

Numpy
-
一、Numpy 是什么
简单来说,Numpy 是 Python 的一个科学计算包,包含了多维数组以及多维数组的操作
-
二、与python原生array区别
-
1、NumPy 数组在创建时有固定的大小,更改ndarray的大小将创建一个新的数组并删除原始数据,不同于Python列表(可以动态增长)
-
2、NumPy 数组中的元素都需要具有相同的数据类型
-
3、数组的元素如果也是数组(可以是 Python 的原生 array,也可以是 ndarray)的情况下,则构成了多维数组
-
4、NumPy 数组操作比使用Python的内置序列可能更有效和更少的代码执行
-
三、构建ndarray
- Numpy 中最重要的一个对象就是 ndarray(n-dimension-array)
- 可以使用Python列表创建数组

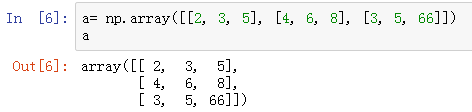
- 多维数组中每个子数组中的元素长度得相同,否则无法形成多维数组,里面只是列表对象

-
四、数据类型
Numpy 中的数组比 Python 原生中的数组(只支持整数类型与浮点类型)强大的一点就是它支持更多的数据类型
-
1、基本数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型
| 数据类型 | 描述 |
|---|---|
| bool_ | 布尔(True或False),存储为一个字节 |
| int_ | 默认整数类型(与C long相同;通常为int64或int32) |
| intc | 与C int(通常为int32或int64)相同 |
| intp | 用于索引的整数(与C ssize_t相同;通常为int32或int64) |
| int8 | 字节(-128到127) |
| int16 | 整数(-32768到32767) |
| int32 | 整数(-2147483648至2147483647) |
| int64 | 整数(-9223372036854775808至9223372036854775807) |
| uint8 | 无符号整数(0到255) |
| uint16 | 无符号整数(0到65535) |
| uint32 | 无符号整数(0至4294967295) |
| uint64 | 无符号整数(0至18446744073709551615) |
| float_ | float64的简写。 |
| float16 | 半精度浮点:符号位,5位指数,10位尾数 |
| float32 | 单精度浮点:符号位,8位指数,23位尾数 |
| float64 | 双精度浮点:符号位,11位指数,52位尾数 |
| complex_ | complex128的简写。 |
| complex64 | 复数,由两个32位浮点(实数和虚数分量) |
| complex128 | 复数,由两个64位浮点(实数和虚数分量) |
-
不同于 Python 列表,NumPy 要求数组必须包含同一类型的数据
-
如果类型不匹配,NumPy 将会向上转换(如果可行)
-
转换级别:字符串 > 浮点数 > 整数

-
2、指定类型创建
可以强行指定类型, 将浮点型转换成整型

注:8位,32位是指二进制的存储的长度,比如32位,能存储2的32次幂的位数,dtype='<U3'的意思是:字符串最大字节是3
-
3、查看类型 ndarray.dtype

-
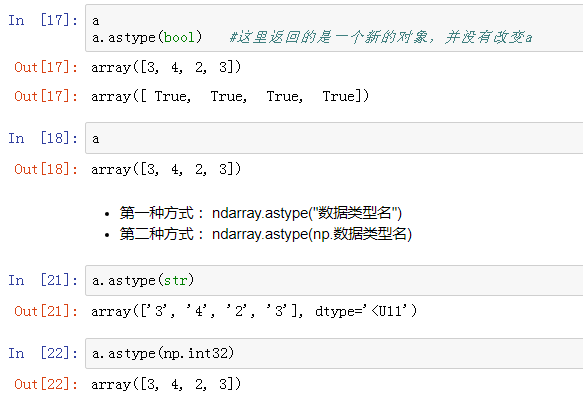
4、类型转换 ndarray.astype()
-
要转换数组的类型,请使用.astype()方法(首选)或类型本身作为函数
-
转换类型之后,ndarray本身并没发生改变,因此ndarray的id不会变
-
五、常用的数组
-
1、np.arange()
用来创建一个线性序列的数组,在给定间隔内返回均匀间隔的值
使用方式:arange([start,] stop[, step,], dtype=None)

-
2、np.linspace()
使用方式:np.linspace(start, stop, num=50, endpoint=True)
-
在指定的间隔内返回均匀间隔的数字,用作相同间隔采样
-
start:标量,序列的起始值
-
stop:标量,除非"endpoint"设置为False,否则为序列的结束值
-
num:int,可选。要生成的样本数。默认值为50,必须为非负数
-
endpoint:是否包含末端点,默认包含

-
3、np.zeros(), np.zeros_like()
np.zeros() 输出一个全0数组,第一个参数输入数组的形状,通过元组或列表定义
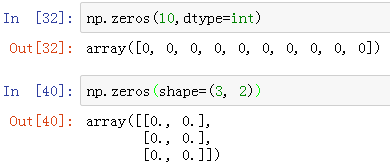
np.zeros_like() 是以另一个数组为基础,根据其形状创建一个全0数组

-
4、np.ones(), np.ones_like()
创建全1的数组,类似np.zeros()

-
5、np.eye()
返回一个二维数组,其中对角线为1,其余为0的二维数组(单位矩阵)

-
6、np.full()
-
返回给定形状和类型的新数组,填充
fill_value -
np.full(shape,fill_value,dtype = None)
-
shape:int或int的序列新数组的形状,例如
(2,3)或2。 -
fill_value:标量填充值。
-
dtype:数据类型,可选数组所需的数据类型默认值为"None"。
-

-
7、设置缺失值 np.nan
np中缺失值用np.nan表示,其他ndarry对象与之运算的结果都为缺失值,运算结果数组的形状与参与运算的数组的形状一致

-
8、随机数组 np.random.xx
-
np.random.randint():随机整数
- 语法:randint(low, high=None, size=None, dtype)
- 使用方法一:将随机整数从“低”(包括)返回到“高”(不包括)——左闭右开
- 使用方法二:返回特定形状的随机整数

-
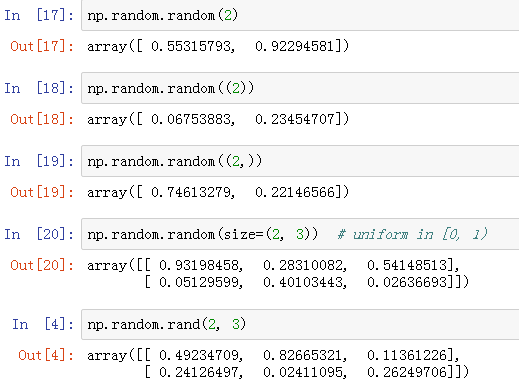
np.random.random(),np.random.rand():随机 [0, 1) 浮点数
-
语法:np.random.random(size=None),np.random.rand(d0, d1, ..., dn)
-
返回随机浮点数,在半开区间[0.0,1.0)中
-
np.random.randn():随机标准正态分布
-
语法:np.random.randn(形状)
-
从“标准正态”分布中返回一个样本

-
np.random.normal():随机正态分布
-
语法:normal(平均值,标准偏差,形状)
-
作用:从正态分布中抽取随机样本。
-
如果平均值和标准差为0和1,或者不写这两个参数,就等同于np.random.randn()

-
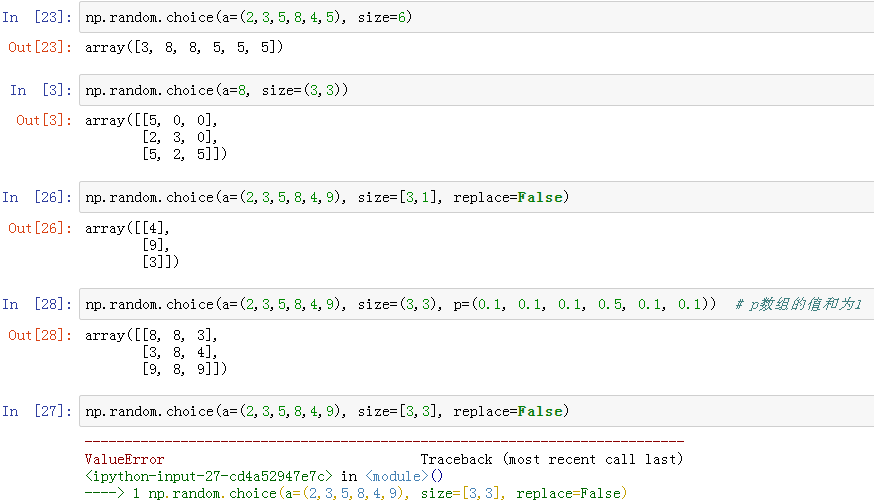
np.random.choice():从给定的1-D阵列生成随机样本
- choice(a, size=None, replace=True, p=None)
- a:1-D数组或int
- 如果是ndarray,则从其元素生成随机样本。
- 如果是int,则生成随机样本,就像a是np.arange(a)
- size:int或int的元组,可选
- 输出形状。如果给定的形状是例如“(m,n,k)”,那么绘制了
m * n * k样本。默认值为None,在这种情况下为a返回单个值
- 输出形状。如果给定的形状是例如“(m,n,k)”,那么绘制了
- p:1-D数组,可选与a中每个条目相关的概率,如果没有给出样品,则假定均匀分布一个条目,该数组的各个概率值加和必须等于1
- replace:True为可重复采样,False为不可重复采样,此时如果要抽取的样本数量超过总样本数量,则报错
- a:1-D数组或int
-
np.random.shuffle():随机洗牌
通过混洗其内容来就地修改序列,此功能仅沿x的第一轴洗牌

-
np.random.seed():设置随机种子
np.random.seed(Num) 可以设置一组种子值,确保每次程序执行的时候都可以生成同样的随机数组

-
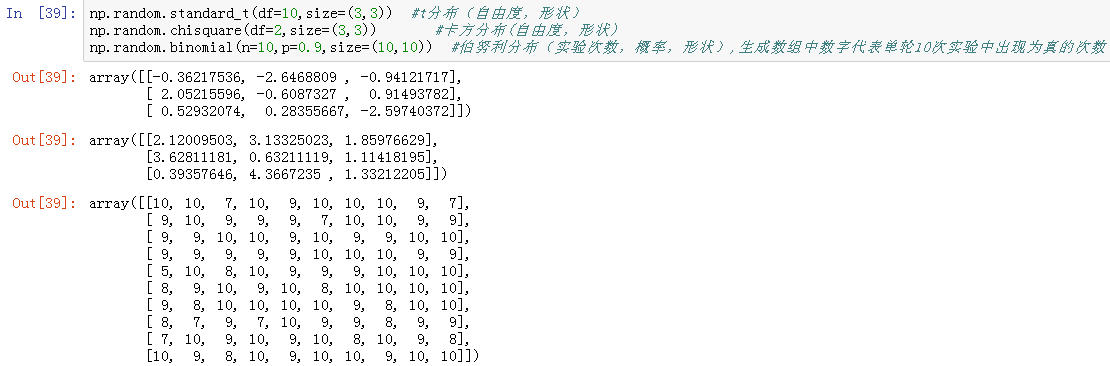
其他分布随机数
-
六、ndarray常用属性

-
ndarray.shape:查看数组形状

-
ndarray.ndim:查看数组的维度

-
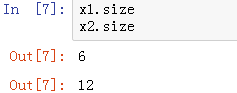
ndarray.size:查看数组中元素的个数
-
七、数组的索引和切片
-
一维数组索引和切片

-
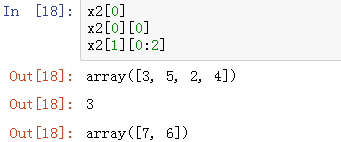
多维数组索引和切片
与python原生的列表、元组不同的是,Numpy数组支持多维数组的多维索引,每一个逗号,代表索引的一个维度:(建议用)

也支持按照以往嵌套列表取元素的方法,一层一层取:(不建议用)
-
修改数组元素值
注意:数组切片是原始数组的视图,这意味着视图上的任何修改都会直接反映到源数组上

-
数组副本
可以通过.copy()方法创建一个副本,进而保留原始数据

-
二维切片
可以使用切片和步长来截取不同长度的数组,使用方式与python原生的对列表和元组的方式相同,语法和之前学过的列表的切片是一样的:X[start: stop: step]

注意:二维数组切片的取法,下面两种方法的差异

-
八、数组的变形
-
1、ndarray.reshape()

技巧:在使用reshape时,可以将其中的一个维度指定为 -1 ,Numpy会自动计算出它的真实值

-
2、ndarray.shape
注意:数组变形通过shape属性来实现,会改变原来数组的形状

-
3、ndarray.resize()
注意:使用resize方法会直接修改数组本身,作用和shape改变数组形状是一样的

-
4、ndarray.ravel()
数组的平铺,不管多少维,全部铺开变成一维,不会修改源数据

-
5、ndarray.T, ndarray.transpose(), ndarray.swapaxes()——转置
transpose()和swapaxes()均需要传入轴编号,transpose()可处理高维,swapaxes()只能处理二维
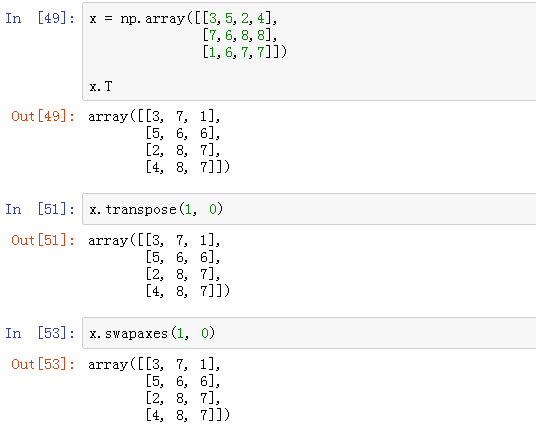
注:无论是 ravel、reshape、T,它们不会更改原有的数组形状,都是返回一个新的数组
-
九、数组的拼接和分裂
-
数组拼接:np.concatenate()
语法:np.concatenate((a1, a2, ...), axis=0, out=None)
沿现有轴加入一系列数组,除尺寸外,阵列必须具有相同的形状
a1, a2, ...:array_like 的序列
axis:int,可选,数组将连接的轴,如果aixs为None,数组在使用前是扁平的,默认值为0

对于一个二维数组,如果说有一个方法,是要求按照axis来操作:
axis=0,操作的基本单位就是一个个一维数组
axis=1,操作的基本单位就是一个个一维数组内部的元素
对于一个三维维数组,如果说有一个方法,是要求按照axis来操作:
axis=0,操作的基本单位就是一个个二维数组
axis=1,操作的基本单位就是一个个一维数组
axis=2,操作的基本单位就是一维数组内部的一个个元素
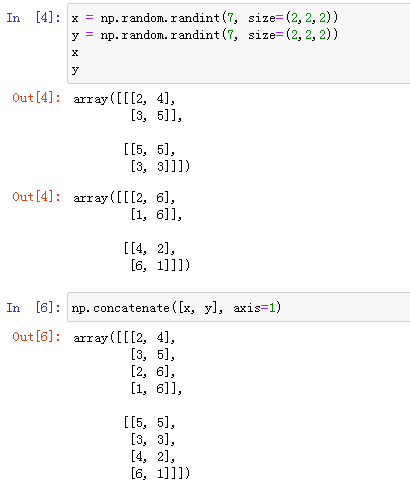
数组拼接:np.vstack(),np.hstack()
np.vstack():按 axis = 0 拼接,处理二维数组时,相当于按行纵向拼接

np.hstack():按 axis = 1 拼接,处理二维数组时,相当于按列横向拼接

-
数组分裂:np.split()
将一个数组分成几个较小的数组
语法:np.split(ary, indices_or_sections, axis=0)
ary: ndarray
indices_or_sections:int或1-D数组
如果indices_or_sections是一个整数N,则数组将被分割沿着‘轴’进入N个相等的数组
如果indices_or_sections是排序整数的1-D数组,则为条目指示数组被分割的‘轴’的位置
如果索引超过沿‘轴’的数组维度,相应地返回一个空的子数组
axis:int,可选,要拆分的轴,默认为0
-
如果indices_or_sections是一个整数N,则数组将被分割沿着‘轴’进入N个相等的数组

-
如果indices_or_sections是排序整数的1-D数组,则为条目指示数组被分割的‘轴’的位置
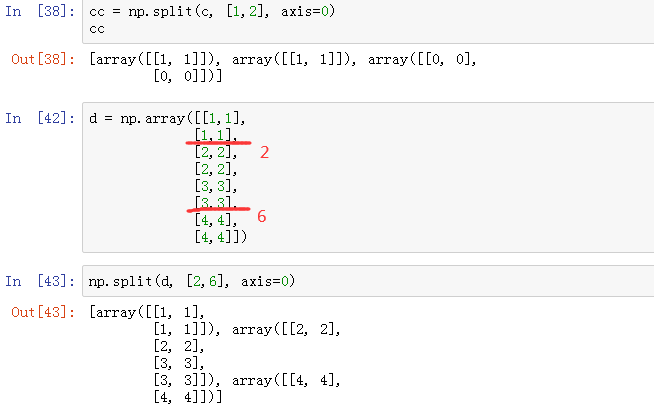
对于一个二维空间,按照[1,2]且axis=0,结果如下:
二维空间内部的、索引值为0的一维数组会被分裂到同一个新的二维空间
二维空间内部的、索引值为1的一维数组会被分裂到同一个新的二维空间
二维空间内部的、索引值为2以及2以后的的一维数组会被分裂到同一个新的二维空间
对于一个二维空间,按照[2,6]且axis=0,结果如下:
二维空间内部的、索引值为0、1的一维数组会被分裂到同一个新的二维空间
二维空间内部的、索引值为2、3、4、5的一维数组会被分裂到同一个新的二维空间
二维空间内部的、索引值为6以及6以后的的一维数组会被分裂到同一个新的二维空间
-
十、常用运算操作
Numpy 中数组上的算术运算符使用元素级别,最后的结果使用新的一个数组来返回
-
1、基本运算符

-
2、基本运算函数
-
Numpy 有两种基本对象:ndarray (N-dimensional array object) 和 ufunc (universal function object)
-
ndarray 是存储单一数据类型的多维数组,而 ufunc 则是能够对数组进行处理的函数



-
3、复合赋值运算符
某些操作(如 += 和 *=)可以修改现有数组,而不是创建新数组

-
4、矩阵运算

- 需要注意的是,乘法运算符 * 的运算在 NumPy 数组中也是元素级别的
- 如果想要执行矩阵乘积,可以使用dot函数
- dot(a, b, out=None)
- 如果'a'和'b'都是1-D数组,它就是向量的内积
- 如果'a'和'b'都是二维数组,那就是矩阵乘法
- 如果'a'或'b'是0-D(标量),它相当于 numpy.multiply(a,b) 或 a * b
- 如果'a'是N-D数组而'b'是1-D数组,则它是和的乘积'a'和'b'的最后一个轴

-
5、用于布尔型数组的方法
获得布尔型数组:
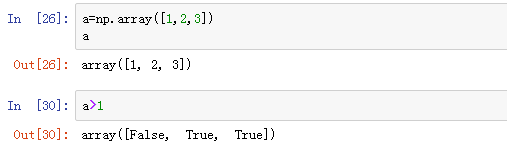
使用布尔型数组进行筛选:

高维数组筛选完的结果为一维数组:


-
十一、聚合函数
-
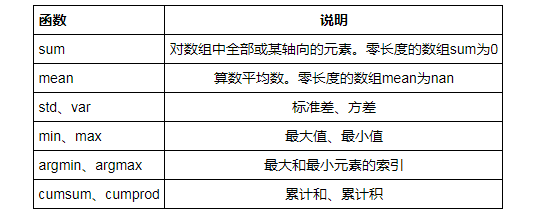
1、常用聚合函数
下面所有的函数都支持 axis 来指定不同的轴,用法类似
通过 np.sum() 方式调用:
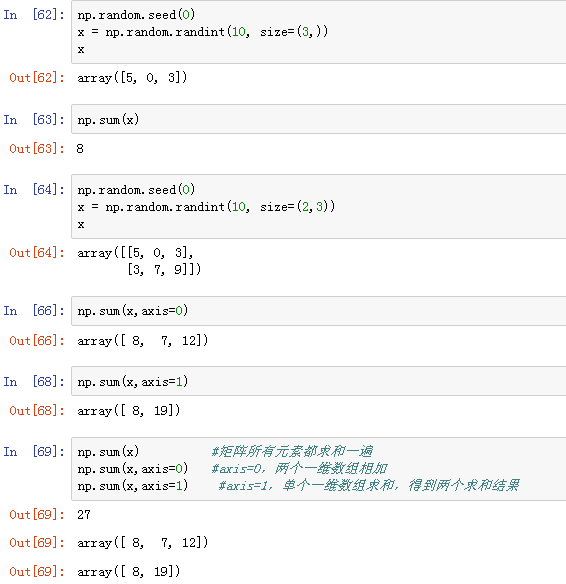
上面的求和方式可以通过数组对象来调用.sum()函数:

总结:
对于二维数组的操作,如果是axis=0
-
操作的对象就是各个一维数组
对于二维数组的操作,如果是axis=1
-
操作的对象就是一维数组内部的一个个元素
-
2、Numpy聚合函数使用场景
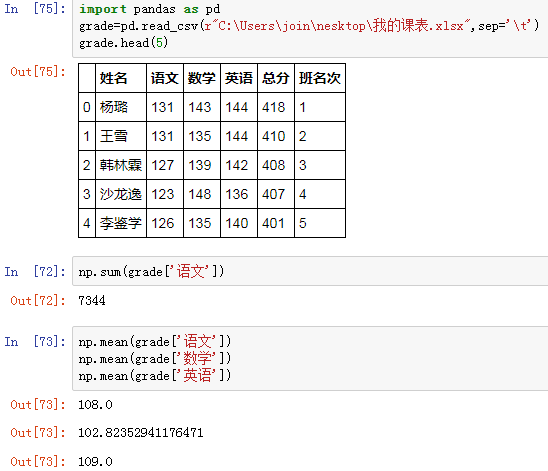
-
十二、Numpy的排序
-
1、np.sort()
-
语法1:a.sort()
-
作用:就地对数组进行排序,会修改源数组
-
语法2:np.sort()
-
作用:对数组进行排序,不会修改源数组

对于多维数组排序,传入轴编号即可,该方法默认 axis = -1:

-
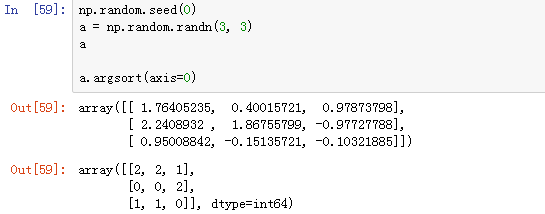
2、np.argsort()
返回将对此数组进行排序的索引


-
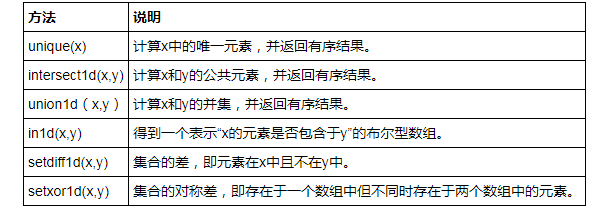
十三、唯一化和集合逻辑
-
1、唯一化

-
2、交集

-
3、并集(去重)

-
4、差集

-
5、补集

-
6、判断一个集合的元素是否包含于另一个集合中

-
十四、Numpy的广播机制
-
广播机制:
-
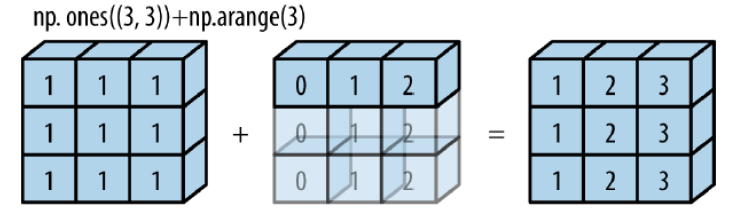
规则1:如果两个数组形状中,只有其中一个维度相同,另一个维度不一致,但是其中一个数组有维度为1,则可以补齐


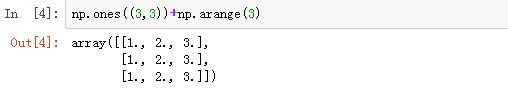
-
规则2:如果两个数组的形状在任何一个维度都不匹配,但两个数组都有其中一维度为1,则数组的形状会沿着维度为1的维度扩展,以匹配另外一个数组形状
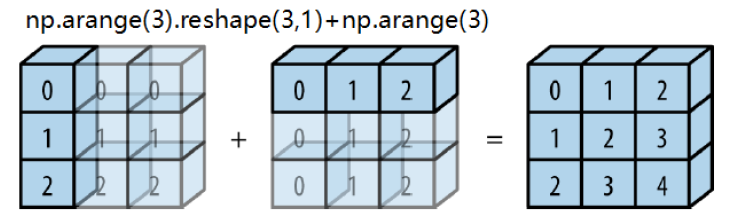

-
规则3:如果两个数组的形状在任何一个维度上都不匹配,并且没有任何一个维度等于1,会广播错误
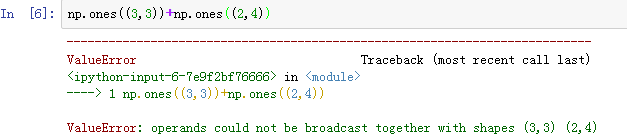

 浙公网安备 33010602011771号
浙公网安备 33010602011771号