浏览器是怎样工作的?
一、从请求到响应
当浏览器发送一个请求到接受所有响应数据,这个过程发生了什么?
开发模式下打开航班管家 H5,通过dev-tool分析jipiao/文件请求,看从Connection Start到Content Download期间,浏览器做了哪些事:

图(1)请求并得到一个网络资源/文件的过程、及时间
结合图1及相关资料,浏览器按时间顺序经历了如下事件:
Queued.浏览器在以下事件发生时产生排队请求:有更高优先级权限的请求;已经打开 6 个同源限制的 TCP 链接;浏览器会短暂分配磁盘缓存中的空间。Stalled.当产生Queued 时,请求会被阻塞。DNS Lookup.浏览器正在查询请求的 IP 地址。Proxy negotiation.浏览器正在和代理服务器协商请求。Request sent.开始发送请求。Waiting(TTFB).浏览器正在等待响应的第一个字节。TTFB表示Time To First Byte。它包括1次往返延迟的时间和服务端准备响应的时间。Content Download.浏览器正在接收响应。
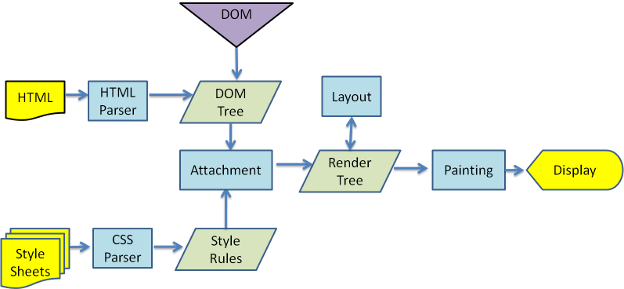
二、渲染引擎的工作内容
TL;DR
当html文件的相应字节被浏览器接受后(通常是8K一个包),“渲染引擎”便开始工作了:
-
渲染引擎将解析到的 HTML 文档标签转换为 DOM 树,并解析内联和嵌入的样式,它们一起合并形成“渲染树”;
-
渲染树由一个个包含颜色、尺寸等属性的矩形构成,并按照正确的顺序显示在屏幕上;
-
布局计算每个节点对象的确切位置和大小;
-
最后是绘制,使用 UI backend layer 把渲染树绘制到屏幕上。
为了更好的用户体验(user experience),渲染引擎会解析一部分内容就显示一部分,不会等到所有的 HTML 都被解析才开始构建和布局渲染树。

简要总结渲染引擎的工作:
- 解析 HTML 标签构建 DOM 树
- 解析 CSS 样式构建 CSSOM 树
- 当DOM 与 CSSOM 都完成时,才将其合并成一个渲染树
- 将渲染树的各个节点绘制到屏幕上
三、深入文档解析过程
HTML 的解析算法并不是传统的自顶向下或自底向上,它包含两个步骤: tokenization 和 tree construction。这里好像比较复杂(详细内容请参考构建对象模型),但至少要明白解析的顺序是自顶向下的。
当然,解析并不一直一帆风顺,当遇到以下情况,解析过程将被阻塞:
- HTML的响应流被阻塞在了网络中
- 有未加载完的脚本
- 执行脚本前,此时还有未加载完的样式文件
- 执行脚本
解析脚本和样式的顺序
样式
异步过程,解析样式不会阻塞DOM构建,但会阻塞构建渲染树。切记,CSSOM和DOM共同构建渲染树,但它们是分别构建的,谁也不影响谁。
解析脚本
同步过程。当解析过程中遇到了<script>标签,会停止继续解析直到脚本执行完成。如果脚本是外链资源,则需要等待资源加载并执行完毕才能继续向下解析。
不过,在文档解析阶段,脚本会询问样式信息。如果样式尚未加载并解析,脚本将得到错误的答案,显然这会导致很多问题。所以,当有一个仍在加载和解析的样式表时,Firefox将阻止所有脚本。 Webkit仅在脚本尝试访问某些可能受卸载样式表影响的样式属性时才阻止脚本。
等等!!!既然加载脚本会阻塞解析过程,那么,为什么后面的脚本(或外部资源)会和当前脚本一起加载呢?这里不得不提到一个优化技术——猜测预加载。
猜测预加载技术
现代主流浏览器都用到了这个优化技术。
当执行脚本的时候,浏览器会启动另一个线程来向下解析文档,找到需要从网络加载的链接并加载它们,加载这些资源的请求是并发的。注意,这项技术不会修改 DOM 树,它仅解析对外部资源(如外部脚本,样式表和图像)的引用。
四、一图胜千言
如果能看到这里,那么真是感谢你的耐心。
另外,我猜想上面大段大段的文字,未必能给你留下什么印象。或许,下面这张图更能表达本文的中心。
更多:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号