手把手教你用Pytorch-Transformers——部分源码解读及相关说明(一)
简介
Transformers是一个用于自然语言处理(NLP)的Python第三方库,实现Bert、GPT-2和XLNET等比较新的模型,支持TensorFlow和PyTorch。本文介对这个库进行部分代码解读,目前文章只针对Bert,其他模型看心情。
手把手教你用PyTorch-Transformers是我记录和分享自己使用 Transformers 的经验和想法,因为个人时间原因不能面面俱到,有时间再填
本文是《手把手教你用Pytorch-Transformers》的第一篇,主要对一些源码进行讲解
目前只对 Bert 相关的代码和原理进行说明,GPT2 和 XLNET 应该是没空写了
实战篇手把手教你用Pytorch-Transformers——实战(二)已经完成一部分
Model相关
BertConfig
BertConfig 是一个配置类,存放了 BertModel 的配置。比如:
- vocab_size_or_config_json_file:字典大小,默认30522
- hidden_size:Encoder 和 Pooler 层的大小,默认768
- num_hidden_layers:Encoder 的隐藏层数,默认12
- num_attention_heads:每个 Encoder 中 attention 层的 head 数,默认12
完整内容可以参考:https://huggingface.co/transformers/v2.1.1/model_doc/bert.html#bertconfig
BertModel
实现了基本的Bert模型,从构造函数可以看到用到了embeddings,encoder和pooler。
下面是允许输入到模型中的参数,模型至少需要有1个输入: input_ids 或 input_embeds。
- input_ids 就是一连串 token 在字典中的对应id。形状为 (batch_size, sequence_length)。
- token_type_ids 可选。就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示属于第二句)。形状为(batch_size, sequence_length)。
Bert 的输入需要用 [CLS] 和 [SEP] 进行标记,开头用 [CLS],句子结尾用 [SEP]
两个句子:
tokens:[CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
token_type_ids:0 0 0 0 0 0 0 0 1 1 1 1 1 1
一个句子:
tokens:[CLS] the dog is hairy . [SEP]
token_type_ids:0 0 0 0 0 0 0
- attention_mask 可选。各元素的值为 0 或 1 ,避免在 padding 的 token 上计算 attention(1不进行masked,0则masked)。形状为(batch_size, sequence_length)。
- position_ids 可选。表示 token 在句子中的位置id。形状为(batch_size, sequence_length)。形状为(batch_size, sequence_length)。
- head_mask 可选。各元素的值为 0 或 1 ,1 表示 head 有效,0无效。形状为(num_heads,)或(num_layers, num_heads)。
- input_embeds 可选。替代 input_ids,我们可以直接输入 Embedding 后的 Tensor。形状为(batch_size, sequence_length, embedding_dim)。
- encoder_hidden_states 可选。encoder 最后一层输出的隐藏状态序列,模型配置为 decoder 时使用。形状为(batch_size, sequence_length, hidden_size)。
- encoder_attention_mask 可选。避免在 padding 的 token 上计算 attention,模型配置为 decoder 时使用。形状为(batch_size, sequence_length)。
encoder_hidden_states 和 encoder_attention_mask 可以结合论文中的Figure 1理解,左边为 encoder,右边为 decoder。
论文《Attention Is All You Need》:https://arxiv.org/pdf/1706.03762.pdf
如果要作为 decoder ,模型需要通过 BertConfig 设置 is_decoder 为 True
def __init__(self, config): super(BertModel, self).__init__(config) self.config = config self.embeddings = BertEmbeddings(config) self.encoder = BertEncoder(config) self.pooler = BertPooler(config) self.init_weights() def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, encoder_hidden_states=None, encoder_attention_mask=None): ...
BertPooler
在Bert中,pool的作用是,输出的时候,用一个全连接层将整个句子的信息用第一个token来表示,源码如下
每个 token 上的输出大小都是 hidden_size (在BERT Base中是768)
class BertPooler(nn.Module): def __init__(self, config): super(BertPooler, self).__init__() self.dense = nn.Linear(config.hidden_size, config.hidden_size) self.activation = nn.Tanh() def forward(self, hidden_states): # We "pool" the model by simply taking the hidden state corresponding # to the first token. first_token_tensor = hidden_states[:, 0] pooled_output = self.dense(first_token_tensor) pooled_output = self.activation(pooled_output) return pooled_output
所以在分类任务中,Bert只取出第一个token的输出再经过一个网络进行分类就可以了,就像之前的文章中谈到的垃圾邮件识别
BertForSequenceClassification
BertForSequenceClassification 是一个已经实现好的用来进行文本分类的类,一般用来进行文本分类任务。构造函数如下
def __init__(self, config): super(BertForSequenceClassification, self).__init__(config) self.num_labels = config.num_labels self.bert = BertModel(config) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(config.hidden_size, self.config.num_labels) self.init_weights()
我们可以通过 num_labels 传递分类的类别数,从构造函数可以看出这个类大致由3部分组成,1个是Bert,1个是Dropout,1个是用于分类的线性分类器Linear。
Bert用于提取文本特征进行Embedding,Dropout防止过拟合,Linear是一个弱分类器,进行分类,如果需要用更复杂的网络结构进行分类可以参考它进行改写。
他的 forward() 函数里面已经定义了损失函数,训练时可以不用自己额外实现,返回值包括4个内容
def forward(...): ... if labels is not None: if self.num_labels == 1: # We are doing regression loss_fct = MSELoss() loss = loss_fct(logits.view(-1), labels.view(-1)) else: loss_fct = CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1)) outputs = (loss,) + outputs return outputs # (loss), logits, (hidden_states), (attentions)
其中 hidden-states 和 attentions 不一定存在
BertForTokenClassification
BertForSequenceClassification 是一个已经实现好的在 token 级别上进行文本分类的类,一般用来进行序列标注任务。构造函数如下。
代码基本和 BertForSequenceClassification 是一样的
def __init__(self, config): super(BertForTokenClassification, self).__init__(config) self.num_labels = config.num_labels self.bert = BertModel(config) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(config.hidden_size, config.num_labels) self.init_weights()
不同点在于 BertForSequenceClassification 我们只用到了第一个 token 的输出(经过 pooler 包含了整个句子的信息)
下面是 BertForSequenceClassification 的中 forward() 函数的部分代码
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds) pooled_output = outputs[1]
bert 是一个 BertModel 的实例,它的输出有4个部分,如下所示
def forward(...): ... return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
从上面可以看到 BertForSequenceClassification 用到的是 pooled_output,即用1个位置上的输出表示整个句子的含义
下面是 BertForTokenClassification 的中 forward() 函数的部分代码,它用到的是全部 token 上的输出。
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds) sequence_output = outputs[0]
BertForQuestionAnswering
实现好的用来做QA(span extraction,片段提取)任务的类。
有多种方法可以根据文本回答问题,一个简单的情况就是将任务简化为片段提取
这种任务,输入以 上下文+问题 的形式出现。输出是一对整数,表示答案在文本中的开头和结束位置

图片来自:https://blog.csdn.net/weixin_37923278/article/details/103006269
参考文章:https://blog.scaleway.com/2019/understanding-text-with-bert/
example:
文本:
Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.
问题:
The Basilica of the Sacred heart at Notre Dame is beside to which structure?
答案:
start_position: 49,end_position: 51(按单词计算的)49-51 是 the Main Building 这3个单词在句中的索引
下面是它的构造函数,和 Classification 相比,这里没有 Dropout 层
def __init__(self, config): super(BertForQuestionAnswering, self).__init__(config) self.num_labels = config.num_labels self.bert = BertModel(config) self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels) self.init_weights()
模型的输入多了两个,start_positions 和 end_positions ,它们的形状都是 (batch_size,)
start_positions 标记 span 的开始位置(索引),end_positions 标记 span 的结束位置(索引),被标记的 token 用于计算损失
即答案在文本中开始的位置和结束的位置,如果答案不在文本中,应设为0
除了 start 和 end 标记的那段序列外,其他位置上的 token 不会被用来计算损失。
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None,
inputs_embeds=None, start_positions=None, end_positions=None): ...
可以参考下图帮助理解
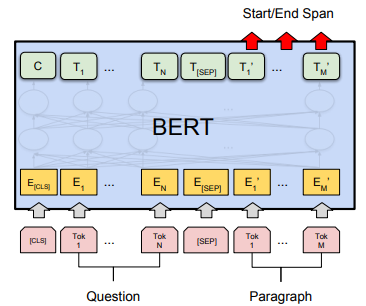
图片来自Bert原论文:https://arxiv.org/pdf/1810.04805.pdf
从图中可以看到,QA 任务的输入是两个句子,用 [SEP] 分隔,第一个句子是问题(Question),第二个句子是含有答案的上下文(Paragraph)
输出是作为答案开始和结束的可能性(Start/End Span)
BertForMultipleChoice
实现好的用来做多选任务的,比如SWAG和MRPC等,用来句子对判断语义、情感等是否相同
下面是它的构造函数,可以到看到只有1个输出,用来输出情感、语义相同的概率
def __init__(self, config): super(BertForMultipleChoice, self).__init__(config) self.bert = BertModel(config) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(config.hidden_size, 1) self.init_weights()
一个简单的例子
example:
tokenizer = BertTokenizer("vocab.txt")
model = BertForMultipleChoice.from_pretrained("bert-base-uncased")
choices = ["Hello, my dog is cute", "Hello, my cat is pretty"]
input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # 形状为[1, 2, 7]
labels = torch.tensor(1).unsqueeze(0)
outputs = model(input_ids, labels=labels)
BertForMultipleChoice 也是用到经过 Pooled 的 Bert 输出,forward() 函数同样返回 4 个内容
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, labels=None): ... pooled_output = outputs[1] ... return outputs # (loss), reshaped_logits, (hidden_states), (attentions)
tokenization相关
对于文本,常见的操作是分词然后将 词-id 用字典保存,再将分词后的词用 id 表示,然后经过 Embedding 输入到模型中。
Bert 也不例外,但是 Bert 能以 字级别 作为输入,在处理中文文本时我们可以不用先分词,直接用 Bert 将文本转换为 token,然后用相应的 id 表示。
tokenization 库就是用来将文本切割成为 字或词 的,下面对其进行简单的介绍
BasicTokenizer
基本的 tokenization 类,构造函数可以接收以下3个参数
- do_lower_case:是否将输入转换为小写,默认True
- never_split:可选。输入一个列表,列表内容为不进行 tokenization 的单词
- tokenize_chinese_chars:可选。是否对中文进行 tokenization,默认True
tokenize() 函数是用来 tokenization 的,这里的 tokenize 仅仅使用空格作为分隔符,输入的文本会先进行一些数据处理,处理掉无效字符并将空白符(“\t”,“\n”等)统一替换为空格。如果 tokenize_chinese_chars 为 True,则会在每个中文“字”的前后增加空格,然后用 whitespace_tokenize() 进行 tokenization,因为增加了空格,空白符又都统一换成了空格,实际上 whitespace_tokenize() 就是用了 Python 自带的 split() 函数,处理前用先 strip() 去除了文本前后的空白符。whitespace_tokenize() 的函数内容如下:
def whitespace_tokenize(text): """Runs basic whitespace cleaning and splitting on a piece of text.""" text = text.strip() if not text: return [] tokens = text.split() return tokens
用 split() 进行拆分后,还会将 标点符号 从文本中拆分出来(不是去除)
example:① → ② → ③
① "Hello, Marry!"
② ["Hello,", "Marry!"]
③ ["Hello", ",", "Marry", "!"]
WordpieceTokenizer
WordpieceTokenizer 对文本进行 wordpiece tokenization,接收的文本最好先经过 BasicTokenizer 处理
wordpiece简介:https://www.jianshu.com/p/60fc9253a0bf
简单说就是把 单词 变成一片一片的,在BERT实战——基于Keras一文中,2.1节我们使用的 tokenizer 就是这样的
它将 “unaffable” 分割成了 “un”, “##aff” 和 “##able”
他的构造函数可以接收下面的 3 个参数
- vocab:给定一个字典用来 wordpiece tokenization
- unk_token:碰到字典中没有的字,用来表示未知字符,比如用 "[UNK]" 表示未知字符
- max_input_chars_per_word:每个单词最大的字符数,如果超过这个长度用 unk_token 对应的 字符 表示,默认100
tokenize()函数
这个类的 tokenize() 函数使用 贪婪最长匹配优先算法(greedy longest-match-first algorithm) 将一段文本进行 tokenization ,变成相应的 wordpiece,一般针对英文
example :
input = "unaffable" → output = ["un", "##aff", "##able"]
BertTokenizer
一个专为 Bert 使用的 tokenization 类,使用 Bert 的时候一般情况下用这个就可以了,构造函数可以传入以下参数
- vocab_file:一个字典文件,每一行对应一个 wordpiece
- do_lower_case:是否将输入统一用小写表示,默认True
- do_basic_tokenize:在使用 WordPiece 之前是否先用 BasicTokenize
- max_len:序列的最大长度
- never_split:一个列表,传入不进行 tokenization 的单词,只有在 do_wordpiece_only 为 False 时有效
我们可以使用 tokenize() 函数对文本进行 tokenization,也可以通过 encode() 函数对 文本 进行 tokenization 并将 token 用相应的 id 表示,然后输入到 Bert 模型中
BertTokenizer 的 tokenize() 函数会用到 WordpieceTokenizer 和 BasicTokenizer 进行 tokenization(实际上由 _tokenize() 函数调用)
_tokenize() 函数的代码如下,其中basic_tokenizer 和 wordpiece_tokenizer 分别是 BasicTokenizer 和 WordpieceTokenizer 的实例。
def _tokenize(self, text): split_tokens = [] if self.do_basic_tokenize: for token in self.basic_tokenizer.tokenize(text, never_split=self.all_special_tokens): for sub_token in self.wordpiece_tokenizer.tokenize(token): split_tokens.append(sub_token) else: split_tokens = self.wordpiece_tokenizer.tokenize(text) return split_tokens
使用 encode() 函数将 tokenization 后的内容用相应的 id 表示,主要由以下参数:
- text:要编码的一个文本(第一句话)
- text_pair:可选。要编码的另一个文本(第二句话)
- add_special_tokens:编码后,序列前后是否添上特殊符号的id,比如前面添加[CLS],结尾添加[SEP]
- max_length:可选。序列的最大长度
- truncation_strategy:与 max_length 结合使用的,采取的截断策略。
- 'longest_first':迭代减少序列长度,直到小于 max_length,适用于输入两个文本的情况,处理后两个文本的序列长度之和是 max_length
- 'only_first':仅截断第一个文本
- 'only_second':仅截断第二个文本
- 'do_not_truncate':不截断,如果输入序列大于 max_length 则会报错
- return_tensors:可选。返回 TensorFlow (传入'tf')还是 PyTorch(传入'pt') 中的 Tensor,而不是返回 Python 列表,前提是已经装好 TensorFlow 或 PyTorch
注意 encode 只会返回 token id,Bert 我们还需要输入句子 id,这时候我们可以使用 encode_plus(),它返回 token id 和 句子 id
encode() 实际上就是用了 encode_plus,但是只选择返回 token_id,代码如下
...
encoded_inputs = self.encode_plus(text, text_pair=text_pair, max_length=max_length, add_special_tokens=add_special_tokens, stride=stride, truncation_strategy=truncation_strategy, return_tensors=return_tensors, **kwargs) return encoded_inputs["input_ids"]
encode_plus() 的参数与 encode 是一样的,可以根据实际需求来选择需要使用的函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号