nnUNet项目记录(完结)
官网

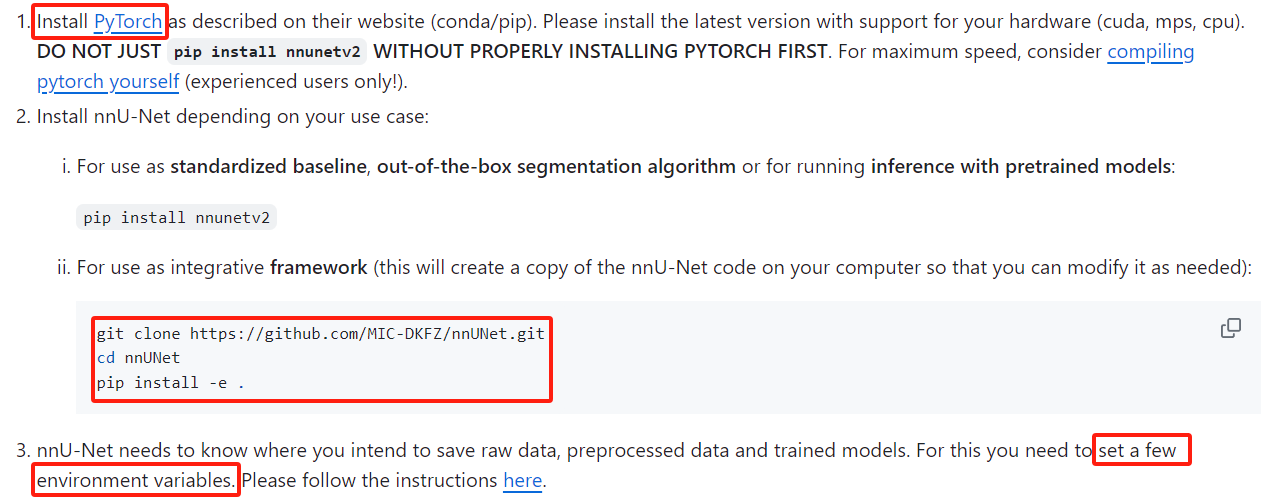
一、Installation Instructions
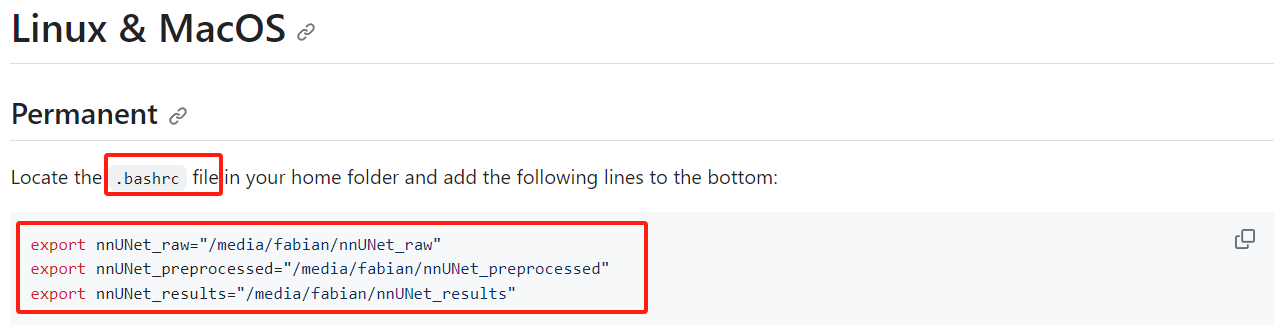
二、Setting up Paths
- 三个环境变量的存放地址
- nnUNet_raw: raw data
- nnUNet_preprocessed: preprocessed data
- nnUNet_results: trained model weights
- How to set environment variables
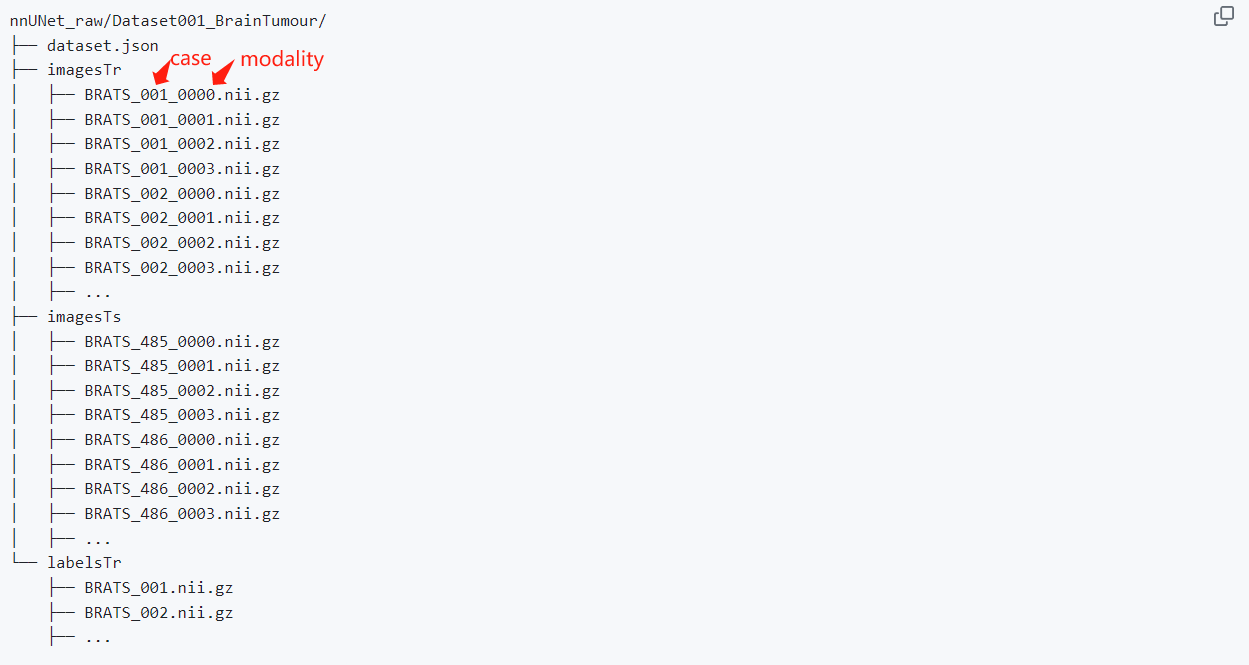
三、Dataset Conversion
- 按照网页中间给出的‘Dataset folder structure’示例进行数据目录整理
- 此处数据为nnUNet_raw,即原始数据

- 每个任务数据集

- 里面的数据文件格式有两种
- 一种是多模态
- 同一case模态之间必须:
1.have the same geometry (same shape, spacing (if applicable) etc.)
2.be co-registered (if applicable) - 所有cases必须模态数及其排序相同
- 同一case模态之间必须:
- 一种是单一模态

- 一种是多模态
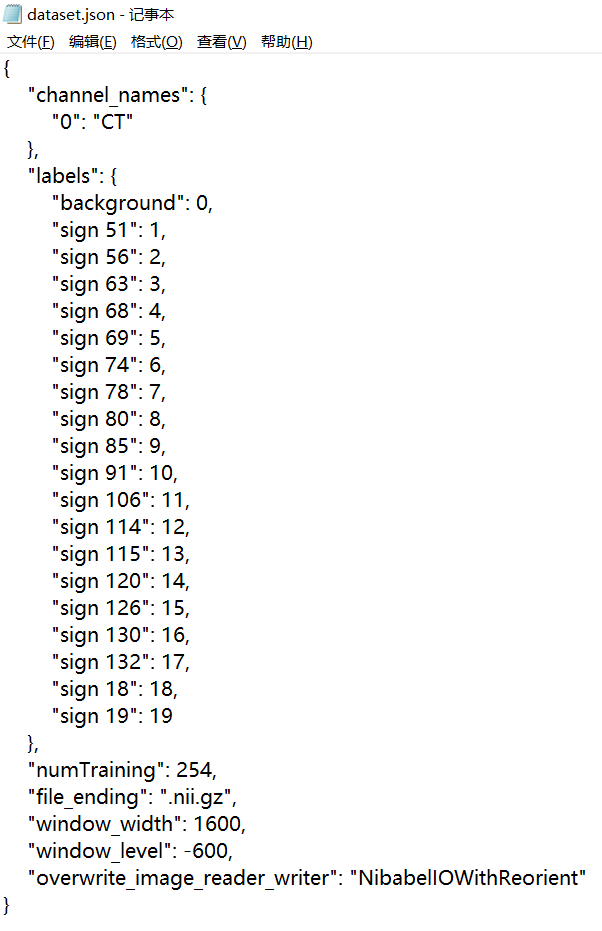
- 制作dataset.json文件
实施过程
-
踩坑
- No Module Named 'nnUNetv2' ——> 没有配置pytorch
- pytorch版本冲突 ——> A100
- No module named 'torch' ——> conda默认安装了pytorch-cpu
- evaluation dice = 0 ——> label值不对应
-
简要过程(高度概括)
- 准备数据(包括下载、转换成项目需要的格式)
- 预处理(网络需要,没什么好说的)
- 训练(一折大约24小时)
- 测试(按照命令执行就行)
- 评估(注意避坑)
-
心路历程(待补充)
- 第一次上手一个完整GitHub项目:
- 一开始是惧怕、陌生,很怕自己搞砸什么。。。
- 但随着推进,渐渐凭借自己解决了遇到的一个又一个问题 ——> ——>
- 心态变成————问题一直会有(祈祷没有),但我感觉我应该可以😃😊💜
- 历时两周,期间经历了“自我怀疑”-“小试牛刀”-“建立信心”-“成就感爆棚”-“心态爆炸”-“重拾信心”-“终于结束”的心路历程,总体来说是一个很适合上手的项目。
- 第一次上手一个完整GitHub项目:
-
重点记录
⭐ 按要求整理数据(前两天感觉根本是摸着石头过河,毫无基础,看得云里雾里,一边摸索一边继续,最终也凭自己将下载好的数据集整理成了项目要求的样子)有两件事情需要重点记录一下:- 重新存放数据(目录级别以及命名方式)
- 制作.json文件(数据描述文件)
⭐ 开始预处理,命令
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity(有了前两天的准备,第三天显得从容了一些,但问题也是层出不穷。先是一直报没有nnunetv2这个包的错误,各种分析、各种查资料、各种试错,依然没有解决,索性破釜沉舟,直接从创建环境开始推倒重来;然后重建环境的时候又一次次遇到了版本冲突。。。)唉~感悟主要有两个:- 一定要严格遵守项目教程,一步一步往下走(这次这个就是漏掉了其中一个环节导致环境没配好);

- 真的是要多查资料(这次这个就是各种翻网上的留言解决的)留个链接地址
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia
⭐ 训练,命令
CUDA_VISIBLE_DEVICES=gpu_id/UUID nnUNetv2_train DATASET_NAME_OR_ID 2d/3d_fullres 0 --npz(大无语,第四天,接着配环境,因为又报错了呜呜呜/(ㄒoㄒ)/~~)错误信息为ModuleNotFoundError: No module named 'torch',于是又开始各种查资料,复盘如下:- 这个错误说明torch的版本不对(因为我明明装了torch)
conda list发现果真装的是cpu版本的(😂🤦),至于原因这里就不细说了(唉,还是说一下吧,因为配环境的时候命令为conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia,于是conda默认安装了最新版本的torch,又由于没找到与cuda版本匹配的torch-gpu版,故就装成了cpu版(ˉ▽ˉ;)...)。总之最后是用pip命令解决了✌pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116,记录一下配置:python3.10,cuda11.7,cudnn8.5,torch版本如下:

- ⏰以后能用docker的一定要用docker!!!
- 环境一配好,直接就train成功了
⭐(时间来到第五天,想要加快训练,因为一个完整的训练要跑1000轮,基本要一天一夜。于是又是各种查资料,翻issue ~~~)
- 改preprocess文件夹下面的plan.json文件,调大batch_size(默认2),issue里面还真有,研究了一下explanation_plans_files.md,最后成功修改,但限制于内存,单块GPU最大6,但好像也没加速(😂)
- 改.bashrc文件,调大进程数(默认12)
export nnUNet_n_proc_DA=32,但也没啥效果(我佛了🧚) - 索性还是基于默认超参接着训练了
⭐fold0训练完成,fold1~fold4同时训练,但一块GPU的吞吐速度有限,于是也跑了四天四夜。。。
⭐训练完成,接着下面的命令
- find_the_best_configuration:
nnUNetv2_find_best_configuration 300 -c 3d_fullres
⭐进行inference
- 根据生成的inference.txt文件进行inference:(时间较长,耐心等待便可)
CUDA_VISIBLE_DEVICES=0 nnUNetv2_predict -d Dataset300_KiTS2021 -i nnUNet_raw/Dataset103_WuHuKidney/imagesTs -o nnUNet_predict_result/Dataset009_ZhongLiuKidney -f 0 1 2 3 4 -tr nnUNetTrainer -c 3d_fullres -p nnUNetPlans - 根据生成的inference.txt文件进行postprocessing:
nnUNetv2_apply_postprocessing -i nnUNet_predict_result -o nnUNet_predict_result_pp -pp_pkl_file /homes/xchang/Data/KiTS21/nnUNet_results/Dataset300_KiTS2021/nnUNetTrainer__nnUNetPlans__3d_fullres/crossval_results_folds_0_1_2_3_4/postprocessing.pkl -np 8 -plans_json /homes/xchang/Data/KiTS21/nnUNet_results/Dataset300_KiTS2021/nnUNetTrainer__nnUNetPlans__3d_fullres/crossval_results_folds_0_1_2_3_4/plans.json
⭐进行evaluation(补充具体步骤): 欸?怎么dice全为0 ???经过自己的头脑风暴与跟狗子激烈的讨论,以及最小系统测试!!!结论居然是要把label值改成一致,具体说来便是:
- kits2021数据集为多标签,{1,2,3}为kidney,{2,3}为mass,{2}为tumor;
- 于是predict出来的分割图也有三个标签(只有label=2才对应tumor);
- 但ground truth的标签只有一个(label=1对应tumor);
- 于是出现了dice=0的情况。
- 我们思路也很直接,既然不一样,那就改成一样。只保留predict结果中label=2的部分,并赋值为1。
⭐最后添加一个predict.sh文件,自动批量执行predict+evaluation,运行命令
sh predict.sh- 成功★,°:.☆( ̄▽ ̄)/$:.°★ 。
后记
-
换服务器训练
激活环境后conda activate [environment name],报错显示No Module Named 'nnUNetv2',但明明是有nnUNetv2这个包的。解决方案:在这个环境下面卸载重装nnUNetv2这个包pip uninstall nnUNetv2 pip install nnUNetv2 -
改dataset.json文件,修改数据相关参数:预处理细节(eg. 窗宽窗位win_width\win_level),交叉验证折数folds等
{ "channel_names": { "0": "CT" }, "labels": { "background": 0, "sign 51": 1, ··· }, "folds": 1, "numTraining": 254, "file_ending": ".nii.gz", "window_width": 1600, "window_level": -600, "overwrite_image_reader_writer": "NibabelIOWithReorient" } -
训练命令
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity CUDA_VISIBLE_DEVICES=gpu_id/uuid nnUNetv2_train DATASET_NAME_OR_ID 3d_fullres 0 --npz # example CUDA_VISIBLE_DEVICES=0 nnUNetv2_train 302 3d_fullres 0 --npz CUDA_VISIBLE_DEVICES=1 nnUNetv2_train 302 3d_fullres 1 --npz CUDA_VISIBLE_DEVICES=2 nnUNetv2_train 302 3d_fullres 2 --npz CUDA_VISIBLE_DEVICES=3 nnUNetv2_train 302 3d_fullres 3 --npz CUDA_VISIBLE_DEVICES=4 nnUNetv2_train 302 3d_fullres 4 --npz -
运行部分折后看结果
CUDA_VISIBLE_DEVICES=gpu_id/uuid nnUNetv2_predict -i /path/to/your/input/data -o /path/to/save/predictions -d DATASET_ID -c 3d_fullres -tr nnUNetTrainer -p nnUNetPlans -f 2 3 4 # example CUDA_VISIBLE_DEVICES=0 nnUNetv2_predict -i ~/nnUNet_raw/Dataset302_TuberculosisROI/imagesTr_rescale -o ~/nnUNet_predict_result/Dataset302_TuberculosisROI -d 302 -c 3d_fullres -tr nnUNetTrainer -p nnUNetPlans -f 2 3 4 # or nnUNetv2_find_best_configuration DATASET_ID -c 3d_fullres -
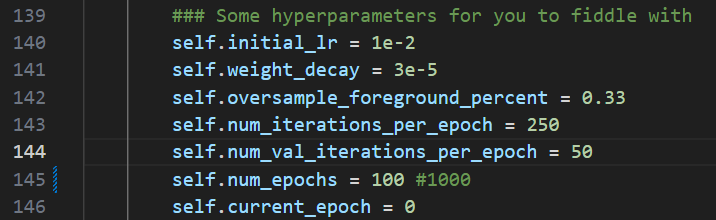
修改训练超参
位置:../nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py
其他
- nnUNet 中的 partial label(issue里面有)
partial label:缺省的值为-1;CrossEntropy(ignore_index=ignore_index)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号