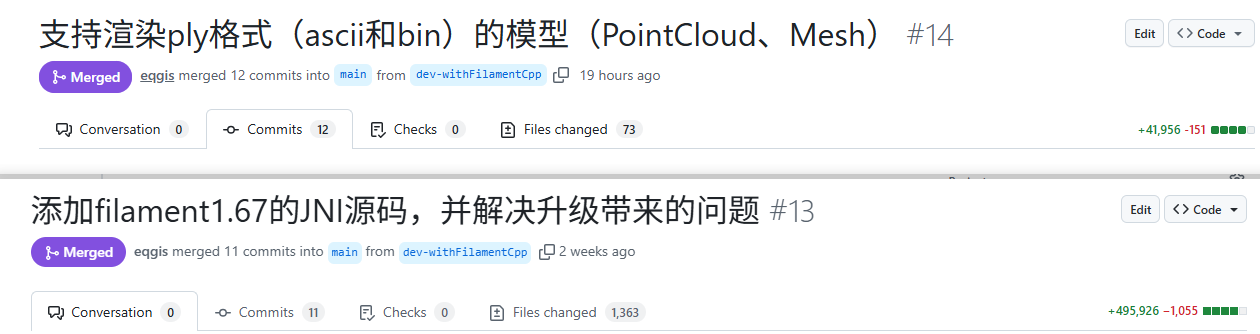
【2026年首文】【Sceneform-EQR】基于 Filament 支持 PLY 点云 / Mesh 并探索 3D Gaussian Splatting 渲染实现
【2026年的第一篇文章!!!欢迎交流!!!】
最近两周没有更新文章,并非懈怠。
而是在 Sceneform-EQR 中做了一件我感兴趣的事情:
——让基于 Filament 的 Sceneform-EQR,支持 PLY 格式,并开始实现渲染 3D Gaussian Splatting。

【Sceneform-EQR】基于 Filament 支持 PLY 点云 / Mesh 并探索 3D Gaussian Splatting 渲染实现
作者:EQ-雪梨蛋花汤
第一章|写在前面:这两周我在做什么
在 Android / AR / 3D 渲染这一侧,Sceneform + Filament 一直是一个“能力强、但边界清晰”的体系。
强在:
- Filament 跨平台 PBR 渲染引擎
- Sceneform 对 Android 开发者非常友好
- 架构清晰,Renderable / Material / Entity 层次明确
但它的边界也非常明确:
Sceneform / Filament 从来不是一个“通用模型加载框架”
目前filament支持的格式仍只有 gltf。而在计算机视觉、点云重建、NeRF / 3DGS 等领域,PLY 几乎是事实标准。
1.1 为什么一定要支持 PLY?
原因其实很现实:
- PLY 是点云领域的通用交换格式
- 绝大多数 3D 扫描、SLAM、SfM、3DGS 的中间结果都是 PLY
- Mesh / PointCloud / Gaussian 数据经常混在一个 PLY 里
如果 Sceneform-EQR 想继续向 “ 3D点云 可视化” 方向发展,PLY 是绕不过去的。
当然,最主要原因还是想学习。于是乎,学着学着就做出来了。
1.2 Filament 的“能力盲区”
但问题也非常明确:
- Filament 不提供任何 PLY Loader
- Filament 的 Java API 层对自定义数据并不友好
- 3D Gaussian Splatting 强依赖排序 + 透明混合
- Filament 当前不支持 Compute Shader
这意味着:
这不是“加个解析器”的问题,而是一次 跨 Java / JNI / C++ / 渲染管线的系统工程。是一个不错的学习机会。
1.3 夜太美,总有人黑着眼眶熬着夜
不是在我敲键盘,就是在键盘在敲我。
断断续续用了半个月的空闲时间,初见成效。
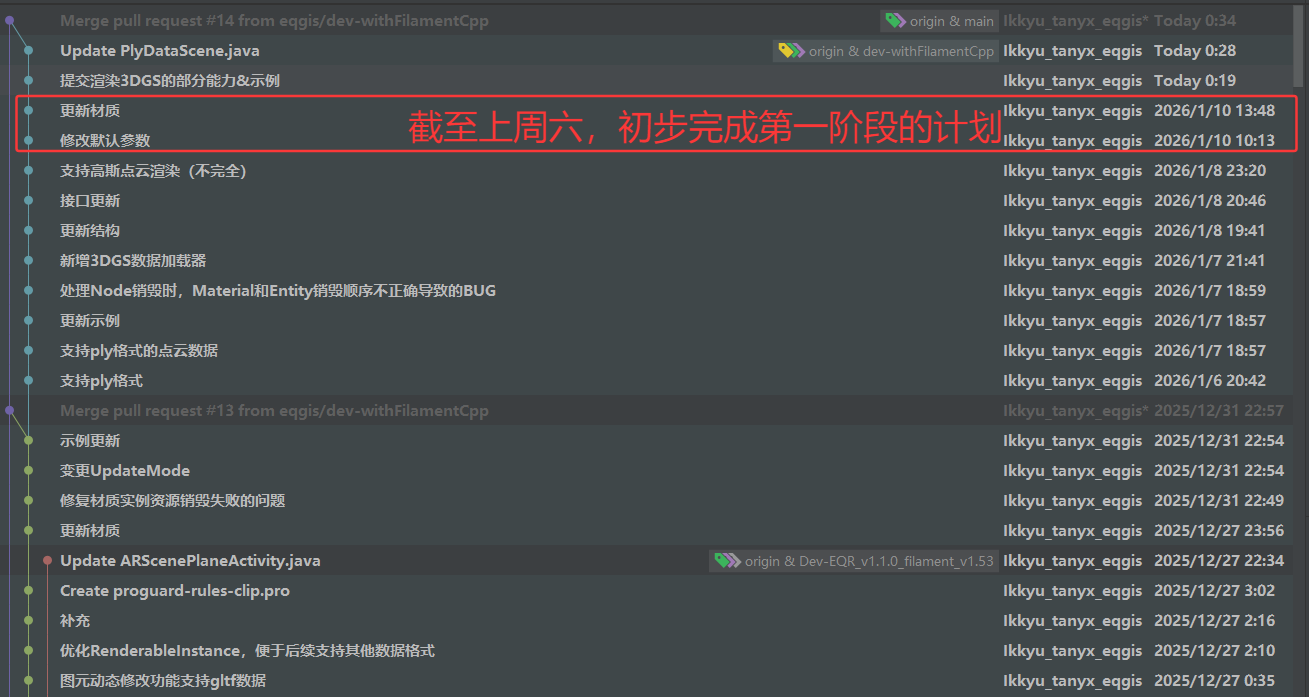
第二章|相关背景与基础知识梳理
在进入实现细节前,先把几个关键背景说清楚。
2.1 Sceneform-EQR 的整体结构
Sceneform-EQR 本质上是:
Android App
├── Sceneform Java 层
│ ├── Renderable
│ ├── Material
│ ├── Scene / Node
│
└── Filament Engine
├── VertexBuffer / IndexBuffer
├── MaterialInstance
├── Entity
关键点在于:
- Java 层并不直接“画东西”
- 所有真实渲染数据,最终都要进入 Filament C++ 世界
2.2 PLY 格式并不只是“点云”
很多人对 PLY 的第一印象是“点云格式”,但实际上:
-
PLY 是一个 通用几何数据容器
-
它可以表示:
- 纯 Point Cloud
- 带 Face 的 Mesh
- 带颜色 / 法线 / 纹理坐标
- 甚至自定义属性(Gaussian、SH)
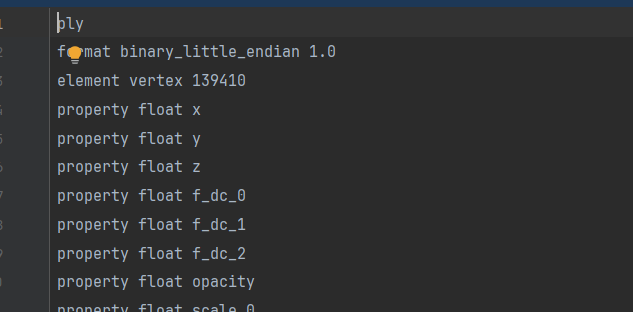
常见结构大致如下:
ply
format binary_little_endian 1.0
comment Created in Blender version 4.2.0
element vertex 79
property float x
property float y
property float z
property float s
property float t
element face 39
property list uchar uint vertex_indices
end_header
这也意味着:
PLY 也有很强的“可扩展性”。
2.3 为什么要开始研究 3D Gaussian Splatting
3DGS 最近两年非常火,但它真正困难的地方不在算法,而在 工程落地:
- 需要大量点(10W~百万级)
- 需要透明混合
- 需要正确的前后排序
- 非常依赖 GPU 能力
而 Filament:
- ✔ 渲染能力很强
- ✖ 不支持 Compute Shader
这直接切断了 GPU 排序这条路。
此外,需要特别说明的是:
3D Gaussian Splatting(3DGS)之所以具备极高的渲染性能,其根本原因并不在于某种新的图形渲染技巧,而在于它将传统实时渲染中高度耦合的“几何构建 + 光照计算 + 可见性判断”等复杂问题,整体退化并重构为一个高度适合 CUDA 并行执行的二维 Gaussian splat 累加计算问题。
相比之下,基于传统 GPU 图形渲染管线(如 OpenGL / Vulkan)的实现方式,并不具备这种算法结构上的优势。在这类管线中渲染 3DGS,通常只能采用 Billboard + GPU 排序 的折中方案:即将每一个高斯点伪装为一个 billboard,由顶点着色器与片元着色器完成投影、椭圆近似与透明混合。
需要明确的是,这种方案的本质只是将 3DGS 的数据结果映射到传统渲染管线中进行可视化,而非复现其原生的 CUDA splatting 计算流程。它仍然受限于三角形光栅化、片元过绘、半透明排序以及固定渲染阶段的性能瓶颈,因此并不能体现 3DGS 在 CUDA 实现下所展现出的真实渲染效率优势。
2.4 顶点渲染顺序的重要性
在 Filament 中使用 transparent 混合模式时,需要特别注意其渲染顺序机制。Filament 并不会在渲染阶段对单个 Renderable 内部的顶点或图元进行深度排序,
而是严格按照 IndexBuffer 中的顶点索引顺序提交并绘制图元。当渲染对象包含大量半透明元素(如 3DGS 中的高斯 billboard)且未进行显式排序时,片元混合将不再符合真实的空间前后关系,极易导致渲染层级错乱。
其直观表现是画面中局部区域同时呈现出“仿佛从上方俯视、又像从下方仰视”的矛盾视觉效果——这种现象并非相机或模型变换错误,而是透明混合顺序失效所致。因此,在基于 Filament 实现 3DGS 可视化时,顶点或图元级别的排序并非优化项,而是保证视觉正确性的必要前置条件。
仔细看下图!!!是不是既像俯视,又像仰视。这就是排序的问题

不幸的是,Filament 本身不支持计算着色器(Compute Shader),也不向上层暴露任何可用的通用 GPU 计算接口。 因此没法实现GPU排序。(虽然CPU排序性能开销很大,但终归是能做排序)
参考:
第三章|技术选型:为什么是 C++ + tinyPly
3.1 tinyPly 的选择原因
在 PLY 数据解析方案的选择上,曾对比过基于 Java 实现的 Jply 与 C++ 实现的 tinyply。
Jply 在 Android 端集成成本较低,调用方式直接,适合进行快速验证与原型开发;但其实现受限于 Java 运行环境,难以与底层渲染数据结构形成高效衔接,也不利于在不同平台间复用解析逻辑。
相比之下,tinyply 作为一个轻量级、无平台依赖的 C++ PLY 解析库,更符合跨平台渲染引擎的使用场景。将 PLY 解析逻辑下沉至 C++ 层,并通过 filament-cpp 扩展与 Filament 的原生数据结构对接,不仅可以避免多语言数据拷贝带来的额外开销。
因此,在综合性能、依赖库大小与平台扩展能力后,最终选择 tinyply 作为 PLY 解析的核心方案。
tinyPly 只做一件事: “只负责把 PLY 变成结构化内存数据”
3.2 为什么要直接引入 Filament JNI 源码
这是一个关键决策,为什么要在Sceneform-EQR中引入 Filament JNI 源码。
如果只使用官方 AAR:
- JNI 层是黑盒
- 无法扩展原生加载逻辑
- 很多内部结构不可控
- aar中未使用的接口增加了依赖库的包体积
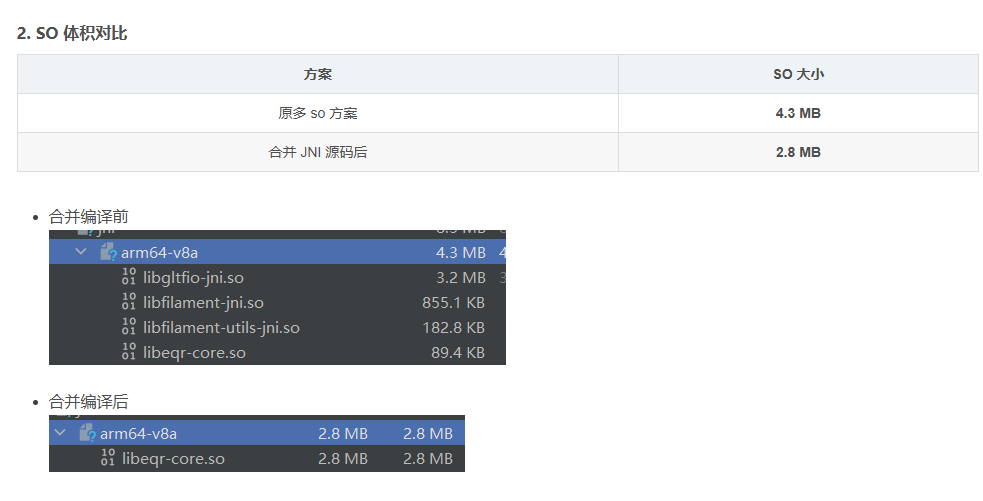
于是我选择了:
包体积对比
直接引入 Filament 1.67 的 JNI 源码
这一步带来的好处是:
- 更小的包体积
- 可控的 Native 生命周期
- 可扩展的数据通道
- 为 PLY / 3DGS 打开空间
第四章|PLY 数据读取与结构解析实现
4.1 数据来源统一:本地 & 网络
我刻意 不破坏 Sceneform 原有的数据加载设计:
- 本地 URI
- 网络 URL
- InputStream → Native
最终 PLY 在 Native 层看到的,永远是一段 内存 buffer。
读取资产 -> 装配数据 -> 销毁资产

4.2 Header 解析与元素识别
解析 PLY 的第一步不是读数据,而是:
- 有哪些 element?
- vertex / face 是否存在?
- 每个 property 的类型与顺序?
tinyPly 示例:
file.request_properties_from_element(
"vertex",
{ "x", "y", "z", "red", "green", "blue" }
);
4.3 Mesh / 点云的自动判断
判断逻辑非常简单,但非常重要:
- 有 face → Mesh
- 只有 vertex → Point Cloud
这一判断直接决定:
- 是否创建 IndexBuffer
4.4 数据整理与内存布局
解析完成后,会整理为几类数组:
- positions:float3
- colors:uchar4 / float4
- indices(若有)
这一步非常关键,因为:
Filament 对 VertexBuffer 布局极其敏感
第五章|Filament 渲染管线的装配
5.1 VertexBuffer / IndexBuffer 构建
根据解析结果动态构建:
VertexBuffer::Builder()
.vertexCount(count)
.bufferCount(1)
.attribute(POSITION, 0, FLOAT3)
点云与 Mesh 的区别在这里完全体现出来。
5.2 点云材质设计
在Filament中渲染普通点云时,采用点图元。
在Filament中渲染3DGS时,用三角图元(两个三角形组成一个quad,实现屏幕对齐的 billboard)。
关键参数:
- pointSize
- color
- blendMode
5.3 Sceneform 层的无感接入
新增setDataFormat(RenderableDataFormat format)方法。
Java 层看到的依然是:
ModelRenderable
.builder()
.setSource(context, Uri.parse(dataPath))
.setDataFormat(Renderable.RenderableDataFormat.PLY)
.build()
PLY 成功融入了原有生态。
第六章|3D Gaussian Splatting 的尝试与现实限制
6.1 3DGS 在工程中的真实难点
理论很美好,工程很现实:
- 每个 Gaussian 都是半透明
- 排序必须准确
- 数量巨大
6.2 Filament 不支持 Compute Shader 的现实
这意味着:
- 无法 GPU 排序
- 无法 Prefix Sum
- 无法并行深度排序
最终只能退回到:
CPU 排序 + 每帧更新 IndexBuffer
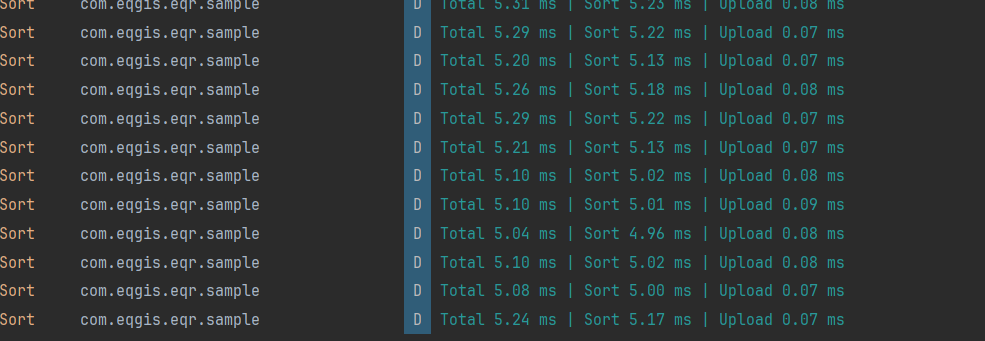
实测数据:
- 14 万点
- 排序约 6ms
- 尚可接受,但不完美
6.3 当前 3DGS 的阶段性结论
- 已实现:数据读取 / 基础渲染
- 未完成:高性能排序 / 完整透明策略
- 状态:抽空继续做
第七章|效果、示例与阶段性成果
7.1 已支持能力总结
当前 Sceneform-EQR 已支持:
- ✔ PLY Mesh(ASCII / Binary)
- ✔ PLY Point Cloud
- ✔ 本地 / 网络加载的加载方式
- doing:3DGS 部分渲染能力


 浙公网安备 33010602011771号
浙公网安备 33010602011771号