
MongoDB入门实战教程(9)
 前面我们学习了如何套用常见的设计模式打造合适的模型设计,本篇我们来看看在MongoDB中如何使用索引来提高查询效率。本文简单介绍了MongoDB的索引的基本概念和术语,为什么MongoDB会采用B树 而 MySQL会采用B+树,常见的MongoDB索引的类型和应用,常见的索引属性及应用。
前面我们学习了如何套用常见的设计模式打造合适的模型设计,本篇我们来看看在MongoDB中如何使用索引来提高查询效率。本文简单介绍了MongoDB的索引的基本概念和术语,为什么MongoDB会采用B树 而 MySQL会采用B+树,常见的MongoDB索引的类型和应用,常见的索引属性及应用。
前面我们学习了如何套用常见的设计模式打造合适的模型设计,本篇我们来看看在MongoDB中如何使用索引来提高查询效率。
1 MongoDB也有索引?
在使用传统关系型数据库如MSSQL、MySQL等的时候,我们经常会为table中需要经常查询的字段建立index(索引)。那么,MongoDB作为NoSQL的代表,是否也有索引呢?
答案是:有的。
-- 查看集合的所有已有索引
db.collectionName.getIndexes()
MongoDB的两种扫描方式
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时会和MySQL一样必须扫描集合中的每个文档并选取那些符合查询条件的记录。

在MongoDB中,全集合扫描被称之为 COLLSCAN,而索引扫描则被称之为IXSCAN。我们可以在MongoDB中使用类似于MySQL中的explain来查看执行计划,判断该查询是否是IXSCAN即索引扫描:
db.userinfos.find({name:"张三"}).explain()
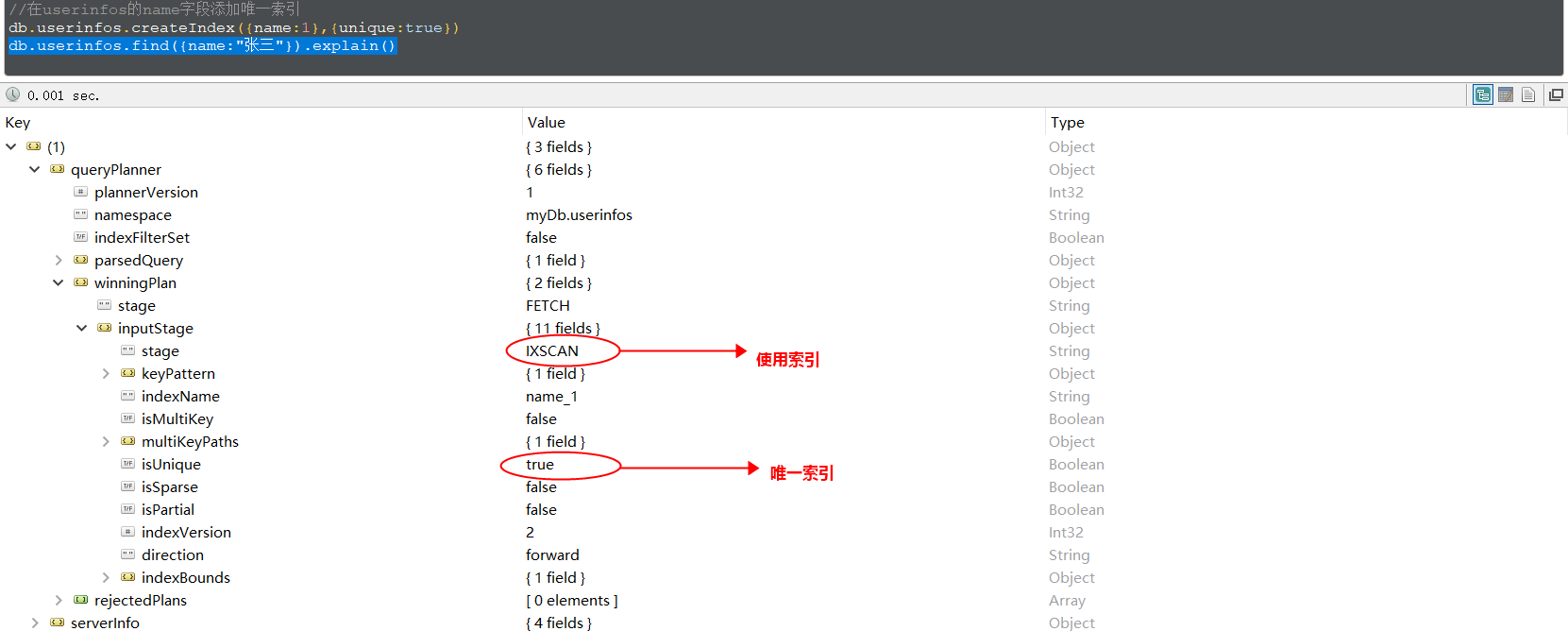
和关系型数据库一样,扫描全集合的查询COLLSCAN的效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
MongoDB索引的数据结构:B树
我们都知道MySQL InnoDB引擎的索引采用的是B+树,那么MongoDB的索引采用的是什么数据结构呢?
答案是:B树。
为什么MySQL采用B+树,而MongoDB采用B树呢?
首先,我们需要知道,什么是B树,什么又是B+树。
(1)B+树(MySQL等关系型数据库广泛采用)
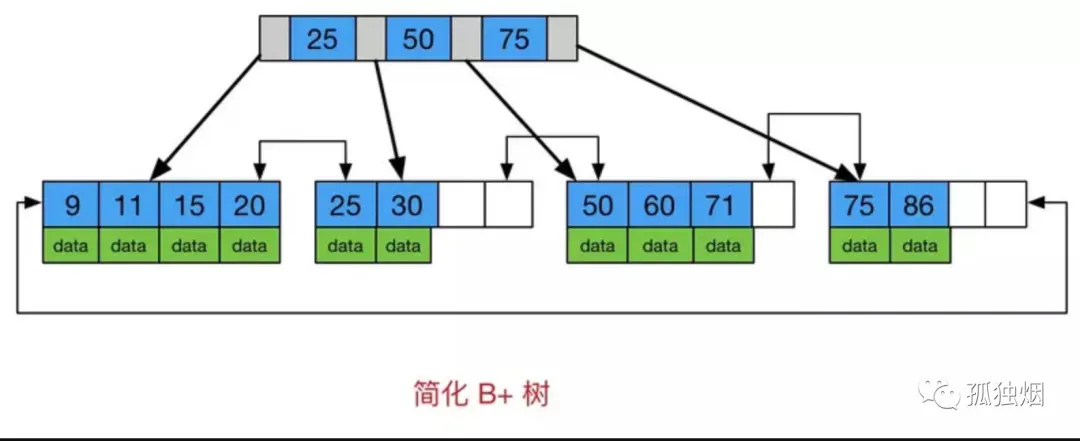
B+树的两个明显特点:
-
数据只出现在叶子节点(查询效率高)
-
所有叶子节点增加了一个链指针(便于范围查询)
(2)B树(MongoDB采用)

B树的两个明显特点:
-
树内的每个节点都存储数据
-
叶子节点之间无指针相邻
针对上面的B+树和B树的特点,我们可以得到以下两个结论:
(1) B树的树内存储数据,因此查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。我们可以认为在做单一数据查询的时候,使用B树平均性能更好。但是,由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
(2) B+树的数据只出现在叶子节点上,因此在查询单条数据的时候,查询速度非常稳定。因此,在做单一数据的查询上,其平均性能并不如B树。但是,B+树的叶子节点上有指针进行相连,因此在做数据遍历的时候,只需要对叶子节点进行遍历即可,这个特性使得B+树非常适合做范围查询。
综述,基于关系型数据库的关系模型 和 文档数据库的文档模型,我们可以知道:MySQL中数据遍历操作比较多(因为需要多表关联和范围查找),所以用B+树作为索引结构。而MongoDB是做单一文档查询比较多(因为内嵌设计不需要多集合关联且很少范围查找),数据遍历操作比较少,所以用B树作为索引结构。
MongoDB的索引查询效率
由于B树/B+树的工作过程十分复杂,但本质上,它是一个有序的数据结构。
我们可以用一个数组来理解它,假设这里有一个索引为{a:1}(a升序):
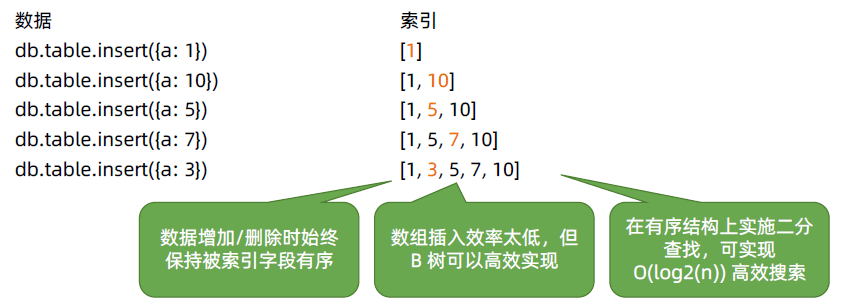
在一个有序的结构上,基于我们学习过的二分查找法,可以实现一个O(log2(n))的高效搜索效率。这也可以解释,为什么基于索引查询,在数据量很大的情况下会快很多。
2 MongoDB索引使用
单键索引
这是最常见的索引类型,无论是在MySQL还是MongoDB中。
// 为collection建立name的升序索引 db.users.createIndex( { name: 1 } ); // 为collection建立name的降序索引 db.users.createIndex( { name: -1 } );
组合索引
这也是一种常见的索引类型,通过建立组合索引可以在保持索引个数的前提下尽可能覆盖更多的查询条件。
例如,在members集合中,假设我们往往需要通过以下几个条件来组合查询:
db.members.find({ gender: "F", age: {$gte: 18}}).sort("join_date:1");
那么,我们就可以针对gender、age和join_date做一个组合索引:
db.members.createIndex({"gender":1,"join_date":1,"age":1});
和MySQL一样,组合索引具有一个特征:最左匹配原则。
那么,这就要求我们在创建组合索引时,需要满足ESR原则:
(1)精确(Equal)匹配的字段放在最前面,比如这里的gender字段;
(2)排序(sort)字段放中间,比如这里的join_date字段;
(3)范围(Range)匹配的字段放在最后面,比如这里的age字段;
上面这个ESR原则,同样适用于MySQL 和 ElasticSearch。
多键索引
MongoDB使用多键索引来索引存储在数组中的内容。
如果索引字段包含数组值,MongoDB会为数组的每个元素创建单独的索引条目。这些多键索引允许查询通过匹配数组中的元素来获取包含数组的文档。
db.classes.insertMany([ { "classname":"class1", "students":[{name:'jack',age:20}, {name:'tom',age:22}, {name:'lilei',age:25}] }, { "classname":"class2", "students":[{name:'lucy',age:20}, {name:'jim',age:23}, {name:'jarry',age:26}] }] ) -- 创建多键索引 db.classes.createIndex({"students.age":1})
地理位置索引
物联网场景下的监控数据存储是MongoDB的一大重要应用场景之一,因此也就催生了一种独特的索引类型:地理位置索引。
-- 创建索引 db.geo_col.createIndex( { location: "2d"} , { min:-20, max: 20 , bits: 10}, { collation: {locale: "simple"} } ) -- 查询 db.geo_col.find( { location : { $geoWithin : { $box : [ [ 1, 1 ] , [ 3, 3 ] ] } } } ) -- 查询结果 { "_id" : ObjectId("5c7e7a6243513eb45bf06125"), "location" : [ 1, 1 ] } { "_id" : ObjectId("5c7e7a6643513eb45bf06126"), "location" : [ 1, 2 ] } { "_id" : ObjectId("5c7e7a6943513eb45bf06127"), "location" : [ 2, 2 ] } { "_id" : ObjectId("5c7e7a6d43513eb45bf06128"), "location" : [ 2, 1 ] } { "_id" : ObjectId("5c7e7a7343513eb45bf06129"), "location" : [ 3, 1 ] } { "_id" : ObjectId("5c7e7a7543513eb45bf0612a"), "location" : [ 3, 2 ] } { "_id" : ObjectId("5c7e7a7743513eb45bf0612b"), "location" : [ 3, 3 ] }
有关地理索引的更多介绍,请参阅2d Index Internals。
全文索引
嗯,Luence、ElasticSearch有全文索引,MongoDB也有!
全文检索会对每一个词建立一个索引(也称为 倒排索引),指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
这个过程类似于通过字典中的检索字表查字的过程。
MongoDB 从 2.4 版本开始支持全文检索,目前支持15种语言的全文索引。
但是,还没有支持中文!还没有支持中文!还没有支持中文!(重要的事情说三遍)
-- 创建全文索引 db.blogArticles.createIndex({"content" : "text"}
3 常见索引属性
唯一索引
索引的唯一属性会导致MongoDB拒绝索引字段的重复值。
除了唯一约束之外,唯一索引在功能上可与其他MongoDB索引互换。
// 在users的name字段添加唯一索引 db.users.createIndex({name:1},{unique:true})
部分(局部)索引
顾名思义,部分索引仅索引符合特定的过滤表达式的集合中的文档。
通过索引集合中的文档子集,部分索引具有较低的存储要求,减少索引创建和维护的性能成本。
部分索引是稀疏索引功能的超集,应该优先于稀疏索引。
//users集合中age>25的部分添加age字段索引 db.users.createIndex( {age:1}, {partialFilterExpression: {age:{$gt: 25}}} ) //查询age<25的document时,因为age<25的部分没有索引,会全表扫描查找(stage:COLLSCAN) db.users.find({age:23}) //查询age>25的document时,因为age>25的部分创建了索引,会使用索引进行查找(stage:IXSCAN) db.users.find({age:26})
稀疏索引
索引的稀疏属性可确保索引仅包含具有索引字段的文档的条目。索引会跳过没有索引字段的文档。
将稀疏索引与唯一索引组合,以拒绝具有字段重复值的文档,但忽略没有索引键的文档。
-- 当document包含address字段时才会创建索引: db.userinfos.createIndex({address:1},{sparse:true})
TTL索引
TTL索引是MongoDB在指定时间后自动从集合中删除文档的特殊索引。
这是某些类型的信息的理想选择,例如机器生成的事件数据,日志和会话信息,这些信息只需要在数据库中保存有限的时间。
//添加测试数据 db.logs.insertMany([ {_id:1,createtime:new Date(),msg:"log1"}, {_id:2,createtime:new Date(),msg:"log2"}, {_id:3,createtime:new Date(),msg:"log3"}, {_id:4,createtime:new Date(),msg:"log4"} ]); //在createtime字段添加TTL索引,过期时间是120s(2分钟) db.logs.createIndex({createtime:1}, { expireAfterSeconds: 120 })
需要注意的是:TTL索引只能设置在date类型字段(或者包含date类型的数组)上,过期时间为字段值+exprireAfterSeconds;document过期时不一定就会被立即删除,因为mongoDB执行删除任务的时间间隔是60s;
4 总结
本文简单介绍了MongoDB的索引的基本概念和术语,为什么MongoDB会采用B树 而 MySQL会采用B+树,常见的MongoDB索引的类型和应用,常见的索引属性及应用。
下一篇,我们会学习MongoDB的事务管理相关知识,这是MongDB 4.x版本提供的新功能,在走向OLTP的路上迈出了坚实的一步。
本系列教程目录:
参考资料
唐建法,《MongoDB高手课》(极客时间)
郭远威,《MongoDB实战指南》(图书)

△推荐订阅学习



 浙公网安备 33010602011771号
浙公网安备 33010602011771号