

MLLM初步调研
架构
典型的MLLM通常由三个模块构成:预训练模态编码器(Modality encoder)、预训练语言模型(Pre-trained LLM)以及连接这些模块的模态接口(Modality interface)
Modality encoder就像人类的眼睛/耳朵,负责接收并预处理光学/声学信号;而Pre-trained LLM则像人类的大脑,对处理后的信号进行理解与推理;Modality interface则负责将经过预处理的不同模态信号转换为大脑可以处理的统一的形式
Modality Encoder
相较于从零开始训练,常见的做法是使用经过对齐预训练的Modality Encoder
下面是一个非常经典的Modality Encoder:
- CLIP通过大规模图像-文本对的对比预训练,实现了与文本的语义对齐视觉编码器
![image]()
这篇文章的贡献就是说明了对比预训练比生成式预训练的效果更好
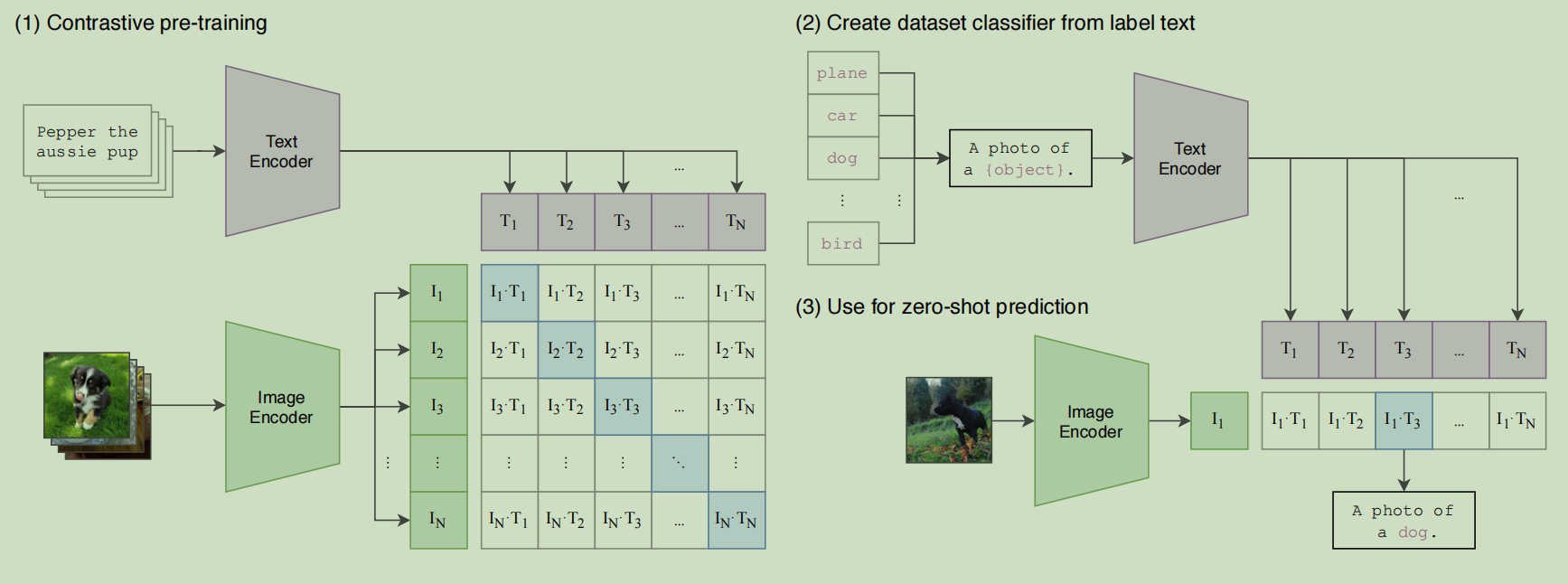
而如果要同时对齐多个模态,那么可以选择图像/视频模态作为基准
- ImageBind发现,只需各模态与图像/视频配对,无需所有模态两两配对,即可涌现跨模态对齐
![image]()

Pre-trained LLM
与其从头开始训练一个LLM,不如从一个预训练好的LLM开始
- Dense模型的选择有很多,一般集中在LLaMA和Vicuna上
- 也有用MoE架构的。MoE-LLaVA发现,在几乎所有基准测试中,MoE实现的性能都优于Dense模型
Modality interface
由于语言模型只能处理文本,因此需要搭建起自然语言与其他模态之间的桥梁
若要从零开始端到端训练大型多模态模型,成本将十分高昂
更实际的解决方案是在预训练的Modality Encoder与Pre-trained LLM之间引入可学习的Modality interface,或者助Export Model将图像转化为语言,再将这些语言输入到语言模型中进行处理
可学习的Modality interface
Modality interface将信息投射到大模型能够高效理解的空间中,也就是在进行对齐
- Align before Fuse证明了这项工作的必要性
![image]()
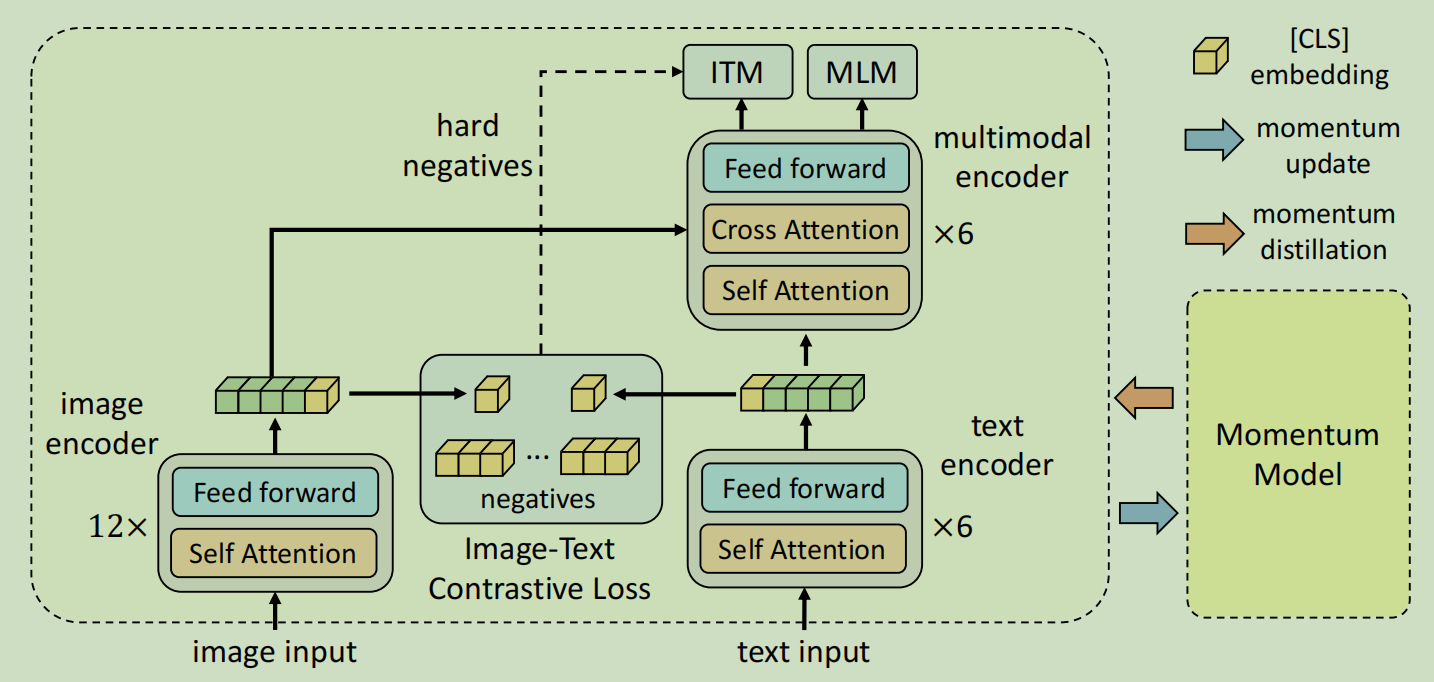
实现Modality interface大致有两种方法:token-level融合和representation-level融合
token-level
Modality Encoder的输出被转换为token,并与text token拼接后输入LLM
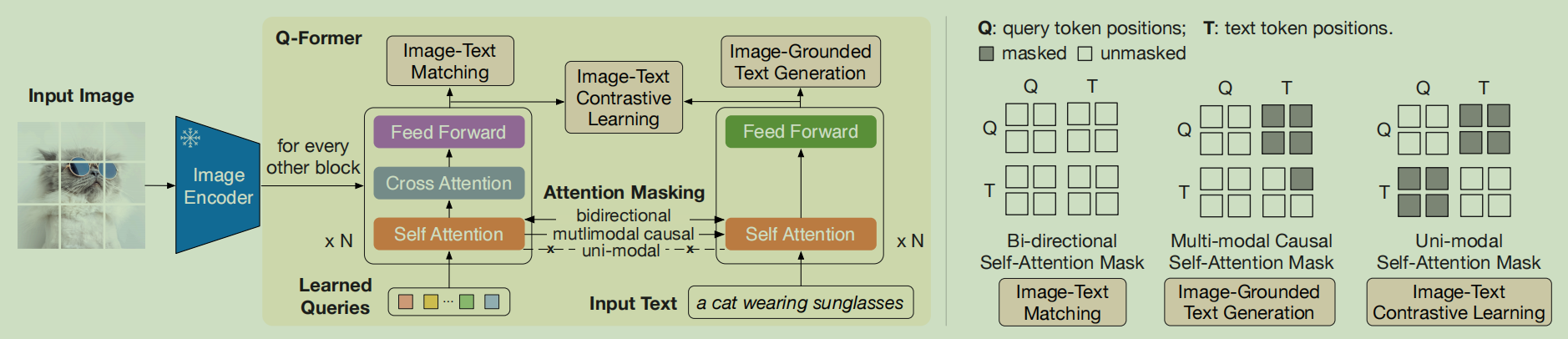
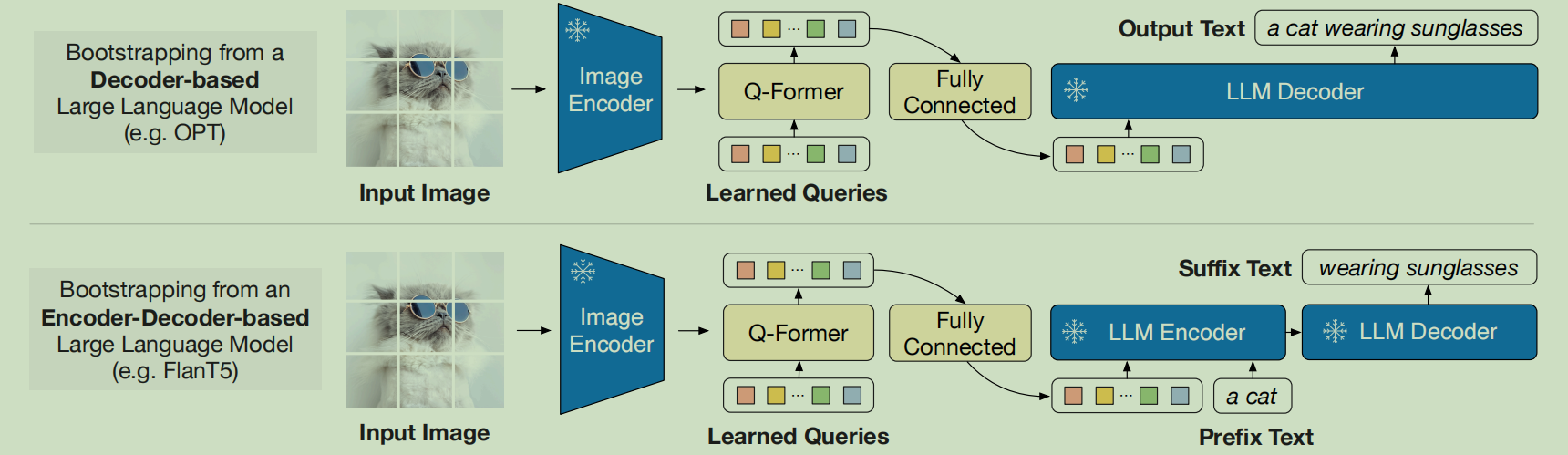
- BLIP-2利用一组可学习的query以查询方式从Modality Encoder中提取信息
![image]()
这种Q-Former风格的方法将Modality Encoder的输出压缩为更少数量的表示向量,然后使用一个简单的桥梁(比如MLP)来与LLM连接
![image]()
- LLaVA直接使用基于MLP的接口来弥合模态差距
![image]()
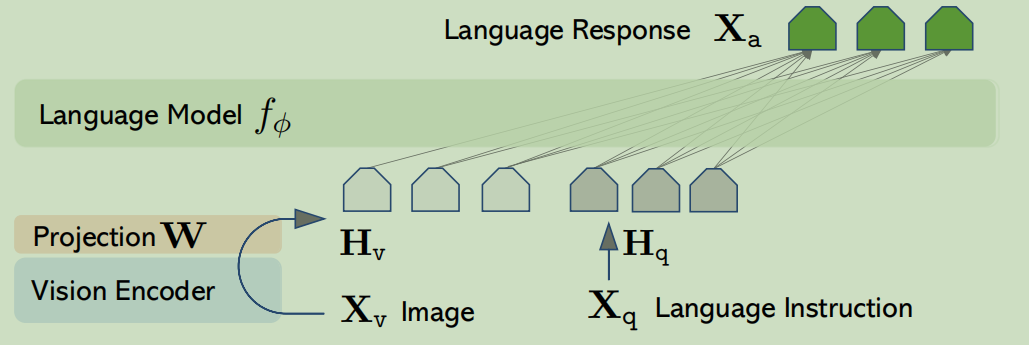
representation-level
representation-level通过在Transformer层中插入额外模块,实现了文本特征与视觉特征之间的深度交互与融合
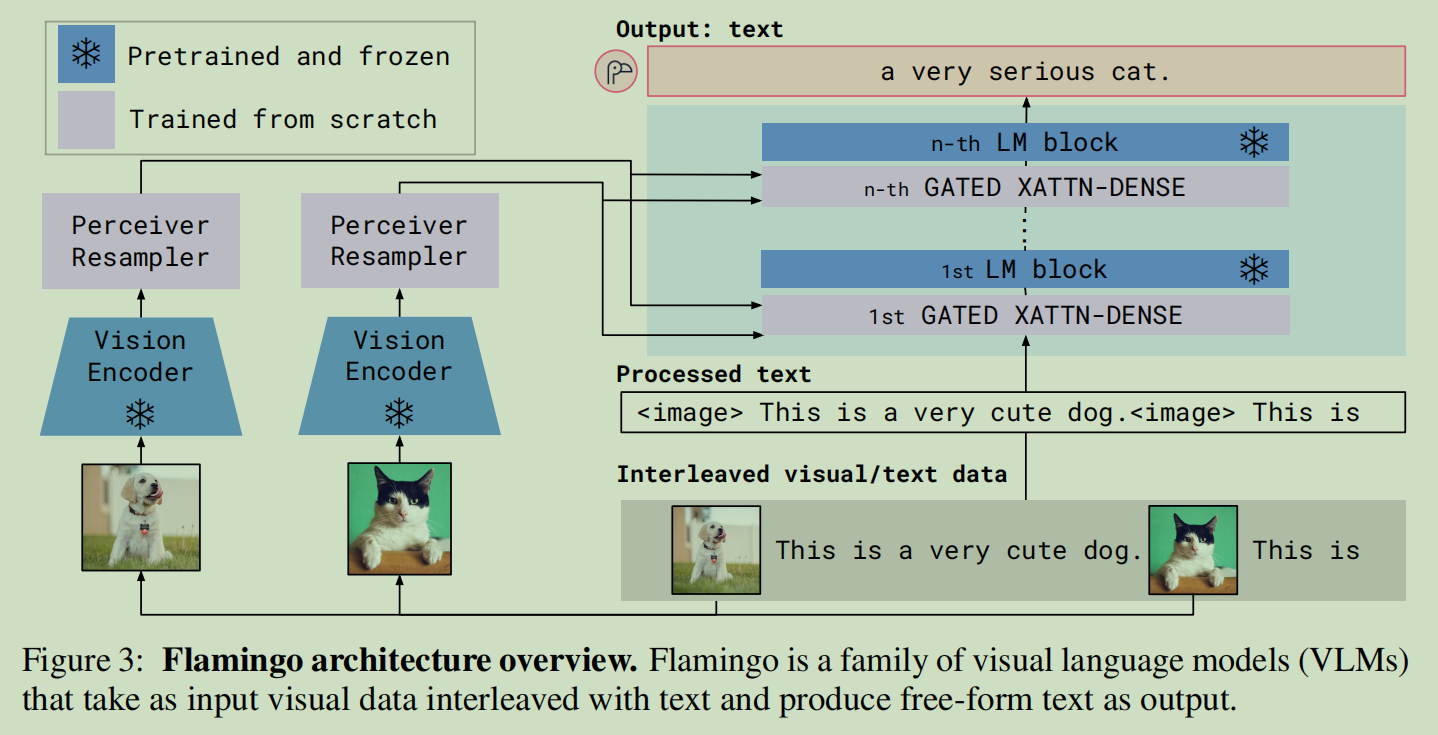
- Flamingo在transformer层之间插入了额外的交叉注意力层
![image]()
有研究发现,token-level融合效果更好
Expert Model
Expert Model核心思想是无需训练即可将多模态输入转化为语言
- VideoChat-Text利用预训练视觉模型和语音识别模型获取视频的标题,字母,描述,物体检测等,然后输入给大模型
![image]()
![image]()


多模态输出
- 图像
- Emu同时训练文本输出和图像输出的能力
![image]()
- Emu同时训练文本输出和图像输出的能力
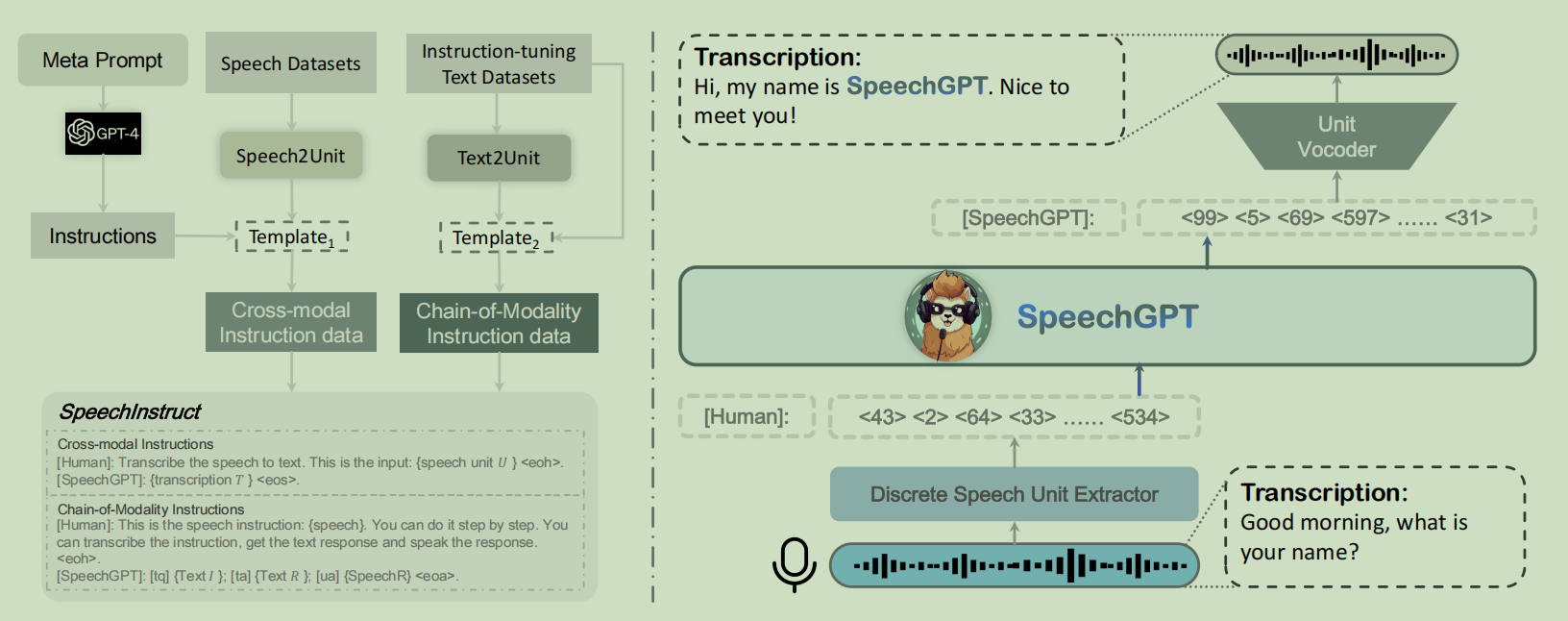
- 音频
- SpeechGPT训练模型输出音频的能力
![image]()
- SpeechGPT训练模型输出音频的能力
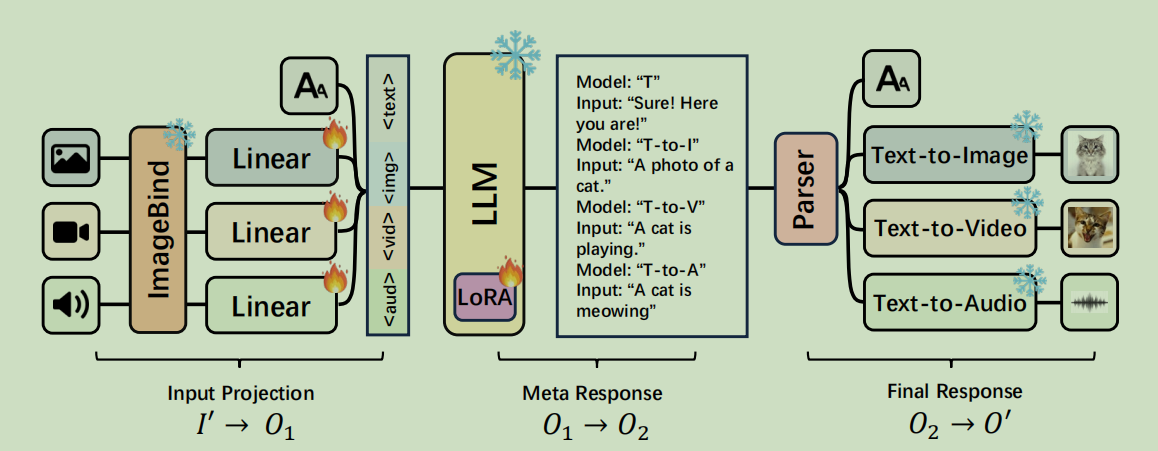
- 混合
- ModaVerse利用LLM作为Agent,选择合适的输出模型
![image]()
- ModaVerse利用LLM作为Agent,选择合适的输出模型

更高级的工作涉及RL
一篇时序-文本融合的研究-ChatTS
研究背景
近年来,多模态大语言模型取得了显著成就,尤其是在视觉-语言任务中,模型展现出复杂的理解和推理能力。然而,这种成功尚未在时间序列领域复制。
主要的瓶颈在于高质量数据集的极端稀缺。于是作者的关键洞见是,可以通过专门在高质量合成数据上进行微调来克服数据稀缺问题。
时序数据生成方法

基于属性的时间序列生成器如下所示:
- 定义一个 "全属性集" ,包含如趋势、周期性、噪声和局部波动等类别。
- 采样一个指标名称(例如"请求计数"),然后让GPT根据该指标的物理含义,从全属性集中选择一个现实的属性子集。
- 一个 "属性采样器" 为选定的属性分配特定的数值(例如,幅度、位置),为单个时间序列创建一个详细的"属性池"。
- 最后,"时间序列生成器" 创建与属性池中的规格完美匹配的数值时间序列数组。
指令微调数据生成方法
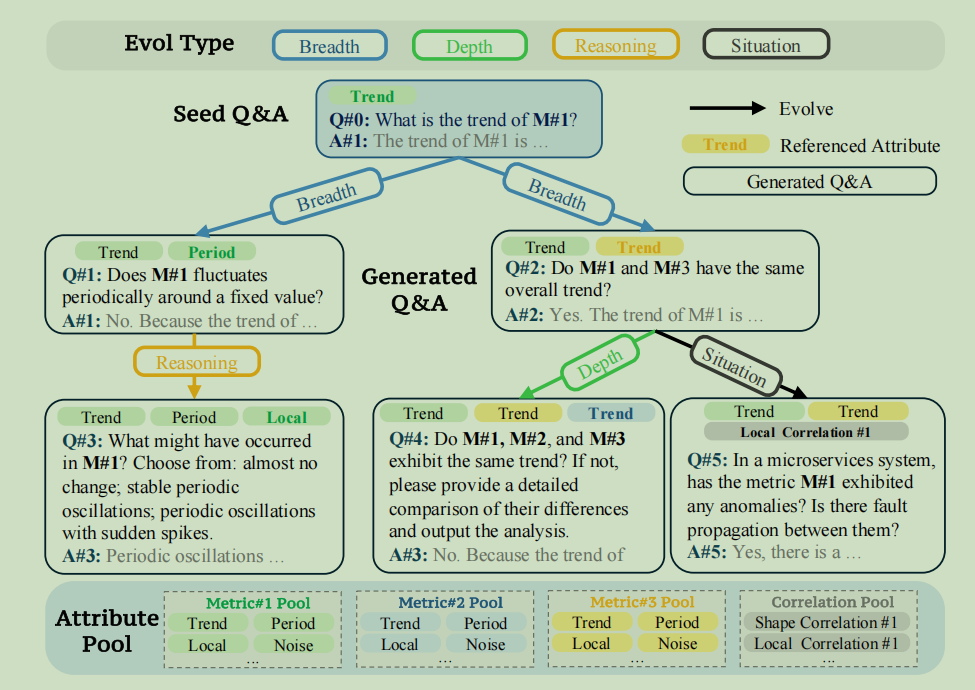
TSEvol 从一个简单的"种子问答"开始,并迭代地重写它以使其更复杂或范围更广。每个演化步骤从Evol Type中选择一个类型,然后再从属性池中选择多个指标(这里的属性池包含了多个指标),将上一个步骤中,这个指标对应的属性池内容给LLM让其生成QA。论文还用了一个过滤器来把LLM生成的低质量QA过滤掉(但是论文没有具体阐述如何过滤)
模型结构
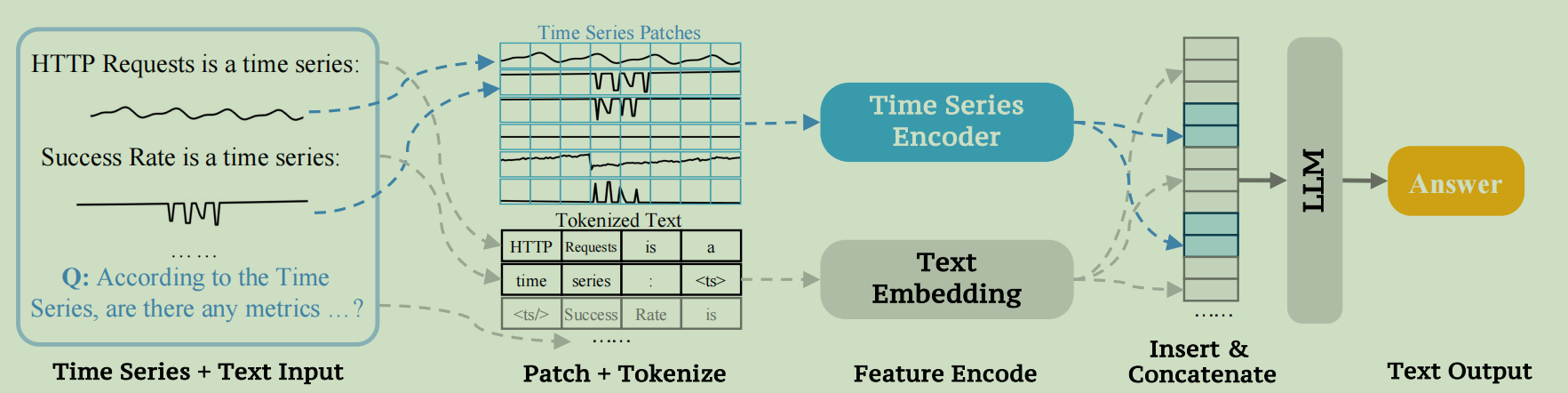
比较简单的结构,TS编码器就是简单的MLP
另外,有一篇2025年8月份将continual learning的综述

 浙公网安备 33010602011771号
浙公网安备 33010602011771号