

0206二阶段AI实验课程《机器学习实战:用BaseML、BaseDT搭建线性回归、多项式回归与SVM模型》
二阶段AI实验课程
,将于2月6日开始。具体时间安排如下,直播方式和一阶段上课保持一致:
2月6日,晚上,19:30~21:00(主讲老师:刘正云)
实验内容:
【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。
2月7日,晚上,19:30~21:00(主讲老师:郑祥)
实验内容:【深度学习】训练常见的卷积神经网络模型,如LeNet和MobileNet,能制作个性化的ImageNet数据集,涉及到MMEdu、EasyTrain等工具。
2月8日,晚上,19:30~21:00(主讲老师:邱奕盛)
实验内容:【模型部署】利用统一推理框架实现模型部署。在训练好的模型基础上,设计简洁的体验界面,最终尝试在行空板上实现完整效果的呈现,涉及XEduHub、PySimpleGUI、PySimpleGUIWeb等工具。
第二阶段课程 |
二阶段AI实验课程,将于2月6日开始。具体时间安排如下,直播方式和一阶段上课保持一致: - 2月6日,晚上,19:30~21:00(主讲老师:刘正云) 实验内容:【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。 - 2月7日,晚上,19:30~21:00(主讲老师:郑祥) 实验内容:【深度学习】训练常见的卷积神经网络模型,如LeNet和MobileNet,能制作个性化的ImageNet数据集,涉及到MMEdu、EasyTrain等工具。 - 2月8日,晚上,19:30~21:00(主讲老师:邱奕盛) 实验内容:【模型部署】利用统一推理框架实现模型部署。在训练好的模型基础上,设计简洁的体验界面,最终尝试在行空板上实现完整效果的呈现,涉及XEduHub、PySimpleGUI、PySimpleGUIWeb等工具。 |
| 123456788888888888888888 |
http://site01.openhydra.net:30012/ |
|
模型训练
模型验证
模型推理
|
|
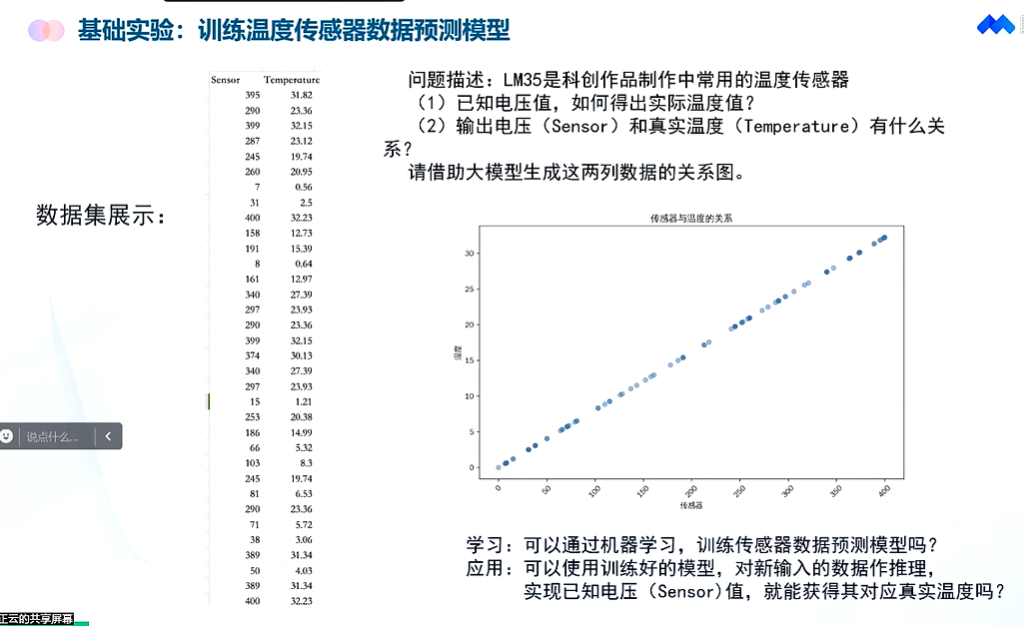
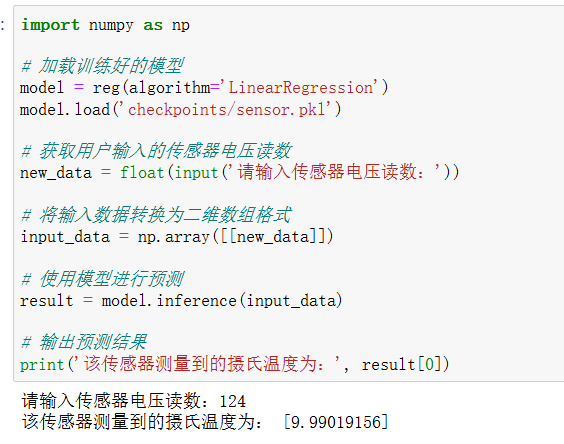
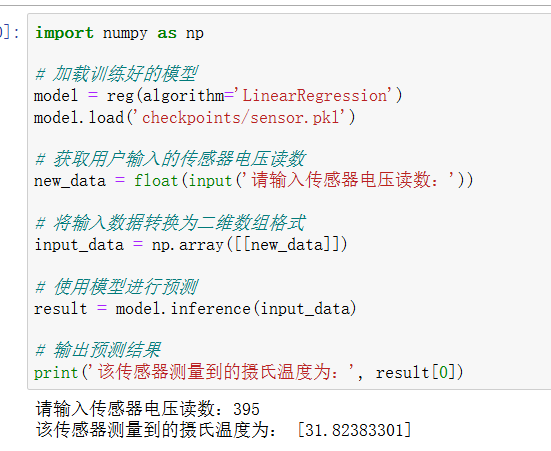
| 实验1 | # 温度推测
回顾任务 预测连续值的任务;
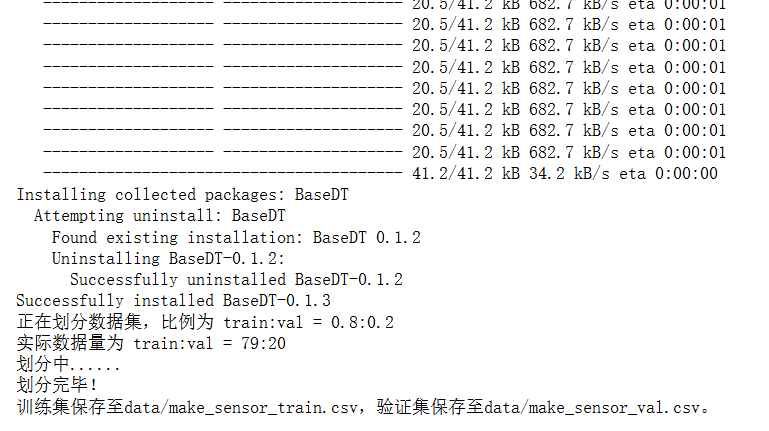
8:2 的方式 ,将数据集进行拆分, 80%分一个表格,(训练集) 20%分一个表格(验证集) xedu的数据处理库,将数据库划分;训练和验证。
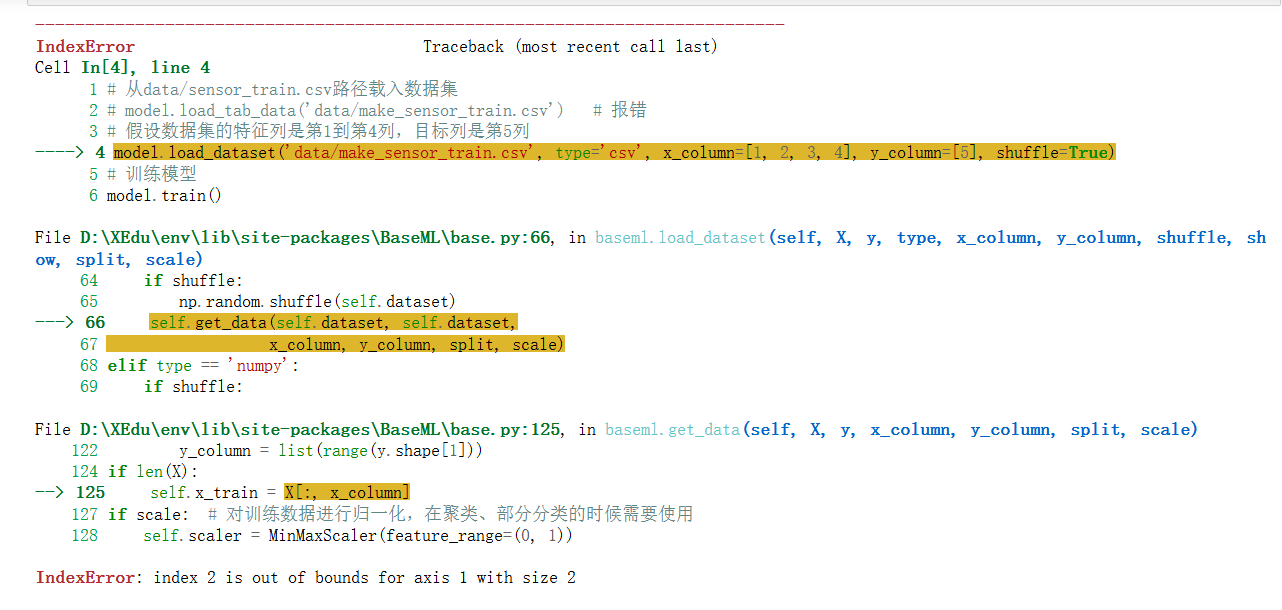
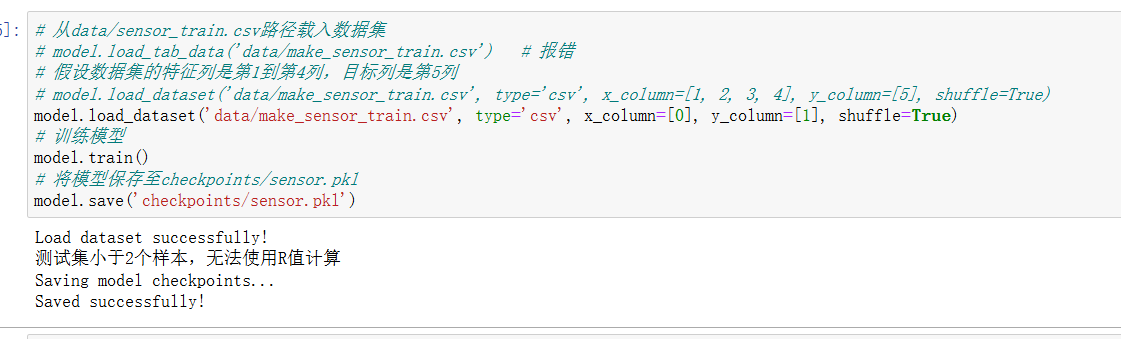
# 更新库文件 !pip install --upgrade BaseDT from BaseDT.dataset import split_tab_dataset # 指定待拆分的csv数据集 path = "data/make_sensor.csv" # 指定特征数据列、标签列、训练集比重 tx,ty,val_x,val_y = split_tab_dataset(path,data_column=range(0,1),label_column=1,train_val_ratio=0.8)
|
|
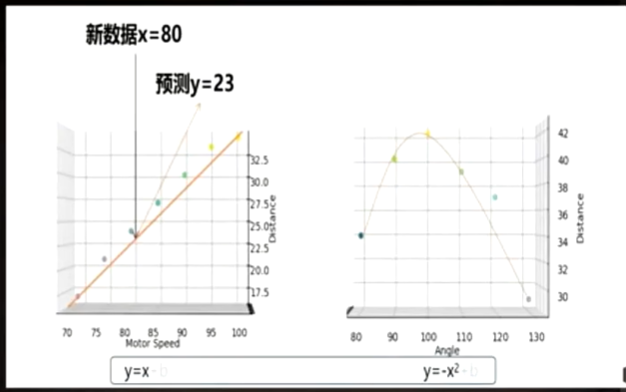
实验3 训练投石机
|
多项式 归回分析
回归于线性的关系。
|
|
数据角度推电机
|
|
|
图片 - 提取成手势关键点坐标。 形成数据集
xeduhub可以提取;
处理高危数据;
回归修改成分类;多项式回归 - 换 svm
|
|
|
|
|
|
问题解决
|
|
|
版本更新 或安装 |
版本更新;
!pip install --update xedu-python
!pip install -U xedu-python
|
|
手势识别问题。
|
|
|
11
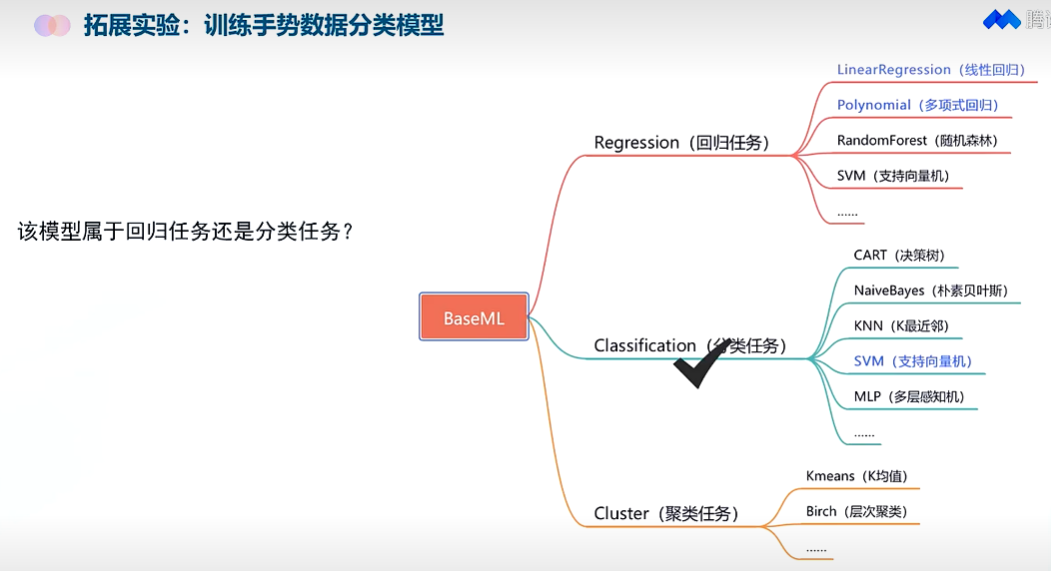
活动3:用支持向量机训练手势分类数据材料
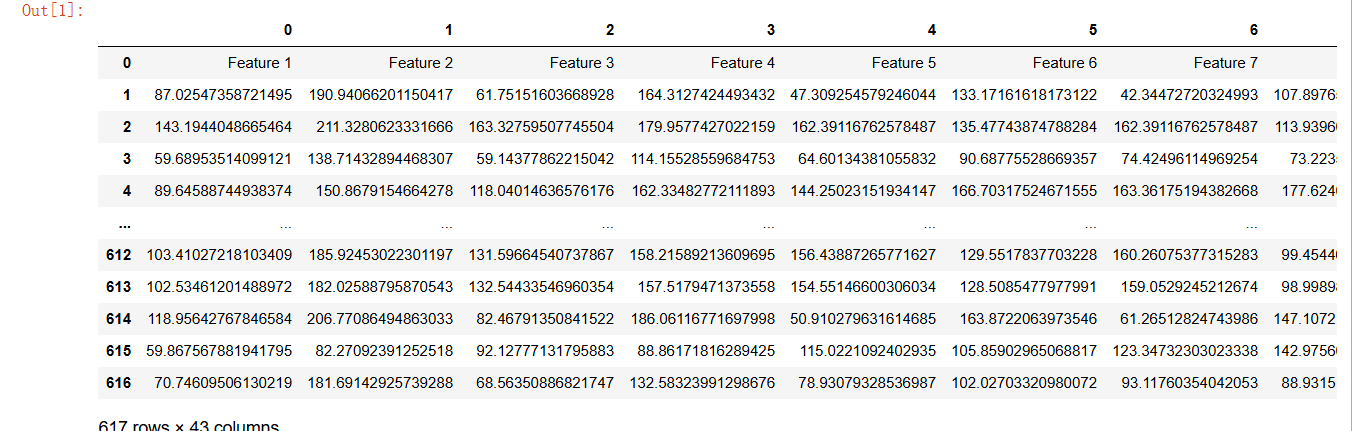
活动目的了解SVM算法的基本原理及其在分类任务中的应用;掌握使用BaseML库实现SVM模型的训练和评估,能够解释模型评估指标的含义. 。; 背景知 识支持向量机(SVM)是一种强大的分类算法,特别适用于高维数据的分类任务。本节课中,我们使用使用BaseML等工具来实现算法。 BaseML的官方文档:https://xedu.readthedocs.io/zh-cn/master/baseml/introduction.html 活动说明:手势分类数据集workflow_pose.csv包含了手势的21个关键点坐标,每个手势对应一个标签。支持向量机(SVM)作为一种高效且强大的分类算法,其在处理复杂分类问题时展现出的优越性能,使其成为了实现手势分类的有力工具。我们将使用手势分类数据集来训练SVM模型,并预测手势类别。 步骤1:数据准备查看数据集 数据集workflow_pose_train.csv是使用XEduHub提取的关键点信息文件,前42列为关键点信息数据,代表21个关键点,每个关键点两个坐标数据;最后一列为标签,“0”代表手势1,“1”代表手势3,“2”代表手势5。 可以直接打开数据集文件查看具体内容,也可以使用 Python 的 pandas 库来读取CSV 文件,具体代码如下: import pandas as pd
# 查看CSV
df = pd.read_csv("data/workflow_pose_train.csv", header=None)
df
|
|
步骤2:加载模型首先我们需要导入必要的库文件并构建SVM分类器。在构建SVM分类器时,使用Classification模块并通过cls('SVM')实例化模型,构建SVM分类器的目标是将数据划分为不同的类别;而在构建线性回归模型时,使用Regression模块并通reg('LinearRegression'/'Polynomial')实例化模型,目标是预测连续的数值。两者的任务模块和算法选择不同。
# 更新库
!pip install --upgrade BaseML
# 导入BaseML的分类模块
from BaseML import Classification as cls
# 使用BaseML中的SVM模块
model=cls('SVM')
步骤3:训练模型将数据集载入模型,进行模型训练,并将模型保存至指定路径,假设数据放置在当前目录下的data文件夹中,训练好的模型存储于当前目录下的checkpoints文件夹中。 # 将数据导入模型中
model.load_tab_data('data/workflow_pose_train.csv')
# 模型训练
model.train()
# 模型保存
model.save('checkpoints/SVM_1.pkl')
步骤4:验证模型模型已经训练完成,但是这样的模型具体的效果究竟好不好?对回归任务来说,简单好用的评估指标之一是R平方值,而对分类任务来说,一般选择准确率指标,准确率可以评价分类模型的准确度,衡量模型预测正确的实例占所有实例的比例。想象一下你在做一个分类测试,准确率就是你回答正确的问题数量占总问题数量的比例。准确率越高,表示模型整体预测的准确性越强。
model.load('checkpoints/SVM_1.pkl')
# 验证模型 这里使用的是准确度验证acc
model.valid('data/workflow_pose_val.csv',metrics='acc')
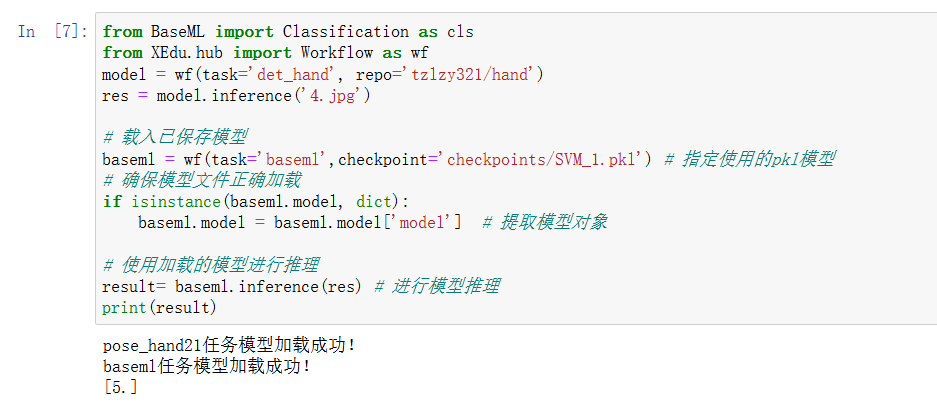
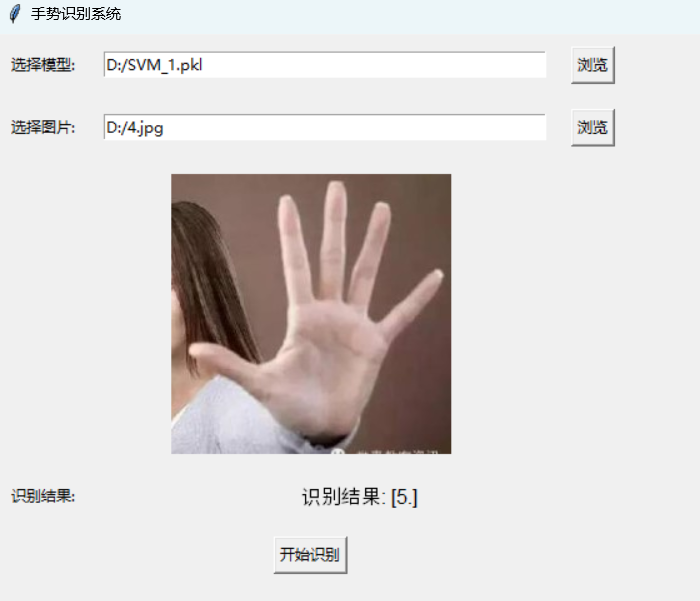
v 步骤5:应用模型在应用模型时,使用模型仓库repo获取图像中的关键点坐标, 测试输出的手势类型是否正确。 from BaseML import Classification as cls
from XEdu.hub import Workflow as wf
# model = wf(task='det_hand', repo='tzlzy321/hand')
model = wf(repo='tzlzy321/hand')
res = model.inference('4.jpg')
# 载入已保存模型
baseml = wf(task='baseml',checkpoint='checkpoints/SVM_1.pkl') # 指定使用的pkl模型
# 确保模型文件正确加载
if isinstance(baseml.model, dict):
baseml.model = baseml.model['model'] # 提取模型对象
# 使用加载的模型进行推理
result= baseml.inference(res) # 进行模型推理
print(result)
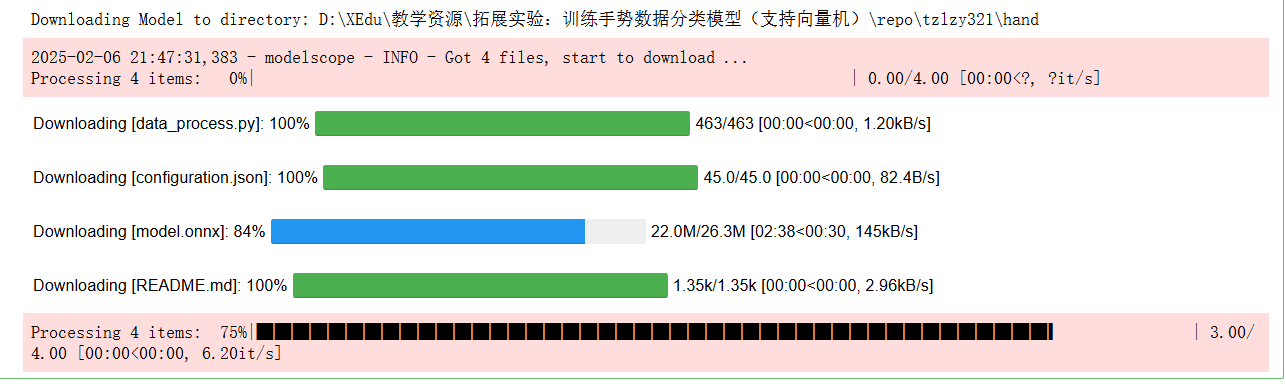
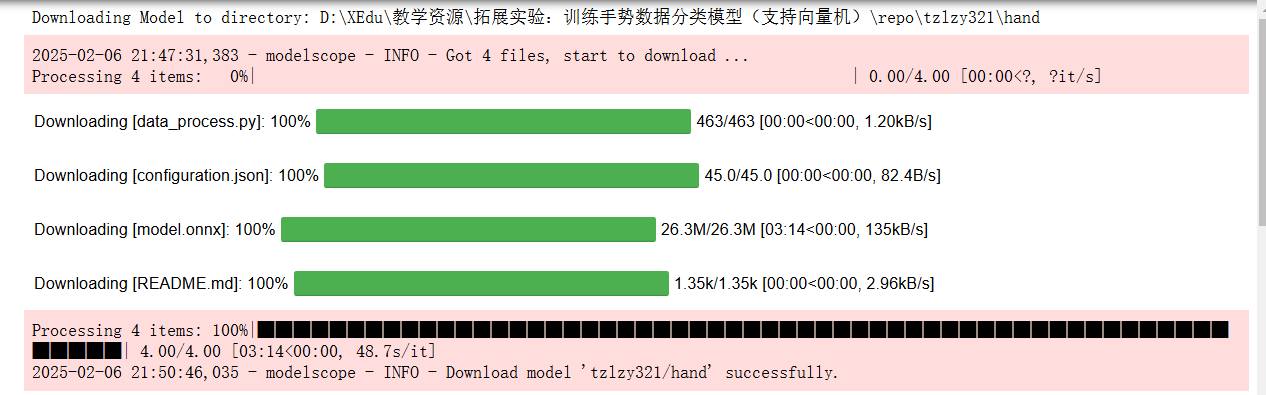
运行后需要观察模型的下载进度,查看xedu的服务后台窗口
要等待下载完成,才能正确的运行识别。 下载后,羡慕路径下要有对应的工具程序才正确。
正确的识别结果。
|
|
|
import os
import numpy as np
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
from XEdu.hub import Workflow as wf
class GestureRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("手势识别系统")
self.root.geometry("800x600")
# 创建变量
self.model_path = tk.StringVar()
self.image_path = tk.StringVar()
self.result_text = tk.StringVar()
# 创建控件
self.create_widgets()
def create_widgets(self):
# 模型选择
tk.Label(self.root, text="选择模型:").grid(row=0, column=0, padx=10, pady=10)
self.model_entry = tk.Entry(self.root, textvariable=self.model_path, width=50)
self.model_entry.grid(row=0, column=1, padx=10, pady=10)
tk.Button(self.root, text="浏览", command=self.load_model).grid(row=0, column=2, padx=10, pady=10)
# 图片选择
tk.Label(self.root, text="选择图片:").grid(row=1, column=0, padx=10, pady=10)
self.image_entry = tk.Entry(self.root, textvariable=self.image_path, width=50)
self.image_entry.grid(row=1, column=1, padx=10, pady=10)
tk.Button(self.root, text="浏览", command=self.load_image).grid(row=1, column=2, padx=10, pady=10)
# 显示图片
self.image_label = tk.Label(self.root)
self.image_label.grid(row=2, column=0, columnspan=3, padx=10, pady=10)
# 显示结果
tk.Label(self.root, text="识别结果:").grid(row=3, column=0, padx=10, pady=10)
self.result_label = tk.Label(self.root, textvariable=self.result_text, font=("Arial", 12), wraplength=400)
self.result_label.grid(row=3, column=1, columnspan=2, padx=10, pady=10)
# 识别按钮
tk.Button(self.root, text="开始识别", command=self.recognize).grid(row=4, column=0, columnspan=3, padx=10, pady=10)
def load_model(self):
file_path = filedialog.askopenfilename(filetypes=[("Pickle files", "*.pkl"), ("All files", "*.*")])
if file_path:
self.model_path.set(file_path)
def load_image(self):
file_path = filedialog.askopenfilename(filetypes=[("Image files", "*.jpg;*.png;*.jpeg"), ("All files", "*.*")])
if file_path:
self.image_path.set(file_path)
self.display_image(file_path)
def display_image(self, image_path):
img = Image.open(image_path)
img.thumbnail((400, 400)) # 调整图片大小
img_tk = ImageTk.PhotoImage(img)
self.image_label.config(image=img_tk)
self.image_label.image = img_tk # 保持对图片的引用
def recognize(self):
model_path = self.model_path.get()
image_path = self.image_path.get()
if not model_path or not image_path:
messagebox.showwarning("警告", "请先选择模型和图片!")
return
try:
# 加载手势检测模型
model = wf(task='det_hand', repo='tzlzy321/hand')
res = model.inference(image_path) # 手势检测的结果
# 检查 res 是否为 None
if res is None:
raise ValueError("手势检测模型没有返回结果,请检查输入图片是否有效。")
# 加载 SVM 模型
baseml = wf(task='baseml', checkpoint=model_path)
if isinstance(baseml.model, dict):
baseml.model = baseml.model['model'] # 提取模型对象
# 提取手势检测结果中的特征
features = np.array(res).reshape(1, -1) # 将特征转换为二维数组
# 使用加载的 SVM 模型进行推理
result = baseml.inference(features) # 进行模型推理
self.result_text.set(f"识别结果: {result}")
except Exception as e:
messagebox.showerror("错误", f"识别过程中发生错误: {e}")
if __name__ == "__main__":
root = tk.Tk()
app = GestureRecognitionApp(root)
root.mainloop()
|
|
import os
import shutil
import numpy as np
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
from XEdu.hub import Workflow as wf
import tempfile
class GestureRecognitionApp:
def __init__(self, root):
self.root = root
self.root.title("手势识别系统")
self.root.geometry("800x600")
# 创建变量
self.model_path = tk.StringVar()
self.image_path = tk.StringVar()
self.result_text = tk.StringVar()
# 创建控件
self.create_widgets()
def create_widgets(self):
# 模型选择
tk.Label(self.root, text="选择模型:").grid(row=0, column=0, padx=10, pady=10)
self.model_entry = tk.Entry(self.root, textvariable=self.model_path, width=50)
self.model_entry.grid(row=0, column=1, padx=10, pady=10)
tk.Button(self.root, text="浏览", command=self.load_model).grid(row=0, column=2, padx=10, pady=10)
# 图片选择
tk.Label(self.root, text="选择图片:").grid(row=1, column=0, padx=10, pady=10)
self.image_entry = tk.Entry(self.root, textvariable=self.image_path, width=50)
self.image_entry.grid(row=1, column=1, padx=10, pady=10)
tk.Button(self.root, text="浏览", command=self.load_image).grid(row=1, column=2, padx=10, pady=10)
# 显示图片
self.image_label = tk.Label(self.root)
self.image_label.grid(row=2, column=0, columnspan=3, padx=10, pady=10)
# 显示结果
tk.Label(self.root, text="识别结果:").grid(row=3, column=0, padx=10, pady=10)
self.result_label = tk.Label(self.root, textvariable=self.result_text, font=("Arial", 12), wraplength=400)
self.result_label.grid(row=3, column=1, columnspan=2, padx=10, pady=10)
# 识别按钮
tk.Button(self.root, text="开始识别", command=self.recognize).grid(row=4, column=0, columnspan=3, padx=10, pady=10)
def load_model(self):
file_path = filedialog.askopenfilename(filetypes=[("Pickle files", "*.pkl"), ("All files", "*.*")])
if file_path:
self.model_path.set(os.path.normpath(file_path)) # 标准化路径
def load_image(self):
file_path = filedialog.askopenfilename(filetypes=[("Image files", "*.jpg;*.png;*.jpeg"), ("All files", "*.*")])
if file_path:
self.image_path.set(os.path.normpath(file_path)) # 标准化路径
self.display_image(file_path)
def display_image(self, image_path):
try:
img = Image.open(image_path)
img.thumbnail((400, 400)) # 调整图片大小
img_tk = ImageTk.PhotoImage(img)
self.image_label.config(image=img_tk)
self.image_label.image = img_tk # 保持对图片的引用
except Exception as e:
messagebox.showerror("错误", f"加载图片失败: {e}")
def recognize(self):
model_path = self.model_path.get()
image_path = self.image_path.get()
if not model_path or not image_path:
messagebox.showwarning("警告", "请先选择模型和图片!")
return
# 检查模型文件是否存在
if not os.path.exists(model_path):
messagebox.showerror("错误", f"模型文件不存在: {model_path}")
return
# 检查图片文件是否存在
if not os.path.exists(image_path):
messagebox.showerror("错误", f"图片文件不存在: {image_path}")
return
try:
# 创建临时目录
temp_dir = tempfile.mkdtemp()
temp_image_path = os.path.join(temp_dir, os.path.basename(image_path))
# 将图片复制到临时目录
shutil.copy(image_path, temp_image_path)
# 加载手势检测模型
model = wf(task='det_hand', repo='tzlzy321/hand')
res = model.inference(temp_image_path) # 手势检测的结果
# 检查 res 是否为 None
if res is None:
raise ValueError("手势检测模型没有返回结果,请检查输入图片是否有效。")
# 加载 SVM 模型
baseml = wf(task='baseml', checkpoint=model_path)
if isinstance(baseml.model, dict):
baseml.model = baseml.model['model'] # 提取模型对象
# 提取手势检测结果中的特征
features = np.array(res).reshape(1, -1) # 将特征转换为二维数组
# 使用加载的 SVM 模型进行推理
result = baseml.inference(features) # 进行模型推理
self.result_text.set(f"识别结果: {result}")
# 删除临时目录
shutil.rmtree(temp_dir)
except Exception as e:
messagebox.showerror("错误", f"识别过程中发生错误: {e}")
if __name__ == "__main__":
root = tk.Tk()
app = GestureRecognitionApp(root)
root.mainloop()
关键改进点
测试建议
|
|
|
|
|
大模型预习 |
【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。 |
搭建算法并训练线性回归 |
使用Python和常用的机器学习库(如NumPy、Scikit-learn)来实现。 理解线性回归线性回归是一种用于预测连续值的监督学习算法。它假设目标变量(因变量)与特征(自变量)之间存在线性关系,模型形式为:
准备数据首先,我们需要准备数据。你可以使用真实数据集,也可以生成一些随机数据。
import numpy as np import matplotlib.pyplot as plt # 生成随机数据 np.random.seed(42) X = 2 * np.random.rand(100, 1) # 生成100个随机特征值 y = 4 + 3 * X + np.random.randn(100, 1) # 生成目标值,带有一些噪声 # 可视化数据 plt.scatter(X, y) plt.xlabel("X") plt.ylabel("y") plt.title("Generated Data") plt.show()
搭建线性回归模型我们可以使用Scikit-learn库中的 from sklearn.linear_model import LinearRegression
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X, y)
# 输出模型参数
print("截距 (w0):", model.intercept_)
print("权重 (w1):", model.coef_)
预测与评估训练完成后,我们可以使用模型进行预测,并评估模型的性能。 # 预测
y_pred = model.predict(X)
# 可视化预测结果
plt.scatter(X, y, label="Actual Data")
plt.plot(X, y_pred, color='red', label="Predicted Line")
plt.xlabel("X")
plt.ylabel("y")
plt.title("Linear Regression Prediction")
plt.legend()
plt.show()
# 评估模型
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print("均方误差 (MSE):", mse)
print("R^2 分数:", r2)
手动实现线性回归(可选)如果你想更深入地理解线性回归,可以手动实现它。以下是使用梯度下降法手动实现线性回归的代码: # 手动实现线性回归
class LinearRegressionManual:
def __init__(self, learning_rate=0.01, n_iterations=1000):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.weights = None
self.bias = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.weights = np.zeros(n_features)
self.bias = 0
# 梯度下降
for _ in range(self.n_iterations):
y_pred = np.dot(X, self.weights) + self.bias
# 计算梯度
dw = (1 / n_samples) * np.dot(X.T, (y_pred - y))
db = (1 / n_samples) * np.sum(y_pred - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
def predict(self, X):
return np.dot(X, self.weights) + self.bias
# 使用手动实现的线性回归
model_manual = LinearRegressionManual(learning_rate=0.1, n_iterations=1000)
model_manual.fit(X, y)
# 预测
y_pred_manual = model_manual.predict(X)
# 可视化手动实现的预测结果
plt.scatter(X, y, label="Actual Data")
plt.plot(X, y_pred_manual, color='green', label="Manual Predicted Line")
plt.xlabel("X")
plt.ylabel("y")
plt.title("Manual Linear Regression Prediction")
plt.legend()
plt.show()
总结
|
训练多项式回归 |
通过引入特征的高次项来拟合非线性关系 理解多项式回归多项式回归的模型形式为:
多项式回归仍然是一个线性模型,因为它是关于参数
的线性组合。 准备数据我们首先生成一些非线性数据来演示多项式回归的效果。 import numpy as np
import matplotlib.pyplot as plt
# 生成非线性数据
np.random.seed(42)
X = 6 * np.random.rand(100, 1) - 3 # 生成100个随机特征值,范围在[-3, 3]
y = 0.5 * X**2 + X + 2 + np.random.randn(100, 1) # 生成目标值,带有一些噪声
# 可视化数据
plt.scatter(X, y)
plt.xlabel("X")
plt.ylabel("y")
plt.title("Generated Nonlinear Data")
plt.show()
使用Scikit-learn实现多项式回归Scikit-learn提供了 步骤:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
# 创建多项式回归模型
degree = 2 # 多项式的阶数
poly_features = PolynomialFeatures(degree=degree, include_bias=False)
linear_reg = LinearRegression()
# 使用Pipeline将多项式特征转换和线性回归组合在一起
model = Pipeline([
("poly_features", poly_features),
("linear_reg", linear_reg)
])
# 训练模型
model.fit(X, y)
# 预测
X_test = np.linspace(-3, 3, 100).reshape(-1, 1) # 生成测试数据
y_pred = model.predict(X_test)
# 可视化结果
plt.scatter(X, y, label="Actual Data")
plt.plot(X_test, y_pred, color='red', label="Polynomial Regression")
plt.xlabel("X")
plt.ylabel("y")
plt.title(f"Polynomial Regression (Degree={degree})")
plt.legend()
plt.show()
评估模型我们可以使用均方误差(MSE)和R²分数来评估模型的性能。 from sklearn.metrics import mean_squared_error, r2_score
# 计算预测值
y_pred_train = model.predict(X)
# 计算均方误差和R²分数
mse = mean_squared_error(y, y_pred_train)
r2 = r2_score(y, y_pred_train)
print("均方误差 (MSE):", mse)
print("R² 分数:", r2)
5. 调整多项式阶数多项式回归的性能高度依赖于选择的阶数( 示例:尝试不同的阶数degrees = [1, 2, 10, 20] # 尝试不同的阶数
plt.figure(figsize=(14, 10))
for i, degree in enumerate(degrees):
# 创建模型
poly_features = PolynomialFeatures(degree=degree, include_bias=False)
linear_reg = LinearRegression()
model = Pipeline([
("poly_features", poly_features),
("linear_reg", linear_reg)
])
# 训练模型
model.fit(X, y)
# 预测
y_pred = model.predict(X_test)
# 可视化结果
plt.subplot(2, 2, i + 1)
plt.scatter(X, y, label="Actual Data")
plt.plot(X_test, y_pred, color='red', label=f"Degree={degree}")
plt.xlabel("X")
plt.ylabel("y")
plt.title(f"Polynomial Regression (Degree={degree})")
plt.legend()
plt.tight_layout()
plt.show()
6. 手动实现多项式回归(可选)如果你想更深入地理解多项式回归,可以手动实现它。以下是使用梯度下降法手动实现多项式回归的代码: class PolynomialRegressionManual:
def __init__(self, degree=2, learning_rate=0.01, n_iterations=1000):
self.degree = degree
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.weights = None
self.bias = None
def fit(self, X, y):
# 生成多项式特征
n_samples = X.shape[0]
X_poly = np.column_stack([X**i for i in range(1, self.degree + 1)])
# 初始化参数
n_features = X_poly.shape[1]
self.weights = np.zeros(n_features)
self.bias = 0
# 梯度下降
for _ in range(self.n_iterations):
y_pred = np.dot(X_poly, self.weights) + self.bias
# 计算梯度
dw = (1 / n_samples) * np.dot(X_poly.T, (y_pred - y))
db = (1 / n_samples) * np.sum(y_pred - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
def predict(self, X):
# 生成多项式特征
X_poly = np.column_stack([X**i for i in range(1, self.degree + 1)])
return np.dot(X_poly, self.weights) + self.bias
# 使用手动实现的多项式回归
degree = 2
model_manual = PolynomialRegressionManual(degree=degree, learning_rate=0.01, n_iterations=1000)
model_manual.fit(X, y)
# 预测
y_pred_manual = model_manual.predict(X_test)
# 可视化手动实现的预测结果
plt.scatter(X, y, label="Actual Data")
plt.plot(X_test, y_pred_manual, color='green', label="Manual Polynomial Regression")
plt.xlabel("X")
plt.ylabel("y")
plt.title(f"Manual Polynomial Regression (Degree={degree})")
plt.legend()
plt.show()
7. 总结
|
支持向量机(SVM) |
【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。 搭建了算法并训练线性回归、多项式回归; 如何支持向量机(SVM) 支持向量机(SVM)是一种强大的机器学习算法,广泛应用于分类和回归问题。以下是关于如何训练SVM模型的详细步骤和方法: 1. 理解SVM的基本原理SVM的核心目标是找到一个最优的超平面,将不同类别的数据分开,并最大化两个类别之间的间隔(Margin)。对于线性可分的数据,SVM通过硬间隔最大化来学习一个线性分类器。对于线性不可分的数据,SVM通过引入核函数将数据映射到高维空间,使其在高维空间中变得线性可分。
2. 选择合适的核函数核函数是SVM实现非线性分类的关键。常用的核函数包括:
3. 准备数据在训练SVM模型之前,需要对数据进行预处理,包括:
4. 训练SVM模型使用Python中的Scikit-learn库可以方便地训练SVM模型。以下是一个简单的示例代码:
import numpy as np
from sklearn import svm
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创建虚拟数据集
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM模型,选择线性核
svm_model = svm.SVC(kernel='linear', C=1)
# 训练模型
svm_model.fit(X_train, y_train)
# 预测测试集
y_pred = svm_model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy}")
5. 模型评估与优化在模型训练完成后,需要评估其在测试集上的表现。常用的评估指标包括准确率、精确率、召回率和F1分数。此外,可以通过调整以下参数来优化模型性能:
6. 实际应用案例SVM在多个领域都有广泛应用,例如:
|
机器学习模型 |
【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。 BaseML支持的机器学习模型 BaseML支持以下几种常见的机器学习模型,涵盖回归、分类和聚类任务: 1. 回归模型
2. 分类模型
3. 聚类模型
如何使用BaseML训练这些模型以下以线性回归、多项式回归和SVM为例,展示如何使用BaseML进行模型训练:
线性回归from BaseML import Regression as reg
import pandas as pd
# 实例化线性回归模型
model = reg('LinearRegression')
# 载入数据
model.load_tab_data('数据文件路径.csv')
# 训练模型
model.train()
# 评估模型
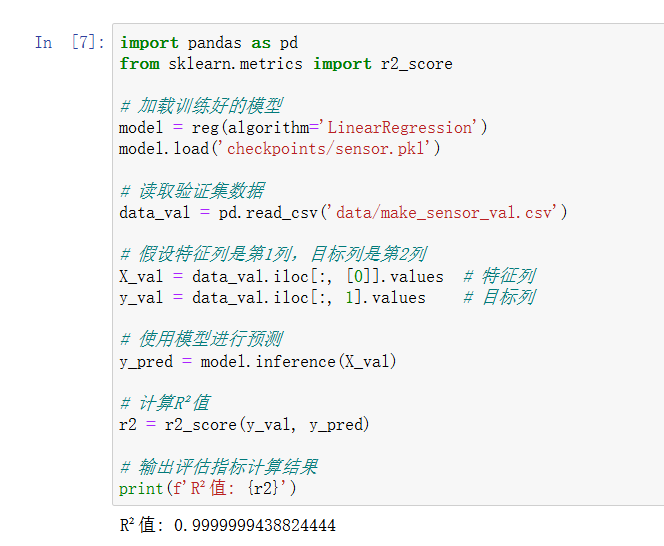
model.valid(metrics='r2') # 使用R²值评估[^28^]
多项式回归from BaseML import Regression as reg
import pandas as pd
# 实例化多项式回归模型
model = reg('Polynomial')
# 载入数据
model.load_tab_data('数据文件路径.csv')
# 训练模型
model.train()
# 评估模型
model.valid(metrics='r2') # 使用R²值评估[^33^]
支持向量机(SVM)from BaseML import Classification as cls
import pandas as pd
# 实例化SVM分类模型
model = cls('SVM')
# 载入数据
model.load_dataset(X='特征数据', y='目标数据', type='pandas', x_column=[特征列], y_column=[目标列])
# 训练模型
model.train()
# 评估模型
model.valid(metrics='accuracy') # 使用准确率评估[^28^][^33^]
适用场景
|
个性化数据集 |
【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。 结合机器学习,使用BaseML、BaseDT等工具,如何制作个性化数据集
制作个性化数据集是实现模型高效训练和精准预测的重要步骤。结合BaseML、BaseDT等工具,可以更高效地完成数据集的创建、预处理和优化。
1. 明确数据需求在制作个性化数据集之前,需要明确以下几点:
2. 数据收集根据需求收集数据。可以使用BaseML、BaseDT等工具来辅助数据收集:
示例代码(使用BaseML导入数据):import baseml as bm
# 从CSV文件导入数据
data = bm.load_data('data.csv')
# 从数据库导入数据
data = bm.load_data('mysql://user:password@host:port/dbname', query='SELECT * FROM table_name')
3. 数据预处理数据预处理是制作个性化数据集的关键步骤,包括数据清洗、特征工程等。
数据清洗
特征工程
示例代码(使用BaseML进行数据预处理):# 去除重复值 data = data.drop_duplicates() # 处理缺失值 data = data.fillna(method='ffill') # 前向填充 data = data.dropna() # 删除缺失值 # 特征标准化 from sklearn.preprocessing import StandardScaler scaler = StandardScaler() data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']]) # 特征编码 data = bm.encode_categorical(data, columns=['category_feature'])
4. 数据标注对于监督学习任务,需要对数据进行标注。标注过程可以手动完成,也可以使用自动化工具。
示例代码(使用BaseDT进行数据标注):import basedt as bd # 手动标注 data['label'] = bd.annotate(data, label_column='target') # 自动标注(基于规则) data['label'] = data['feature'].apply(lambda x: 'class1' if x > threshold else 'class2')
5. 数据划分将数据集划分为训练集、验证集和测试集,以便进行模型训练和评估。
示例代码(使用BaseML划分数据集):train_data, test_data = bm.split_data(data, test_size=0.2, random_state=42) train_data, val_data = bm.split_data(train_data, test_size=0.2, random_state=42)
6. 数据增强(可选)对于某些任务,可以通过数据增强来扩充数据集,提高模型的泛化能力。
示例代码(使用BaseML进行数据增强):# 数据增强 augmented_data = bm.augment_data(train_data, method='smote', target_column='label')
7. 数据存储将处理好的数据存储为适合模型训练的格式,例如CSV、HDF5等。
示例代码(使用BaseML保存数据):bm.save_data(train_data, 'train_data.csv') bm.save_data(val_data, 'val_data.csv') bm.save_data(test_data, 'test_data.csv')
8. 验证数据集在使用数据集之前,需要验证其质量和一致性,确保数据集符合模型训练的要求。
示例代码(使用BaseML验证数据集):# 验证数据集 bm.validate_data(train_data, val_data, test_data)
总结通过以上步骤,结合BaseML、BaseDT等工具,可以高效地制作个性化数据集,为机器学习模型的训练和优化提供高质量的数据支持。
|
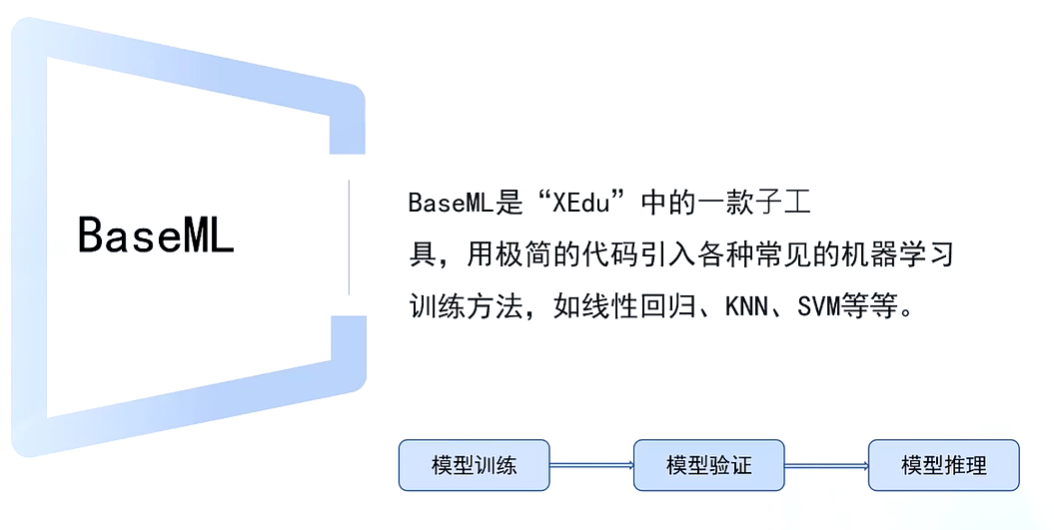
BaseML |
BaseML 是什么,怎么用,什么时候用。
BaseML是什么BaseML是一个用于机器学习模型训练和应用的工具,支持多种常见的机器学习算法,如线性回归、多项式回归、K近邻分类等。它提供了从数据加载、模型训练到模型评估和应用的全流程支持,适合用于快速构建和部署机器学习模型。
如何使用BaseML1. 数据加载BaseML支持从多种数据源加载数据,包括CSV文件、数据库等。例如:
Python复制
2. 模型训练选择合适的算法并进行模型训练。例如,使用线性回归模型:
Python复制
3. 模型评估评估模型性能,BaseML支持多种评估指标,如准确率、R²值等:
Python复制
4. 模型保存与加载训练好的模型可以保存,方便后续使用:
Python复制
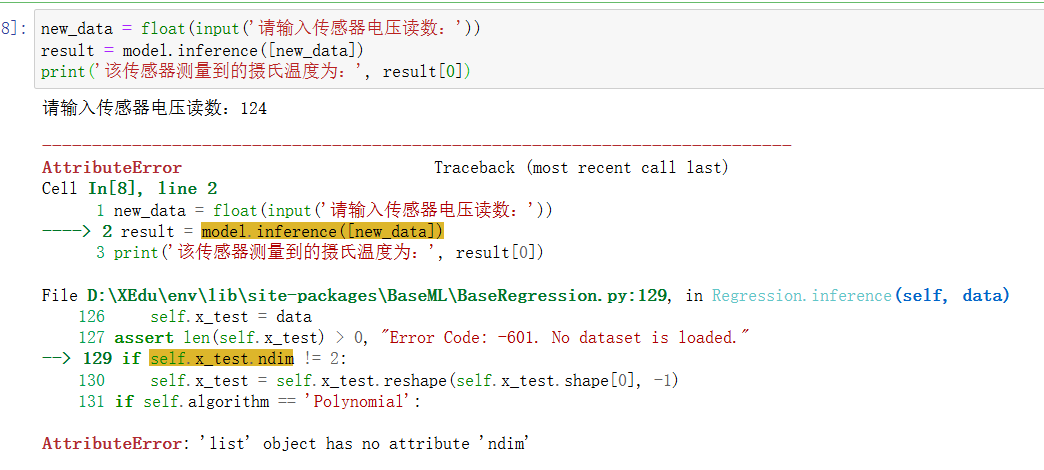
5. 模型推理使用训练好的模型进行预测:
Python复制
适用场景BaseML适用于以下场景:
总结BaseML是一个功能强大的机器学习工具,适合快速开发和部署机器学习模型。它支持多种算法,提供从数据加载到模型推理的全流程支持,适用于教育、快速原型开发和实际项目应用。
|
BaseDT |
BaseDT是什么,怎么用,什么时候用。
BaseDT是什么BaseDT是一个用Python编写的强大数据处理库,专为机器学习和深度学习中的数据预处理而设计。它支持多种数据类型(如图片、文本、语音等)的处理操作,例如调整大小(resize)、裁剪(crop)、归一化(normalize)等。此外,BaseDT还支持数据集的下载、检查和转换,以及数据的可视化和I/O设备的调用。
如何使用BaseDT1. 安装可以通过以下命令安装BaseDT:
bash复制
或者从PyPI下载源代码进行安装。
2. 数据处理BaseDT提供了丰富的数据处理功能,支持不同类型的数据处理模块:
3. 数据集处理BaseDT还提供了数据集的处理功能,例如:
4. 模型部署数据处理BaseDT可以将处理后的数据转换为模型训练和部署所需的张量格式:
Python复制
这确保了数据处理流程在训练和部署阶段的一致性。
适用场景BaseDT适用于以下场景:
通过使用BaseDT,你可以专注于模型的构建和训练,而无需担心数据处理的复杂性
|





















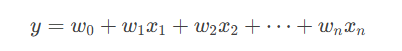




 浙公网安备 33010602011771号
浙公网安备 33010602011771号