
Python爬虫
Python1-环境配置
Python2-基础认识
Python3-数据类型
Python4-面向对象
Python5-闭包和装饰器
Python6-IO模块
Python7-进程线程携程
Python8-网络编程
Python爬虫
爬虫要用的东西
Python请求库的安装
- requests
- selenium 或 DrissionPage
- ChromeDriver (Google chrome)和 GeckoFriver(Firefox chrome)
- PhantomJS
- aiohttp
Python解析库的安装
- lxml
- Beautiful Soup
- pyquery
- tesserocr
数据库的安装
- MySQL/MongoDB
- Redis
Python存储库的安装
Web库的安装
- Flask
- Tornado
APP爬取相关库的安装
- Charles
- mitmproxy
- Appium
爬虫框架的安装
- pyspider
- Scrapy
- Scrapy-Splash
- Scrapy-Redis
部署相关库的安装
- Docker
- Scrapyd
- Scrapyd-Client
- Scrapyd API
- Scrapyrt
- Gerapy
爬虫的概念
模拟浏览器,发送请求,获取响应
爬虫的作用
数据采集,软件测试,12306抢票,网站上的投票,网络安全
爬虫的分类
分类方法
根据被爬网站的数量不同分为:
通用爬虫:目标没有上限,如搜索引擎。
聚焦爬虫:目标有上限,专门抓取一个网站数据。
根据是否以获取数据为目,将聚焦爬虫分为:
功能性爬虫
数据增量爬虫
根据url地址和对应的网页内容是否发送改变,将数据增量爬虫分为:
基于url地址变化、内容也随之变化的增量爬虫
url地址不变,内容变化的数据增量爬虫
爬虫的流程
服务器渲染:get
- 客户端输入网址后,请求服务器,
- 请求到服务器后会返回过来一个html包,
- 如果请求中携带参数,服务器将参数进行一些解析,
- 将有关于参数的内容进行排序,并写入html包内返回给客户端,
- 浏览器将包进行解析然后
客户端渲染:get-post
- 客户端输入网址后,请求服务器,服务器返回html骨架
- 客户端发送参数,服务器进行解析返回数据
- 客户端解析数据加载进入html包中
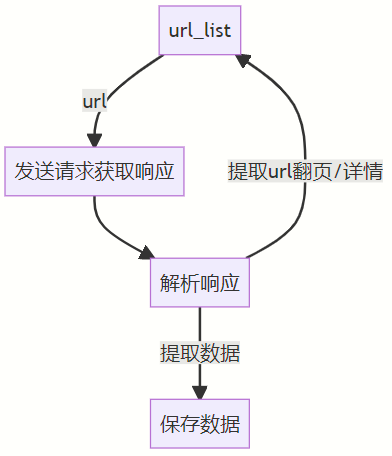
- 获取一个url
- 向url发送请求,并获取响应(需要http协议)
- 如果从响应当中提取url,则继续发送请求获取响应
- 如果从响应当中提取数据,则将数据进行保存
HTTP协议的复习
HTTP协议
-
请求:
- 请求行——请求方式(get/post)请求url地址 协议
- 请求头——一些服务器用到的附加信息
- 请求体——放一些请求参数
-
响应:
- 状态行——协议 状态码 200 404 502 302
- 响应头——放一些客户端要使用的一些附加信息
- 响应体——服务器返回的真正客户端要用的内容(HTML,json)等
-
反爬机制 (请求头的内容):
- User-Agent:请求载体的身份标识
- Referer:防盗链(这次请求是从那个页面过来的)
- Cookie:本地字符串数据信息(用户登录信息)
-
反爬机制 (响应头的内容):
- Cookie:本地字符穿数据信息(用户登录信息)
- 各种莫名其妙的字符串(这个需要经验,一般是token字样,防止攻击)
-
GET :查询方式用到的多,显示请求
-
POST :修改信息用的多,隐示请求
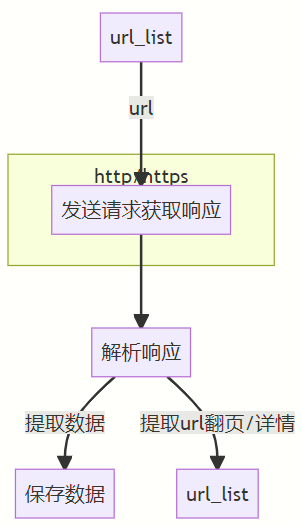
http及https的概念及区别
HTTP:超文本传输协议,默认端口80
HTTPS:HTTP+SSL(安全套接字层),默认端口443,SSL对传输的内容进行加密处理
常见的请求头
请求行
| 请求方法 | 空格 | URL | 空格 | 协议版本 | 回车符 | 换行符 |
|---|
请求头
| 头部字段名 | : | 值 | 回车符 | 换行符 |
|---|---|---|---|---|
| 头部字段名 | : | 值 | 回车符 | 换行符 |
| 回车符 | 换行符 |
请求数据
| 1 | 1 | 1 | 1 | 1 |
|---|
请求头
Content-Type
Host:主机和端口号
Connection:链接类型
Upgrade-Insecure-Requests:升级为HTTPS请求
User-Agent:浏览器名称
Referer:页面跳转处
Cookie:Cookie
Authorization:用于表示HTTP协议中需要认证资源的认证信息
爬虫常用的请求头
User-Agent:浏览器名称
Referer:页面跳转处
Cookie:Cookie
爬虫常用的响应头
Set-Cookie:对方服务器设置cookie到用户浏览器的缓存
常见的状态码
200:成功
302:跳转
303:post请求重定向
307:get请求重回定向
403:资源不可用,非法请求没有权限
404:找不到页面,请求地址有问题
500:服务器内部错误
503:服务器负载过重未能答复,爬虫访问请求频繁
所有的状态码都不可信,一切以是否抓包得到的响应中获取到数据为准
network中得到的源码才是判断依据,elements中的源码是渲染之后的源码不能作为判断依据
浏览器的运行过程
客户机使用域名请求dns服务器获取ip,使用ip请求web服务器获取数据。
第一个请求一般是html的静态页面,静态页面中有其他资源,再进行后续的请求访问。
爬虫的运行过程
爬虫只会发送一次请求,不会有initiator,爬虫也不具备有渲染能力,爬虫获取的只有数据。
爬虫需要获取:
- 骨骼文件:html静态页面
- 肌肉文件:js/ajax请求
- 皮肤文件:css/font/图片
抓包过程
根据发送请求的流程分别在 骨骼 / 肌肉 / 皮肤 响应中查找数据
urllib
import urllib.request,urllib.parse
# get请求
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode("utf-8"))
# post请求
data = bytes(urllib.parse.urlencode({"hello":"word"}),encoding="utf-8")
print(data)
response = urllib.request.urlopen("http://httpbin.org/post",data=data)
print(response.read().decode("utf-8"))
# 超时请求
try:
response = urllib.request.urlopen("http://www.baidu.com",timeout=0.01)
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("time out!")
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode("utf-8"))
url = "http://httpbin.org/post"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
}
data = bytes(urllib.parse.urlencode({"name":"eric"}),encoding='utf-8')
req = urllib.request.Request(url=url,data=data,headers=headers,method='POST')
resource = urllib.request.urlopen(req)
print(resource.read().decode("utf-8"))
url = "http://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"s
}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
requests
requests进阶
防盗链
代理
异步(多线程,多进程,协程)
线程(执行单位) 进程(资源单位)
一个简单的请求
# 消除警告
from requests import urllib3
urllib3.disable_warnings() #消除警告信息
import requests
url = "https://www.baidu.com"
response = requests.get(url)
print(response.text)
字符不匹配进行的操作
import requests
url = "https://www.baidu.com"
response = requests.get(url)
print(response.encoding) # 探查使用的encoding格式
response.encoding = 'utf8' # 设置转换
print(response.text)
response.content
import requests
url = "https://www.baidu.com"
response = requests.get(url)
print(response.encoding) # 探查使用的encoding格式
response.encoding = 'utf8' # 设置转换
print(response.text)
print(response.content) # 打印bytes类型的响应源码,可以进行一个decode操作
#保存图片
response = requests.get("https://github.com/favicon.ico")
with open('favicon.ico','wb') as f:
f.write(response.content)
f.close()
使用resoinse.content进行decode来解决乱码问题
import requests
url = "https://www.baidu.com"
response = requests.get(url)
print(response.content.decode('GBK'))
常见的响应对象参数和方法
import requests
url = "https://www.baidu.com"
response = requests.get(url)
print(response.url) # 响应url
print(response.status_code) # 状态码
print(response.request.headers) # 响应对象的请求头 # 重要数据 'User-Agent': 'python-requests/2.29.0'
print(response.headers) # 响应头 # 重要数据 'Set-Cookie': 'BDORZ=27315'
print(response.request._cookies) # 打印请求携带的cookie
print(response.cookies) # 答应响应设置cookies
发送带有参数的请求
要先找到关键参数
# 1.使用url直接携带参数
import requests
url = "https://www.baidu.com/s?wd=python"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
with open('baidu.html','wb') as f:
f.write(response.content)
# 2.使用params参数 ,构建参数字典,发送请求的时候设置参数字典
import requests
url = "https://www.baidu.com/s?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
data = {'wd':'python'}
response = requests.get(url=url,headers=headers,params=data)
with open('baidu.html','wb') as f:
f.write(response.content)
带cookie的请求
# 通过headers携带cookie
import requests
url = "https://www.baidu.com/s?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'Cookie':'asdasdsadasdas'
}
response = requests.get(url=url,headers=headers)
with open('baidu.html','wb') as f:
f.write(response.content)
# 构建cookie字典进行匹配
import requests
url = "https://www.baidu.com/s?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
}
temp = 'cookiekey=cookeivalue;cookiekey1=cookeivalue1;cookiekey2=cookeivalue2;cookiekey3=cookeivalue3;cookiekey4=cookeivalue4;'
cookie_list = temp.split("; ")
# 构建cookie字典
cookies = {key: value for key,value in zip(cookie_list.split('='))}
response = requests.get(url=url,headers=headers,cookies=cookies)
with open('baidu.html','wb') as f:
f.write(response.content)
# cookiejar对象转换为cookie
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(response.cookies)
dict_cookie = requests.utils.dict_from_cookiejar(response.cookies)
print(dict_cookie)
# 会丢失对那个域名
jar_cookie = requests.utils.cookiejar_from_dict(dict_cookie)
print(jar_cookie)
设置超时
import requests
url = 'http://twitter.com'
response = requests.get(url, timeout=3)
设置代理服务器
代理是什么
- 代理ip是一个ip,指向的是一个代理服务器
- 代理服务器能够帮助我们向目标服务器转发请求
代理分类(功能上的分类)
- 正向代理:类似邮差,代理发送,例如VPN
- 反向代理:服务器不知道将数据发送给谁了,例如nginx
代理IP分类(根据匿名强度)
- 透明代理:服务器可以通过代理找到本机
- 匿名代理:服务器知道是代理服务器发送的请求,但不能找到服务器
- 高匿代理:服务器不知道是不是代理服务器
根据协议分类
- http代理
- https代理
- socks隧道代理
#透明代理设置
REMOTE_ADDE = Proxy IP
HTTP_VIA = Proxy IP
HTTP_x_FORWARDED_FOR = Your IP
#匿名代理设置
REMOTE_ADDE = Proxy IP
HTTP_VIA = Proxy IP
HTTP_x_FORWARDED_FOR = Proxy IP
#高匿代理设置
REMOTE_ADDE = Proxy IP
HTTP_VIA = not determined
HTTP_x_FORWARDED_FOR = not determined
使用verify参数忽略CA证书
import requests
url = 'https://sam.huat.edu.cn:8443/selfservice'
# 开启忽略
requests.get(url,verify=False)
requests模块发送post请求
post数据来源
- 固定值 抓包比较不变值
- 输入值 抓包根据自身变化值
- 预设值-静态文件 需要提前从静态html中获取(正则)
- 预设值-请求获取 需要对指定地址发送请求获取数据
- 预设值-客户端生成 分析js模拟生成数据
import requests
import json
import sys
# 文件上传
# files = {'file':open('favicon.ico','rb')}
# response = requests.post("https://httpbin.org/post",files=files)
# print(response.text)
class King(object):
def __init__(self,word) -> None:
# 初始参数
# 起始的url,headers
self.url = 'http://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_web_fanyi&sign=85169a3e7ba1ca16'
self.headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
self.data = {
'from': 'zh',
'to': 'en',
'q': word,
}
def get_data(self):
response = requests.post(self.url, data=self.data, headers=self.headers)
return response.content
def parse_data(self,data):
# loads将json字符串转换成python字典
dict_data = json.loads(data)
try:
# 中文
print(dict_data['content']['out'])
except:
# 英文
print(dict_data['content']['word_mean'][0])
def run(self):
# 编写爬虫逻辑
# 发送请求获取响应
response = self.get_data()
# 数据解析
self.parse_data(response)
if __name__ == "__main__":
# 运行程序输入
# word = input('请输入要翻译的单词和句子:')
# 命令运行
word = sys.argv[1]
king = King(word)
king.run()
利用requests.session进行状态保持
作用:自动处理cookie
场景:连续多次请求
import requests
import re
def loggin():
# session对象
session = requests.session()
# headers
session.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
# url1获取token
url1 = r'https://gitee.com/login?redirect_to_url=%2F'
# 发送请求获取响应
res_1 = session.get(url1).content.decode()
# 正则提取token
token = re.findall(r'<meta name="csrf-token" content="(.*?)" />',res_1)[0]
print(token)
# url2登录
url2 = 'https://github.com/session'
# 构建表单数据
data = {
'encrypt_key': 'password',
'utf8': '✓',
'authenticity_token': token,
'redirect_to_url': '/',
'user[login]': '17538920323',
'encrypt_data[user[password]]': 'CAP+OG6DCnwpuiyIuMADgWIvP8XBjEUOjYfNX3G5z3BTMoC6158WE9xRg9Ybf8nK6PKyG+xY6fZkNxTRA4IqCSbWXW6X0mi9XgXoJFsZoXW2JSmWrfHRLfeyYgZ2rOQoUvKRHbdrsyokCJ1oh0NoTMDrGu6Eh/aDxPd0knmpWqQ=',
'user[remember_me]': '0',
}
print(data)
# 发送请求登录
session.post(url2,data=data)
# url3验证
url3 = 'https://gitee.com/ELMEight'
response = session.get(url3)
with open('gitee.html','wb') as f:
f.write(response.content)
if __name__ == "__main__":
loggin()
DrissionPage
selenium模拟浏览器操作
大幅度降低爬虫编写能力,但是性能也降低了,在迫不得已不会使用。
安装selenium和chromedriver
selenium支持直接调用浏览器,包括PhantomJS这些无界面浏览器
找到浏览器的版本,记住前三位113.0.5672.xxx
访问镜像网站下载chromedriver
解压然后放置在python.exe同文件内,如果是conda就放在conda.exe同文件内
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
print(driver.title)
driver.quit()
selenium工作原理
利用浏览器的原生API,封装成一套更加面向对象的selenium webdriver api,直接操作浏览器页面的元素,甚至操作浏览器本身。
webdriver本质上是一个web-server,对外提供webapi,其中封装了浏览器的各种功能。
不同的浏览器需要不同的webdriver
import time
from selenium import webdriver
# 创建浏览器对象
driver = webdriver.Chrome()
# git访问页面
driver.get('https://www.baidu.com/')
# 元素的定位使用id,输入python
driver.find_element_by_id('kw').send_keys('python')
# 点击
driver.find_element_by_id('su').click()
# 停止6s
time.sleep(6)
# 退出浏览器
driver.quit()
driver对象的常用属性和方法
driver.page_source 当前标签页面浏览器渲染之后的网页源代码
driver.curent_url 当前标签页url
driver.close() 关闭当前标签页,如果只要一个标签页则关闭浏览器
driver.quit() 关闭浏览器
driver.forward() 页面前进
driver.back() 页面后退
driver.screen_shot(img_name) 页面截图
driver对象定位标签元素获取标签对象的方法
find_element_by_id 返回一个元素
find_element(s)_by_class_name 根据类名获取元素列表
find_element(s)_by_name 根据标签的name属性返回包含标签对象元素的列表
find_element(s)_by_xpath 返回一个包含元素的列表
find_element(s)_by_link_text 根据连接文本获取元素列表
find_element(s)_by_partial_link_text 根据链接包含的文本获取元素列表
find_element(s)_by_tag_name 根据标签名获取元素列表
find_element(s)_by_css_selector 根据css选择器来获取元素列表
没有s就返回匹配到的第一个标签对象,没有匹配到就报异常
有s就返回匹配的列表,没有匹配到就返回空列表
by_link_text全部文本和by_partial_link_text包含某个文本
使用方法driver.find_element_by_id('str')
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url)
# driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python3')
# driver.find_element_by_css_selector('#kw').send_keys('python3')
# driver.find_element_by_name('wd').send_keys('python3')
# driver.find_element_by_class_name('s_ipt').send_keys('python3')
# driver.find_element_by_id("su").click()
# driver.find_element_by_link_text("新闻").click()
# driver.find_element_by_partial_link_text("新").click()
# 唯一标签中,或者多标签中的第一个时使用
print(driver.find_element_by_tag_name("title"))
driver.find_element_by_css_selector
driver.quit()
标签对象提取文本内容和属性值
element.text 获取文本
element.get_attribute("属性名") 获取属性值
element.click() 点击操作
element.clear() 清空文本
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url)
el_list = driver.find_elements_by_xpath('//*[@id="hotsearch-content-wrapper"]/li')
for el in el_list:
print(el.text, el.get_attribute('href'))
# element.send_keys(data) 输入操作
# element.clear() 清空文本
selenium的其他使用方法
selenium标签页面切换
- 获取所有页面的窗口句柄
- 利用窗口句柄字切换到句柄指向的标签页
- 具体方法
current_windows = driver.window_handles
driver.switch_to.windows(current_windows[0])
- 示例
from selenium import webdriver
url = 'https://jn.58.com/'
driver = webdriver.Chrome()
driver.get(url)
# 定位操作元素
el = driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[2]/a')
el.click()
# 切换操作页面
driver.switch_to.window(driver.window_handles[-1])
# 定位操作元素
el_list = driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
print(el_list)
driver.close()
switch_to切换frame标签
使用id值进行定位跳转
driver.switch_to.frame('login_frame')
先定位后跳转
el_frame = driver.find_element_by_xpath('//*[@id="login_frame"]')
driver.switch_to.frame(el_frame)
from selenium import webdriver
url = 'https://qzone.qq.com/'
driver = webdriver.Chrome()
driver.get(url)
# 切换到页面的框架中
# driver.switch_to.frame('login_frame')
# 首先使用元素定位
el_frame = driver.find_element_by_xpath('//*[@id="login_frame"]')
driver.switch_to.frame(el_frame)
# 定位操作元素
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').send_keys('123456789')
driver.find_element_by_id('p').send_keys('abcdefghigk')
driver.find_element_by_id('login_button').click()
driver.close()
selenium对cookie的处理
driver.cookies() 获取cookie
driver.delete_cookie("CookieName") 删除一条cookie
driver.delete_all_cookie() 删除全部的cookie
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url)
cookie = {}
cookie_dict = {cookie['name'] : cookie['value'] for cookie in driver.get_cookies()}
print(cookie_dict)
driver.close()
selenium控制浏览器执行js代码
driver.execute_script(js) 执行js代码
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url)
# 滚动条的拖动scrollTo(x,y)
js = 'scrollTo(0,100)'
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 执行js
driver.execute_script(js)
页面等待
-
强制等待
- 不智能
time.sleep() -
隐式等待
- 针对元素定位,隐式等待设置一个时间,在一段时间内判定元素定位是否成功,成功就进行下一步,不成功就报超时。
from selenium import webdriver url = 'http://www.baidu.com' driver = webdriver.Chrome() # 设置之后的的所有位置定位操作都有最大十秒的等待时间 driver.implicitly_wait(10) driver.get(url) driver.find_element_by_xpath('//*[@id="s_lg_im"]') driver.close() -
显式等待
- 明确等待某一个元素,只等待一个元素,时间内等待到元素,没有等待到报错,每0.5秒尝试一次
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By url = 'http://www.baidu.com' driver = webdriver.Chrome() driver.get(url) # 显式等待,等待时间20秒,每0.5秒检查一次,检查到就向下执行,检查不到就等待,超时报错 WebDriverWait(driver,20,0.5).until(EC.presence_of_element_located((By.LINK_TEXT,'hao123'))) print(driver.find_element_by_link_text('hao123').get_attribute('href')) driver.quit()
无头浏览器
开启Chrome浏览器无界面模式
实例化对象 options = webdriver.ChromeOptions()
配置对象添加开启无界面模式的命令 options.add_argument("--headless")
配置对象添加禁用gpu的命令 options.add_argument("--disable-gpu")
实例化带有配置对象的driver对象 driver = webdriver.Chrome(chrome_options=options)
from selenium import webdriver
url = 'http://www.baidu.com'
# 创建一个配置对象
opt = webdriver.ChromeOptions()
# 添加配置参数
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
# 创建浏览器对象的时候添加配置对象
driver = webdriver.Chrome(chrome_options=opt)
driver.get(url)
driver.save_screenshot('baidu_daociyiyou.png')
selenium使用代理ip
实例化配置对象 options = webdriver.ChromeOptions()
配置对象添加使用代理ip的命令 options.add_argument('--proxy-server=http://202.20.16.82:9527')
实例化带有配置对象的driver对象 driver = webdriver.Chrome(chrome_options=options)
from selenium import webdriver
url = 'http://www.baidu.com'
# 创建一个配置对象
opt = webdriver.ChromeOptions()
# 添加配置参数
opt.add_argument('--proxy-server=http://202.20.16.82:9527')
# 设置用户代理,user-agent
opt.add_argument('--user-agent=Mozilla/5.0 python37')
# 创建浏览器对象的时候添加配置对象
driver = webdriver.Chrome(chrome_options=opt)
driver.get(url)
示例
from selenium import webdriver
import time
class Douyu(object):
def __init__(self) -> None:
self.url = 'https://www.douyu.com/directory/all'
self.driver = webdriver.Chrome()
def parse_data(self):
time.sleep(1)
room_list = self.driver.find_elements_by_xpath('//*[@id="listAll"]/section[2]/div[2]/ul/li/div')
# 遍历房间列表从每一个房间中获取数据
data_list = []
for room in room_list:
temp = {}
temp['title'] = room.find_element_by_xpath('./a/div[2]/div[1]/h3').text
temp['type'] = room.find_element_by_xpath('./a/div[2]/div[1]/span').text
temp['owner'] = room.find_element_by_xpath('./a/div[2]/div[2]/h2').text
temp['num'] = room.find_element_by_xpath('./a/div[2]/div[2]/span').text
# 需要翻页
# temp['img'] = room.find_element_by_xpath('./a/div[1]/div[1]/picture/img').get_attribute('src')
data_list.append(temp)
return data_list
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
# url
# driver
# get
self.driver.get(self.url)
while True:
# parse
data_list=self.parse_data()
# save
self.save_data(data_list)
# next
try:
el_next = self.driver.find_element_by_xpath('//*[contains(text(),"下一页")]')
self.driver.execute_script('scrollTo(0,10000)')
el_next.click()
except Exception as e:
print(e)
break
if __name__ == "__main__":
douyu = Douyu()
douyu.run()
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
web = Chrome()
web.get("https://lagou.com")
time.sleep(2)
# 找到某个元素,点击他
el = web.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a')
el.click()
# 找到输入框输入信息 => 输入回车/点击搜索按钮
web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python", Keys.ENTER)
time.sleep(2)
# 查找存放数据的位置,进行数据提取
li_list = web.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li')
for li in li_list:
job_name = li.find_element_by_tag_name('h3').text
job_price = li.find_element_by_xpath('./div[1]/div[1]/div[2]/div/span').text
print(job_price, job_name)
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
web = Chrome()
web.get('http://lagou.com')
time.sleep(1)
web.find_element_by_xpath('//*[@id="cboxClose"]').click()
time.sleep(1)
web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python", Keys.ENTER)
time.sleep(1)
# 在selenium眼中,新窗口默认切换不过来
web.switch_to.window(web.window_handles[-1]) # 切换工作窗口
# 在新窗口中提取内容
job_detail = web.find_element_by_xpath('').text
print(job_detail)
web.close() # 关闭子窗口
# 切换到原来窗口视角
web.switch_to.window(web.window_handles[0])
数据解析
结构化数据
json数据(多数)
只需要获得url并进行访问即可,可以使用json模块,re模块,jsonpath模块进行数据提取
xml数据(少数)
和html类似
re模块,lxml模块,xml标签可以自定义,xml更倾向于数据传输存储,xml树形结构
非结构化数据
html数据
不能用统一的格式解析数据,re模块,lxml模块
html标签固定,html更倾向于数据的显示
常用数据解析方法
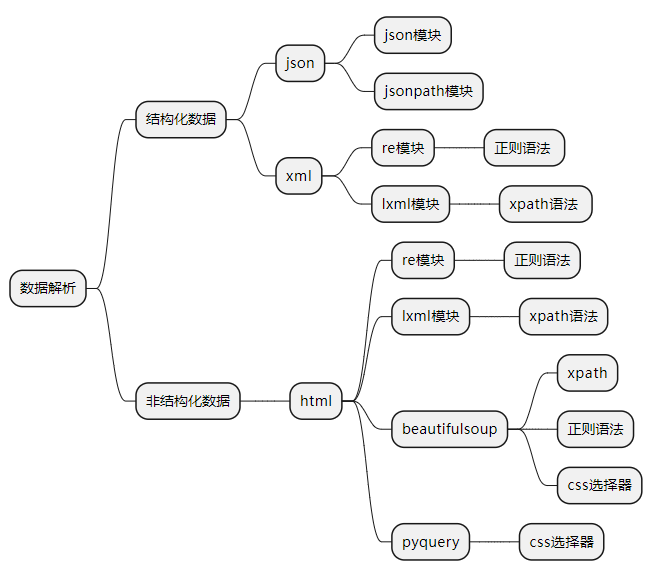
jsonpath
使用场景
多层嵌套的复杂字典中直接提取数据
安装
# 原生sql语句操作
sql = 'select * from user'
result = db.session.execute(sql)
# 查询全部
User.query.all()
# 主键查询
User.query.get(1)
# 条件查询
User.query.filter_by(User.username='name')
# 多条件查询
from sqlalchemy import and_
User.query.filter_by(and_(User.username =='name',User.password=='passwd'))
# 比较查询
User.query.filter(User.id.__lt__(5)) # 小于5
User.query.filter(User.id.__le__(5)) # 小于等于5
User.query.filter(User.id.__gt__(5)) # 大于5
User.query.filter(User.id.__ge__(5)) # 大于等于5
# in查询
User.query.filter(User.username.in_('A','B','C','D'))
# 排序
User.query.order_by('age') # 按年龄排序,默认升序,在前面加-号为降序'-age'
# 限制查询
User.query.filter(age=18).offset(2).limit(3) # 跳过二条开始查询,限制输出3条
# 增加
use = User(id,username,password)
db.session.add(use)
db.session.commit()
# 删除
User.query.filter_by(User.username='name').delete()
# 修改
User.query.filter_by(User.username='name').update({'password':'newdata'})
使用
from jsonpath import jsonpath
ret = jsonpath(a,'jsonpath语法规则字符串')
#结果为列表,获取数据需要索引
jsonpath语法规则
| JSONPath | 描述 |
|---|---|
| $ | 根节点 |
| @ | 现行节点 |
| . or [] | 取子节点 |
| n/a | 取父节点 |
| .. | 不关心位置选择所有符合条件的内容 |
| * | 匹配所有元素节点 |
| n/a | 根据属性访问,json不支持 |
| [] | 迭代器标识(可以进行简单的迭代操作) |
| [,] | 支持迭代器中做多选 |
| ?() | 支持过滤操作 |
| () | 表达式计算 |
| n/a | 分组,jsonpath不支持 |
常用语法
$ 根节点,最外层的大括号
. 子节点
.. 内部任意位置,子孙节点
from jsonpath import jsonpath
# 数据
data = {'key1':{'key2':{'key3':{'key4':{'key5':{'key6':'python'}}}}}}
# 第一种方式
ret = jsonpath(data,'$.key1.key2.key3.key4.key5.key6')
# 第二种方式
ret = jsonpath(data,'$..key6')
print(ret)
示例
from jsonpath import jsonpath
import json
book_dict = {"store":{"book":[{"category":"reference","author":"Nigel Rees","title":"Saying of the Century","price":8.95,},{"category":"fiction","author":"Evelyn Waugh","title":"Sword of Honour","price":12.99,},{"category":"fiction","author":"Herman Melville","title":"Moby Dick","isbn":"0-553-21311-3","price":8.99,},{"category":"fiction","author":"J. R. R. Tolkien","title":"The Lord of the Rings","isbn":"0-395-19395-8","price":22.99,}],"bicycle":{"color":"red","price":19.95}}}
data = json.dumps(book_dict)
data = json.loads(data)
print(jsonpath(data,"$..color"))
import jsonpath
import requests
import json
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}
response = requests.get('https://www.lagou.com/lbs/getAllCitySearchLabels.json', headers=headers)
dict_data = json.loads(response.content)
print(jsonpath.jsonpath(dict_data,'$..name'))
re解析
正则表达式
限定符
x* # x出现0次或多次
x+ # x出现1次或多次
x? # x出现0次或1次
x{5} # x出现6次
x{2,5} # x出现2-6次
x{2,} # x出现2次以上
或运算符
(x|y) # 匹配x或b
(xy)|(gy) # 匹配xy或gy
字符类
[abc] # 匹配a或b或c
[a-c] # 匹配a或b或c
[a-zA-Z0-9] # 匹配小写字母或大写字母或数字
[^0-9] # 匹配非数字字符
元字符
\d # 匹配数字字符
\D # 匹配非数字字符
\w # 匹配单词字符(字母、数字、下划线)
\W # 匹配非单词字符
\s # 匹配空白字符(空格、换行符、制表符)
\S # 匹配非空白字符
. # 匹配任意字符(换行符除外)
\b # 标注字符边界
^ # 匹配行首
$ # 匹配行尾
贪婪匹配、懒惰匹配
.+ # 贪婪匹配任意字符(换行符除外)
.+? # 懒惰匹配任意字符(换行符除外)
如果需要匹配特殊字符,需要加反斜线进行转义。
re模块
在编程语言中使用正则,如果正则表达式中出现了小括号,编程语言会把小括号视为匹配边界,
也就是说它会把小括号里面的内容视为一个group,这个group才是编程语言眼里的正则表达式,
在Python里面的解决方法是在小括号内的最前面加上?:,这样可以申明这个小括号不是一个group
import re
re.findall('.+','字符串',flags=re.S) # 匹配所有符合条件的值,返回列表
re.search() # 查找符合规则的字符,只返回第一个,且返回Match对象,匹配失败返回None
re.finditer() # 返回一个迭代器,迭代器里面是所有符合规则的Match对象
re.match() # 和search一样,返回Match对象,但要求必须从字符串开头匹配,匹配失败返回
None
re.fullmatch() # 从头匹配到尾,进行匹配的字符串整体需要符合正则表达式,匹配成功返回Match对
象,匹配失败返回None
re.sub() # 替换匹配的字符串,返回替换完成的文本
re.subn() # 替换匹配的字符串,返回替换完成的文本和替换的次数
re.split() # 用正则表达式的字符串做分隔符,分割原字符串,返回列表
re.compile() # 创建正则表达式对象,方便后面使用
flags参数:
re.I 不区分大小写
re.M 让^匹配每一行的开头
re.S #让.匹配所有字符(包括换行符)
注:re下的所有方法,都可以传flags参数,如果想要同时使用多个flags参数,可以使用|进行分割,如:
flags=re.I | re.M
使用
import re
# findall: 匹配字符串中所有的符合正则的内容,以列表形式返回
lst = re.findall(r"\d+", "我的电话号是10086,其他人的电话是:10010")
print(lst)
# finditer: 匹配字符串中所有的内容,以迭代器的形式返回
it = re.finditer(r"\d+", "我的电话号是10086,其他人的电话是:10010")
print(it)
for i in it: # 从迭代器中取出内容
print(i.group())
# search: 全文匹配,返回的结果是match对象,拿数据要用.group(),特点找到一个结果就返回
s = re.search(r"\d+", "我的电话号是10086,其他人的电话是:10010")
print(s.group())
# match: 从头开始匹配,剩余同search一样
s = re.match(r"\d+", "10086,其他人的电话是:10010")
print(s.group())
# 预加载正则表达式
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号是10086,其他人的电话是:10010")
for i in ret:
print(i.group())
ret = obj.findall("我的电话号是10086,其他人的电话是:10010")
print(ret)
# 示例
s = '''<div class='jav'><span id = '1'>郭麒麟</span></div><div class='jj'><span id = '2'>sb</span></div><div class='jolin'><span id = '3'>大草莓</span></div><div class='sylar'><span id = '4'>fys</span></div><div class='tory'><span id = '5'>alsf</span></div>'''
obj = re.compile(r"<div class='.*?'><span id = '(?P<id>.*?)'>(?P<wahaha>.*?)</span></div>", re.S)
# re.S,占用的是flags的参数符号。S表示.符号能匹配换行符
# (?P<name>) 的作用是给被括住的正则表达式进行命名
result = obj.finditer(s)
for it in result:
print(it.group('wahaha'))
lxml
lxml模块可以利用XPath规则语法,来快速定位HTML/XML文档中特定元素以及获取节点信息(文本内容,属性值)
xpath helper插件
xpath_helper.crx提取码: vp58
xpath语法
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素 |
| / | 从根节点选取、或者是元素和元素间的过度 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
常用语法
节点选择语法
/html 从父节点寻找
/html/head/title 绝对路径
//title 从文档中寻找
//title/text() 从文档中找打标签获取标签内的text
//link/@href 抽取属性,抽取连接
节点修饰语法
| 路径表达式 | 结果 |
|---|---|
| //title[@lang="eng"] | 选择lang属性为eng的所有title元素 |
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] | 选取bookstore子元素的最后一个book元素 |
| /bookstore/book[last()-1] | 选取bookstore子元素的倒数第二个book元素 |
| /bookstore/book[position()>1] | 选择bookstore下面的book元素,从第二个开始选取 |
| //book/title[text()='Harry Potter'] | 选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
| /bookstore/book[price>35.00]/title | 选取bookstore元素中的book元素的所有title元素,且其中的pruce元素的值必须大于35.00 |
通过索引修饰节点 //li[position()>1]/div[1]
通过属性值修饰节点 //ul[@id="thread_list"]/li[position()>1]/div[1]
通过子节点的值修饰 //div[span[2]>=9.6]/../..//a/span[1]
通过包含修饰 //ul[contains(@id,'thread_list')]/li[3] || //ul[contains(text(),'天王盖地虎')]/li[3]
通配语法
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
复合使用语法 //td | //ul/li[3]
示例
from lxml import etree
text = '''
<div>
<ul>
<li class="item-1">
<a href="link1.html">first item</a>
</li>
<li class="item-1">
<a href="link2.html">second item</a>
</li>
<li class="item-inactive">
<a href="link3.html">third item</a>
</li>
<li class="item-1">
<a href="link4.html">fourth item</a>
</li>
<li class="item-0">
<a href="link5.html">fifth item</a>
</ul>
</div>
'''
# 创建element对象
# html = etree.HTML(response.content)
html = etree.HTML(text)
# 输出查看数据格式
# print(html)
# 定位提取
# print(html.xpath('//a[@href="link2.html"]/text()'))
# 列表提取
# text_list = html.xpath("//a/text()")
# link_list = html.xpath("//a/@href")
# 打印列表
# print(text_list)
# print(link_list)
# 对标打印
# for text in text_list:
# myindex = text_list.index(text)
# link = link_list[myindex]
# print(text,link)
# zip对标打印
# for text,link in zip(text_list,link_list):
# print(text,link)
# 更简短的方法
el_list = html.xpath("//a")
for el in el_list:
print(el.xpath("./text()"))
print(el.xpath("./@href"))
# tostring用法
handeled_html_str = etree.tostring(html).decode()
# 会补全语法错误,只会补全添加缺失的标签
print(handeled_html_str)
import requests
from lxml import etree
class Tieba(object):
def __init__(self,name) -> None:
self.url = 'https://tieba.baidu.com/f?ie=utf-8&kw={}'.format(name) # %E6%9D%8E%E6%AF%85%E5%90%A7
self.hearders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
# 低端请求头
# self.hearders = {'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.01;Windows NT 5.0)'}
def get_data(self,url):
response = requests.get(url,headers=self.hearders)
return response.content
def parse_data(self,data):
# 创建element对象
data = data.decode().replace("<!--","").replace("-->","")
html = etree.HTML(data)
el_list = html.xpath('//li[@class=" j_thread_list clearfix thread_item_box"]/div/div[2]/div[1]/div[1]/a')
# print(len(el_list))
data_list = []
for el in el_list:
temp = {}
temp['title'] = el.xpath("./text()")[0]
temp['link'] = 'http://tieba.baidu.com' + el.xpath("./@href")[0]
data_list.append(temp)
# 获取下一页url
try:
next_url = 'https:' + html.xpath('//a[contains(text(),"下一页>")]/@href')[0]
except:
next_url = None
return data_list,next_url
def save_date(Self, data_list):
for data in data_list:
print(data)
def run(self):
# url
# headers
next_url = self.url
while True:
# 发送请求,获取响应
data=self.get_data(next_url)
# 从响应中提取数据(数据和翻页用的url)
data_list, next_url = self.parse_data(data)
self.save_date(data_list)
print(next_url)
# 判断是否终结
if next_url == None:
break
if __name__ == "__main__":
tieba = Tieba('传智播客')
tieba.run()
bs4解析(过时)
html语法
html = '''<html> <head> <title>The Dormouse's story</title></head><body><p class="title" name="dromouse"><b>The Dormouse's story</b></p><p class ="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class= ="sister" id="link1"><!-- Elsie - -> </a>,<a href="http://example.com/lacie" class="sister" id="link2">L acie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,features='lxml')
print(soup.prettify())
print(soup.title.string) #得到title标签的内容
#选择元素
#如有多个,返回选择的第一个内容
soup = BeautifulSoup(html,'lxml')
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
#获取名称
soup = BeautifulSoup(html,'lxml')
print(soup.title.name)
#获取属性
soup = BeautifulSoup(html,'lxml')
print(soup.p.attrs['name'])
print(soup.p['name'])
#获取内容
soup = BeautifulSoup(html,'lxml')
print(soup.p.string)
#嵌套选择
soup = BeautifulSoup(html,'lxml')
print(soup.head.title.string)
#子节点和子孙节点
soup = BeautifulSoup(html,'lxml')
print(soup.p.contents)
soup = BeautifulSoup(html,'lxml')
print(soup.p.children) #children 迭代器
for i,child in enumerate(soup.p.children):
print(i,child)
soup = BeautifulSoup(html,'lxml')
print(soup.p.descendants) # descendant获取子孙节点
for i,child in enumerate(soup.p.descendants):
print(i,child)
#父节点和祖先节点
soup = BeautifulSoup(html,'lxml')
print(soup.a.parent)
soup = BeautifulSoup(html,'lxml')
print(list(enumerate(soup.a.parent)))
#兄弟节点
soup = BeautifulSoup(html,'lxml')
print(list(enumerate(soup.a.next_siblings)))
print(list(enumerate(soup.a.previous_siblings)))
html = '''<div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2" name="element"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div></div>'''
#标准选择器
# #可根据标签名,属性,内容查找文档
find_all(name,attrs,recursive,text,**kwargs)
#name
soup = BeautifulSoup(html,'lxml')
# print(soup.find_all('ul'))
# print(type(soup.find_all('ul')[0]))
for ul in soup.find_all('ul'):
print(ul.find_all('li'))
#attrs
soup = BeautifulSoup(html,'lxml')
# print(soup.find_all(attrs={'id':'list-1'}))
# print(soup.find_all(attrs={'name':'element'}))
print(soup.find_all(id = 'list-1'))
print(soup.find_all(class_ = 'element'))
#text
soup = BeautifulSoup(html,'lxml')
print(soup.find_all(text='Foo'))
#find()
#find()返回单个元素 find_all()返回所有元素
soup = BeautifulSoup(html,'lxml')
print(soup.find('ul'))
print(type(soup.find('ul')))
print(soup.find('page'))
#find_parents()返回所有祖先节点,find_parent()返回直接父节点
find_parents() find_parent
#返回后面所有兄弟节点 返回后面第一个兄弟节点
find_next_siblings() find_next_sibling()
#返回前面所有兄弟节点 返回前面第一个兄弟节点
find_previous_siblings() find_previous_sibling()
#返回节点后所有符合条件的节点 返回第一个符合条件的节点
find_all_next() find_next()
#返回节点后所有符合条件的节点 返回第一个符合条件的节点
find_all_previous() find_previous()
#css选择器
#通过select()直接传入css选择器即可完成选择
soup = BeautifulSoup(html,'lxml')
print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-1 .element'))
print(type(soup.select('ul')[0]))
soup = BeautifulSoup(html,'lxml')
for ul in soup.select('ul'):
print(ul.select('li'))
#获取属性
soup = BeautifulSoup(html,'lxml')
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])
#获取内容
soup = BeautifulSoup(html,'lxml')
for li in soup.select('li'):
print(li.get_text())
反爬
为什么要反爬
- 爬虫站总PV(PV指页面的访问次数)(尤其是指三月份爬虫)
- 公司可免费的资源被批量抓走,丧失竞争力,少赚钱
- 状告爬虫成功的几率小,灰色地带
服务器常反那些爬虫
十分低级的应届毕业生,性能太高
十分低级的创业小公司,不断爬取
失控的小爬虫
成型的商业对手
抽风的搜索引擎
常见概念
爬虫:使用任何技术手段,批量的获取网站信息的一种方式
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式
误伤:在反爬过程中,错误的将正常用户识别为爬虫。误伤率高的反爬策略,效果也不好
拦截:成功的阻止爬虫访问。通常来讲拦截效率越高的反爬虫策略,误伤的可能性越大
资源:机器成本与人力成本的总和
反爬的三个方向
- 基于身份识别进行反爬
- 基于爬虫行为进行反爬
- 基于数据加密进行反爬
常见基于身份识别进行反爬
通过headers字段进行反爬
- 通过headers中的user-agent字段来反爬
- 通过referer字段或者是其他字段来反爬
- 通过cookie来反爬
通过请求参数来反爬
-
通过从html静态文件中获取请求数据(github登录数据)
- 仔细分析抓包得到的每一个包,搞清楚请求之间的联系
-
通过发送请求获取请求数据
- 仔细分析抓包得到的每一个包,搞清楚请求之间的联系,搞清楚请求参数的来源
-
通过js生成请求参数
- 分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
-
通过验证码来反爬
- 打码平台或者是机器学习的方式识别验证码,其中打码平台廉价易用
常见基于爬虫行为进行反爬
基于请求频率或总请求数量
-
通过请求ip/账号单位时间内总请求数量进行反爬
- 对应的通过购买高质量的ip的方式能够解决问题/购买多个账号
-
通过同一ip/账号请求之间的间隔进行反爬
- 请求之间进行随机等待,模拟真实用户操作,在添加事件间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号则账号之间设置随机休眠
-
通过对请求ip/账号每天请求次数设置阈值进行反爬
- 对应的通过购买高质量ip的方法/多账号,同时设置请求间随机休眠
根据爬取行为进行反爬,通常在爬取步骤上做分析
-
通过js实现跳转来反爬
- 多次抓包获取条状url,分析规律
-
通过蜜罐获取爬虫ip(或代理ip),进行反爬
- 完成爬虫的编写之后,使用代理批量爬取测试/仔细分析响应内容结构,找出页面中存在的陷阱
-
通过假数据反爬
- 长期运行,核对数据库中数据同实际页面中数据对应情况,如果存在问题/仔细分析响应内容
-
阻塞任务队列
- 观察运行过程中请求响应状态/仔细分析源码获取垃圾url生成规则,对url进行过滤
-
阻塞网络IO
- 观察爬虫运行状态/多线程对请求线程记时/发送请求
-
运维平台综合审计
- 仔细观察分析,长期运行测试目标网站,检查数据采集速度,多方面处理
常见基于数据加密进行反爬
对响应中含有的数据进行特殊化处理
-
通过自定义字体来反爬
- 切换到手机版/解析字体文件进行翻译
-
通过css来反爬
- 计算css的偏移
-
通过js 动态生成数据进行反爬
- 解析关键js,获得数据生成流程,模拟生成数据
-
通过数据图片化反爬
- 通过使用图片解析引擎从图片中解析数据
-
通过编码格式进行反爬
- 根据源码进行多格式解码,获得真正的解码格式
验证码处理
图片验证码
-
什么是图片验证码
- 验证码(captcha),全自动区分计算机和人类的图灵测试
-
验证码的作用
- 防止恶意破解密码,刷票,论坛灌水,刷页。
-
图片验证码在爬虫中使用的场景
- 登录,注册,频繁发送请求时,服务器弹出验证码进行验证
-
图片验证码的处理方案
- 手动输入,这种方法仅限于登录一次就可持续使用的情况
- 图像识别引擎解析,使用光学识别引擎处理图片中的数据,目前常用于图片数据提取,较少用于验证码处理
- 打码平台,爬虫常用识别验证码解决方案
图片识别引擎
OCR指使用扫描仪或数码相机对文本资料进行扫码成图像文件,然后对图像文件进行分析处理,自动识别获取文字信息及版面信息的软件
-
什么是tesseract
-
图片识别引擎环境安装
-
引擎安装
下载github上的exe安装包,安装完成后添加环境变量
-
python库安装
pip/pip3 install pillow pip/pip3 install pytesseract
-
-
图片识别引擎的使用
-
from PIL import Image import pytesseract im = Image.open() result = pytesseract.image_to_string(im) print(result)
-
-
图片识别引擎的使用扩展
打码平台
chrome浏览器的使用
-
新建隐身窗口
-
chrome中network的更多功能
- preserver log浏览器缓存
- ctrl+r,刷新,ctrl+e,停止,Filter,过滤
- 通过点击XHR,JS,CSS,Img,Media等进行分类,观察特定种类的包
-
寻找登录接口
- 寻找actions对应的url地址,发送post或者get请求
- 通过抓包寻找url地址
js解析
确定js的位置
查看获取的js文件,然后定位谁加密的js文件
- 通过initiator定位js文件
- 通过search搜索关键字定位到js文件
- 通过元素绑定的事件监听函数找到js文件
注释:三种方法不保证每一种都能找到js,要三种方法都进行定位
分析js代码,掌握加密步骤
精进js语法,多练习,静心
可以做断点进行解析
python模拟
-
通过第三方js加载模块,直接加载js运行
-
js2py是一个js的翻译工具,可以通过纯python实现js解释器
-
找到关键js,输入需要的参数,导入需要的函数文件,获取需要的数据
import js2py import requests # 创建js执行环境 context = js2py.EvalJs() # 加载js文件(要执行的js代码所需要的函数文件) headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0;Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36'} big_js = requests.get('http://s.xnimg.cn/a85738/wap/mobile/wechatLive/js/BigInt.js',headers=headers).content.decode() ## 加入文件 context.execute(big_js) # 执行语句 context.execute("setMaxDigits(130)") # 创建data context.n = {"class":"python21"}
-
-
pyv8
-
execjs
-
-
用python模块进行重现
import hashlib data = "python87" # 创建hash对象 md5 = hashlib.md5() # 向hash对象中添加需要做hash运算的字符串 md5.update(data.encode()) # 获取字符串的hash值 result = md5.hexdigest() print(result)
示例
import js2py
import requests
import json
def login():
# 创建session对象
session = requests.session()
# 设置请求头
session.headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0;Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36'}
# 发送获取公钥数据包的get请求
response = session.get('http://activity.renren.com/livecell/rKey')
print(response.content.decode('utf8'))
# 创建n
n = json.loads(response.content.decode('utf8'))['data']
# 创建t
t = {'password':'qweszdazxc'}
# 获取前置js代码
rsa_js = session.get('http://s.xnimg.cn/a85738/wap/mobile/wechatLive/js/RSA.js').content.decode()
bigint_js = session.get('http://s.xnimg.cn/a85738/wap/mobile/wechatLive/js/BigInt.js').content.decode()
barrett_js = session.get('http://s.xnimg.cn/a85738/wap/mobile/wechatLive/js/Barrett.js').content.decode()
# 创建js环境对象
context = js2py.EvalJs()
# 将变量和js代码加载到环境对象中执行
context.execute(rsa_js)
context.execute(bigint_js)
context.execute(barrett_js)
context.n = n
context.t = t
# 将关键js代码放到环境对象中执行
pwd_js = '''
t.password = t.password.split("").reverse().join(""),
setMaxDigits(130);
var o = new RSAKeyPair(n.e,"",n.n)
,r = encryptedString(o, t.password);
'''
context.execute(pwd_js)
# 获取加密密码
print(context.r)
# 构建formdata
formdata = {
'phoneNum':1717280586,
"password":context.r,
"c1":-100,
"rKey":n['rKey']
}
print(formdata)
# 发送post请求,模拟登录
url = 'http://activity.renren.com/livecell/ajax/clog'
response = session.post(url,data=formdata)
# 验证
print(response.content.decode())
if __name__ == "__main__":
login()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号