聊聊数据库~5.SQL运维上篇
1.6.SQL运维篇
运维这块逆天只能说够用,并不能说擅长,所以这篇就当抛砖之用,欢迎补充和纠错
PS:再说明下CentOS优化策略这部分的内容来源:首先这块逆天不是很擅长,所以主要是参考网上的DBA文章,之后请教了下运维相关的朋友,大家辩证看就行了,我只能保证90%的准确度(具体看业务)
1.6.1.概念
1.RAID系
RAID:磁盘冗余队列
把多个容量小的磁盘组成一组容量更大的磁盘,并提供数据冗余来保证数据完整性的技术
RAID0:数据条带(好处:成本低,应用:数据备份)
需要硬盘数>=2,数据没有冗余或修复功能,只是多个小容量变成大容量的功能
RAID1:磁盘镜像(好处:数据安全、读很快)
磁盘的数据镜像到另一个磁盘上,最大限度的保证系统的可靠性和可修复性
RAID5:分布式奇偶校验磁盘阵列(好处:性价比高,缺点:两块磁盘失效则整个卷的数据都无法恢复,应用:从数据库)
把数据分散到多个磁盘上,如果任何一个盘数据失效都可以从奇偶校验块中重建
RAID10:分片镜像(优点:读写性能良好,相对RAID5重建更简单速度更快,缺点:贵)
对磁盘先做RAID1之后对两组RAID1的磁盘再做RAID0
| RAID级别 | 特点 | 备份 | 盘数 | 读 | 写 |
|---|---|---|---|---|---|
RAID0 |
便宜,读写快,不安全 | 没有 | N | 快 | 快 |
RAID1 |
贵,高速读,最安全 | 有 | 2N | 快 | 慢 |
RAID5 |
性价比高,读快,安全 | 有 | N+1 | 快 | 取决于最慢盘 |
RAID10 |
贵,高速,安全 | 有 | 2N | 快 | 快 |
2.SAN和NAS
SAN:通过专用高速网将一个或多个网络存储设备和服务器连接起来的专用存储系统
通过光纤连接到服务器,设备通过块接口访问,服务器可以将其当做硬盘使用
NAS:连接在网络上, 具备资料存储功能的装置,以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽、提高性能、降低总拥有成本、保护投资。其成本远远低于使用服务器存储,而效率却远远高于后者
使用网络进行连接,通过基于文件协议(NFS、SMB)来访问
PS:网络存储一般都是用来搭建开发环境或者数据库备份
3.QPS和TPS
QPS(Queries Per Second):每秒钟处理的请求数(一般都是查询,但DML、DDL也包括)
eg:
10ms处理1个sql,1s处理100个sql,那么QPS<=100(100ms处理1个sql,QPS<=10)
TPS(Transactions Per Second):每秒钟系统能够处理的交易或事务的数量(每秒事务数|消息数)
一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数
PS:QPS看的多些
1.6.2.常见问题
1.超高的CPU|内存使用率:容易因CPU|内存资源耗尽而宕机
PS:如果是CPU密集型:需要更好的CPU;需要更大的并发量:需要更多的CPU(WEB项目)
MySQL有同一数据中多次写操作合并为一次写操作
2.并发量大:容易导致数据库连接数被占满
PS:MySQL的
max_connections默认是100(根据硬件条件调整)
3.磁盘IO:导致性能直线下降(热点数据内存放不下时)
解决:定期整理磁盘碎片、
RAID增强传统硬盘、SSD、Fusion-io(PCIe)、网络存储NAS or ASN
PS:SSD应用于存在大量随机IO或解决单线程IO瓶颈的场景
4.网卡流量(网络):容易出现无法连接数据库的现象
解决:
- 减少从服务器的数量
- 分级缓存(防止同一时间缓存的大量失效)
- 避免使用
select *进行查询(减少传输过程中的无用字节)- 分离业务网络和服务器网络
5.大表定义:单表数据量超过千万行 or 表数据文件超过10G
问题:大表更容易出现慢查询、DDL也很慢也容易导致其他问题
解决:分库分表(拆分为多个小表)
PS:分库分表前可以对大表的历史数据进行归档(冷热数据隔离)【核心:归档时间点的选择】
DDL影响的补充说明:
建索引很慢,而且会引起长时间的主从延迟修改表结构需要长时间锁表- 引起长时间的主从延迟
- 影响正常的数据操作
分库分表容易出现的问题:
- 分表主键的选择
- 不能保证id是全局唯一,这时候可以使用诸如
雪花算法来解决
- 不能保证id是全局唯一,这时候可以使用诸如
- 跨库跨表的join问题
- 事物问题(分布式事物诞生了)
PS:不太影响的案例:日志表(insert和select很多,很少delete和update)
6.大事务定义:运行时间较长,操作数据比较多的事物
问题:
- 锁定太多的数据,造成大量的阻塞和锁超时
- 回滚需要的时间很长(又得锁一段时间了)
- 执行时间长,容易导致主从的延迟
解决:- 避免一次处理大量数据(分批处理)
- 去除在事物中不必要的select语句(一般都是事物中使用过多查询导致的)
- PS:select完全可以在事物外查询,事物专注于写
SQL标准中定义的4种隔离级别:
- 未提交读(
read uncommited) - 已提交读(
read commited)- 不可重复读
- 可重复读(
repeatable read)innodb的默认隔离级别
- 可串行化(
serializable) - PS:隔离性低到高,
并发性高到低
PS:查看事物隔离级别-show variables like '%iso%';,设置会话的隔离级别:set session tx_isolation='read-committed'
扩展:CentOS优化策略(MySQL服务器)
1.内核相关(/etc/sysctl.conf)
查看默认值:sysctl -a
tcp相关设置:
# 三次握手listen的最大限制
net.core.somaxconn = 65535 # 默认是128
# 当网络接受速率大于内核处理速率时,允许发送到队列中的包数
net.core.netdev_max_backlog = 65535 # 默认是1000
# Linux队列的最大半连接数(超过则丢包)
net.ipv4.tcp_max_syn_backlog = 65535 # 默认是128(不适合Web服务器)
PS:这边只是一个参考,自己可以根据环境适当降低(最大端口数一般都是65535)
注意:如果是Web服务器,
net.ipv4.tcp_max_syn_backlog不宜过大(容易有synflood攻击的安全问题),net.ipv4.tcp_tw_recycle和net.ipv4.tcp_tw_reuse不建议开启
加快tcp链接回收的几个参数:
# TCP等待时间,加快tcp链接回收
net.ipv4.tcp_fin_timeout = 10 # 默认60
# 把发起关闭,但关闭没完成的TCP关闭掉
net.ipv4.tcp_tw_recycle = 1 # 默认0(不适合Web服务器)
# 允许待关闭的socket建立新的tcp
net.ipv4.tcp_tw_reuse = 1 # 默认0(不适合Web服务器)
PS:net.ipv4.tcp_tw_reuse扩展说明:主动调用closed的一方才会在接收到对端的ACK后进入time_wait状态
参考文章:
https://blog.csdn.net/weixin_41966991/article/details/81264095
缓存区大小的最大值和默认值:
net.core.wmem_default = 87380 # 默认212992
net.core.wmem_max = 16777216 # 默认212992
net.core.rmem_default = 87380 # 默认212992
net.core.rmem_max = 16777216 # 默认212992
PS:每个socket都会有一个rmem_default大小的缓存空间(如果设置了setsockopt则就是多少,最大不超过rmem_max)
减少失效连接所占用的系统资源:
# 对于tcp失效链接占用系统资源的优化,加快资源回收效率
# 链接有效时间(单位s)
net.ipv4.tcp_keepalive_time = 120 # 默认7200
# tcp未获得相应时重发间隔(单位s)
net.ipv4.tcp_keepalive_intvl = 30 # 默认75
# 重发数量(单位s)
net.ipv4.tcp_keepalive_probes = 3 # 默认9
内存相关参数:
# 共享单个共享内存下的最大值
kernel.shmmax = 4294967295 # 最大为物理内存-1byte
# 除非虚拟内存全部占满,否则不使用交换分区(为了性能)
# (free -m ==> Swap)
vm.swappiness = 0 # 默认30
PS:kernel.shmmax设置的足够大,一般就是为了容纳整个innodb的缓冲池
eg:
4G = 4*1024 M = 4*1024*1024 KB = 4*1024*1024*1024 byte = 4294967296 - 1 = 4294967295
PS:unsigned int=>[0, 2^32)=>[0,4294967296)=>[0,4294967295]巧不,一样的值
2.资源限制(/etc/security/limit.conf)
打开文件数的限制(追加到配置后即可)
# [*|%] [soft|hard] [type_item] [value]
* soft nofile 65536
* hard nofile 65535
默认值:ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 3548
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024 《《看这
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 3548
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
PS:一般来说是够用了,但是一个遇到大型数据库可能就不够看了(多表多库配置高)
*:所有用户有效、soft:当前系统生效、hard:系统中所能设置的最大值、nofile:所限制的资源是打开文件的最大数、65536:数值【重启才生效】
3.磁盘调度策略(/sys/block/devname/queue/scheduler)
现在默认策略就是deadline,所以不用优化了【对数据库支持很不错】
PS:通过cat /sys/block/sda/queue/scheduler查看([这个就是设置的值])
noop [deadline] cfq
如果不是可以通过:echo deadline > /sys/block/sda/queue/scheduler来设置
cfq:会在队列中插入一些不必要的请求,会导致相应时间加长,一般桌面系统用的比较多
noop:实现了一个FIFO队列,像电梯工作一样对IO请求进行组织,当有一个新请求到来时会合并到最近请求之后,以此保证请求同一介质(倾向于饿死读而利于写)一般闪存设备、RAM、嵌入式系统用的比较多
deadline:确保了在一个截止时间内去服务请求(可调整)默认读期限短于写期限(防止写操作因为不能被读而出现饿死的现象)
4.文件系统
Win:NTFS,Linux:EXT3|4、XFS
Linux现在基本上都是选择XFS,如果是EXT3、EXT4还需要设置一下:/etc/fstab(慎重)
/dev/sda1/ext4 noatime,nodiratime,data=writeback 1 1
PS:noatime表示不记录访问时间,nodiratime不记录目录的访问时间(可以减少一些写的操作)
不同的日志策略:
data=[wtiteback|ordered|journal]
- writeback:只有原数据写入日志,原数据写入和数据写入并不是同步的(最快)PS:Innodb有自己的事务日志,所以是最好的选择
- ordered:只会记录原数据,但提供了一些一致性的保证,在写原数据之前会先写数据,使他们保持一致(比writeback慢但更安全)
- journal:提供了原子日志的一种行为,在数据写入到最终位置之前,将记录到日志中(最慢,对Innodb来说是没有必要)
课后拓展:
TPS、并发用户数、吞吐量关系
https://www.cnblogs.com/zhengah/p/4532156.html
针对Mysql所在linux服务器的系统优化参数
https://blog.csdn.net/qq_40999403/article/details/80666102
网络优化之net.ipv4.tcp_tw_recycle参数
https://blog.csdn.net/chengm8/article/details/51668992
linux socket 缓存: core rmem_default rmem_max
https://blog.csdn.net/penzchan/article/details/41682411
Linux上的free命令详解、swap机制
http://www.cnblogs.com/xiaojianblogs/p/6254535.html
磁盘IO过高时的处理办法
https://www.cnblogs.com/wjoyxt/p/4808024.html
文件系统对性能的影响
https://blog.csdn.net/qq_30353203/article/details/78197870
1.6.3.MySQL配置参数
建议:优先从数据库设计和SQL优化着手,然后才是配置优化和存储引擎的选择,最后才是硬件提升
设计案例:
列太多不行,关联太多也不行(10个以内),不恰当的分区表,使用了外键
分区表:一个服务器下,逻辑上还是一个表,物理存储上分成了多个表(类似于SQLServer的水平分库)
PS:分库分表:物理和逻辑上都拆分成多个表了
之前讲环境的时候简单说了下最基础的
[mysqld]
# 独立表空间: 每一个表都有一个.frm表描述文件,还有一个.ibd文件
innodb_file_per_table=on
# 不对连接进行DNS解析(省时)
skip_name_resolve=on
# 配置sql_mode
sql_mode='strict_trans_tables'
然后说SQL_Mode的时候简单说了下全局参数和会话参数的设置方法:MySQL的SQL_Mode修改小计
- 全局参数设置:
set global 参数名=参数值;- 只对新会话有效,重启后失效
- 会话参数设置:
set [session] 参数名=参数值- 只对当前会话有效,其他会话不影响
这边继续说下其他几个影响较大的配置参数:(对于开发人员来说,简单了解即可,这个是DBA的事情了)
1.安全相关配置
expire_logs_days:自动清理binlog- PS:一般最少保存7天(具体根据业务来)
max_allowed_packet:配置MySQL接收包的大小- PS:默认太小。如果配置了主从,需要配置成一样大(防止丢包)
skip_name_resolve:禁用DNS查找(这个我们之前说过了,主要是提速)- PS:如果启用了,那么进行用户授权时,只能通过
ip或者ip段或者本机host出现过的域名进行授权- 用
*的是没影响的
- 用
- PS:如果启用了,那么进行用户授权时,只能通过
sysdata_is_now:保证sysdate()返回确定性日期- PS:如果主从使用了binlog的
statement模式,sysdata的结果会不一样,最后导致数据不一致- 类似的问题还有很多,eg:获取最后一次id的时候(
last_insert_id()) - 扩:现在MySQL有了
Mixed模式
- 类似的问题还有很多,eg:获取最后一次id的时候(
- PS:如果主从使用了binlog的
read_only:一般用户只能读数据,只有root用户可以写:- PS:推荐在从库中开启,这样就只接受从主库中的写操作,其它只读
- 从库授权的时候不要授予超级管理员的权限,不然这个参数相当于废了
skip_slave_start:禁用从库(Slave)自动恢复- MySQL在重启后会自动启用复制,这个可以禁止
- PS:不安全的崩溃后,复制过去的数据可能也是不安全的(手动启动更合适)
sql_mode:设置MySQL的SQL模式(这个上次说过,默认是宽松的检测,这边再补充几个)strict_trans_tables:对所有支持事物类型的表做严格约束:- 最常见,主要对事物型的存储引擎生效,其他的没效果
- PS:如果插入数据不符合规范,则中断当前操作
no_engine_subtitution:建表的时候指定不可用存储引擎会报错only_full_group_by:检验group by语句的合法性- 要求在在分组查询语句中,把所有没有使用聚合函数的列,列出来
- eg:
select count(url),name from file_records group by url;- 使用了name字段,name不是聚合函数,那必须在group by中写一下
ansi_quotes:不允许使用双引号来包含字符串- PS:防止数据库迁移的时候出错
- PS:生存环境下最好不要修改,容易报错对业务产生影响(严格变宽松没事)
PS:一般SQL_Mode是测试环境相对严格(strict_trans_tables,only_full_group_by,no_engine_subtitution,ansi_quotes),线上相对宽松(strict_trans_tables)
补充说下sysdate()和now()的区别:(看个案例就懂了)
PS:对于一个语句中调用多个函数中
now()返回的值是执行时刻的时间,而sysdate()返回的是调用该函数的时间
MariaDB [(none)]> select sysdate(),sleep(2),sysdate();
+---------------------+----------+---------------------+
| sysdate() | sleep(2) | sysdate() |
+---------------------+----------+---------------------+
| 2019-03-28 09:09:29 | 0 | 2019-03-28 09:09:31 |
+---------------------+----------+---------------------+
1 row in set (2.001 sec)
MariaDB [(none)]> select now(),sleep(2),now();
+---------------------+----------+---------------------+
| now() | sleep(2) | now() |
+---------------------+----------+---------------------+
| 2019-03-28 09:09:33 | 0 | 2019-03-28 09:09:33 |
+---------------------+----------+---------------------+
1 row in set (2.000 sec)
2.内存相关
sort_buffer_size:每个会话使用的排序缓冲区大小- PS:每个连接都分配这么多eg:1M,100个连接==>100M(默认是全部)
join_buffer_size:每个会话使用的表连接缓冲区大小- PS:给每个join的表都分配这么大,eg:1M,join了10个表==>10M
binlog_cache_size:每个会话未提交事物的缓冲区大小read_rnd_buffer_size:设置索引缓冲区大小read_buffer_size:对MyISAM全表扫描时缓冲池大小(一般都是4k的倍数)- PS:对临时表操作的时候可能会用到
read_buffer_size的扩充说明:
现在基本上都是Innodb存储引擎了,大部分的MyISAM的配置就不用管了,但是这个还是需要配置下的
引入下临时表知识扩展:
- 系统使用临时表:
- 不超过16M:系统会使用
Memory表 - 超过限制:使用
MyISAM表
- 不超过16M:系统会使用
- 自己建的临时表:(可以使用任意存储引擎)
create temporary table tb_name(列名 类型 类型修饰符,...)
PS:现在知道为啥配置read_buffer_size了吧(系统使用临时表的时候,可能会使用MyISAM)
3.IO相关参数
主要看看Innodb的IO相关配置
事物日志:(总大小:Innodb_log_file_size * Innodb_log_files_in_group)
- 事物日志大小:
Innodb_log_file_size - 事物日志个数:
Innodb_log_files_in_group
日志缓冲区大小:Innodb_log_buffer_size
一般日志先写到缓冲区中,再刷新到磁盘(一般32M~128M就够了)
知识扩展:redo Log内存中缓冲区的大小:(字节为单位)
show variables like 'innodb_log_buffer_size';- PS:以字节为单位,每隔1s就会把数据存储到磁盘上
show variables like 'innodb_log_files_in_group';- PS:有几个就产生几个
ib_logfile文件(默认是2)
- PS:有几个就产生几个
日志刷新频率:Innodb_flush_log_at_trx_commit
- 0:每秒进行一次日志写入缓存,并刷新日志到磁盘(最多丢失1s)
- 1:每次交执事物就把日志写入缓存,并刷新日志到磁盘(默认)
- 2:每次事物提交就把日志写入缓存,每秒刷新日志到磁盘(推荐)
刷新方式:Innodb_flush_method=O_DIRECT
关闭操作系统缓存(避免了操作系统和Innodb双重缓存)
如何使用表空间:Innodb_file_per_table=1
为每个innodb建立一个单独的表空间(这个基本上已经成为通用配置了)
是否使用双写缓存:Innodb_doublewrite=1(避免发生页数据损坏)
- 默认是开启的,如果出现写瓶颈或者不在意一些数据丢失可以不开启(开启后性能↑↑)
- 查看是否开启:
show variables like '%double%';
设置innodb缓冲池大小:innodb_buffer_pool_size
如果都是innodb存储引擎,这个参数的设置可以这样来算:(一般都是内存的
75%)
查看命令:show global variables like 'innodb_buffer_pool_size';
PS:缓存数据和索引(直接决定了innodb性能) 课后拓展:https://www.cnblogs.com/wanbin/p/9530833.html
innodb缓存池实例的个数:innodb_buffer_pool_instances
PS:主要目的为了减少资源锁增加并发。
每个实例的大小=总大小/实例的个数
一般来说,每个实例大小不能小于1G,而且个数不超过8个
4.其他服务器参数
sync_binlog:控制MySQL如何像磁盘中刷新binlog- 默认是0,MySQL不会主动把缓存存储到磁盘,而是靠操作系统
- PS:为了数据安全,建议主库设置为1(效率也容易降低)
- 还是那句话:一般不去管,具体看业务
- 控制内存临时表大小:
tmp_table_sizeandmax_heap_table_size- PS:建议保持两个参数一致
max_connections:设置最大连接数- 默认是100,可以根据环境调节,太大可能会导致内存溢出
Sleep等待时间:一般设置为相同值(通过连接参数区分是否是交互连接)interactive_timeout:设置交互连接的timeout时间wait_timeout:设置非交互连接的timeout时间
扩展工具:pt-config-diff
使用参考:pt-config-diff u=root,p=pass,h=localhost /etc/my.conf
eg:比较配置文件和服务器配置
pt-config-diff /etc/my.cnf h=localhost --user=root --password=pass
3 config differences
Variable /etc/my.cnf mariadb2
========================= =========== ========
max_connect_errors 2 100
rpl_semi_sync_master_e... 1 OFF
server_id 101 102
课后拓展:https://www.cndba.cn/leo1990/article/2789
扩展:常见存储引擎
常见存储引擎:
- MyISAM:不支持事物,表级锁
- 索引存储在内存中,数据放入磁盘
- 文件后缀:
frm、MYD、MYI
Innodb:事物级存储引擎,支持行级锁和事物ACID特性- 同时在内存中缓存索引和数据
- 文件后缀:
frm、ibd
Memory:表结构保存在磁盘文件中,表内容存储在内存中- Hash索引、B-Tree索引
- PS:容易丢失数据(重启后数据丢失,表结构依旧存在)
CSV:一般都是作为中间表- 以文本方式存储在文件中,不适合大表
- frm(表结构)、CSV(表内容)、CSM(元数据,eg:表状态、数据量)
- PS:不支持索引(engine=csv),所有列不能为Null
- 详细可以查看上次写的文章:小计:协同办公衍生出的需求
- Archive:数据归档(压缩)
- 文件:
.frm(存储表结构)、.arz(存储数据) - 只支持
insert和select操作 - 只允许在自增ID列上加上索引
适合场景:日志类(省空间)
- 文件:
- Federated:建立远程连接表(性能不怎样,默认禁止)
- 本地不存储数据(数据全部在远程服务器上)
- 本地需要保存表结构和远程服务器的连接信息
- PS:类似于SQLServer的链接服务器
逆天点评:除非你有100%的理由,否则全选innodb,特别不建议混合使用
Memory存储引擎
Memory存储引擎:
- 支持
Hash和BTree两种索引- Hash索引:等值查找(默认)
- Btree索引:范围查找
create index ix_name using btree on tb_name(字段,...)
- PS:不同场景下的不同选择,性能差异很大
- 所有字段类型都等同于固定长度,且不支持
Text和Blog等大字段类型- eg:
varchar(100)等价于>char(100)
- eg:
- 存储引擎使用表级锁
- PS:性能不见得比innodb好
- 大小由
max_heap_table_size决定(默认16M)- PS:如果想存大点,就得改参数(对已经存在的表不生效,需要重建才行)
- 常用场景(
数据易丢失,要保证数据可再生)- 缓存周期性聚合数据的结果
- 用于查找或者映射的表(eg:邮编和地区的对应表)
- 保存数据分析中产生的中间表
PS:现在基本上都是redis了,如果不使用redis的小项目可以考虑(eg:官网、博客...)
文章拓展:
OLAP、OLTP的介绍和比较
https://www.cnblogs.com/hhandbibi/p/7118740.html
now()与sysdate()
http://blog.itpub.net/22664653/viewspace-752576/
https://stackoverflow.com/questions/24137752/difference-between-now-sysdate-current-date-in-mysql
binlog三种模式的区别(row,statement,mixed)
https://blog.csdn.net/keda8997110/article/details/50895171/
MySQL-重做日志 redo log -原理
https://www.cnblogs.com/cuisi/p/6525077.html
详细分析MySQL事务日志(redo log和undo log)
https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html
innodb_flush_method的性能差异与File I/O
https://blog.csdn.net/melody_mr/article/details/48626685
InnoDB关键特性之double write
https://www.cnblogs.com/geaozhang/p/7241744.html
存储引擎的扩展
1.简单回顾
上节在最后的时候说了下存储引擎,这边简单回顾下:
| 存储引擎 | 是否支持事物 | 文字说明 |
|---|---|---|
MyISAM |
不支持 | MySQL5.6以前的默认存储引擎 |
CSV |
不支持 | 用CSV格式来存储数据(一般当中间表) |
Archive |
不支持 | 只能查询和添加数据(一般记录日志用) |
Memory |
不支持 | 数据只存储在内存中(容易丢失) |
innodb |
支持(行级锁) | 现在基本上都使用这个 |
NDB |
支持(行级锁) | MySQL集群才使用(内存型,数据会持久化一份) |
补充说明:
Archive存储引擎的数据会用zlib来压缩,而且只支持在自增ID上添加索引NDB存储引擎的数据存储在磁盘中(热数据存储在内存中),支持Ttree索引和集群- 场景:数据需要完全同步(这些后面会继续说的)
2.常见场景
提一个场景:innodb表无法在线修改表结构的时候怎么解决?
先看下Innodb不支持在线修改表结构都有哪些情况:(主要从性能方面考虑)
- 第一次创建
全文索引和添加空间索引(MySQL5.6以前版本不支持)- 全文索引:
create fulltext index name on table(列,...); - 空间索引:
alter table geom add spatial index(g);
- 全文索引:
- 删除主键或者添加自增列
- PS:innodb存储就是按照主键进行顺序存储的(这时候需要重新排序)
- 删除主键:
alter table 表名 drop primary key - 加自增列:
alter table 表名 add column id int auto_increment primary key
- 修改列类型、修改表字符集
- 修改列类型:
alter table 表名 modify 列名 类型 类型修饰符 - 修改字符集:
alter table 表名 character set=utf8mb4
- 修改列类型:
PS:DDL不能并发执行(表级锁)长时间的DDL操作会导致主从不一致
DDL没法进行资源限制,表数据多了容易占用大量存储IO空间(空间不够就容易执行失败)
3.解决方案
安装:yum install percona-toolkit or apt-get install percona-toolkit
PS:离线包:
https://www.percona.com/downloads/percona-toolkit/LATEST/
命令:pt-online-schema-change 选项 D=数据库,t=表名,u=用户名,p=密码
原理:先创建一个类型修改完的表,然后把旧表数据copy过去,然后删除旧表并重命名新表
查看帮助文档:pt-online-schema-change --help | more
官方文档:https://www.percona.com/doc/percona-toolkit/LATEST/pt-online-schema-change.html
PS:一般就--alter和--charset用的比较多(--execute代表执行)
常用:pt-online-schema-change --alter "DDL语句" --execute D=数据库,t=表名,u=用户名,p=密码
eg:添加新列:
pt-online-schema-change --alter "add 列名 类型" --execute D=数据库,t=表名,u=用户名,p=密码
知识回顾:
- 添加字段:add
alter table tb_name add 列名 数据类型 修饰符 [first | after 列名];- PS:SQLServer没有
[first | after 列名]
- 修改字段:alter、change、modify
- 修改字段名:
alter table tb_name change 旧列名 新列名 类型 类型修饰符 - 修改字段类型:
alter table tb_name modify 列名 类型 类型修饰符 - 添加默认值:
alter table tb_name alter 列名 set default df_value
- 修改字段名:
- 删除字段:drop
alter table tb_name drop 字段名
4.InnoDB专栏
写在前面的概念:排它锁(别名:独占锁、写锁)、共享锁(别名:读锁)
4.1.innoDB是如何实现事物的?
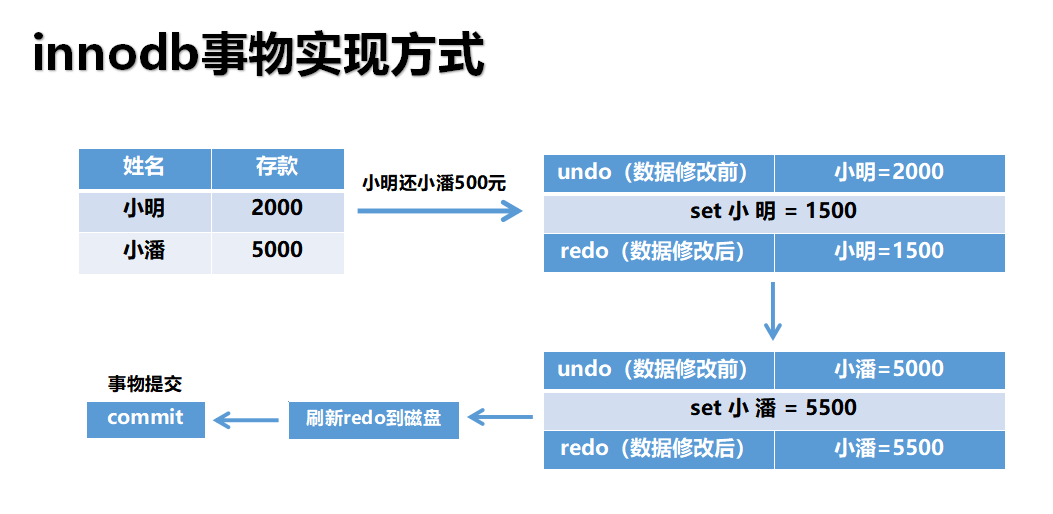
事物4大特性:A(原子性)C(一致性)I(隔离性)D(持久性)
innodb事务日志主要就是redo log(重做日志)和undo log(回滚日志)
| 事物特性 | innodb实现方式 |
|---|---|
| 原子性(A) | 回滚日志(undo log):用于记录数据修改前的状态 |
| 一致性(C) | 重做日志(redo log):用于记录数据修改后的状态 |
| 隔离性(I) | 锁(lock):用于资源隔离(共享锁 + 排他锁) |
| 持久性(D) | 重做日志(redo log) + 回滚日志(undo log) |
我画个转账案例:
4.2.innodb读操作是否会阻塞写操作?
一般情况下:查询需要对资源添加共享锁(读锁) | 修改需要对资源添加排它锁(写锁)
| 是否兼容 | 写锁 |
读锁 |
|---|---|---|
写锁 |
不兼容 | 不兼容 |
读锁 |
不兼容 | 兼容 |
PS:共享锁和共享锁之间是可以共存的(读的多并发)理论上讲读操作和写操作应该相互阻塞
而innodb看起来却仿佛打破了这个常规,看个案例:
1.启动一个事物,但是不提交
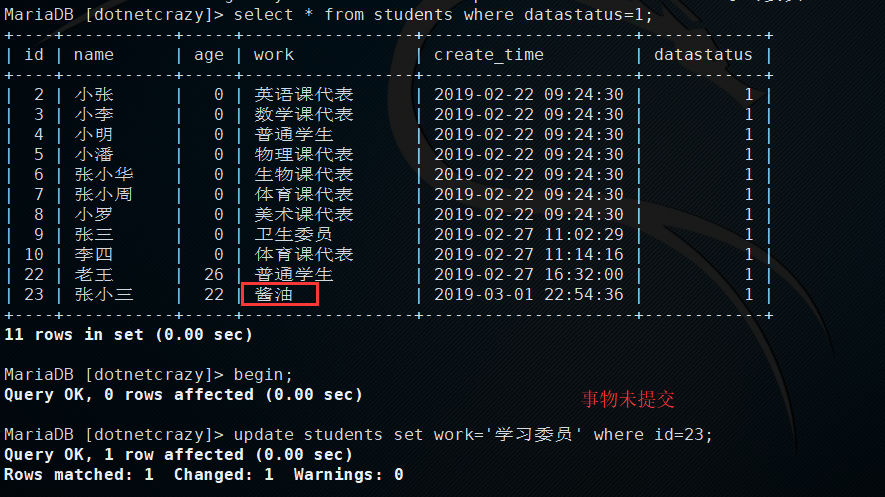
2.在另一个连接中查询
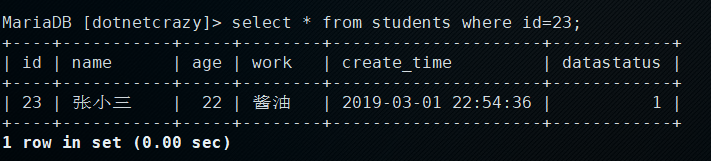
PS:理论上独占锁没提交时是不能读操作的,但innodb做了优化,会查询undo log(未修改前的数据)中的记录来提高并发性
3.提交事物后再查询,这时候就看到更新后的数据了
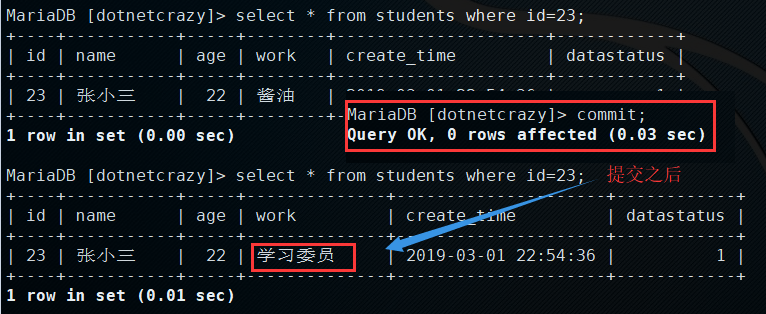
PS:这个就是innodb的MVCC(多版本并发控制)
知识拓展:
【推荐】Mysql的InnoDB事务多版本并发控制如何实现(MVCC)
https://www.cnblogs.com/aspirant/p/6920987.html
https://blog.csdn.net/u013007900/article/details/78641913
https://www.cnblogs.com/dongqingswt/p/3460440.html
https://www.jianshu.com/p/a3d49f7507ff
https://www.jianshu.com/p/a03e15e82121
https://www.jianshu.com/p/5a9c1e487ddd
基于mysql全文索引的深入理解
https://www.cnblogs.com/dreamworlds/p/5462018.html
【推荐】MySQL中的全文索引(InnoDB存储引擎)
https://www.jianshu.com/p/645402711dac
innodb的存储结构
https://www.cnblogs.com/janehoo/p/6202240.html
深入浅出空间索引:为什么需要空间索引
https://www.cnblogs.com/mafeng/p/7909426.html
常见的空间索引方法
https://blog.csdn.net/Amesteur/article/details/80392679
【推荐】pt-online-schema-change解读
https://www.cnblogs.com/xiaoyanger/p/6043986.html
pt-online-schema-change使用说明、限制与比较
https://www.cnblogs.com/erisen/p/5971416.html
pt-online-schema-change使用注意要点
https://www.jianshu.com/p/84af8b8f040b
详细分析MySQL事务日志(redo log和undo log)
https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html
1.6.4.MySQL权限相关
1.账号权限设置
之前在SQL环境篇的时候简单提了一下权限设置(点我回顾),现在再说说常用的权限知识:
1.2.创建账号
用户组成格式:用户名@可访问控制的列表
- 用户名:一般16字节
- 以
UTF-8为例:1英文字符 = 1字节,1中文 = 3字节
- 以
- 可访问控制列表:
%:所有ip都可访问(一般都这么干的,数据比较重要的推荐使用第二种)192.168.1.%:192.168.1网段的ip都可以访问- 这个不包含
localhost(数据库本地服务器不能访问)
- 这个不包含
localhost:只能通过数据库服务器进行本地访问
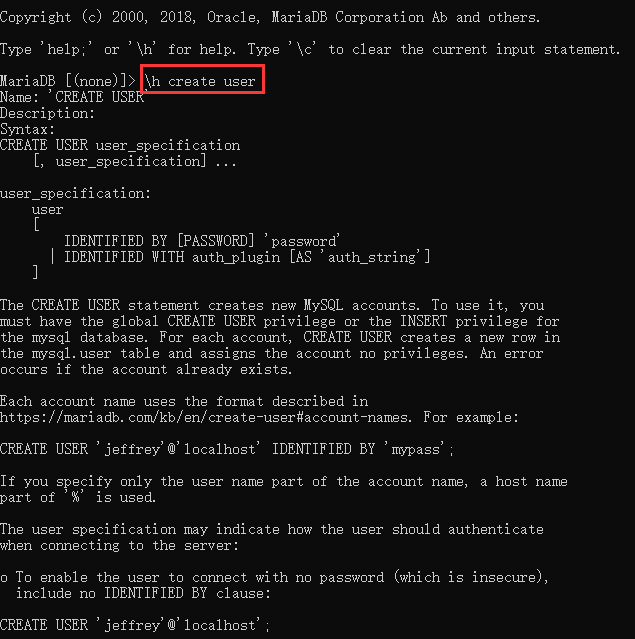
1.创建命令:create user 用户名@ip identified by '密码';
PS:可以使用
\h create user来查看帮助文档
2.查看当前用户:select user();
PS:MariaDB查看当前数据库有哪些用户:select user,password,host from mysql.user;
MySQL:
select user,authentication_string,host from mysql.user;
3.修改密码:alter user user() identified by '密码';
4.另类思路:我一般都是直接在表中插入数据(MySQL是authentication_string)
eg:
insert into mysql.user(user,host,password) values("用户名","%",password("密码"));
PS:修改密码:
update mysql.user setpassword=password('新密码') where user='用户名';
知识拓展:ERROR 1045 (28000): Access denied for user 'mysql'@'localhost'
1.3.常用权限
| 权限类别 | 语句 | 说明文字 |
|---|---|---|
admin |
create user |
创建新用户权限 |
| - | grant option |
为用户设置权限 |
| - | super |
设置服务器权限 |
DDL |
create |
创建数据库和表 |
| - | alter |
修改表结构权限 |
| - | index |
创建和删除索引 |
| - | drop |
删除数据库和表 |
DML |
select |
查询表数据权限 |
| - | insert |
插入表数据权限 |
| - | update |
删除表数据权限 |
| - | execute |
可执行存储过程 |
| - | delete |
删除表数据权限 |
补充说明:super:如设置全局变量等系统语句,一般DBA会有这个权限
PS:MariaDB查看数据库支持哪些权限:show privileges;
1.4.用户授权
权限这个东西大家都懂,一般都是最小权限
授权命令如下:grant 权限列表 on 数据库.表 to 用户名@ip
PS:开发的时候可能为了省事这么设置:
grant all [privileges] on 数据库.* to 用户名@'%';
正规点一般这么设置:
- 线上:
grant select,insert,update on 数据库.* to 用户名@ip - 开发:
grant select,insert,update,index,alter,create on 数据库.* to 用户名@ip段
PS:查看当前用户权限:show grants for 用户名;,刷新数据库权限:flush privileges;
以前可以在授权的时候直接创建用户(加一段
identified by '密码'),新版本好像分开了
1.5.权限收回
命令如下:revoke 权限列表 on 数据库.表 from 用户名@ip
eg:
revoke create,alter,delete from django.* from dnt@'%'(是from而不是on)
2.数据库账号安全
这个了解即可,我也是刚从DBA朋友那边了解到的知识(MySQL8.0),基本上用不到的,简单罗列下规范:
- 只给最小的权限(线上权限基本上都是给最低的(防黑客))
- 密码强度限制(MySQL高版本默认有限制,主要针对MariaDB)
- 密码有期限(谨慎使用,不推荐线上用户设置有效期)
- 历史密码不可用(不能重复使用旧密码)
- PS:现在用BAT的产品来修改密码基本上都是不让使用上次的密码
设置前三次使用过的密码不能再使用:create user@'%'identified by '密码' password history 3;
PS:设置用户密码过期:alter user 用户名@ip password expire;
3.迁移问题
经典问题:如何从一个实例迁移数据库账号到另一个实例?
- eg:老集群 > 新集群
官方文档:https://www.percona.com/doc/percona-toolkit/LATEST/pt-show-grants.html
3.1.版本相同
数据库备份下,然后在新环境中恢复
然后导出用户创建和授权语句:eg:pt-show-grants -u=root,-p=密码,-h=服务器地址 -P=3306
扩展文章:pt-show-grants的使用(eg:
pt-show-grants --host=192.168.36.123 --port=3306 --user=root --password=密码)
生成的脚本大致是这样的:(把脚本放新服务器中执行即可)
CREATE USER IF NOT EXISTS 'mysql.sys'@'localhost';
ALTER USER 'mysql.sys'@'localhost' IDENTIFIED WITH 'mysql_native_password' AS '*THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE' REQUIRE NONE
PASSWORD EXPIRE DEFAULT ACCOUNT LOCK;GRANT SELECT ON `sys`.`sys_config` TO 'mysql.sys'@'localhost';
GRANT TRIGGER ON `sys`.* TO 'mysql.sys'@'localhost';
GRANT USAGE ON *.* TO 'mysql.sys'@'localhost';
-- Grants for 'root'@'%'
CREATE USER IF NOT EXISTS 'root'@'%';
ALTER USER 'root'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9' REQUIRE NONE PASSWORD EXPI
RE DEFAULT ACCOUNT UNLOCK;GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
3.2.版本不同
可以使用上面的方法,但是需要使用mysql_upgrade升级下系统表(适用:低版本到高版本)但是推荐使用生成SQL脚本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号