

JVM性能优化(二)之垃圾收集器
1、垃圾是如何被发现的?
通过引用计数或者可达性分析,但是引用计数会有循环引用的问题,导致垃圾丢失。所以可达性分析更可靠,因此也就有了GCRoot。
2、那么GcRoot从哪里发起?
1)局部变量表中的变量
2)成员变量:静态变量,常量
3)本地方法栈中的变量
3、由此,垃圾回收算法引申而出:
1)标记+清除:通过可达性分析进行标记垃圾,再进行清除。但是这样会有空间碎片。
2)标记+整理:其实就是标记+清除+整理。这样的空间就连续了,但是花费时间也较多。
3)标记+复制:首先一开始就保留一定的空间,然后在清除之后,把存活的对象复制到保留的空间。(其实就是上一篇文章看到的jvm分区)
4、收集器有哪些?
单线程:serial
并发:parallel 吞吐量优先
并行:cms,G1,zgc 停顿时间优先,但是G1可以兼顾吞吐量和停顿时间。
5、G1是如何兼顾吞吐量和停顿时间的?
首先G1的堆内存空间划分与原始的划分方式不同,它没有划分新生代老年代的大小,而是一系列空间的集合,不需要连续空间,如下图:
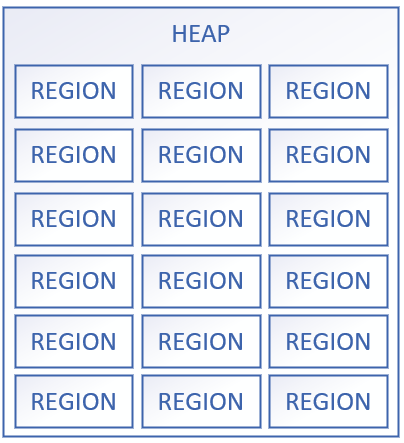
整个堆划分为N个大小相同的Region。Region的所属年代可以根据需要去变换。收集器对不同角色的Region采用不同的策略去处理。
回收过程:
1)youngGc:当Eden区满时,首先会计算当前回收大概需要的时间,如果小于我们设定的时间-XX:MaxGCPauseMills,则会扩大Eden区。再次发生gcs时如果计算出来的时间接近我们设定的值,则会触发youngGc.
2)采用标记复制算法进行GC
6、G1与cms比较
G1在垃圾收集时的内存占用和程序额外负载都比CMS要高。一般来说,小内存应用上,CMS会比G1更占用;而在大内存的服务器上(6G以上的内存),G1垃圾收集器能够发挥出更大的优势。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号