pandas是基于numpy的一种工具,该工具是为了解决数据分析任务而创建的,是python的一个数据分析包。是一个强大的分析结构化数据的工具集,它的使用基础是Numpy(提供高性能的矩阵运算),用于数据挖掘和数据分析,同时也提供数据清洗功能。pandas最初被作为金融数据分析工具而开发出来,因此为时间序列分析提供了很友好的支持。
数据结构:
Series:一位数组,与numpy中的一维array类似。二者与python基本的数据结构list也很相似。series如今能保存不同的数据类型,字符串,布尔型,数字等都能保存在series 中。
Time-Series:以时间为索引的series。
DataFrame:是Pandas中的一个(二维)表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典或者将DataFrame理解为Series的容器。
Panel:三维度的数组,可以理解为DataFrame的容器。
Panel4D:像Panel一样的4维数据容器。
PanelND:创建像Panel4D一样N维命名容器的模块。
import numpy as np
import pandas as pd
#Data Structure
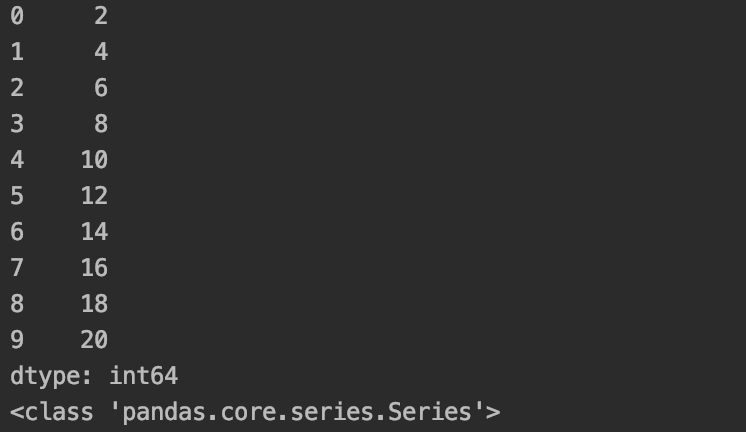
s=pd.Series([i*2 for i in range(1,11)])
print(s)
print(type(s))
![]()
dates=pd.date_range('20200414',periods=8)
print(dates)
print(type(dates))
![]()
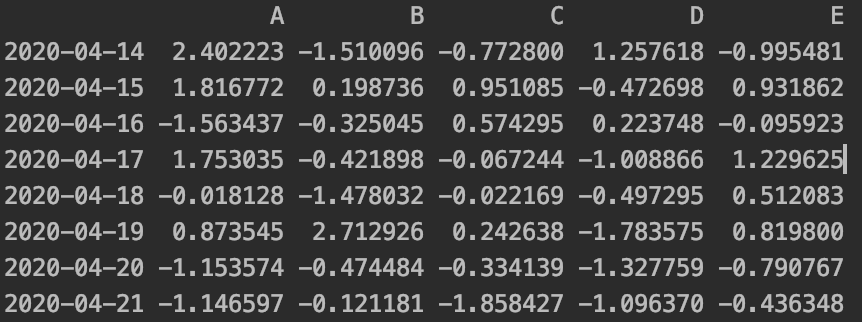
df=pd.DataFrame(np.random.randn(8,5),index=dates,columns=list('ABCDE'))
print(df)
![]()
df1=pd.DataFrame({'A':1,'B':pd.Timestamp('20200414'),'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='float32'),'E':pd.Categorical(['police','student','teacher','doctor'])})
df2=pd.DataFrame({'A':1,'B':pd.date_range('20200414',periods=4),'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='float32'),'E':pd.Categorical(['police','student','teacher','doctor'])})
print(df1)
print(df2)
![]()
#Basic
#Basic
print(df.head(3))#打印前三条
print(df.tail(3))#打印后三条
print(df.index)#索引
print(df.values)#值
print(df.T)#转置
print(df)
#print(df.sort(columns='C'))#改成sort_values
print(df.sort_values('C',ascending=False))#以C列降序进行排序
print(df.sort_index(axis=0,ascending=False))#axis=0,索引行降序排列,axis=1,索引列降序
print(df.describe())#对dataframe进行描述,个数,方差,平均值,中位数,最小值,最大值等等
#切片
#select(切片)
print(type(df['A']))#多个series组成dataframe,所以语法一般是通用的
print(df[:3])#切片,取前三行
print(df['20200415':'20200420'])#通过索引来切片
print(df.loc[dates[0]])#取第一行
print(df.loc['20200414':'20200418'])#可以指定维度
print(df['20200414':'20200418'])#行上的选取,可以是df[0:4]
print(df.loc['20200414':'20200418',['B','D']])#可以指定维度
print(df.at[dates[0],'C'])#df.at选定一个单元格
print(df.iloc[1:3,2:4])#通过下标进行选择
print(df.iloc[1,4])#第一行第四列的单元格
print(df.iat[1,4])#第一行第四列的单元格
print(df[df.B>0][df.A<0])#取B列大于0,A列小于0的数据
print(df[df>0])#取df大于0的数据,不满足条件的返回NaN
print(df[df['E'].isin([1,2])])#E列中包含1和2的,没有返回空
#Set
#Set
s1=pd.Series(list(range(10,18)),index=pd.date_range('20200414',periods=8))
df['F']=s1#df中新增f列
print(df)
df.at[dates[0],'A']=0#一行一列置为空
df.iat[2,2]=1#第2行2列置为1,下标是从0开始的
df.loc[:,'D']=np.array([4]*len(df))#D列置为4
print(df)
df4=df.copy()#复制df
df4[df4>0]=-df4#把所有df4中大于0的数都置为负数
print(df4)
#缺失值处理
#Missing Values
df5=df.reindex(index=dates[:4],columns=list('ABCD')+['G'])#reindex为dataframe重新索引和列轴的功能
df5.loc[dates[0]:dates[1],'G']=1#G列的前两行置为1
print(df5)
print(df5.dropna())#删除数据为空的整行数据
print(df5.fillna(value=2))#将数据为空的值填为2
print(df5.fillna('missing'))#缺失值用字符串填充
print(df5.fillna(method='pad'))#缺失值用前一个数据代替
print(df5.fillna(method='bfill'))#缺失值用后一个数据代替
print(df5.fillna(method='pad',limit=1))#limit进行限制,限制每列只能代替一个空值
print(df5.fillna(df5.mean()))#可用描述统计量代替空值
print(df.fillna(df5.mean()['A':'B']))#选择某一列进行缺失值的处理
#统计
#Statistic
print(df.mean())#均值
print(df.var())#方差
s=pd.Series([1,2,4,np.nan,5,7,9,10],index=dates)
print(s)
print(s.shift(2))#从前向后移动两位
print(s.diff())#与前一个数的差值,第一个数之前没有数值,所以为NaN
print(s.value_counts())#值出现的次数,绘制直方图比较方便
print(df.apply(np.cumsum))#累加,每列累加
print(df.apply(lambda x:x.max()-x.min()))#lambda匿名函数的格式:冒号前是参数,可以有多个,用逗号隔开,冒号右边的为表达式。其实lambda返回值是一个函数的 #地址,也就是函数对象
#表格拼接
#Content
pieces=[df[:3],df[-3:]]#生成一个碎片,前三行,后三行,df[:-3]是截取到倒数第三行
print(pd.concat(pieces))#进行拼接
left=pd.DataFrame({'key':['x','y'],'value':[1,2]})
right=pd.DataFrame({'key':['x','z'],'value':[3,4]})
print('left:',left)
print('right:',right)
print(pd.merge(left,right,on='key',how='inner'))#内连接
print(pd.merge(left,right,on='key',how='outer'))#外连接
df6=pd.DataFrame({'A':['a','b','c','d'],'B':list(range(4))})
print(df6)
print(df6.groupby('A').sum())#分组求和,类似于SQL
#透视表
#reshape
#类似于透视表
import datetime
df7=pd.DataFrame({'A':['one','one','two','three']*6,
'B':['a','b','c']*8,
'C':['foo','foo','foo','bar','bar','bar']*4,
'D':np.random.randn(24),
'E':np.random.randn(24),
'F':[datetime.datetime(2017,i,1) for i in range(1,13)]+
[datetime.datetime(2017,i,15) for i in range(1,13)]})
print(df7)
print(pd.pivot_table(df7,values='D',index=['A','B'],columns=['C']))#类似于excel的透视表
#时间序列
#Time Series
t_exam=pd.date_range('20200414',periods=10)
t_exam1=pd.date_range('20200414',periods=10,freq='S')#freq设置频率,以秒为间隔
print(t_exam)
print(t_exam1)
#图表
#Graph
ts=pd.Series(np.random.randn(1000),index=pd.date_range('20200414',periods=1000))
ts=ts.cumsum()
from pylab import *
ts.plot()
show()
#文件操作
#File
df8=pd.read_excel('/Users/luxiaolu/Desktop/aaa.xlsx','Sheet1')#打开excel要指定sheet
#print(df8[:10])
df9=pd.read_csv('/Users/luxiaolu/Desktop/aaa.csv')#csv不需要指定sheet
print(df9[:10])#以切片的方式查看前10条
print(df9.head(10))#调用函数查看前10条
#保存为excel或者csv文件
df8.to_excel('/Users/luxiaolu/Desktop/bbb.xlsx')
df8.to_csv('/Users/luxiaolu/Desktop/bbb.csv')
报错,解决办法:
print(df.sort(columns='C'))
![]()
print(df.sort_values('C'))
也可以加上已降序的方式,不加ascending=False,默认为true
print(df.sort_values('C',ascending=False)









 浙公网安备 33010602011771号
浙公网安备 33010602011771号