

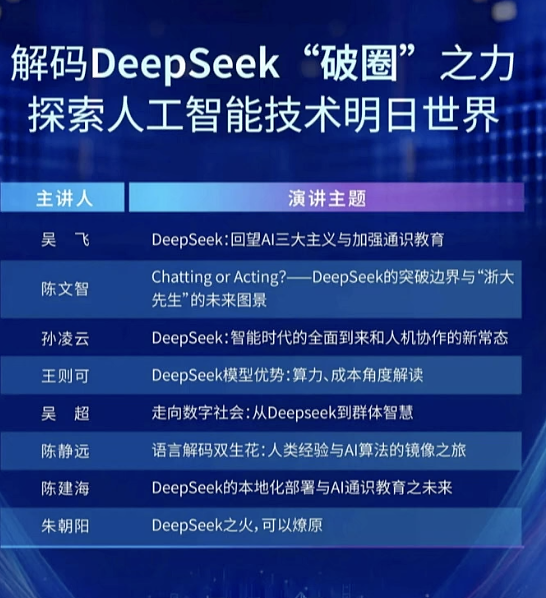
浙大-人工智能 mooc317
|
浙大-人工智能 肖俊
渗透与再生: 大模型生态下Al+X产业新触角
|
|
|
浙江大学DeepSeek系列专题线上公开课 (第二季)
思维链 CoT
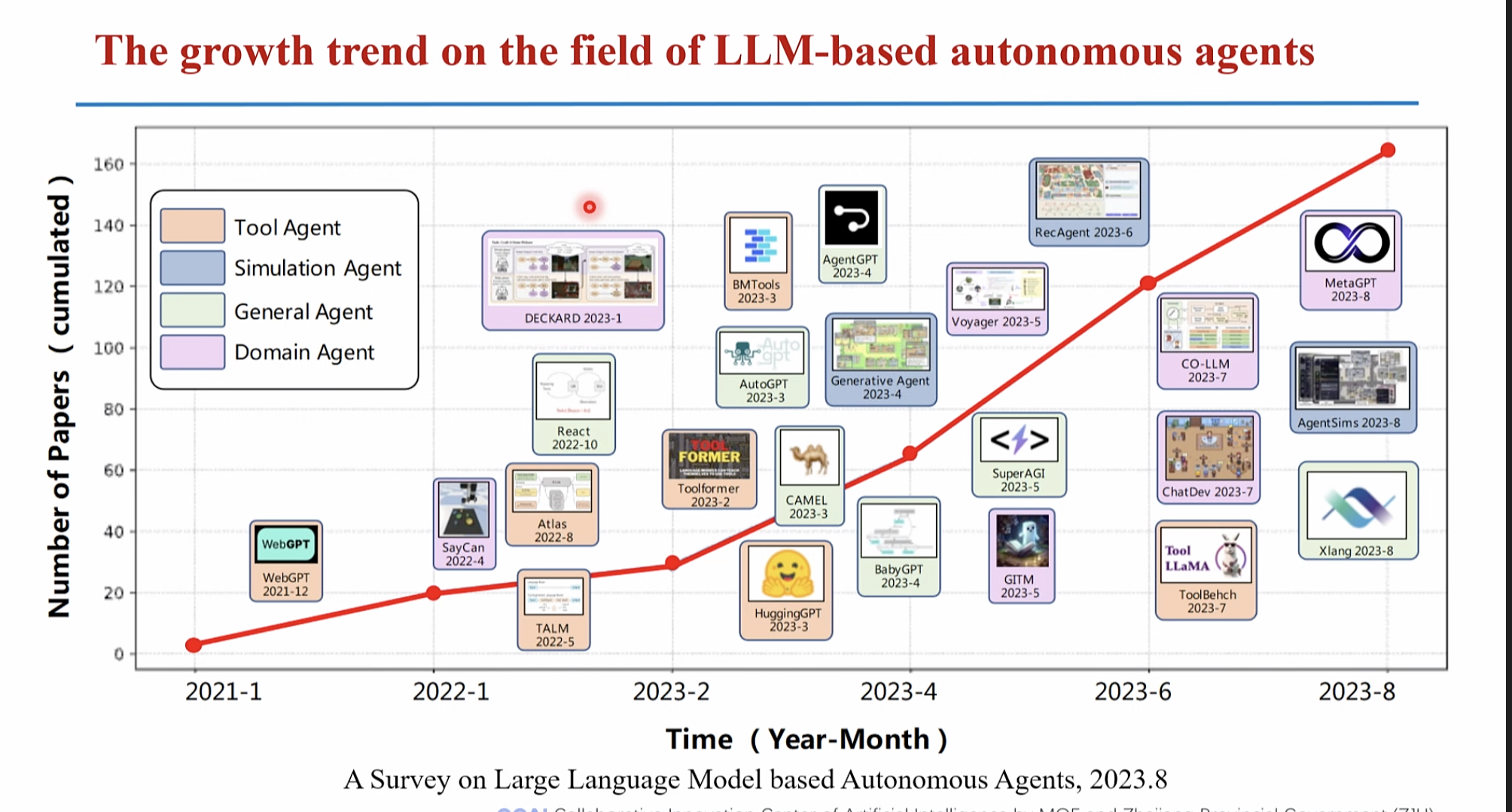
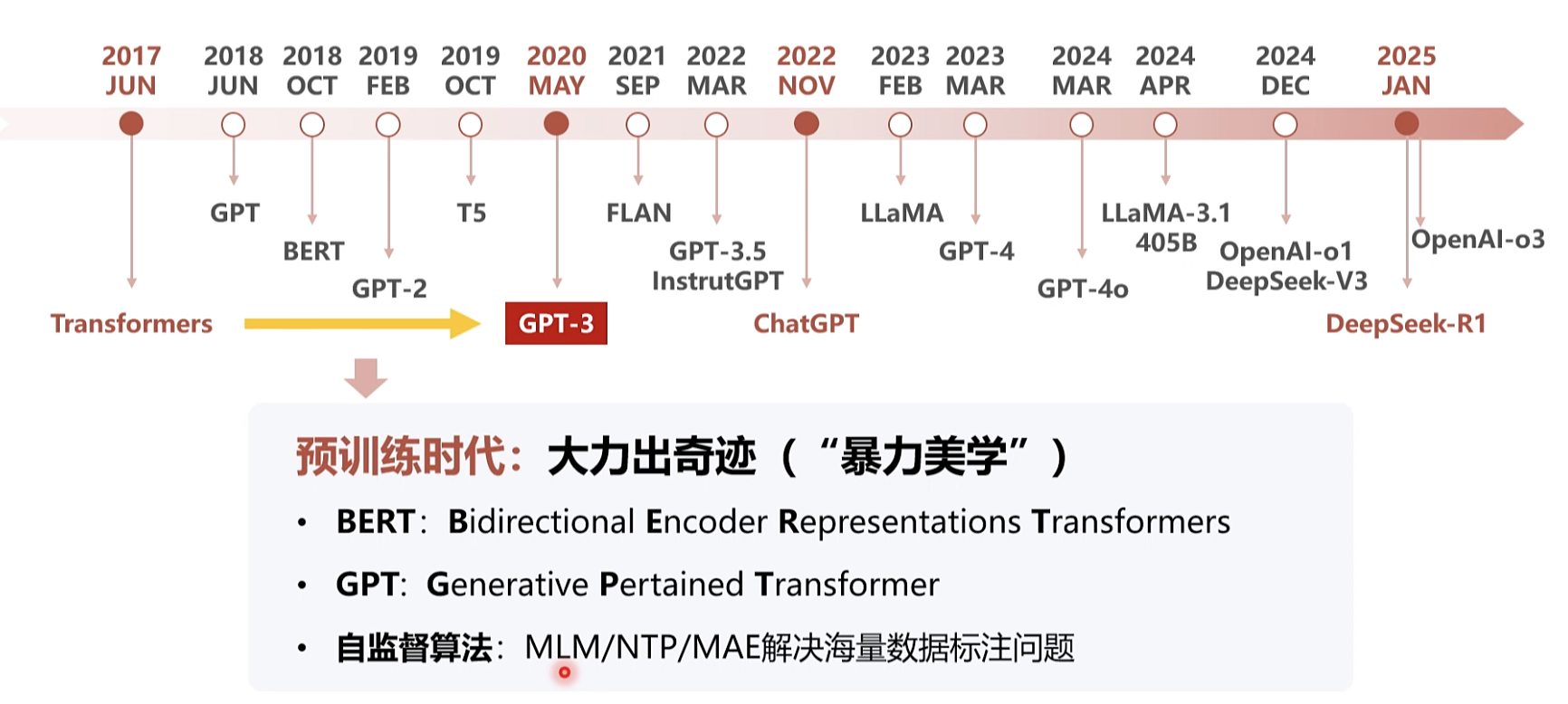
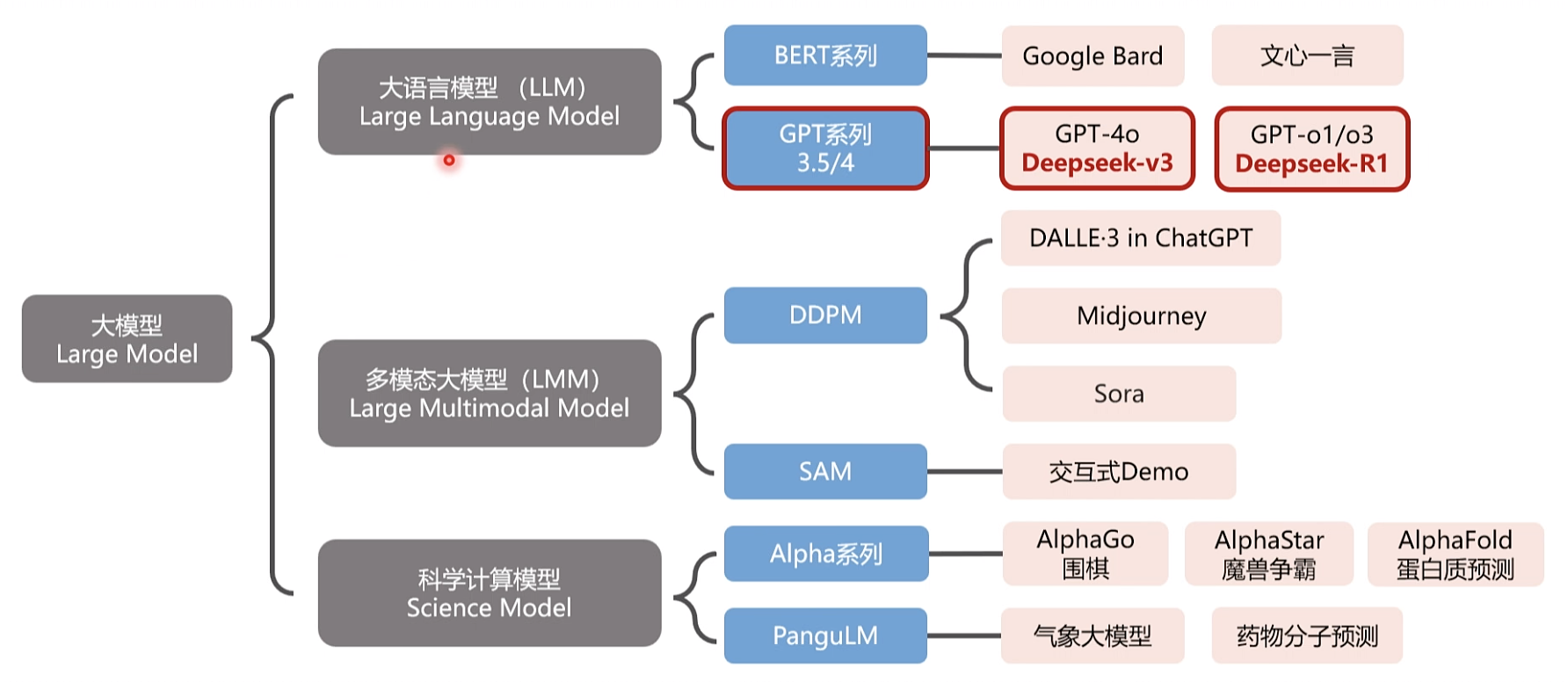
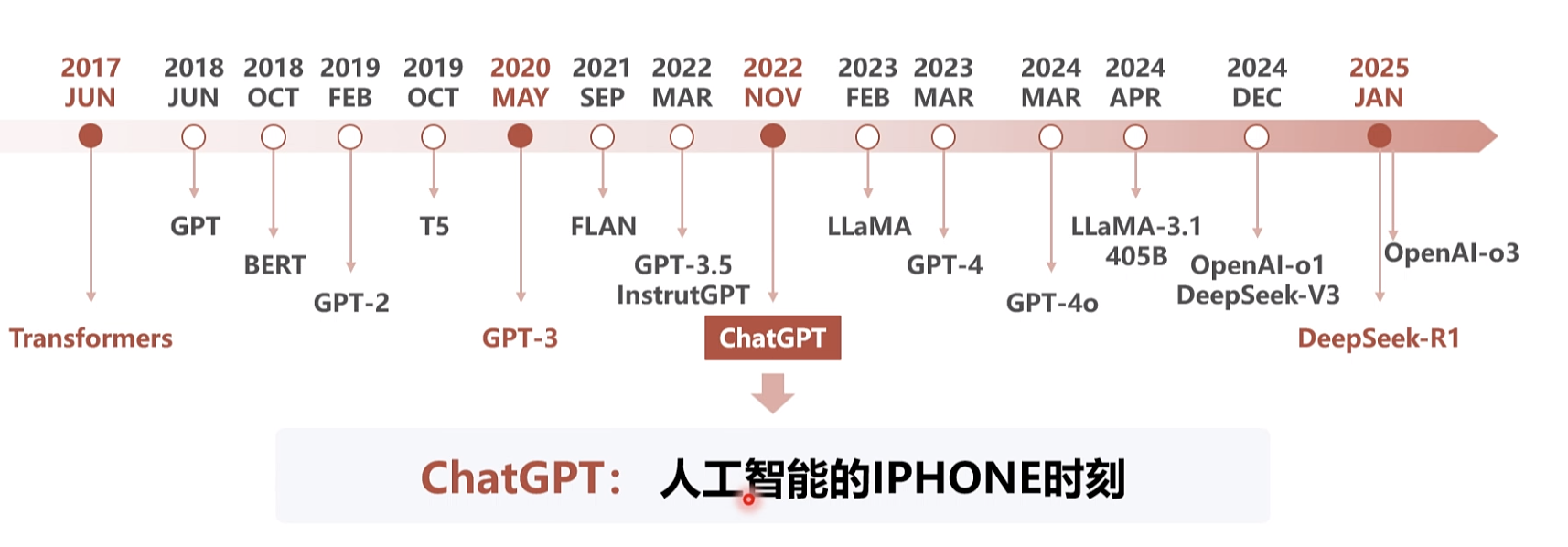
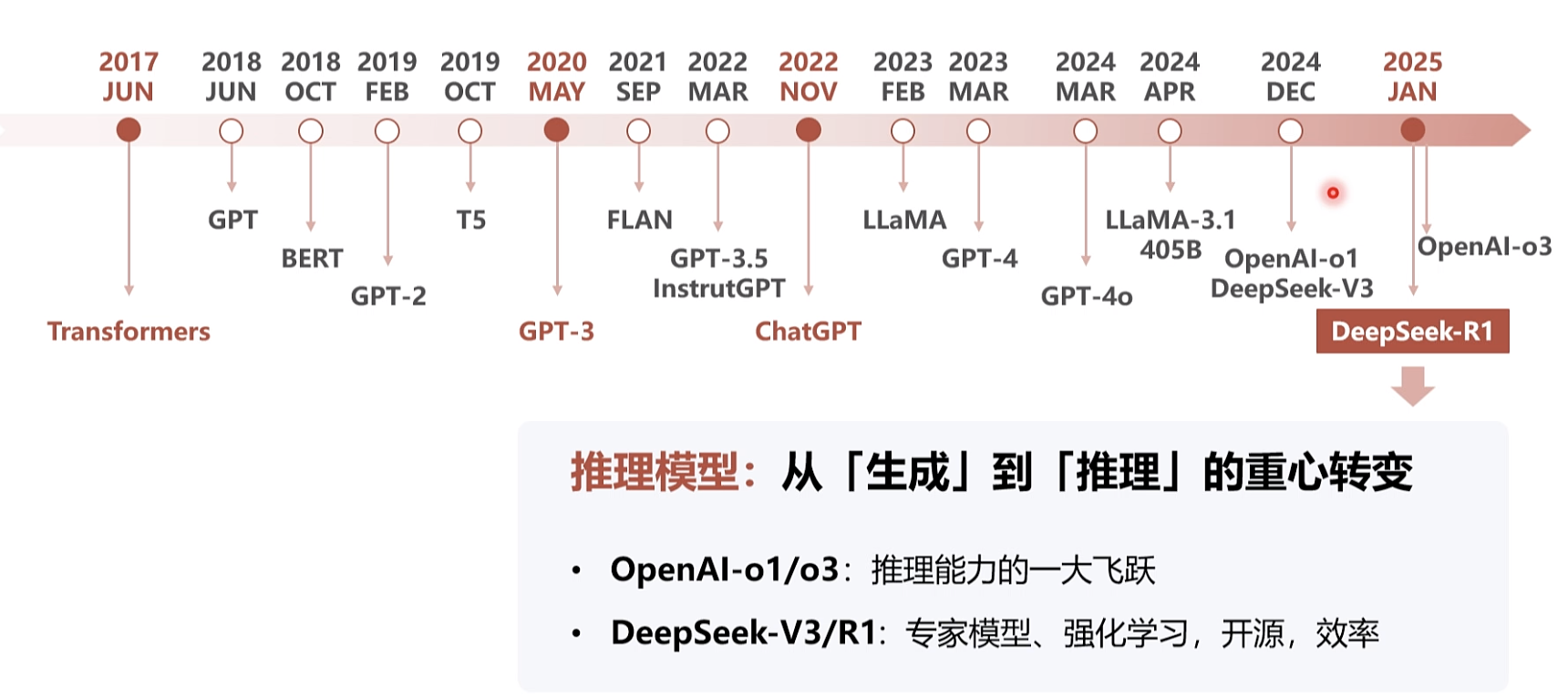
大模型的产生快速回望历史
自回归
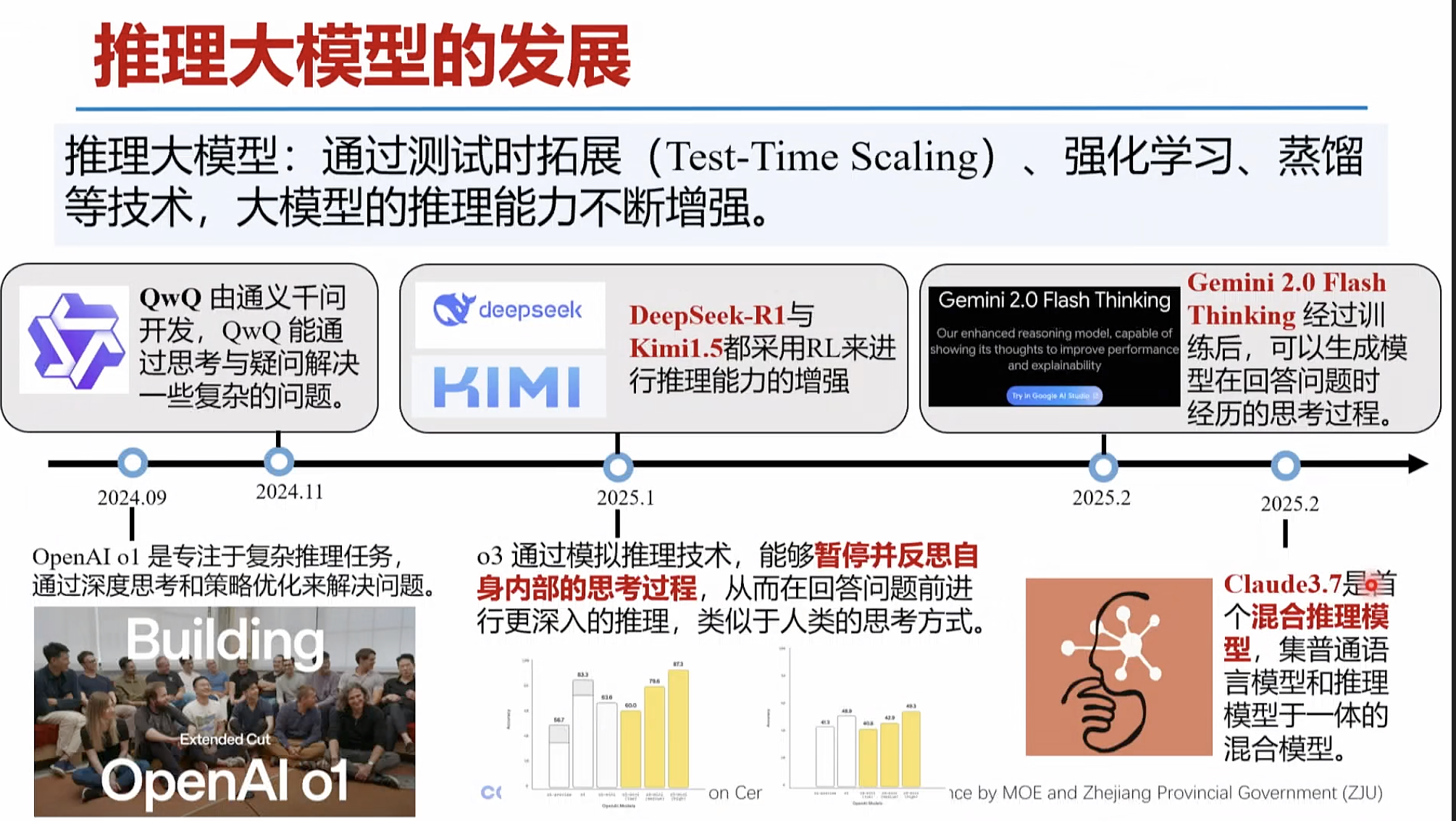
横空出世: OpenAI 01/03、DeepSeek-R1等
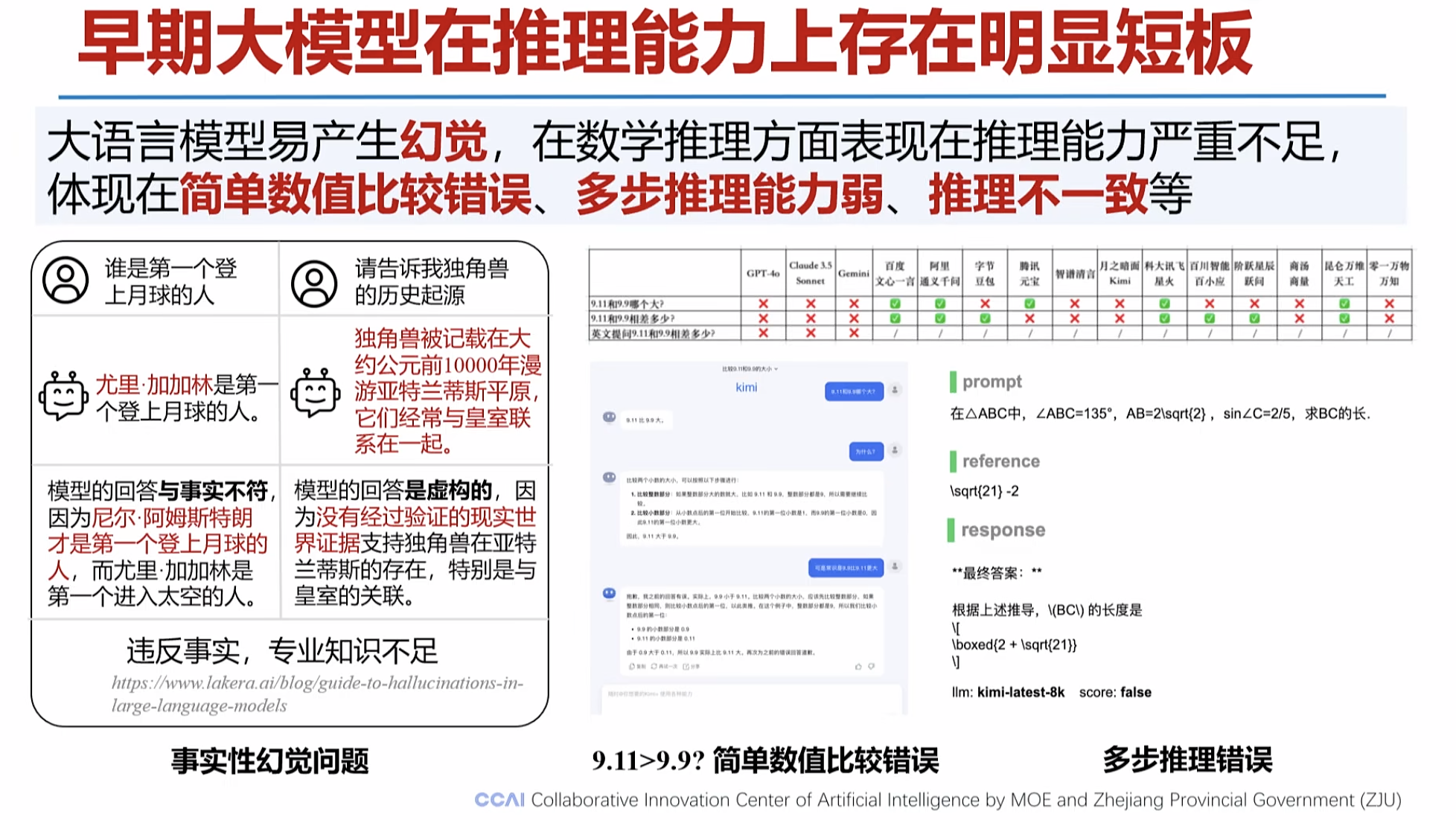
1。早期的大模型推理能力不足
推理提升的 原因
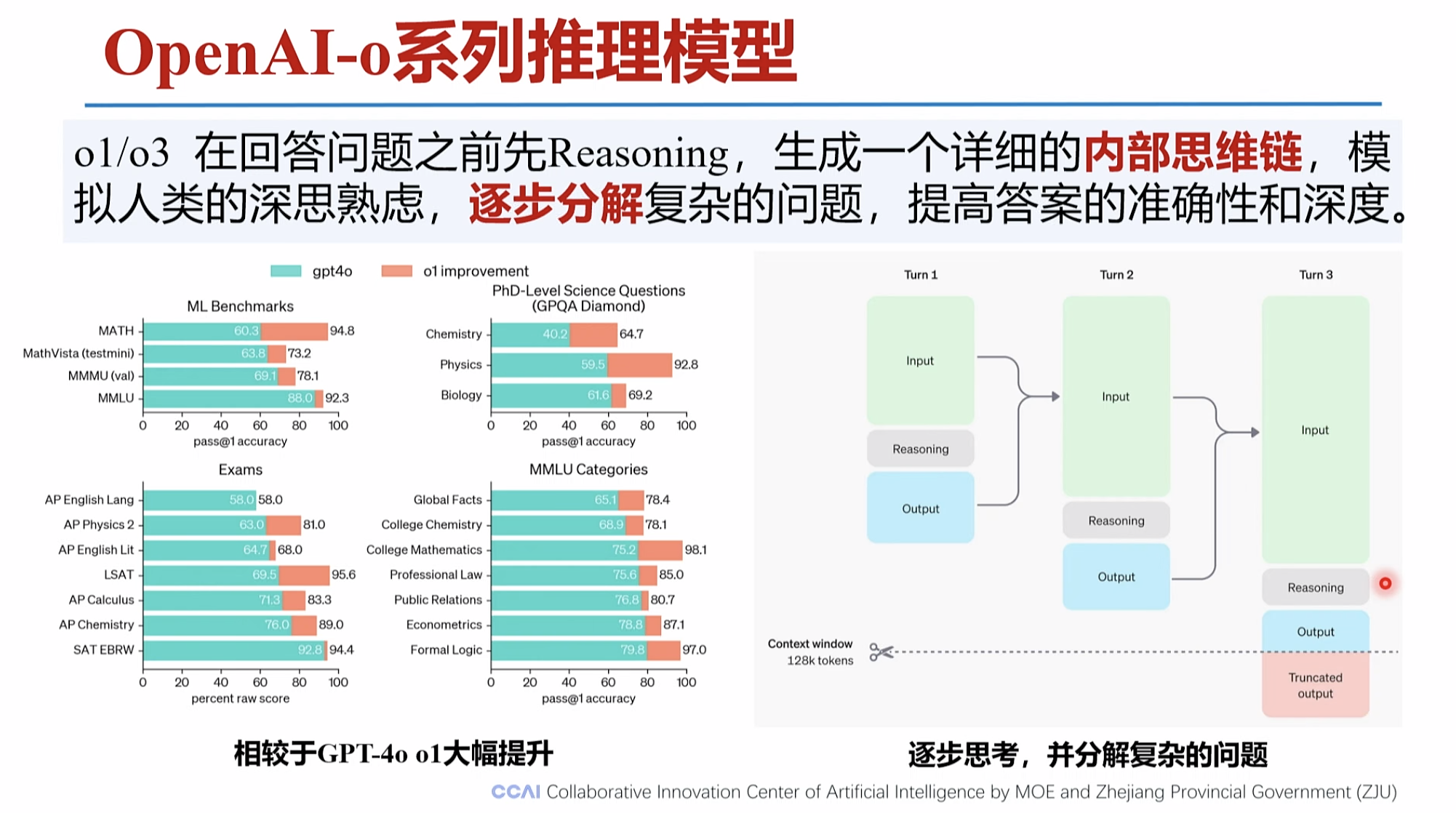
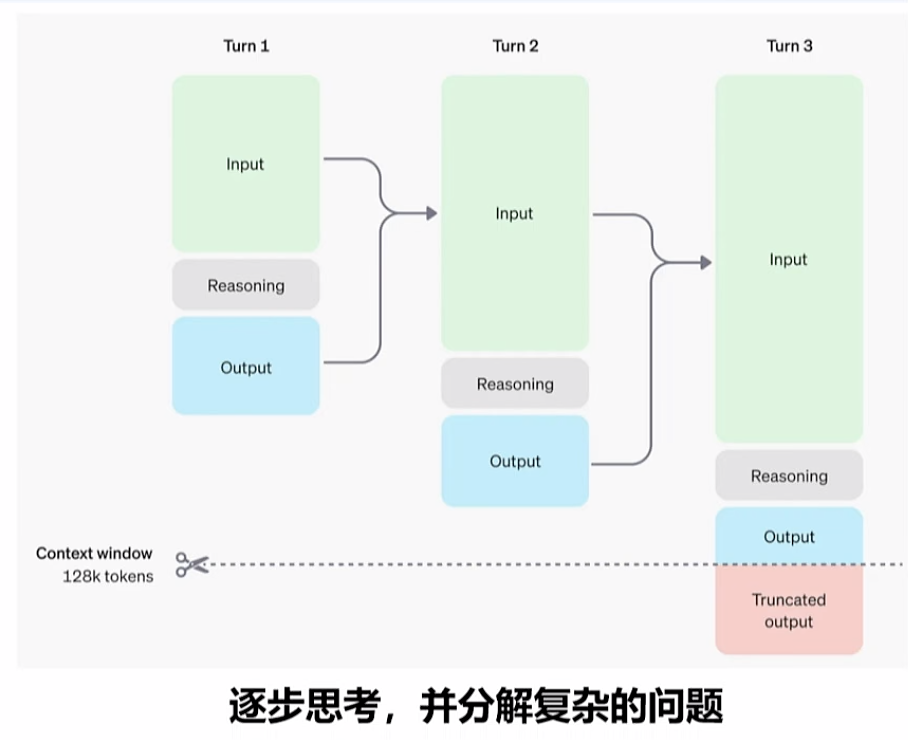
o1 ,o系列回答前, 会有内部思维链的 生成。
偷懒是人类社会进步的原动力
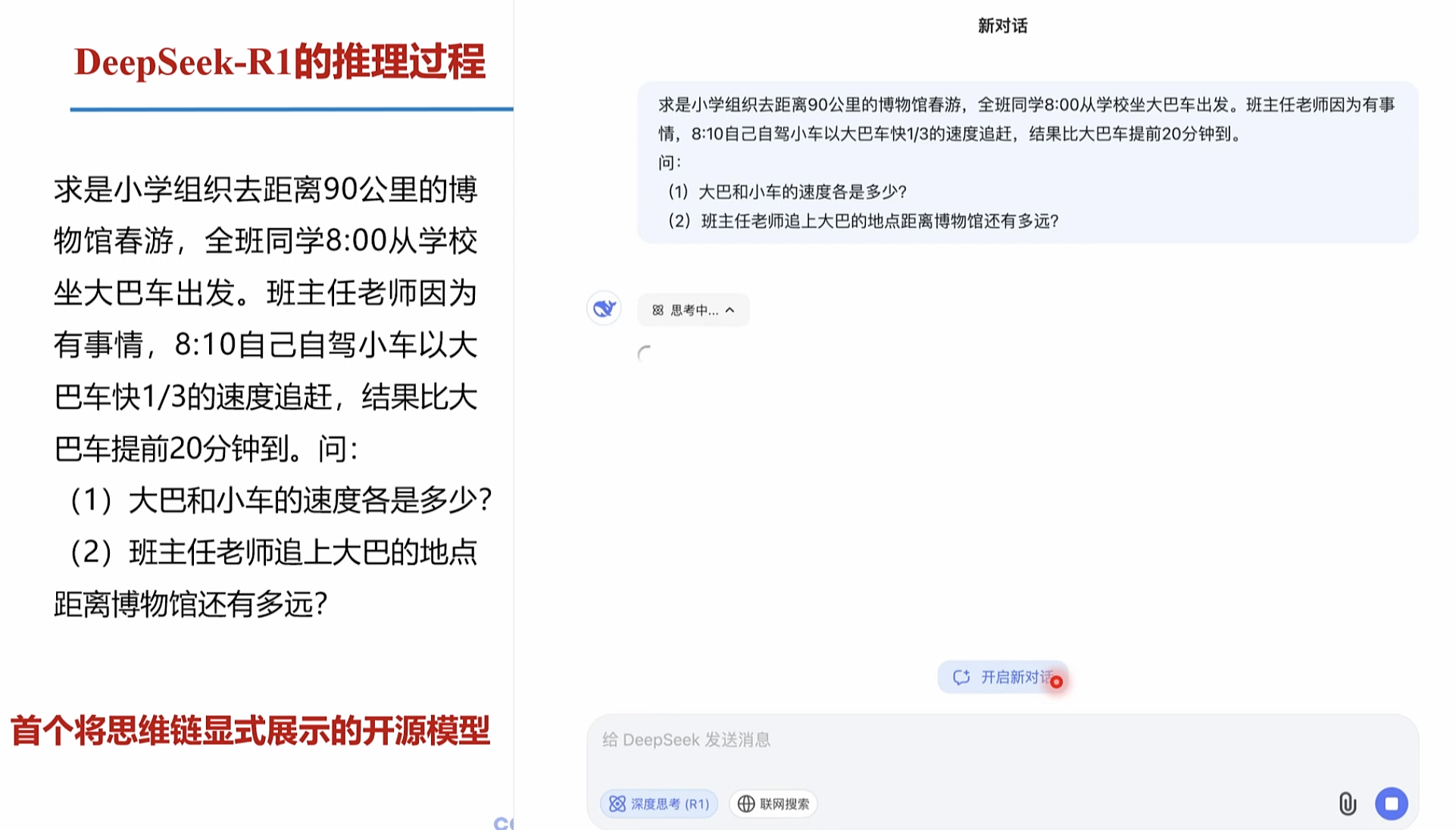
DeepSeek-R1的推理过程
深思考的过程,就是思维链展示的过程。 减少的错误的发生比例
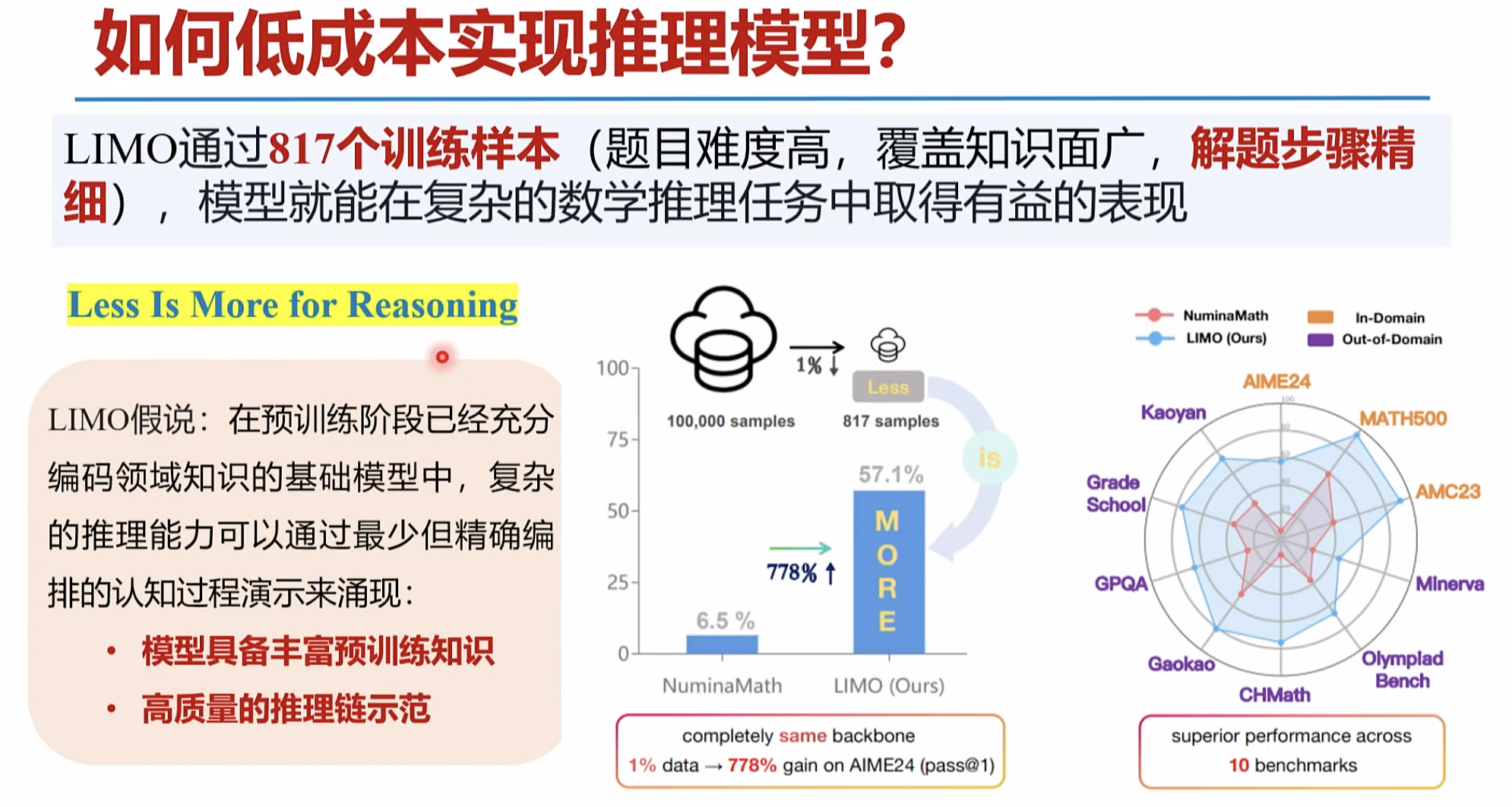
李飞飞 1000条数据 微调
https://codeium.com/refer?referral_code=f6r9dihmdd9ctmy1
|
|
|
二1,自动化思维链(CoT)的实现是新一代大模型的精髓之-经过精心设计的少量高质量样本即可实现适用于某个专业领域
2.的高性能低成本推理模型
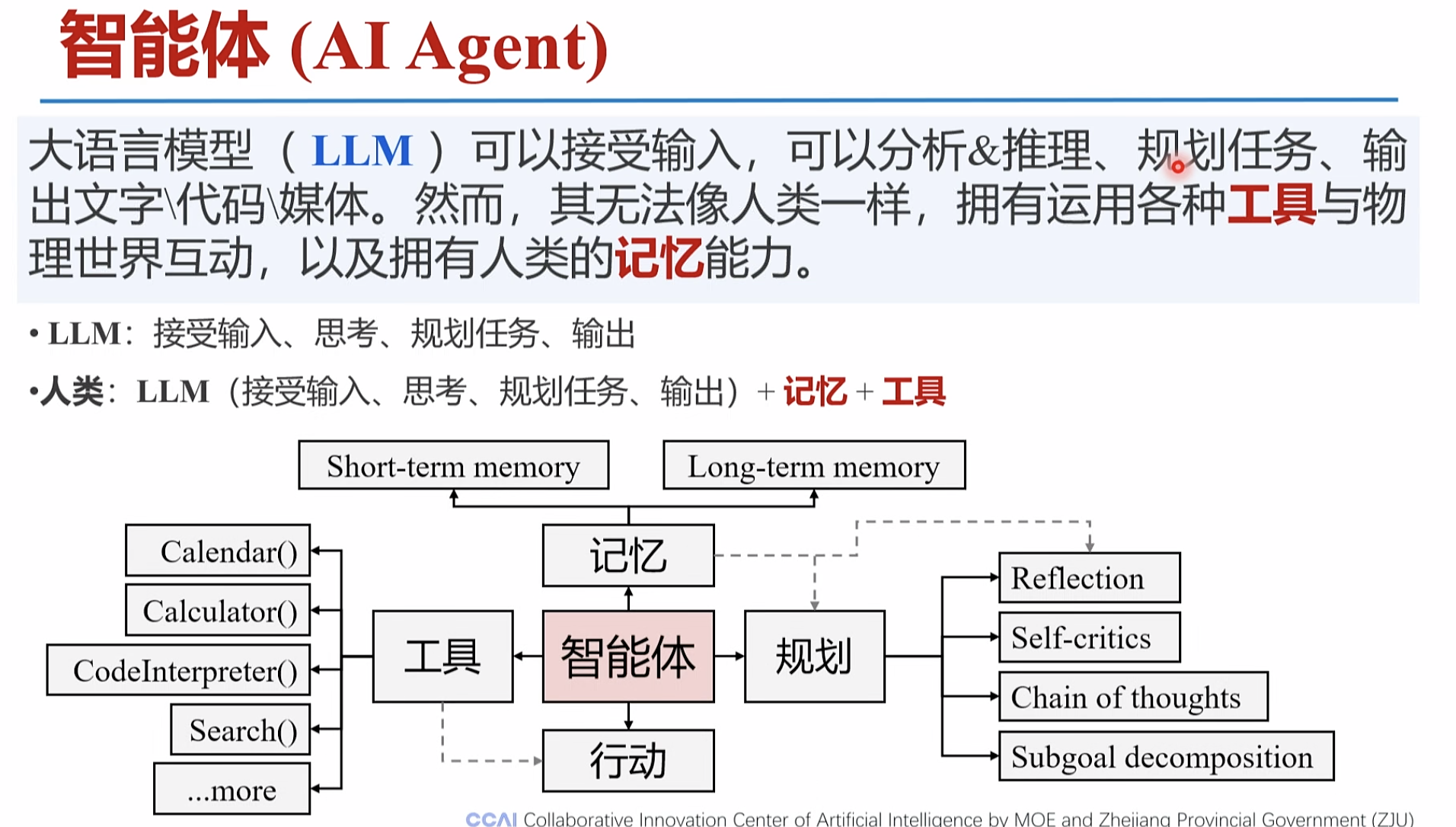
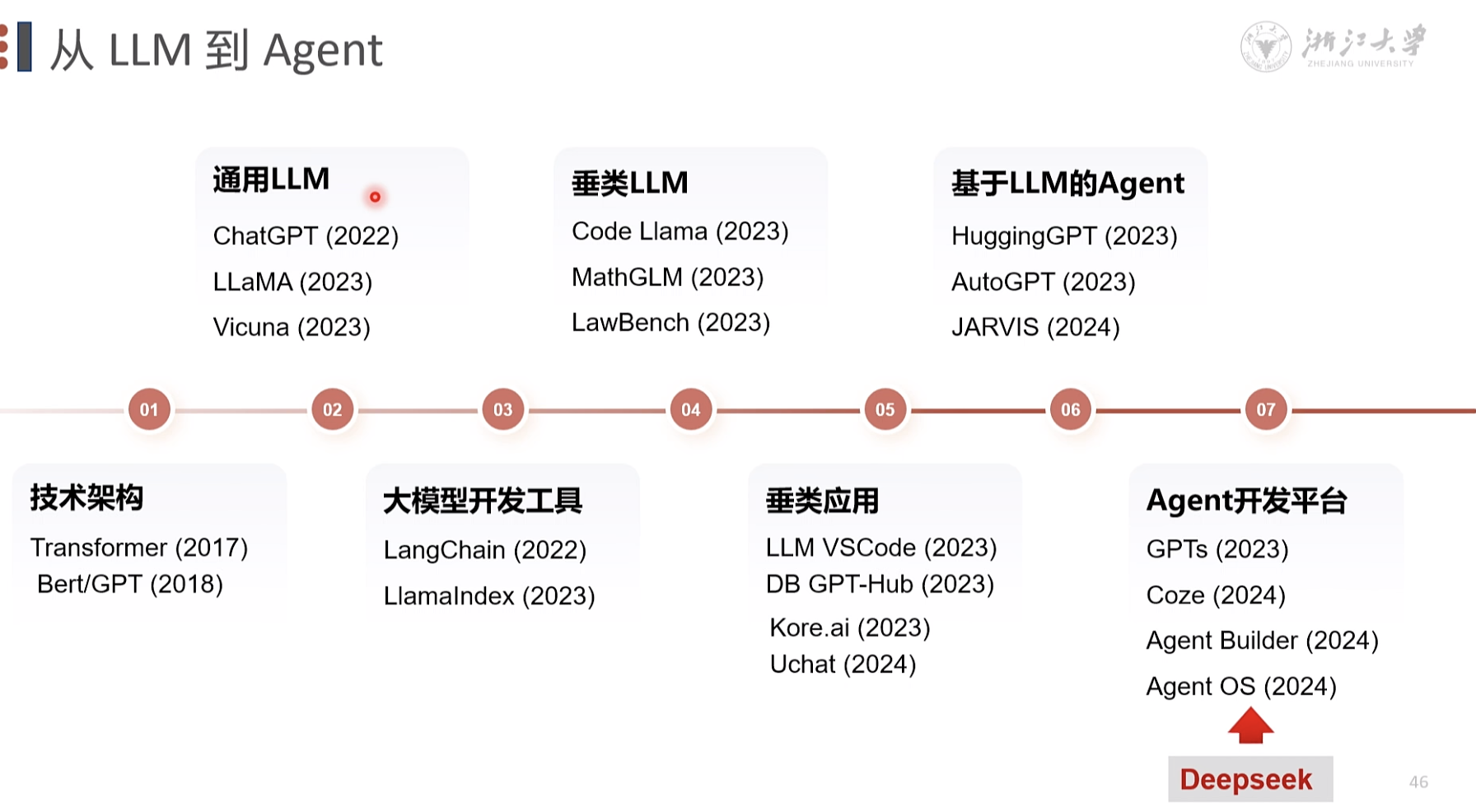
智能体(AIAgent) 是什么?
自动化工作链路
软件系统。 和大模型互动,调用软硬件工具,链接交互 为大模型提供记忆
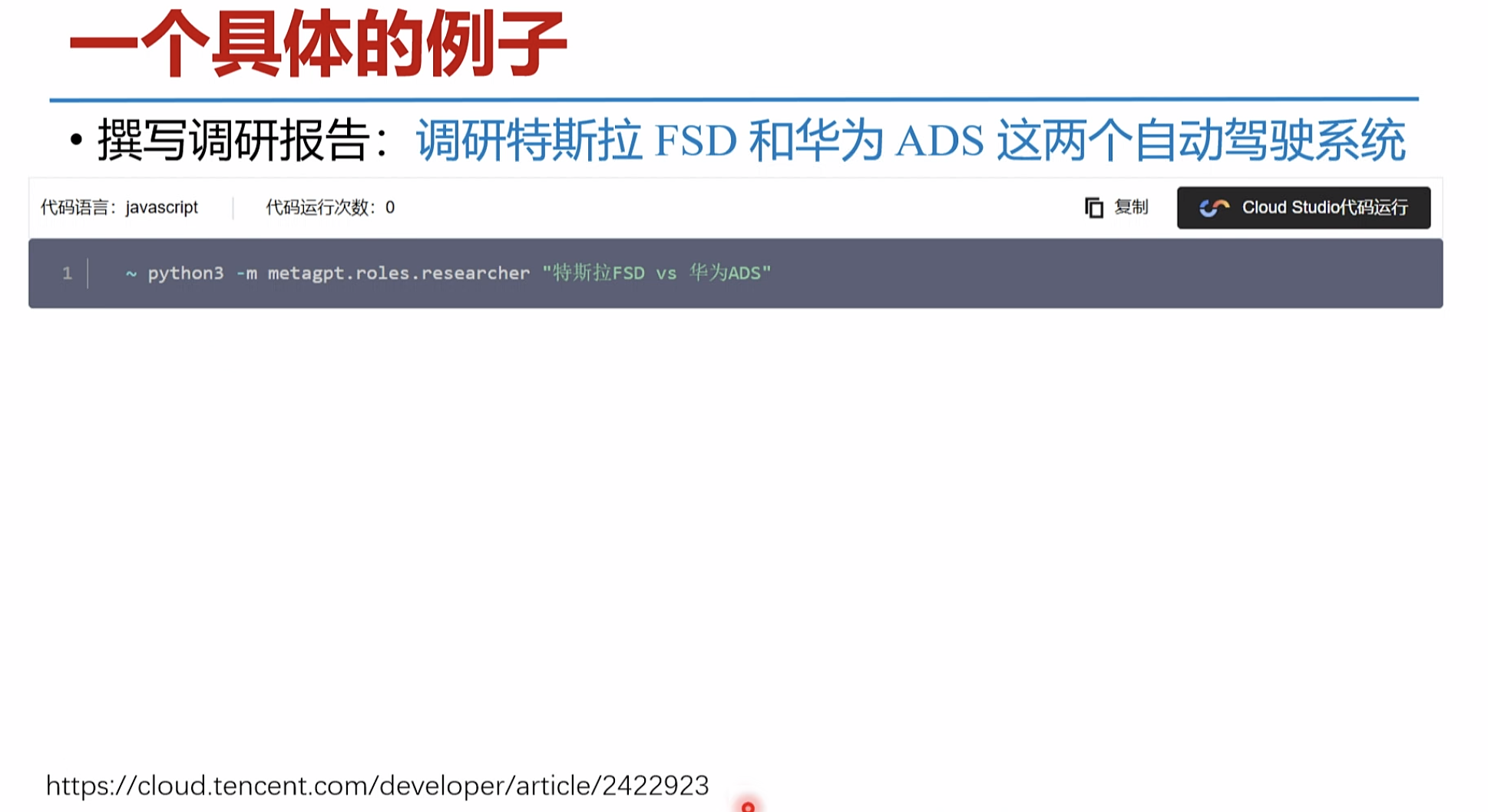
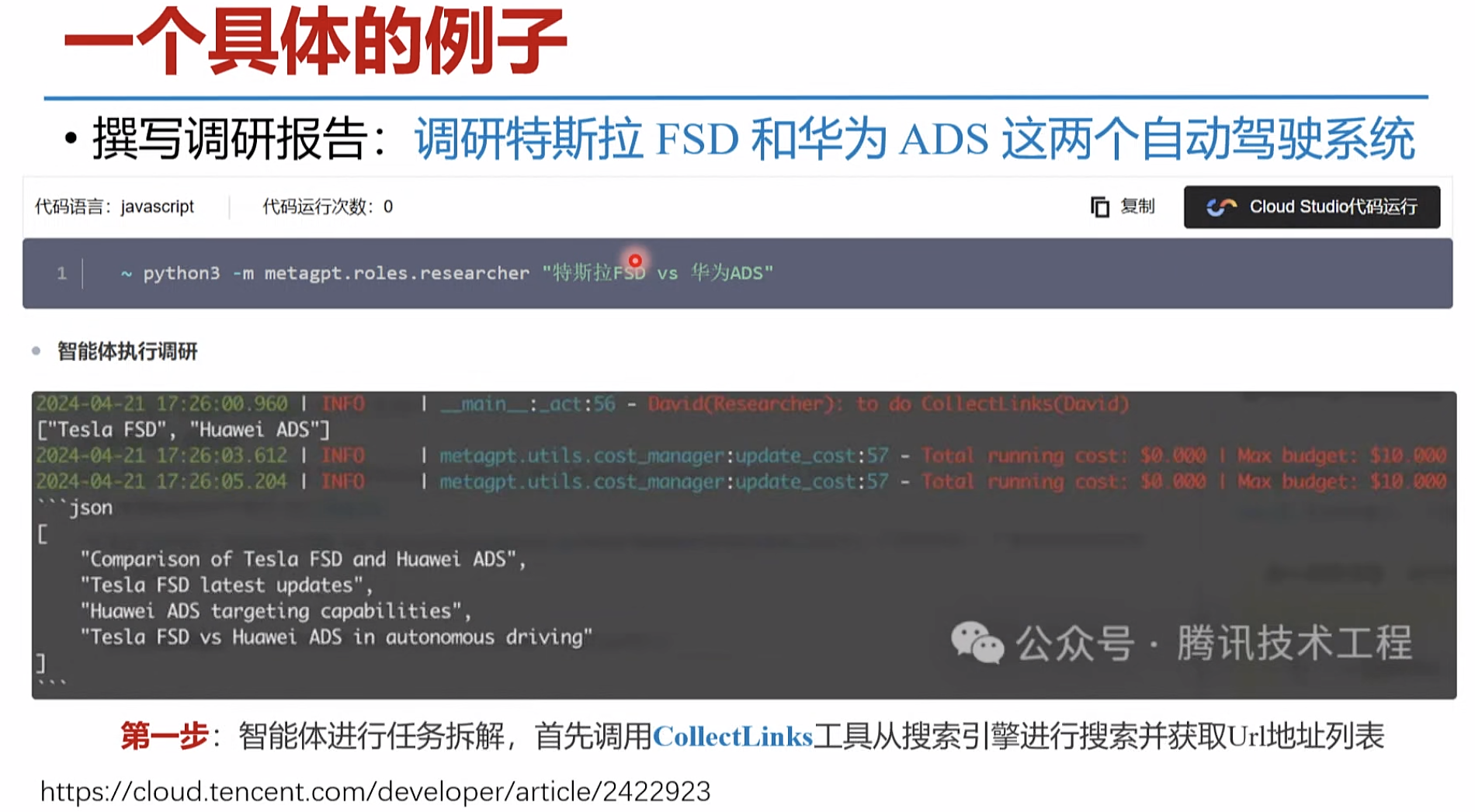
智能体的讲解案例 https://cloud.tencent.com/developer/article/2422923
爬取网页 大模型阅读整理。 生成 报告
一个具体的例子
智能体
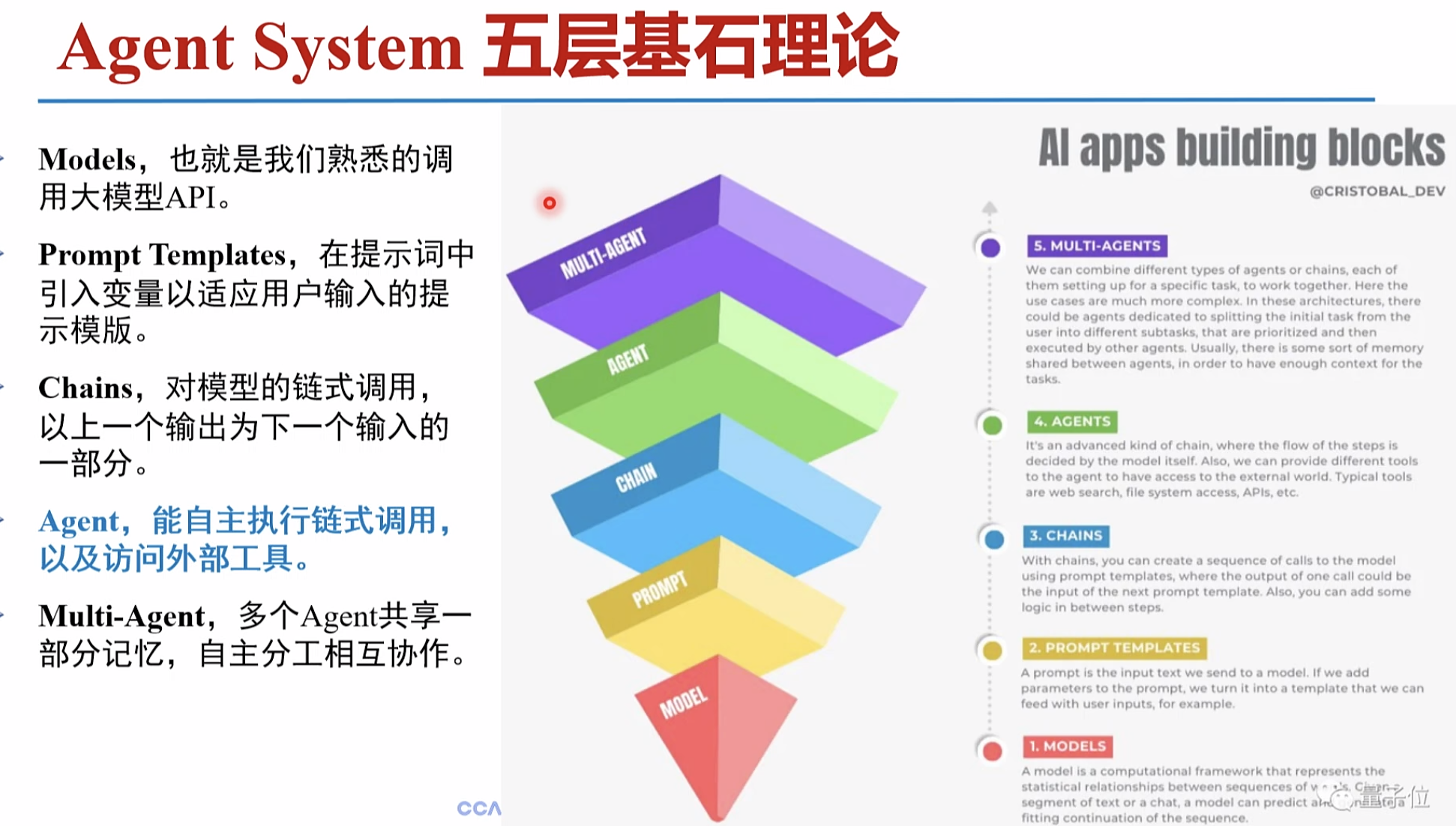
大模型 支持api 提示词 模板支持 模型 链式调用 输出 迭代到输入 访问外部工具 多个
智能体,帮助大模型感知世界,做出决策。
更复杂的任务:大小模型协作的生成式智能体
大模型规划 对用户任务,进行子任务划分,规划 去开源社区,自动找,每个任务对应的最好的 模型。 每个任务对于一个 , 小模型 执行具体任务 组成工作流, 生成 , 整合 反馈用户
大模型开源处理很多问题, 不是解决问题
HuggingGPT:大小模型协作的生成式智能体
|
|
|
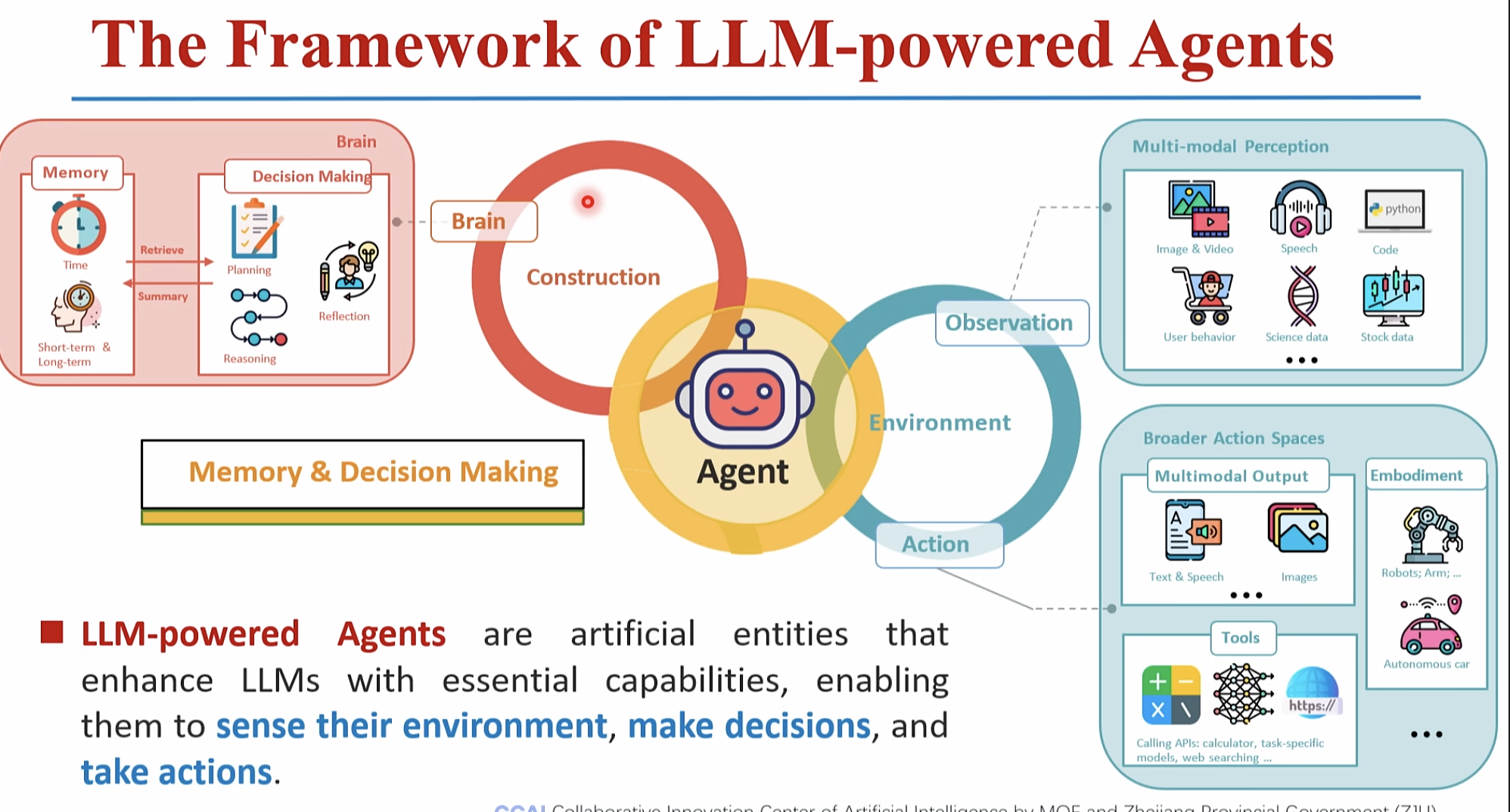
三1.智能体(AI Agent) 是大模型 (Brain)的眼(Observation)和手
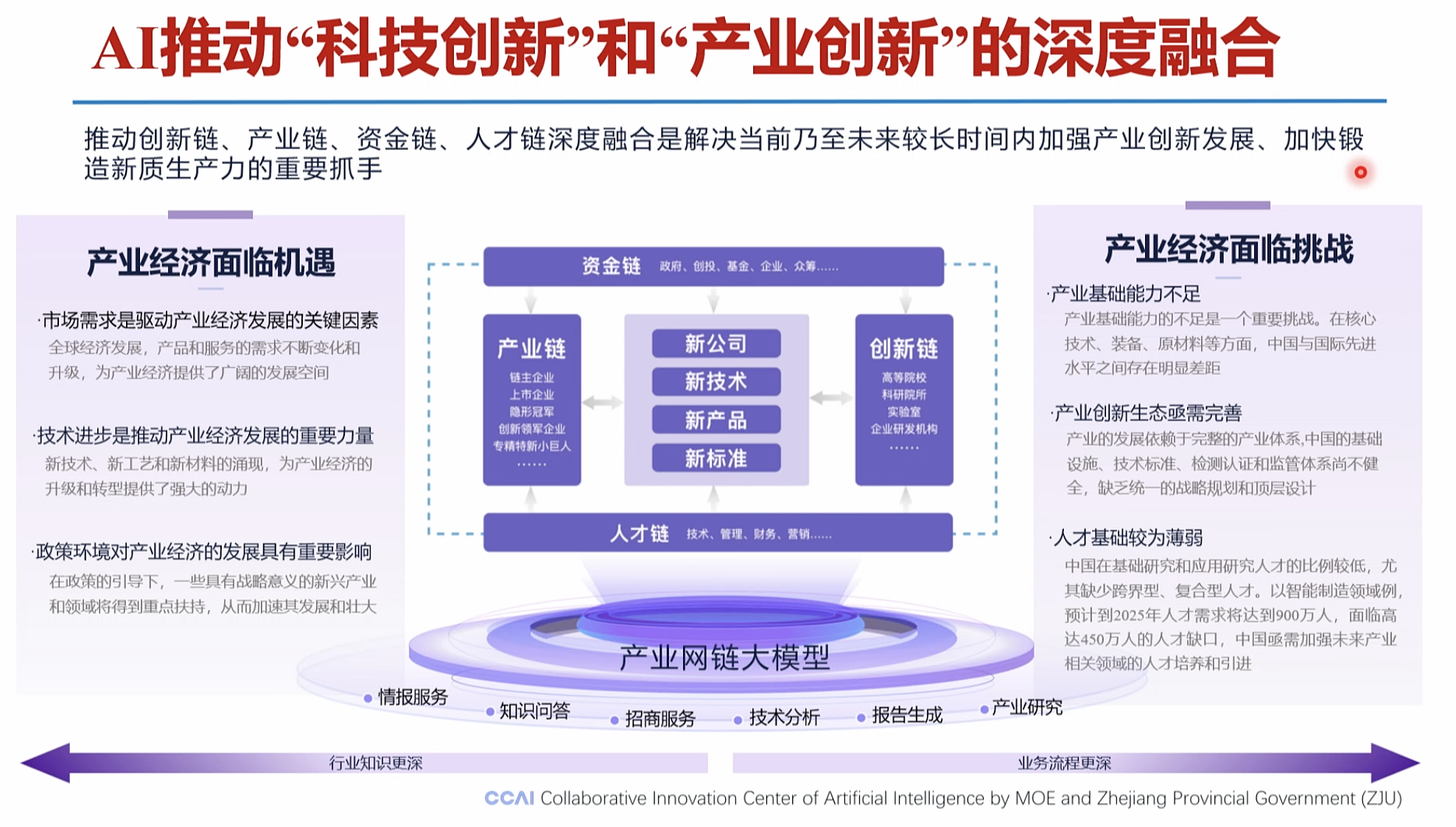
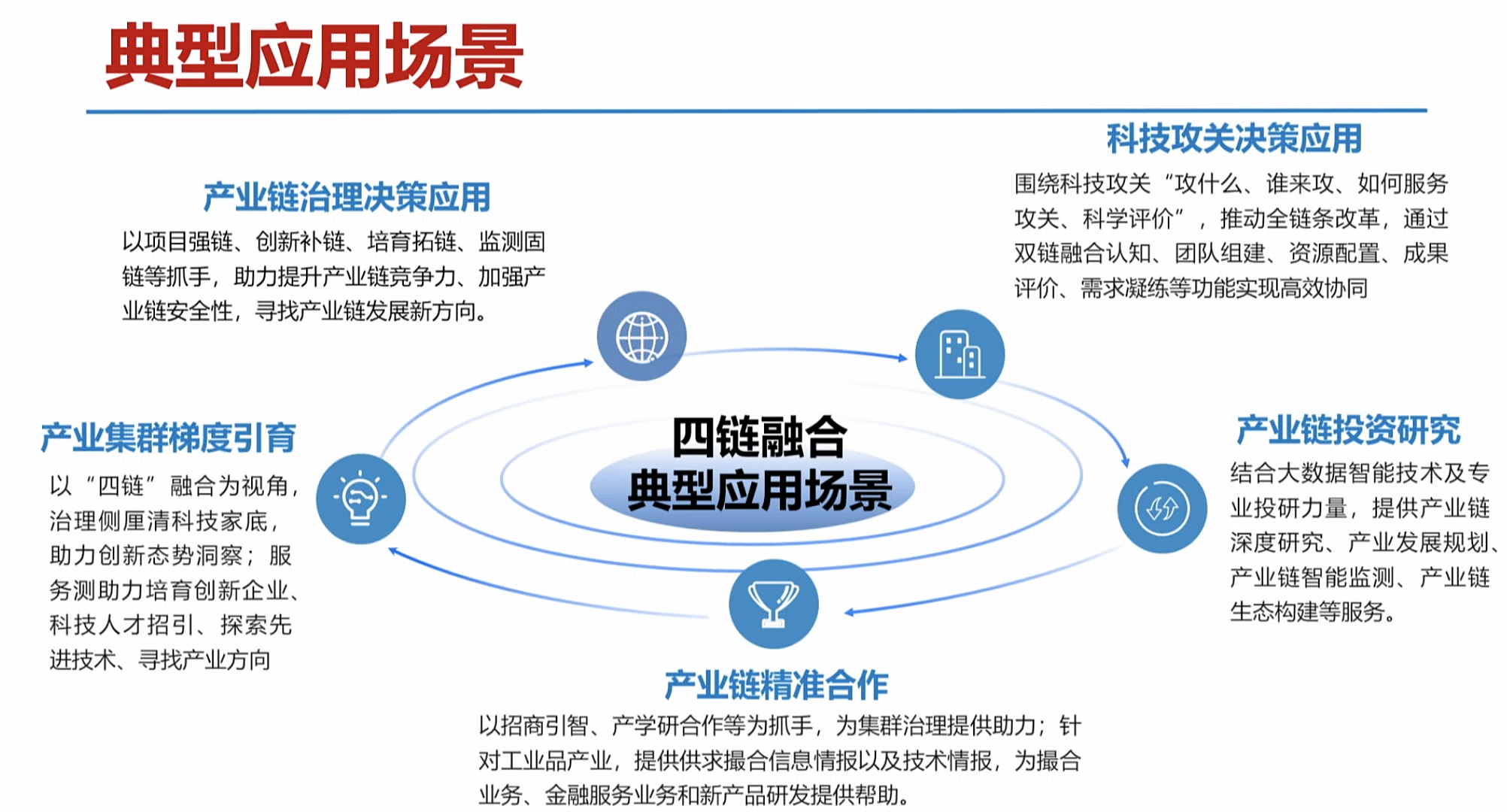
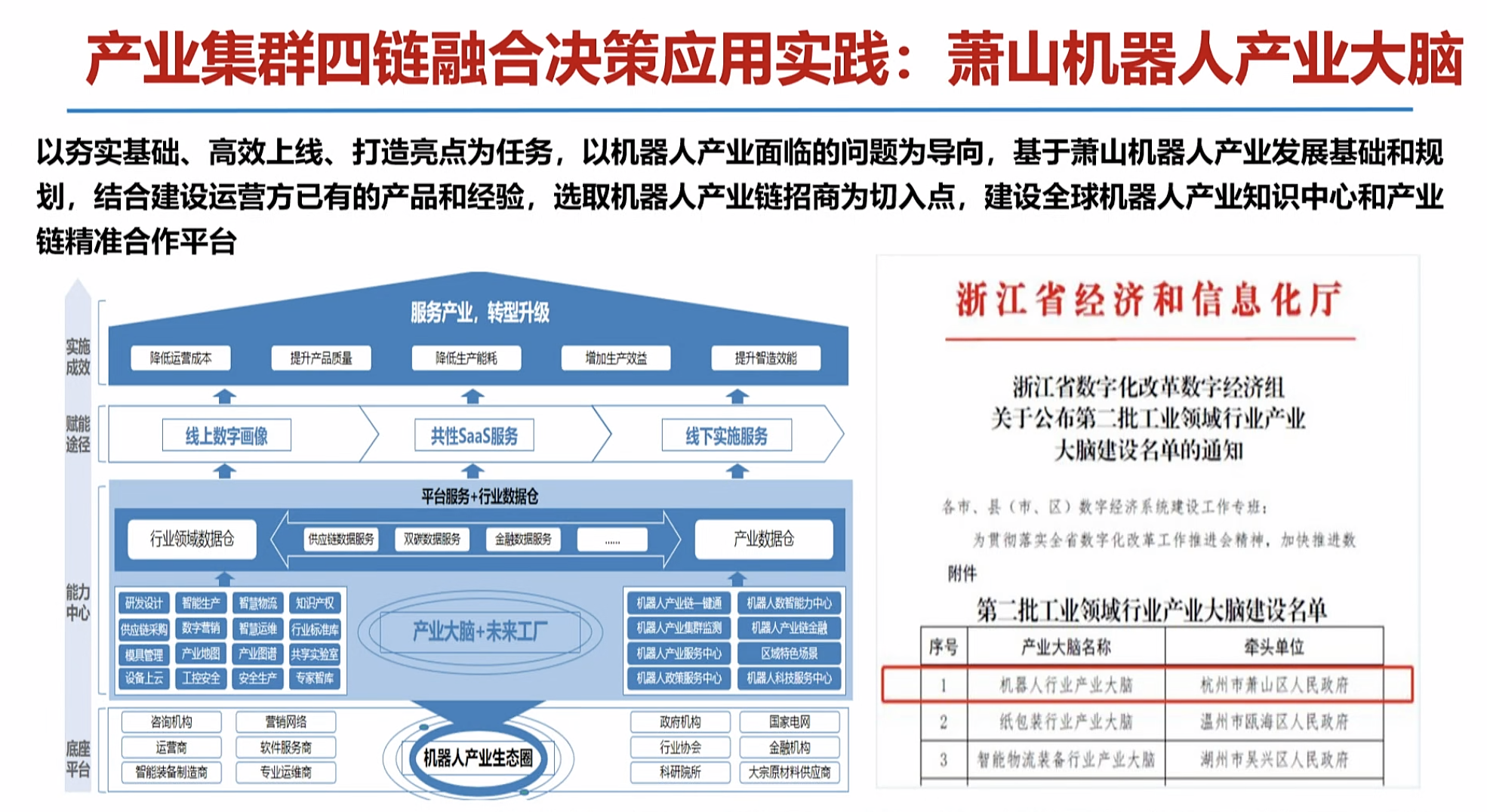
四链融合产业大脑案例
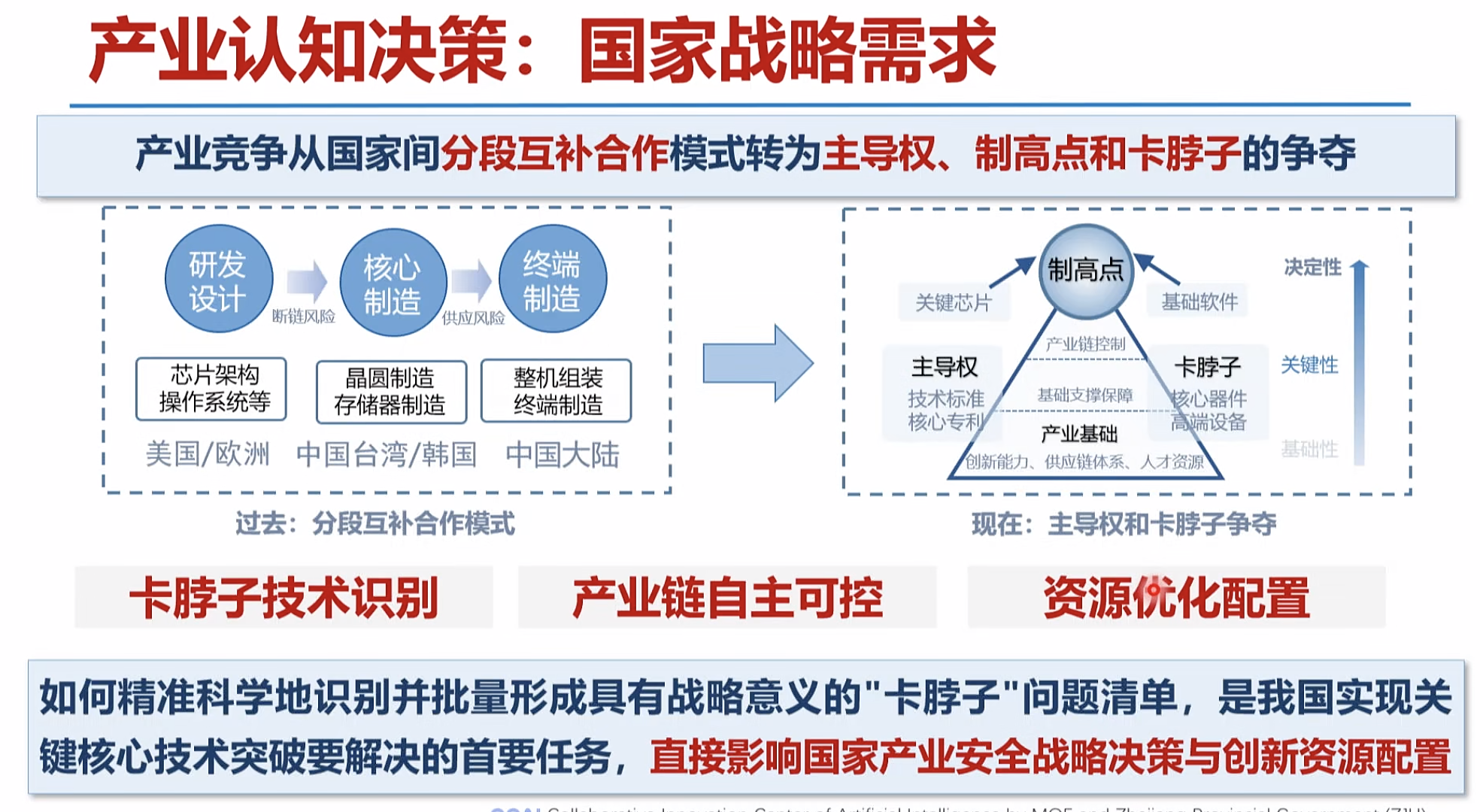
产业发展决策:广阔的社会需求
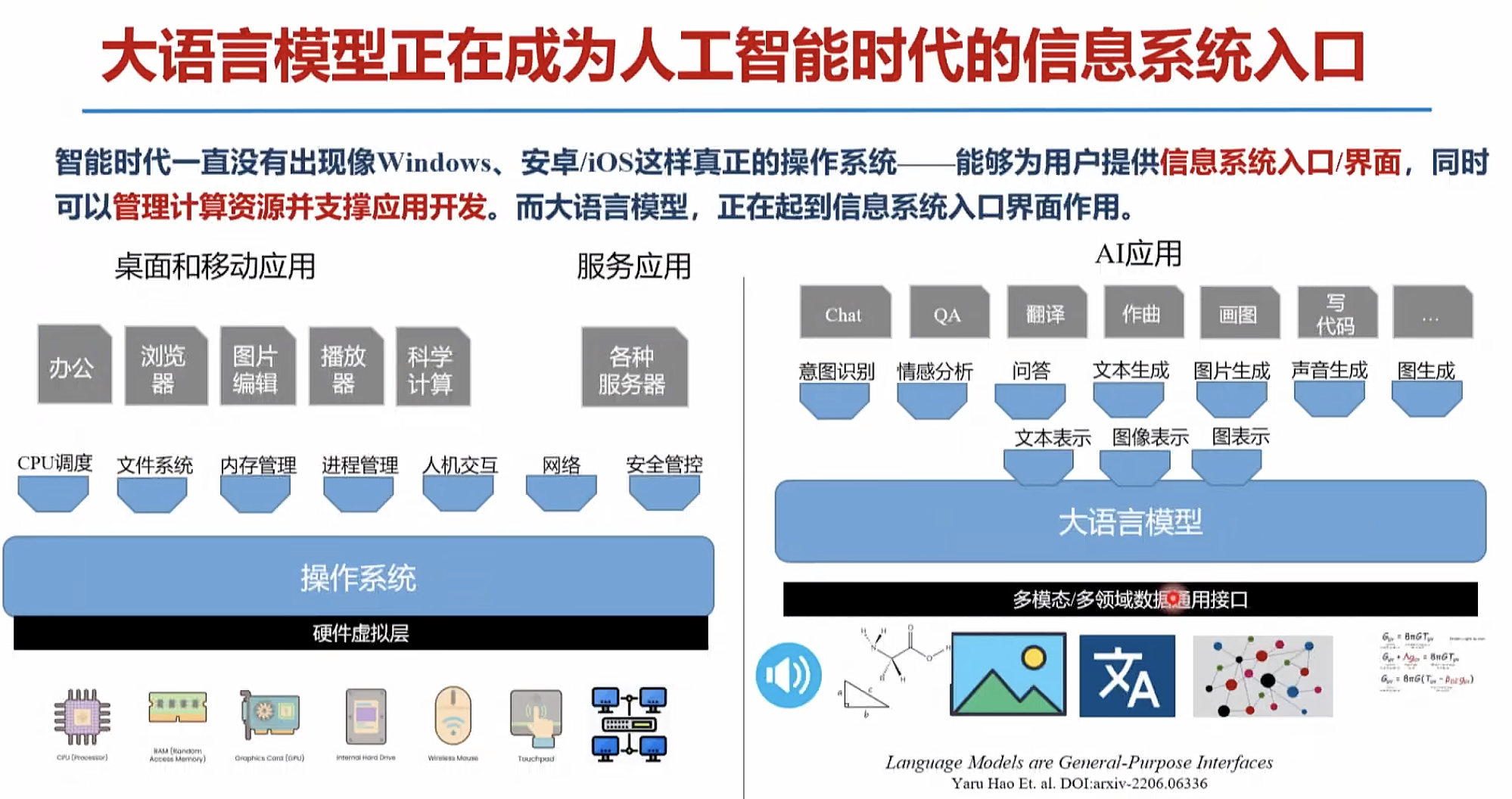
如何精准感知产业技术态势,科学研判产业发展方向,及时布局产业化应用场景培育新产品,成为未来产业大变局中区域/企业实现竞争突围的关键。
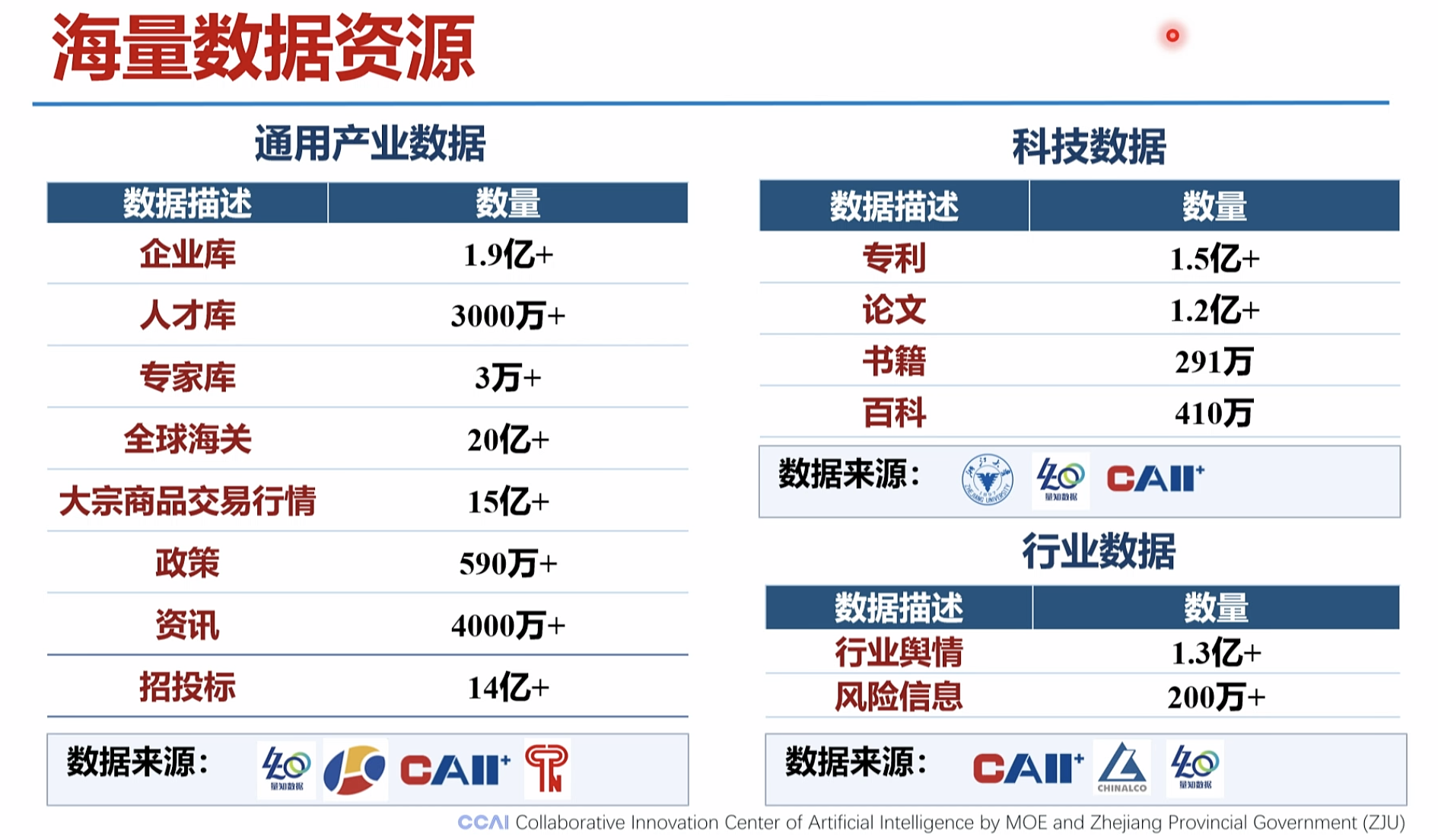
海量数据资源
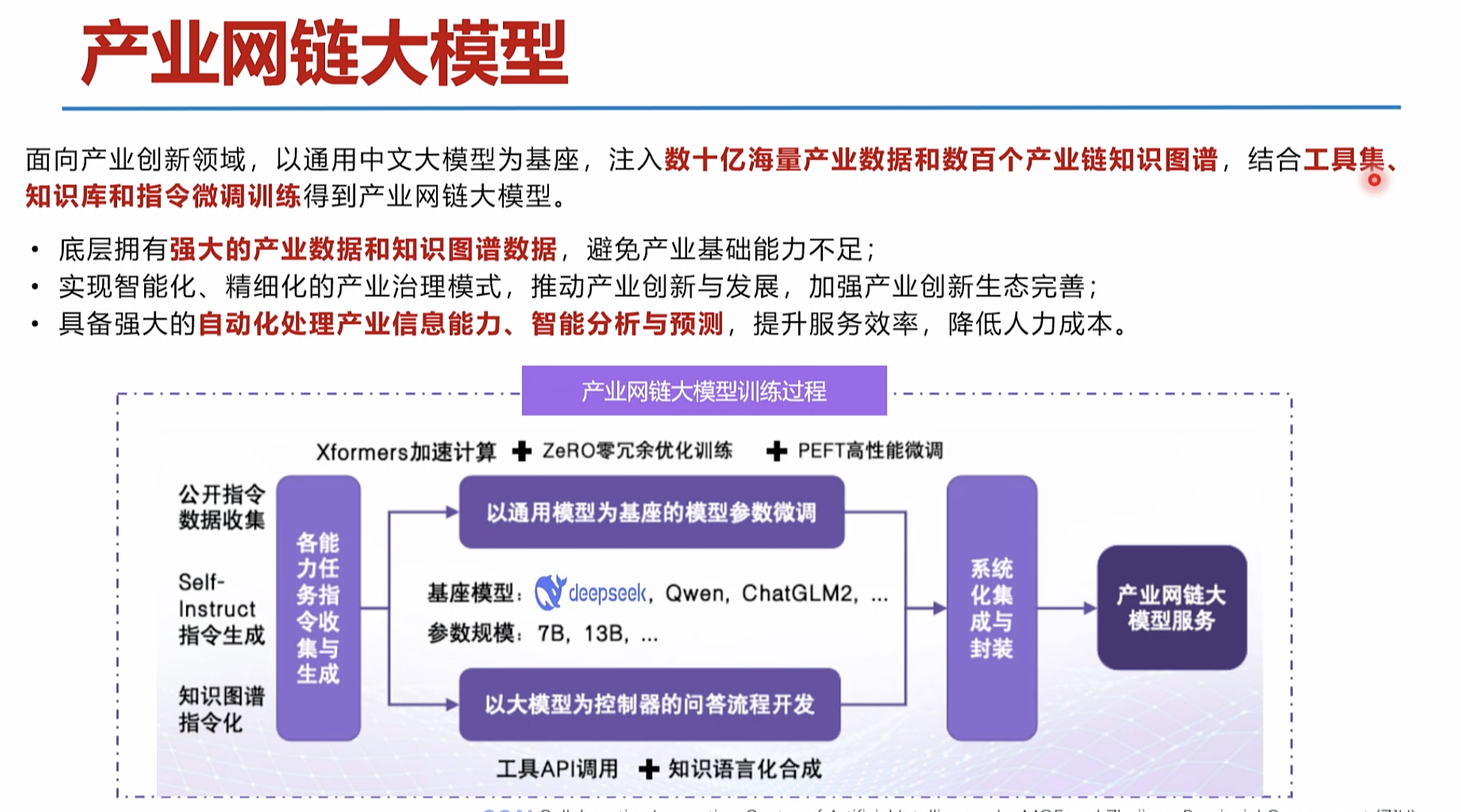
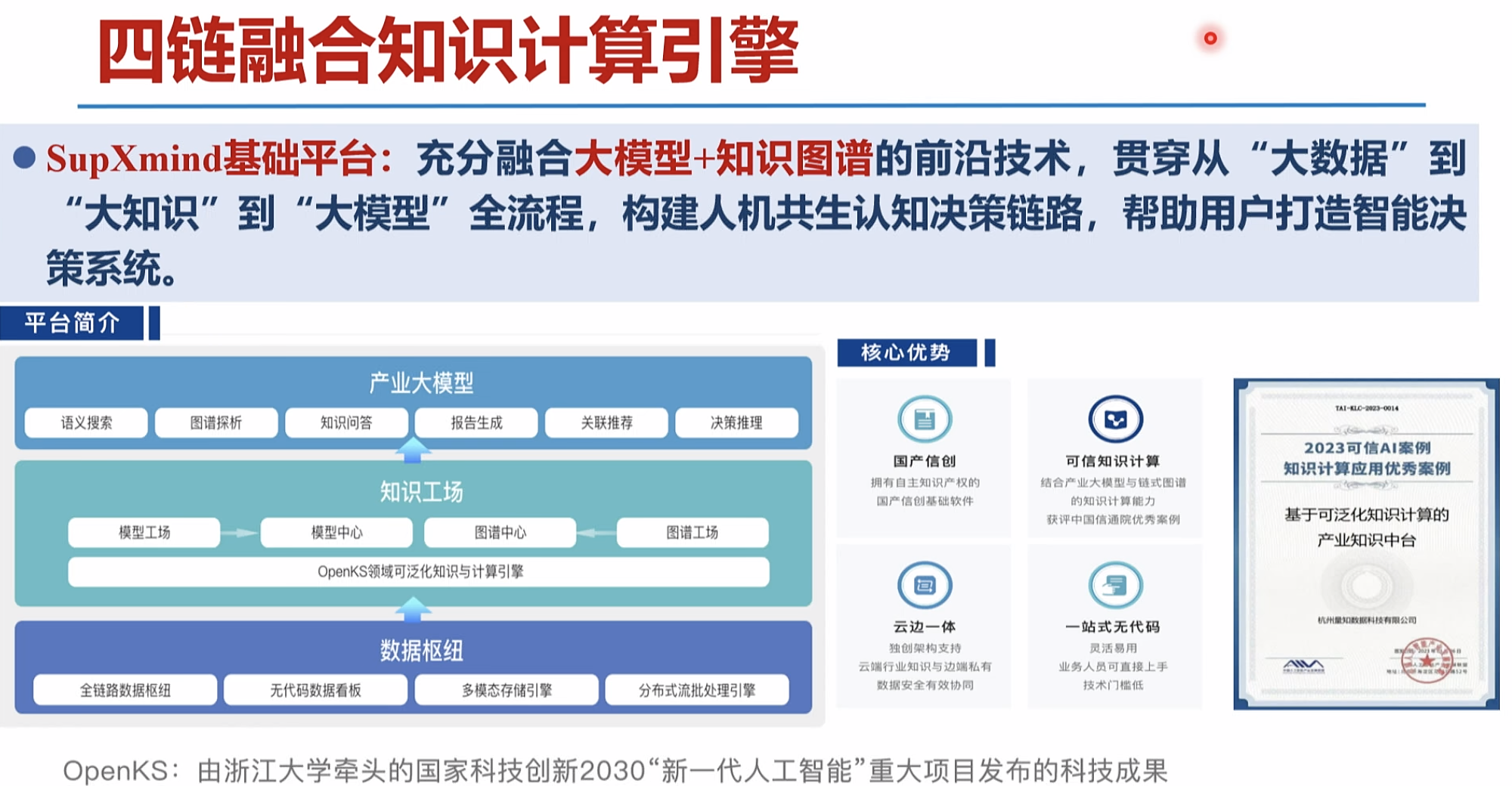
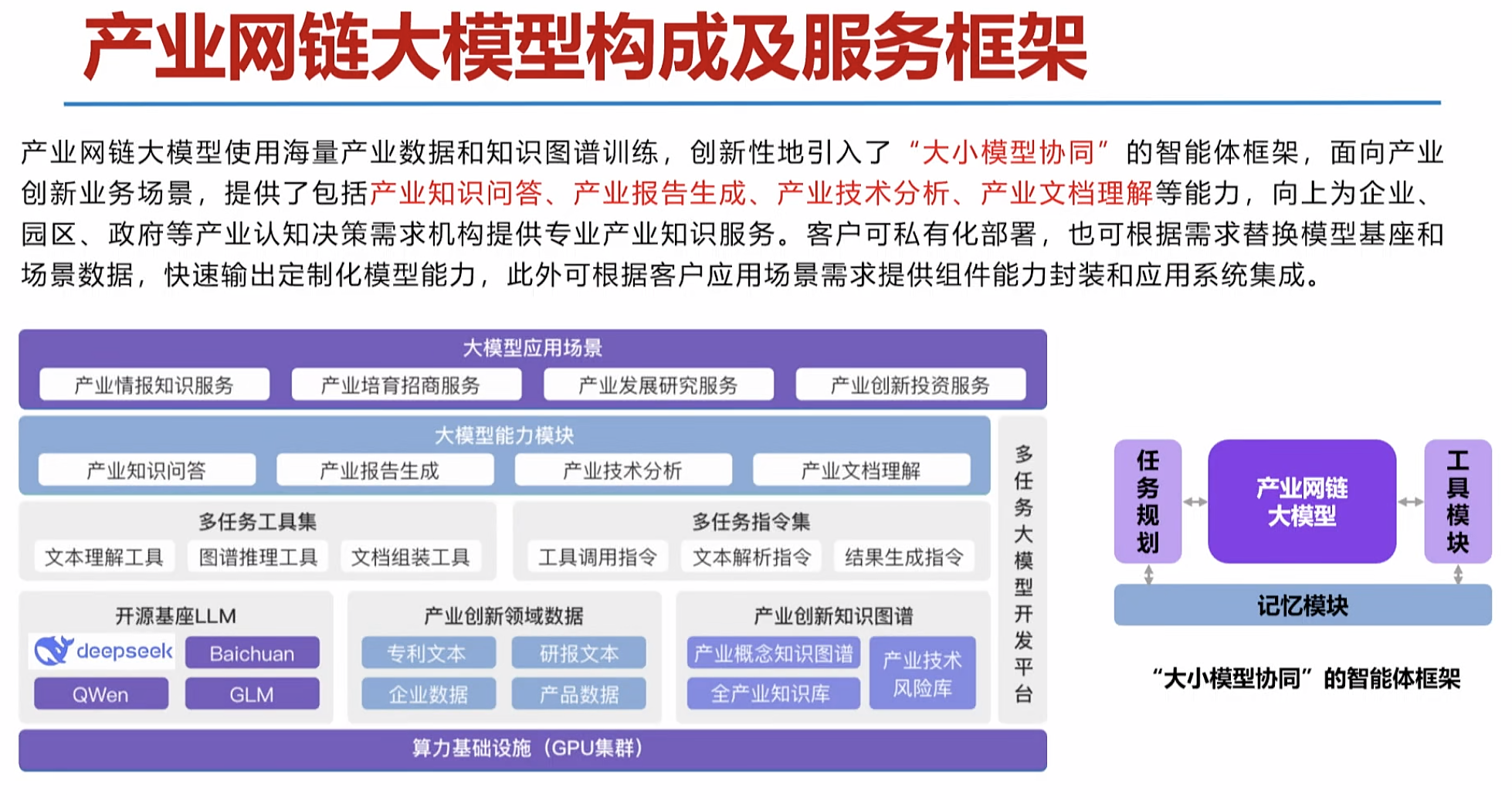
产业垂域大模型iChainGPT
|
|
|
|
|
|
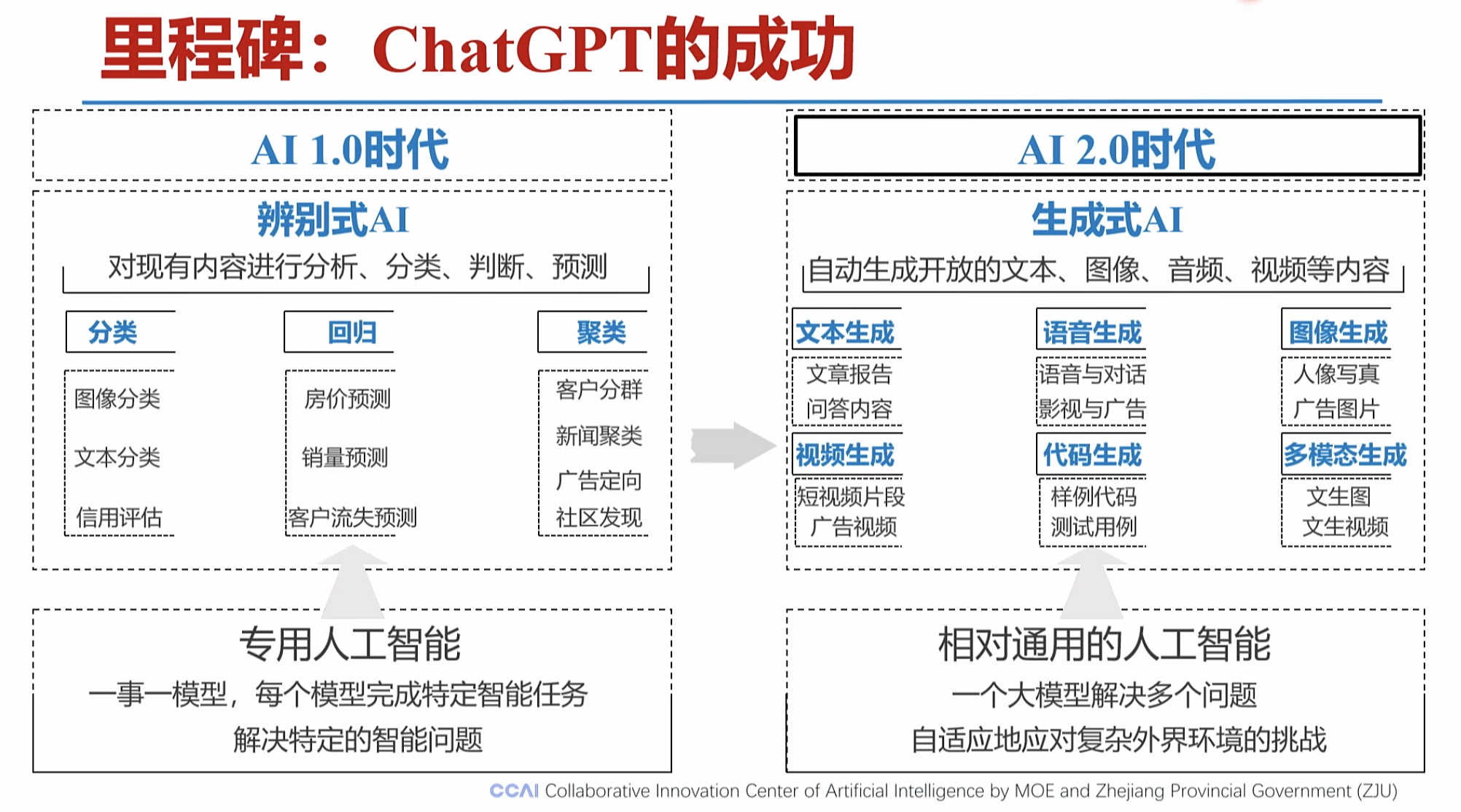
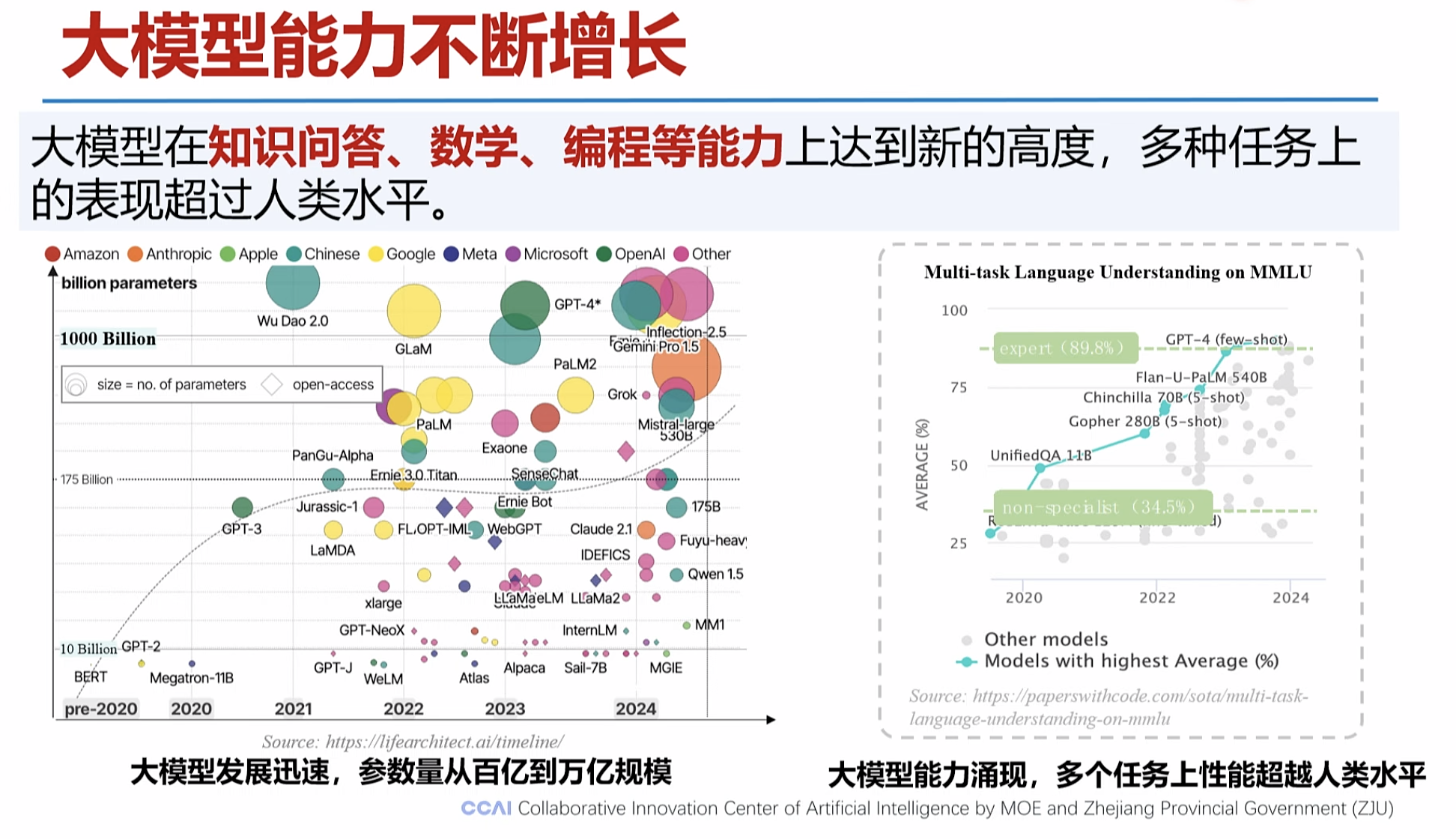
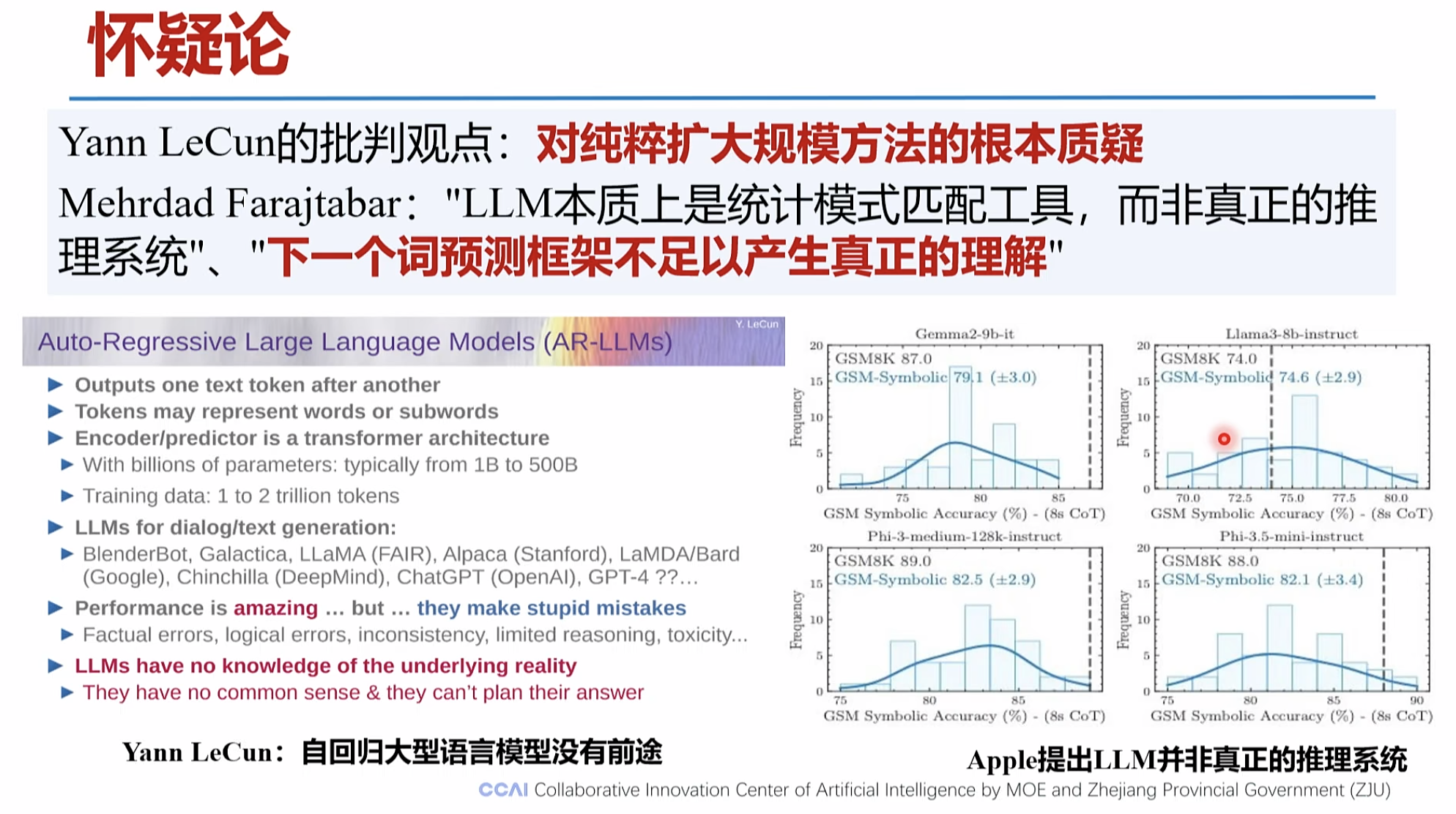
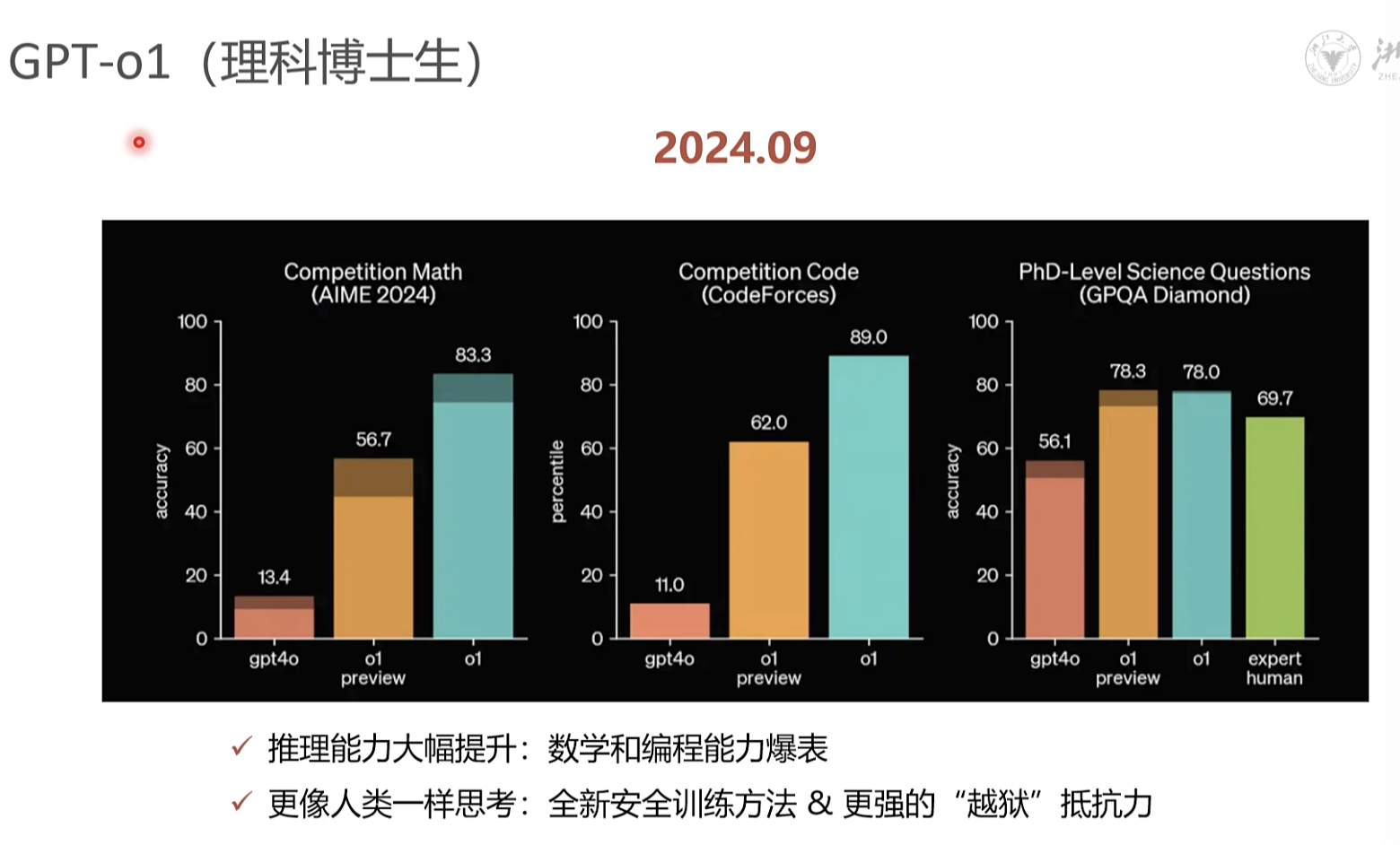
1.新一代大模型的推理能力正在不断增强
|
|
|
|
|
|
|
|
|
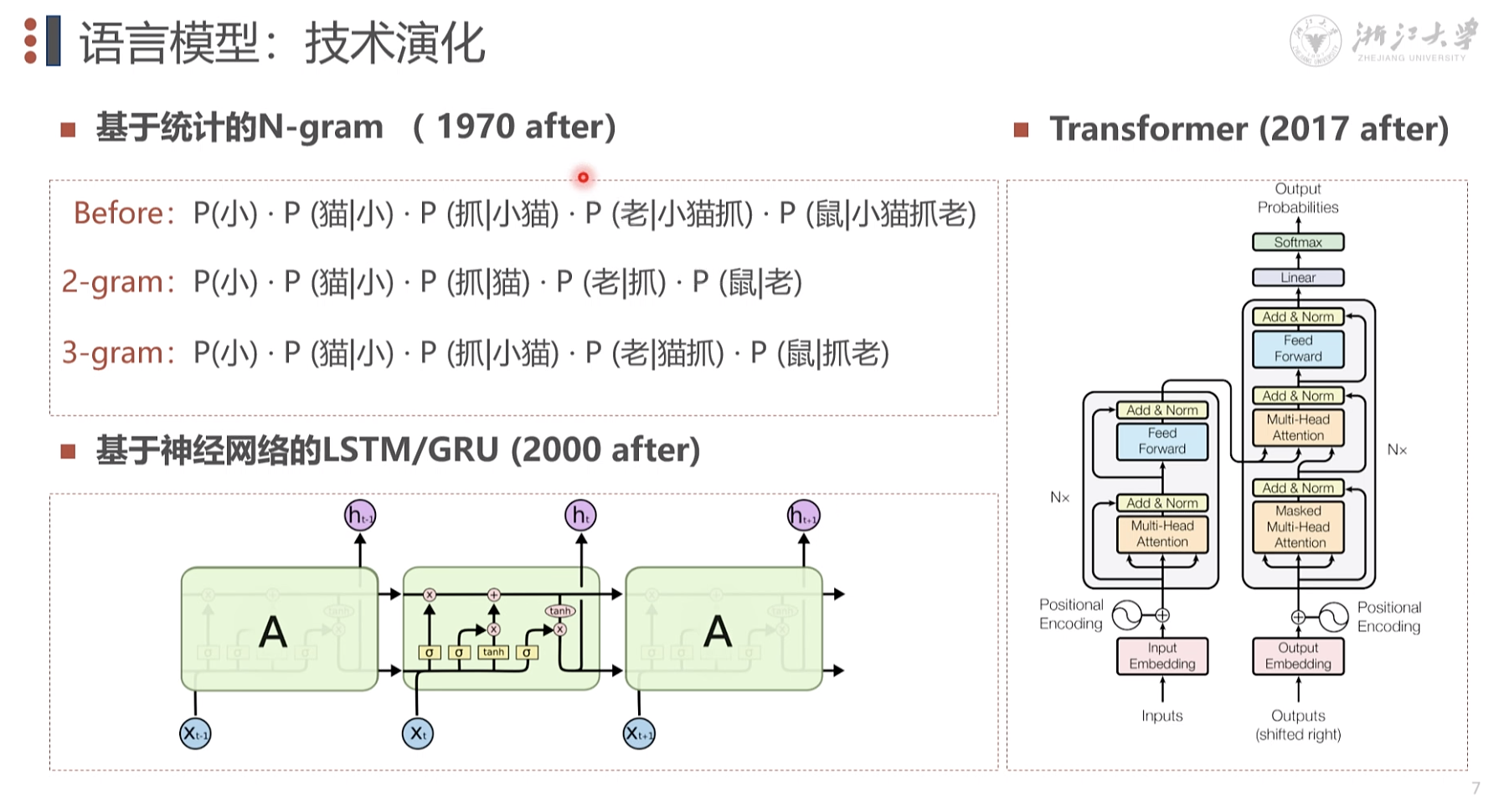
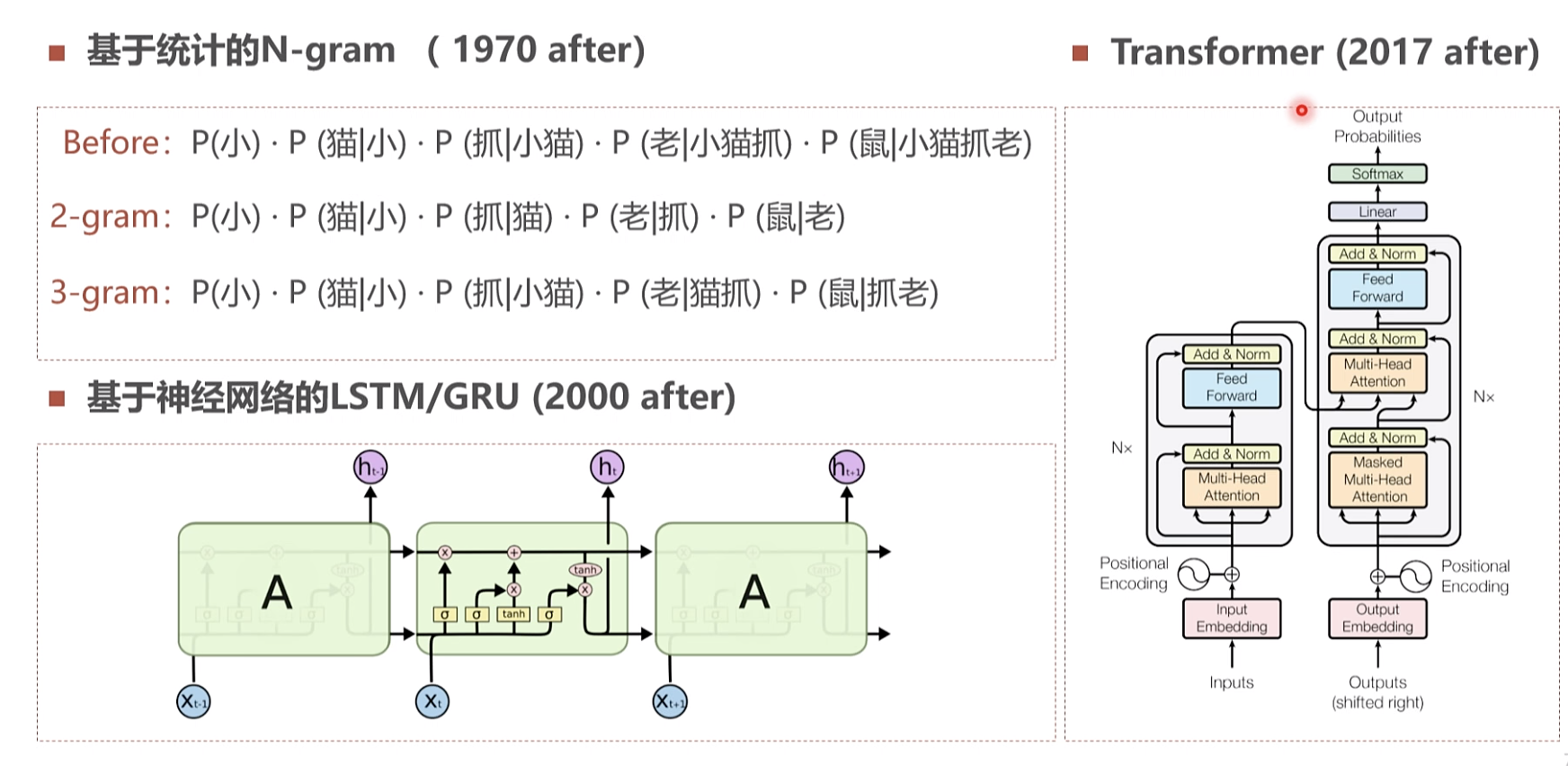
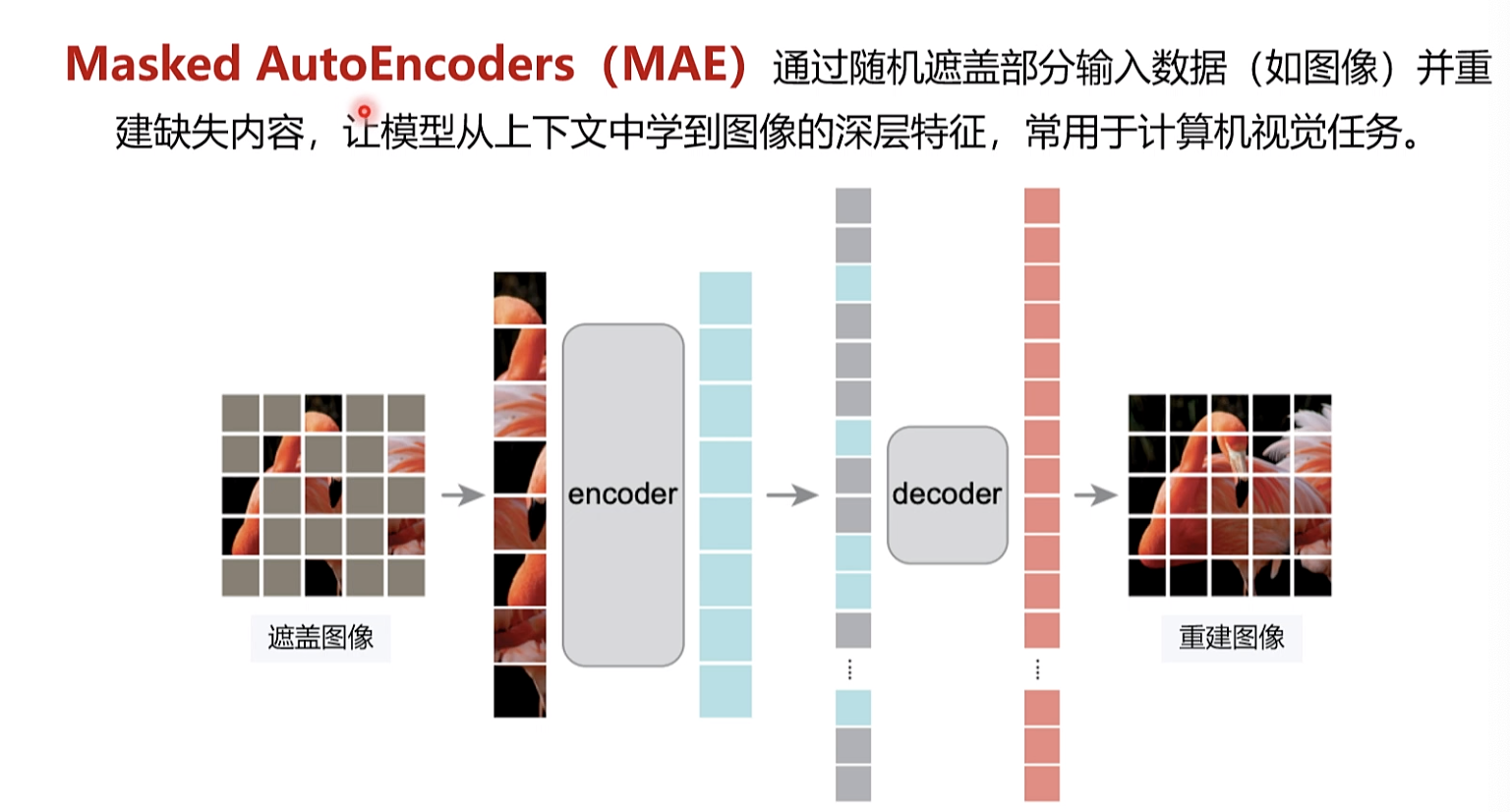
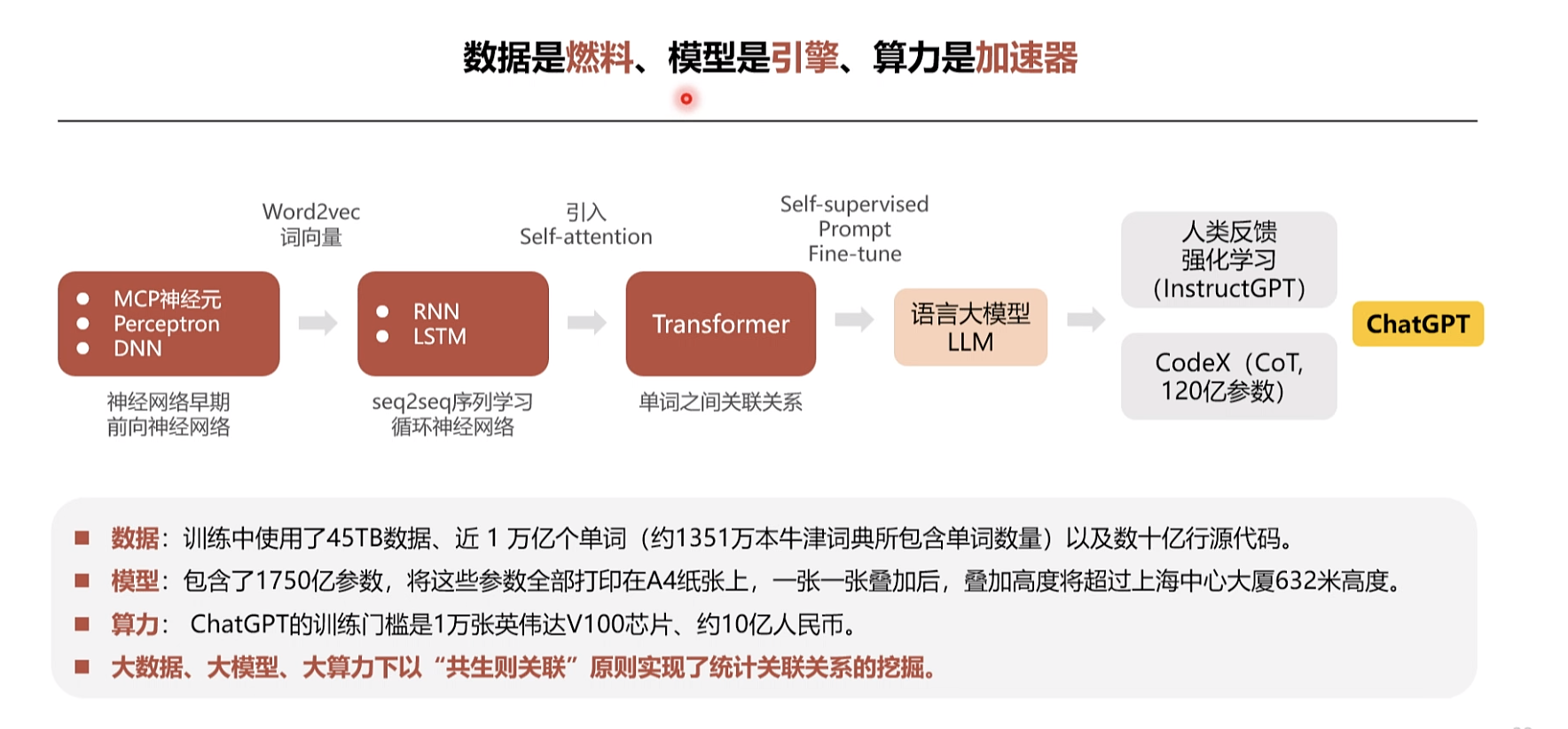
1970年后n范式 网络抓取处理 。2000开始深度学习
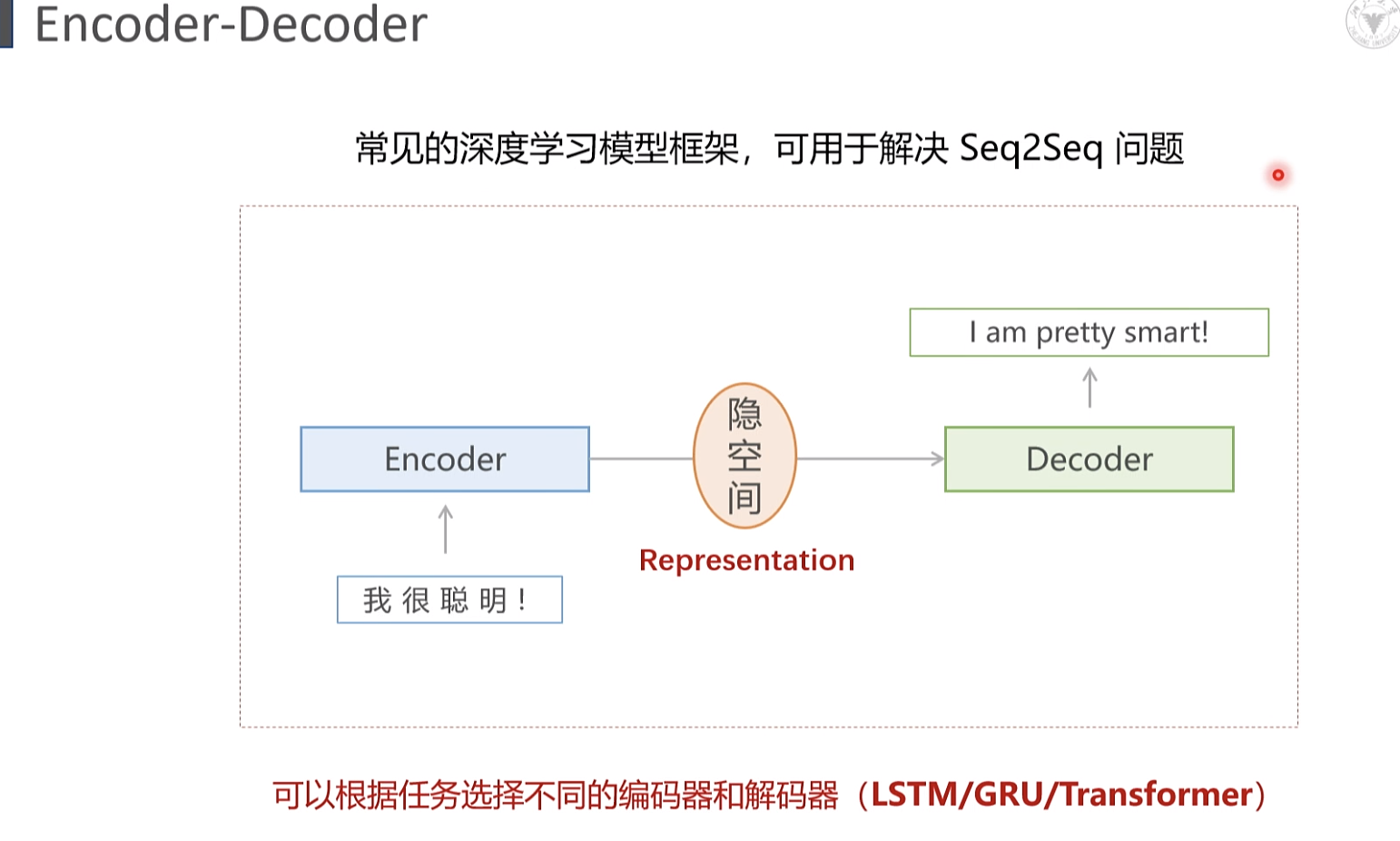
学习框架
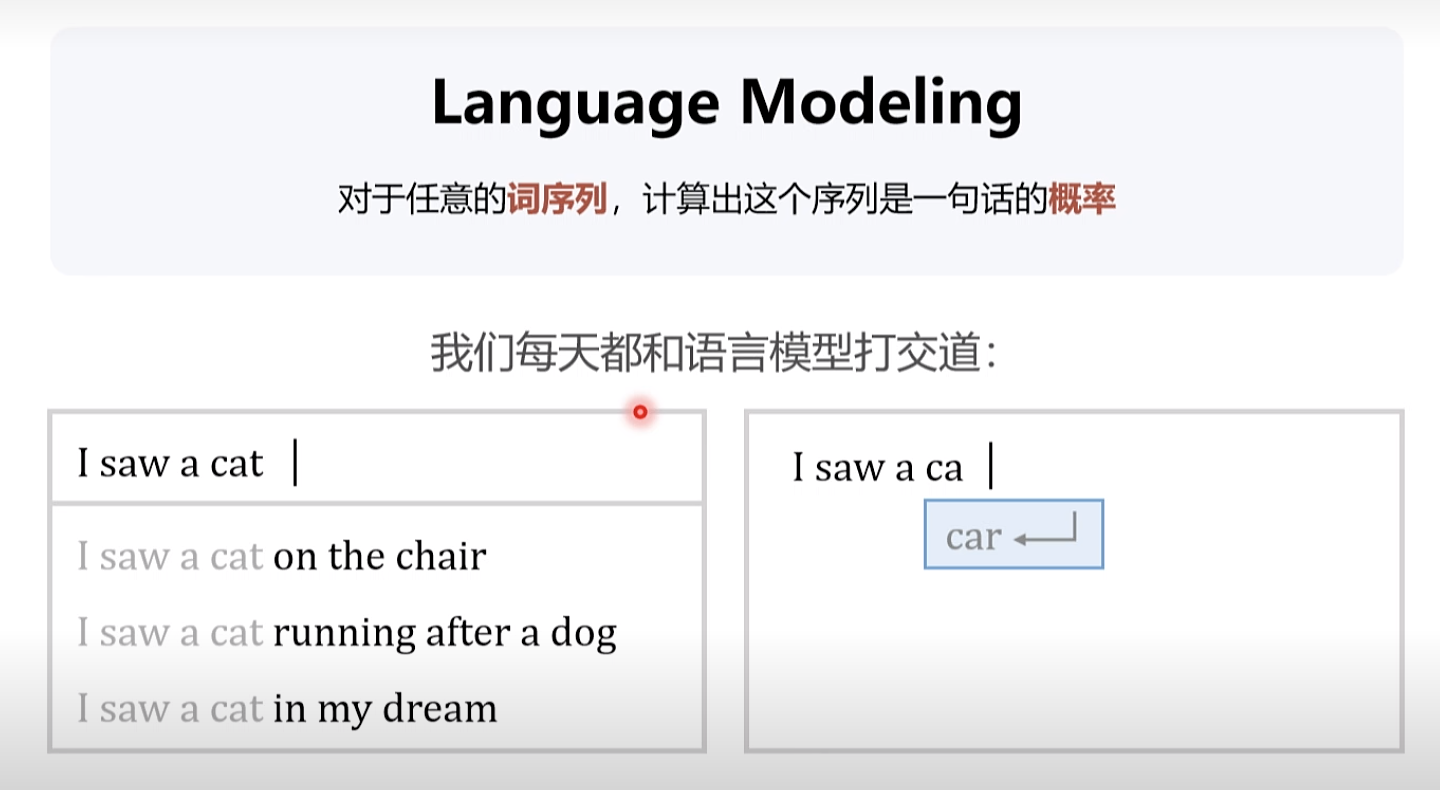
序列到序列的问题
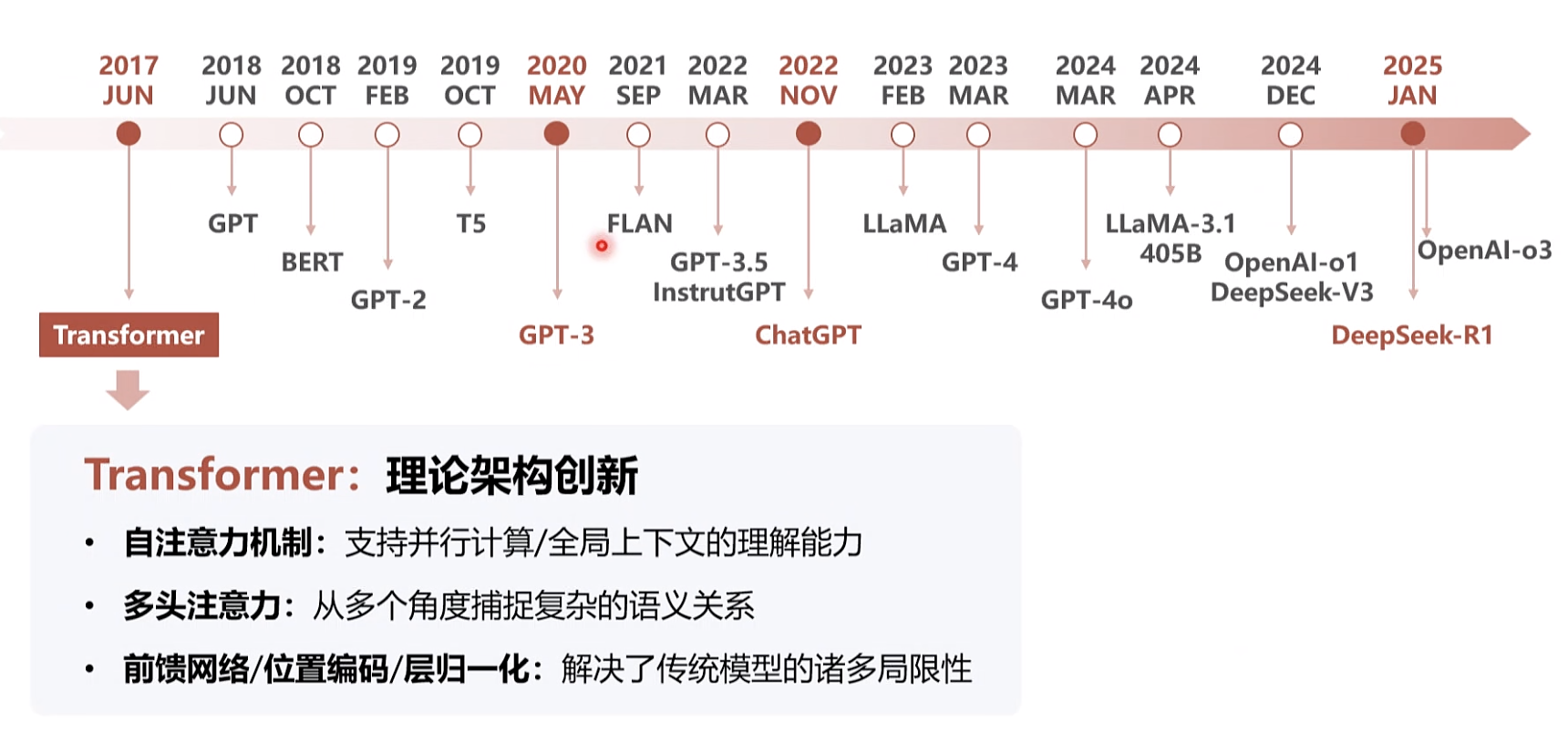
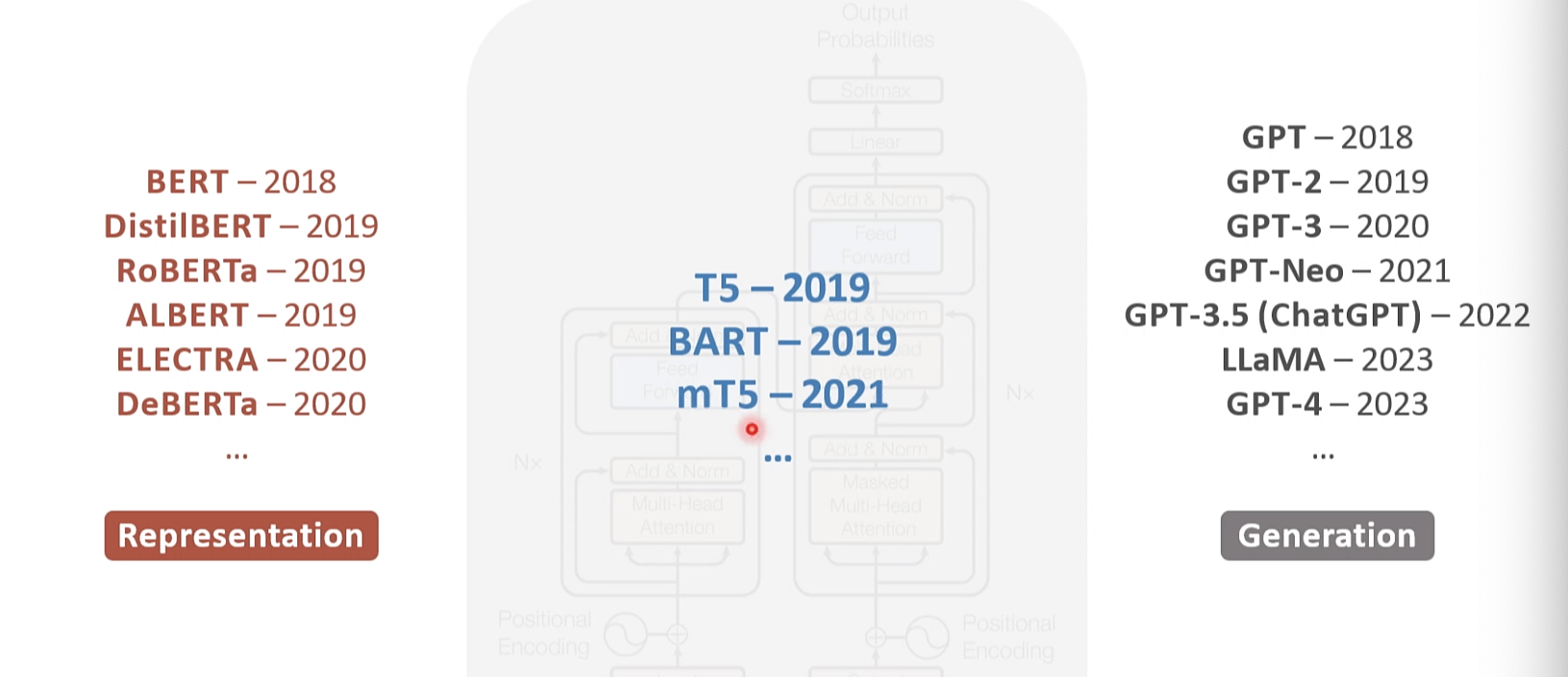
大语言模型简史
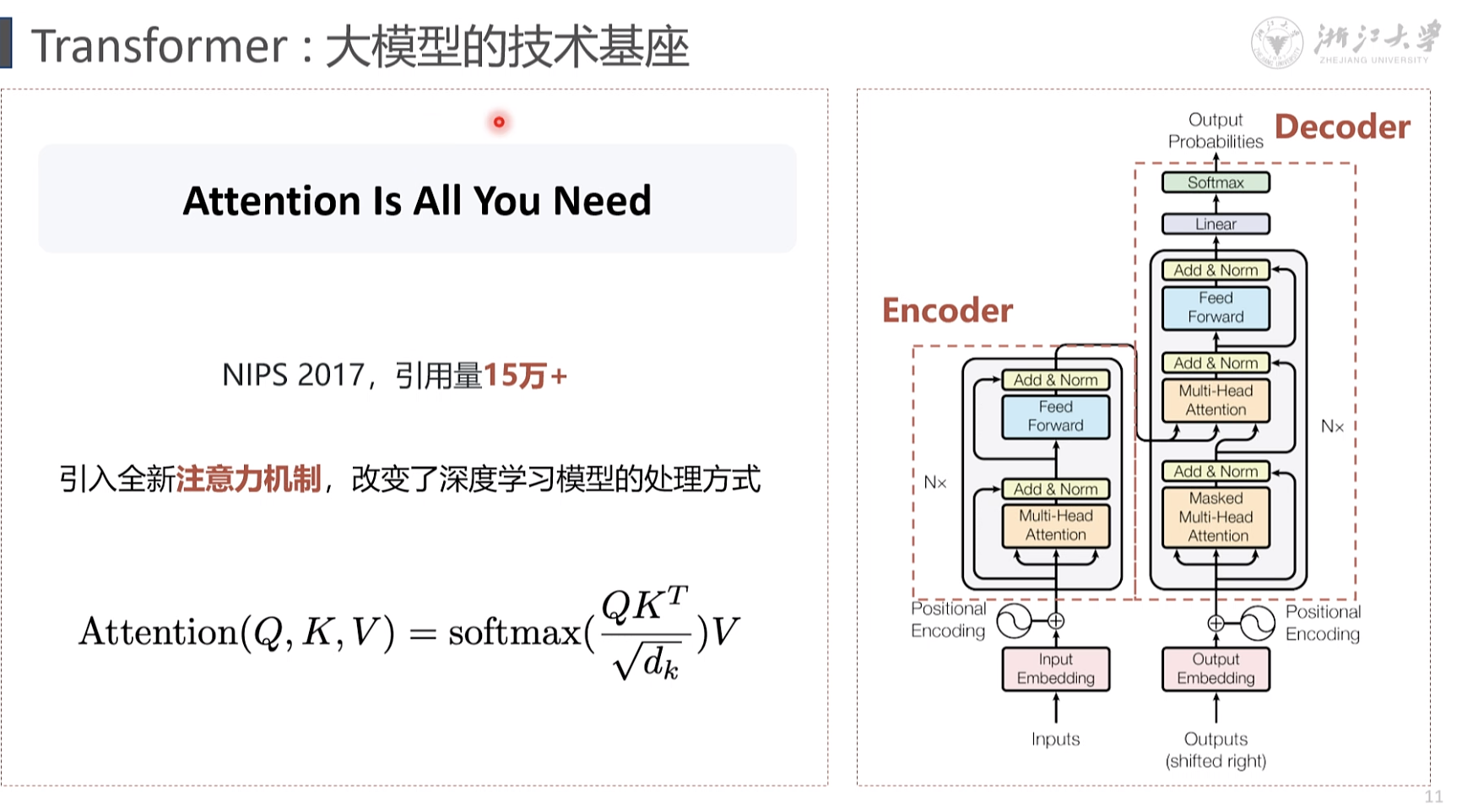
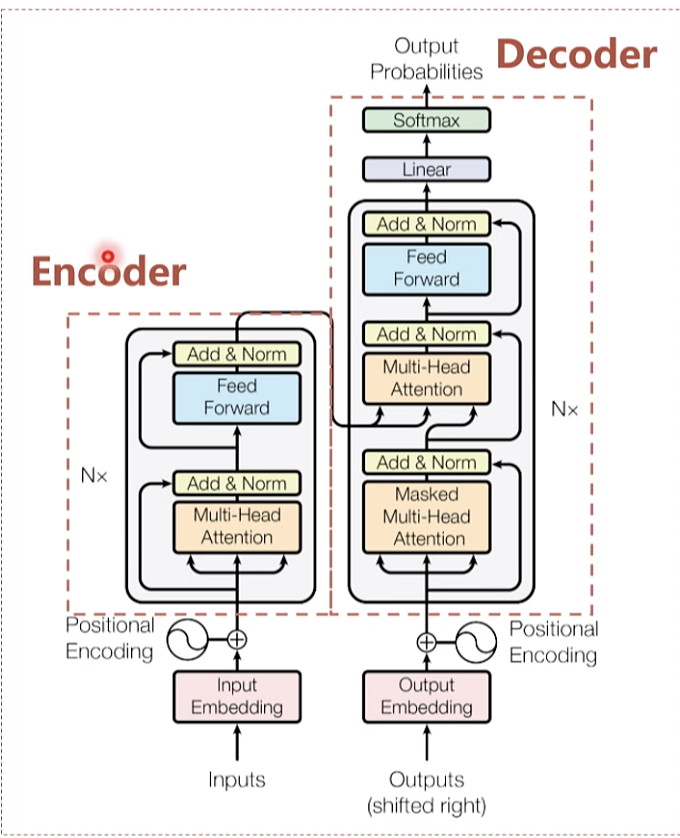
注意力机制
N x 堆叠方式 模型参数的累计
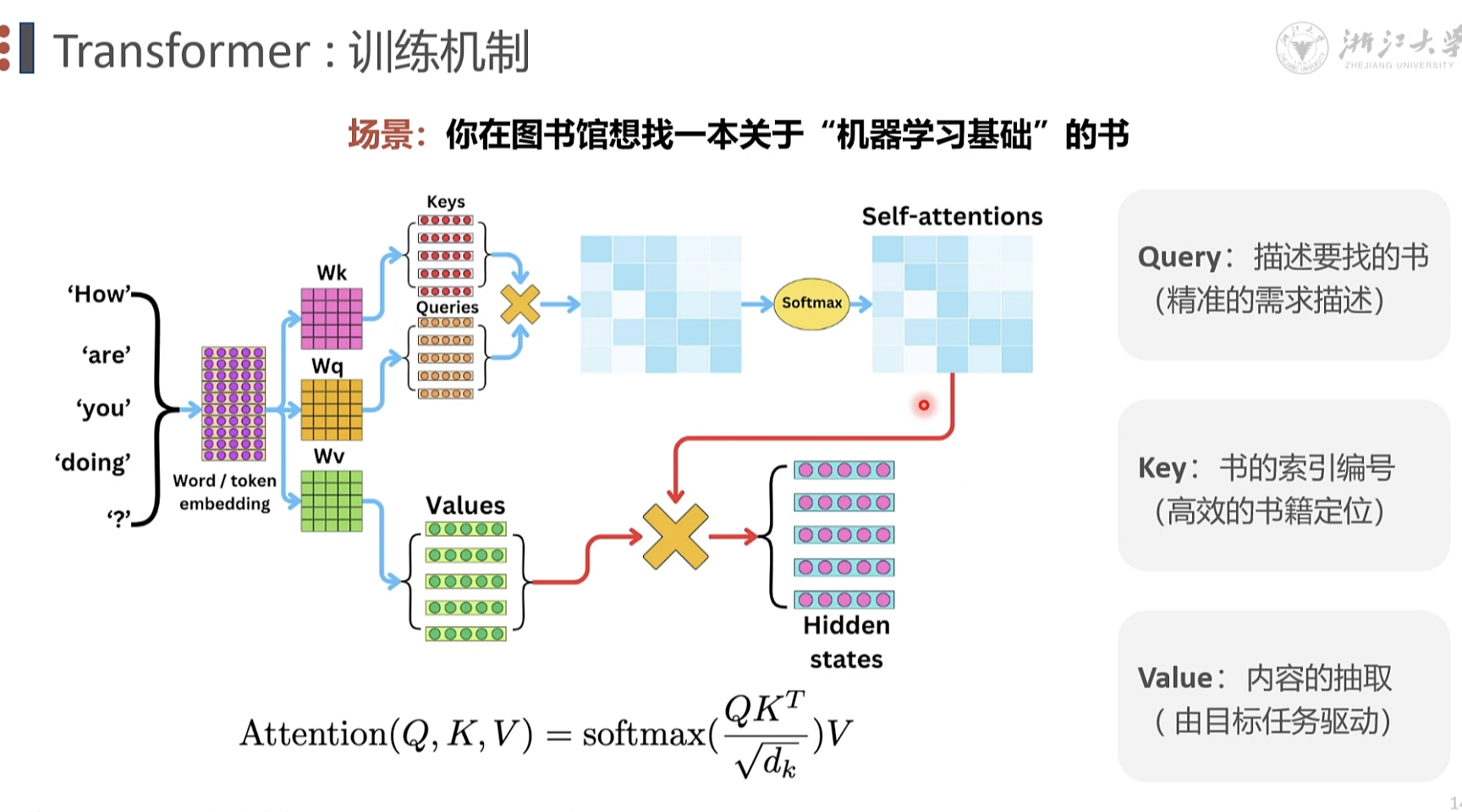
注意力机制 自注意力
Gradient 图像梯度; 邻域像素之间的 像素差
q; 查询 k,键值 v, 内容
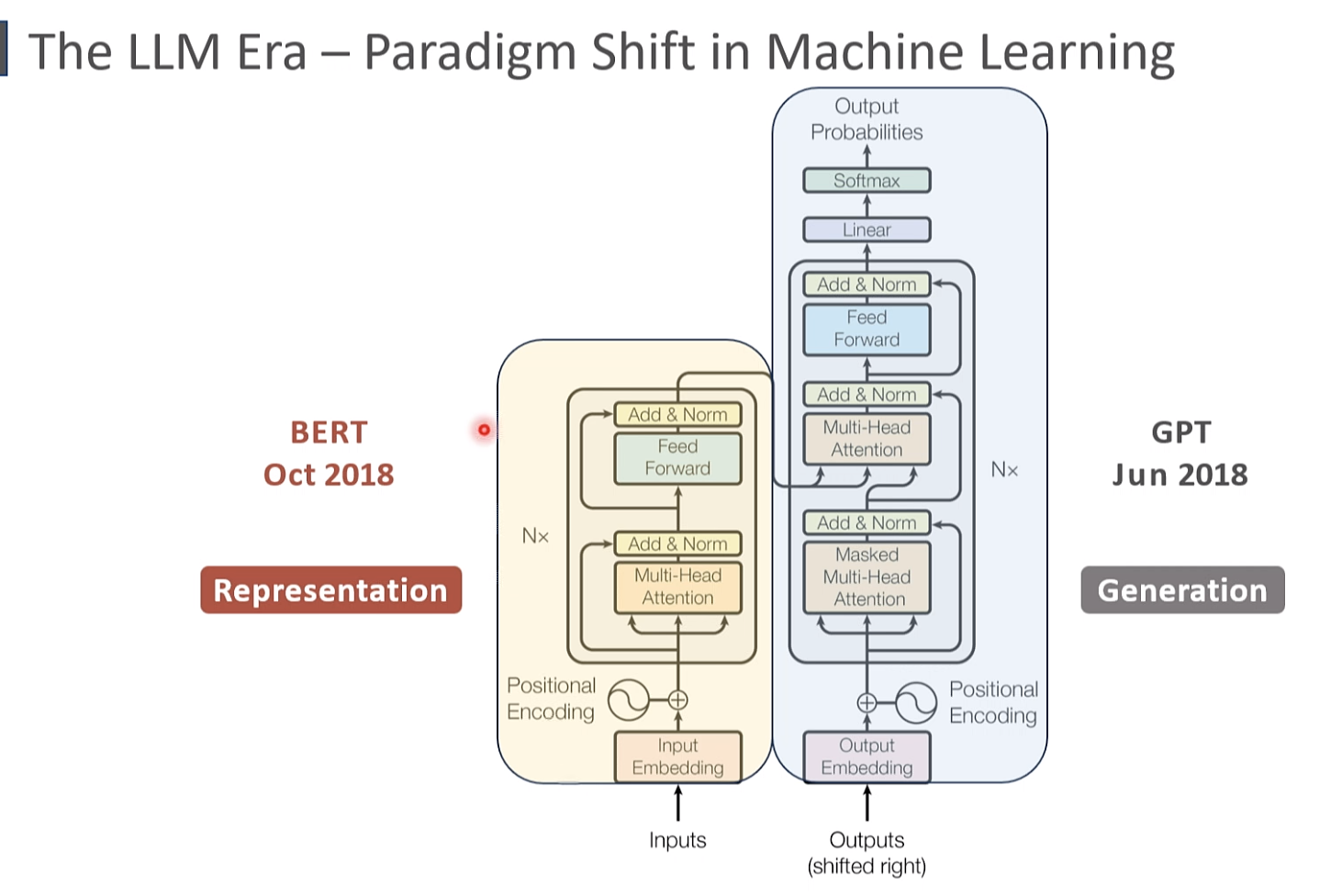
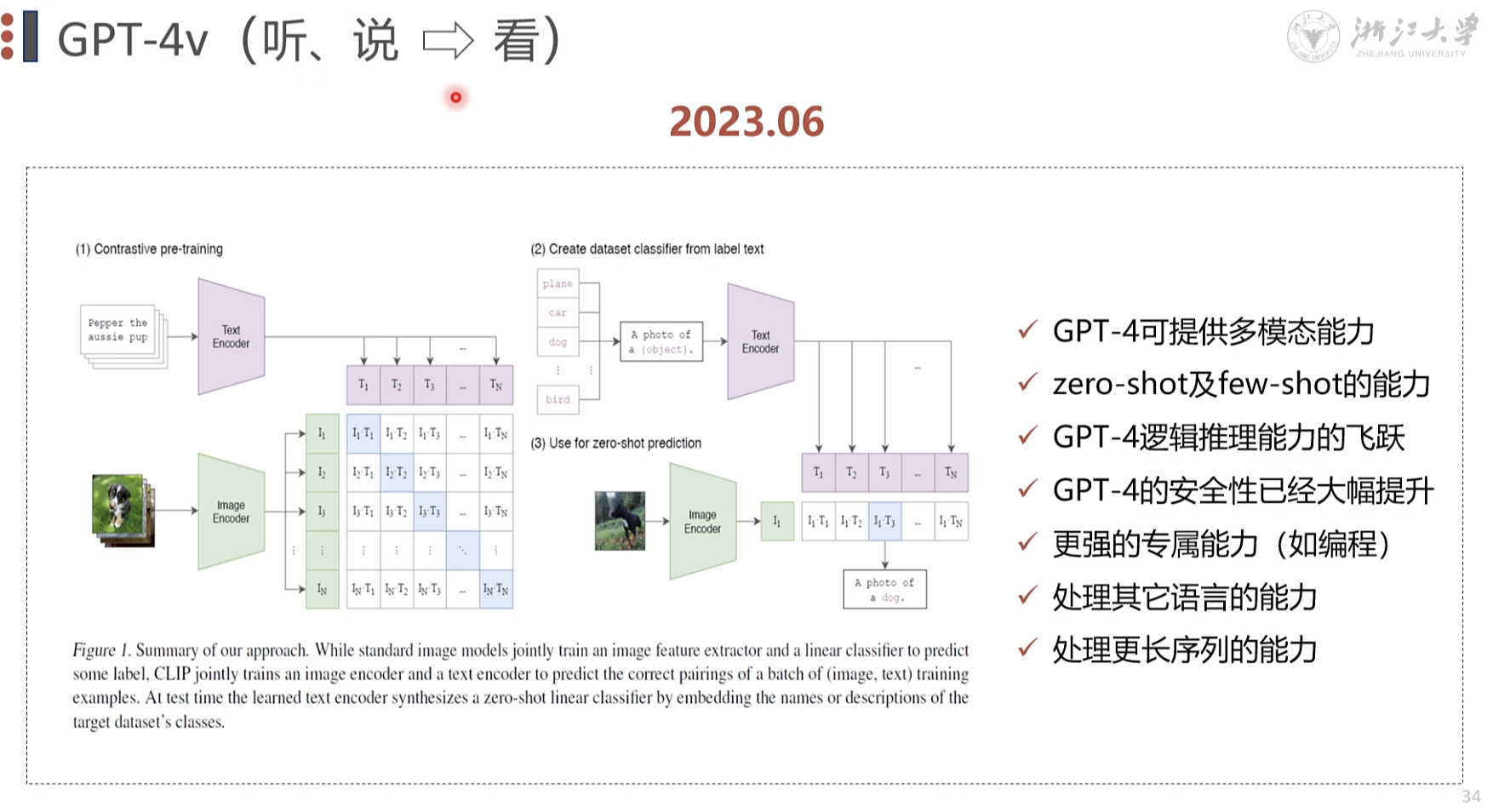
LLM 范式的变换 2018
BERT 2018 10 编码 GPT 2018 11 解码
bert 通用 进入领域 学术界 常用, 很早开源
|
|
|
数据是燃料、模型是引擎、算力是加速器
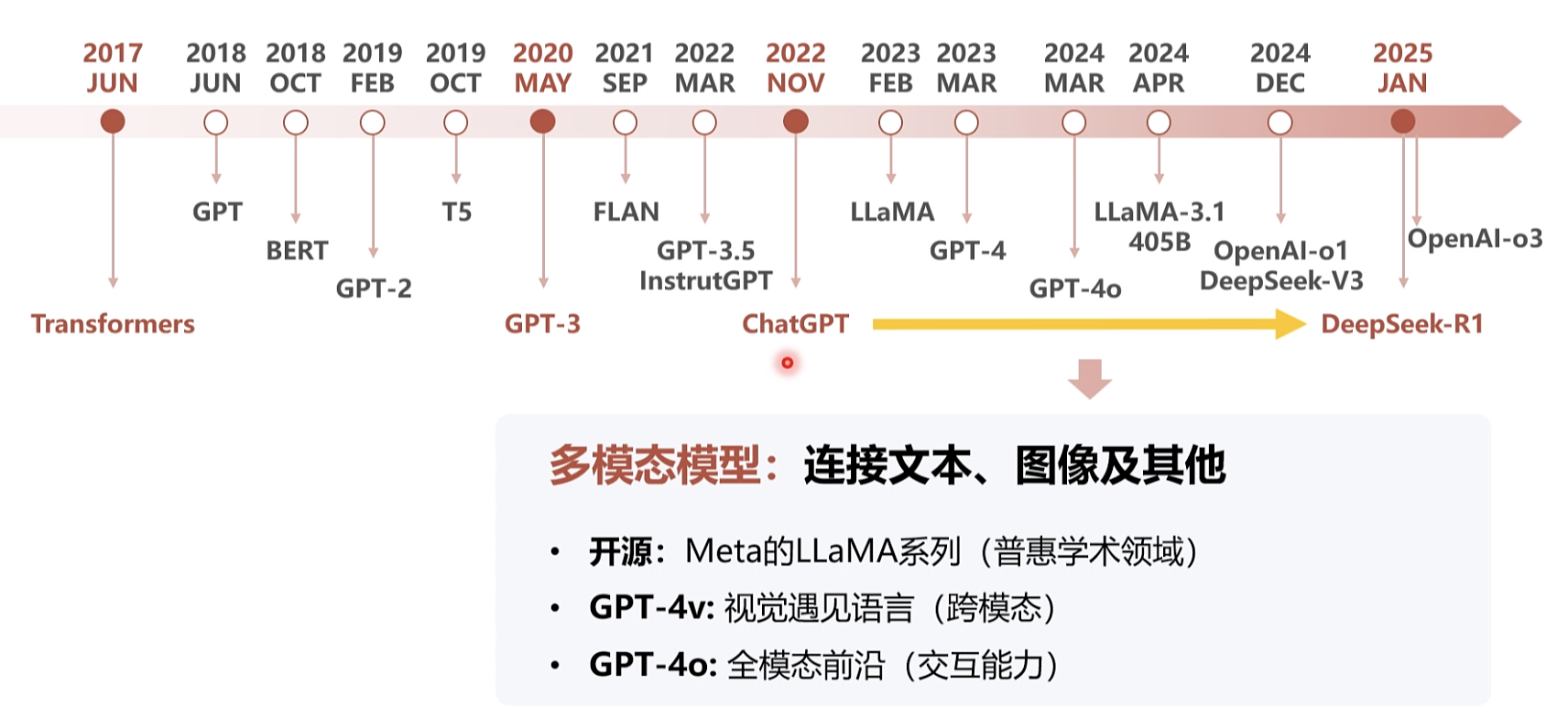
. 多模型,接受,语言,视频
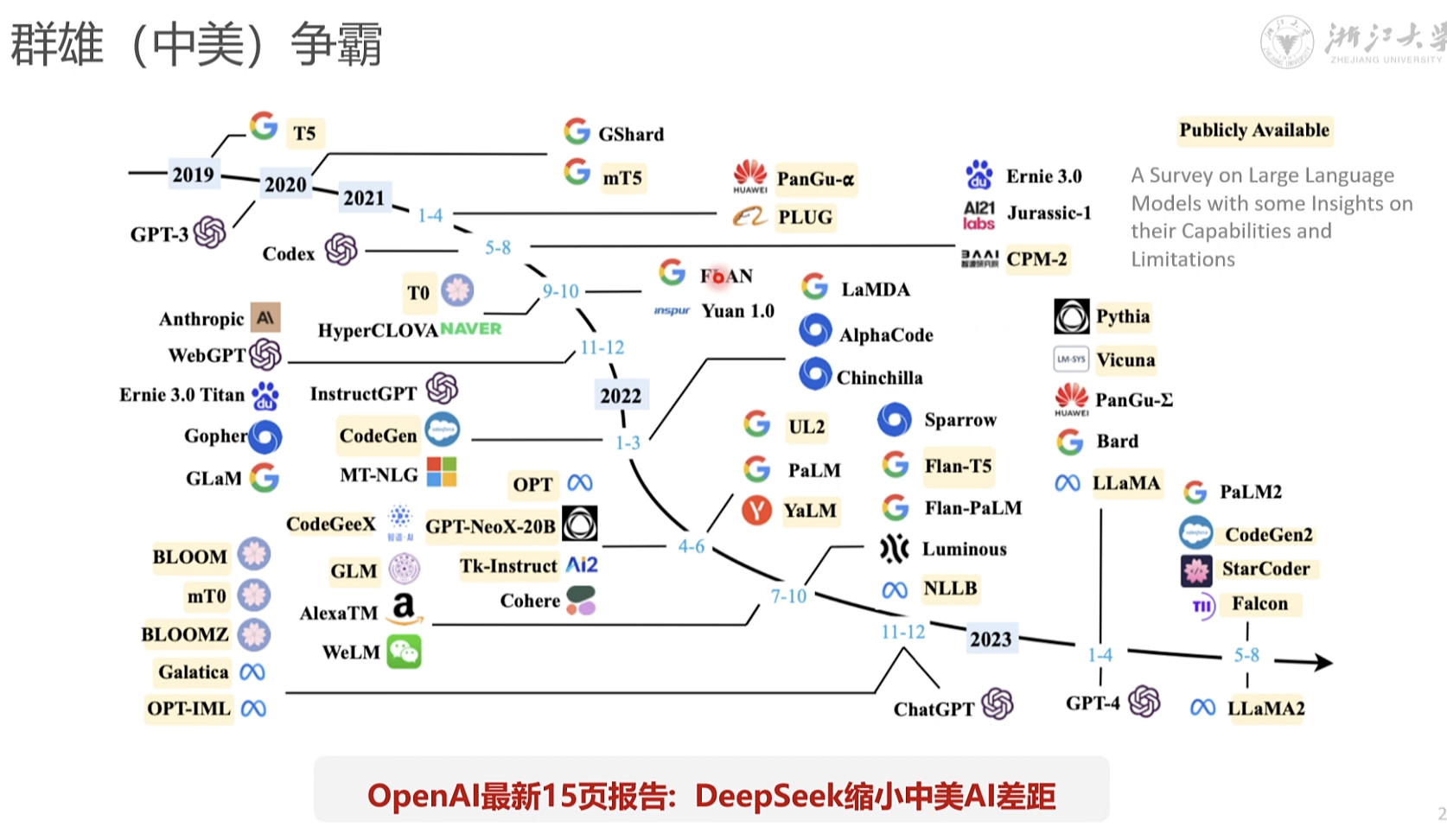
openai 出来 开源模型要追赶 6-12个月 deepseek 代差 缩短到 1-3个月
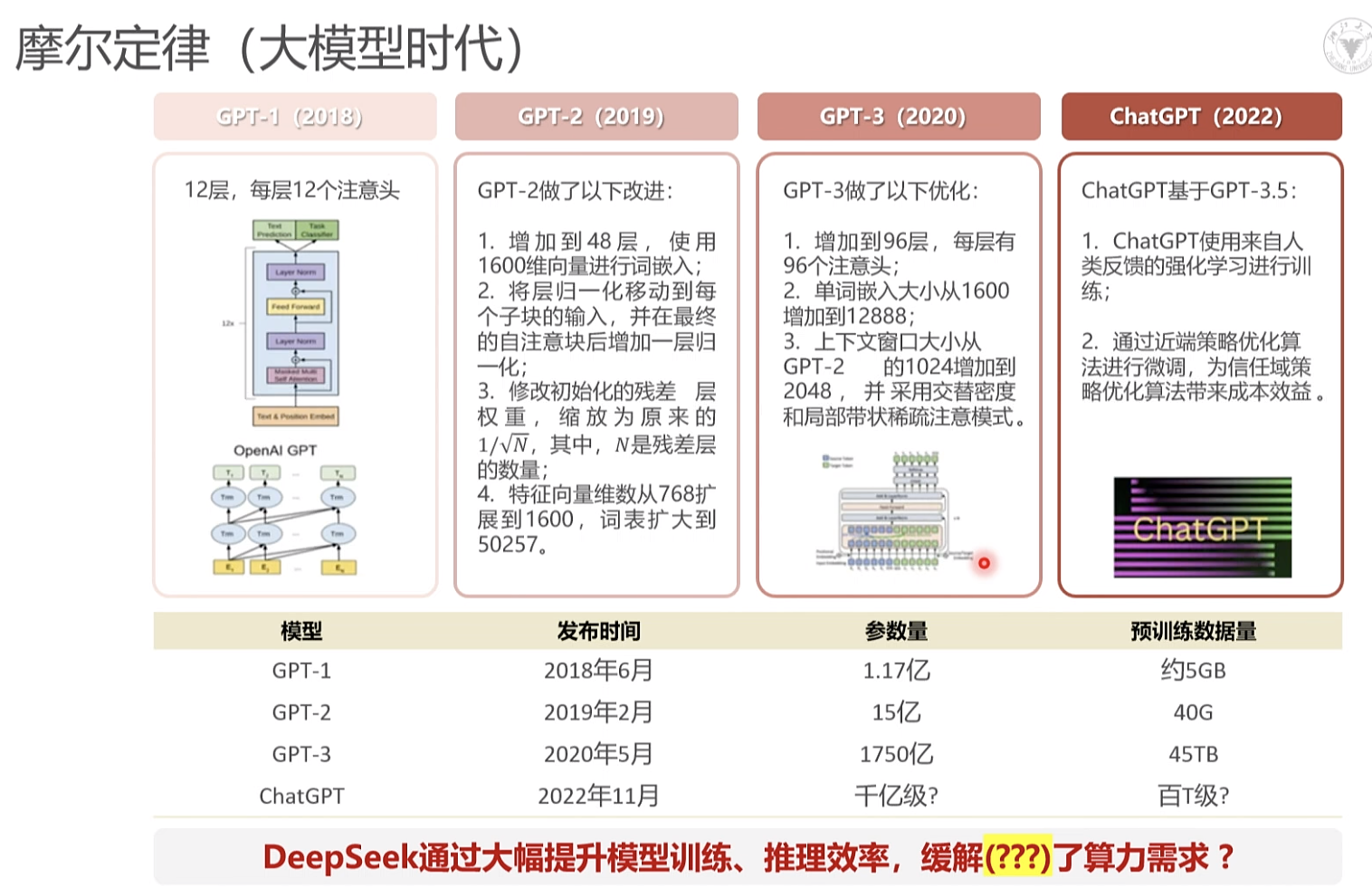
大模型 摩尔定律
18个月 芯片能力翻倍
大模型每6个月, 指数级上升。
deepseek为什么会提升了推理效率。 - 英伟达受影响。
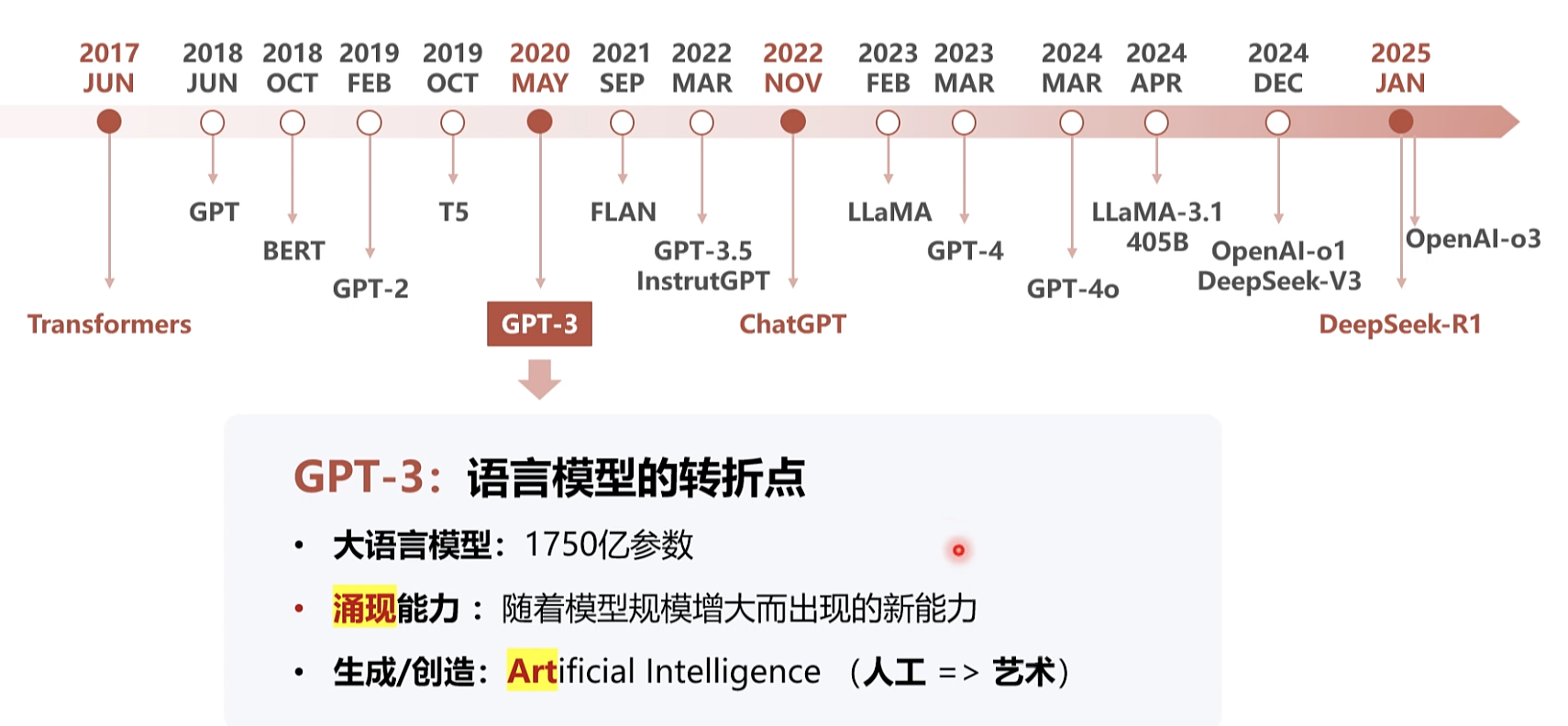
aigc GPT-3: 语言模型的转折点
艺术词根,Art
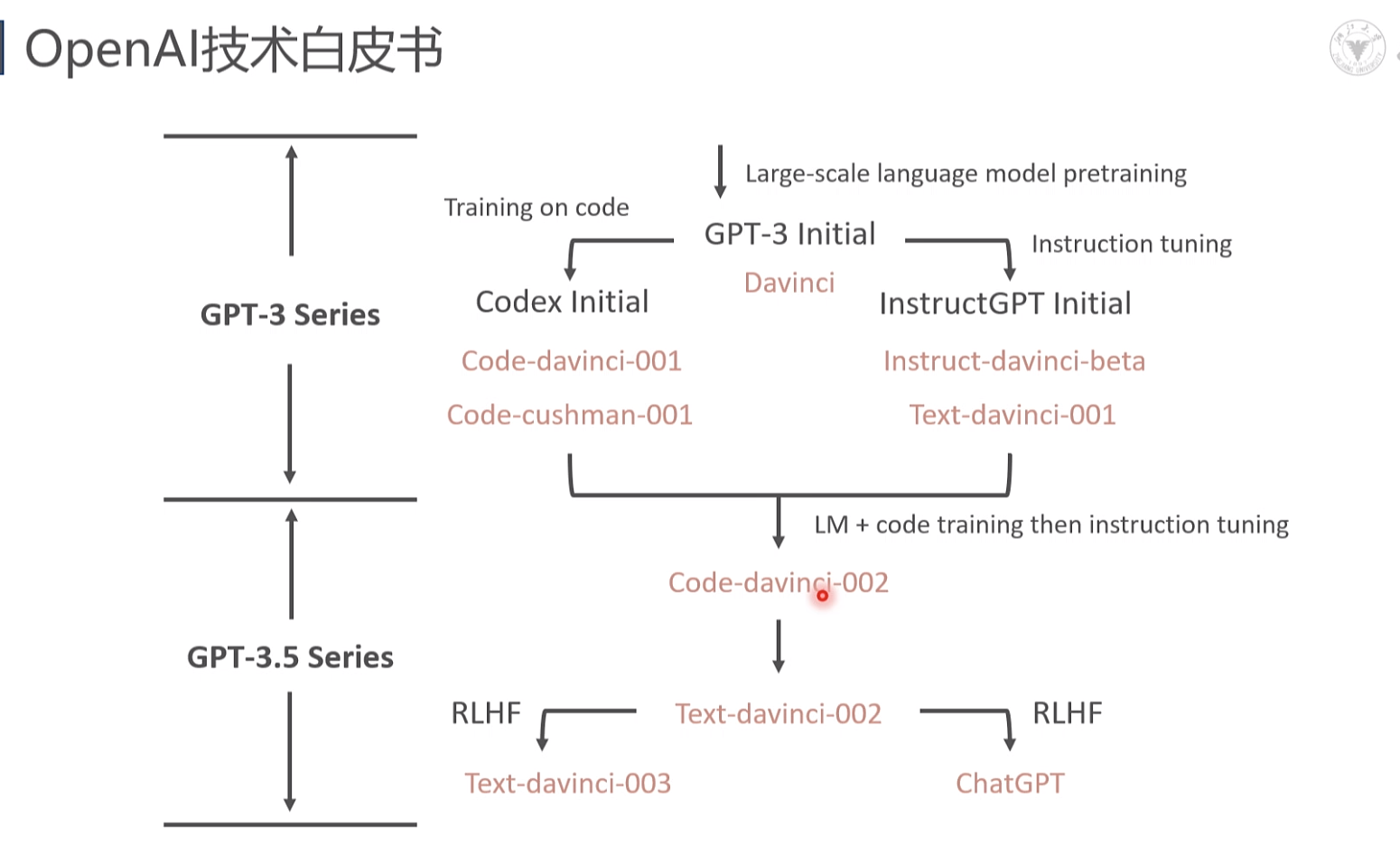
openai 技术白皮书
Training on coc GPT-3 Initial nstruction tuning 初代 GPT-3 展示了三个重要能力 (来自于大规模的预训练) 语言生成:来自语言建模的训练目标(说人话) 世界知识: 来自 3000 亿单词的训练语料库(百晓生) 上下文学习: 上下文学习可以泛化,仍然难以溯源 (触类旁通 初代 GPT-3 表面看起来很弱,但有非常强的潜力,展示出极为强大的“涌现”能力
GPT-3 Initia nstruction tuning GPT-3 Series Codex Initialo InstructGPT Initial 2020 - 2021 年,penAl 投入了大量的精力通过代码训练和指令微调来增强 GPT-3。 使用思维链进行复杂推理的能力很可能是代码训练的一个神奇副产物使用指令微调将 GPT-3.5 的分化到不同的技能树 (数学家/程序员/...
1) 指令微调不会为模型注入新的能力 (解锁能力)2) 指令微调牺牲性能换取与人类对齐 (“对齐税”) code training then instruci Code-davinci-002
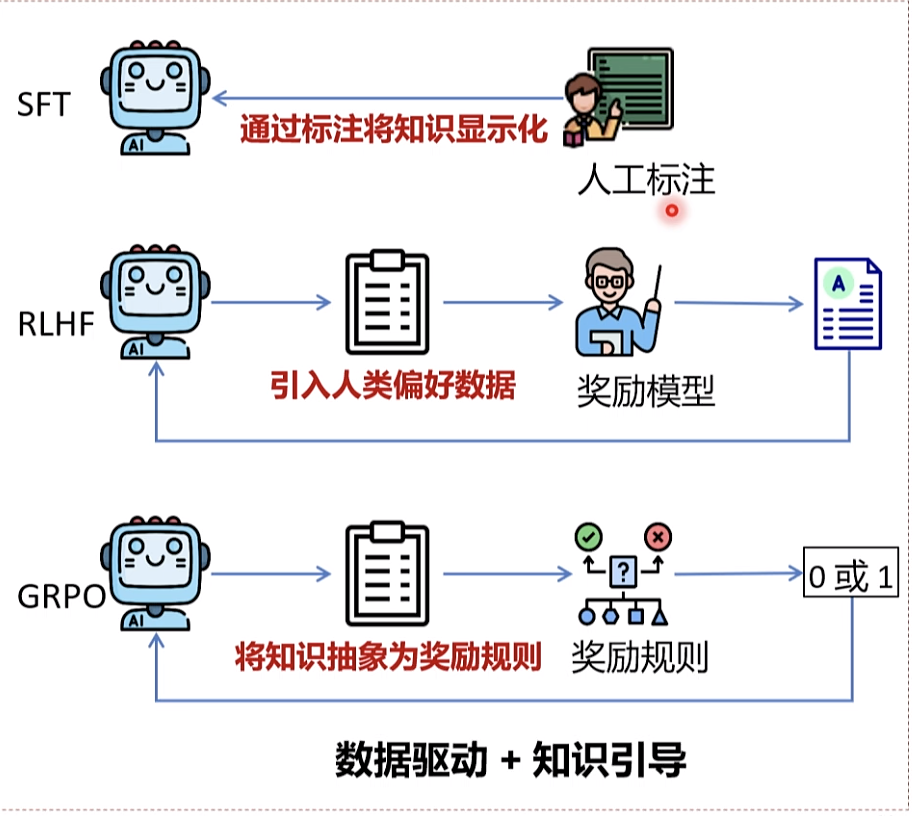
RLHF(基于人类反馈的强化学习的指今微调)触发的能力: 翔实的回应 公正的回应 拒绝不当问题 拒绝其知识范围之外的问题
open 4o 是文科
语言能力
deep seek 推理能力
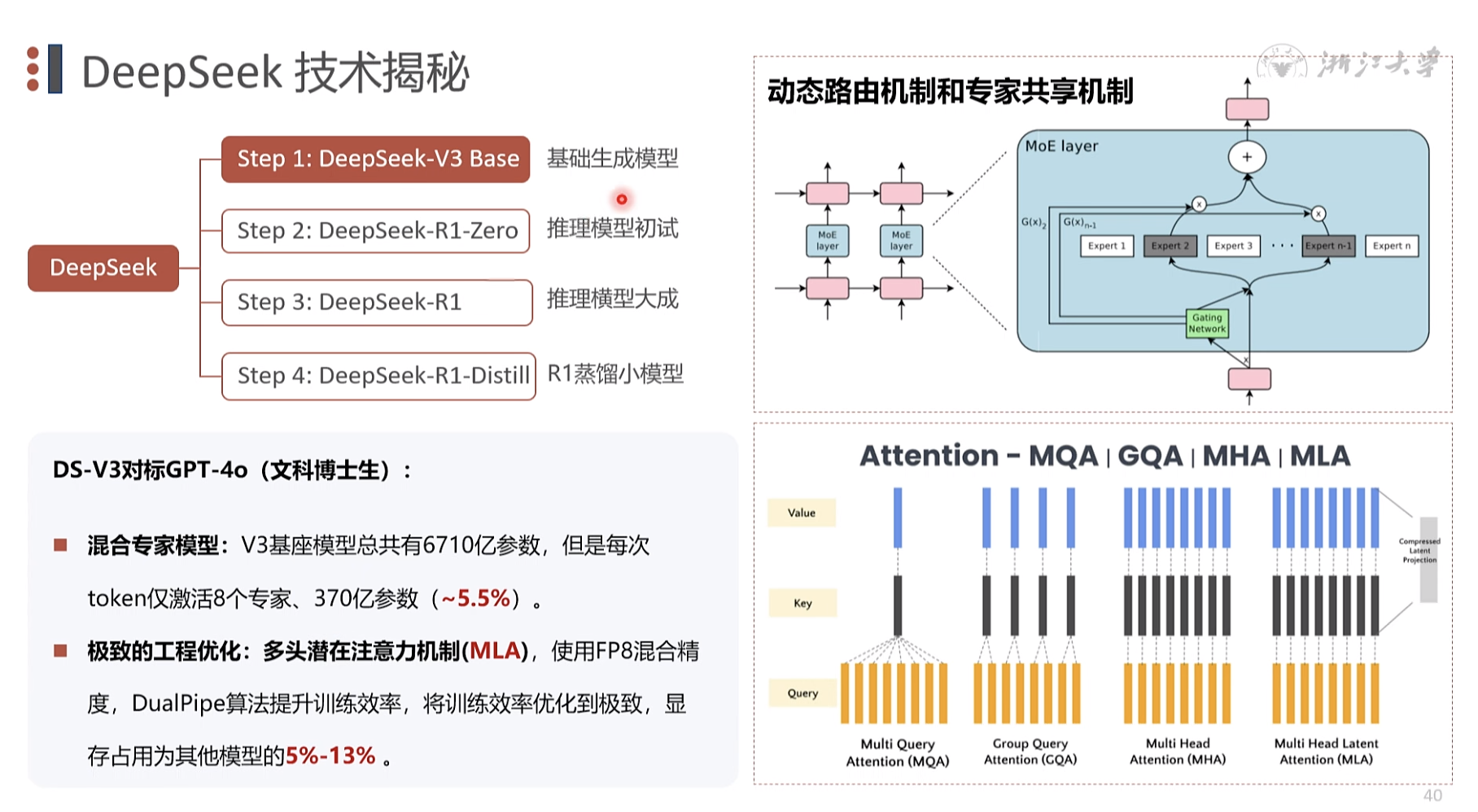
DeepSeek
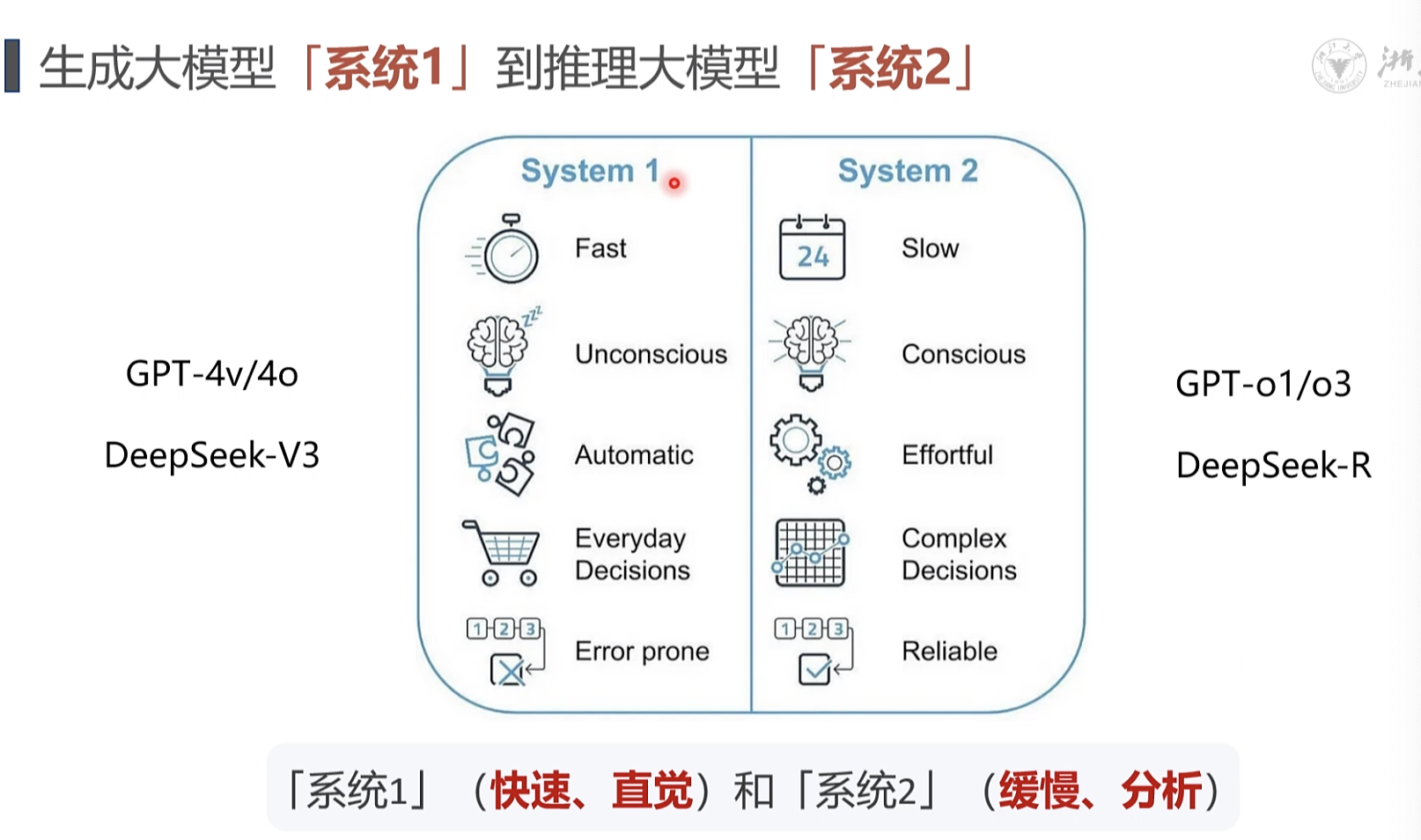
推理模型: 从[生成]到[推理] 的重心转变 · OpenAl-o1/o3: 推理能力的一大飞跃DeepSeek-V3/R1: 专家模型、强化学习,开源,效率
v3 文科 ,语言理解 DS-V3对标GPT-4o (文科博士生) 混合专家模型: V3基座模型总共有6710亿参数,但是每次token仅激活8个专家、370亿参数 (~5.5%)
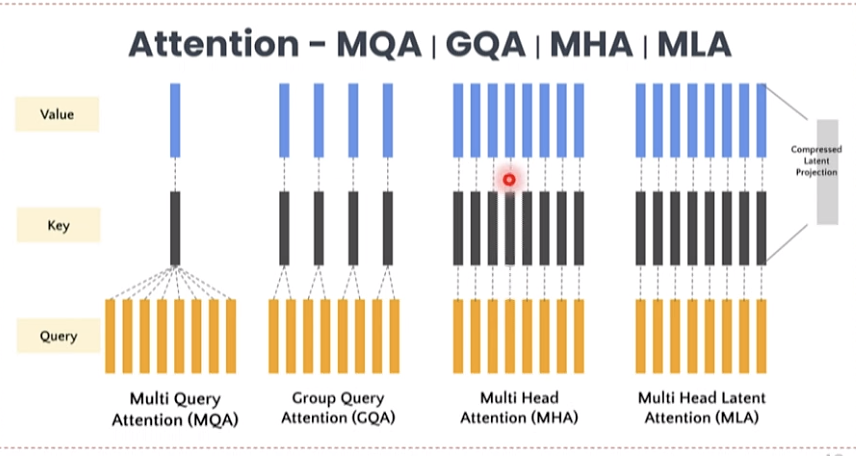
极致的工程优化:多头潜在注意力机制(MLA),使用FP8混合精度,DualPipe算法提升训练效率,将训练效率优化到极致,显存占用为其他模型的5%-13%
训练成本 1/10 推理成本 1/20
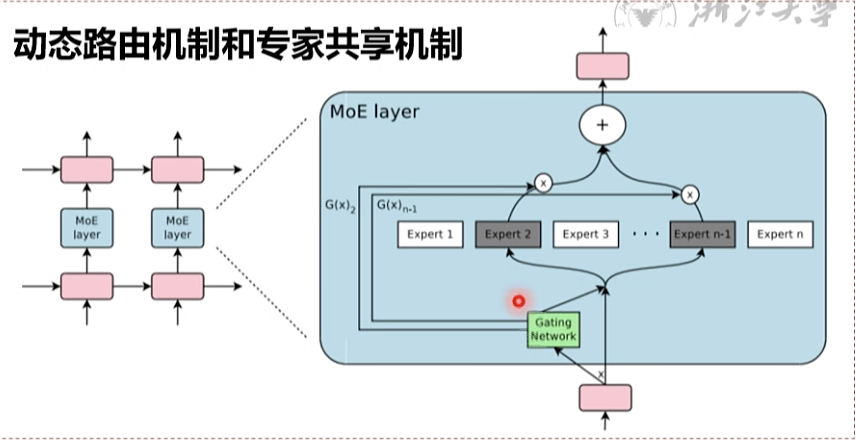
混合专家模型 1991年提出 ,现在优化结构,用于推理
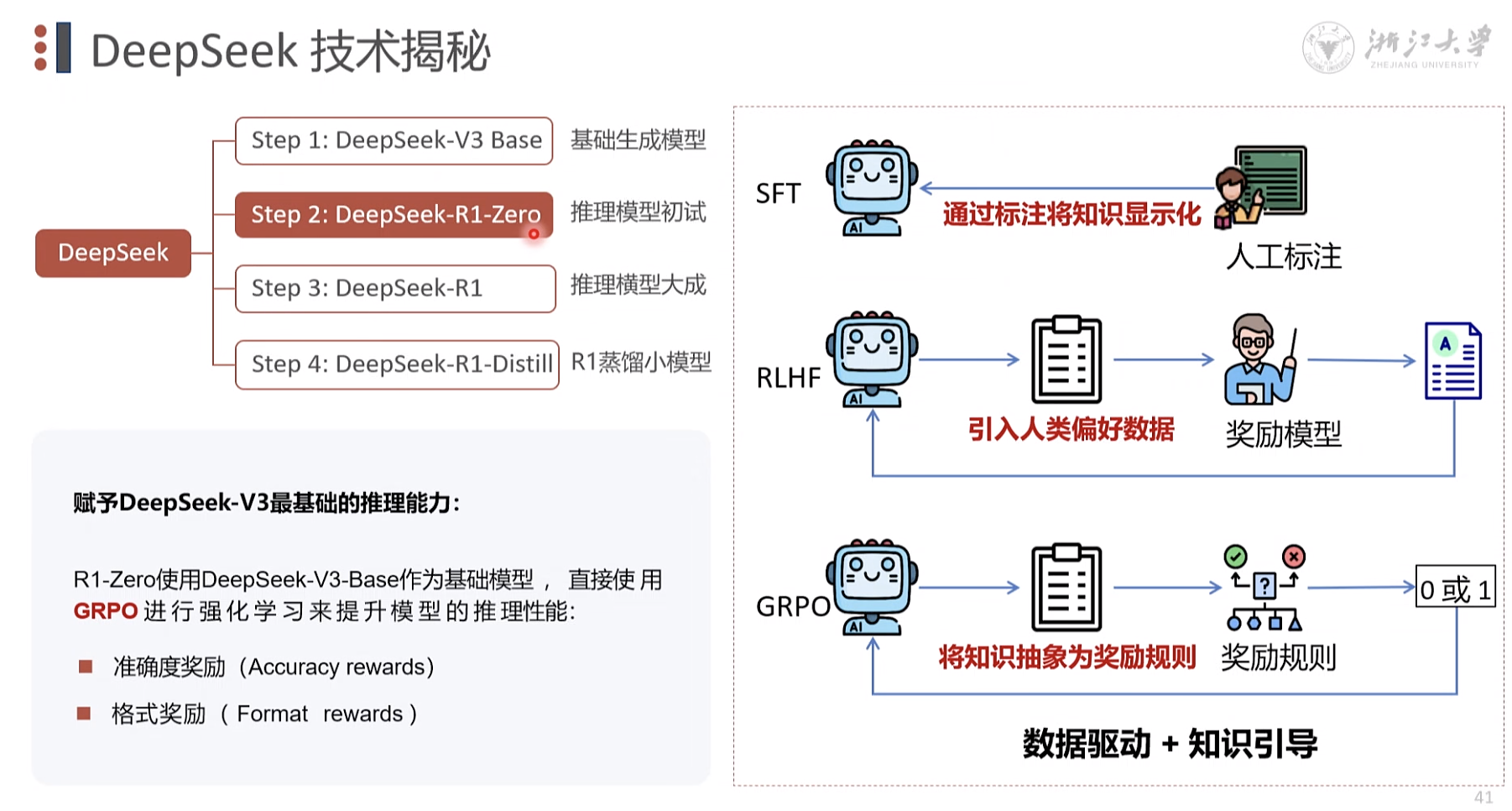
推理模型 初试 赋予DeepSeek-V3最基础的推理能力: R1-Zero使用DeepSeek-V3-Base作为基础模型 , 直接使 用GRPO 进行强化学习来提升模型的推理性能: 准确度奖励 (Accuracy rewards) 格式奖励 ( Format rewards )
R1-Zero
指令微调 GRPO 规则组合,简画模型, 降低评分 压力。 没有数据集都可以
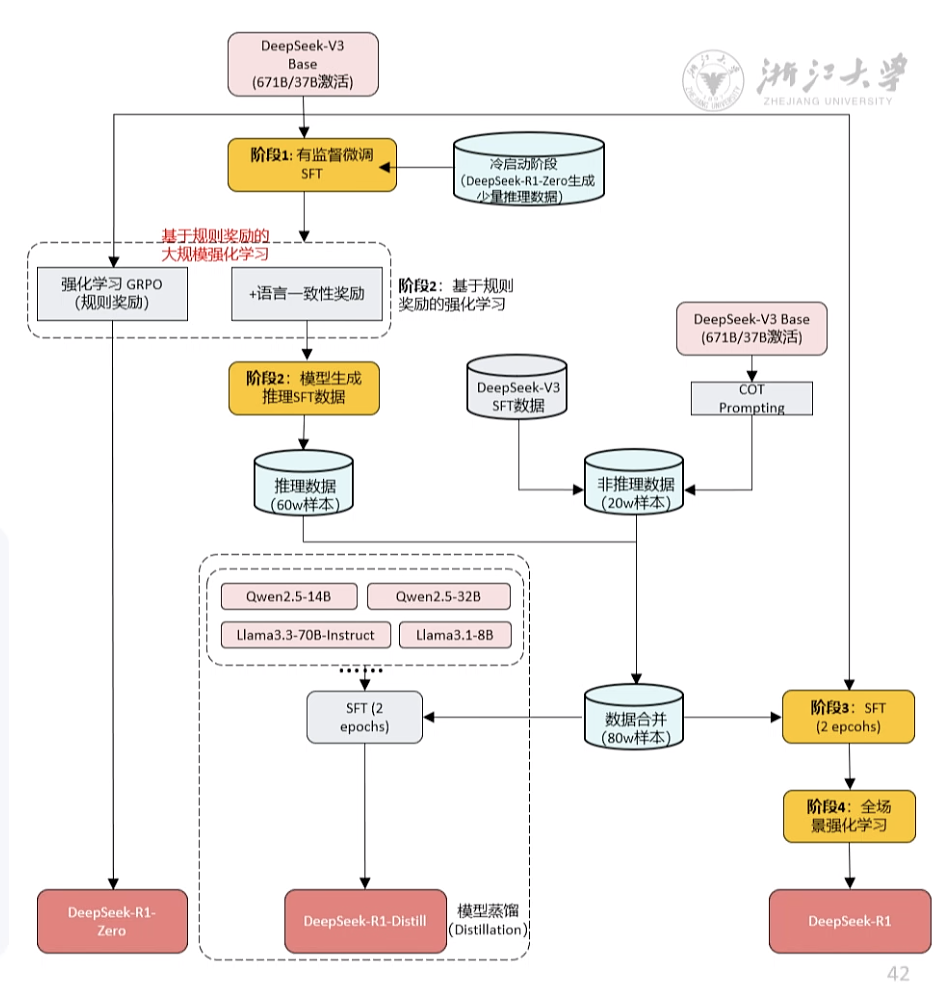
DS-R1对标OpenAl-o1 (理科博士生)阶段1: DeepSeek-R1-Zero生成少量推理数据 + SFT => 为V3植入初步推理能力 (冷启动)阶段2: 根据规则奖励直接进行强化学习 (GRPO) 训练=>提升推理能力 (多轮迭代,获取大量推理数据)阶段3:选代生成推理/非推理样本微调 => 增强全场景能力阶段4: 全场景强化学习 => 人类偏好对齐 (RLHF)
SFP 理论推理 微调
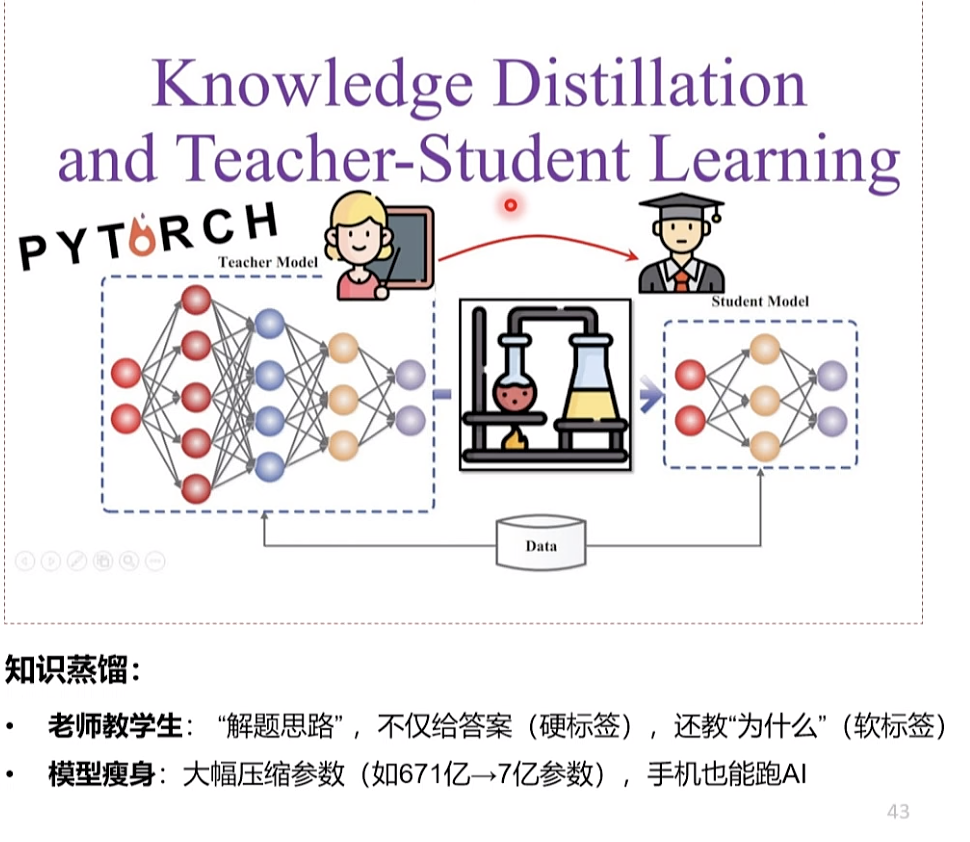
Step 4: DeepSeek-R1-Distill R1蒸馏小模型 DeepSeek-R1-Distill模型: (1) 基于各个低参数量通用模型 (千问、Llama等)2)使用DeepSeek-R1同款数据微调(3) 大幅提升低参数量模型性能
蒸馏,好比提问高质量问题,抽取核心知识问题。 知识蒸馏 老师教学生:“解题思路”,不仅给答案(硬标签)还教“为什么”(软标签)模型瘦身:大幅压缩参数(如671亿 7亿参数),手机也能跑AI 大模型瘦身,可以用于某些领域使用。 手机跑ai,
新一代智能体
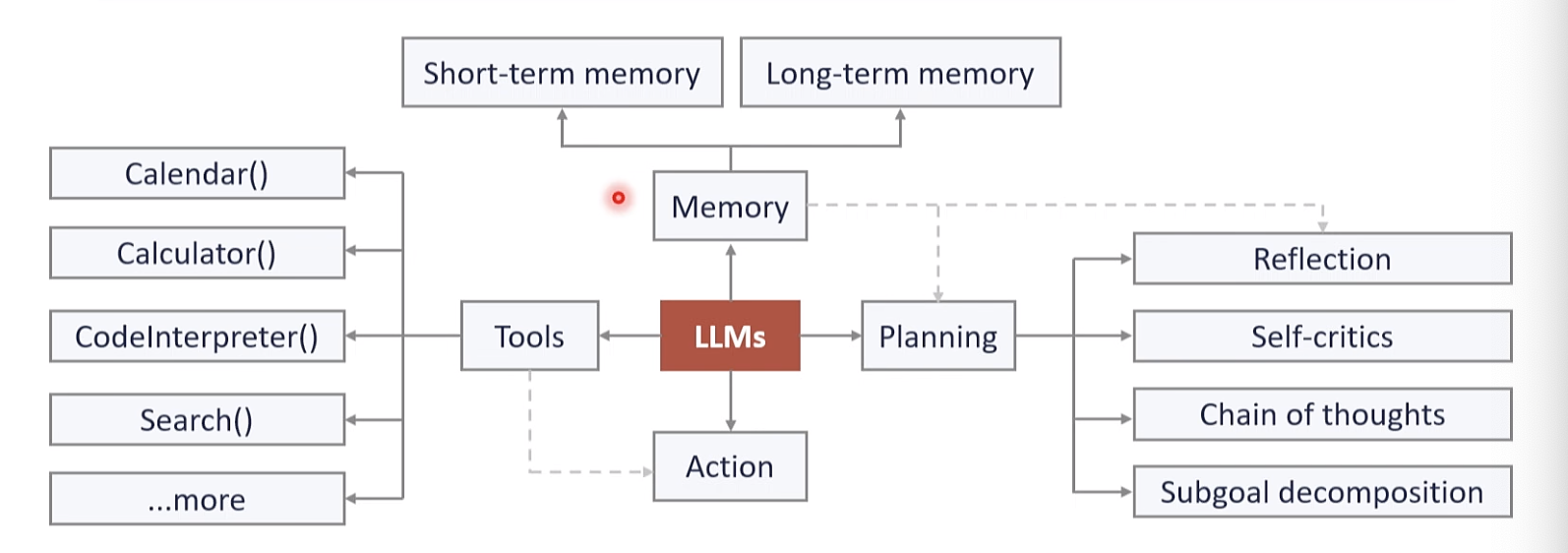
[系统2]LLM是Agent的大脑,其核心能力是“逻辑推理0 Planning skills: 对问题进行拆解得到解决路径,既进行任务规划Tool Use: 评估自己所需的工具,进行工具选择,并生成调用工具请求短期记忆包括工具返回值,已完成推理路径,长期记忆包括可访问的外部长期存储等Memory:
|
|
|
由“时空型GPT”作为决策大脑动,构成一个闭环多智能体协同系统实现流程自组织、即时空智能的自主化构建任务自执行、内容自生成,
自主化构建
|
|
|
|
|

































































 浙公网安备 33010602011771号
浙公网安备 33010602011771号