OpenCV如何进行算法提速——以光流法为例
1 背景
OpenCV在将算法提速方面可谓无所不用其极。KLT光流可能是做视觉SLAM最常用的前端之一(Vins-mono采用)。本文即分析光流法的具体实现,借此窥探OpenCV中算法实现的工程技巧。
2 稀疏光流原理
2.1 光流法
光流法有两个比较强的假设:
- 同一个object point, 其intensity 在相邻帧上是不变的。
- 某个像素和其一定范围内的像素的运动是相近的。
基于此, 有以下等式:
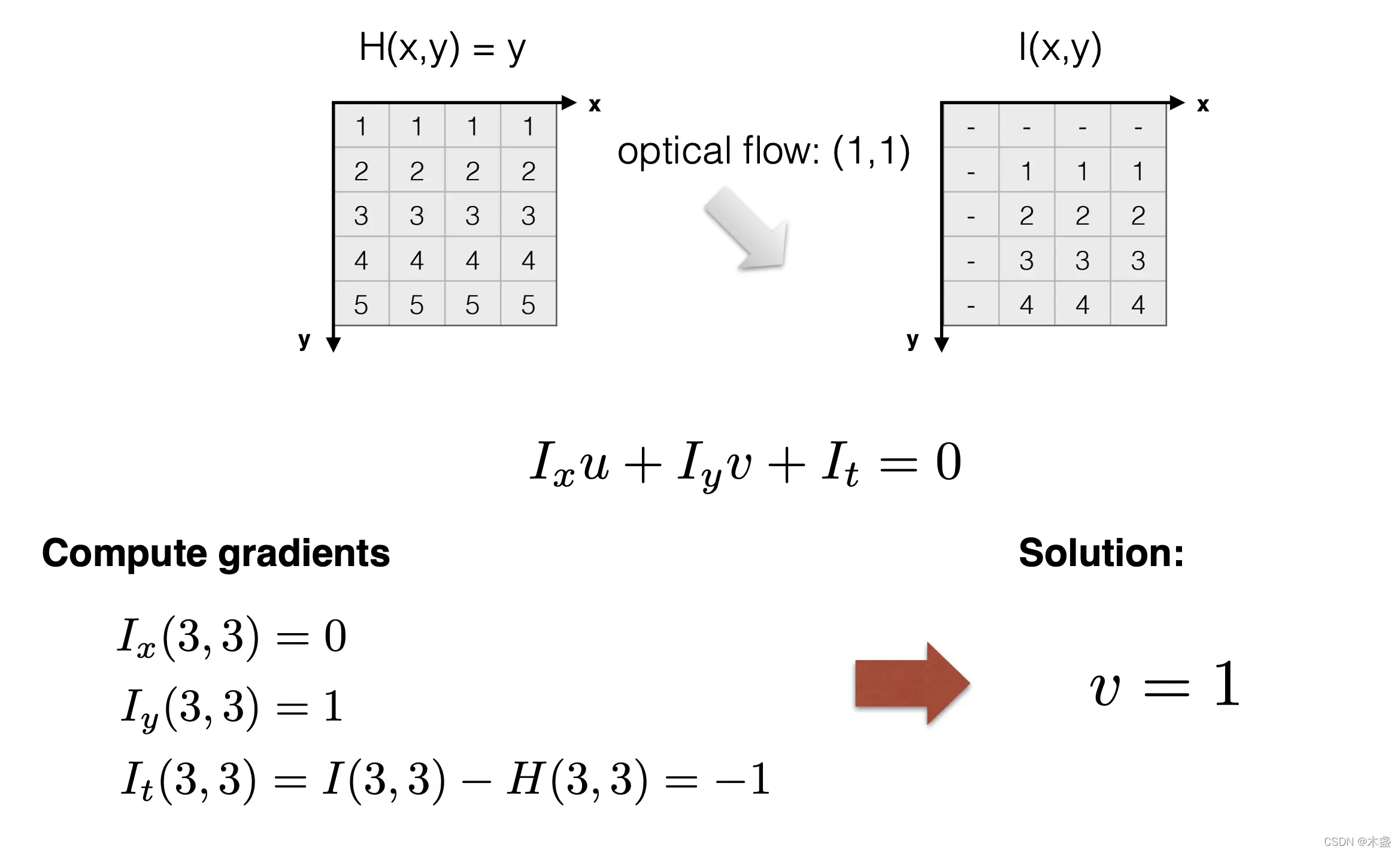
其中, \(I(x, y, z)\)表示图像在t时刻, x, y位置处的intensity. 对上式进行一阶泰勒展开, 有
记\(u = \frac{ \partial x }{ \partial t }, v = \frac{ \partial y }{ \partial t }, I_{x} = \frac{ \partial I }{ \partial x }, I_{y} = \frac{ \partial I }{ \partial y }, I_{t} = \frac{ \partial I }{ \partial t }\), 则上式可简洁地记为:
各种方法围绕该式进行计算.
其中:
- \(I_{x}\) 为当前帧图像在y轴方向的梯度(通过像素差分得到)。
- \(I_{y}\)为当前帧图像在y轴方向的梯度(通过像素差分得到)。
- \(I_{t}\)则可以通过下一帧图像与当前帧图像差分得到。
2.2 LK光流
- 类型: 稀疏光流
- 核心思想: Lucas-Kanade方法是稀疏光流的基石。它基于三个核心假设:
- 亮度恒定: 同一个物理点在不同帧间的像素强度保持不变。
- 时间连续性/小运动: 相邻帧之间,点的运动位移很小。
- 空间一致性: 一个特征点周围邻域内的所有像素点具有相似的运动。
- 基于这些假设,LK方法通过在一个小窗口内最小化光度误差来求解一个超定线性方程组,从而得到特征点的运动矢量。为了处理较大的位移,OpenCV中实现了该算法的金字塔版本 (calcOpticalFlowPyrLK),通过在不同分辨率的图像金字塔上进行迭代计算,由粗到精地估计运动,显著提升了对大运动的鲁棒性。
- 算法原理:
-
对于LK光流,会提取特征点附近5x5区域内的所有点,构建25个方程(见公式(0)),组成矩阵形式:
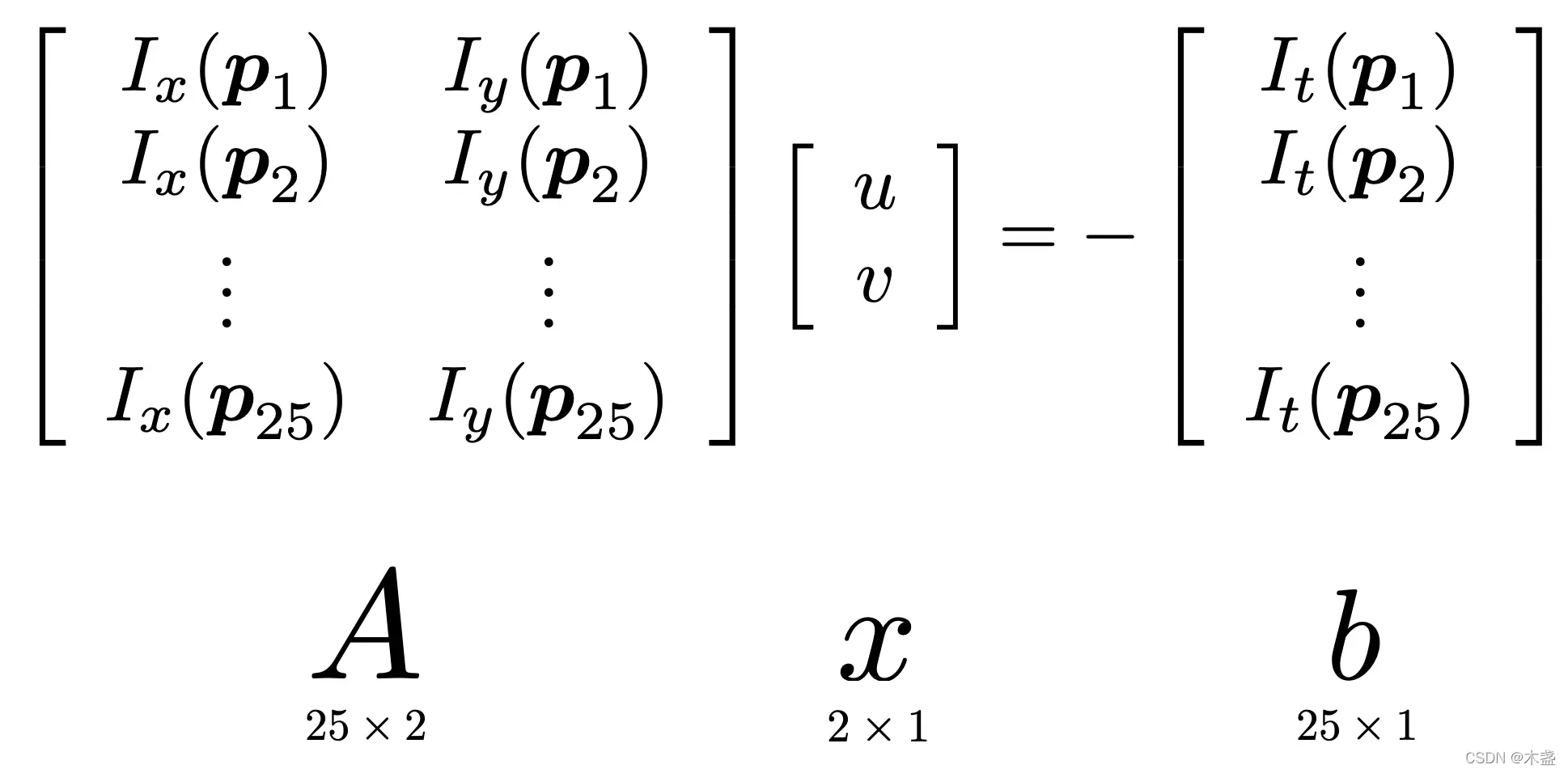
-
随后通过最小二乘来获得特征点的移动。最小二乘为:\(A^\top A = A^\top b\),则有
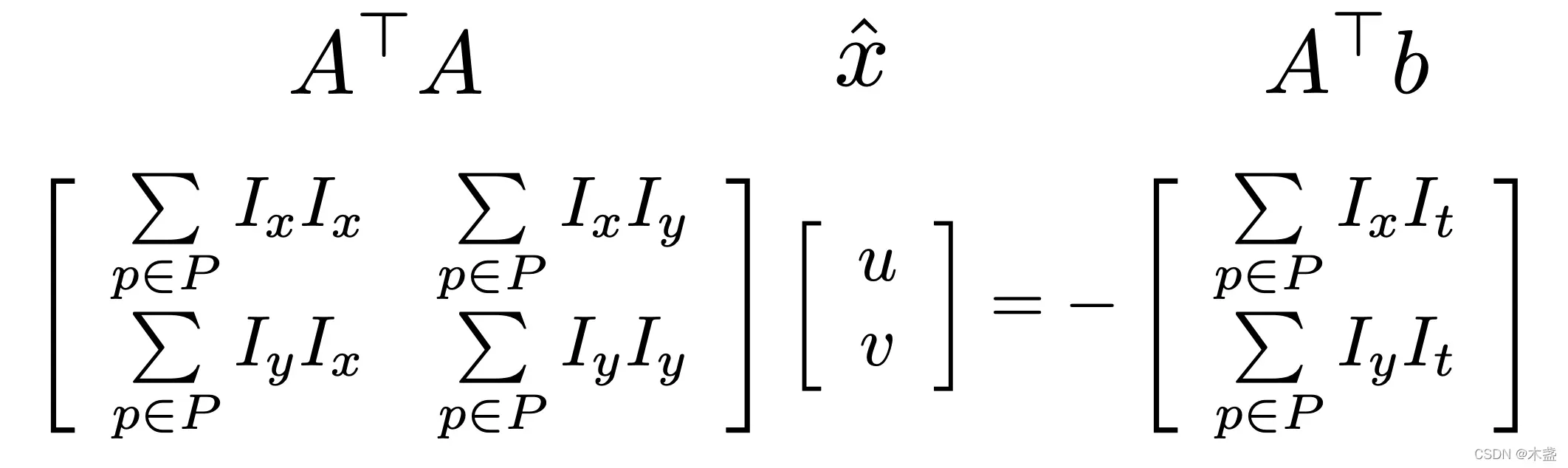
-
3 OpenCV中的光流加速
实际实现中,为了获得更快的光流法提取效果,OpenCV采取了一系列措施。我这里以OpenCV-4.12的源码举例(modules/video/src/lkpyramid.cpp),分析OpenCV的加速措施。
3.1 HAL加速
HAL是"Hardware Abstract Layer"的缩写。是OpenCV的抽象层。我们以cv::pyrDown函数为例,窥探一下OpenCV是如何使用它的。
cv::pyrDown函数为光流金字塔里的降采样的函数,其先对原始图像进行高斯模糊,再进行下采样。
其完整版实现为:
void cv::pyrDown( InputArray _src, OutputArray _dst, const Size& _dsz, int borderType )
{
CV_INSTRUMENT_REGION();
CV_Assert(borderType != BORDER_CONSTANT);
CV_OCL_RUN(_src.dims() <= 2 && _dst.isUMat(),
ocl_pyrDown(_src, _dst, _dsz, borderType))
Mat src = _src.getMat();
Size dsz = _dsz.empty() ? Size((src.cols + 1)/2, (src.rows + 1)/2) : _dsz;
_dst.create( dsz, src.type() );
Mat dst = _dst.getMat();
int depth = src.depth();
if(src.isSubmatrix() && !(borderType & BORDER_ISOLATED))
{
Point ofs;
Size wsz(src.cols, src.rows);
src.locateROI( wsz, ofs );
CALL_HAL(pyrDown, cv_hal_pyrdown_offset, src.data, src.step, src.cols, src.rows,
dst.data, dst.step, dst.cols, dst.rows, depth, src.channels(),
ofs.x, ofs.y, wsz.width - src.cols - ofs.x, wsz.height - src.rows - ofs.y, borderType & (~BORDER_ISOLATED));
}
else
{
CALL_HAL(pyrDown, cv_hal_pyrdown, src.data, src.step, src.cols, src.rows, dst.data, dst.step, dst.cols, dst.rows, depth, src.channels(), borderType);
}
PyrFunc func = 0;
if( depth == CV_8U )
func = pyrDown_< FixPtCast<uchar, 8> >;
else if( depth == CV_16S )
func = pyrDown_< FixPtCast<short, 8> >;
else if( depth == CV_16U )
func = pyrDown_< FixPtCast<ushort, 8> >;
else if( depth == CV_32F )
func = pyrDown_< FltCast<float, 8> >;
else if( depth == CV_64F )
func = pyrDown_< FltCast<double, 8> >;
else
CV_Error( cv::Error::StsUnsupportedFormat, "" );
func( src, dst, borderType );
}
可以看到其先调用了CALL_HAL宏来尝试调用hal版本的算法。cv_hal_pyrdown也是一个宏,其定义在“modules/imgproc/src/hal_replacement.hpp”中。根据不同的编译选项,该宏的定义可能为以下几种硬件加速版本的算法之一:
- fastcv:FastCV 是 高通 提供的一个计算机视觉加速库,专门用于 ARM 架构的设备(如 Snapdragon 处理器)。它优化了多个常见的图像处理算法,包括图像滤波、特征提取、图像变换等。。详见Enable OpenCV with FastCV for Qualcomm Chipsets
- IPP:Intel Performance Primitives 是英特尔提供的高效硬件加速库,旨在优化图像和信号处理操作。在 OpenCV 中,HAL 支持通过调用 IPP 函数来加速许多图像处理操作,尤其在 Intel CPU 上执行时,能提供显著的性能提升。我们x86平台上的多为IPP加速库。但其没有pyrDown的硬件加速版本实现。
- CUDA: NVIDIA 提供的 CUDA 是一个并行计算平台,专门用于加速 GPU 上的计算。OpenCV 支持通过 CUDA 对图像处理任务进行加速,尤其在处理高分辨率图像或视频时,能够显著提高性能。
- opencl: OpenCL 是一种支持异构计算的平台,允许在 CPU、GPU 及其他加速器上运行计算任务。OpenCV 通过 HAL 层支持 OpenCL 进行硬件加速,尤其是在图像处理和计算机视觉算法中。
如果有硬件加速版本的算法,则CALL_HAL会直接返回结果而不执行后面的代码。否则,会执行普通cpu版本的pyrDown_<>函数。
3.2 多线程加速
大部分OpenCV的算法都进行了并行化改造,甚至包括一些基础的函数(例如cv::resize())。它们大多以以下结构的形式给出:
void Algorithm1::calc(args...) {
// 一些准备工作
cv::parallel_for_(Range(a, b), Algorithm1Invoker(args...));
}
有两个需要注意的函数或者结构体:cv::parallel_for_与基类为cv::ParallelLoopBody的Algorithm1Invoker。
3.2.1 cv::parallel_for_
cv::parallel_for_是OpenCV的并行化数据处理函数,其接受一个cv::Range参数来指定需要并行化的数据范围,接受一个cv::ParallelLoopBody参数来指定并行化的代码的具体实现。举例来说,对于resize操作,我想对目标图像的每一行实现并行化计算其像素值,则我可以指定参数1为cv::Range(0, dst_img.rows)。cv::parallel_for_函数会根据当前可用的线程数量以及用户的其他设置,自动将该range切分为多个sub range来并行化。切分好range后,会调用OpenMP或者自己内部实现的线程池进行加速。
3.2.2 cv::ParallelLoopBody
其实现为
class CV_EXPORTS ParallelLoopBody
{
public:
virtual ~ParallelLoopBody();
virtual void operator() (const Range& range) const = 0;
};
为一个纯虚接口类。通常需要实现一个派生类来继承该基类,接受一个range,完成对range范围内的算法的操作。比如resize操作,其输入range为[i, i+1]时,则该函数需要完成对目标图像的(i, i+1)行的像素的赋值。
- 可以通过
cv::setNumThreads(1)来关闭线程加速,从而降低生产环境中的CPU占用。
在pyrDown_<>中,首先构建每个降采样后的像素在原图像中的索引,随后调用cv::PyrDownInvoker(继承自cv::ParallelLoopBody)逐行并行加速降采样。
3.3 指令集加速
下面分析cv::PyrDownInvoker函数。
其定义为
template<class CastOp>
void PyrDownInvoker<CastOp>::operator()(const Range& range) const
{
const int PD_SZ = 5;
typedef typename CastOp::type1 WT;
typedef typename CastOp::rtype T;
Size ssize = _src->size(), dsize = _dst->size();
int cn = _src->channels();
int bufstep = (int)alignSize(dsize.width*cn, 16);
AutoBuffer<WT> _buf(bufstep*PD_SZ + 16);
WT* buf = alignPtr((WT*)_buf.data(), 16);
WT* rows[PD_SZ];
CastOp castOp;
int sy0 = -PD_SZ/2, sy = range.start * 2 + sy0, width0 = std::min((ssize.width-PD_SZ/2-1)/2 + 1, dsize.width);
ssize.width *= cn;
dsize.width *= cn;
width0 *= cn;
for (int y = range.start; y < range.end; y++)
{
T* dst = (T*)_dst->ptr<T>(y);
WT *row0, *row1, *row2, *row3, *row4;
// fill the ring buffer (horizontal convolution and decimation)
int sy_limit = y*2 + 2;
for( ; sy <= sy_limit; sy++ )
{
WT* row = buf + ((sy - sy0) % PD_SZ)*bufstep;
int _sy = borderInterpolate(sy, ssize.height, _borderType);
const T* src = _src->ptr<T>(_sy);
do {
int x = 0;
const int* tabL = *_tabL;
for( ; x < cn; x++ )
{
row[x] = src[tabL[x+cn*2]]*6 + (src[tabL[x+cn]] + src[tabL[x+cn*3]])*4 +
src[tabL[x]] + src[tabL[x+cn*4]];
}
if( x == dsize.width )
break;
if( cn == 1 )
{
x += PyrDownVecH<T, WT, 1>(src + x * 2 - 2, row + x, width0 - x);
for( ; x < width0; x++ )
row[x] = src[x*2]*6 + (src[x*2 - 1] + src[x*2 + 1])*4 +
src[x*2 - 2] + src[x*2 + 2];
}
else if( cn == 2 )
{
x += PyrDownVecH<T, WT, 2>(src + x * 2 - 4, row + x, width0 - x);
for( ; x < width0; x += 2 )
{
const T* s = src + x*2;
WT t0 = s[0] * 6 + (s[-2] + s[2]) * 4 + s[-4] + s[4];
WT t1 = s[1] * 6 + (s[-1] + s[3]) * 4 + s[-3] + s[5];
row[x] = t0; row[x + 1] = t1;
}
}
else if( cn == 3 )
{
x += PyrDownVecH<T, WT, 3>(src + x * 2 - 6, row + x, width0 - x);
for( ; x < width0; x += 3 )
{
const T* s = src + x*2;
WT t0 = s[0]*6 + (s[-3] + s[3])*4 + s[-6] + s[6];
WT t1 = s[1]*6 + (s[-2] + s[4])*4 + s[-5] + s[7];
WT t2 = s[2]*6 + (s[-1] + s[5])*4 + s[-4] + s[8];
row[x] = t0; row[x+1] = t1; row[x+2] = t2;
}
}
else if( cn == 4 )
{
x += PyrDownVecH<T, WT, 4>(src + x * 2 - 8, row + x, width0 - x);
for( ; x < width0; x += 4 )
{
const T* s = src + x*2;
WT t0 = s[0]*6 + (s[-4] + s[4])*4 + s[-8] + s[8];
WT t1 = s[1]*6 + (s[-3] + s[5])*4 + s[-7] + s[9];
row[x] = t0; row[x+1] = t1;
t0 = s[2]*6 + (s[-2] + s[6])*4 + s[-6] + s[10];
t1 = s[3]*6 + (s[-1] + s[7])*4 + s[-5] + s[11];
row[x+2] = t0; row[x+3] = t1;
}
}
else
{
for( ; x < width0; x++ )
{
int sx = (*_tabM)[x];
row[x] = src[sx]*6 + (src[sx - cn] + src[sx + cn])*4 +
src[sx - cn*2] + src[sx + cn*2];
}
}
// tabR
const int* tabR = *_tabR;
for (int x_ = 0; x < dsize.width; x++, x_++)
{
row[x] = src[tabR[x_+cn*2]]*6 + (src[tabR[x_+cn]] + src[tabR[x_+cn*3]])*4 +
src[tabR[x_]] + src[tabR[x_+cn*4]];
}
} while (0);
}
// do vertical convolution and decimation and write the result to the destination image
for (int k = 0; k < PD_SZ; k++)
rows[k] = buf + ((y*2 - PD_SZ/2 + k - sy0) % PD_SZ)*bufstep;
row0 = rows[0]; row1 = rows[1]; row2 = rows[2]; row3 = rows[3]; row4 = rows[4];
int x = PyrDownVecV<WT, T>(rows, dst, dsize.width);
for (; x < dsize.width; x++ )
dst[x] = castOp(row2[x]*6 + (row1[x] + row3[x])*4 + row0[x] + row4[x]);
}
}
注意到其对每一行进行降采样的时候,调用了PyrDownVecH函数来加速计算。该函数为一个模板函数,其对于uint8的一个偏特化版本为:
template<typename T1, typename T2, int cn> int PyrDownVecH(const T1*, T2*, int)
{
// row[x ] = src[x * 2 + 2*cn ] * 6 + (src[x * 2 + cn ] + src[x * 2 + 3*cn ]) * 4 + src[x * 2 ] + src[x * 2 + 4*cn ];
// row[x + 1] = src[x * 2 + 2*cn+1] * 6 + (src[x * 2 + cn+1] + src[x * 2 + 3*cn+1]) * 4 + src[x * 2 + 1] + src[x * 2 + 4*cn+1];
// ....
// row[x + cn-1] = src[x * 2 + 3*cn-1] * 6 + (src[x * 2 + 2*cn-1] + src[x * 2 + 4*cn-1]) * 4 + src[x * 2 + cn-1] + src[x * 2 + 5*cn-1];
return 0;
}
#if (CV_SIMD || CV_SIMD_SCALABLE)
template<> int PyrDownVecH<uchar, int, 1>(const uchar* src, int* row, int width)
{
int x = 0;
const uchar *src01 = src, *src23 = src + 2, *src4 = src + 3;
v_int16 v_1_4 = v_reinterpret_as_s16(vx_setall_u32(0x00040001));
v_int16 v_6_4 = v_reinterpret_as_s16(vx_setall_u32(0x00040006));
for (; x <= width - VTraits<v_int32>::vlanes(); x += VTraits<v_int32>::vlanes(), src01 += VTraits<v_int16>::vlanes(), src23 += VTraits<v_int16>::vlanes(), src4 += VTraits<v_int16>::vlanes(), row += VTraits<v_int32>::vlanes())
v_store(row, v_add(v_add(v_dotprod(v_reinterpret_as_s16(vx_load_expand(src01)), v_1_4), v_dotprod(v_reinterpret_as_s16(vx_load_expand(src23)), v_6_4)), v_shr<16>(v_reinterpret_as_s32(vx_load_expand(src4)))));
vx_cleanup();
return x;
}
//...
#endif
可以看到,如果SIMD指令集可用,会调用SIMD指令,一次性处理128/32=4个像素的高斯模糊,如此处理一行中的大部分像素,并返回已经处理的像素梳理。如果不可用,则直接返回0。
这就是OpenCV的工程哲学之一:尽可能使用SIMD指令处理能被4整除的数据,对于剩余的数据,再使用naive版本的算法继续处理。
3.4 浮点转定点
回顾计算机原理知识:计算机在计算float型变量和int型变量的加减乘除时,其运算的时间是不一样的。尤其是乘除法,可以达到5-10倍的运算时间差别。
因此,在光流法的像素的双非线性插值中, 其插值系数都是从浮点型先转到int型,再参与后续的计算的
//void cv::detail::LKTrackerInvoker::operator()(const Range& range) const
//...
const int W_BITS = 14, W_BITS1 = 14;
int iw00 = cvRound((1.f - a)*(1.f - b)*(1 << W_BITS));
int iw01 = cvRound(a*(1.f - b)*(1 << W_BITS));
int iw10 = cvRound((1.f - a)*b*(1 << W_BITS));
int iw11 = (1 << W_BITS) - iw00 - iw01 - iw10;
// ...
for( ; x < winSize.width*cn; x++, dsrc += 2, dIptr += 2 )
{
int ival = CV_DESCALE(src[x]*iw00 + src[x+cn]*iw01 +
src[x+stepI]*iw10 + src[x+stepI+cn]*iw11, W_BITS1-5);
int ixval = CV_DESCALE(dsrc[0]*iw00 + dsrc[cn2]*iw01 +
dsrc[dstep]*iw10 + dsrc[dstep+cn2]*iw11, W_BITS1);
int iyval = CV_DESCALE(dsrc[1]*iw00 + dsrc[cn2+1]*iw01 + dsrc[dstep+1]*iw10 +
dsrc[dstep+cn2+1]*iw11, W_BITS1);
// .....
4 总结
OpenCV的算法,根据编译选项的不同,可能会有以下一种或多种加速:
- HAL硬件加速。
- 多线程加速。
- 指令集加速(SIMD或者NEON)
- 浮点转定点加速。
OpenCV的很多基础函数都进行了多线程加速,因此需要特别注意,如果不指定可使用的线程数量,即使是一个简单的resize,也可能导致算法的CPU占用飙升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号