人工神经网络入门
内容来自:
https://blog.csdn.net/2501_93508870/article/details/152129593
https://c.biancheng.net/view/ubyyfl6.html
https://mp.weixin.qq.com/s/cUOo_yPjYleMm_Yn1HAj5A
前导知识:
线性代数(矩阵运算,矩阵相乘)、高等数学(导数、微分)、概率论与数理统计(均匀分布、正态分布)、Python(函数、循环、随机数)、NumPy、Matplotlib;信息论;矩阵论;

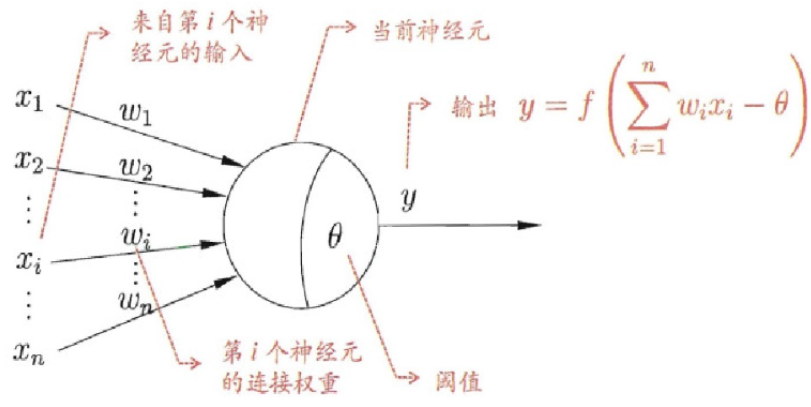
神经元模型
神经元模型是 1943 年由心理学家 Warren McCulloch 和数理逻辑学家 Walter Pitts 在合作的 a logical calculus of the ideas immanent in nervous activity 论文中提出的,并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。
在神经网络中,神经元处理单元可以表示不同的对象,例如特征、字母、概念,或者一些有意义的抽象模式。网络中处理单元的类型分为三类,分别是输入单元、输出单元和隐单元:
- 输入单元接收外部世界的信号与数据;
- 输出单元实现系统处理结果的输出;
- 隐单元是处在输入和输出单元之间,不能由系统外部观察的单元。
神经元间的连接权值反映了单元间的连接强度,信息的表示和处理体现在网络处理单元的连接关系中。
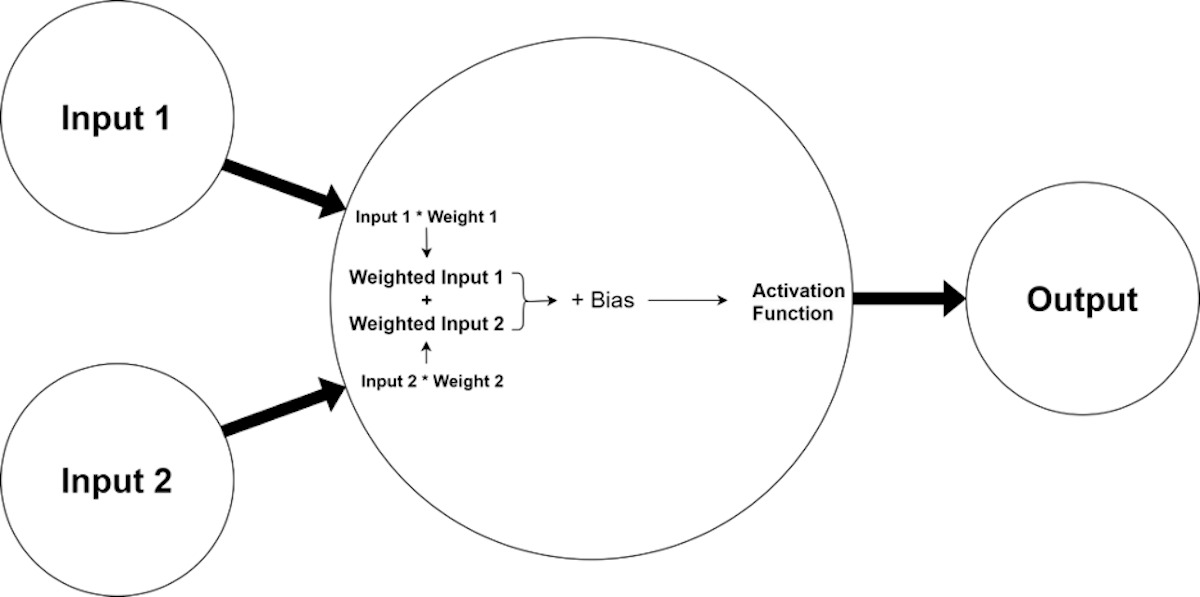
神经网络是一种模仿生物神经网络的结构和功能的数学模型或计算模型,它是由大量的节点(即神经元)和其间的相互连接构成的,每个节点代表一种特定的输出函数,称为激励函数(激活函数),每两个节点间的连接都代表一个通过该连接信号的加权值,称之为权重。
神经元是神经网络的基本元素,如下图所示:
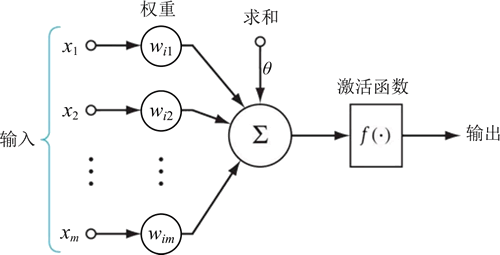
图 1 神经元
其中, x1,…,xm 是从其他神经元传来的输入信号,wij 表示从神经元 j 到神经元 i 的连接权值,θ 表示一个阈值,或称为偏置(bias),则神经元 i 的输出与输入的关系表示为:
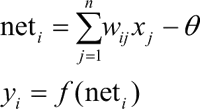
其中,yi 表示神经元 i 的输出,函数 f 称为激活函数,neti 称为净激活。若将阈值看成神经元 i 的一个输入 x0 的权重 wi0,则上面的式子可以简化为:
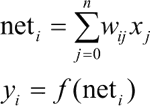
若用 X 表示输入向量,用 W 表示权重向量,即:
X=[x0, x1,…,xn ]
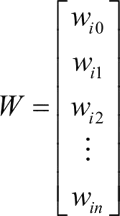
则神经元的输出可以表示为向量相乘的形式:
yi = f(neti) = f(XW)
如果神经元的净激活为正,则称该神经元处于激活状态或兴奋状态,如果神经元的净激活为负,则称神经元处于抑制状态。
多层感知机
多层感知机(Multi-Layer Perceptron,MLP)是一种前向结构的人工神经网络,用于映射一组输入向量到一组输出向量。
MLP 可以认为是一个有向图,由多个节点层组成,每一层全连接到下一层。除输入节点外,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。
多层感知机由以下几个部分组成:
- 输入层:接收外部信息,并将这些信息传递到网络中。输入层中的节点并不进行任何计算,它们只是将数据分布到下一层的神经元。
- 隐藏层:一个或多个隐藏层位于输入层和输出层之间。每个隐藏层都包含若干神经元,这些神经元具有非线性激活函数,如 Sigmoid 或 Tanh 函数。隐藏层的神经元与前一层的所有神经元全连接,并且它们的输出会作为信号传递到下一层。
- 输出层:输出层产生网络的最终输出,用于进行预测或分类。输出层神经元的数量取决于要解决的问题类型,例如在二分类问题中通常只有一个输出神经元,而在多分类问题中则可能有多个输出神经元。
- 权重和偏置:连接两个神经元的权重表示这两个神经元之间联系的强度。每个神经元还有一个偏置项,它帮助调整神经元激活的难易程度。
- 激活函数:激活函数引入非线性因素,使得神经网络能够学习和模拟更复杂的关系。没有激活函数的神经网络将无法解决线性不可分的问题。
多层感知机模型如下图所示:
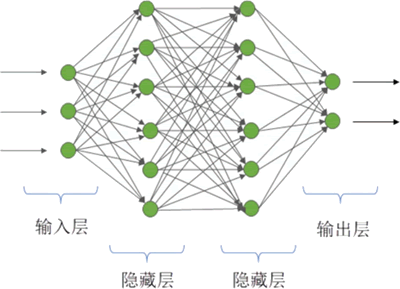
图 5 多层感知机模型
多层感知机通过在训练过程中不断调整连接权重和偏置来学习输入数据中的模式。这种调整通常是通过反向传播算法实现的,该算法利用输出误差来更新网络中的权重,以减少预测错误。
MLP 是感知机的推广,克服了感知机不能对线性不可分数据进行识别的弱点。若每个神经元的激活函数都是线性函数,那么任意层数的MLP都可以被简化成一个等价的单层感知机。
MLP 本身可以使用任何形式的激活函数,譬如阶梯函数或逻辑 S 形函数(Logistic Sigmoid
Function),但为了使用反向传播算法进行有效学习,激活函数必须限制为可微函数。由于具有良好的可微性,很多 S
形函数,尤其是双曲正切(Hyperbolic Tangent)函数及逻辑 S 形函数,被采用为激活函数。
常被 MLP 用来进行学习的反向传播算法,在模式识别领域已经成为标准的监督学习算法,并在计算神经学及并行分布式处理领域中获得广泛研究。MLP 已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
隐藏层神经元的作用是从样本中提取样本数据中的内在规律模式并保存起来,隐藏层每个神经元与输入层都有边相连,隐藏层将输入数据加权求和并通过非线性映射作为输出层的输入,通过对输入层的组合加权及映射找出输入数据的相关模式,而且这个过程是通过误差反向传播自动完成的。
当隐藏层节点太少的时候,能够提取以及保存的模式较少,获得的模式不足以概括样本的所有有效信息,得不到样本的特定规律,导致识别同样模式新样本的能力较差,学习能力较差。
当隐藏层节点个数过多时,学习时间变长,神经网络的学习能力较强,能学习较多输入数据之间的隐含模式,但是一般来说输入数据之间与输出数据相关的模式个数未知,当学习能力过强时,有可能把训练输入样本与输出数据无关的非规律性模式学习进来,而这些非规律性模式往往大部分是样本噪声,这种情况叫作过拟合(Over
Fitting)。
过拟合是记住了过多和特定样本相关的信息,当新来的样本含有相关模式但是很多细节并不相同时,预测性能并不是太好,降低了泛化能力。这种情况的表现往往是在训练数据集上误差极小,在测试数据集上误差较大。
具体隐藏层神经元个数的多少取决于样本中蕴含规律的个数以及复杂程度,而样本蕴含规律的个数往往和样本数量有关系。确定网络隐藏层参数的一个办法是将隐藏层个数设置为超参,使用验证集验证,选择在验证集中误差最小的作为神经网络的隐藏层节点个数。还有就是通过简单的经验设置公式来确定隐藏层神经元个数:
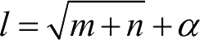
其中,l 为隐藏层节点个数,m 是输入层节点个数,n 是输出层节点个数,α 一般是 1~10 的常数。
MLP 在 20 世纪 80 年代的时候曾是相当流行的机器学习方法,拥有广泛的应用场景,譬如语音识别、图像识别、机器翻译等,但自 20 世纪 90 年代以来,MLP 遇到来自更为简单的支持向量机的强劲竞争。由于深度学习的成功,MLP 又重新得到了关注。
=================================================
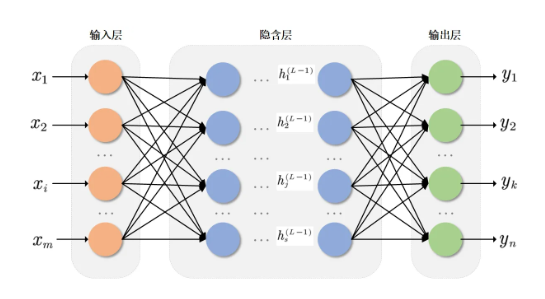
一、先搞懂:神经网络像“多层计算器”
神经网络的核心是分层处理信息,就像工厂流水线:原料(输入数据)→加工(隐藏层)→成品(输出结果)。
1. 3大核心层
输入层:接收原始数据,比如识别图片时的像素值、预测房价时的面积/地段数据。
节点数=输入数据的维度(例:用2个特征预测房价,输入层就有2个节点)。
隐藏层:核心“加工间”,负责提取数据特征(比如从图片像素中识别“边缘”“颜色块”)。
层数和节点数可调整,简单任务1-2层足够,复杂任务(如图像识别)可能有几十层。
输出层:输出最终结果,比如“这张图是猫(1)还是狗(0)”“房价预测值150万”。
节点数=任务目标(二分类1个节点,多分类(如识别10种动物)10个节点)。
二、最小单元:神经元怎么“思考”?
每层的“节点”就是神经元,它的工作分3步,核心是加权计算+非线性转换。
1. 第一步:算“加权输入”(给输入打分)
每个输入会被赋予一个“权重”( wi,可理解为“重要性”),再加上一个“偏置”(b,调整基准),求和得到净输入z。
公式:

xi:神经元的第 i 个输入(比如输入层的“面积”“地段”);
wi:对应 xi 的权重(比如“面积”对房价影响大, w就大);
b:偏置项(避免输入全为0时神经元“不工作”)。
例子:用 “面积( x1=100m² , w1=1.2)” “地段( x2=8分, w2=5)” 预测房价,偏置 b=20,则:
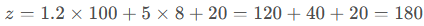
2. 第二步:过“激活函数”(加个“决策规则”)
净输入 z是线性的,无法处理复杂问题(比如区分“猫”和“狗”的非线性特征),所以需要激活函数把 z转换成非线性输出 a。
常用3种激活函数 :

接上面例子:若用ReLU激活, a=max(0,180)=180(可理解为房价的“初步预测值”)。
3. 第三步:输出结果(传给下一层或收尾)
激活后的 a,要么作为下一层神经元的输入,要么作为最终结果(如输出层用Sigmoid输出“是猫的概率0.92”)。
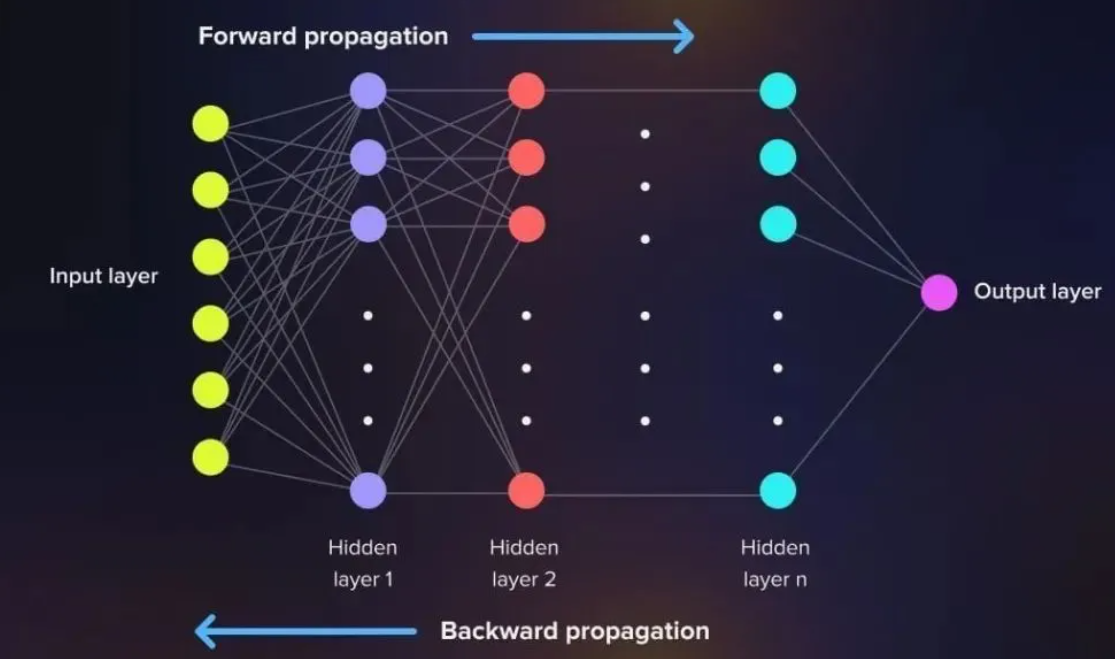
三、核心流程:神经网络怎么“学”?(前向+反向)
神经网络的“学习”,本质是通过前向传播算预测值→反向传播调参数,不断降低“预测误差”。
1. 前向传播:从输入到输出的“正向计算”
简单说就是“逐层算输出”,把输入层数据通过权重、偏置、激活函数,一步步传到输出层,得到预测值 y^。
以“输入层(2节点)→隐藏层(3节点)→输出层(1节点)”为例:
输入层→隐藏层:每个隐藏节点用公式

算净输入,再过ReLU 得 a隐;
隐藏层→输出层:输出节点用
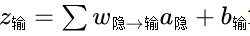
算净输入,再过Sigmoid得预测值 y^。
2. 误差计算:先看“预测错多少”
有了预测值 y^,需要和真实值 y(比如标签“这是猫, y=1”)比,算“误差”。常用2种误差函数:
均方误差(MSE):适用于回归任务(预测连续值,如房价、温度)
公式:

( m是样本数,误差越大,Loss值越大)
交叉熵损失:适用于分类任务(预测离散类别,如猫/狗)
公式(二分类):
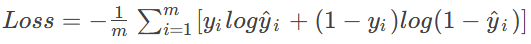
3. 反向传播:“倒着调参数”(最关键!)
这个部分需要导数、微分的知识。
误差出来后,要反过来调整所有的 w(权重)和 b(偏置),让下次预测更准。核心是用梯度下降找“最优参数”。
(1)核心逻辑:梯度下降
梯度是“误差对参数的导数”,代表“参数变化1单位时,误差的变化方向”。梯度下降的规则是:
参数 = 参数 - 学习率×梯度
学习率( η):控制每次调整的“步长”,太大容易“跑过头”,太小收敛慢(常用0.0001、0.001,、0.01、0.1);
梯度:若梯度为正,参数减“步长”→误差减小;若梯度为负,参数加“步长”→误差减小。
(2)具体步骤(简化版)
计算输出层误差:用误差函数对输出层的 z求导,得到输出层误差 δ输; 详见:https://www.cnblogs.com/emanlee/p/19181442
传递误差到隐藏层:用输出层误差 δ输 和 权重 w隐→输,算隐藏层误差 δ隐 (链式法则); 详见:https://www.cnblogs.com/emanlee/p/19181854
更新参数:用误差 δ算梯度,再按 “参数=参数-η×梯度” 调整 w 和 b。
假设某权重 w=2,梯度=0.5,学习率 η=0.1,则新权重 w新=2−0.1×0.5=1.95。
四、小白必知:2个实用知识点
1. 常见优化算法(比“普通梯度下降”更好用)
SGD(随机梯度下降):每次用1个样本更参数,快但波动大;
Mini-Batch(小批量):每次用10-100个样本更参数,平衡“速度”和“稳定”(最常用);
Adam:自带“动量”和“自适应学习率”,新手直接用,收敛快还不容易卡壳。
2. 简单代码示例(Python版,能跑通!)
用Python实现一个“预测房价”的简单神经网络(3层,输入2个特征,输出1个房价):
# https://www.cnblogs.com/emanlee/p/19178995
# ArtificialNeuralNetworks.py
import numpy as np ## import matplotlib.pyplot as plt from matplotlib.ticker import MaxNLocator import os # 创建保存图片的目录 if not os.path.exists('nn_plots'): os.makedirs('nn_plots') # 1. 激活函数及其导数 def relu(z): return np.maximum(0, z) def relu_derivative(z): return (z > 0).astype(float) # ReLU derivative def linear(z): return z # Linear activation for output layer def linear_derivative(z): return np.ones_like(z) # Derivative of linear function is 1 # 2. 参数初始化 (使用Xavier初始化改进) def init_params(input_dim, hidden_dim, output_dim): # Xavier initialization for more stable training w1 = np.random.randn(input_dim, hidden_dim) * np.sqrt(2 / (input_dim + hidden_dim)) b1 = np.zeros((1, hidden_dim)) # Hidden layer bias w2 = np.random.randn(hidden_dim, output_dim) * np.sqrt(2 / (hidden_dim + output_dim)) b2 = np.zeros((1, output_dim)) # Output layer bias return w1, b1, w2, b2 # 3. 前向传播 def forward(w1, b1, w2, b2, X): z1 = np.dot(X, w1) + b1 # Input to hidden layer net input a1 = relu(z1) # Hidden layer output z2 = np.dot(a1, w2) + b2 # Hidden to output layer net input a2 = linear(z2) # Output layer uses linear activation for regression return z1, a1, z2, a2 # 4. 损失计算 (MSE) def compute_loss(a2, Y): m = Y.shape[0] loss = (1/(2*m)) * np.sum((a2 - Y)**2) return loss def compute_loss_derivative(a2, Y): return (a2 - Y) / Y.shape[0] # Derivative of MSE # 5. 反向传播 def backward(w1, b1, w2, b2, z1, a1, z2, a2, X, Y): m = X.shape[0] # Output layer gradients dz2 = compute_loss_derivative(a2, Y) * linear_derivative(z2) dw2 = (1/m) * np.dot(a1.T, dz2) db2 = (1/m) * np.sum(dz2, axis=0, keepdims=True) # Hidden layer gradients dz1 = np.dot(dz2, w2.T) * relu_derivative(z1) dw1 = (1/m) * np.dot(X.T, dz1) db1 = (1/m) * np.sum(dz1, axis=0, keepdims=True) return dw1, db1, dw2, db2 # 6. 参数更新 (带学习率衰减) def update_params(w1, b1, w2, b2, dw1, db1, dw2, db2, lr, decay_rate=0.0001, epoch=0): # Learning rate decay current_lr = lr / (1 + decay_rate * epoch) w1 = w1 - current_lr * dw1 b1 = b1 - current_lr * db1 w2 = w2 - current_lr * dw2 b2 = b2 - current_lr * db2 return w1, b1, w2, b2, current_lr # 7. 可视化函数 def plot_training_curve(losses, learning_rates, save_path='nn_plots/training_curve.png'): """Plot training loss and learning rate curves""" fig, ax1 = plt.subplots(figsize=(10, 6)) color = 'tab:red' ax1.set_xlabel('Epoch') ax1.set_ylabel('Loss', color=color) ax1.plot(losses, color=color) ax1.tick_params(axis='y', labelcolor=color) ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) ax1.set_title('Training Loss and Learning Rate') ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis color = 'tab:blue' ax2.set_ylabel('Learning Rate', color=color) # we already handled the x-label with ax1 ax2.plot(learning_rates, color=color) ax2.tick_params(axis='y', labelcolor=color) fig.tight_layout() # otherwise the right y-label is slightly clipped plt.savefig(save_path, dpi=300, bbox_inches='tight') plt.close() def plot_predictions_vs_actual(Y, predictions, epoch, save_dir='nn_plots/'): """Plot predictions vs actual values""" plt.figure(figsize=(10, 6)) plt.scatter(Y, predictions, alpha=0.6) plt.plot([Y.min(), Y.max()], [Y.min(), Y.max()], 'r--') # Perfect prediction line plt.xlabel('Actual Values') plt.ylabel('Predictions') plt.title(f'Predictions vs Actual Values (Epoch {epoch})') plt.grid(True, linestyle='--', alpha=0.7) plt.savefig(f'{save_dir}predictions_epoch_{epoch}.png', dpi=300, bbox_inches='tight') plt.close() def plot_weight_distributions(w1, w2, epoch, save_dir='nn_plots/'): """Plot weight distributions""" fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5)) ax1.hist(w1.flatten(), bins=20, alpha=0.7) ax1.set_title('Distribution of Input-Hidden Weights') ax1.set_xlabel('Weight Value') ax1.set_ylabel('Frequency') ax1.grid(True, linestyle='--', alpha=0.7) ax2.hist(w2.flatten(), bins=20, alpha=0.7) ax2.set_title('Distribution of Hidden-Output Weights') ax2.set_xlabel('Weight Value') ax2.set_ylabel('Frequency') ax2.grid(True, linestyle='--', alpha=0.7) plt.tight_layout() plt.savefig(f'{save_dir}weights_dist_epoch_{epoch}.png', dpi=300, bbox_inches='tight') plt.close() # 8. 主训练函数 def train_model(X, Y, input_dim, hidden_dim, output_dim, epochs=1000, lr=0.1, decay_rate=0.0001): # Initialize parameters w1, b1, w2, b2 = init_params(input_dim, hidden_dim, output_dim) # Lists to track training progress losses = [] learning_rates = [] # Initial predictions _, _, _, initial_preds = forward(w1, b1, w2, b2, X) plot_predictions_vs_actual(Y, initial_preds, 0) plot_weight_distributions(w1, w2, 0) # Training loop for epoch in range(epochs): # Forward propagation z1, a1, z2, a2 = forward(w1, b1, w2, b2, X) # Compute loss loss = compute_loss(a2, Y) losses.append(loss) # Backward propagation dw1, db1, dw2, db2 = backward(w1, b1, w2, b2, z1, a1, z2, a2, X, Y) # Update parameters with learning rate decay w1, b1, w2, b2, current_lr = update_params( w1, b1, w2, b2, dw1, db1, dw2, db2, lr, decay_rate, epoch ) learning_rates.append(current_lr) # Print progress and save plots at intervals if epoch % 100 == 0: print(f"Epoch {epoch}, Loss: {loss:.4f}, Learning Rate: {current_lr:.6f}") # Save predictions plot at certain epochs if epoch in [100, 300, 500, 700, epochs-1]: plot_predictions_vs_actual(Y, a2, epoch) plot_weight_distributions(w1, w2, epoch) # Final plots plot_training_curve(losses, learning_rates) return w1, b1, w2, b2, losses # 9. 测试模型 if __name__ == "__main__": # Generate synthetic data (house prices based on area and location) np.random.seed(42) # For reproducibility num_samples = 100 # Features: area (in 100 sq.m), location score (1-10) X = np.random.rand(num_samples, 2) X[:, 0] = X[:, 0] * 100 # Area: 0-100 sq.m X[:, 1] = X[:, 1] * 9 + 1 # Location score: 1-10 # True price function with some noise true_weights = np.array([1.2, 5.0]) # Weights for area and location true_bias = 20.0 # Base price noise = np.random.normal(0, 5, (num_samples, 1)) # Add some noise Y = (X @ true_weights).reshape(-1, 1) + true_bias + noise # Train the model print("Starting model training...") w1, b1, w2, b2, losses = train_model( X, Y, input_dim=2, hidden_dim=3, output_dim=1, epochs=1000, lr=0.001, # Lower learning rate for more stable training decay_rate=0.001 ) # Final evaluation _, _, _, final_preds = forward(w1, b1, w2, b2, X) final_loss = compute_loss(final_preds, Y) print(f"\nFinal training loss: {final_loss:.4f}") # Print true vs learned parameters for comparison print("\nTrue weights:", true_weights) print("True bias:", true_bias) # Print model architecture summary print("\nModel Architecture:") print(f"Input layer: {X.shape[1]} features") print(f"Hidden layer: {w1.shape[1]} neurons") print(f"Output layer: {w2.shape[1]} output")
=======================================
np.random.rand 是 NumPy 库中用于生成随机数的函数,主要功能是创建一个指定形状的数组,并填充在 [0, 1) 区间内均匀分布的随机浮点数。
=======================================
np.random.seed 是 NumPy 中用于设置随机数种子的函数,它的主要作用是让随机数生成过程变得可复现。
=======================================
np.random.normal 是 NumPy 中用于生成符合正态分布(高斯分布)随机数的函数。正态分布是统计学中最常用的分布之一,具有钟形曲线特征。
=======================================
numpy.ndarray.flatten() 是 NumPy 数组的一个方法,用于将多维数组 "展平" 为一维数组。它会返回一个新的一维数组,原数组的结构不会被改变。
=======================================
np.ones_like 是 NumPy 中的一个函数,用于创建一个与输入数组形状和数据类型相同,但所有元素都为 1 的新数组。
=======================================
深度学习框架有诸多选择,每个框架都有其独特的特点和优势。以下是一些主流的深度学习框架:
-
TensorFlow:
- 由Google开发,使用C++语言编写,支持多种语言接口(如Python、Java、R等)。
- 采用数据流图进行计算,拥有灵活的架构,可部署在多种设备上。
- 庞大的用户社区和丰富的教程资源,是使用人数最多、社区最为庞大的框架之一。
- 支持静态和动态图,用户可自定义模型架构,且具备高效的分布式计算能力。
-
PyTorch:
- 由Facebook开发,前身是Torch,但使用Python重新编写,更加灵活。
- 支持动态图,提供了Python接口,易于调试和修改。
- 在学术界广受好评,因其直观易用的语法和强大的社区支持。
-
Keras:
- 一个基于Theano和TensorFlow等框架的高层框架,提供大量方便快速训练和测试的高层接口。
- 对于常见应用,使用Keras开发效率高,但运行效率可能不如底层框架。
- 高度模块化,搭建网络简洁,API风格统一,易于扩展。
-
Caffe:
- 由加州大学伯克利的博士贾扬清开发,全称是Convolutional Architecture for Fast Feature Embedding。
- 对卷积网络支持较好,用C++编写,提供C++、Matlab和Python接口。
- 早期在ImageNet等比赛中表现出色,但灵活性相对不足,内存占用高。不过其升级版本Caffe2已有所改进。
-
MXNet:
- 主要作者是李沐,如今是亚马逊的官方框架。
- 具有很好的分布式支持,性能出色,占用显存低。
- 开发语言接口丰富(包括Python、C++、R、Matlab、Scala、JavaScript等),但教程不够完善。
-
Theano:
- 诞生于蒙特利尔理工学院,是深度学习库的首创之一。
- 核心是一个数学表达式的编译器,能将结构转化为高效代码在CPU或GPU上运行。
- 为深度学习中处理大型神经网络算法的计算而设计,但目前已停止维护。
-
PaddlePaddle:
- 百度研发的开源开放深度学习平台,是国内最早开源且功能完备的深度学习平台。
- 有最全面的官方支持的工业级应用模型,涵盖多个领域。
- 支持稠密参数和稀疏参数场景的超大规模深度学习并行训练,具有强大的多端部署能力。
-
Chainer、TensorLayer、CNTK(Microsoft Cognitive Toolkit)、DeepLearning4j 以及 ONNX 等也是值得关注的深度学习框架,它们在不同领域和场景下有着各自的应用优势。
在选择深度学习框架时,可以根据具体需求、项目规模和团队的熟悉程度来进行权衡和选择。每个框架都有其独特的优势和适用场景,因此选择最适合自己的框架是至关重要的。
=======================================
参考:
https://www.cnblogs.com/emanlee/p/19179509 numpy 中二维数据 乘以(@) 一维数组。 ![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号