

大数据学习之Hadoop(一)
安装hadoop
1、下载安装包
2、解压
3、修改hadoop配置信息,在hadoop的安装目录下找到
/software/hadoop-2.6.0/etc/hadoop
vi hadoop-env.sh
修改JAVA_HOME
JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
4、将hadoop添加到环境变量
export HADOOP_HOME=/software/hadoop-2.6.0
export PATH=$HADOOP_HOME/bin:$PATH
5、测试运行:
1)建在 hadoop-2.7.2 文件下面创建一个 input 文件夹
2)将 hadoop 的 xml 配置文件复制到 input
cp etc/hadoop/*.xml input
3)执行 share 目录下的 mapreduce 程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
4)查看输出结果
cat output/*
6、启动HDFS
1)cd /software/hadoop-2.6.0/etc/hadoop
配置:core-site.xml
configurations中添加:
<!-- 指定 HDFS 中 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:8020</value> </property>
<!-- 指定 hadoop 运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/app/tmp</value> </property>
2)配置hdfs-site.xml
<!-- 指定 HDFS 副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property>
<property>
<name>dfs .namenode.http-address</name>
<value>localhost:50070</value>
</property>
3)启动
(3.1)格式化 namenode(第一次启动时格式化,以后不需要)
bin/hdfs namenode -format

格式化成功
(3.2)启动
sbin/start-dfs.sh
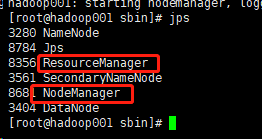
然后jsp看一下是否启动成功
问题来了:我的宿主机没法访问
然后我修改主机域名,修改host配置,关闭防火墙systemctl stop firewalld,最终可以访问了http://192.168.1.25:50070/dfshealth.html#tab-overview
7、启动yarn
1)cp mapred-site.xml.template mapred-site.xml
添加:(这个作用是指定mapreduce的调度框架是yarn)
<!-- 指定 mr 运行在 yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
2)配置 yarn-site.xml
<!-- reducer 获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
3)启动:./start-yarn.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号