
Elastic学习之旅 (2) 快速安装ELK
 本篇,我们会料了解ElasticSearch的安装方式,并通过docker-compose的方式快速搭建一个两个ES节点的ElasitcSearch + Kibana服务。然后,通过手动安装Logstash并导入测试数据集,为后续学习ElasticSearch基本概念和查询练习奠定了基础。
本篇,我们会料了解ElasticSearch的安装方式,并通过docker-compose的方式快速搭建一个两个ES节点的ElasitcSearch + Kibana服务。然后,通过手动安装Logstash并导入测试数据集,为后续学习ElasticSearch基本概念和查询练习奠定了基础。
上一篇:初识ElasticSearch
ElasticSearch的安装方式
ElasticSearch可以有多种安装方式,比如直接下载安装到宿主机进行运行,也可以通过docker的方式运行,完全取决我们的用途。这里,我们只是为了学习和练习,通过docker方式运行即可。Docker安装的前置条件
这里为了成功通过docker安装ElasticSearch+Kibana,我们需要准备一下docker和docker-compose(如果你的实验机器没有安装的话):
安装docker:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo yum -y install docker systemctl enable docker && systemctl start docker docker --version
安装docker-compose:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo yum -y install docker systemctl enable docker && systemctl start docker docker --version
这里我们通过直接运行的方式(非Docker)运行Logstash,因此这里我们安装一下JDK:
yum install java-1.8.0-openjdk java -version
修改系统参数(如果你的机器配置较低的话,比如只有2个G内存):
# 修改配置 sudo vim /etc/sysctl.conf vm.max_map_count = 655360 # 让配置生效 sudo sysctl -p
Docker安装ElasticSearch+Kibana
这里我们以ES 7.1.0版本为例,虽然它是几年前的版本了,但这里我们只是学习完全够用了。
下面是我们准备好的docker-compose.yml文件:
version: '2.2' services: kibana: image: docker.elastic.co/kibana/kibana:7.1.0 container_name: kibana7 environment: - I18N_LOCALE=en-US - XPACK_GRAPH_ENABLED=true - TIMELION_ENABLED=true - XPACK_MONITORING_COLLECTION_ENABLED="true" ports: - "5601:5601" networks: - es7net elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0 container_name: es7_01 environment: - cluster.name=edisontalk - node.name=es7_01 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - discovery.seed_hosts=es7_01,es7_02 - cluster.initial_master_nodes=es7_01,es7_02 ulimits: memlock: soft: -1 hard: -1 volumes: - es7data1:/usr/share/elasticsearch/data ports: - 9200:9200 networks: - es7net elasticsearch2: image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0 container_name: es7_02 environment: - cluster.name=edisontalk - node.name=es7_02 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - discovery.seed_hosts=es7_01,es7_02 - cluster.initial_master_nodes=es7_01,es7_02 ulimits: memlock: soft: -1 hard: -1 volumes: - es7data2:/usr/share/elasticsearch/data networks: - es7net volumes: es7data1: driver: local es7data2: driver: local networks: es7net: driver: bridge
在这个文件中,定义了两个ES实例 和 一个Kibana实例,两个ES实例组成了一个小集群,Kibana则是可视化查询工具。
这里需要注意的是参数是“ES_JAVA_OPTS”,建议将Xmx 和 Xms 设置成一样的,如这里的512M。当然,如果你的机器配置较低,建议将这两个值调的低一些,比如256M。但是,Xmx的值不要超过机器内存的50%!
运行docker-compose文件执行运行安装:
docker-compose up -d
运行后等待1分钟,通过浏览器URL访问ES实例:
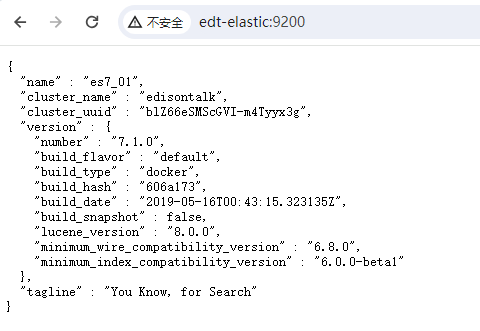
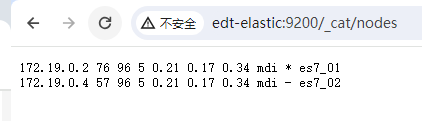
然后通过浏览器URL访问Kibana实例:
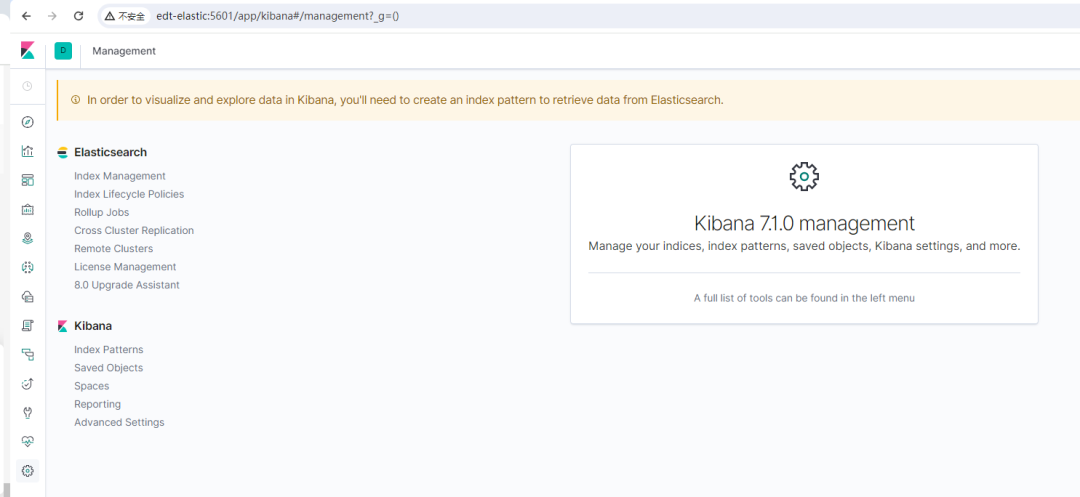
至此,你的ES+Kibana初步安装好了。
安装Logstash并导入测试数据集
这里我们再安装一个logstash,选择下载一个logstash-7.1.0安装到宿主机上的/usr/local/elastic/elk7目录下。
从这里下载logstash 7.1.0,与我们刚刚安装的ES实例保持一致:https://www.elastic.co/cn/downloads/past-releases/logstash-7-1-0
然后将其copy到你的服务器上,并进行解压:
然后准备一个logstash.conf配置文件,并copy到logstash-7.1.0/bin目录下:
input { file { path => "/usr/local/elastic/elk7/logstash-7.1.0/bin/movies.csv" start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," columns => ["id","content","genre"] } mutate { split => { "genre" => "|" } remove_field => ["path", "host","@timestamp","message"] } mutate { split => ["content", "("] add_field => { "title" => "%{[content][0]}"} add_field => { "year" => "%{[content][1]}"} } mutate { convert => { "year" => "integer" } strip => ["title"] remove_field => ["path", "host","@timestamp","message","content"] } } output { elasticsearch { hosts => "http://localhost:9200" index => "movies" document_id => "%{id}" } stdout {} }
这个配置文件定义了我们需要采集的数据的路径,为了实现测试数据集的导入,我们也需要下载一个测试数据集,这里选择的是MovieLens的开放数据集,选择其small类型的movies测试数据,将这个movices.csv数据copy到logstash-7.1.0/bin目录下即可。
数据集地址:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
这个movie.csv中包含了一些电影的id和标题,以及该电影的类别,数据格式如下:
movieId, title, genres
最后,开始运行logstash:
sudo ./logstash -f logstash.conf
稍后,我们就可以看到一条条数据被传到了ElasticSearch中:
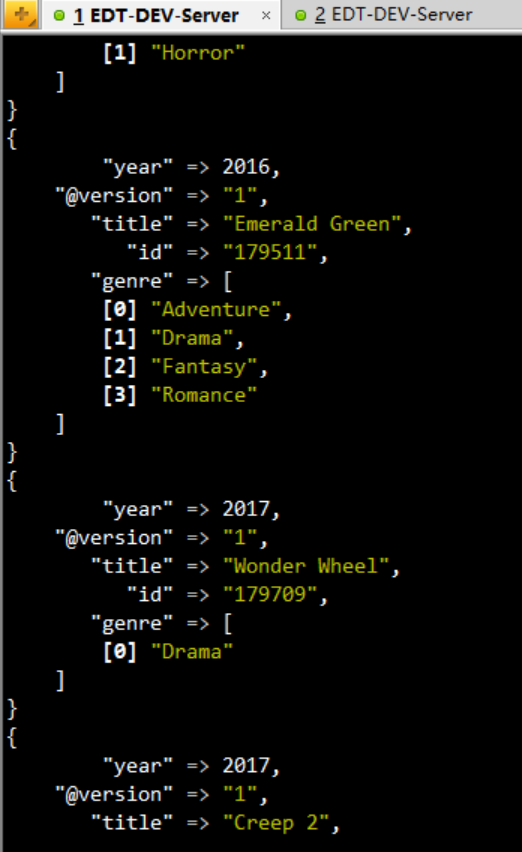
NOTE:logstash的执行比较慢,需要耐心等待一下,取决于你的测试服务器的配置了。
数据插入完成后,我们可以到Kibana的Dev Tools中验证一下:
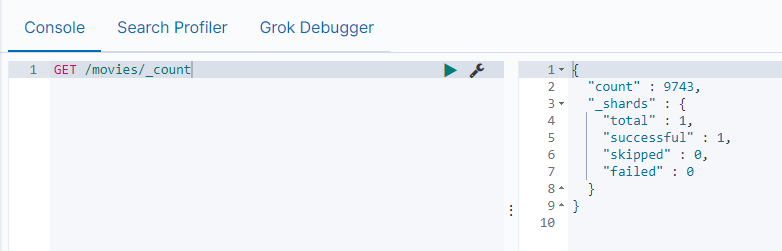
可以看到,共计9743个movie数据被传到了ElasticSearch中。
安装Cerebro可视化管理界面
Cerebro是一个常用的开源可视化管理工具,它可以对ElasticSearch进行集群监控和管理、集群配置修改、索引分片管理。
要安装Cerebro,只需要修改一下我们的docker-compose.yml,添加一个service即可:
version: '2.2' services: cerebro: image: lmenezes/cerebro:0.8.3 container_name: cerebro ports: - "9000:9000" command: - -Dhosts.0.host=http://elasticsearch:9200 networks: - es7net ......
然后重新执行以下命令即可安装:
docker-compose up -d
安装好后访问9000端口即可看到:
小结
本篇,我们了解了ElasticSearch的安装方式,并通过docker-compose的方式快速搭建了一个两个ES节点的ElasitcSearch + Kibana服务。然后,通过手动安装Logstash并导入测试数据集,为后续学习ElasticSearch基本概念和查询练习奠定了基础。
下一篇,我们就正式开始ElasticSearch的入门,先从一些常见的基本概念走起!
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》



 浙公网安备 33010602011771号
浙公网安备 33010602011771号