爬虫
爬虫的基础知识
爬虫的定义

爬虫的作用
爬虫用途主要有以下几个方面
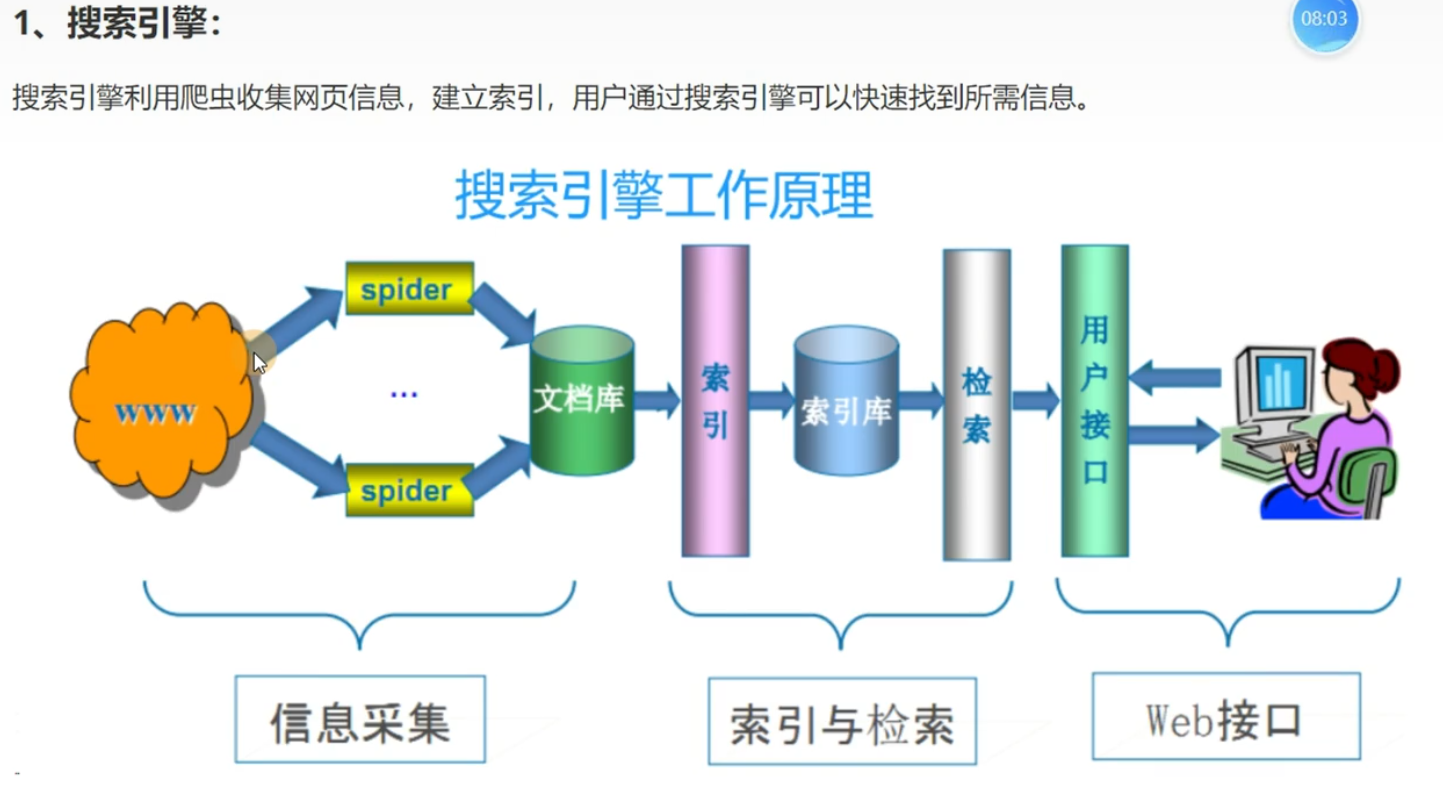
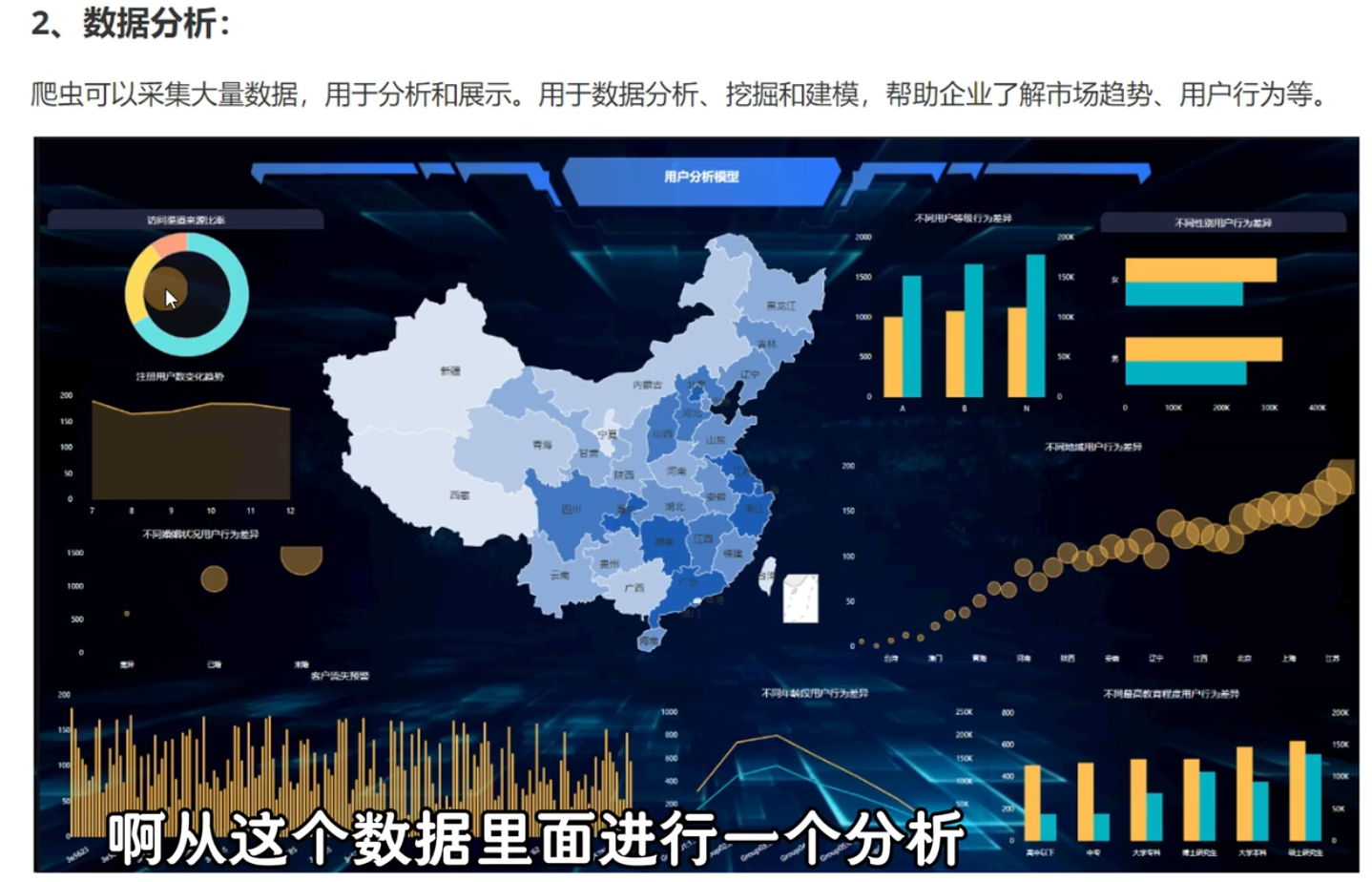


爬虫的分类




爬虫的工作流程

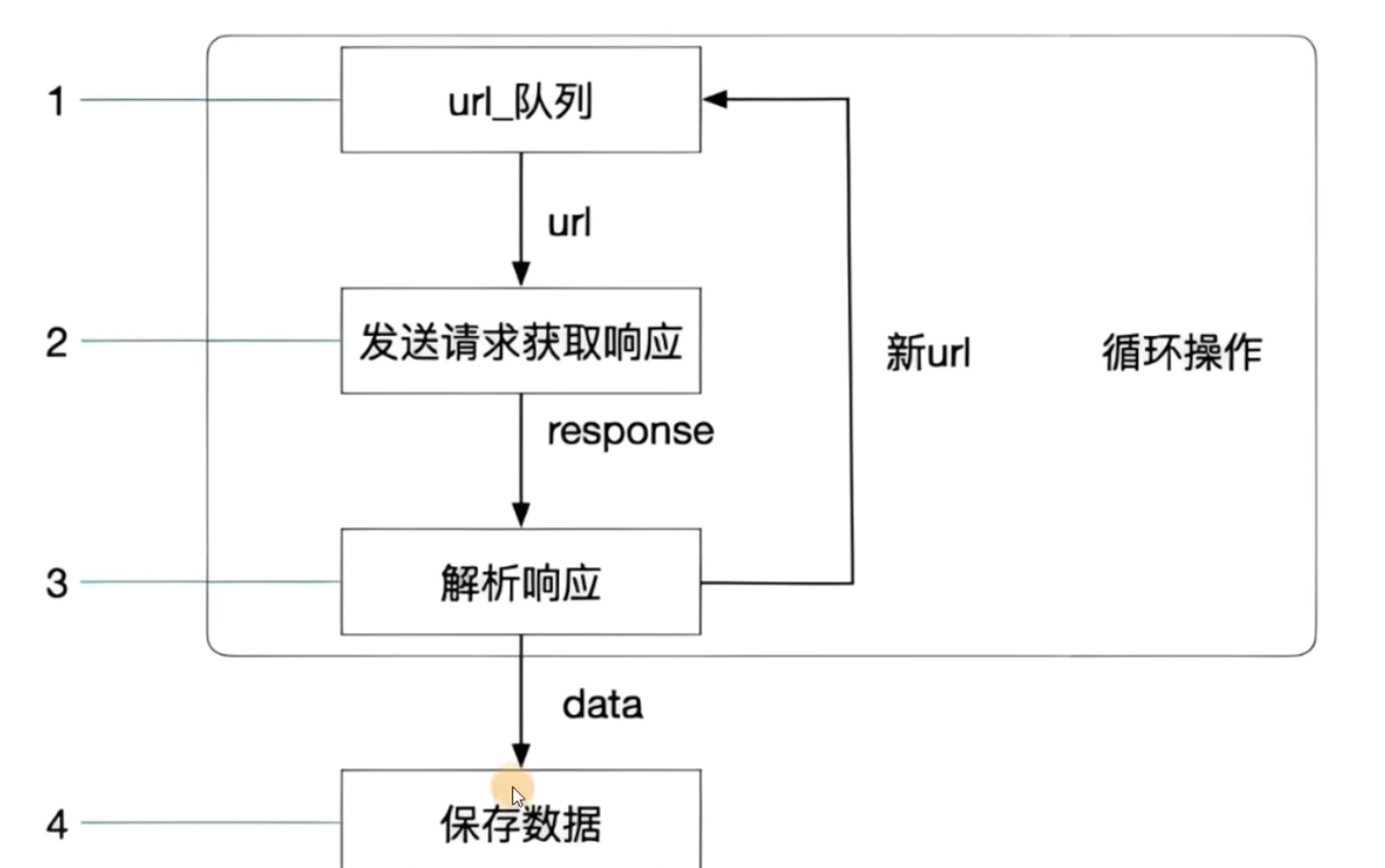
这里的URL队列是因为我们要采集数据的网页可能有很多。比如一个新闻网站上面的不同类型的新闻。这个时候就可以将不同类型的新闻(对应不同的URL)放到一个队列里面,然后进行循环采集;或者就像图片中说的,在某一次解析网页的时候,这个网络包含一个新的网页链接,我们就可以把这个新的网页URL放到URL队列里面
robots协议

可以输入www.baidu.com/robots.txt看一看
只不过没人会管这个协议,因为如果遵守这个协议的话基本上就采集不到什么东西。但是有一条原则:不要采集涉及用户隐私的东西(名字,电话,地址,身份证号等)
HTTP和HTTPS协议

HTTP的请求过程
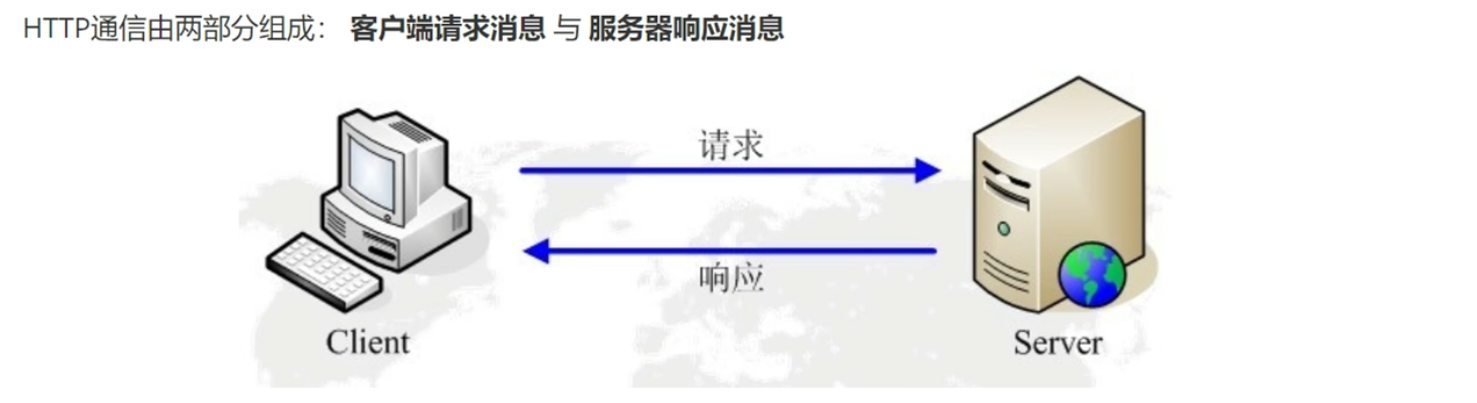

我们键入一个URL后,由于我们请求的对象有很多个(HTML,CSS,图片等),所以不止是发一个请求。具体看有哪些请求的话,打开一个网页之后,按F12,选择网络,再刷新一下网页就可以看到请求的东西了

HTTP请求信息
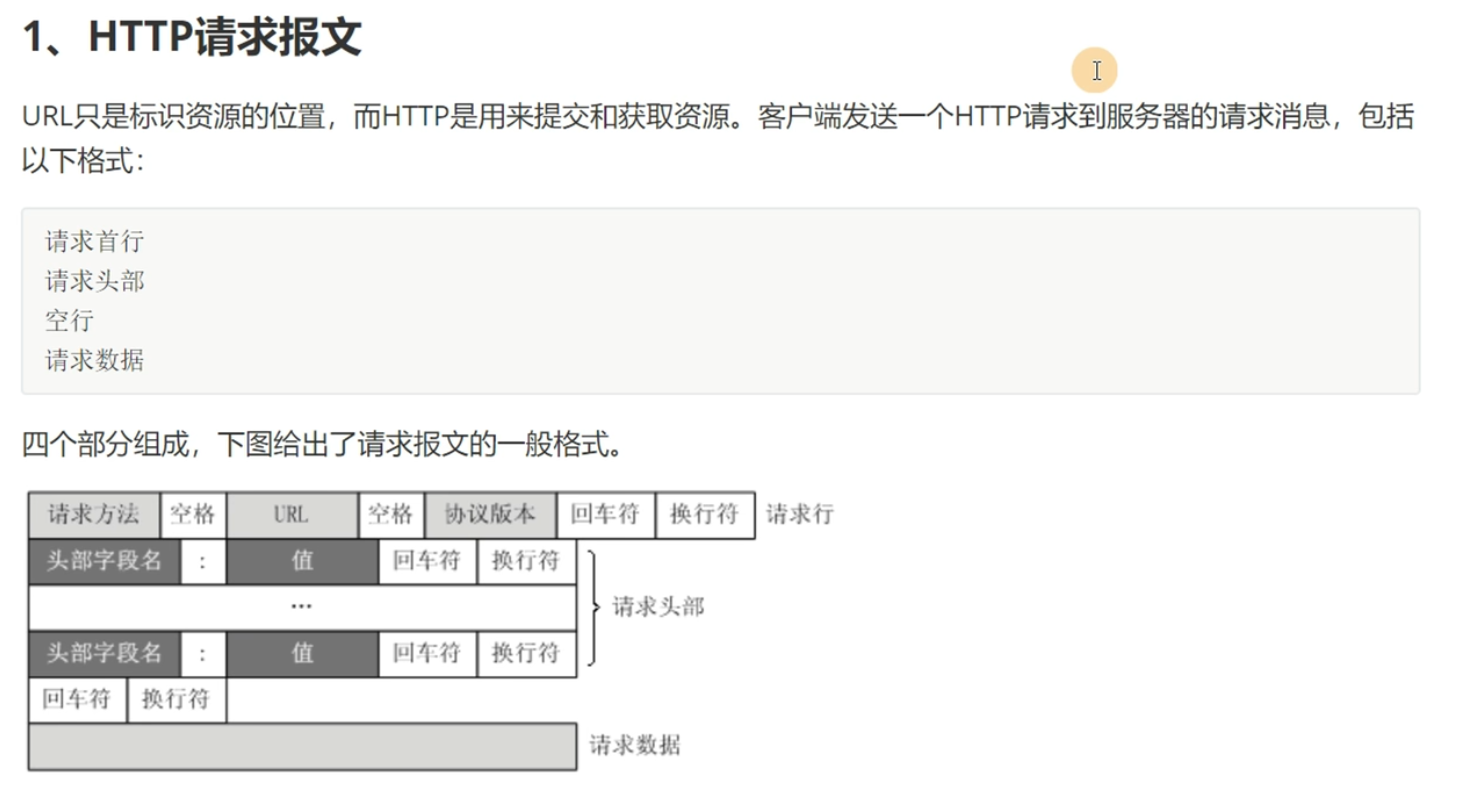
具体查看请求报文的话,按F12,选择网络,再刷新一下网页获得请求的东西,点击一个东西,就可以看到标头(header),载荷(payload)等
HTTP请求方法


爬虫常用的就两种:GET和POST

请求体也就是载荷(payload)
POST对传递的数据长度没有限制,但是GET是有的
常用的请求头
请求头也就是header
- Host (主机和端口号)
- Connection (连接类型)
- Upgrade-Insecure-Requests (升级为HTTPS请求)
- User-Agent (浏览器名称)
- Accept (传输文件类型)
通俗一点说就是,客户端希望得到的内容的类型是什么*/*:什么类型的文件都可以
- Referer (页面跳转处)
就是我们输入的URL不一定是真正的URL,他可能给我们导到另一个URL,这个URL就是Referer - Accept-Encoding (文件编码格式)
就是客户端支持解码的形式(其他的发过来不能解码) - Accept-Language (语言种类)
- Content-Length(请求体字节数)
- Content-Type (POST数据类型)
- Cookie (Cookie)
- x-requested-with :XMLHttpRequest (表示该请求是Ajax异步请求)
上面的东西,最重要的是User-Agent,Referer和Cookie
HTTP响应信息
响应报文
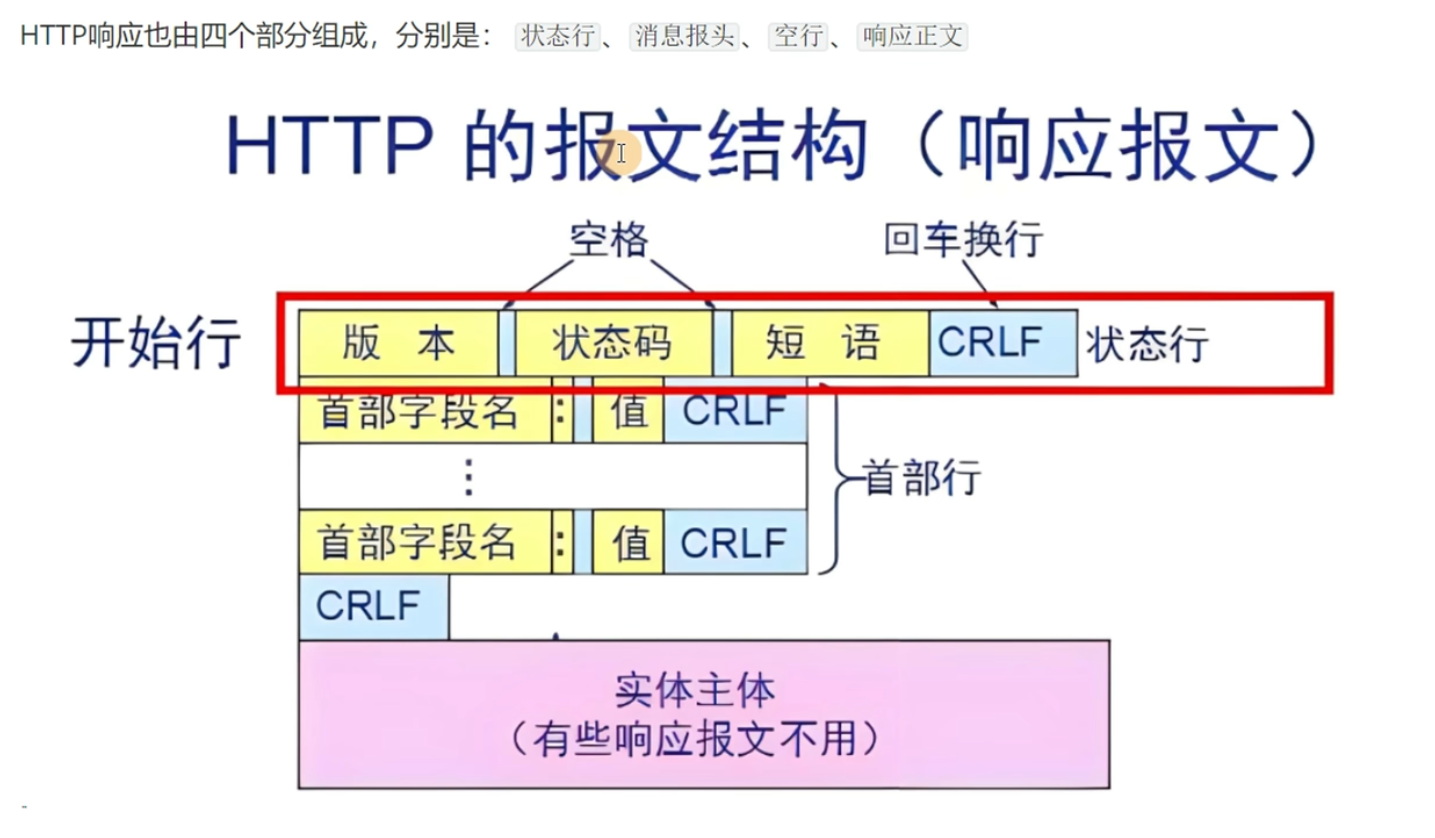
CRLF是空白行,粉色的是响应体(当然不是所有响应报文都有响应体的)
Cookie信息

Cookie一般保存在本地浏览器。按F12,点击应用,在存储中就可以找到Cookie了
Expires/Max-Age表示Cookie被删除的时间。在这个时间之前,任何一次请求都会将所有Cookie全部发给服务器
Session就是可以自动登录这种
状态码范围

HTTP响应状态码参考

具体见书P65
requests基本使用

发送get请求
"""
准备工作:
安装requests请求库: pip install requests
在代码中导入requests: import requests
需求: 使用代码获取百度首页的内容:
步骤:
1、准备好百度的地址: https://www.baidu.com/
2、发送请求: requests.get(url='请求的地址')
3、获取返回的结果: response = requests.get(url='请求的地址')
"""
# 导入requests模块
import requests
# 百度首页的URL
url = 'https://www.baidu.com/'
# 使用requests发送请求: 请求百度首页, 接收返回的结果
response = requests.get(url=url)
# 打印结果
#print(response.text)
输出包含请求头,URL,IP等内容
响应数据的获取
如果按照response.text输出,会发现是有乱码的。那么我们怎么输出到正确的数据呢?
# 方式一:response.text :获取到的是字符串
print(response.text)
# 这种方法之所以会出现乱码,是因为这是自动解码的,不一定选择UTF-8,所以可能会出现乱码
# 方式二:response.content: 获取到的是原始的二进制数据(bytes类型的数据)
# 需要用decode方法转换为字符串
print(response.content.decode())
# 这里的decode默认使用的是UTF-8编码,所以不会出现乱码
# 使用另一种解码:print(response.content.decode('gbk'))
# gbk是只包含中文的编码方式
字符集编码
字符、字符集

Python3中的字符串

str和bytes类型的互相转换
"""
encode: 对字符串进行编码,转换为二进制的格式(bytes类型)
decode: 对二进制的字符串(bytes类型)进行解码,转换为字符串
"""
s = '你好 python'
# 将字符串转换为bytes类型:
res = s.encode()
print(res)
# 输出'\xe4\xbd\xa0\xe5\xa5\xbd python'
# bytes类型的字符串(二进制字符串)
ss = b'\xe4\xbd\xa0\xe5\xa5\xbd python'
# 将bytes类型转换为字符串
res2 = ss.decode()
print(res2)
# 输出'你好 python'
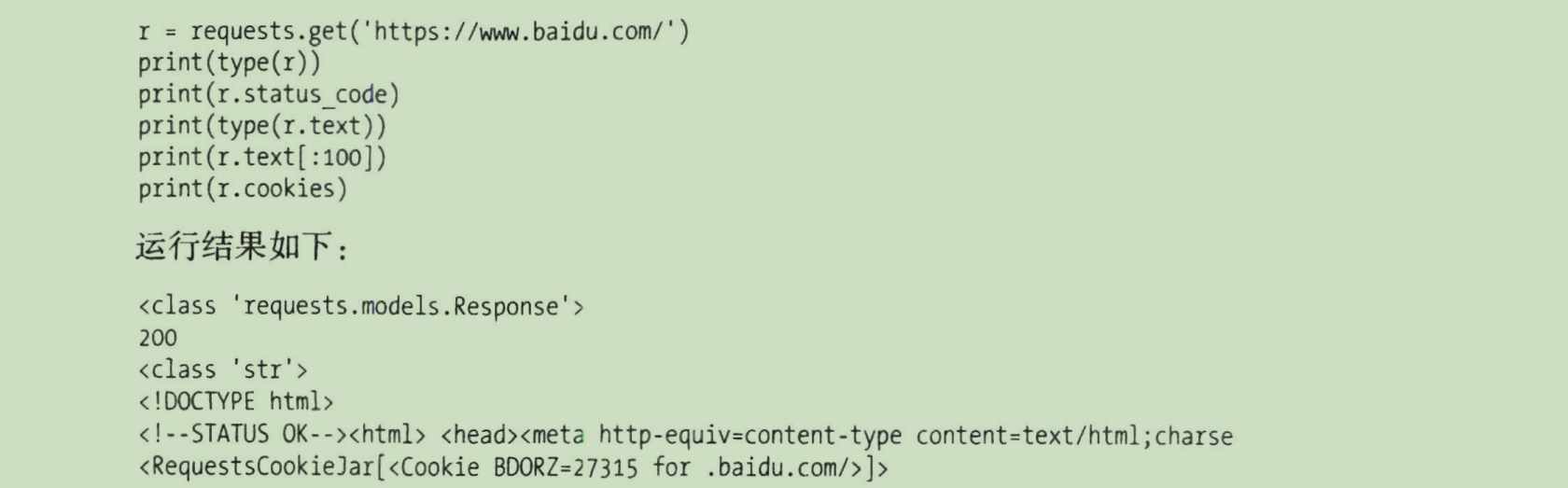
response的其他属性

- 状态码
![image]()

一些例子:
携带HTTP请求头
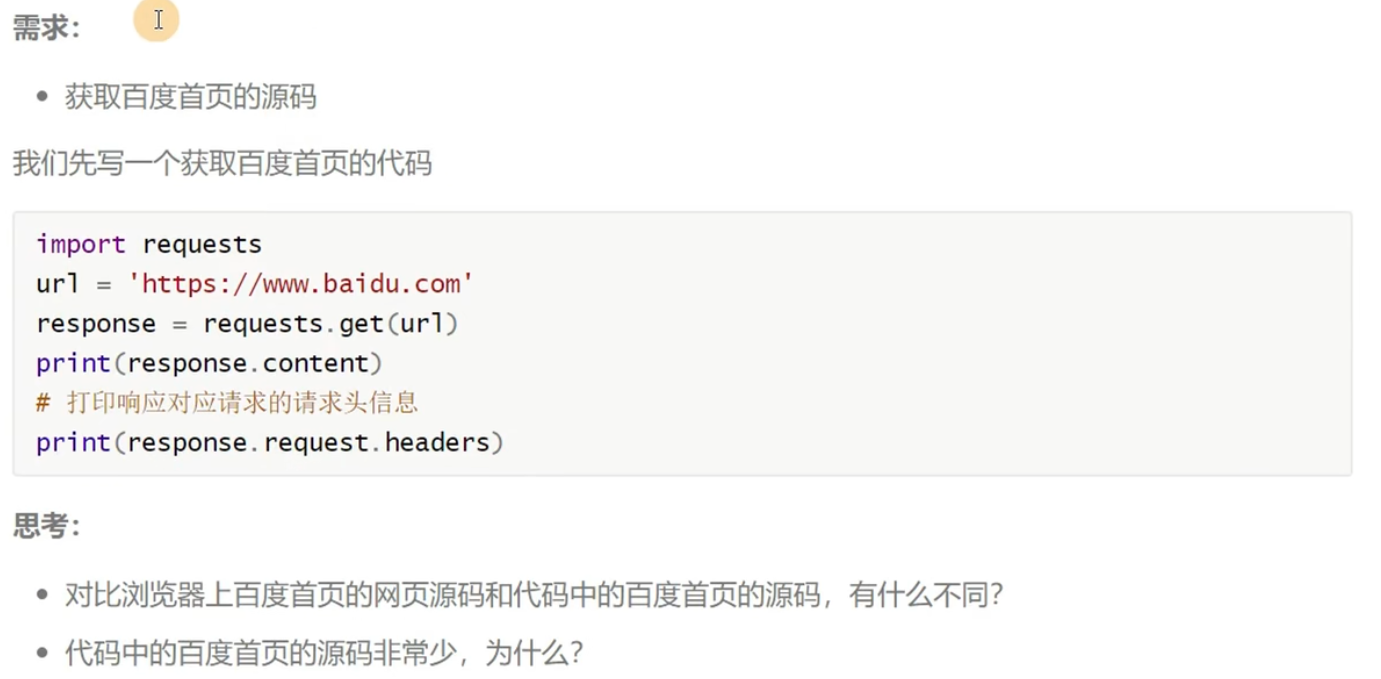
这里百度首页的网页源码指的是:按F12,点击网络,选择www.baidu.com,点击响应
之所以代码中的非常少,是因为代码发送请求的时候,请求头中的User-Agent是表示了自己是爬虫程序了,百度就可以做一个反爬虫,随便返回内容(使用request.headers查看请求头信息)
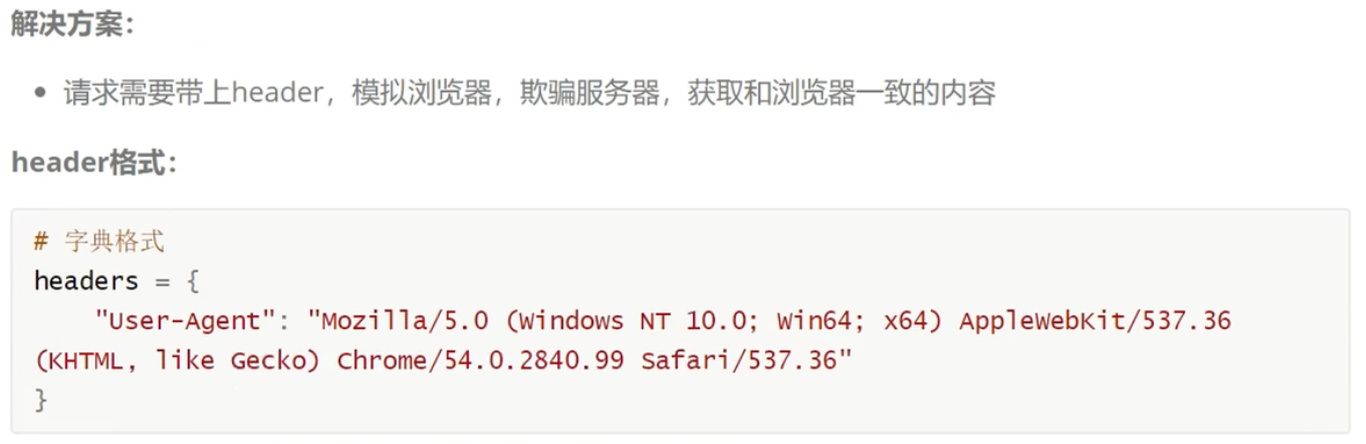
这个header是一个字典,具体内容可以按照F12检查的网页源码中的请求头写
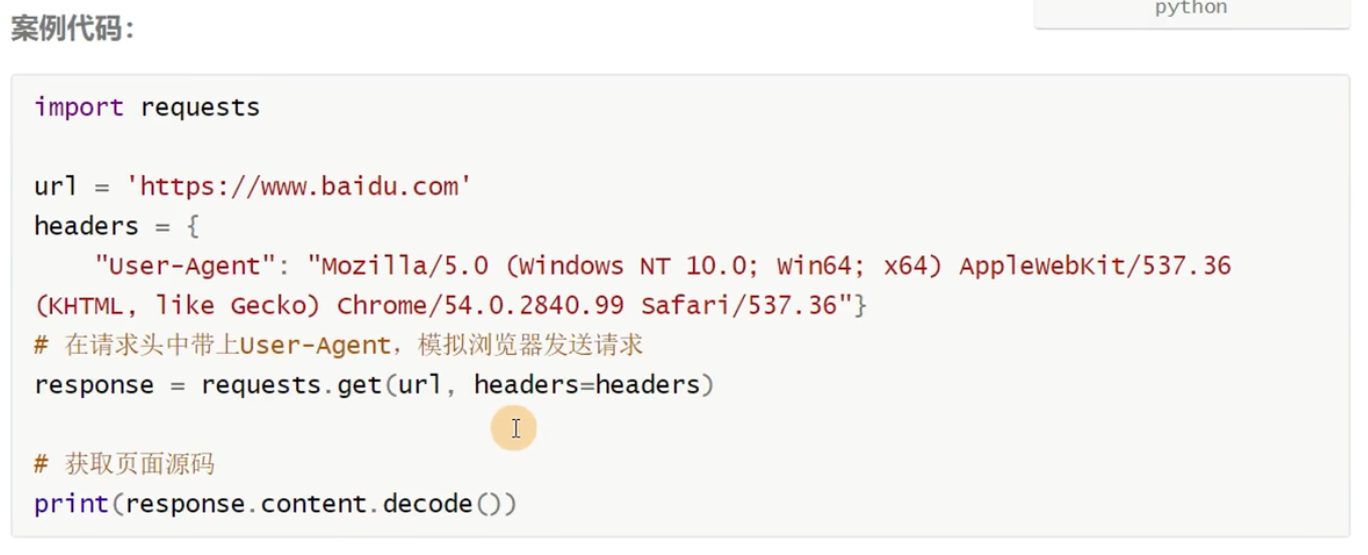
案例实战
百度图片下载
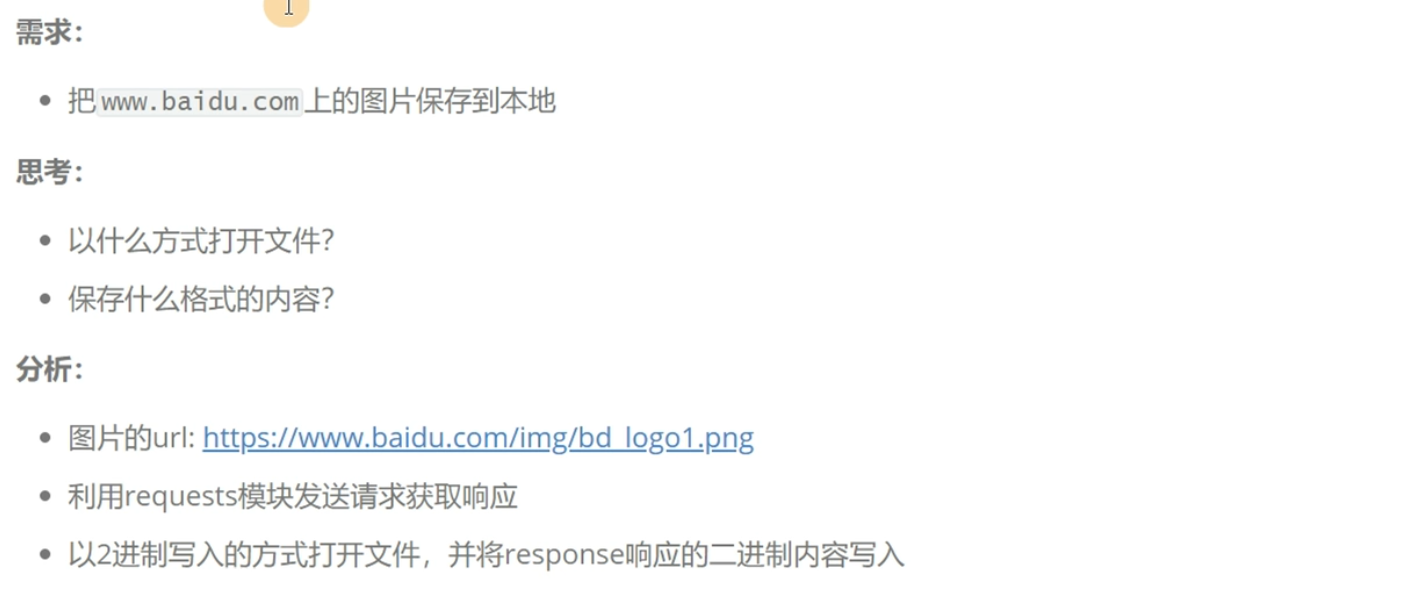
import requests
url = 'https://www.baidu.com/img/24lianghui_3fa64faa4dd8496d4ab2a1d411a93dad.gif'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
# 发送请求获取响应信息
response = requests.get(url=url, headers=header)
# 将返回的响应信息的内容写入到一个图片文件中
with open("baidu.jpg", 'wb') as f:
f.write(response.content)
with open("baidu.jpg", 'wb') as f:这句代码的作用是将从指定 URL 下载的内容(在这个例子中是一张图片)保存到本地文件中。具体解释如下:
-
open("baidu.jpg", 'wb'):"baidu.jpg"是要保存的文件名。'wb'表示以二进制写入模式打开文件。w表示写入模式,b表示二进制模式。
-
with语句:with语句用于确保文件在使用后被正确关闭。即使在写入文件时发生异常,with语句也会自动关闭文件。有了with,就不用手动关闭文件了。
-
as f:as f将打开的文件对象赋值给变量f,这样你就可以通过f来操作文件。
-
f.write(response.content):response.content是从 URL 下载的内容(以字节形式)。f.write()方法将字节内容写入到文件中。
百度网页下载
假设上面代码的提取的是百度的首页
只需要将上面代码的
with open("baidu.jpg", 'wb') as f:
f.write(response.content)
部分改为
with open("baidu.html", 'w', encoding='utf-8') as f:
f.write(response.content.decode())
即可
运行这段代码,就会在本地中得到一个HTML文件。在VScode中运行这个HTML文件,会得到百度的首页,但是这个网页的URL不是www.baidu.com,而是一个localhost了
网易云音乐下载
音频和视频文件的URL获取方式:按F12,选择网络,选择媒体,选择某一个文件就可以看到其URL了(如果没有文件的话可以播放音频或视频,因为播放才是发送GET请求)
import requests
# 歌曲消愁的地址
url = 'https://m801.music.126.net/20240309193058/16f526b24ef5a651c758d3971e8ebd96/jdyyaac/obj/w5rDls0JwrLDji7Cms0j/284'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=header)
with open("消愁.m4a", 'wb') as f:
f.write(response.content)
注意除了文本,剩下的对象都要用wb写入文件
这里的文件格式,在之前查看URL的时候可以看到,是什么就写什么
站点图标下载
见书P61
数据提取之Xpath
需求
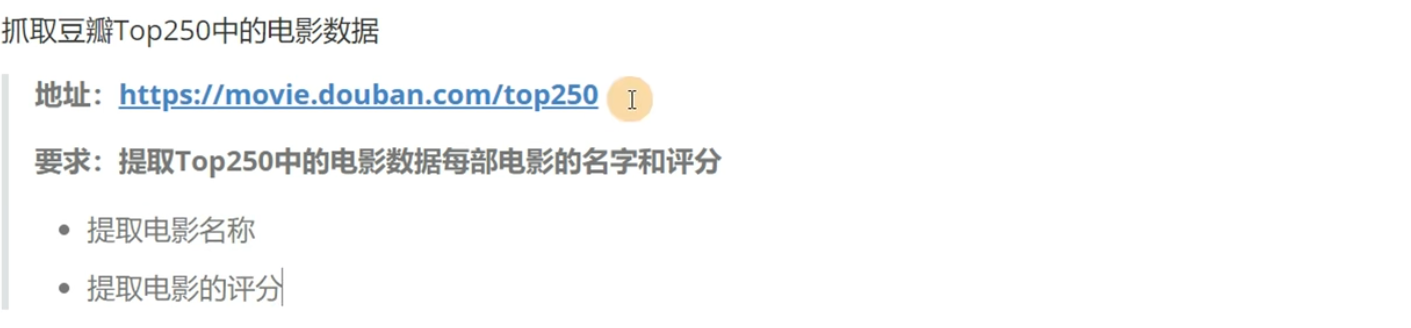
首先将HTML文件爬下来
import requests
# 准备请求数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
url = 'https://movie.douban.com/top250'
# 发送请求
response = requests.get(url=url, headers=headers)
with open('douban.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode())
我们所需要的所有数据都是在这个HTML里面的,所以我们要从这个HTML里面提取数据。这就要用到Xpath
Xpath语法

XML类似于HTML,也就是Xpath可以提取HTML里的数据
对于一个网页,按F12,选择元素,按Ctrl+F,在里面写Xpath就好了
比如对于豆瓣Top250,我们先按下F12,然后按下左上角的按钮
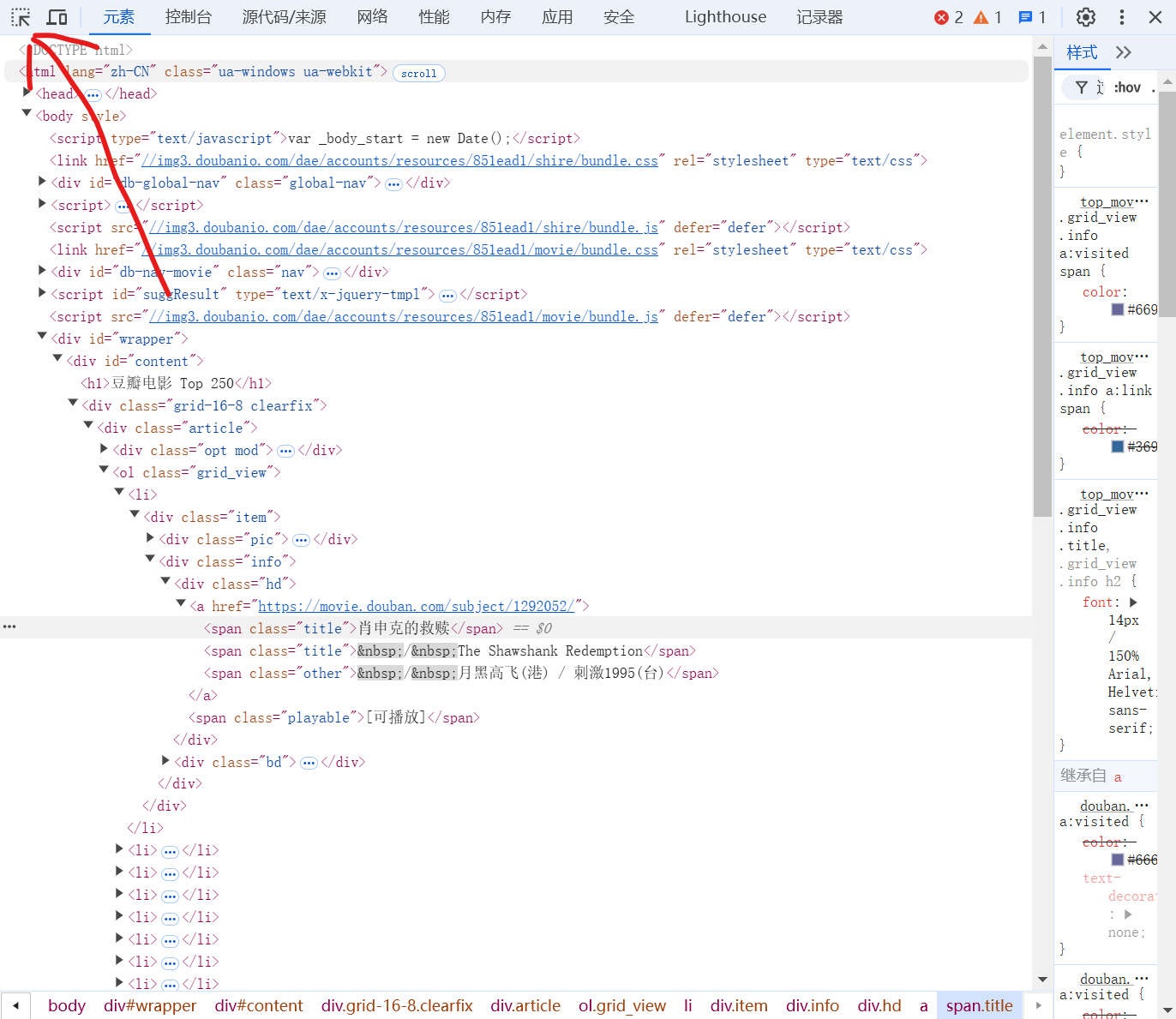
然后将鼠标放到“肖申克的救赎”上面,左键点击即可,就可以定位到HTML文件的一个位置,然后右键点击这个位置,选择复制,选择复制Xpath即可,就可以得到Xpath了。然而这种方法得到的Xpath不是很稳定而且很复杂,自己写的就要好得多(实际上不用自己写,按照上面的操作,最后一步不选择复制Xpath,而是选择复制完整Xpath,这个样子就可以直接拿去用了)
选取节点

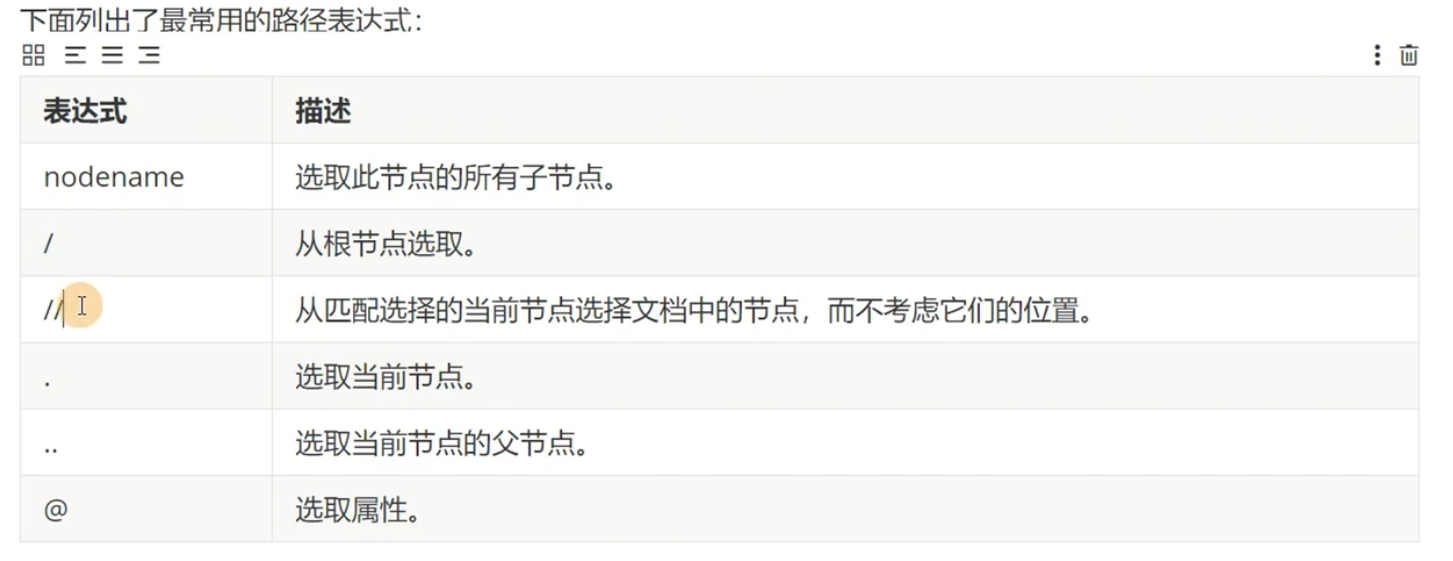
下面是依次举例:
nodename:HTML文件中,尖括号后面的就是nodename,比如head,body/:这个应该是从当前选中的节点开始向下选择当前节点的直接儿子(注意只能选择直接儿子,所以必须以/html开头)//:选择当前节点的所有子孙.:表示不再看当前节点之外的,直接从当前节点开始选。下一解代码会有示例..:表示从父节点开始选@:比如//ol/li[1]//div[@class="pic"]进行定向选择
谓语(条件过滤)
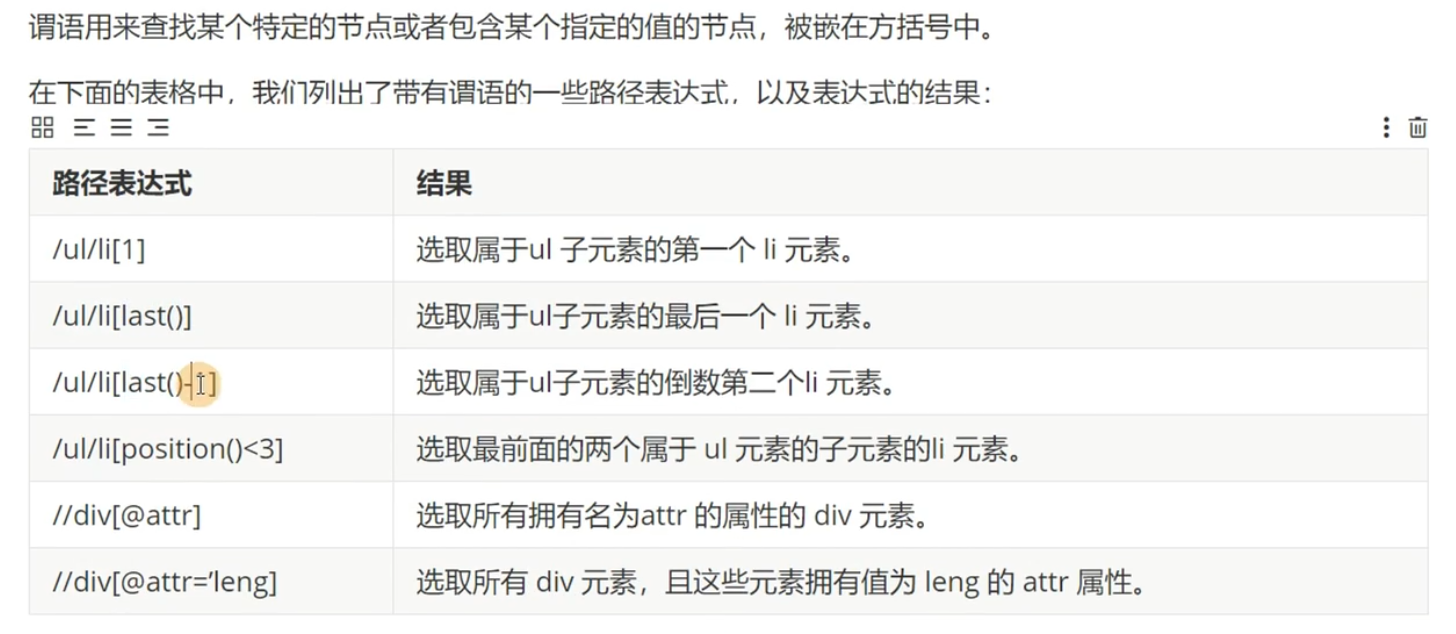
选取未知节点
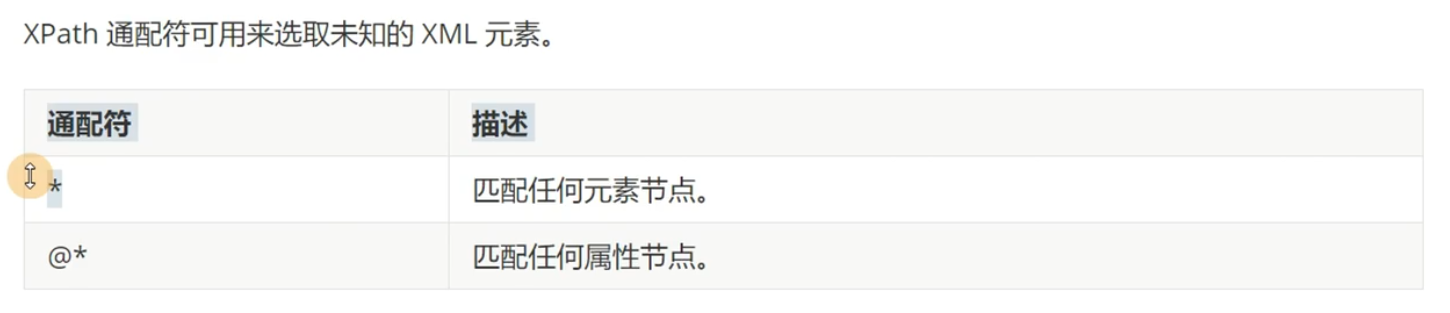

模糊匹配

获取数据
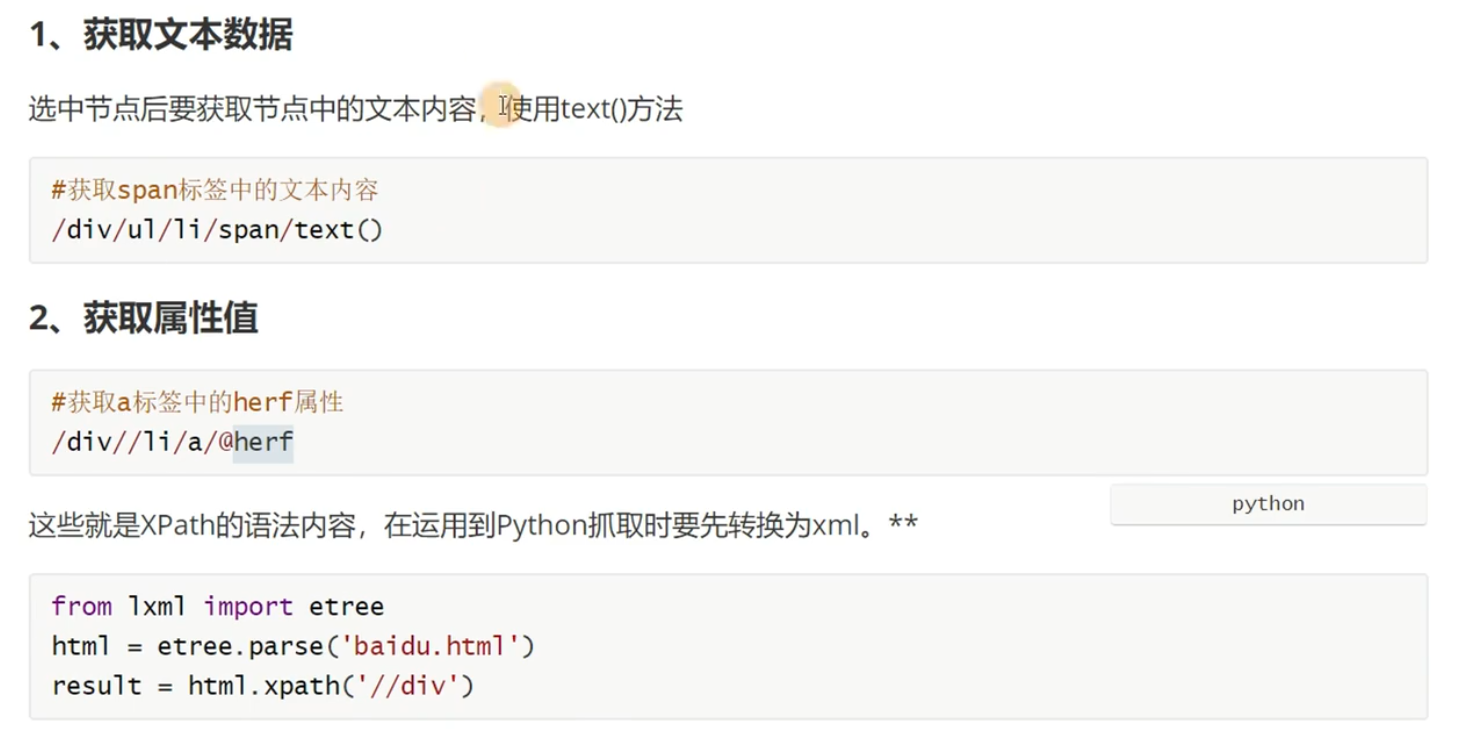
页面的数据要么在文本里面,要么在属性里面
Python中使用Xpath
"""
1、导入lxml
2、将获取到的网页内容转换为xml
3、通过xpath去定位和解析页面中的内容
"""
from lxml import etree
# 读取html页面内容(请求得到的response.content.decode())
page = open('douban.html', 'r', encoding='utf-8').read()
# 将html页面内容转换为xml文档对象
html = etree.HTML(page)
# 使用xpath语法提取页面数据
titles = html.xpath("///*[@class='title']][1]/text()")
score = html.xpath("///*[@class='rating_num']][1]/text()")
print(titles)
print(score)
但是上面的代码的名字和评分是两个列表,一般来说,下面的方法更通用
"""
xpath数据提取的技巧:
1、定位到包含所有数据的的元素 //ol
2、再从中找到包含条数数据所有内容的元素 //ol/li
3、对定位到包含所有元素的列表进行遍历,得到包含单条数据的元素
4、再提单条数据中的详细内容
"""
from lxml import etree
# 读取html页面内容(请求得到的response.content.decode())
page = open('douban.html', 'r', encoding='utf-8').read()
# 将html页面内容转换为xml文档对象
html = etree.HTML(page)
# 定位到包含条数数据所有内容的元素
data_list = html.xpath('//ol/li')
# 对定位到包含所有元素的列表进行遍历,得到包含单条数据的元素
for li in data_list:
# 提单条数据中的详细内容
title = li.xpath(".//span[@class='title']/text()") # 这里的 . 就是直接从li开始往下找
score = li.xpath(".//span[@class='rating_num']/text()")
number = li.xpath('.//div[@class="star"]/span[last()]/text()')
print("电影的名称:", title[0], "评分:", score[0], "评价人数", number[0])
# 注意title,score和number都是列表
最后的输出结果如下
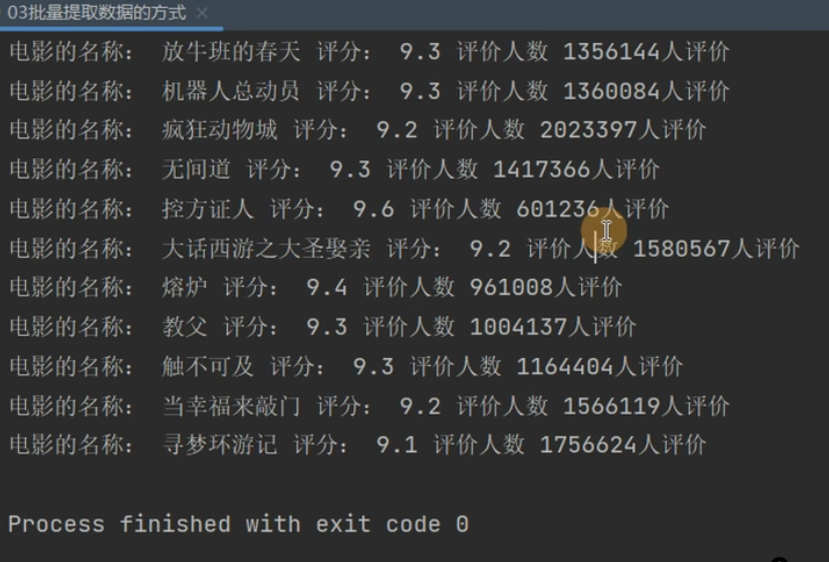
上面是抓取单页数据,我们要抓取多页数据怎么办呢?只需要将所有页面的URL放进一个列表里面进行遍历就好了
from lxml import etree
import requests
class DouBan:
base_url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
def __init__(self):
# 定义一个属性用来保存所有的url地址
self.url_list = []
# 生成所有页面的url地址保存到url_list属性中
for i in range(10):
url = self.base_url.format(i * 25)
self.url_list.append(url)
def get_page_data(self, url):
"""抓取单页数据的函数"""
# 发送请求
url = "https://movie.douban.com/top250" # 这里假设一个初始URL,实际可能需要根据分页逻辑调整
response = requests.get(url=url, headers=self.headers)
# 读取html页面内容(请求得到的response.content.decode())
page = response.content.decode()
# 将html页面内容转换为xml文档对象
html = etree.HTML(page)
# 定位到包含条数数据所有内容的元素
data_list = html.xpath('//ol/li')
# 对定位到包含所有元素的列表进行遍历,得到包含单条数据的元素
for li in data_list:
# 提单条数据中的详细内容
title = li.xpath(".//span[@class='title']/text()")
score = li.xpath(".//span[@class='rating_num']/text()")
number = li.xpath('.//div[@class="star"]/span[last()]/text()')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
# 发送请求
url = "https://movie.douban.com/top250" # 这里假设一个初始URL,实际可能需要根据分页逻辑调整
response = requests.get(url=url, headers=headers)
# 读取html页面内容(请求得到的response.content.decode())
page = response.content.decode()
# 将html页面内容转换为xml文档对象
html = etree.HTML(page)
# 定位到包含条数数据所有内容的元素
data_list = html.xpath('//ol/li')
# 对定位到包含所有元素的列表进行遍历,得到包含单条数据的元素
for li in data_list:
# 提单条数据中的详细内容
title = li.xpath(".//span[@class='title']/text()")
score = li.xpath(".//span[@class='rating_num']/text()")
number = li.xpath('.//div[@class="star"]/span[last()]/text()')
def run(self):
for url in self.url_list:
print("===============开始抓取页面:", url)
self.get_page_data(url)
if __name__ == '__main__':
db = DouBan()
db.run()
GET请求参数
查询参数的基本使用
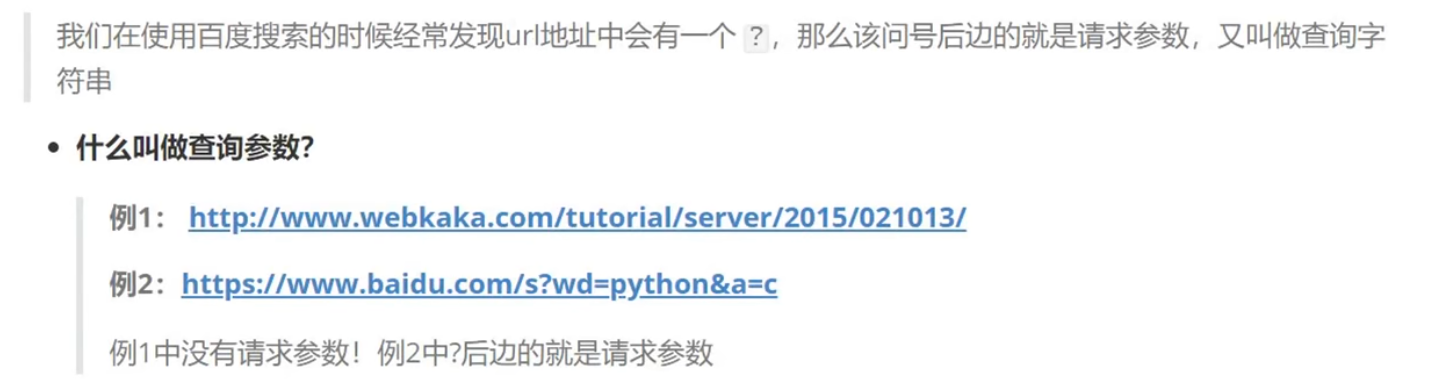
查看豆瓣Top250的参数:进入Top250的第二页,按F12,选择网络,选择第一个对象,选择载荷,就可以看到查询字符串参数了
import requests
# requests请求传递查询参数方式一:参数直接拼接在URL后
url = 'https://www.baidu.com/s?ie=UTF-8&wd=%E9%95%BF%E5%9F%8E'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=headers)
print(response.content.decode())
# 方式二:通过params参数传递
# 请求地址
url = 'https://www.baidu.com/s'
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
# 请求参数(查询参数)
params = {
'ie': "UTF-8",
'wd': "长城"
}
# 发送请求传递参数时,使用params进行传递
response = requests.get(url=url, headers=headers, params=params)
print(response.content.decode())
搜狗问答数据抓取
多页数据抓取代码实现
上面两个内容视频没有
POST请求和模拟登陆
POST请求介绍

下面以百度翻译手机版为例说明
首先打开百度翻译,将其切换为手机版,如下
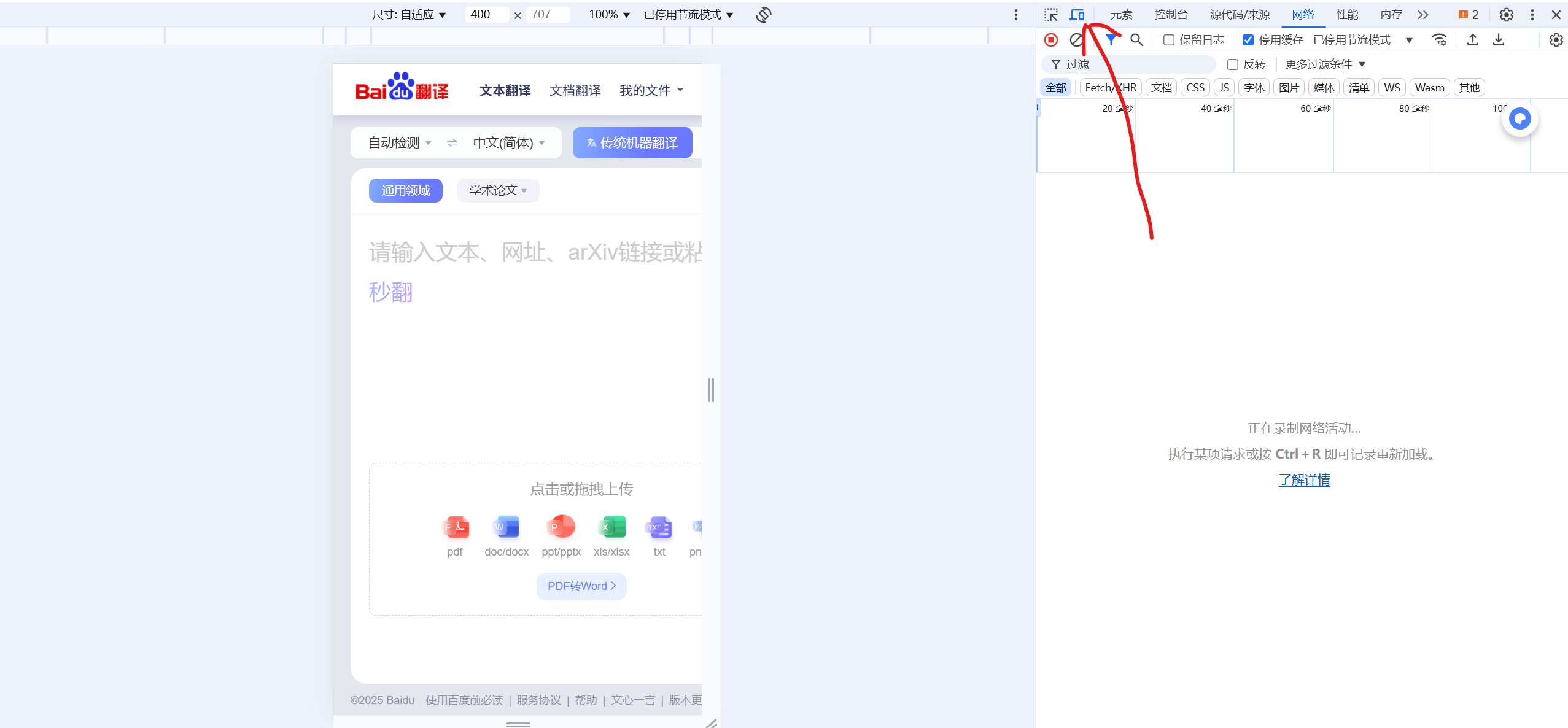
然后输入一个单词,找到sug对象
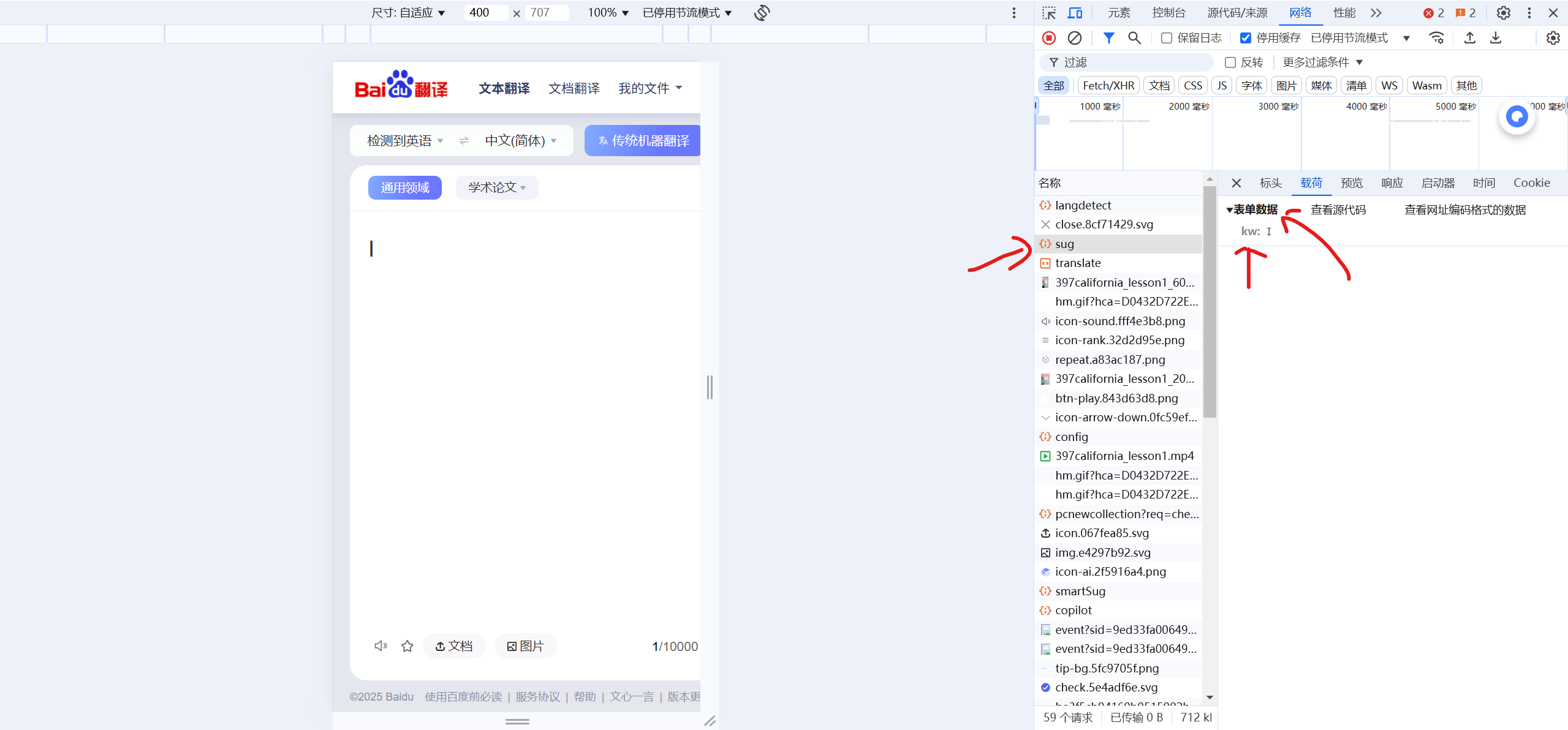
从里面可以看到字典的关键字以及传的数据类型(form-data还是json)是什么。这里是传递form-data:
"""
# 发送post请求的方法:
requests.post()
参数传递:
1. 表单参数: form-data
requests.post(url, data=字典参数)
2. json参数:
requests.post(url, json=字典参数)
"""
import requests
# 百度翻译手机版
url = 'https://fanyi.baidu.com/sug'
params = {
"kw": "python3"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
response = requests.post(url=url, data=params, headers=headers)
print(response.content.decode())
使用课堂派的话,传递的就是json数据:
import requests
# 登录接口URL
url = 'https://openapi5.ketangpai.com/UserApi/login'
# 请求参数(JSON格式)
params = {
"code": "",
"type": "login",
"reqtimestamp": 1709991594825,
"remember": '0',
"password": "a54e426qr5t6y",
"email": "3247119728@qq.com",
"mobile": ""
}
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
# 发送POST请求
response = requests.post(url=url, json=params, headers=headers)
# 打印响应内容
print(response.content.decode())
# 对于返回的是json数据的响应,也可以像下面这个样子输出,会自动得到json数据
# print(response.json())
.json()方法就是将返回结果(JSON格式的字符串)转化为字典
POST请求案例
这个没有
模拟登陆

如何进行模拟登陆

以中华网为例,输入错误的密码之后,就可以得到响应
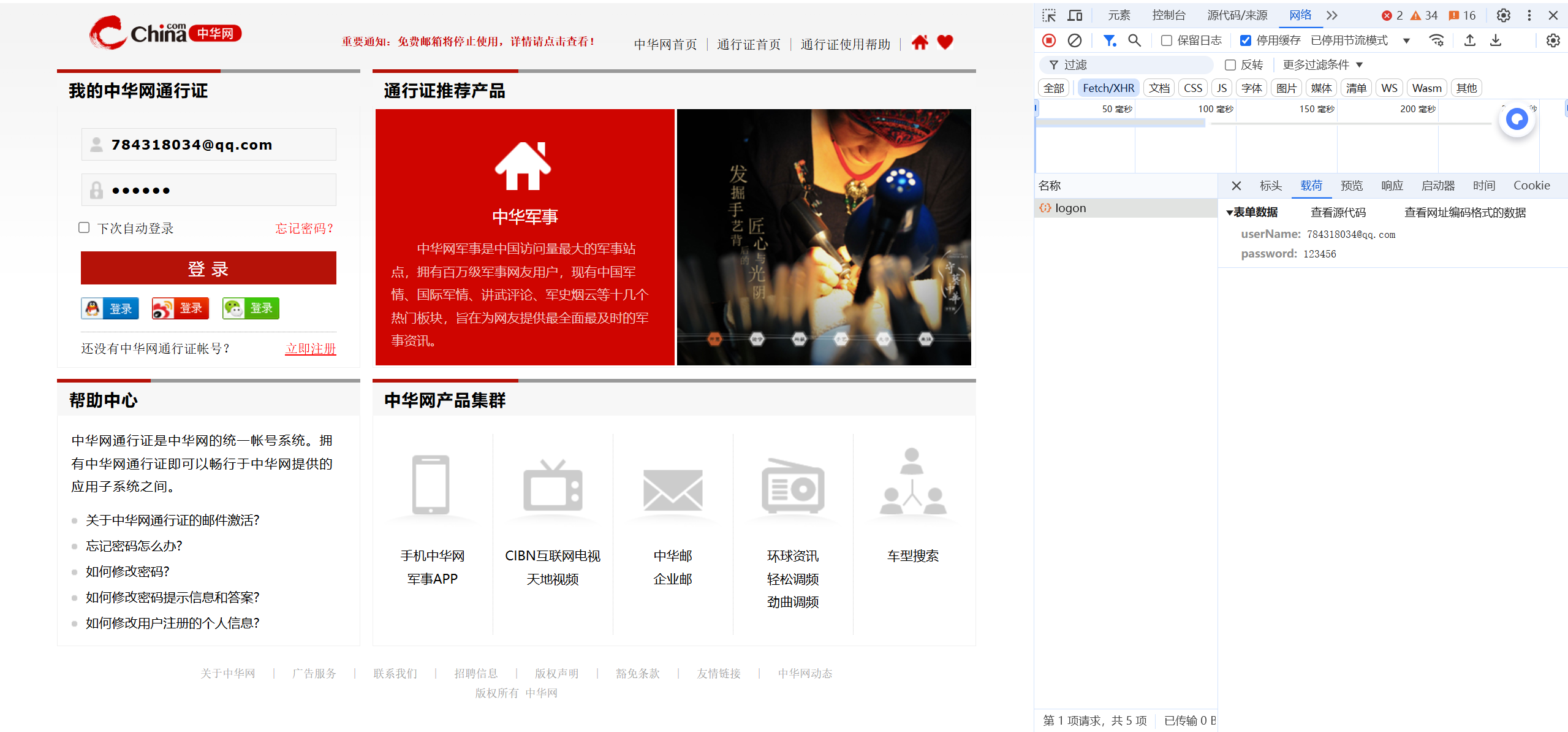
那么后端服务器如何判断是否登陆成功呢?也就是说现在我们想要访问登录后的一个页面,那么我们会发一个请求,后台服务器如何判断这个请求是登陆成功之后发的请求呢?这就涉及到下面两种鉴权方式
Cookie+Session鉴权机制


登陆成功之后服务器会发起SessionId会话,里面会携带Cookie,以后客户的每次请求都会携带Cookie,服务器就可以在Cookie里面找SessionId,如果有效就判断登陆成功
同样以中华网为例说明一下。假设登陆成功了之后,就可以通过如下方式查找Cookie

其实这里应该有SessionId的,但是没有说明有其他不同名的但是相同作用的字段。之后的每次请求都会带上Cookie,如果鉴权失败,会返回到登陆界面
一般来说,登陆失败得到的响应的载荷是form-data,那么就使用Cookie+Session
总结使用cookie+session鉴权的网站模拟登录的流程步骤如下
- 传递账号密码,进行登录
- 登录之后保存cookie(返回时在响应头的set-cookie字段中)
- 请求其他的页面时,携带cookie
基于Token的鉴权机制
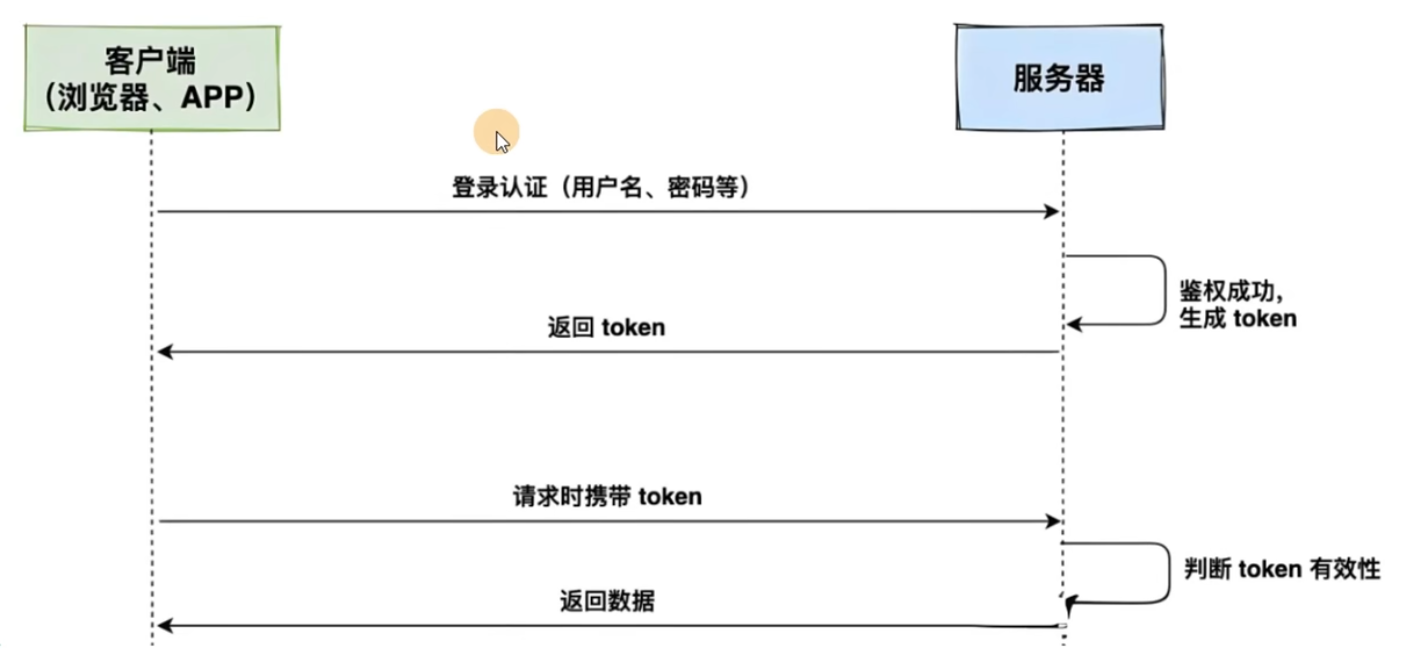
在浏览器返回的响应中,可以按照如下方式查看Token信息
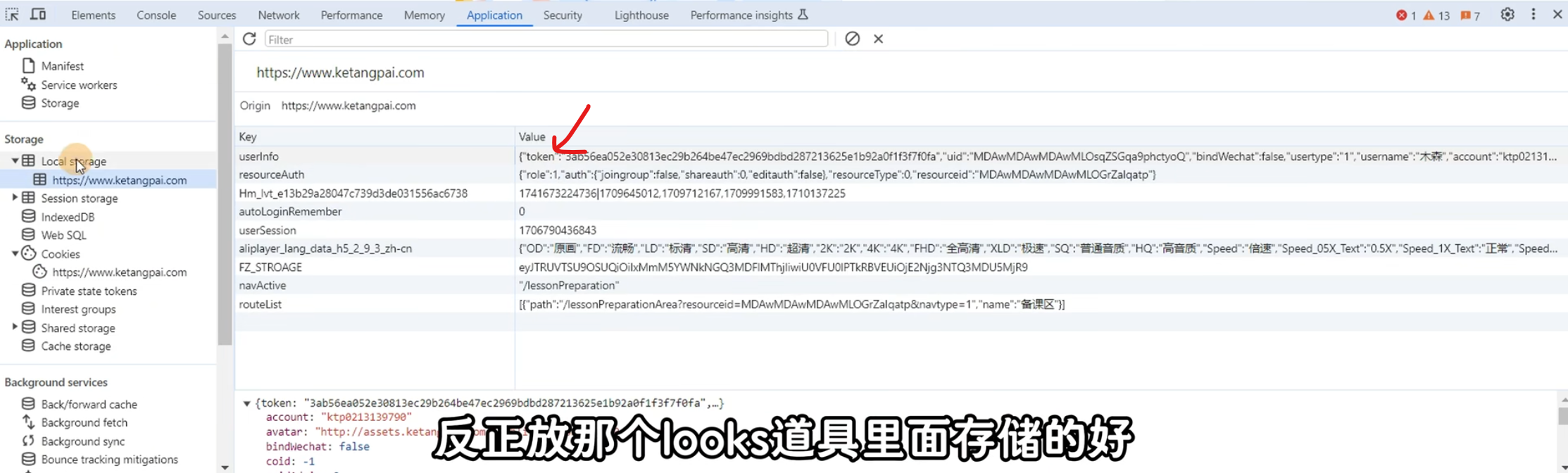
一般来说,登陆失败得到的响应的载荷是Request Payload,那么就使用Token
还可以通过看响应的域名和登陆界面的域名是否一样(如果不一样那么肯定用的是Toekn)
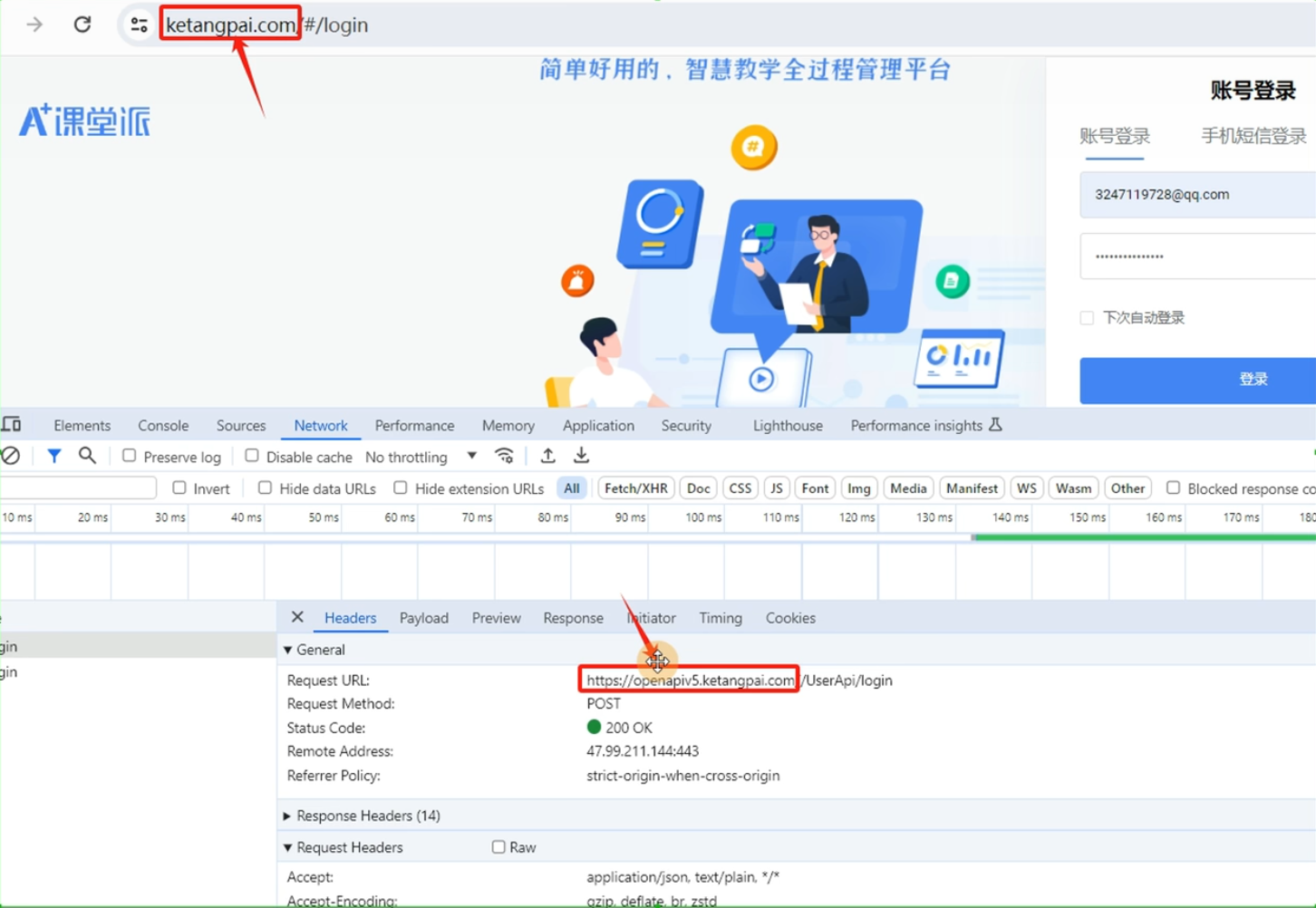
总结使用token鉴权的网站模拟登录的流程如下
- 传递账号密码,进行登录
- 登录之后保存token(返回的时候,在响应体中)
- 请求其他的页面时,携带token
requests处理Cookie的方案
方式一:以字典格式传递
cookies = {}
request.get(cookies=cookies)
方式二:以字符串格式传递
headers = {
'Cookie':"字符串格式cookie值”
}
request.get(headers=headers)
方案三:使用request.session(),创建一个对象,这个对象会自动保存上次请求的Cookie
中华网模拟登陆案例
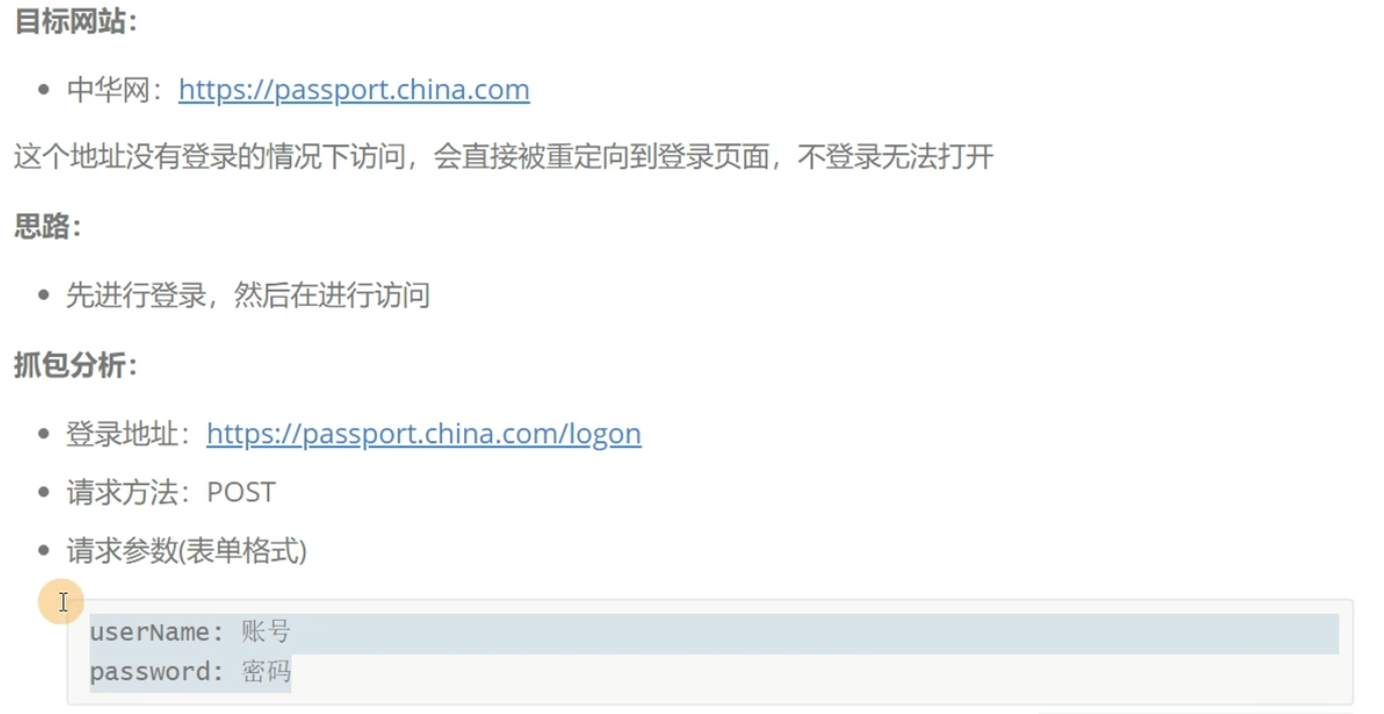
"""
模拟登录,访问需要登录之后才能打开的页面
1、发送登录请求
2、保存cookie信息
3、携带cookie信息请求需要登录的页面
"""
import requests
# 登录URL
login_url = 'https://passport.china.com/logon'
# 登录参数(示例)
params = {
"username": "your_username",
"password": "your_password"
}
# 发送登录请求
response = requests.post(url=login_url, data=params)
# 打印响应内容
print(response.content.decode())
但是上面的代码其实是会抓取失败的,因为目标网站做了反爬虫,按照之前说的,我们加上User-Agent,但是会发现还是失败了,说明这个网站有其他的反爬处理:检测请求的来源(从哪一个页面发送的这个请求)
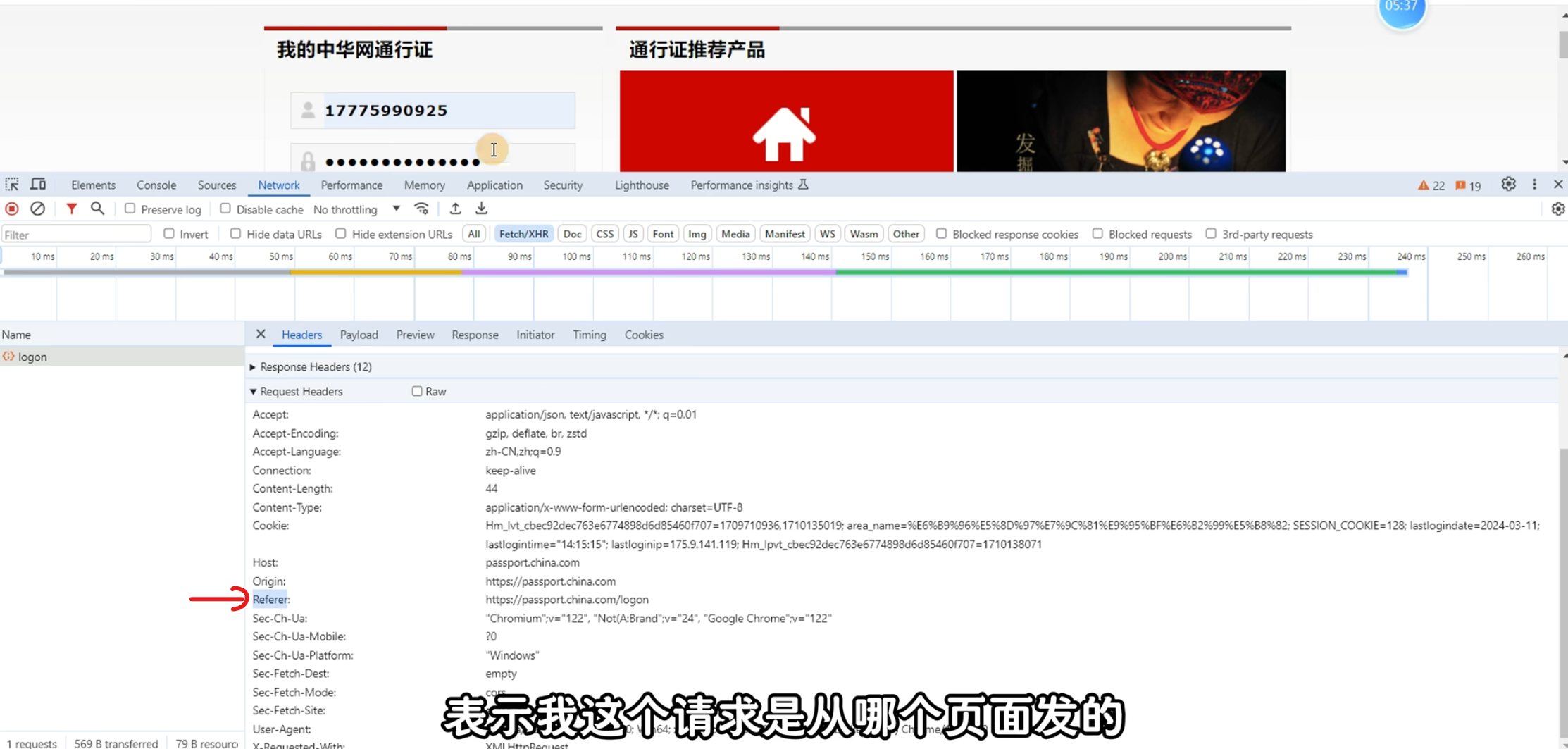
解决方法也很简单:人工抓包一下,然后看看Referer字段,加到header里面即可
"""
模拟登录,访问需要登录之后才能打开的页面
1、发送登录请求
2、保存cookie信息
3、携带cookie信息请求需要登录的页面
"""
import requests
# 登录URL
login_url = 'https://passport.china.com/logon'
# 登录参数(示例)
params = {
"username": "your_username",
"password": "your_password"
}
headers = {
"Referer": "https://passport.china.com/logon",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
# 发送登录请求
response = requests.post(url=login_url, data=params, headers=headers)
# 打印响应内容
print(response.content.decode())
注意登陆之后要携带Cookie
方案一:
# 请求需要登录的页面
res2 = requests.get('https://passport.china.com', headers=headers, cookies=response.cookies)
print(res2.content.decode())
方案二:Cookie字符串具体的值只能在浏览器中手动登陆然后抓包响应,在响应头中的Cookie字段中去找(所以很麻烦)
# 方式二:以字符串格式传递
headers = {
"Referer": "https://passport.china.com/logon",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Cookie": "__gads=ID=0e160abb1f268f46-2250d24b21e30070:T=1690872676:RT=1690872676:S=ALNI_MYYYVR0JUD6SBvLTeT59hDJ0nmR"
}
# 请求需要登录的页面
res2 = requests.get('https://passport.china.com', headers=headers)
print(res2.content.decode())
方案三:
# 1、使用requests.session创建一个请求的对象
http = requests.session()
# 2、发送请求进行登录
response = http.post(url=login_url, data=params, headers=headers)
# 3、请求需要登录的页面
res2 = http.get('https://passport.china.com', headers=headers)
print(res2.content.decode())
requests扩展
见书P66
Beautiful Soup
见书

 浙公网安备 33010602011771号
浙公网安备 33010602011771号