院技术部正在翻译一份医学影像技术手册,包含上千条内部非公开的专业术语与缩写。如果想在翻译时保证准确性,并减少对大量示例的依赖,以下哪种做法更合适? A. 仅提供少量缩写翻译示例。如“MRI → 磁共振成像”,“CT → 计算机断层扫描”,让大模型依照模仿。 B. 分配“专业医学翻译员”角色,依靠零样本提示直接解决 C. 接入专业术语库,并使用RAG技术,以动态查询并统一术语标准 D. 尽可能增加示例数量,用穷举方式涵盖所有缩写的翻译场景。 相关知识点: A. 错误:少量示例不足以覆盖所有缩写。B. 错误:零样本提示难以保证准确性。C. 正确:RAG技术结合术语库能动态查询并确保翻译一致性。D. 错误:穷举方式效率低且难以覆盖所有情况。
单选 4.在大模型应用落地的过程中,下列哪类人员最应主导提示词设计? A. 仅技术人员 B. 业务领域专家+技术人员协作 C. 仅业务部门领导 D. 数据标注团队 相关知识点: A. 错误:仅技术人员缺乏业务场景理解。B. 正确:业务领域专家和技术人员协作能结合实际需求和技术实现。C. 错误:仅业务部门领导可能缺乏技术背景。D. 错误:数据标注团队主要负责数据处理,不适合主导提示词设计。
5.阿里云AI助理在处理用户问题"如何开通阿里云ECS实例?"时,其处理流程最可能是以下哪一项? A. 用户输入问题→计算用户问题与文档块的向量相似度→大模型基于Top K文档块生成回答 B. 用户输入问题→调用大模型直接生成草稿→用文档库修正关键参数 C. 用户输入问题→匹配文档标题关键词→返回预设操作手册链接 D. 用户输入问题→检索所有相关文档→人工提取知识点→提交大模型润色 相关知识点: A. 正确:基于向量相似度检索相关文档块,再由大模型生成回答,这是典型的RAG流程。B. 错误:直接生成草稿可能导致错误。C. 错误:仅匹配关键词无法捕捉复杂语义。D. 错误:人工提取知识点效率低下。
6.某公司收集了5万条用户对产品的文字反馈,需在8小时内完成分类统计,要求按“价格、售后、体验”三个维度划分,且需理解用户反馈中的隐含语义(如“客服回应慢”可能关联“售后”,“太贵了”可能关联“价格”)。最合适的解决方案是? A. 人工逐条阅读并分类 B. 编写正则表达式匹配关键词 C. 调用大模型 API进行语义分类 D. 使用OCR技术提取文本后分类 相关知识点: A. 错误:人工分类效率低。B. 错误:正则表达式无法理解隐含语义。C. 正确:大模型具备强大的语义理解能力。D. 错误:OCR技术与文本分类无关。
7.作为健康App开发者,某用户希望改善久坐习惯但难以坚持运动提醒。如何设计一个解决方案,既能个性化激励用户,又能科学调整健康计划? A. 用大模型生成固定话术,每天中午12点推送“该运动了”聊天提醒。 B. 提供空白计划表,由用户每周日手动填写下周运动时间 C. 接入智能手环记录步数,每日生成“步数达标率”图表 D. 搭建健康管理Agent:分析日程→动态推荐碎片化运动(如会议间隙深蹲)→达标解锁勋章+调整下周计划 相关知识点: A. 错误:固定话术提醒缺乏灵活性。B. 错误:手动填写计划表难以坚持。C. 错误:步数达标率图表无法直接激励用户。D. 正确:动态推荐运动、设置激励机制并调整计划,既个性化又科学。
8.你正在开发一个多功能智能客服系统,目标是提高客户支持效率。以下哪种设计最适合提高系统效率? A. 让每个客服Agent独立处理客户问题,并在解决问题后结束会话。 B. 让多个Agent根据问题类型协作分工,每个Agent负责不同领域的支持。 C. 让所有客服Agent根据相同的规则解决所有问题。 D. 客服Agent仅提供基础FAQ解答,不进行任何复杂问题的处理。 相关知识点: A. 错误:独立处理所有问题会导致效率低下。B. 正确:分工明确的多Agent系统更高效。C. 错误:统一规则无法应对复杂问题。D. 错误:仅提供FAQ解答功能受限。
9.你尝试用大模型解决一个特定任务,以下哪种情况适合使用 LoRA方法进行微调? A. 快速训练一个全新的基础大模型以满足任务需求 B. 在有限算力下提升大模型的生成质量,同时兼顾较低的资源消耗 C. 同时优化模型的所有参数以达到最佳效果 D. 通过微调来增加模型参数量,以提升性能 相关知识点: A. 错误:LoRA不适合快速训练全新模型。B. 正确:LoRA通过优化低秩矩阵旁路参数降低资源消耗。C. 错误:LoRA不优化所有参数。D. 错误:LoRA不增加模型参数量。 正确答案: B
10.某新闻机构希望其AI系统生成的报道能够深度模仿某资深记者的写作风格,并可以生成任何领域、任何类型的新闻报道。以下哪种方法能最有效地实现上述目标? A. 在生成时实时检索该记者的历史文章片段做参考 B. 在提示词中提及该记者的名字或代表作 C. 基于该记者过往稿件对预训练大模型进行领域适配微调,并在提示词中给出需要模仿的案例片段。 D. 在输出前做错别字和文法规范的校验 相关知识点: A. 错误:实时检索效果有限。B. 错误:提及名字或代表作无法深度模仿风格。C. 正确:微调模型并结合提示词能更好地模仿风格。D. 错误:错别字校验与风格模仿无关。
11.某公司计划开发一款面向电商场景的智能商品咨询应用,在对大模型做微调前应该先做什么? A. 直接拿用户和客服的聊天记录,洗洗就开练 B. 先明确需求(比如要降成本还是促销售),再收数据 C. 先定技术方案(比如用云还是本地服务器) D. 先上线功能到业务系统,再看业务怎么评价 相关知识点: A. 错误:直接训练模型可能导致方向偏差。B. 正确:明确需求是项目成功的基础。C. 错误:技术方案应在需求明确后确定。D. 错误:上线功能后再调整风险高。 正确答案: B
12.某医疗AI模型在接收到罕见的患者症状描述时,错判为某常见病。这一问题最可能与以下哪一项因素最为相关? A. 公平性约束未充分实施 B. 模型鲁棒性不足,难以应对罕见病症 C. 模型可解释性差,无法清晰说明诊断依据 D. 数据脱敏失效,导致敏感信息泄露 相关知识点: A. 错误:公平性约束与罕见病识别无直接关系。B. 正确:模型对罕见病症的适应能力差。C. 错误:可解释性差与误判无直接关系。D. 错误:数据脱敏失效与误判无关。 正确答案: B
13.某视频创作平台推出了一款AI视频生成工具,用户可以利用该工具快速制作高质量的短视频。然而,平台发现部分用户误将AI生成的视频当作真人创作。为了减少用户的误解,提升内容透明度,以下哪项措施最为有效? A. 对生成的视频进行加密处理,防止未经授权的传播 B. 使用数字水印技术标记视频的所有权 C. 不提供任何与AI生成相关的标识或声明 D. 在视频中添加明确的AIGC声明,提示内容由AI生成 相关知识点: A. 错误:加密处理主要用于版权保护。B. 错误:数字水印与解决误解无关。C. 错误:不提供标识会加剧误解。D. 正确:添加AIGC声明是最直接有效的透明化措施。
14.某医疗团队正在开发一个AI系统,用于分析患者的病历(文本)和医学影像(图片)。为了高效实现这一目标,选择以下哪种方案最为合适? A. 分别训练两个独立的单模态模型,一个处理文本,一个处理图片 B. 使用一个多模态大模型来同时处理文本和图片数据 C. 仅使用传统的深度学习模型进行图像分类 D. 手动标注所有数据后用规则引擎进行推理 相关知识点: A. 错误:单独训练两个模型难以整合信息。B. 正确:多模态模型能同时处理文本和图像。C. 错误:传统方法功能有限。D. 错误:规则引擎难以处理复杂数据。
15.某位热爱艺术的自媒体创作者想使用通义系列应用来帮助创作。请问他能够使用通义系列应用实现下列哪些操作? A. 通过给定“日落时分”的关键词,让通义千问模仿李商隐的风格生成一首诗歌 B. 使用一张风景照作为视频的第一帧,并结合“日落时分”的提示词,自动生成一段展示日落变化过程的视频 C. 可以使用通义万相生成一张“日落时分”的图像,并且在图像中包含“夕阳无限好”这几个准确的文字 D. 使用一张人像,让通义万相在兼顾原始人物相貌的同时进行多种风格化的重绘 相关知识点: A. 正确:通义千问支持文本生成。B. 正确:通义万相支持视频生成。C. 正确:通义万相支持生成包含文字的图像。D. 正确:通义万相支持风格化重绘。
16.某零售公司希望大模型帮助分析其2023年的销售数据,重点关注季节性和区域差异。以下哪两个提示词最有效? A. 请分析2023年销售额的变化趋势 B. 分三步分析:1. 按季度计算增长率并绘制趋势图;2. 对比各区域销售额占比变化;3. 结合节假日和促销活动总结驱动因素。 C. 示例:2022年分析步骤:1. 按月对比销售额;2. 排查异常值;3. 综合结论。问题:请根据2023年数据特点,调整步骤后分析。 D. 请分析2023年销售额的增长情况,并列出所有可能的原因。 相关知识点: A. 错误:过于笼统。B. 正确:提供了具体分析框架。C. 正确:参考示例有助于引导分析。D. 错误:过于宽泛。 正确答案: B C
17.用户向银行智能客服提问"转账被卡在中间状态",但智能客服无法回答。你发现知识库中包含相关内容,但仅出现"滞留""挂账"等术语,导致无法匹配"卡在中间"等口语表达。以下哪三种方案更有利于批量解决此类问题? A. 让大模型对用户的口语问题改写为内部术语,再进行RAG问答 B. 优化向量模型的语义理解能力,增强对口语化表达的捕捉能力 C. 用文档增强技术自动扩展口语化同义词 D. 要求用户使用专业术语提问 相关知识点: A. 正确:改写口语问题为内部术语。B. 正确:优化语义理解能力。C. 正确:扩展同义词库。D. 错误:要求用户使用术语体验差。
18.某客服系统需快速部署一个支持多语言对话的AI助手,但开发周期紧张且计算资源有限。以下哪些方法能同时满足“快速迭代”和“低资源消耗”的要求? A. 全参微调:基于多语言数据重新训练整个模型。 B. LoRA:仅优化低秩矩阵旁路参数,冻结原模型权重。 C. 强化学习:通过用户反馈持续优化模型策略。 D. 提示工程(Prompt Tuning):设计高质量提示词引导模型输出。 相关知识点: A. 错误:全参微调资源消耗大。B. 正确:LoRA降低资源消耗。C. 错误:强化学习资源消耗大。D. 正确:提示工程快速优化性能。 正确答案: B D
19.某团队微调了一个医疗问答模型,计划在真实场景部署前进行全面评测。以下哪些做法是必要的? A. 在测试集上评估模型回答的准确率 B. 统计模型推理时的GPU显存占用 C. 通过人工审核判断回答的医学专业性 D. 仅依赖训练集损失函数值判断模型效果 相关知识点: A. 正确:测试集评估是关键指标。B. 正确:了解资源消耗有助于部署优化。C. 正确:人工审核判断专业性。D. 错误:仅依赖训练集损失不可靠。 正确答案: A B C
20.某科技公司计划开发一款智能家居助手,能够通过语音指令控制家电,并通过文本形式实时反馈设备状态。以下哪些技术或方法适合实现这一目标? A. 使用单一模态模型分别处理语音和设备状态数据 B. 使用多模态大模型同时处理语音和设备状态数据 C. 在本地设备上部署小模型完成简单任务,云端部署大模型完成复杂任务 D. 仅使用传统规则引擎解析语音指令并控制设备 相关知识点: A. 错误:单一模态模型功能有限。B. 正确:多模态模型能同时处理语音和状态。C. 正确:本地小模型+云端大模型结合高效。D. 错误:规则引擎难以应对复杂任务。





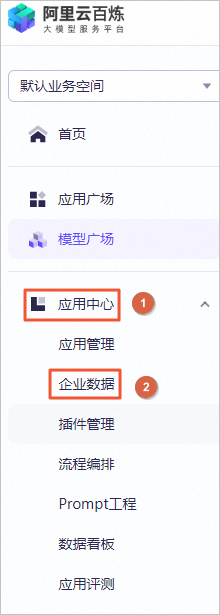
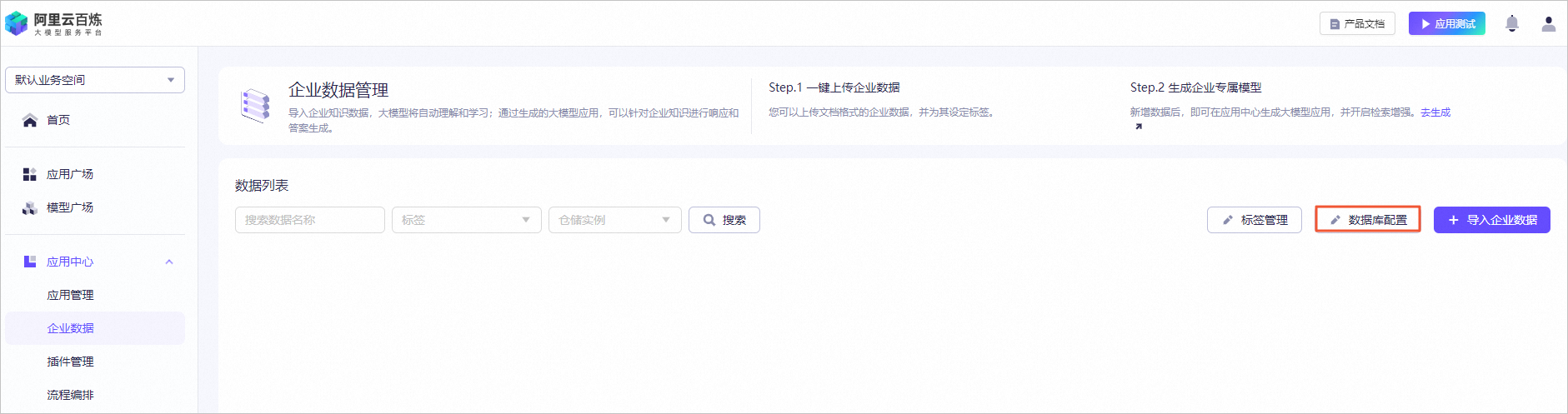
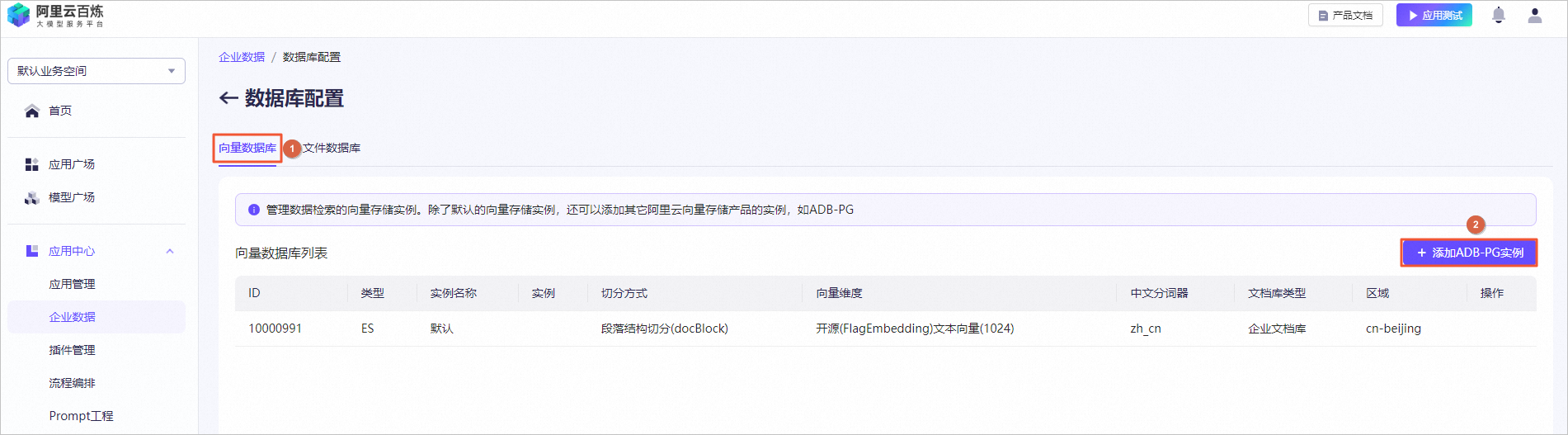
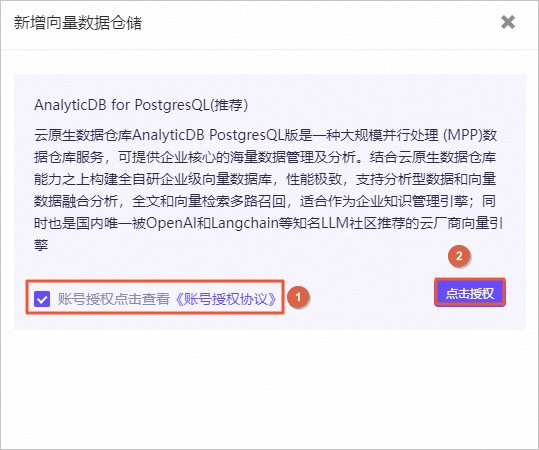
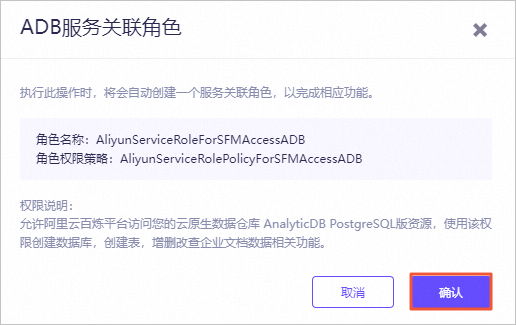
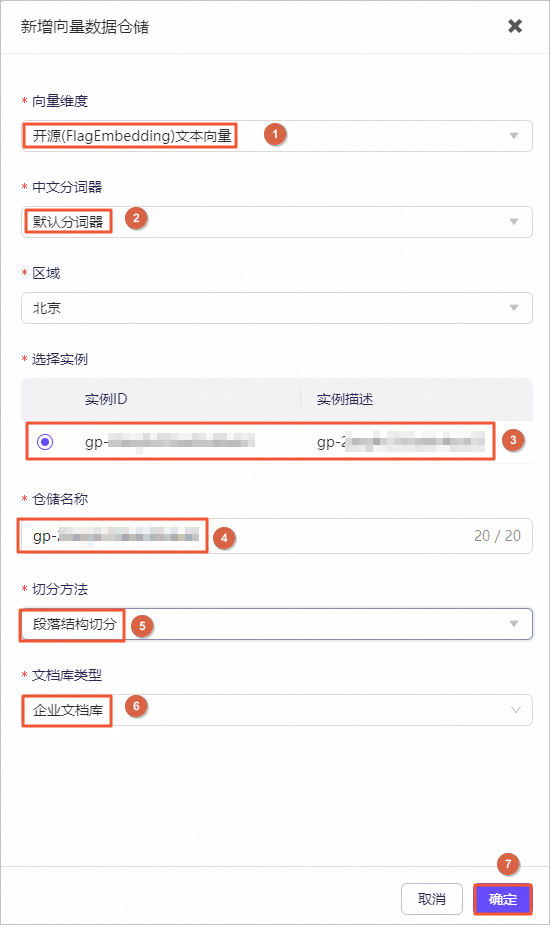
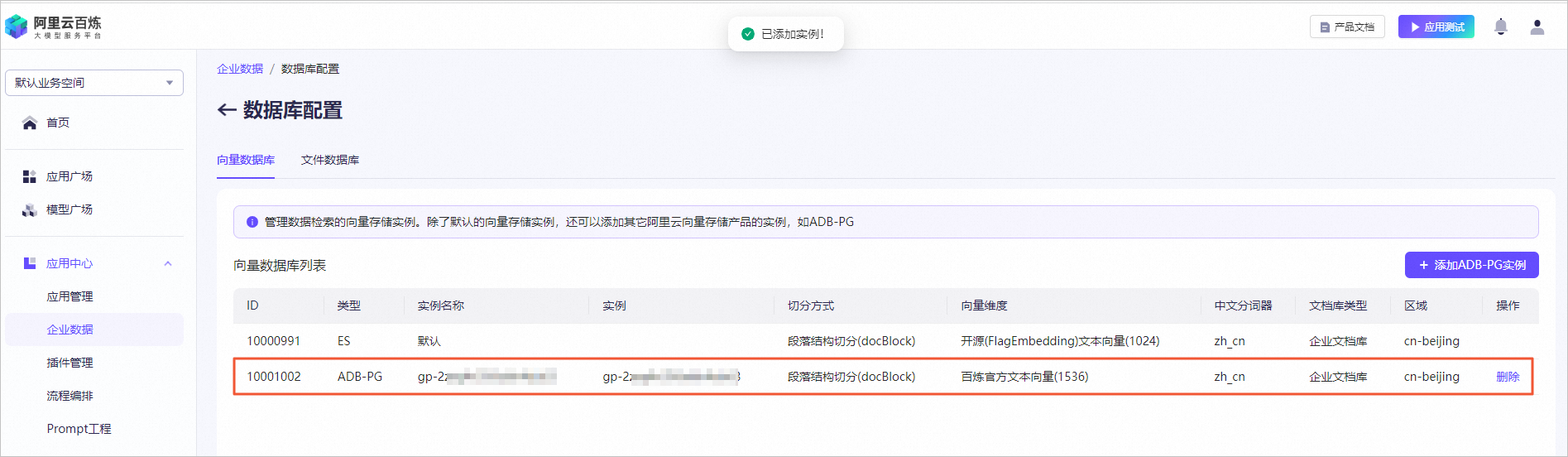
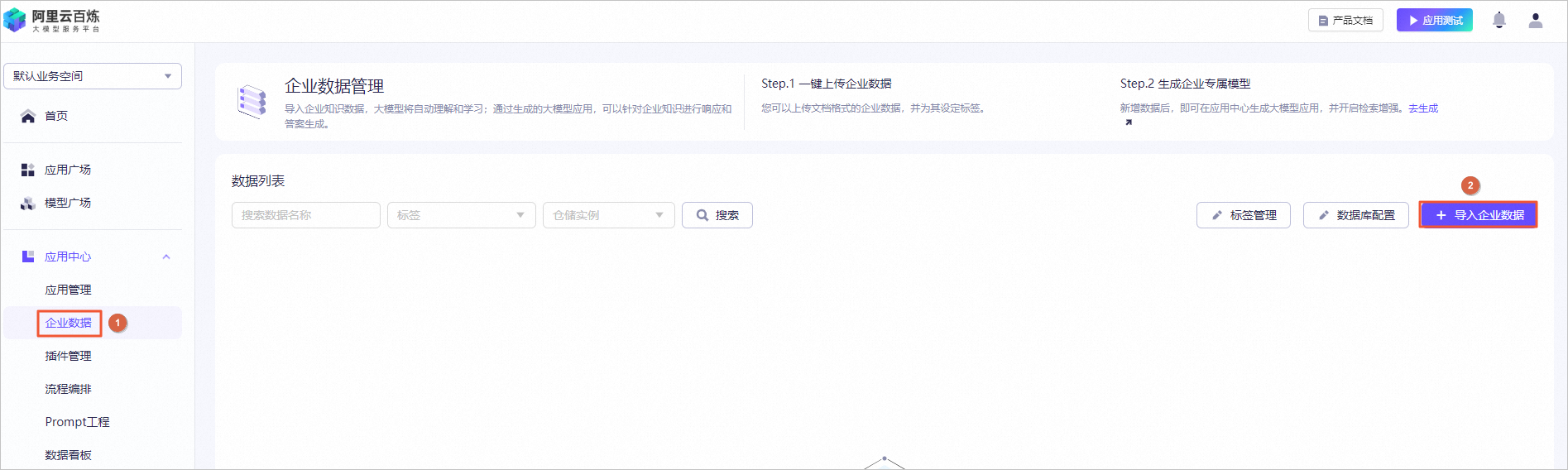
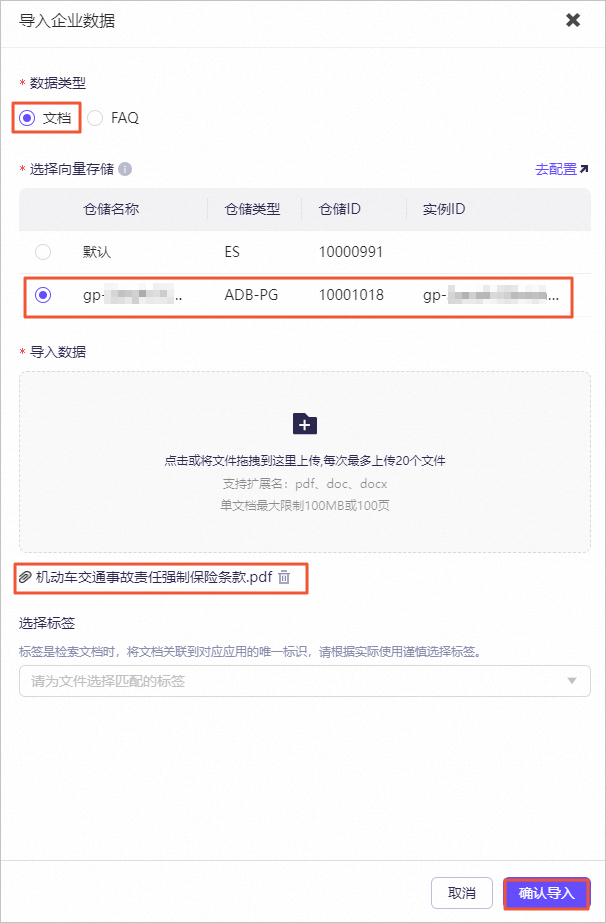
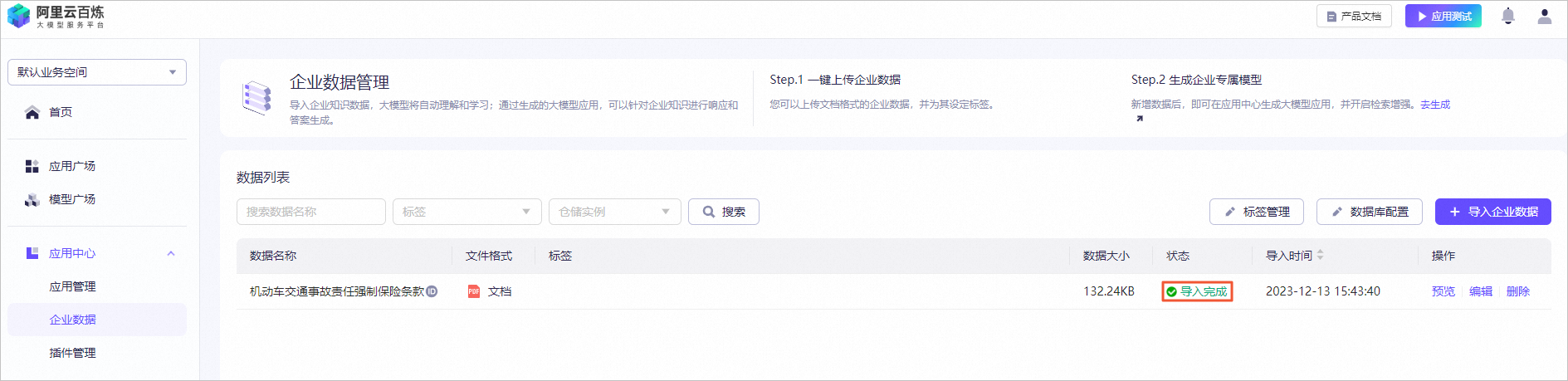
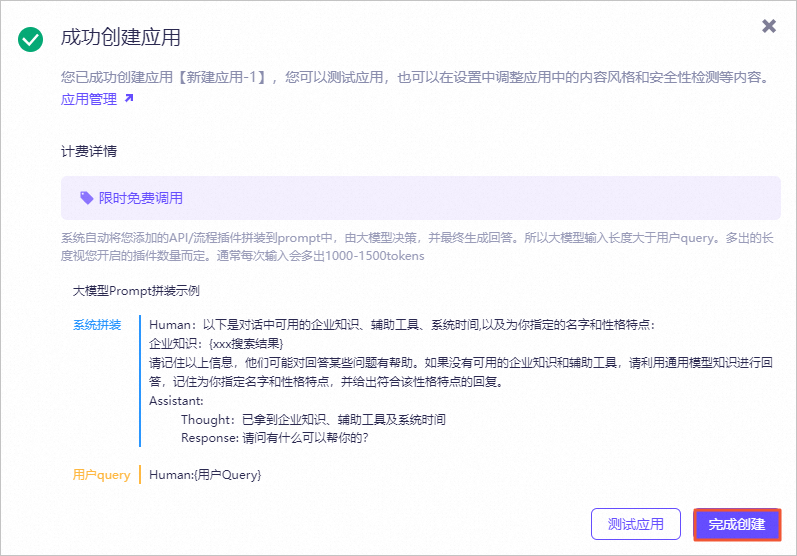
 图标,验证模型机器人回复的答案内容。例如,输入投保人、被保险人义务。
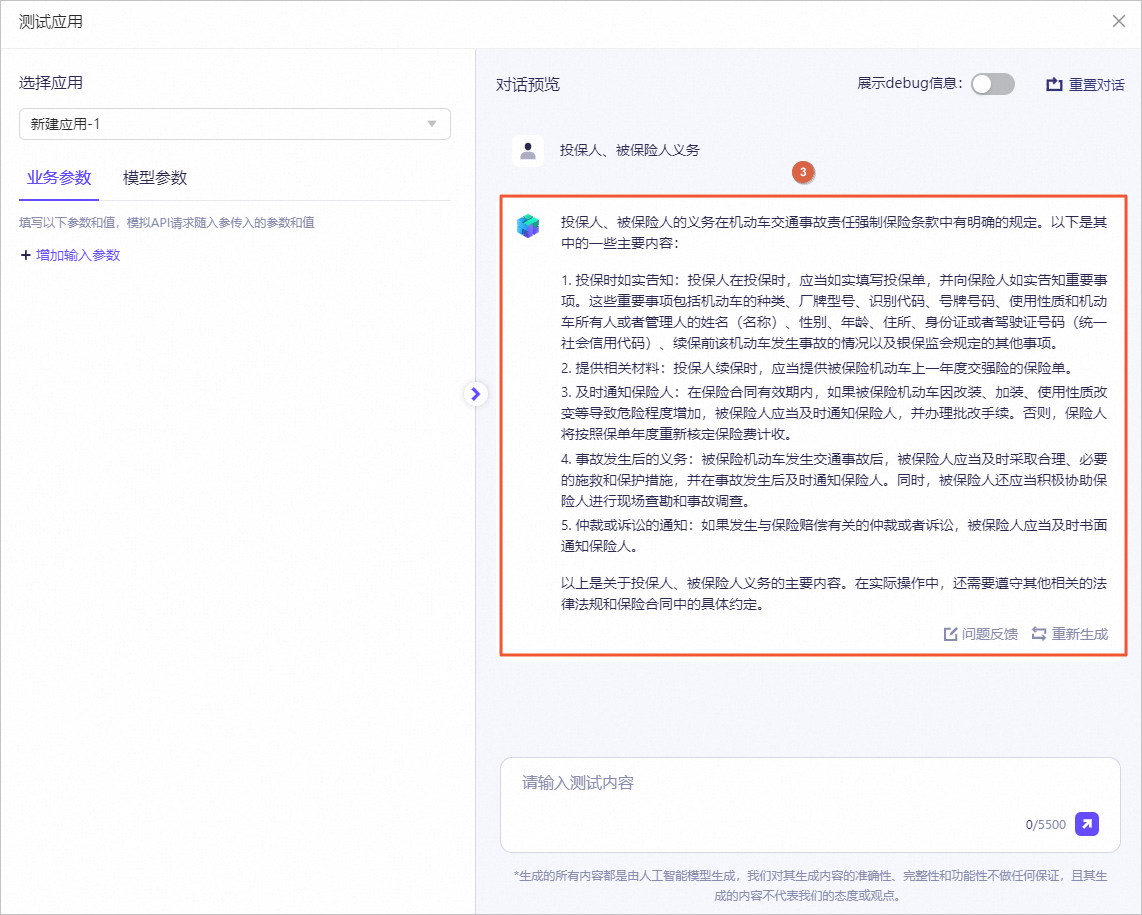
图标,验证模型机器人回复的答案内容。例如,输入投保人、被保险人义务。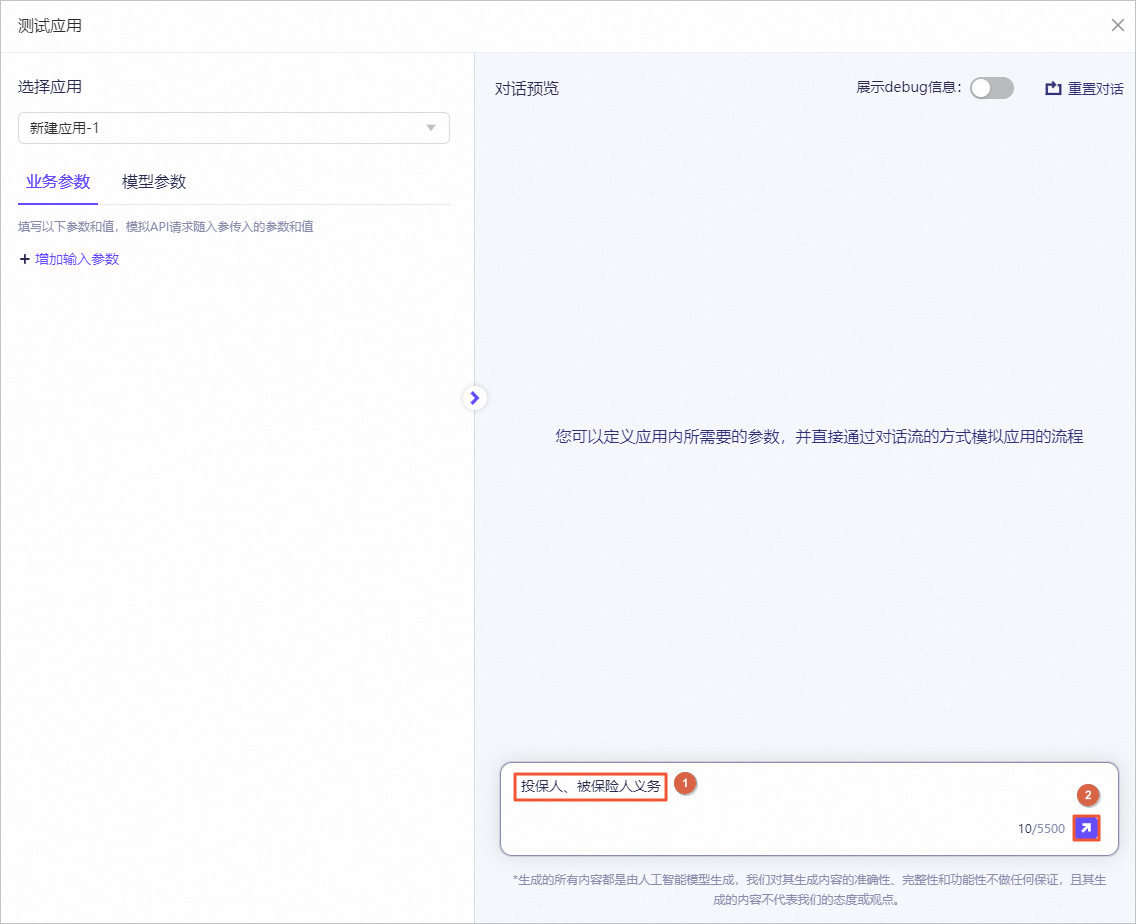
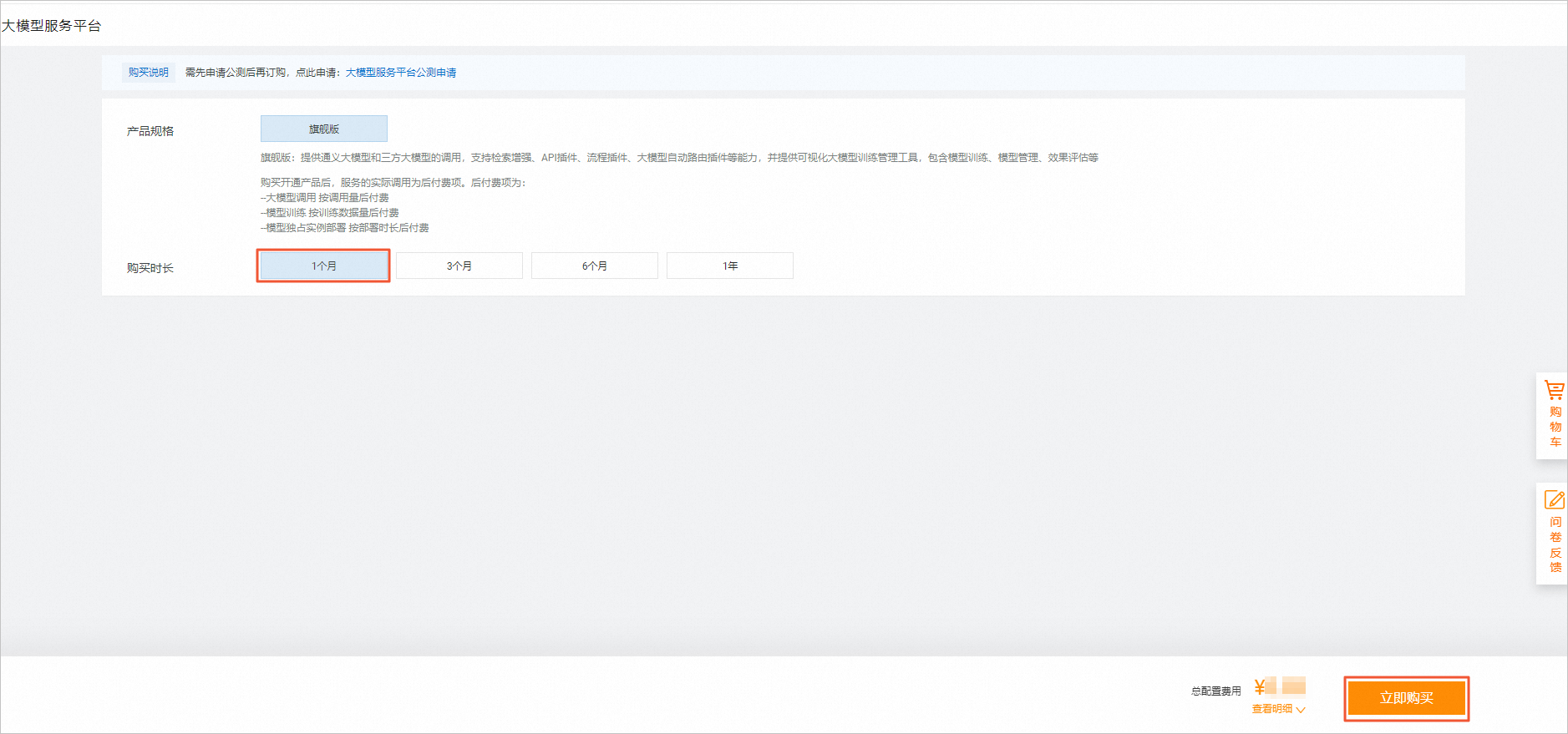
 大模型服务平台百炼
大模型服务平台百炼 云原生数据仓库 AnalyticDB PostgreSQL版
云原生数据仓库 AnalyticDB PostgreSQL版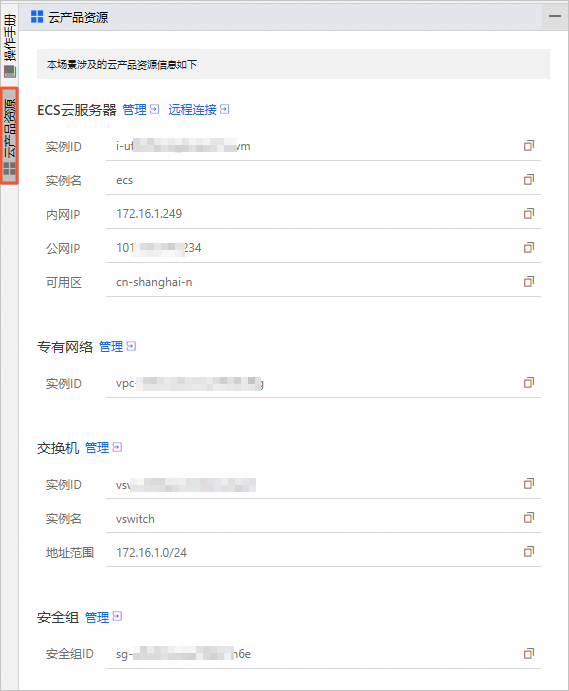



 浙公网安备 33010602011771号
浙公网安备 33010602011771号