self-attention自注意力机制
Self-Attention(自注意力)
前导知识:自然语言处理,Transformer。
4.Self-attention自注意力机制
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
注意力机制的计算过程:
1.将输入单词转化成嵌入向量(Transformer中,先把词变为向量表示,再加上位置编码);
2.根据嵌入向量得到q,k,v三个向量(怎么得到的?对前一步的向量,分别乘以WQ WK WV )【这三个矩阵是随机生成的】;
3.为每个向量计算一个score:score =q . k (q和k內积、点乘);
4.为了梯度的稳定,Transformer使用了score归一化,即除以 ;
;
5.对score施以softmax激活函数;
6.softmax点乘Value值v,得到加权的每个输入向量的评分v;
7.相加之后得到最终的输出结果z : 。
。
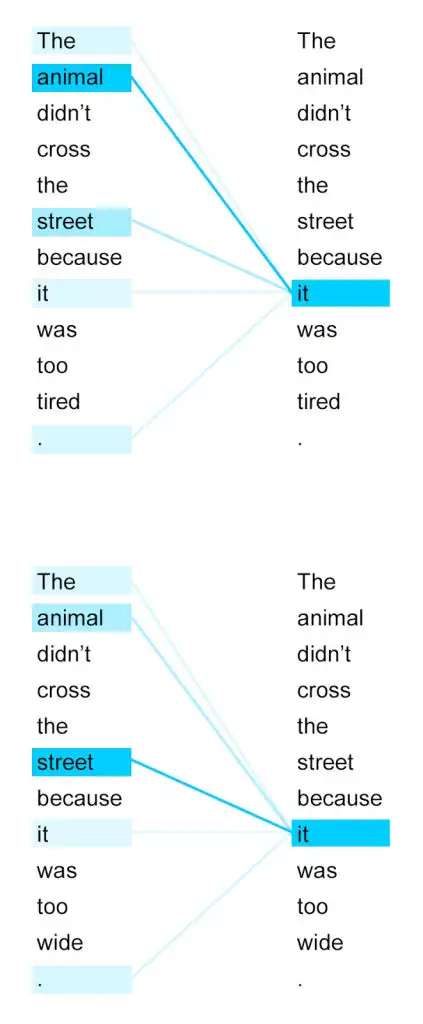
接下来我们详细看一下self-attention,其思想和attention类似,但是self-attention是Transformer用来将其他相关单词的“理解”转换成我们正在处理的单词的一种思路,我们看个例子: The animal didn't cross the street because it was too tired 这里的it到底代表的是 animal 还是 street 呢,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,self-attention 就能够让机器把 it 和 animal 联系起来,接下来我们看下详细的处理过程。
首先,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和embedding的维度一样,其值在BP(反向传播)的过程中会一直进行更新,得到的这三个向量的维度是64低于embedding维度的。( Query、Key、Value 怎么得到的?)
假设只有Thinking 和 Machines 两个词,这两个词的嵌入向量分别为X1和X2.
X1乘以Wq得到q1,X1乘以Wk得到k1,X1乘以Wv得到v1,
X2乘以Wq得到q2,X1乘以Wk得到k2,X1乘以Wv得到v2,
Wq , Wk , Wv 又是怎么得到的?矩阵是随机初始化的,后续更新。
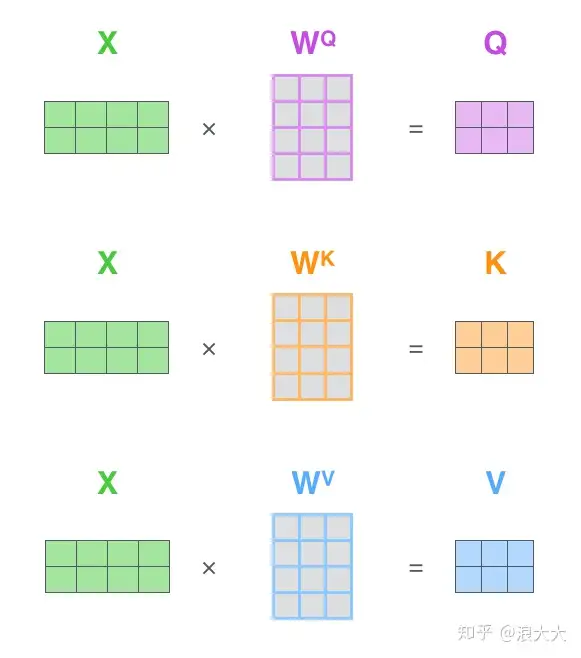

那么Query、Key、Value这三个向量又是什么呢?这三个向量对于attention来说很重要,当你理解了下文后,你将会明白这三个向量扮演者什么的角色。
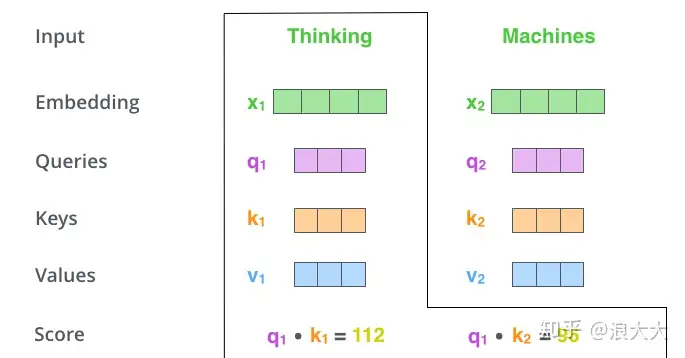
计算self-attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是Query与Key做点乘,以下图为例,首先我们需要针对Thinking这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即q1·k1(点乘),然后是针对于第二个词即q1·k2(点乘)
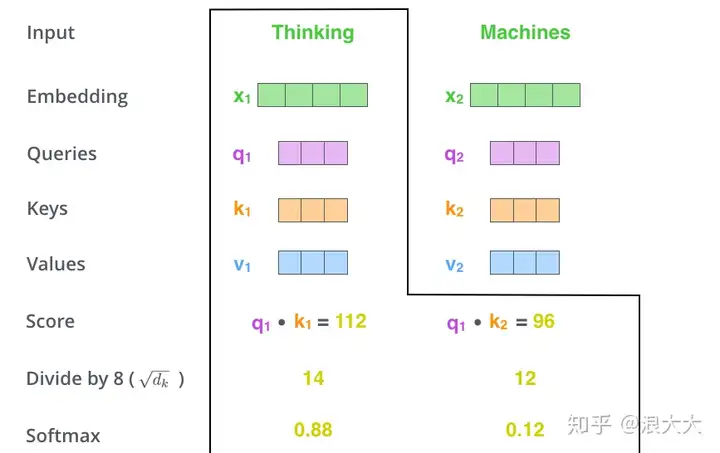
接下来,把点乘的结果除以一个常数,这里我们除以8,这个值一般是采用上文提到的矩阵的第一个维度的开方即64的开方8,当然也可以选择其他的值,然后把得到的结果做一个softmax的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会会很大。
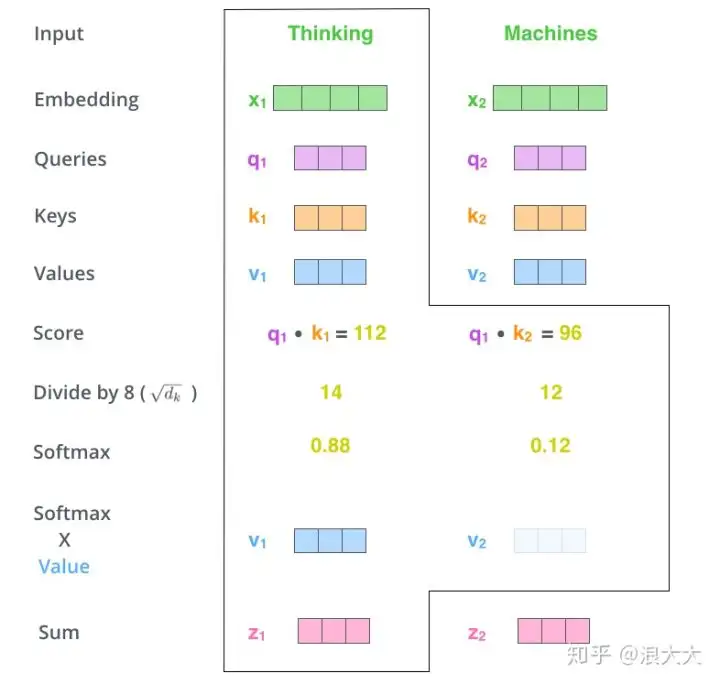
下一步就是把Value和softmax得到的值进行相乘,并相加,得到的结果即是self-attetion在当前节点的值
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出Query, Key, Value的矩阵,然后把embedding的值与三个矩阵直接相乘,把得到的新矩阵Q与K相乘,乘以一个常数,做softmax操作,最后乘上V矩阵
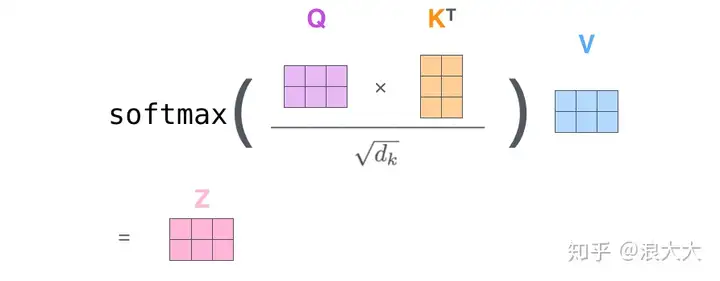
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention:
以上就是self-attention的计算过程,下边是两个句子中 it 与上下文单词的关系热点图,很容易看出来第一个图片中的 it 与 animal 关系很强,第二个图 it 与 street 关系很强。这个结果说明注意力机制是可以很好地学习到上下文的语言信息。
5.注意力机制的优缺点
attention的优点
1.参数少:相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
2.速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
3.效果好:在Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
缺点:
需要的数据量大。因为注意力机制是抓重点信息,忽略不重要的信息,所以数据少的时候,注意力机制效果不如bilstm,因为企业数据都是十万百万级的数据量,用注意力机制就很好。还有传统的lstm,bilstm序列短的时候效果也比注意力机制好。所以注意力机制诞生的原因就是面向现在大数据的时代,企业里面动不动就是百万数据,超长序列,用传统的递归神经网络计算费时还不能并行计算,人工智能很多企业比如极视角现在全换注意力机制了
缺点:
自注意力机制的信息抓取能力其实不如RNN和CNN,在小数据集的表现不如后两者,只有在数据量上来了之后才能发挥出实力。实际应用中数据集较小时建议还是用CNN和RNN
原始的输入embedding维度为dim,将原始的输入接一个DNN层,DNN层的维度为3 * dim,然后将映射后的结果平均分为三份,也就是Q,K,V, 每份embedding维度都为dim,然后就可以了
REF 转自
https://zhuanlan.zhihu.com/p/265108616
https://zhuanlan.zhihu.com/p/67909876
https://zhuanlan.zhihu.com/p/446134625

 浙公网安备 33010602011771号
浙公网安备 33010602011771号