
Elastic学习之旅 (10) Logstash数据采集
 本篇我们来了解一下ElasticSearch中的数据采集神器Logstash的核心概念和基本架构,并通过一个简单的Logstash配置文件了解了如何定义Pipeline。通过使用常用的插件,基本可以满足我们日常的需求!
本篇我们来了解一下ElasticSearch中的数据采集神器Logstash的核心概念和基本架构,并通过一个简单的Logstash配置文件了解了如何定义Pipeline。通过使用常用的插件,基本可以满足我们日常的需求!
上一篇:结构化搜索
Logstash是啥?
Logstash是一款优秀的开源ETL工具/数据搜集处理引擎,可以对采集到的数据做一系列的加工和处理,目前已支持200+插件具有比较成熟的生态。
下图展示了Logstash的上下游主流生态:
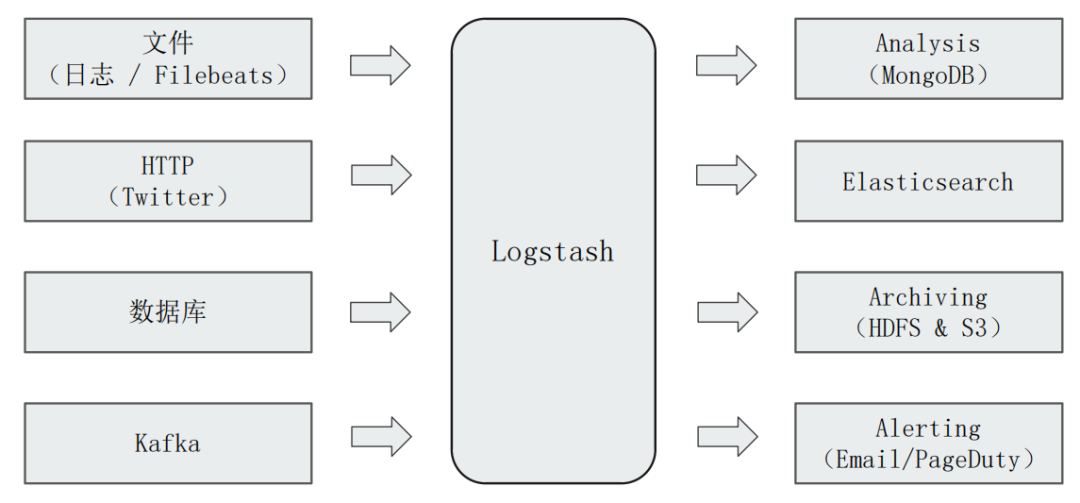
Logstash不仅可以从日志中获取数据,才可以从Kafka 甚至是 数据库中采集数据。采集到数据之后,可以转发给ElasticSearch(最常见的场景),也可以转发给MongoDB等。
Logstash的核心概念
第一个概念:Logstash Pipeline
Logstash的Pipeline包含了 input(采集) - filter(转换) - output(输出) 三个阶段的处理流程。
第二个概念:Logstash Event
数据在Pipeline内部流转时的具体表现形式就是Event,数据在input阶段被转换为Event,而在output阶段被转化成目标格式数据。
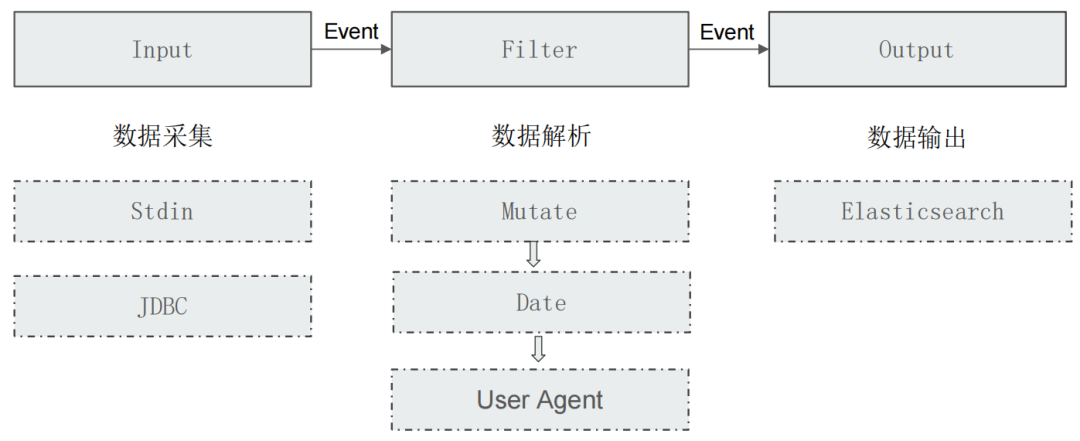
我们可以通过下图来了解Logstash的基本架构:input-filter-output三个阶段,每个阶段都可以使用一些常用插件来实现一些功能。
Logstash的配置文件
我们知道了Logstash的核心是input-filter-output的三阶段pipeline,那么对于Logstash我们要做的就是定义这个pipeline要做什么,因此我们可以来看看它的配置文件结构,如下图所示的一个logstash配置文件:
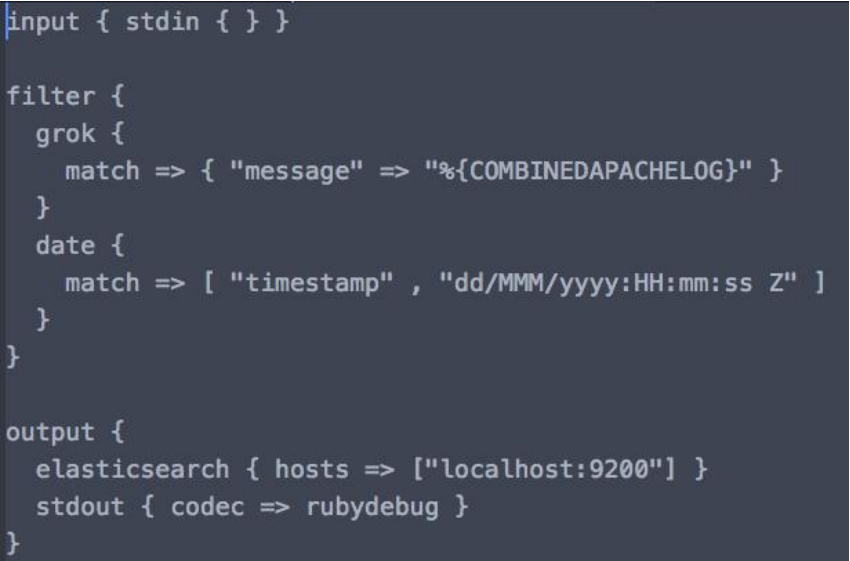
input:使用了stdin插件读取控制台的内容作为输入;
filter:使用了grok和date插件对输入的数据做了格式化的处理转换;
output:使用了elasticsearch插件将解析后的数据发送到elasticsearch,并通过stdout插件对解析后的数据调用rubydebug做一个输出;
从上面的介绍可以看出,一个Logstash Pipeline的每个阶段都可以用多个插件,完全取决于你的业务需求。
这时候,我们再来看看我们在 快速搭建ELK 中的logstash配置文件时,是不是就容易理解了?
input { file { path => "/usr/local/elastic/elk7/logstash-7.1.0/bin/movies.csv" start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," columns => ["id","content","genre"] } mutate { split => { "genre" => "|" } remove_field => ["path", "host","@timestamp","message"] } mutate { split => ["content", "("] add_field => { "title" => "%{[content][0]}"} add_field => { "year" => "%{[content][1]}"} } mutate { convert => { "year" => "integer" } strip => ["title"] remove_field => ["path", "host","@timestamp","message","content"] } } output { elasticsearch { hosts => "http://localhost:9200" index => "movies" document_id => "%{id}" } stdout {} }
小结
本篇,我们了解了ElasticSearch中的数据采集神器Logstash的核心概念和基本架构,并通过一个简单的Logstash配置文件了解了如何定义Pipeline。通过使用常用的插件,基本可以满足我们日常的需求!
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》



 浙公网安备 33010602011771号
浙公网安备 33010602011771号