

PAI Model Gallery 支持云上一键部署 DeepSeek-V3、DeepSeek-R1 系列模型
PAI Model Gallery 支持云上一键部署 DeepSeek-V3、DeepSeek-R1 系列模型 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| https://pai.console.aliyun.com/?regionId=cn-shanghai#/quick-start/models 01 DeepSeek-V3、R1 系列模型DeepSeek-V3 是 DeepSeek 发布的 MoE(Mixture-of-Experts)大语言模型,总参数量为671B,每个 token 激活的参数量为37B。为了实现高效的推理和成本效益的训练,DeepSeek-V3 采用了 MLA(Multi-head Latent Attention)和 DeepSeekMoE 架构。此外,DeepSeek-V3 首次引入了一种无需辅助损失的负载均衡策略,并设定了多 token 预测的训练目标,以提升性能。DeepSeek-V3 在14.8万亿个多样且高质量的 token 上对模型进行了预训练,随后通过监督微调(SFT)和强化学习来充分发挥其潜力。DeepSeek-R1 是 DeepSeek 发布的高性能 AI 推理模型,在后训练阶段大规模使用强化学习技术,显著提升了模型的推理能力,在数学、代码、自然语言推理等任务上,其性能与 OpenAI 的 o1 正式版相当。DeepSeek-R1 具有660B的参数量,DeepSeek 开源 660B 模型的同时,通过模型蒸馏,微调了若干参数量较小的开源模型,其中包括:
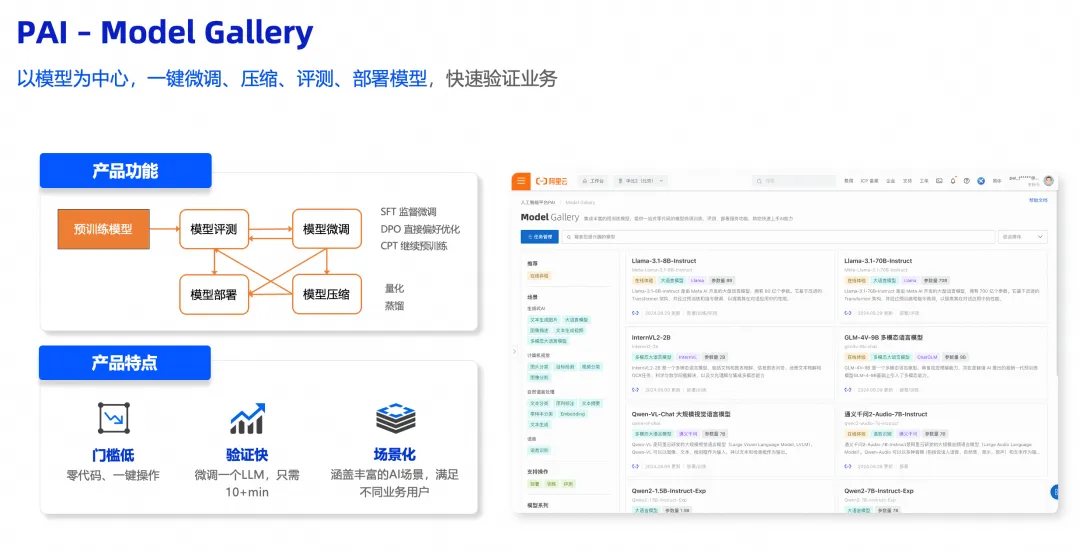
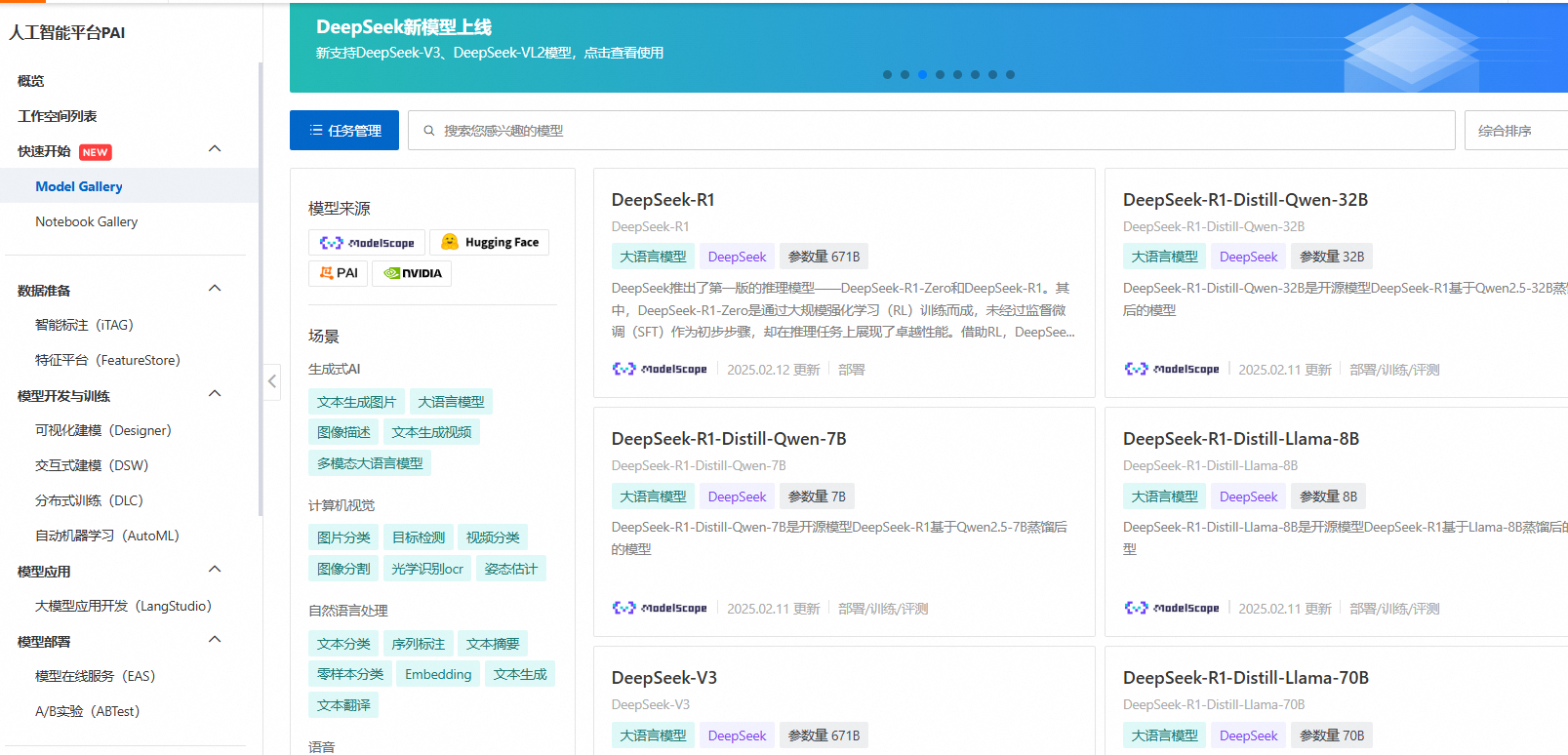
02 PAI Model Gallery 简介Model Gallery 是阿里云人工智能平台 PAI 的产品组件,它集成了国内外 AI 开源社区中优质的预训练模型,涵盖了 LLM、AIGC、CV、NLP 等各个领域,如Qwen,DeepSeek等系列模型。通过 PAI 对这些模型的适配,用户可以零代码实现从训练到部署再到推理的全过程,简化了模型的开发流程,为开发者和企业用户带来了更快、更高效、更便捷的 AI 开发和应用体验。PAI Model Gallery 访问地址:https://pai.console.aliyun.com/#/quick-start/model03
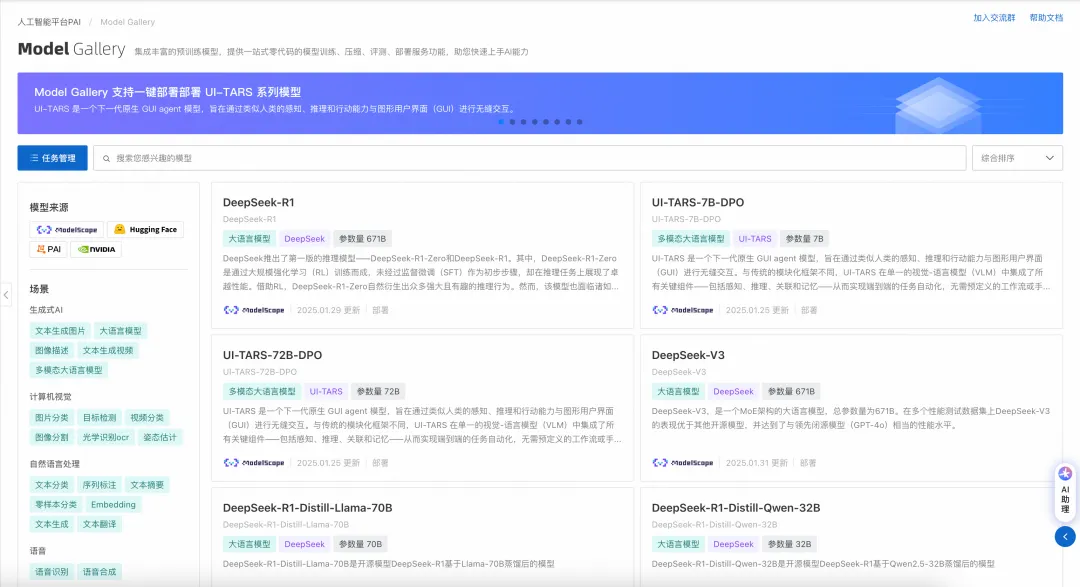
PAI Model Gallery 一键部署 Deep Seek-V3、Deep Seek-R11. 进入 Model Gallery 页面(链接:https://pai.console.aliyun.com/#/quick-start/models)
欢迎各位开发者持续关注和使用 PAI-Model Gallery,Model Gallery 会不断上线 SOTA 模型。如果您有任何模型需求,欢迎您联系我们 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
一键部署DeepSeek-V3、DeepSeek-R1模型更新时间:2025-02-12 11:21:24
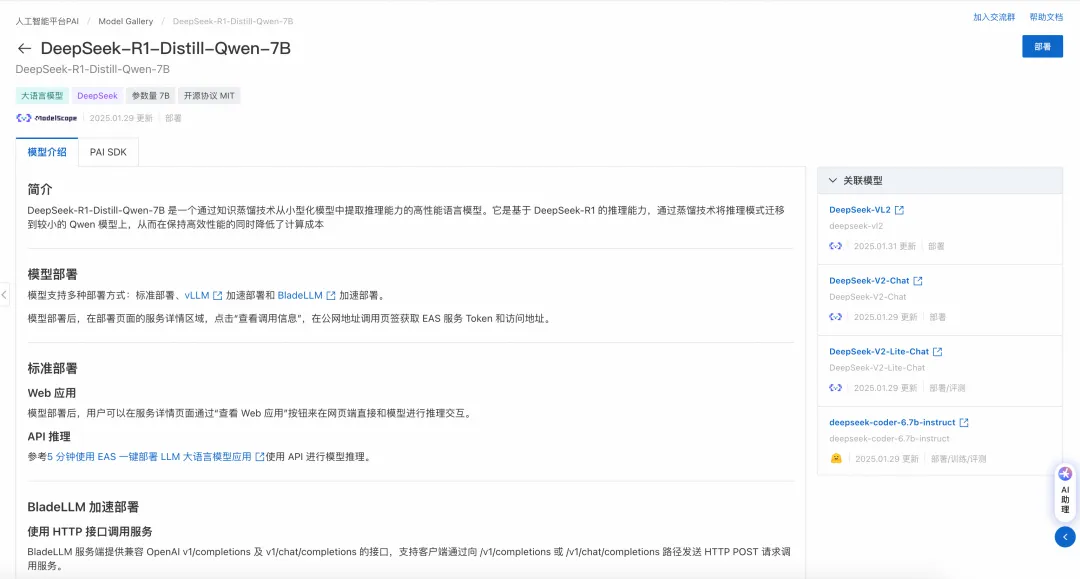
DeepSeek-V3是由深度求索公司推出的一款拥有6710亿参数的专家混合(MoE)大语言模型,DeepSeek-R1是基于DeepSeek-V3-Base训练的高性能推理模型。Model Gallery提供了vLLM或BladeLLM加速部署功能,帮助您一键部署DeepSeek-V3和DeepSeek-R1系列模型。 支持的模型列表DeepSeek-R1、DeepSeek-V3满血版模型的参数量较大(671B),所需配置和成本较高(8卡96G显存以上)。建议您选择蒸馏版模型(机器资源较充足、部署成本较低)。 根据测试,DeepSeek-R1-Distill-Qwen-32B模型的效果和成本较优,适合云上部署,可尝试作为DeepSeek-R1的替代模型。您也可以选择7B、8B、14B等其他蒸馏模型部署,Model Gallery还提供了模型评测功能,可以评测模型实际效果(评测入口在模型详情页右上角)。 表中给出的是最低所需配置机型,在Model Gallery的部署页面的资源规格选择列表中系统已自动过滤出模型可用的公共资源规格。
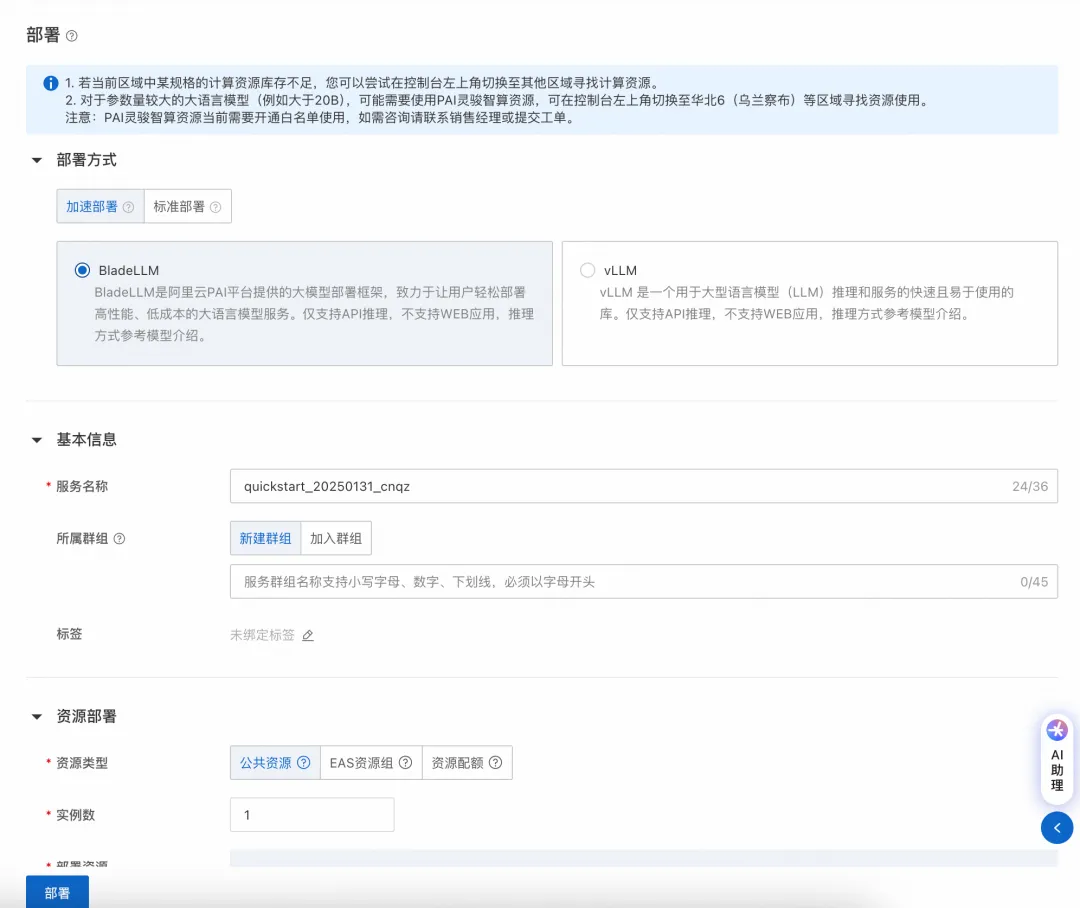
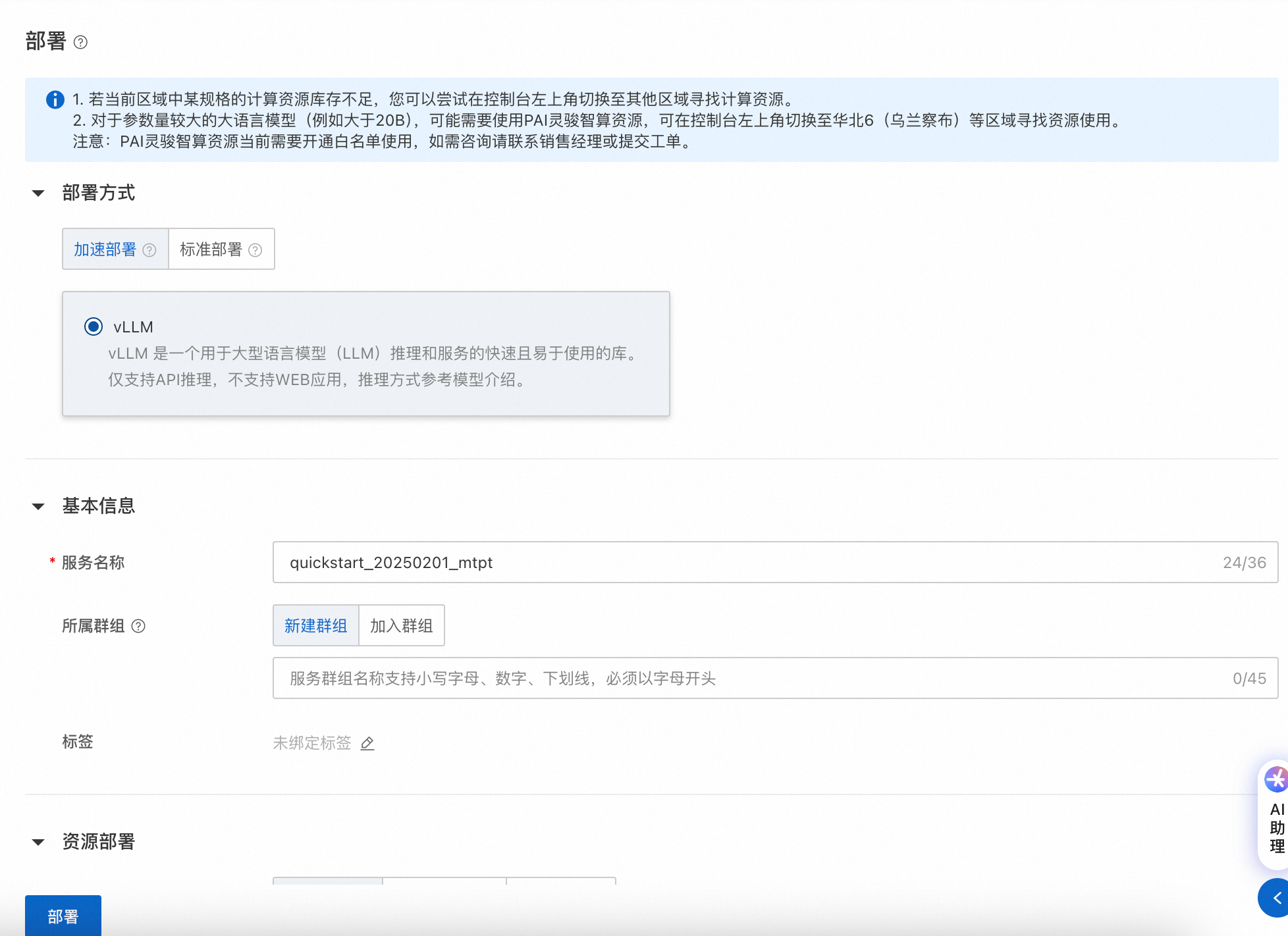
部署方式说明:
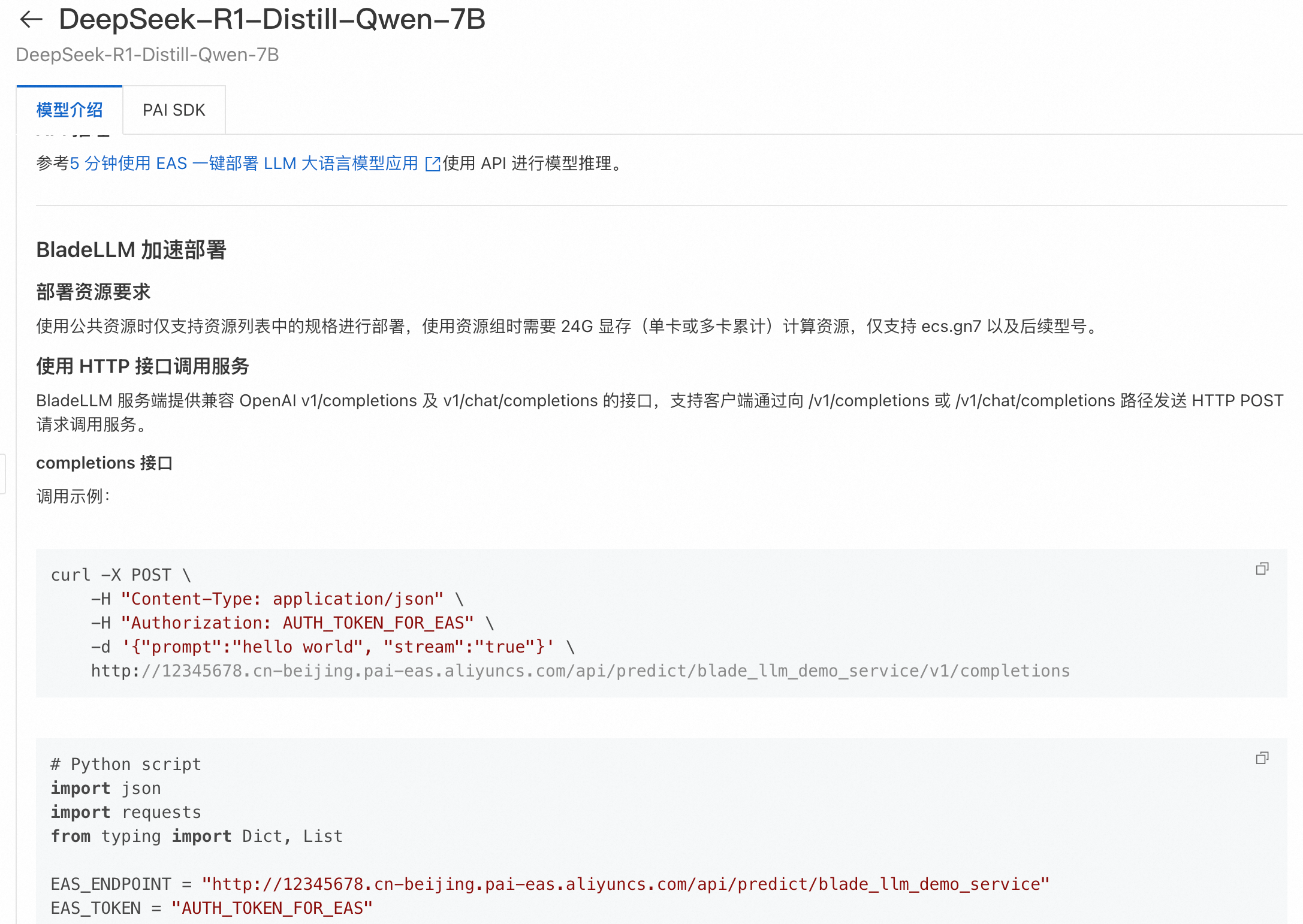
推荐使用加速部署(BladeLLM、SGLang),性能和支持的最大Token数都会更优。 加速部署仅支持API调用方式,标准部署支持API调用方式及WebUI chat界面。 部署模型
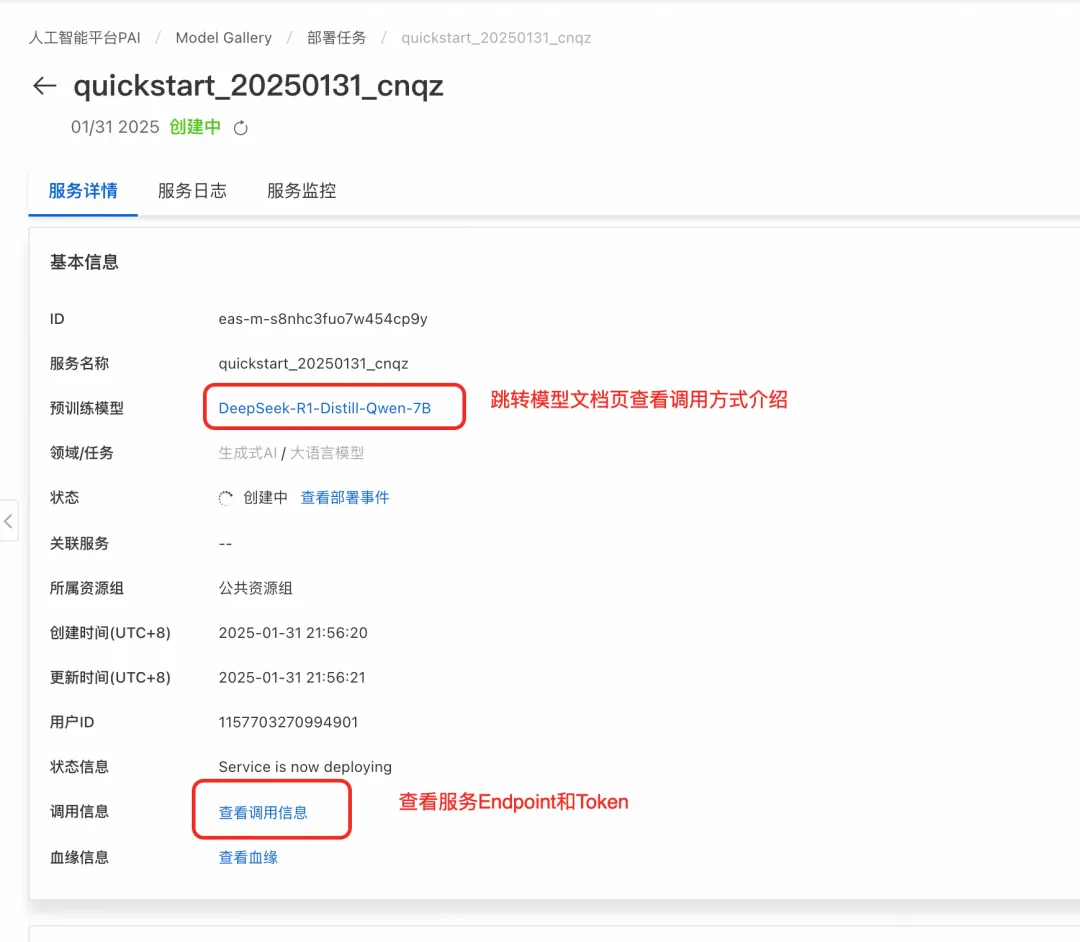
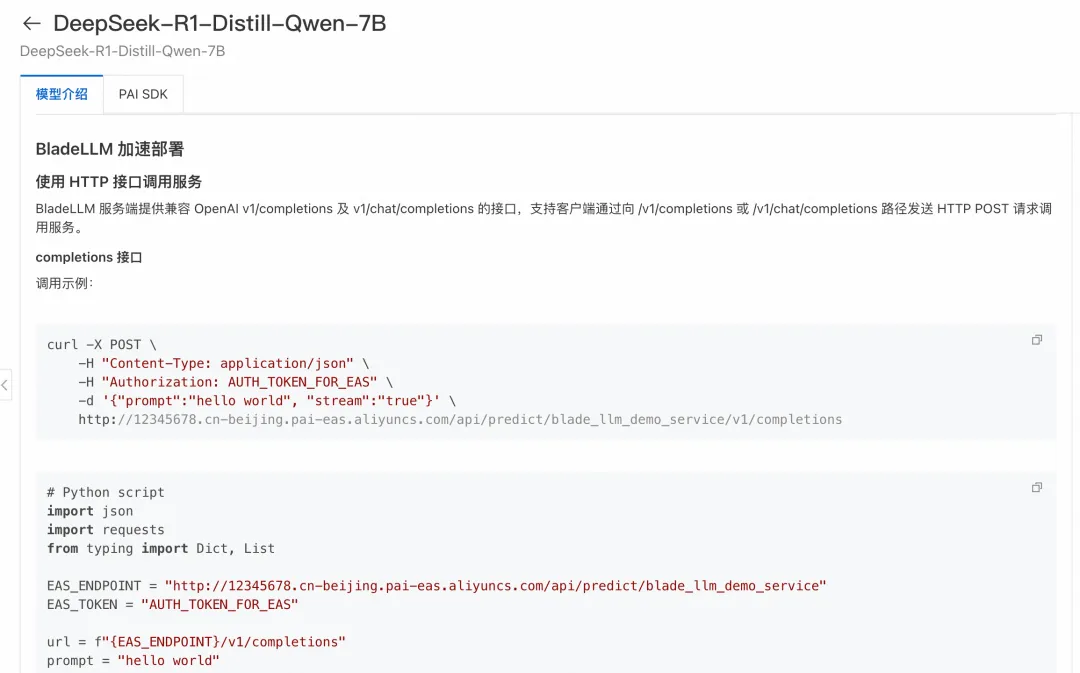
使用推理服务部署成功后,在服务页面单击查看调用信息获取调用的 Endpoint 和 Token。 不同部署方式支持的服务调用方式不同,您可以在Model Gallery的模型介绍页查看详细说明。
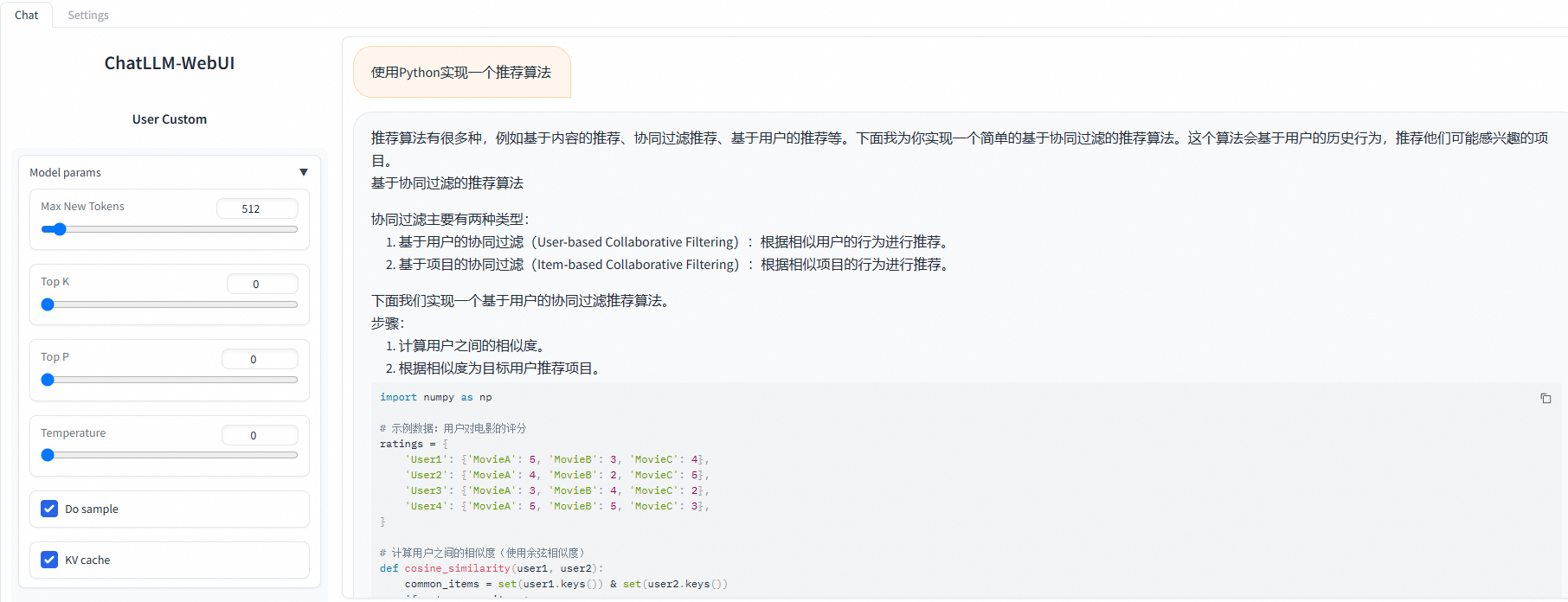
如果是标准部署,支持Web应用。在PAI-Model Gallery > 任务管理 > 部署任务中单击已部署的服务名称,在服务详情页面右上角单击查看WEB应用,即可通过ChatLLM WebUI进行实时交互。
API调用,详情请参见如何使用API进行模型推理。 关于成本
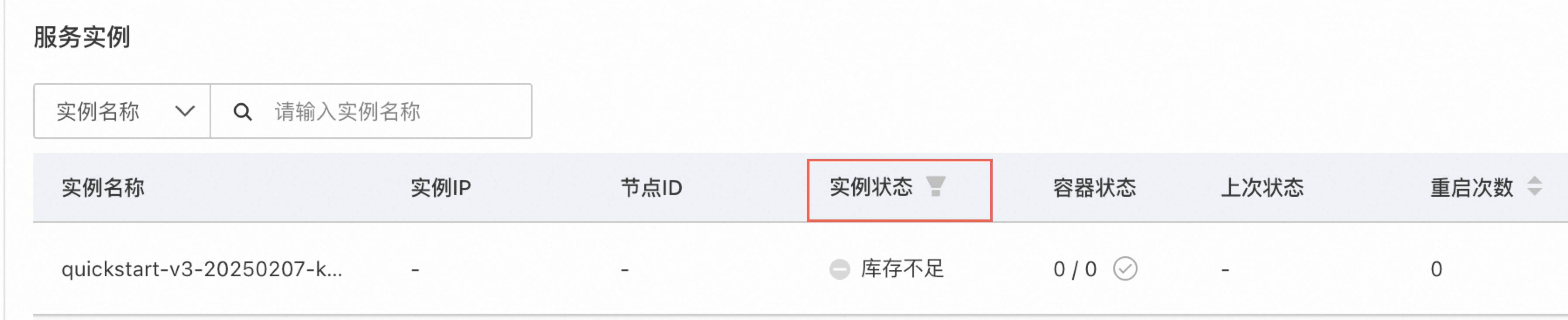
FAQ点击部署后服务长时间等待可能的原因:
您可以耐心等待观察一段时间,如果服务仍长时间无法正常启动运行,建议尝试以下步骤:
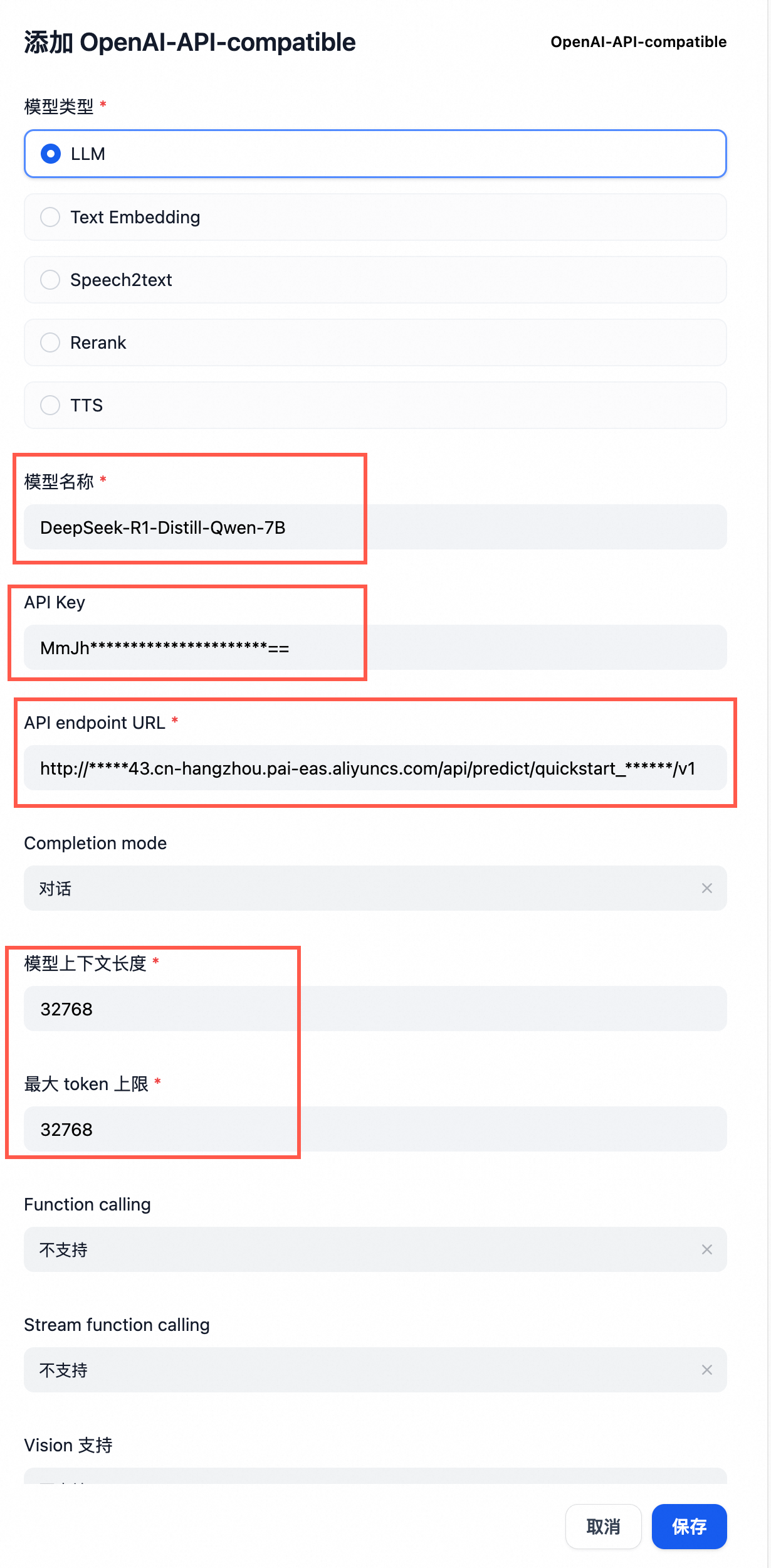
服务部署成功后,调用API返回404请检查调用的URL是否加上了OpenAI的API后缀,例如v1/chat/completions。详情可以参考模型主页调用方式介绍。 模型部署之后没有“联网搜索”功能“联网搜索”功能并不是仅通过直接部署一个模型服务就能实现的,而是需要基于该模型服务自行构建一个AI应用(Agent)来完成。 通过PAI的大模型应用开发平台LangStudio,可以构建一个联网搜索的AI应用,详情请参考Chat With Web Search应用流。 模型服务如何集成到AI应用(以Dify为例)以DeepSeek-R1-Distill-Qwen-7B模型为例,建议采用vLLM加速部署。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
https://www.aliyun.com/solution/tech-solution/deepseek-r1-for-platforms?spm=5176.21213303.J_v8LsmxMG6alneH-O7TCPa.5.39842f3d1J3U3K&scm=20140722.S_product@@%E6%8A%80%E6%9C%AF%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88@@2868650._.ID_product@@%E6%8A%80%E6%9C%AF%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88@@2868650-RL_DeepSeek-LOC_2024SPAllResult-OR_ser-PAR1_213e365517394283044626249e5cb4-V_4-RE_new6-P0_0-P1_0 0门槛
https://chatboxai.app/zh#download
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
跳转至主内容
产品与服务计算存储网络与CDN安全中间件数据库NoSQL 数据库数据仓库大数据计算数据计算与分析人工智能与机器学习企业服务与云通信企业基础服务迁移与运维管理 Model Gallery
集成丰富的预训练模型,提供一站式零代码的模型训练、压缩、评测、部署服务功能,助您快速上手AI能力
通义千问2 Megatron CPT系列模型发布
最新发布Qwen2 Megatron CPT(继续预训练)系列模型,立即点击查看。
 Model Gallery 支持一键部署部署 UI-TARS 系列模型
UI-TARS 是一个下一代原生 GUI agent 模型,旨在通过类似人类的感知、推理和行动能力与图形用户界面(GUI)进行无缝交互。
Model Gallery支持部署NVIDIA NIM模型了!
NVIDIA NIM是英伟达推出的一套易于使用的预构建容器工具,NIM模型大部分是英伟达做过优化的模型,相比原始开源模型有显著的部署性能优化,点击查看
DeepSeek新模型上线
新支持DeepSeek-V3、DeepSeek-VL2模型,点击查看使用
阿里最新重磅开源模型已上线
新上线阿里巴巴最新重磅开源模型QwQ-32B-Preview、Marco-o1,立即点击体验。
通义千问2.5系列模型发布!
通义千问2.5系列模型已陆续发布!在预训练模型与对话模型之外,还新增了代码生成与数学推理专项模型,立即点击查看!
裁判员模型评测功能上线!
模型评测“专家模式”已支持裁判员模型评测功能,使用能力更强的LLM作为裁判来评估其他LLM在开放性问题上的表现。该功能限时免费,欢迎在模型详情页点击“评测”->“切换到专家模式”使用该功能。
体验AIGC文生视频
最新发布AIGC文生视频模型CogVideoX、PAI平台自研的EasyAnimate_v3(类Sora模型),立即点击查看。
通义千问2 Megatron CPT系列模型发布
最新发布Qwen2 Megatron CPT(继续预训练)系列模型,立即点击查看。
Model Gallery 支持一键部署部署 UI-TARS 系列模型
UI-TARS 是一个下一代原生 GUI agent 模型,旨在通过类似人类的感知、推理和行动能力与图形用户界面(GUI)进行无缝交互。
模型来源
    场景
生成式AI
计算机视觉
自然语言处理
语音
生物医学
其他
支持操作
体验
模型系列
DeepSeek-R1
DeepSeek-R1
DeepSeek推出了第一版的推理模型——DeepSeek-R1-Zero和DeepSeek-R1。其中,DeepSeek-R1-Zero是通过大规模强化学习(RL)训练而成,未经过监督微调(SFT)作为初步步骤,却在推理任务上展现了卓越性能。借助RL,DeepSee...
2025.02.12 更新
部署
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Qwen-32B是开源模型DeepSeek-R1基于Qwen2.5-32B蒸馏后的模型
2025.02.11 更新
部署/训练/评测
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-7B是开源模型DeepSeek-R1基于Qwen2.5-7B蒸馏后的模型
2025.02.11 更新
部署/训练/评测
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Llama-8B是开源模型DeepSeek-R1基于Llama-8B蒸馏后的模型
2025.02.11 更新
部署/训练/评测
DeepSeek-V3
DeepSeek-V3
DeepSeek-V3,是一个MoE架构的大语言模型,总参数量为671B。在多个性能测试数据集上DeepSeek-V3的表现优于其他开源模型,并达到了与领先闭源模型(GPT-4o)相当的性能水平。
2025.02.12 更新
部署
DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1-Distill-Llama-70B是开源模型DeepSeek-R1基于Llama-70B蒸馏后的模型
2025.02.11 更新
部署/训练/评测
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-14B是开源模型DeepSeek-R1基于Qwen2.5-14B蒸馏后的模型
2025.02.11 更新
部署/训练/评测
DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-1.5B是开源模型DeepSeek-R1基于Qwen2.5-1.5B蒸馏后的模型
2025.02.11 更新
部署/训练/评测
DeepSeek-V3-GGUF
DeepSeek-V3-GGUF
DeepSeek-V3,是一个MoE架构的大语言模型,总参数量为671B。在多个性能测试数据集上DeepSeek-V3的表现优于其他开源模型,并达到了与领先闭源模型(GPT-4o)相当的性能水平。
2025.02.06 更新
部署
UI-TARS-7B-DPO
UI-TARS-7B-DPO
UI-TARS 是一个下一代原生 GUI agent 模型,旨在通过类似人类的感知、推理和行动能力与图形用户界面(GUI)进行无缝交互。与传统的模块化框架不同,UI-TARS 在单一的视觉-语言模型(VLM)中集成了所有关键组件——包括感知、...
2025.02.10 更新
部署
UI-TARS-72B-DPO
UI-TARS-72B-DPO
UI-TARS 是一个下一代原生 GUI agent 模型,旨在通过类似人类的感知、推理和行动能力与图形用户界面(GUI)进行无缝交互。与传统的模块化框架不同,UI-TARS 在单一的视觉-语言模型(VLM)中集成了所有关键组件——包括感知、...
2025.01.25 更新
部署
Qwen2.5-VL-7B-Instruct
Qwen2.5-VL-7B-Instruct
Qwen2.5-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。
2025.02.05 更新
部署/训练
UI-TARS-7B-SFT
UI-TARS-7B-SFT
UI-TARS 是一个下一代原生 GUI agent 模型,旨在通过类似人类的感知、推理和行动能力与图形用户界面(GUI)进行无缝交互。与传统的模块化框架不同,UI-TARS 在单一的视觉-语言模型(VLM)中集成了所有关键组件——包括感知、...
2025.02.10 更新
部署
通义千问2.5-7B-Instruct-1M
Qwen2.5-7B-Instruct-1M
Qwen2.5-1M 是 Qwen2.5 系列模型的长上下文版本,支持最长可达 100 万个 Token 的上下文长度。与 Qwen2.5 128K 版本相比,Qwen2.5-1M 在处理长上下文任务时表现出显著改进的性能,同时保持了其在短任务中的能力。
2025.02.06 更新
部署/训练/评测
通义千问2.5-14B-Instruct-1M
Qwen2.5-14B-Instruct-1M
Qwen2.5-1M 是 Qwen2.5 系列模型的长上下文版本,支持最长可达 100 万个 Token 的上下文长度。与 Qwen2.5 128K 版本相比,Qwen2.5-1M 在处理长上下文任务时表现出显著改进的性能,同时保持了其在短任务中的能力。
2025.02.06 更新
部署/训练/评测
Qwen2-VL-72B-Instruct
qwen2-vl-72b-instruct
Qwen2-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。
2025.01.20 更新
部署
QVQ-72B-Preview
QVQ-72B-Preview
QVQ-72B-Preview 是由 Qwen 团队开发的一个实验性研究模型,专注于提升 AI 的推理能力。作为预览版本,它展示了很强的分析能力。
2025.01.13 更新
部署
QwQ-32B-Preview
QwQ-32B-Preview
QwQ-32B-Preview 是由 Qwen 团队开发的一个实验性研究模型,专注于提升 AI 的推理能力。作为预览版本,它展示了很强的分析能力。
2025.02.06 更新
部署/评测
Llama-3.3-70B-Instruct
Llama-3.3-70B-Instruct
Meta 的 Llama3.3-70B 是经过预训练和指令微调的生成式模型,拥有 700 亿参数(仅处理文本输入/输出)。Llama 3.3 针对多语言对话使用场景进行了优化,并在常见的行业基准测试中优于许多现有的开源和封闭聊天模型。
2025.02.06 更新
部署/评测
通义千问2.5-7B-Instruct
qwen2.5-7b-instruct
通义实验室最新推出的 Qwen2.5 系列 是 Qwen2 系列 的升级版本。这一系列包括了不同规模的 Base 和 Instruct 模型,分别有 0.5B、7B、7B、32B 和 72B 等。Qwen2.5 系列在长文本、多语言处理能力、人类偏好对齐、序列长度等方面都...
2025.02.06 更新
部署/训练/压缩/评测
Qwen2.5-VL-3B-Instruct
Qwen2.5-VL-3B-Instruct
Qwen2.5-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。
2025.02.04 更新
部署/训练
InternLM3-8B-Instruct
internlm3-8b-instruct
InternLM3 已开源了一个拥有80亿参数的指令模型,名为 InternLM3-8B-Instruct,该模型专为通用用途和高级推理设计。
2025.01.17 更新
部署
DeepSeek-VL2
deepseek-vl2
DeepSeek-VL2 是一系列先进的专家混合(Mixture-of-Experts, MoE)视觉-语言模型,显著提升了其前身 DeepSeek-VL 的性能。DeepSeek-VL2 在各种任务中展示了卓越的能力,包括但不限于视觉问答、光学字符识别、文档/表格/图表理...
2025.01.17 更新
部署
UI-TARS-2B-SFT
UI-TARS-2B-SFT
UI-TARS 是一个下一代原生 GUI agent 模型,旨在通过类似人类的感知、推理和行动能力与图形用户界面(GUI)进行无缝交互。与传统的模块化框架不同,UI-TARS 在单一的视觉-语言模型(VLM)中集成了所有关键组件——包括感知、...
2025.02.10 更新
部署
免责声明:Model Gallery 内涉及来源于第三方的模型,阿里云不对三方模型的可用性、合规性、安全性承担任何责任,请您在开启使用前查看三方模型许可协议并在许可范围内使用。此外,您应核实第三方模型的备案情况,对于未通过备案的模型,我们建议您仅可基于测试/研究目的使用。因三方模型导致的风险或者纠纷,需您自行承担全部责任。如您发现 Model Gallery 内展示的三方模型任何问题,请及时与我们联系。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



 浙公网安备 33010602011771号
浙公网安备 33010602011771号