
3.K均值算法
作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
第一种划分:

第二种划分:

2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
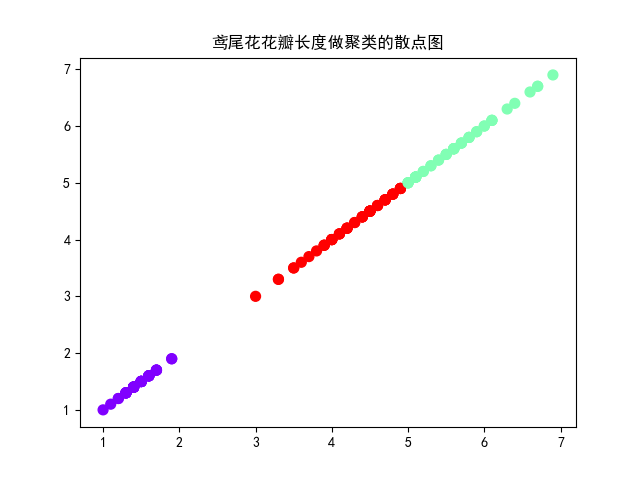
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
iris = load_iris() # 鸢尾花数据
# 特征名称(共有四个):花萼长度、花萼宽度、花瓣长度、花瓣宽度
# iris.feature_names
L0 = iris.data[:, 2] # 花瓣长度
x = L0.reshape(-1, 1) # 花瓣长度数据列
model = KMeans(n_clusters=3) # 构建模型 3类
model.fit(x) # 训练模型
pre_kmeans = model.predict(x) # 预测每个样本的聚类索引
print("预测结果:\n", pre_kmeans)
# 画图
plt.scatter(x[:, 0], x[:, 0], c=pre_kmeans, s=20, cmap='rainbow')
plt.show()
运行结果:
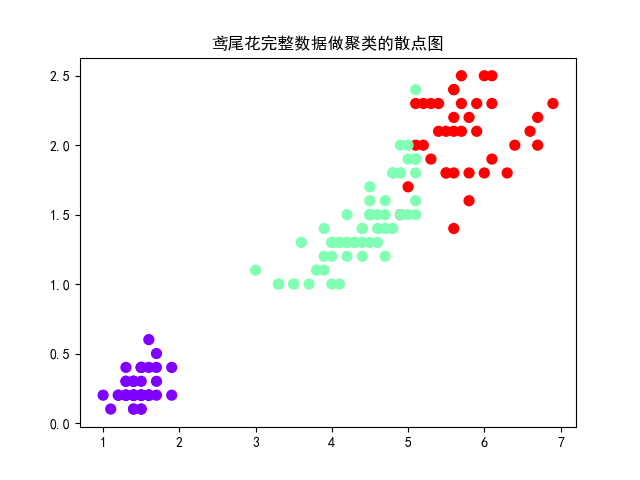
4). 鸢尾花完整数据做聚类并用散点图显示.
运行结果:
5)想想k均值算法中可以用来做什么?
均值算法是一种典型的无监督学习算法,用来对数据进行分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号