
MAF快速入门(7)工作流的状态共享
 在实际业务场景中,一个AI工作流的多个步骤之间往往需要共享上下文数据,例如用户原始输入、模型的输出缓存等。在MAF中,提供了一个 WorkflowContext 的模型,它原生提供了工作流上下文的状态共享能力。
在实际业务场景中,一个AI工作流的多个步骤之间往往需要共享上下文数据,例如用户原始输入、模型的输出缓存等。在MAF中,提供了一个 WorkflowContext 的模型,它原生提供了工作流上下文的状态共享能力。
大家好,我是Edison。
最近我一直在跟着圣杰的《.NET+AI智能体开发进阶》课程学习MAF的开发技巧,我强烈推荐你也上车跟我一起出发!
上一篇,我们学习了MAF中进行了Agent和Executor的混合编排,相信你一定有了更多地理解。本篇,我们来通过一个经典的例子了解下MAF中工作流如何实现状态的共享。
状态共享的应用场景
在实际业务场景中,一个AI工作流的多个步骤之间往往需要共享上下文数据,例如用户原始输入、模型的输出缓存等。在MAF中,提供了一个 WorkflowContext 的模型,它原生提供了工作流上下文的状态共享能力。
举个例子,在下面这个聚合统计流程中,创建了一个FileContentState的共享内容通过WorkflowContext进行传递共享给后续的两个统计Executor使用,进而进行聚合输出结果。

WorkflowContext API一览
在WorkflowContext API中,它提供了以下一些状态读取和设置的接口,作为字典我们可以了解一下:
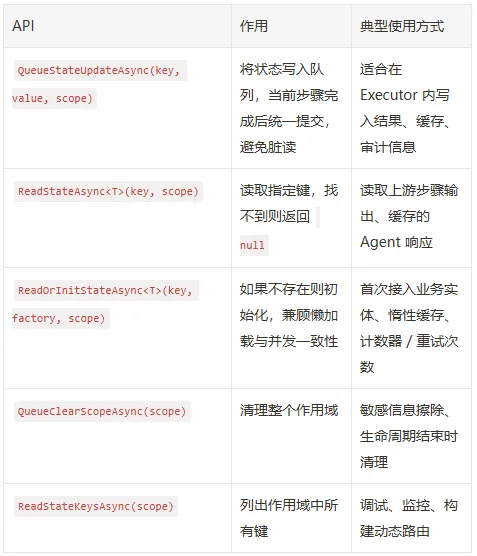
这里我们用的比较多的是:QueueStateUpdateAsync 和 ReadStateAsync 两个方法。
实验案例
今天来实践一个文档统计的工作流案例,和上面的例子相似:
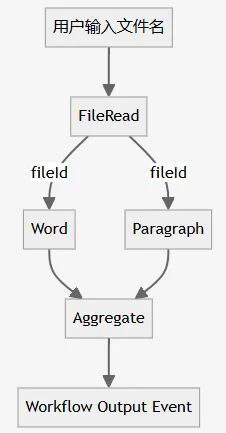
这是一个典型的扇入扇出(Fan-In & Fan-Out)工作流:
首先,用户输入一个文件名,FileReadExecutor会读取该文件的内容并将文件内容传入工作流上下文中共享,同时将文件ID号传递给后续流程。
然后,单词统计Executor 和 段落统计Executor 会分别统计该文件内容的 单词数 和 段落数。
最后,聚合统计Executor会将收集到的 单词数 和 段落数 交由LLM进行友好信息的输出,最初反馈给用户。
这个案例展示了一次写入,多处读取的经典场景,它也是并发协作的基础。
准备工作
在今天的这个案例中,我们仍然创建了一个.NET控制台应用程序,安装了以下NuGet包:
- Microsoft.Agents.AI.OpenAI
- Microsoft.Agents.AI.Workflows
- Microsoft.Extensions.AI.OpenAI
我们的配置文件中定义了LLM API的信息:
{ "OpenAI": { "EndPoint": "https://api.siliconflow.cn", "ApiKey": "******************************", "ModelId": "Qwen/Qwen3-30B-A3B-Instruct-2507" } }
这里我们使用 SiliconCloud 提供的 Qwen/Qwen3-30B-A3B-Instruct-2507 模型,之前的 Qwen2.5 模型在这个案例中不适用。你可以通过这个URL注册账号:https://cloud.siliconflow.cn/i/DomqCefW 获取大量免费的Token来进行本次实验。
然后,我们将配置文件中的API信息读取出来:
var config = new ConfigurationBuilder() .AddJsonFile($"appsettings.json", optional: false, reloadOnChange: true) .Build(); var openAIProvider = config.GetSection("OpenAI").Get<OpenAIProvider>();
定义数据传输模型
首先,我们定义一下在这个工作流中需要生成传递的数据模型:
(1)FileStats :统计结果DTO
internal sealed class FileStats { public int WordCount { get; init; } public int ParagraphCount { get; init; } }
(2)FileContentStateConstants :常量,类似于Cache Key的作用
internal static class FileContentStateConstants { public const string ScopeName = "FileContentState"; }
定义示例数据集
这里我们Mock了一个文档数据集,用于模拟读取的文件内容。
internal static class SharedStateSampleData { private static readonly IReadOnlyDictionary<string, string> Documents = new Dictionary<string, string> { ["ProductBrief"] = "MAF Workflow 让 .NET 团队可以像积木一样组合 Agent、Executor 与工具, 支持流式事件、并发节点和可观测性。\n\n它强调企业级能力, 包括状态管理、依赖注入、权限控制, 适合搭建端到端 AI 业务流程。", ["WeeklyReport"] = "本周平台完成了 Shared State 功能的代码走查, 已经覆盖 Fan-out/Fan-in, Loop, Human-in-the-Loop 三种场景。\n\n下周计划: 1) 集成多模型投票; 2) 增加异常回滚; 3) 落地监控指标。" }; public static string GetDocument(string name) => Documents.TryGetValue(name, out var content) ? content : throw new ArgumentException($"未找到文档: {name}"); }
文件读取Executor
MAF中定义了一个Executor的基类,所有自定义Exectuor都需要继承于它。
internal sealed class FileReadExecutor() : Executor<string, string>("FileReadExecutor") { public override async ValueTask<string> HandleAsync(string message, IWorkflowContext context, CancellationToken cancellationToken = default) { var content = SharedStateSampleData.GetDocument(message); var fileId = Guid.NewGuid().ToString("N"); await context.QueueStateUpdateAsync(fileId, content, FileContentStateConstants.ScopeName, cancellationToken); Console.WriteLine($"📦 FileReadExecutor 已成功将 {message} 写入 Scope:{FileContentStateConstants.ScopeName}"); return fileId; } }
在这个Executor中,接收了用户的输入文件名,然后模拟从Mock文档内容中读取文件内容,并将文件ID 和 文件内容 通过 QueueStateUpdateAsync 方法传入共享状态存储区中,以便后续节点在需要的时候可以从共享状态中读取传递的内容。
最后,将文件ID直接传递给下一个节点。
文字统计 和 段落统计Executor
这里我们弄了两个用于统计文件内容的Executor,演示一下如何通过 ReadStateAsync 方法读取共享状态存储区中的内容。
(1)文字统计
internal sealed class WordCountingExecutor() : Executor<string, FileStats>("WordCountingExecutor") { public override async ValueTask<FileStats> HandleAsync(string fileId, IWorkflowContext context, CancellationToken cancellationToken = default) { string? content = await context.ReadStateAsync<string>(fileId, FileContentStateConstants.ScopeName, cancellationToken); if (content is null) { throw new InvalidOperationException($"无法在 Scope:{FileContentStateConstants.ScopeName} 中找到 fileId={fileId}"); } int wordCount = content.Split([' ', '\n', '\r'], StringSplitOptions.RemoveEmptyEntries).Length; return new FileStats { WordCount = wordCount }; } }
(2)段落统计
internal sealed class ParagraphCountingExecutor() : Executor<string, FileStats>("ParagraphCountingExecutor") { public override async ValueTask<FileStats> HandleAsync(string fileId, IWorkflowContext context, CancellationToken cancellationToken = default) { string? content = await context.ReadStateAsync<string>(fileId, FileContentStateConstants.ScopeName, cancellationToken); if (content is null) { throw new InvalidOperationException($"无法在 Scope:{FileContentStateConstants.ScopeName} 中找到 fileId={fileId}"); } int paragraphCount = content.Split(['\n', '\r'], StringSplitOptions.RemoveEmptyEntries).Length; return new FileStats { ParagraphCount = paragraphCount }; } }
聚合输出Executor
在工作流最后,我们定义给一个聚合输出的节点来汇总和输出用户友好的统计结果,这里我们首先获取到结构化的统计结果,然后通过LLM让其根据结果输出最终的反馈信息:
internal sealed class AggregationExecutor : Executor<FileStats> { private readonly AIAgent _aggregationAgent; private readonly AgentThread _thread; private readonly List<FileStats> _buffer = []; public AggregationExecutor(IChatClient chatClient) : base("AggregationExecutor") { // 创建 Agent 和对话线程 this._aggregationAgent = chatClient.CreateAIAgent( "你是一个专业的文档统计结果输出大师,你可以将收到的JSON格式统计结果(如总词数、总段落数 以及 统计时间等)进行友好的信息输出给用户。", "output_agent", "Output user friendly message based on input document stats result"); ; this._thread = this._aggregationAgent.GetNewThread(); } public override async ValueTask HandleAsync(FileStats message, IWorkflowContext context, CancellationToken cancellationToken = default) { this._buffer.Add(message); if (this._buffer.Count < 2) { return; } int totalWords = this._buffer.Sum(x => x.WordCount); int totalParagraphs = this._buffer.Sum(x => x.ParagraphCount); var output = new { 总词数 = totalWords, 总段落数 = totalParagraphs, 统计时间 = DateTimeOffset.UtcNow }; var response = await this._aggregationAgent.RunAsync(JsonSerializer.Serialize(output), this._thread, cancellationToken: cancellationToken); await context.YieldOutputAsync(response.Text, cancellationToken); } }
构建工作流
现在万事俱备,只欠一个Workflow,现在Let's do it!
Step1: 获取ChatClient
var chatClient = new OpenAIClient( new ApiKeyCredential(openAIProvider.ApiKey), new OpenAIClientOptions { Endpoint = new Uri(openAIProvider.Endpoint) }) .GetChatClient(openAIProvider.ModelId) .AsIChatClient();
Step2: 实例化自定义Agent & Executors
var fileRead = new FileReadExecutor(); var wordCounting = new WordCountingExecutor(); var paragraphCounting = new ParagraphCountingExecutor(); var aggregate = new AggregationExecutor(chatClient);
Step3: 创建Fan-out/Fan-in工作流
var sharedStateWorkflow = new WorkflowBuilder(fileRead) .AddFanOutEdge(fileRead, [wordCounting, paragraphCounting]) .AddFanInEdge([wordCounting, paragraphCounting], aggregate) .WithOutputFrom(aggregate) .Build(); Console.OutputEncoding = Encoding.UTF8; Console.WriteLine("✅ Shared State Workflow 构建完成");
Step4: 测试工作流
var documentKey = "ProductBrief"; Console.WriteLine("━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"); Console.WriteLine($"📂 演示文档: {documentKey}"); Console.WriteLine("━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"); await using (var run = await InProcessExecution.StreamAsync(sharedStateWorkflow, documentKey)) { await foreach (WorkflowEvent evt in run.WatchStreamAsync()) { switch (evt) { case WorkflowStartedEvent started: Console.WriteLine($"🚀 Workflow Started"); break; case ExecutorCompletedEvent executorCompleted: Console.WriteLine($"✅ {executorCompleted.ExecutorId} 完成"); break; case WorkflowOutputEvent outputEvent: Console.WriteLine("━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"); Console.WriteLine("🎉 工作流执行完成"); Console.WriteLine("━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\n"); Console.WriteLine($"{outputEvent.Data}"); break; case WorkflowErrorEvent errorEvent: Console.WriteLine("✨ 收到 Workflow Error Event:"); Console.WriteLine($"{errorEvent.Data}"); break; default: break; } } await run.DisposeAsync(); }
测试结果如下图所示:
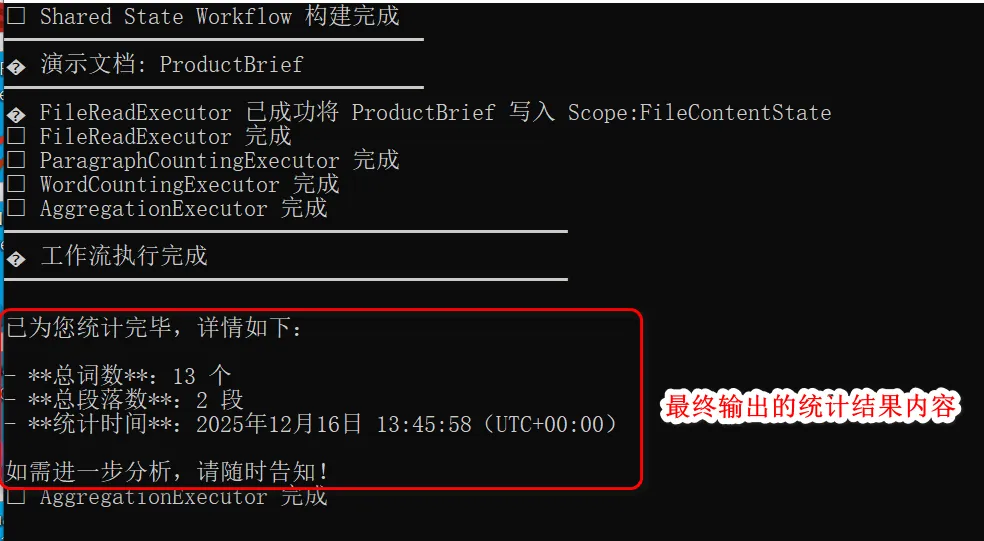
可以看见,经过多个节点的统计和聚合,由LLM总结输出了用户友好的统计结果内容。
小结
本文介绍了工作流的状态共享的应用场景 和 WorkflowContext相关的API,最后给出了一个文档内容统计的Fan-out/Fan-In工作流案例供参考。
下一篇,我们将继续学习MAF中工作流的上下文相关内容。
参考资料
圣杰,《.NET + AI 智能体开发进阶》(推荐指数:★★★★★)
Microsoft Learn,《Agent Framework Tutorials》



 浙公网安备 33010602011771号
浙公网安备 33010602011771号