Embedding和Word2Vec实战
在之前的文章中谈到了文本向量化的一些基本原理和概念,本文将介绍Word2Vec的代码实现
Word2Vec论文地址
Embedding
与one-hot编码相比,词嵌入可以将更多的信息塞入更低的维度中
下面我们用 Keras 完成一个词嵌入的学习,Keras 的 Embedding 层的输入是一个二维整数张量, 形状为(samples,sequence_length),即(样本数,序列长度)
较短的序列应该用 0 填充,较长的序列应该被截断,保证输入的序列长度是相同的
Embedding 层输出是(samples,sequence_length,embedding_dimensionality) 的三维浮点数张量。
- 首先,我们需要对文本进行分词处理,然后对分词结果进行序列化
- 再统一输入的序列长度,最后把统一长度的序列化结果输入到 Embedding 层中
整个过程可以用下面的图描述

从样本的角度看,我们可以用下面的图描述这个过程
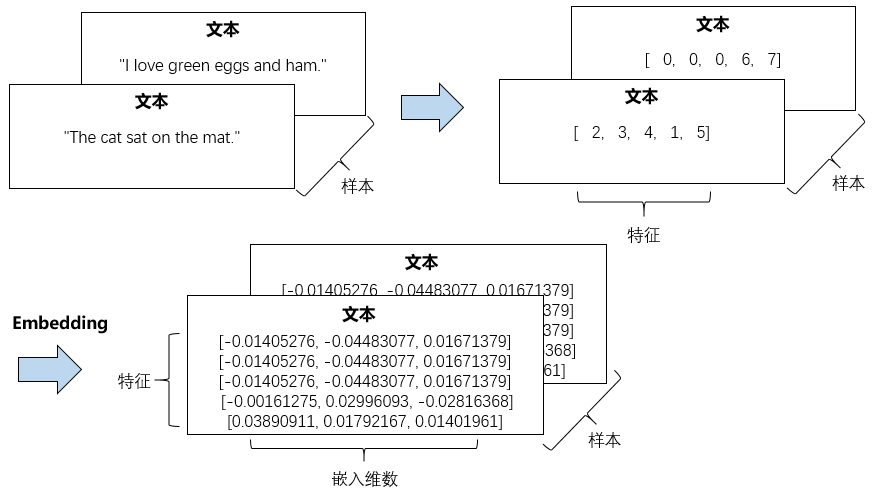
示意代码如下
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.models import Sequential from keras.layers import Embedding, Flatten, Dense docs = ["The cat sat on the mat.", "I love green eggs and ham."] # 只考虑最常见的8个单词 max_words = 8 # 统一的序列化长度 # 大于这个长度截断,小于这个长度用0补全 maxlen = 5 # 嵌入的维度 embedding_dim = 3 # 分词 tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(docs) # 字典 word_index = tokenizer.word_index # 序列化 sequences = tokenizer.texts_to_sequences(docs) # 统一序列长度 data = pad_sequences(sequences, maxlen=maxlen) # Embedding模型 model = Sequential() # Embedding至少需要max_wrods和embedding_dim两个参数 model.add(Embedding(max_words, embedding_dim, input_length=maxlen, name='embedding')) model.compile('rmsprop', 'mse') out = model.predict(data) print(out) print(out.shape) # 查看权重 layer = model.get_layer('embedding') print(layer.get_weights())
刚刚对Keras中的一些文本处理模块和Embedding做了简单的说明和演示
在Embedding层后面可以跟上神经网络,完成各种文本任务
下面使用IMDB电影评论做一个情感预测任务
from keras.datasets import imdb from keras import preprocessing from keras.models import Sequential from keras.layers import Flatten, Dense, Embedding # 特征单词数 max_words = 10000 # 在20单词后截断文本 # 这些单词都属于max_words中的单词 maxlen = 20 # 嵌入维度 embedding_dim = 8 # 加载数据集 # 加载的数据已经序列化过了,每个样本都是一个sequence列表 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_words) # 统计序列长度,将数据集转换成形状为(samples,maxlen)的二维整数张量 x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # 构建模型 model = Sequential() model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) # 将3维的嵌入张量展平成形状为(samples,maxlen * embedding_dim)的二维张量 model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
我们只是简单测试一下,我们最后得到的效果如下图所示,这是只看前20个(maxlen为20)单词的效果

如果增加到50个单词,验证集就达到了80%的正确率

Word2Vec
gensim实现Word2Vec
gensim库提供了一个word2vec的实现,我们使用几个API就可以方便地完成word2vec
from gensim.models import Word2Vec import re documents = ["The cat sat on the mat.", "I love green eggs and ham."] sentences = [] # 去标点符号 stop = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+' for doc in documents: doc = re.sub(stop, '', doc) sentences.append(doc.split())
#sentences = [["The", "cat", "sat", "on", "the", "mat"], # ["I", "love", "green", "eggs", "and", "ham"]] # size嵌入的维度,window窗口大小,workers训练线程数 # 忽略单词出现频率小于min_count的单词 # sg=1使用Skip-Gram,否则使用CBOW model = Word2Vec(sentences, size=5, window=1, min_count=1, workers=4, sg=1)
print(model.wv['cat'])
训练得到Word2Vec模型后,我们在Keras的Embedding层中使用这个Word2Vec得到的权重
再利用神经网络或其他方法去完成各种文本任务
Keras的Embedding和Word2Vec
我们去kaggle上下IMDB的电影评论数据集,用这个数据集来学习
因为在自己电脑上跑程序,没有用服务器,本文只取了前100条用来学习
下面是kaggle上别人用这个数据集做的实验
https://www.kaggle.com/alexcherniuk/imdb-review-word2vec-bilstm-99-acc/data
import pandas as pd import re from gensim.models import Word2Vec from keras.preprocessing.sequence import pad_sequences from sklearn.model_selection import train_test_split from keras.models import Sequential from keras.layers import Embedding, Flatten, Dense """ 读取训练集并构造训练样本 """ def split_sentence(sentence): stop = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+' sentence = re.sub(stop, '', sentence) return sentence.split() data = pd.read_csv(r"F:\pythonWP\keras\blog\labeledTrainData.tsv", sep='\t') data = data[:100] sentences = data.review.apply(split_sentence) """ 训练Word2Vec """ # 嵌入的维度 embedding_vector_size = 10 w2v_model = Word2Vec( sentences=sentences, size=embedding_vector_size, min_count=1, window=3, workers=4) # 取得所有单词 vocab_list = list(w2v_model.wv.vocab.keys()) # 每个词语对应的索引 word_index = {word: index for index, word in enumerate(vocab_list)} # 序列化 def get_index(sentence): global word_index sequence = [] for word in sentence: try: sequence.append(word_index[word]) except KeyError: pass return sequence X_data = list(map(get_index, sentences)) # 截长补短 maxlen = 150 X_pad = pad_sequences(X_data, maxlen=maxlen) # 取得标签 Y = data.sentiment.values # 划分数据集 X_train, X_test, Y_train, Y_test = train_test_split( X_pad, Y, test_size=0.2, random_state=42) """ 构建分类模型 """ # 让 Keras 的 Embedding 层使用训练好的Word2Vec权重 embedding_matrix = w2v_model.wv.vectors model = Sequential() model.add(Embedding( input_dim=embedding_matrix.shape[0], output_dim=embedding_matrix.shape[1], input_length=maxlen, weights=[embedding_matrix], trainable=False)) model.add(Flatten()) model.add(Dense(5)) model.add(Dense(1, activation='sigmoid')) model.compile( loss="binary_crossentropy", optimizer='adam', metrics=['accuracy']) history = model.fit( x=X_train, y=Y_train, validation_data=(X_test, Y_test), batch_size=4, epochs=10)
由于训练样本少,得到的模型没有太大意义,波动也大,仅用来学习。整个训练集的使用可以去上面分享的链接去看kaggle上别人的实验

LSTM和Word2Vec实现电影评论情感分析
数据集还是使用的跟上面是一样的,kaggle 上 IMDB 的电影评论数据集。下面的代码是在服务器上测试的。
在建模之前,需要进行简单的数据处理,这是其中一条评论。可以看到,里面还有存在 html 的标签 <br />还有许多标点符号 \\ 、 " 和 () 等等
'<br /><br />This movie is full of references. Like \\Mad Max II\\", \\"The wild one\\" and many others. The ladybug´s face it´s a clear reference (or tribute) to Peter Lorre. This movie is a masterpiece. We´ll talk much more about in the future."'
我们预处理首先就要去掉 html 标签和这些标点符号,标点符号保留 “-” 和 “´” 下进行测试
- 一些缩写会用到上引号,如 We´ll
- 一些短语会用到小横杆,比如 heavy-handed
另外,为了简化训练词向量和模型训练的过程,还进行了其他处理,比如转换为小写和词性还原。然后使用停用词库去除一些对 情感分析 用处不大的词。
比如a, an, the 等
停用词库简单使用了 sklearn 中自带的停用词。预处理代码如下
import pandas as pd import re from sklearn.feature_extraction import text from nltk.stem import WordNetLemmatizer # 读取数据 data = pd.read_csv(r"./data/labeledTrainData.tsv", sep='\t') def clean_review(raw_review: str) -> str: # 1. 评论是爬虫抓取的,存在一些 html 标签,需要去掉 review_text = raw_review.replace("<br />", '') # 2. 标点符号只保留 “-” 和 上单引号 review_text = rex.sub(' ', review_text) # 3. 全部变成小写 review_text = review_text.lower() # 4. 分词 word_list = review_text.split() # 5. 词性还原 tokens = list(map(lemmatizer.lemmatize, word_list)) lemmatized_tokens = list(map(lambda x: lemmatizer.lemmatize(x, "v"), tokens)) # 6. 去停用词 meaningful_words = list(filter(lambda x: not x in stop_words, lemmatized_tokens)) return meaningful_words stop_words = set(text.ENGLISH_STOP_WORDS) rex = re.compile(r'[!"#$%&\()*+,./:;<=>?@\\^_{|}~]+') lemmatizer = WordNetLemmatizer() sentences = data.review.apply(clean_review)
训练 Word2Vec 获取词向量
from gensim.models import Word2Vec embedding_vector_size = 256 w2v_model = Word2Vec( sentences=sentences, size=embedding_vector_size, min_count=3, window=5, workers=4)
查看预处理完每句话大概有多少个单词
cal_len = pd.DataFrame() cal_len['review_lenght'] = list(map(len, sentences)) print("中位数:", cal_len['review_lenght'].median()) print("均值数:", cal_len['review_lenght'].mean()) del cal_len
中位数: 82.0 均值数: 110.52928
用 数字索引 表示原来的句子
from keras.preprocessing.sequence import pad_sequences from sklearn.model_selection import train_test_split # 取得所有单词 vocab_list = list(w2v_model.wv.vocab.keys()) # 每个词语对应的索引 word_index = {word: index for index, word in enumerate(vocab_list)} # 序列化 def get_index(sentence): global word_index sequence = [] for word in sentence: try: sequence.append(word_index[word]) except KeyError: pass return sequence X_data = list(map(get_index, sentences)) # 截长补短 # max_len 根据中位数和平均值得来的 maxlen = 100 X_pad = pad_sequences(X_data, maxlen=maxlen) # 取得标签 Y = data.sentiment.values # 划分数据集 X_train, X_test, Y_train, Y_test = train_test_split( X_pad, Y, test_size=0.2, random_state=42)
构建和训练模型
from keras.models import Sequential from keras.layers import Embedding, Bidirectional, LSTM, Dropout, Dense # 让 Keras 的 Embedding 层使用训练好的Word2Vec权重 embedding_matrix = w2v_model.wv.vectors model = Sequential() model.add(Embedding( input_dim=embedding_matrix.shape[0], output_dim=embedding_matrix.shape[1], input_length=maxlen, weights=[embedding_matrix], trainable=False)) model.add(Bidirectional(LSTM(128, recurrent_dropout=0.1))) model.add(Dropout(0.25)) model.add(Dense(128, activation='sigmoid')) model.add(Dropout(0.3)) model.add(Dense(1, activation='sigmoid')) model.compile( loss="binary_crossentropy", optimizer='adam', metrics=['accuracy'] ) history = model.fit( x=X_train, y=Y_train, validation_data=(X_test, Y_test), batch_size=50, epochs=8 )
实验结果,准确率81左右


 浙公网安备 33010602011771号
浙公网安备 33010602011771号