
走向面试之数据库基础:三、SQL进阶之变量、事务、存储过程与触发器
 所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。这里使用事务解决刚刚的那个转账的问题,注意这里使用到了系统变量@@ERROR,但是@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计,于是我们可以定义一个局部变量来记录整个操作序列期间的错误数。
所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。这里使用事务解决刚刚的那个转账的问题,注意这里使用到了系统变量@@ERROR,但是@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计,于是我们可以定义一个局部变量来记录整个操作序列期间的错误数。
一、变量那点事儿
1.1 局部变量
(1)声明局部变量
DECLARE @变量名 数据类型 DECLARE @name varchar(20) DECLARE @id int
(2)为变量赋值
SET @变量名 =值 --set用于普通的赋值 SELECT @变量名 = 值 --用于从表中查询数据并赋值,,可以一次给多个变量赋值 SET @name=‘张三’ SET @id = 1 SELECT @name = sName FROM student WHERE sId=@id
(3)输出变量的值
SELECT 以表格的方式输出,可以同时输出多个变量;而PRINT 则是以文本的方式输出,一次只能输出一个变量的值。
SELECT @name,@id PRINT @name PRINT @id print @name,@id --错误!!
1.2 全局变量
(1)关于全局变量与局部变量
局部变量:
①局部变量必须以标记@作为前缀 ,如@Age int;
②局部变量需要先声明,再赋值;
全局变量(系统变量):
①全局变量必须以标记@@作为前缀,如@@version;
②全局变量由系统定义和维护,我们只能读取,不能修改全局变量的值;
(2)有哪些全局变量?

补充:@@error变量,在每次执行完SQL语句后,都会为@@error变量赋值,如果上次执行的SQL语句有错,则将@@errro赋值为一个不为0的值,否则(执行没错),则将@@error赋值为0.
(3)怎么使用全局变量
select @@LANGUAGE as '当前使用语言' select @@SERVERNAME as '当前服务器名称' select @@TRANCOUNT as '当前连接打开的事务数' select @@MAX_CONNECTIONS as '可以同时连接的最大数目' select @@VERSION as '当前服务器版本' select @@ERROR as '最后一个T-SQL错误的错误号'

二、选择与循环:if(小苹果) begin 一直听根本停不下来 end
2.1 无处不在的 IF ELSE
(1)条件选择语法


IF(条件表达式) BEGIN --相当于C#里的{ 语句1 …… END --相当于C#里的} ELSE BEGIN 语句1 …… END
(2)假设我们有一张选课成绩表SC,其中包括三个字段{S#,C#,Score},其中S#为学号,C#为课程号,而Score则为成绩。S#为Student表的外键,C#为课程表的外键。那么,根据这三张表,我们有一个需求:
计算平均分数并输出:如果平均分数超过60分输出成绩最高的三个学生的成绩,否则输出后三名的学生;
declare @avgscore float = 0 select @avgscore = AVG(Score) from SC if(@avgscore>60) begin print '前三名' select top 3 s.Sname,sc.Score from Student s join SC sc on s.S#=sc.S# order by Score desc end else begin print '后三名' select top 3 s.Sname,sc.Score from Student s join SC sc on s.S#=sc.S# order by Score asc end
2.2 死了都要爱 WHILE
(1)循环语句语法
WHILE(条件表达式) BEGIN --相当于C#里的{ 语句 …… continue --退出本次循环 BREAK --退出整个循环 END --相当于C#里的}
(2)经典案例:计算1-100之间所有奇数的和
declare @index int = 1 declare @sum int = 0 while(@index <= 100) begin if(@index%2!=0) begin set @sum=@sum+@index end set @index=@index+1 end
三、事务:锤锤,不是说好一起同生共死吗?
3.1 什么是事务?
(1)事务(Transaction)是并发控制的基本单位
所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。 例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
事务具有以下4个基本特征:简称ACID
● Atomic(原子性):事务中的所有元素作为一个整体提交或回滚,事务的个元素是不可分的,事务是一个完整操作。
● Consistency(一致性):事物完成时,数据必须是一致的,也就是说,和事物开始之前,数据存储中的数据处于一致状态。
● Isolation(隔离性):对数据进行修改的多个事务是彼此隔离的。这表明事务必须是独立的,不应该以任何方式以来于或影响其他事务。
● Durability(持久性):事务完成之后,它对于系统的影响是永久的,该修改即使出现系统故障也将一直保留,真实的修改了数据库。
(2)事务的语法步凑
• 开始事务:BEGIN TRANSACTION 开启事务
• 事务提交:COMMIT TRANSACTION --提交操作
• 事务回滚:ROLLBACK TRANSACTION --取消操作
3.2 为什么需要事务?
以最经典的转账情形为例,我们要从A账户转一笔钱到B账户,需要进行两部操作:第一步,从A账户扣除指定的金额数目;第二部,将B账户增加指定的金额数目;
update bank set balance=balance-1000 where cid='0001' update bank set balance=balance + 1000 where cid='0002'
这里假设A账户有1000元,B账户有10元,并且银行约束每个账户必须保留10元最低存款额。这时,如果我们要从A账户转1000元到B账户的话,会在第一步从A账户扣除1000元时违反约束条件,从而出现错误,阻止了此次转账操作;但是,这并没有影响到第二步操作,于是B账户得到了天上掉下来的1000元。该怎么解决?我们可以将这两步放到一个操作序列里边,如果任何一步出现错误,都不会执行下一步操作,于是我们就可以用到事务了。
3.3 使用事务完成同生共死
这里使用事务解决刚刚的那个转账的问题,注意这里使用到了系统变量@@ERROR,但是@@ERROR只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计,于是我们可以定义一个局部变量来记录整个操作序列期间的错误数。
begin transaction declare @sumerror int = 0 update bank set balance=balance-1000 where cid='0001' set @sumerror = @sumerror + @@ERROR update bank set balance=balance + 1000 where cid='0002' set @sumerror = @sumerror + @@ERROR if(@sumerror = 0) begin commit transaction end else begin rollback transaction end
四、存储过程:别以为你藏在数据库里我就不用你
4.1 什么是存储过程?
存储过程(Procedure)是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。因此,我们可以简单的理解为:使用存储过程就像在数据库中运行方法。
4.2 存储过程的优点
(1)执行速度更快 – 在数据库中保存的存储过程SQL语句都是编译过的
(2)允许模块化程序设计 – 类似方法的复用
(3)提高系统安全性 – 防止SQL注入
(4)减少网络流量 – 只需要传输存储过程的名称
4.3 使用存储过程
(1)系统存储过程
由系统定义,存放在master数据库中,名称以“sp_”开头或”xp_”开头:
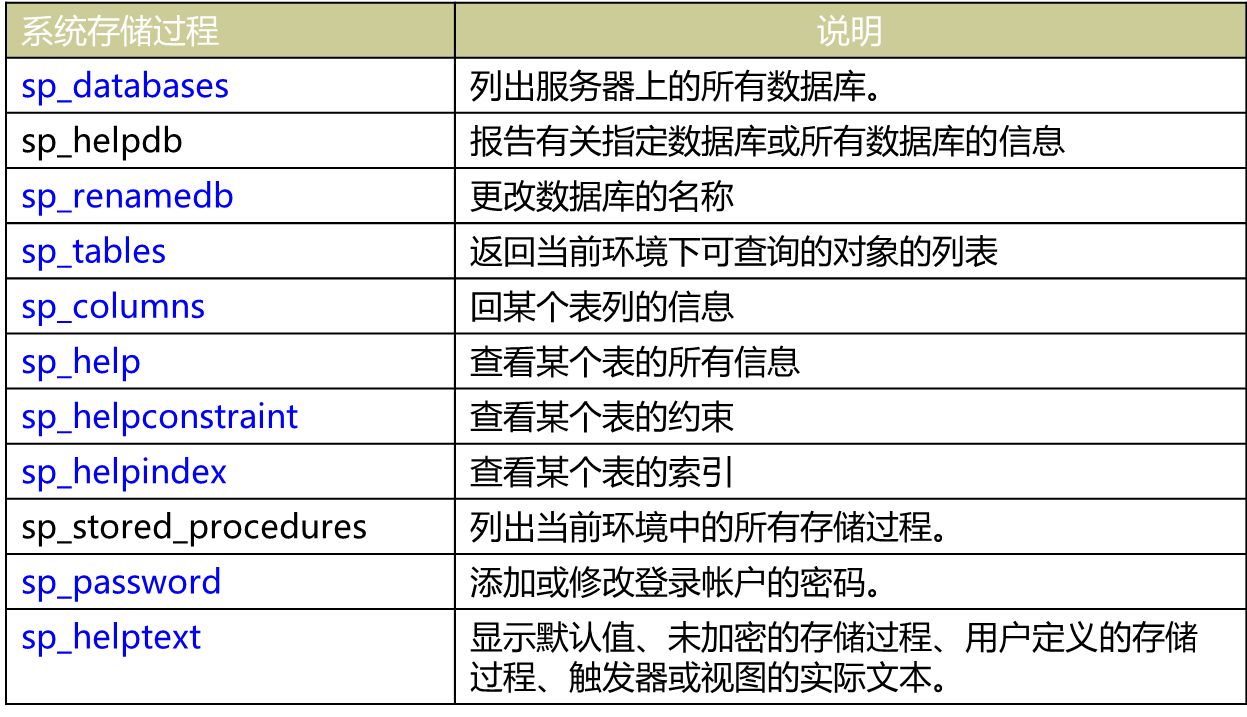
(2)自定义存储过程
自定义的存储过程可以以usp_开头,由用户在自己的数据库中创建的存储过程。
这里我们可以创建一个Account表的分页存储过程,看看怎么使用的吧:
create proc usp_GetPagedAccountData @pageIndex int = 1, @pageSize int = 10 as begin select * from (select ROW_NUMBER() OVER(order by Id) as rownum,* from Account) as t where t.rownum between @pageSize*(@pageIndex-1)+1 and @pageIndex*@pageSize Order by t.Id end
如何来执行存储过程呢?
exec usp_GetPagedAccountData @pageIndex=2,@pageSize=10
(3)使用输出参数
如果希望在使用存储过程后,将用户传递的某个参数输出改变后的结果,可以使用输出参数关键字:OUTPUT
具体的使用语法为:
declare @a int exec usp_pp @canshu= @a output print @a
这里我们看一个实例,加入有以下的一个存储过程,它接收用户传递过来的一个年龄,在Student表找出所有大于这个年龄的学生信息,并返回大于这个年龄的学生人数。
create proc usp_GetInfoByAge @page int = 10, @pcount int output as begin select @pcount=COUNT(*) from Student where Sage>@page select * from Student where Sage>@page end -- 下面是调用的代码以及返回结果 declare @outputCount int=0 exec usp_GetInfoByAge @page=18,@pcount=@outputCount output select @outputCount
五、触发器:If you jump,I will jump too.
5.1 什么是触发器?
触发器(Trigger)是一种特殊类型的存储过程,它不同于之前的我们介绍的存储过程。触发器主要是通过事件进行触发被自动调用执行的。而存储过程可以通过存储过程的名称被调用。
触发器对表进行插入、更新、删除的时候会自动执行的特殊存储过程,它一般用在比check约束更加复杂的约束上面。
触发器和普通的存储过程的区别是:触发器是当对某一个表进行操作,诸如:update、insert、delete这些操作的时候,系统会自动调用执行该表上对应的触发器。
5.2 触发器的类型
(1)after/for 触发器(之后触发):insert触发器、update触发器、delete触发器
(2)instead of 触发器 (之前触发)
两种类型的区别是:After和for都是在增删改执行的时候执行另外的SQL语句,而Instead of 是使用另外的SQL语句取代原来的操作;
5.3 使用触发器
(1)触发器语法
CREATE TRIGGER triggerName ON 表名 after(for)(for与after都表示after触发器) | instead of UPDATE|INSERT|DELETE(insert,update,delete) AS begin … end
(2)after触发器实例:
假如我们有一张成绩表Score{sId,cId,grade}和学生表Student{sId,sName,sAge},其中Score中的sId是Student中的主键,即Scroe中的sId为外键。那么,现在我们有这样一个需求:在每次向成绩表中添加新数据的时候,首先判断插入的学生学号是否存在于Student表中,如果存在则显示“插入成功”,如果不存在(也就是操作人员输入有误)那么则此次新增操作作废。
CREATE TRIGGER tgForScoreOnInsert ON Score after INSERT -- 后置的新增触发器 AS Begin declare @stuid int,@courseid int--定义两个变量 select @stuid = sId,@courseid = cId from inserted--获得新增行的数据 if exists(select * from Student where sId=@stuid)--判断分数学员是否存在 print ‘插入成功’ else --如果不存在,则把更新增成功的分数记录给删除掉 delete from Score where sId = @stuid and cId = @courseid End
(3)instead of触发器实例:
由instead of触发器的定义可以知道,instead of触发器表示并不执行其定义的操作(insert、update、delete)而仅是执行触发器本身的内容。
因此,借助instead of触发器的这个特点,我们可以看看这个场景:假如我们有一张借书记录表,图书馆规定每个学生最多只能借5本书,因此我们需要在添加借书记录时首先判断该生是否已经达到了最大的借书数量,如果达到了则提示“已达到借书最大限制,无法再继续借阅”,如果没有达到才会添加到记录表中。
create trigger tgInsteadOfRecordOnInsert on Record INSTEAD OF INSERT as begin --首先在记录表中查找,判断是否还能借 if exists(select 1 from inserted a join Record b on a.cardNo=b.cardNo group by a.cardNo having count(*)>=5) --给出提示 print '已达到借书最大限制,无法再继续借阅!' else insert into Record select * from inserted end
5.4 触发器使用建议
(1)尽量避免在触发器中执行耗时操作,因为触发器会与SQL语句认为在同一个事务中。(事务不结束,就无法释放锁。)
(2)避免在触发器中做复杂操作,影响触发器性能的因素比较多(如:产品版本、所使用架构等等),要想编写高效的触发器考虑因素比较多(编写触发器容易,编写复杂的高性能触发器难!)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号