实验六
实验内容
实验一 :控制器设计实验
整体方案设计
输入输出引脚
- opcode:7位输入的操作码
- func3:三位功能码,补充opcode相同的指令的功能
- func7:七位功能码,补充opcode和func3均相同的指令的功能
- ExtOp : 宽度为 3 位 ,选择立即数产生器的输出类型
- RegWr:宽度为 1 位 ,控制是否对寄存器 rd 进行写回,为 1 时写回寄存器
- ALUASrc 宽度为 1 位 ,选择 ALU 输入端 A 的来源。为 0 时选择 BusA ,为 1 时选择 PC
- ALUBSrc 宽度为 2 位 ,选择 ALU 输入端 B 的来源。为 00 时选择 BusB ,为 01 时选择常数 4 ,为 10 时选择立即数Imm
- ALUctr:宽度为 4 位 ,选择 ALU 执行的操作
- BandJ:宽度为 3 位 ,说明跳转指令的类型 ,用于生成最终的分支控制信号
- MemtoReg:宽度为 1 位 ,选择寄存器 rd 写回数据来源,为 0 时选择 ALU 输出,为1时选择数据存储器输出
- MemWr:宽度为 1 位 ,控制是否对数据存储器进行写入,为 1时写回存储器
- MemOp :宽度为 3 位 ,控制数据存储器读写格式
原理图
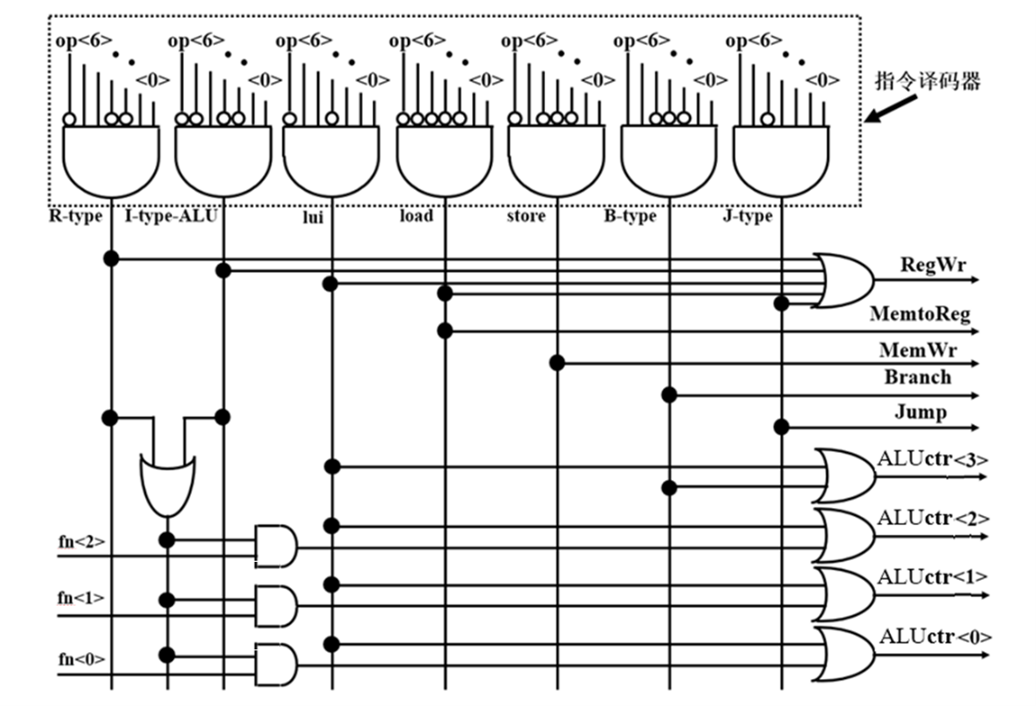
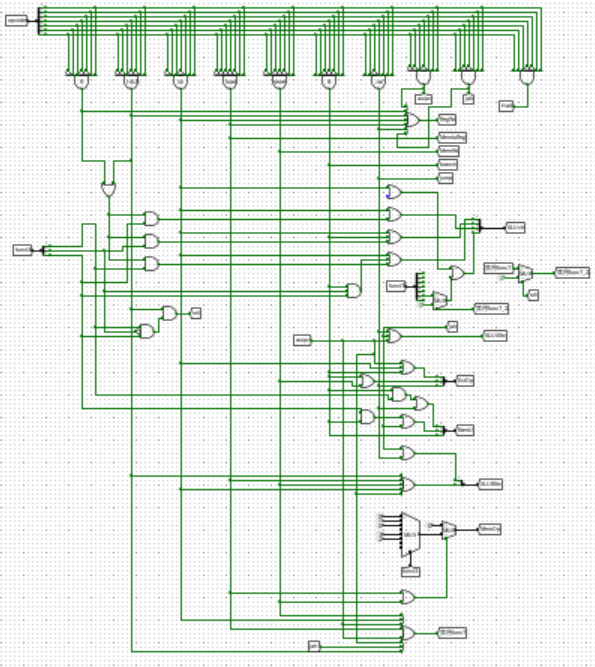
电路图
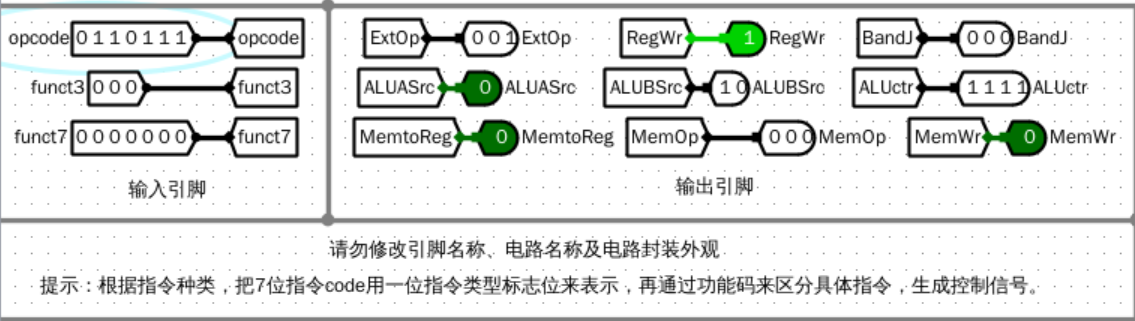
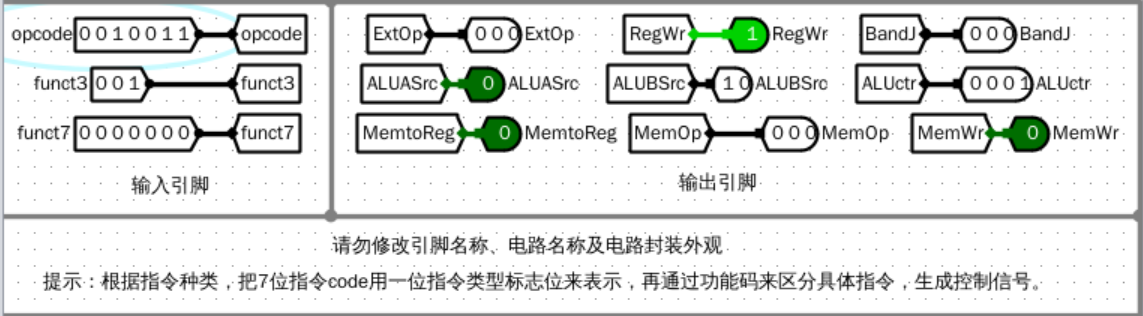
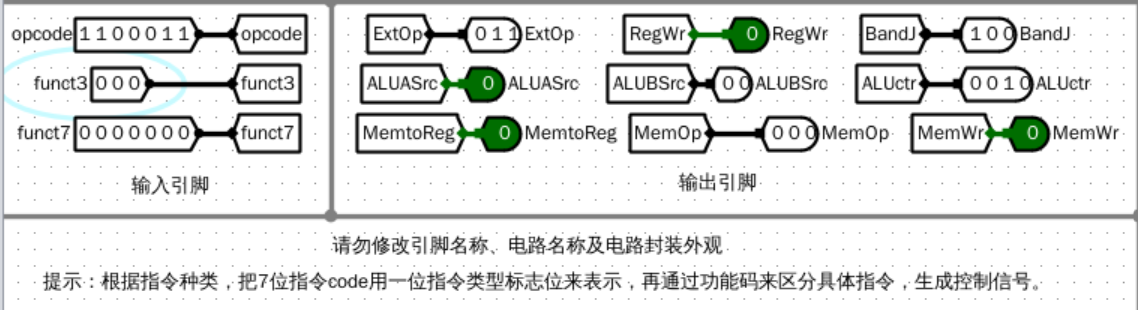
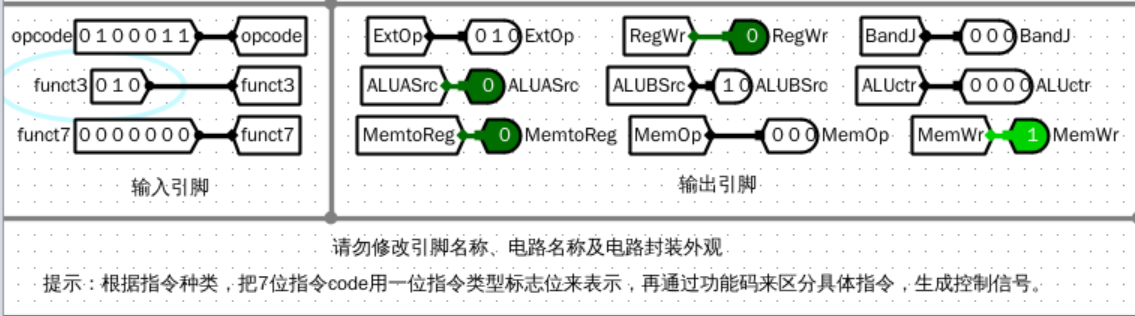
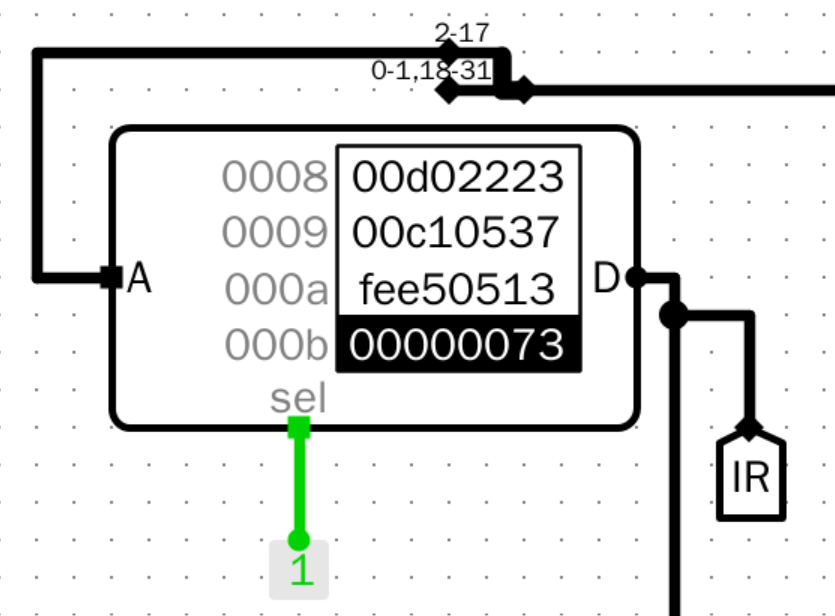
仿真测试(部分解码示例)
-
lui
![image]()
-
slli
![image]()
-
beq
![image]()
-
sw
![image]()
错误现象及分析
- 在完成实验的过程中,没有遇到任何错误。
实验二 :单周期 CPU 设计实验
整体方案设计
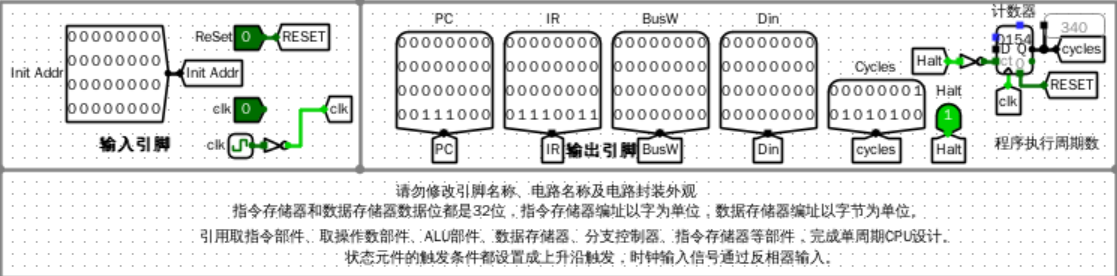
输入输出引脚
- Init Addr:决定初始PC指向的值
- RESET:决定是否加载init addr,为1时,加载init addr到PC中。
- clk:时钟
- PC:当前的程序计数器值
- IR:当前的指令值
- BusW:当前在数据通路上的值,也即即将写入寄存器堆的值
- Din:即将写入数据存储器的值
- cycles:程序已执行的总周期数
- Halt:CPU执行完停机指令后置位,表示已停止
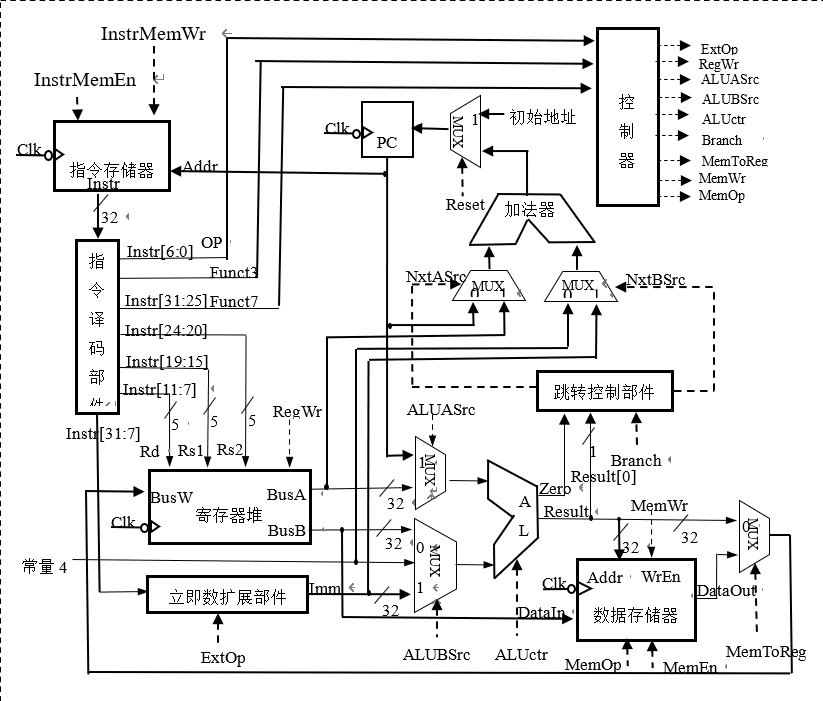
原理图
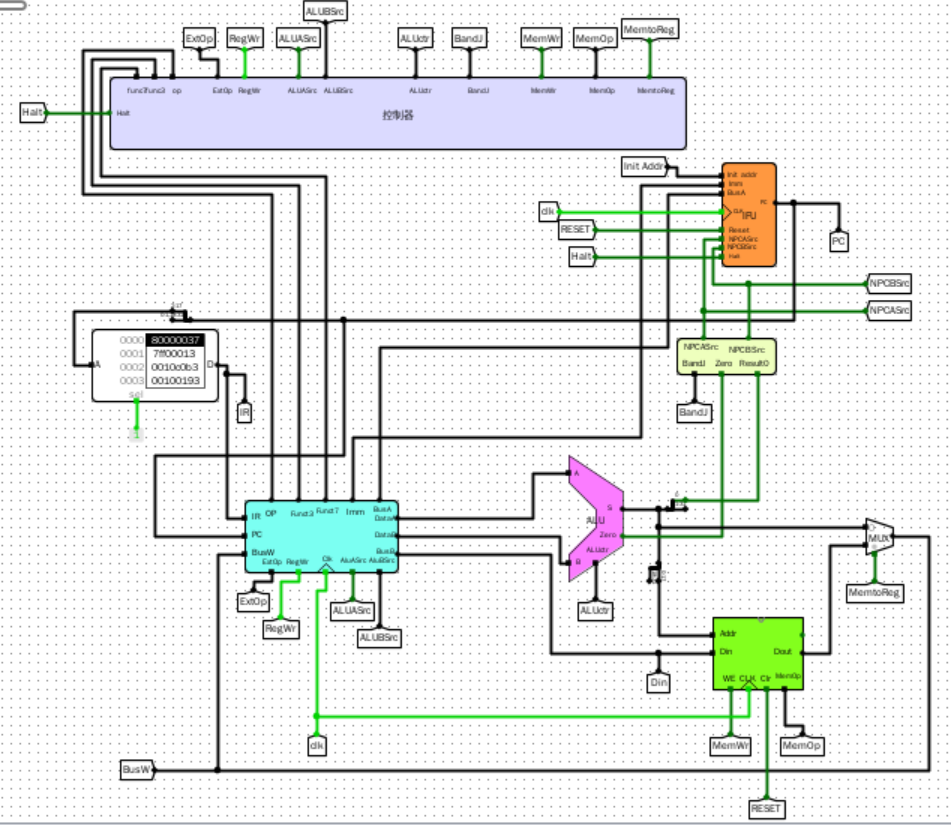
电路图
仿真测试
加载了lab6.2.hex,运行结果如下:
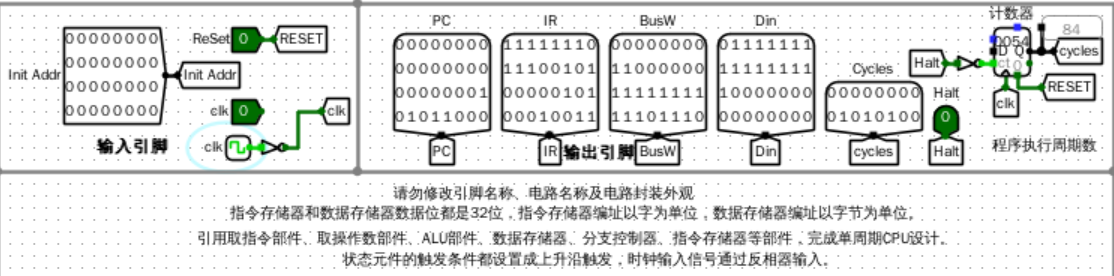
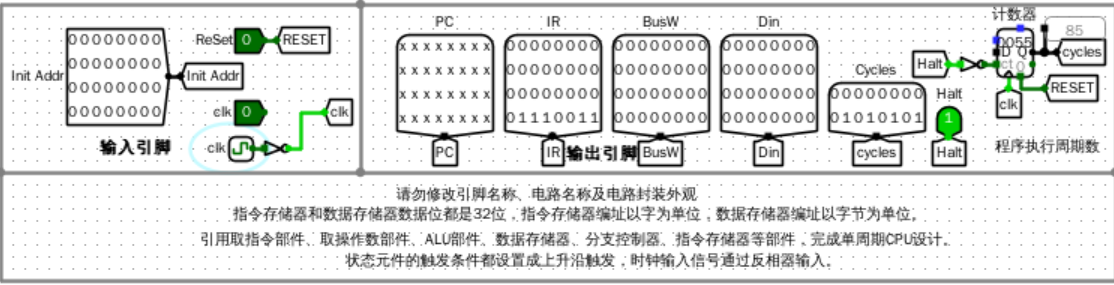
错误现象及分析
- 在完成实验的过程中,没有遇到任何错误。
实验三 :累加和程序测试实验
引脚,原理图和电路图
与实验二完全相同
实验结果
- 输入输出引脚
![image]()
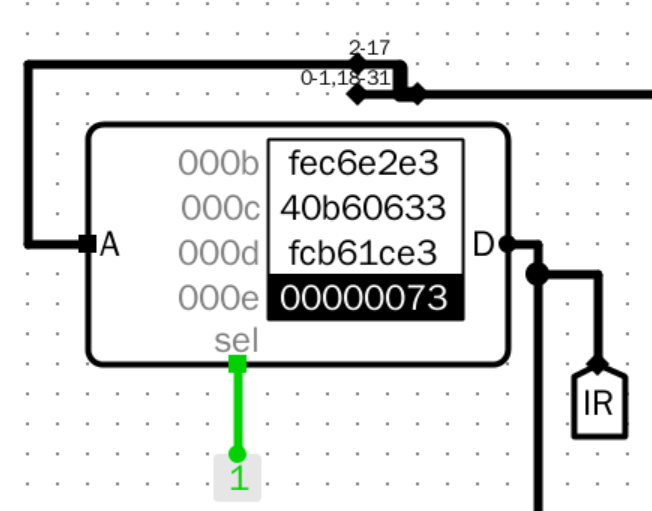
- 指令存储器
![image]()
- 数据存储器
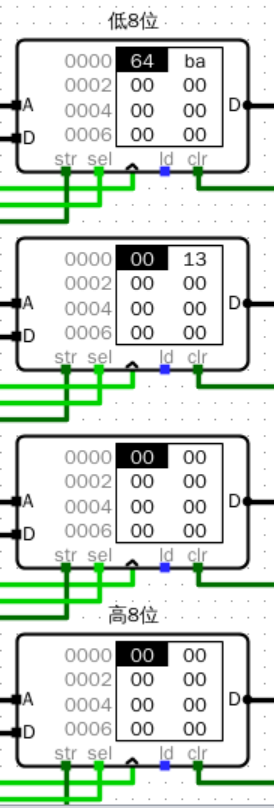
![image]()
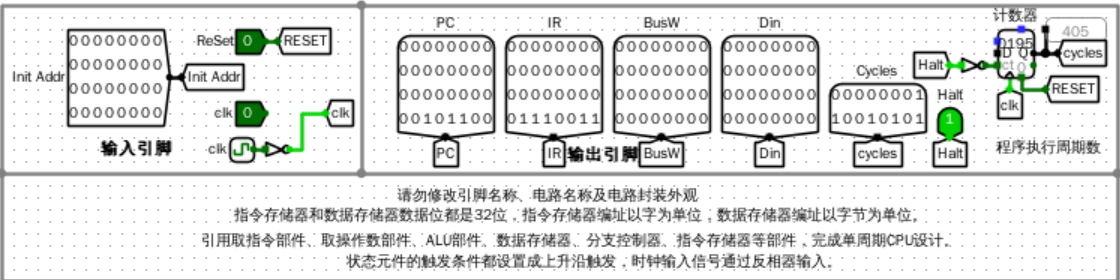
错误现象及分析
- 在完成实验的过程中,没有遇到任何错误。
实验四:用冒泡排序程序进行 CPU 设计验证
引脚,原理图和电路图
与实验二完全相同
实验结果
- 输入输出引脚
![image]()
- 指令存储器
![image]()
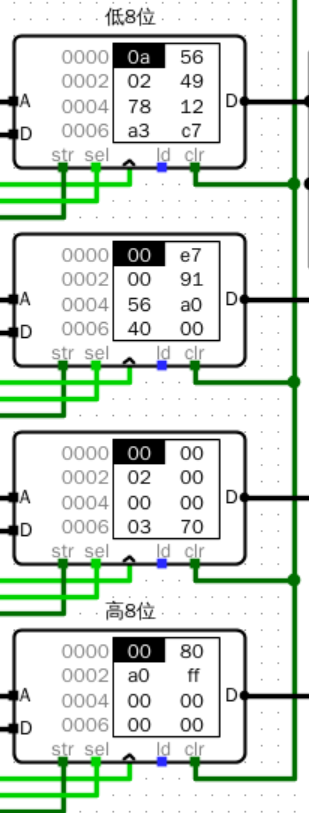
- 数据存储器
![image]()
错误现象及分析
没有遇到任何问题
实验五 :官方测试集实验
引脚,原理图和电路图
与实验二完全相同
表格填入
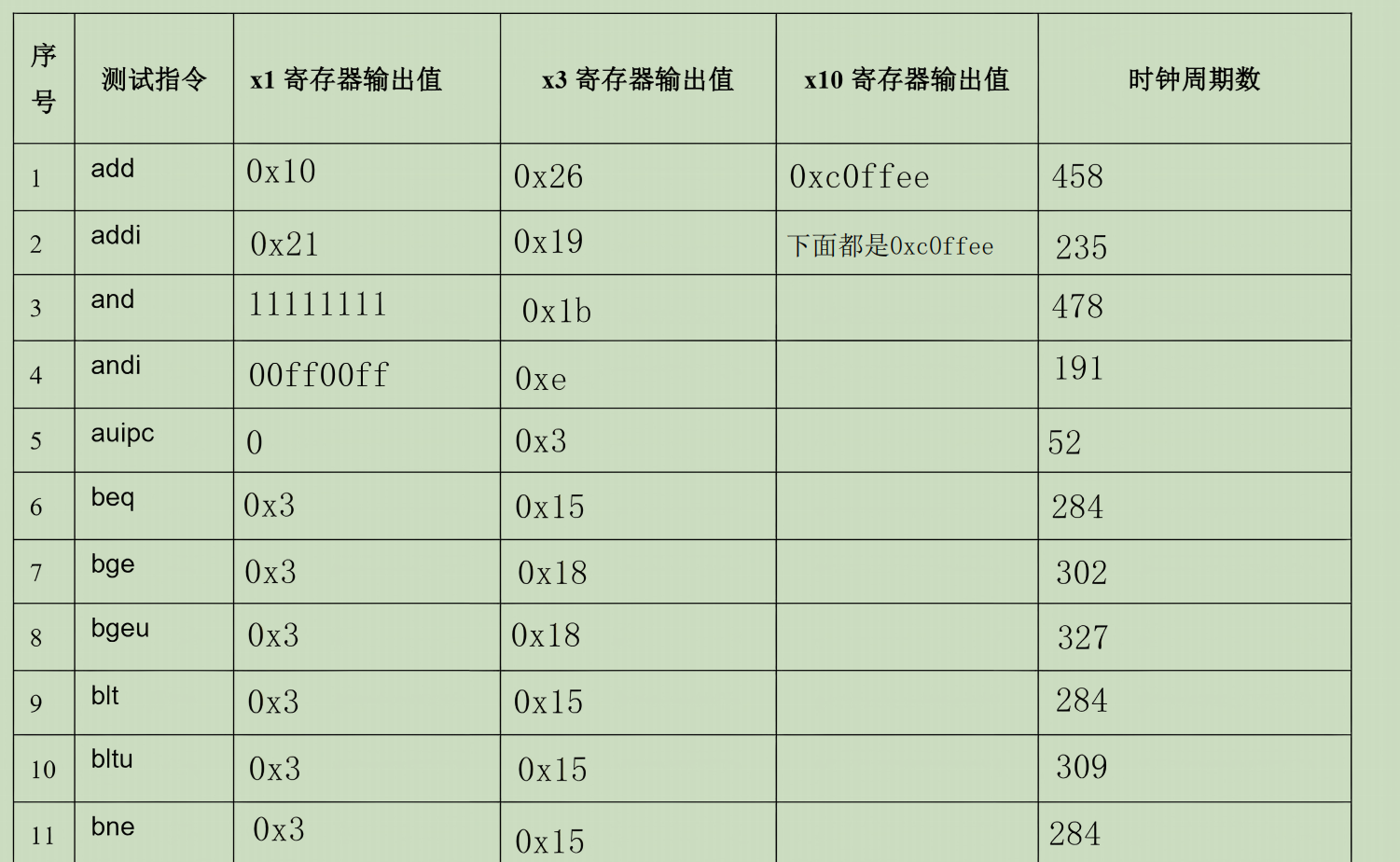
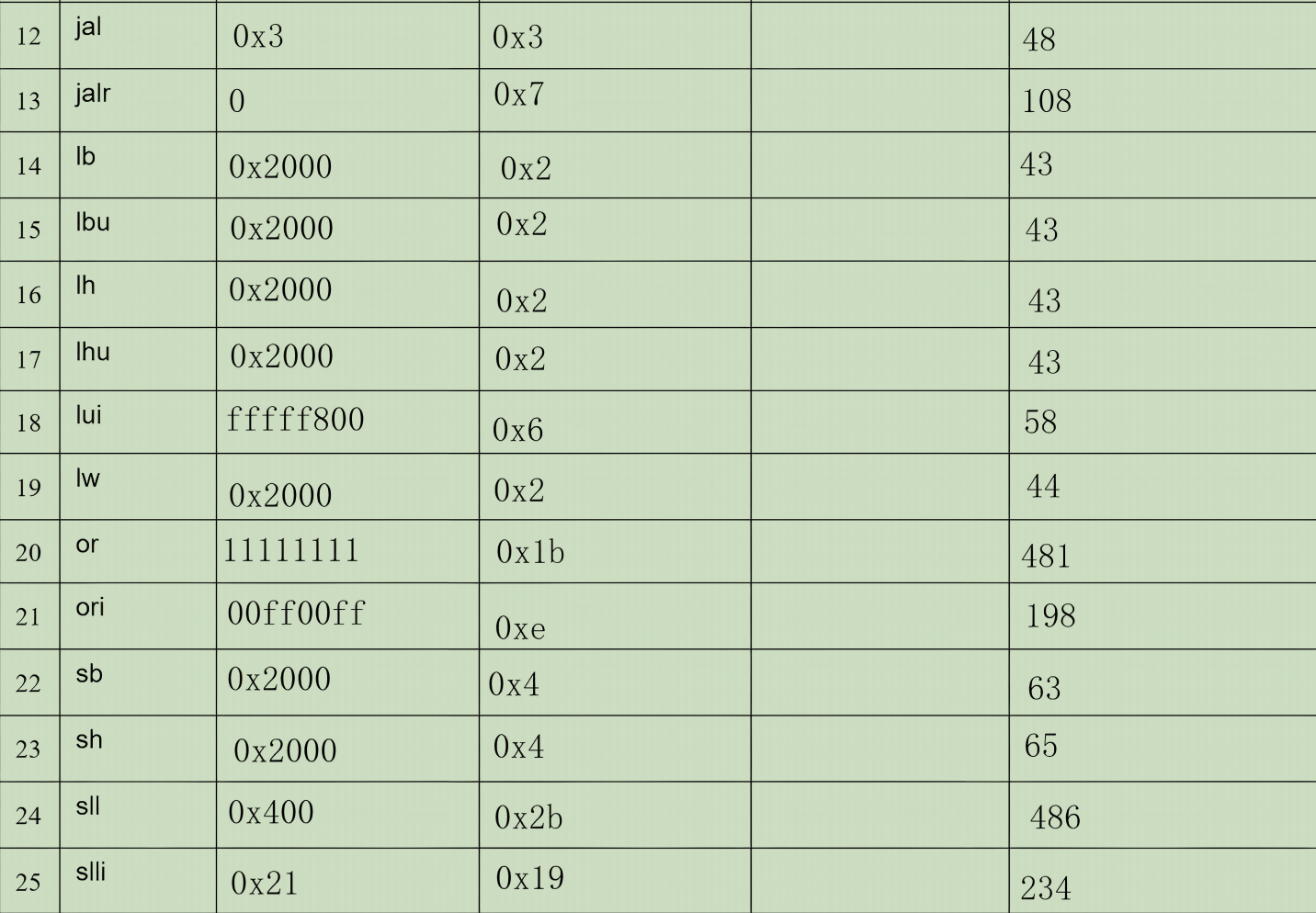

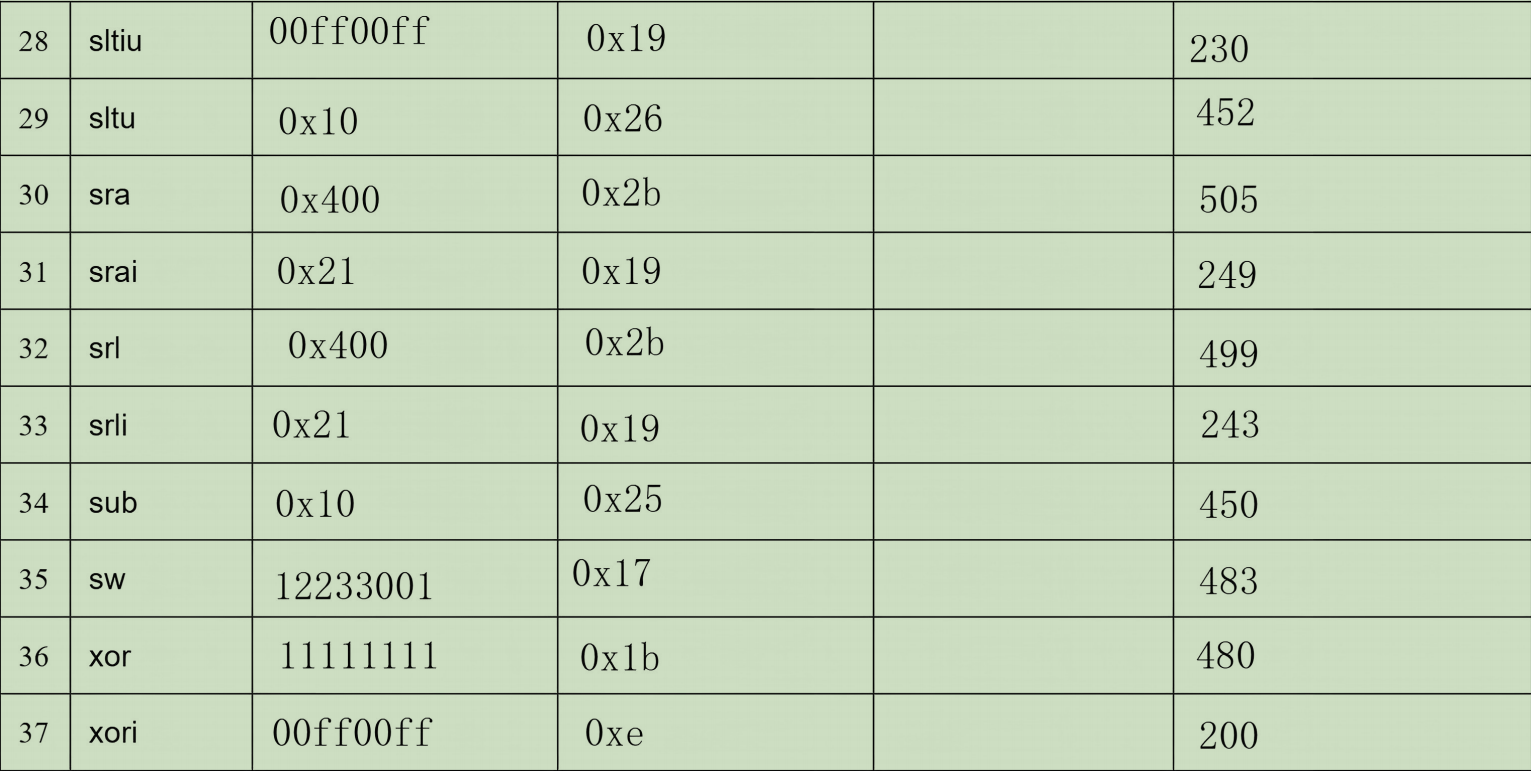
错误现象及分析
- 在完成实验的过程中,没有遇到任何错误。
实验六:计算机系统基础 PA 程序测试实验
引脚,原理图和电路图
与实验二完全相同
实验结果
测试程序比较多,只展示bubble-sort的测试结果
- 输入输出(进入了无限循环)
![image]()
- 寄存器结果
![image]()
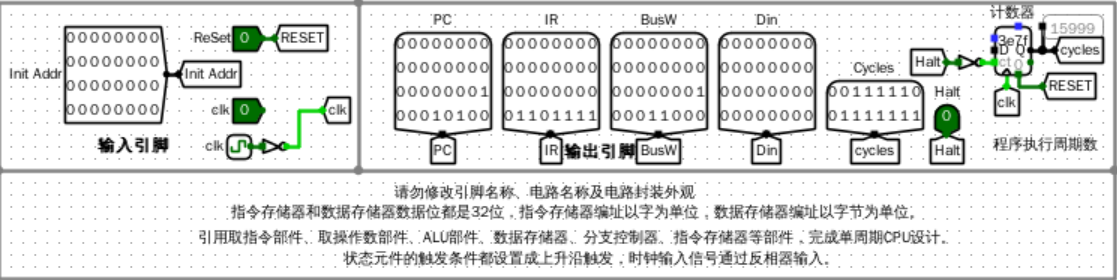
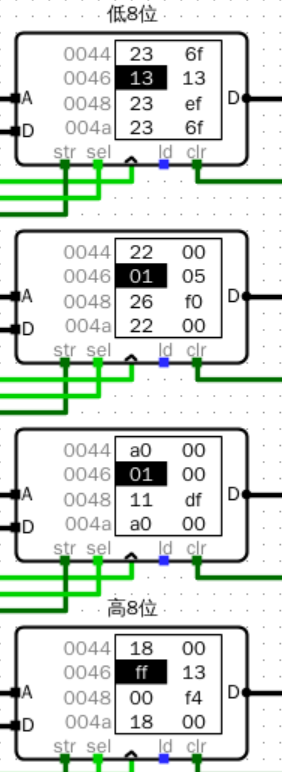
错误现象及分析
发现一个问题,会进入无限循环
这是在执行到指令0x6f的时候开始的
查阅指令集后发现这条指令意思是 jar x0, 0 ,实际上是跳转到自己,无限循环。这样倒是不会影响实验最后输出和数据存储器的结果,但是会导致时钟计数停不下来,因此可以考虑在电路中加上一个判断装置,如直接
判断IR为0x6f时设置halt=1,方便判断指令执行的总条数
这是图省事就没有加了,手动结束的
思考题
如何在单 CPU 上实现多任务处理,例如同时执行计算累加和与数据排序两个程序,阐述思路。
ICS提供了思路,轮流执行不同程序的一部分,来模拟多任务处理
如何实现任务切换:
- 将多个程序存放在不同的内存区域。例如,程序A(计算累加)存储在内存的地址
0x1000-0x1FFF区域,程序B(数据排序)存储在地址0x2000-0x2FFF区域 - 通过一个“时间片”机制来进行任务切换,例如每执行一定数量的指令后就切换到另一个任务
- 在程序执行过程中,PC会根据当前任务的指令位置不断增加。如果达到一个预设的时间片(例如,执行10条指令),就通过某种方式触发任务切换
- 任务切换时,保存当前任务的状态(例如,PC值,寄存器值等)到一个特定的内存区域或堆栈中,然后将程序计数器(PC)指向下一个任务的入口地址
在 CPU 的基础上,如何实现键盘输入、TTY 输出部件等输入输出设备的数据访问,构建完整的计算机系统。
CPU与外设通信的常用方式有端口映射和内存映射两种:
- 端口映射I/O:将外设的数据、状态、控制寄存器称为I/O端口。对端口进行编号,CPU使用in与out指令同端口间通过按编号“打电话”的方式通信
- 使用专门的I/O指令(IN/OUT)
- 独立的I/O地址空间,不占用内存地址
- 内存映射:将数据存储在内存中的一个特定地址(比如 0xF000),CPU通过读取这个地址来获取按键/显存/TTY信息
- 将设备寄存器映射到CPU的物理地址空间
- CPU通过普通内存访问指令(LOAD/STORE)与设备通信
实现键盘输入的思路如下:
- 键盘扫描:设计一个键盘扫描电路,当键盘上的按键被按下时,控制器会生成一个中断请求,并将按键的扫描码存储到一个缓冲区中
- 键盘数据读取:CPU可以在需要时读取缓冲区中的按键数据。可以通过检查一个状态寄存器来判断是否有新的按键输入
实现TTY输出的思路如下:
- 输出缓冲区:设计一个输出缓冲区来存储字符数据。当CPU需要向屏幕显示文本时,它会将字符写入缓冲区
- 数据传输:当缓冲区被填满时,TTY设备将开始将缓冲区中的字符逐个发送到显示器上。显示完成后,缓冲区为空,CPU可以继续写入新的字符
阐述如何在单周期 CPU 基础上实现多周期 CPU
跟着PPT做就好了
将每条指令分解为多个阶段,每个阶段使用一个独立的时钟周期来完成。每条指令的执行被划分为多个步骤,每个步骤在不同的时钟周期内执行
设计思路:
- 每条指令分成多个阶段,每个阶段在一个时钟内完成
- 不同指令包含的时钟个数不同
- 阶段的划分要均衡,每个阶段只能完成一个独立、简单的功能
- 加临时寄存器存放指令执行的中间结果
- 同一个功能部件能在不同的时钟中被重复使用
- 用有限状态机来表示指令执行流程,并以此设计控制器
阐述如何在单周期 CPU 基础上实现流水线 CPU
跟着PPT做就好了
以Load指令为准,分为五个阶段:取指令段IF,译码/读寄存器段ID,执行段EX,存储器段M,写回寄存器段WB
ID段生成所有控制信号,并随指令执行过程信息同步向后续阶段流动
与单周期处理器的控制器的实现方法一样,无需采用有限状态机

 浙公网安备 33010602011771号
浙公网安备 33010602011771号