第十九课 多模态深度学习(第十八课没上)



首先介绍一下早期的多模态模型
现在我们有视觉模型和语言模型
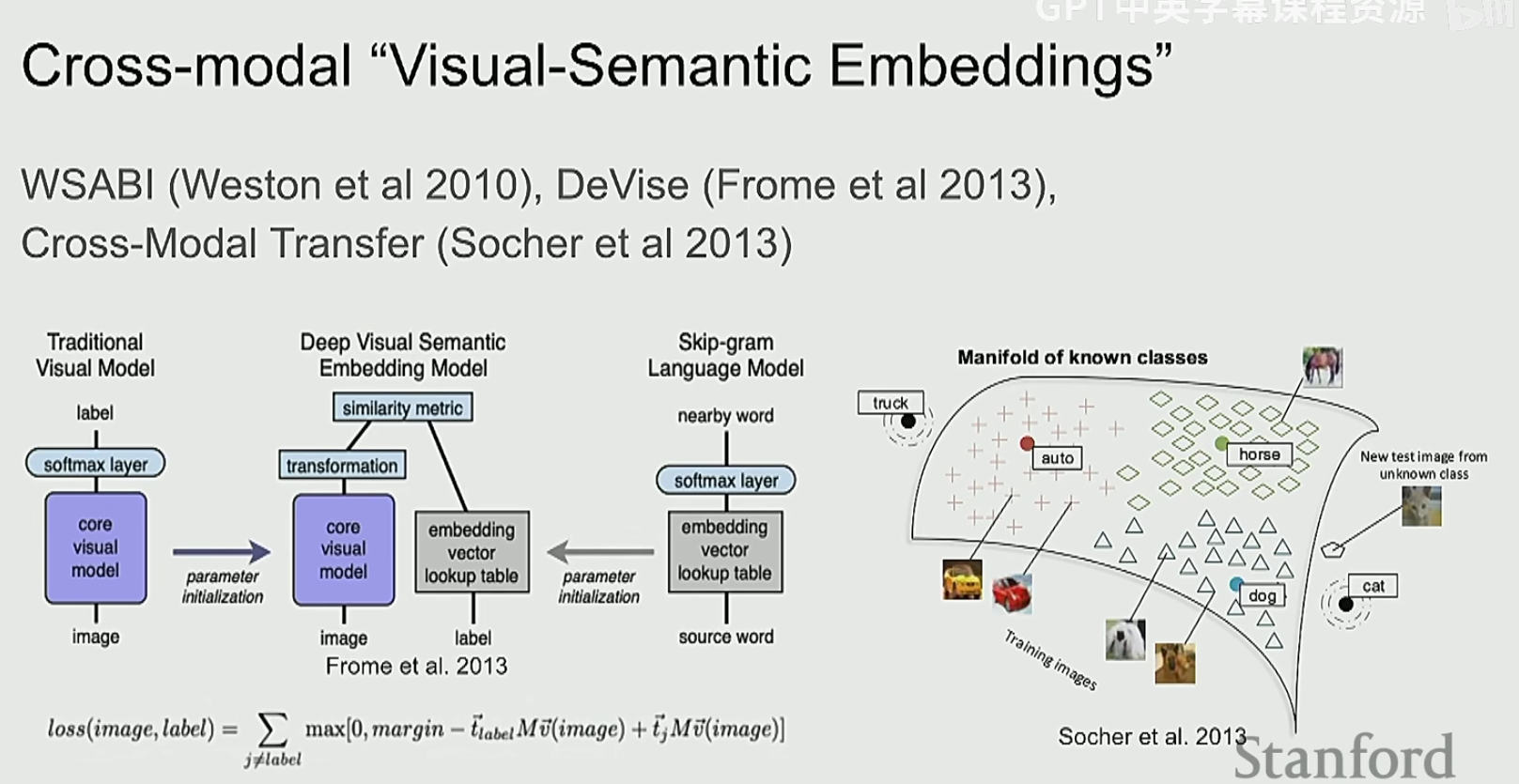
我们现在要把图片嵌入和词嵌入放到同一个空间中,这个时候就要定义一种评估函数,让相近的文字和图片挨在一起,不相近的则远离
除了跨模态迁移(就是结合图片和文本,上面的方法),也可以将他们融合,一起反映多模态词嵌入。一个著名的算法就是视觉词袋

举一个简单的例子。我们是怎么学会“猫”这个字的呢?我们可以去字典查询定义,也可以选择看图片。显然后者是一个更好的方法
现在我们会利用深度学习的方法实现多模态
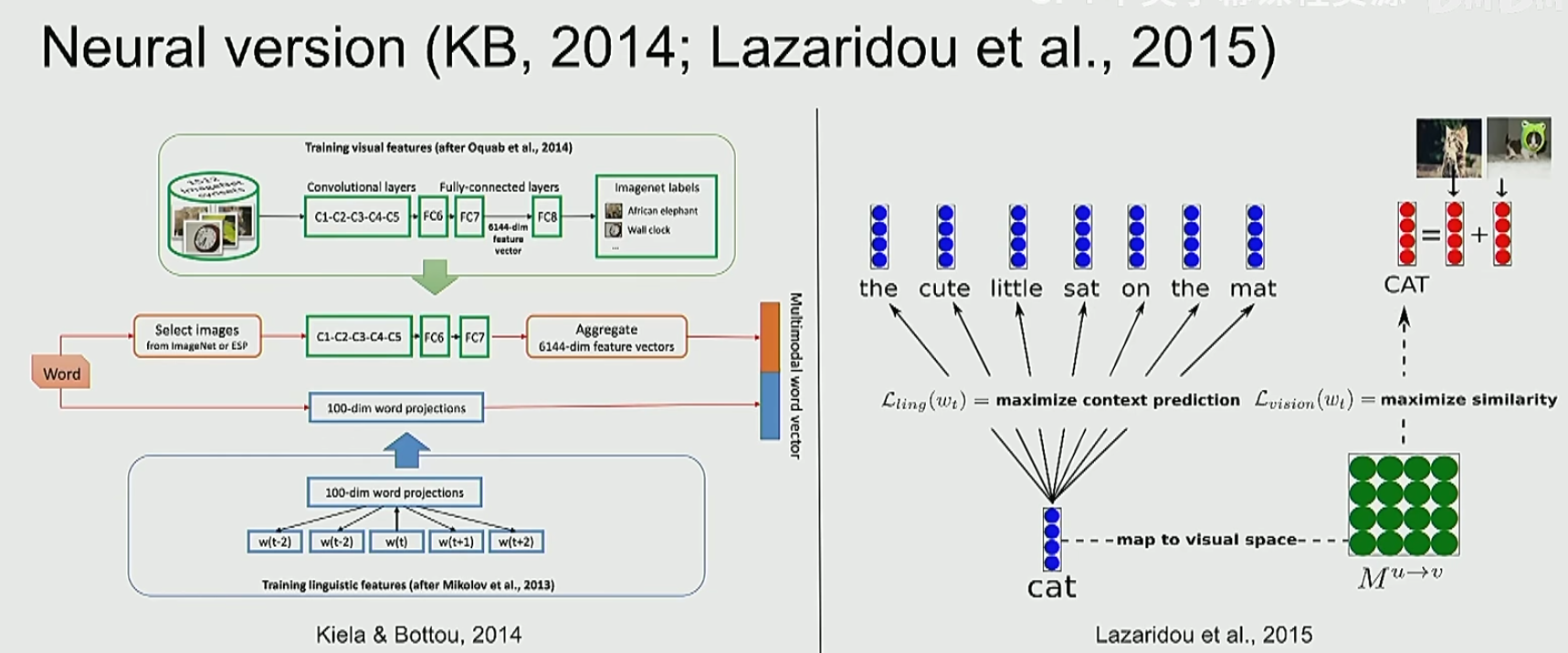
词嵌入的表示非常局限,我们更关心句子

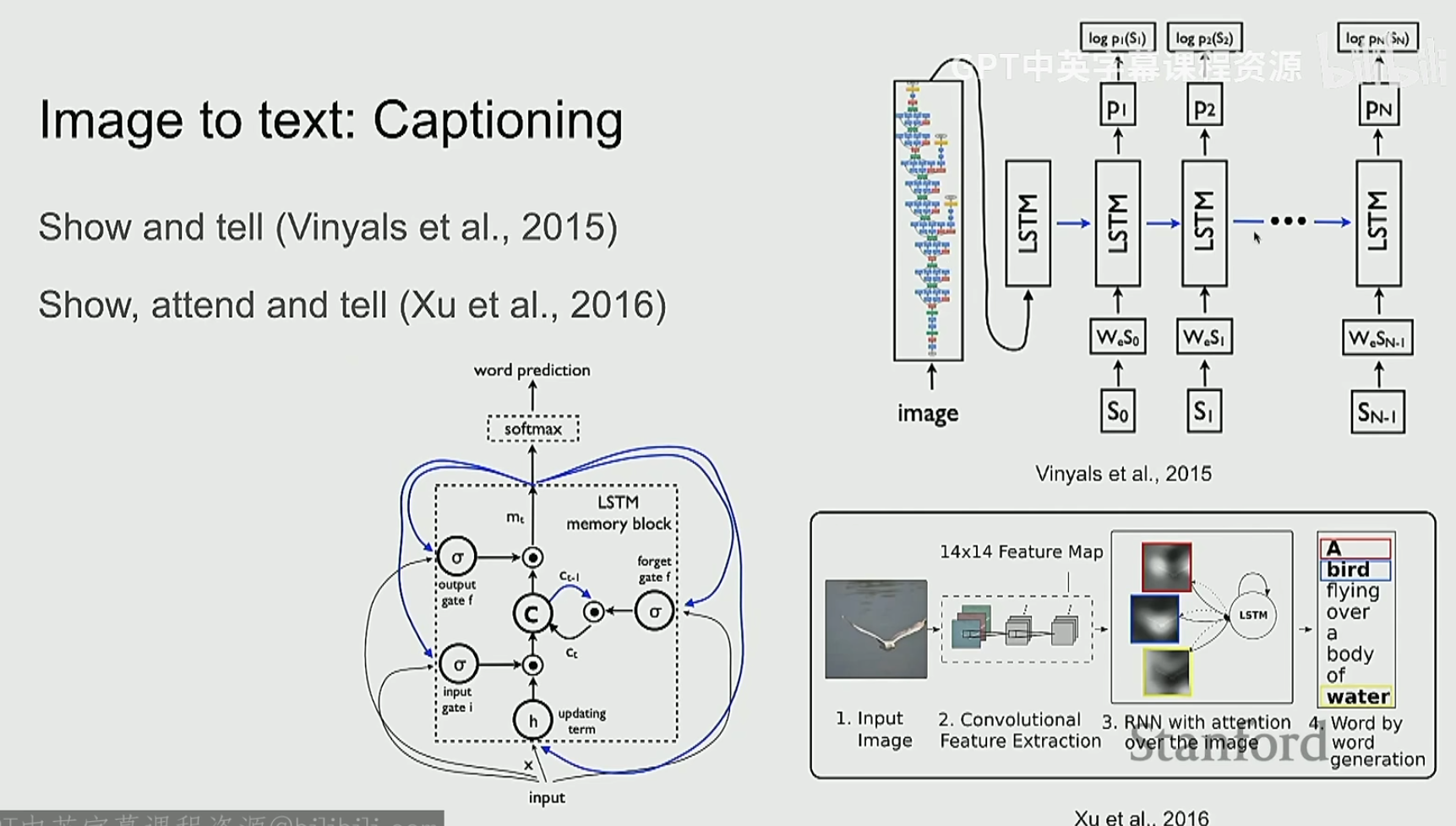
编码器在发展,解码器当然也要发展

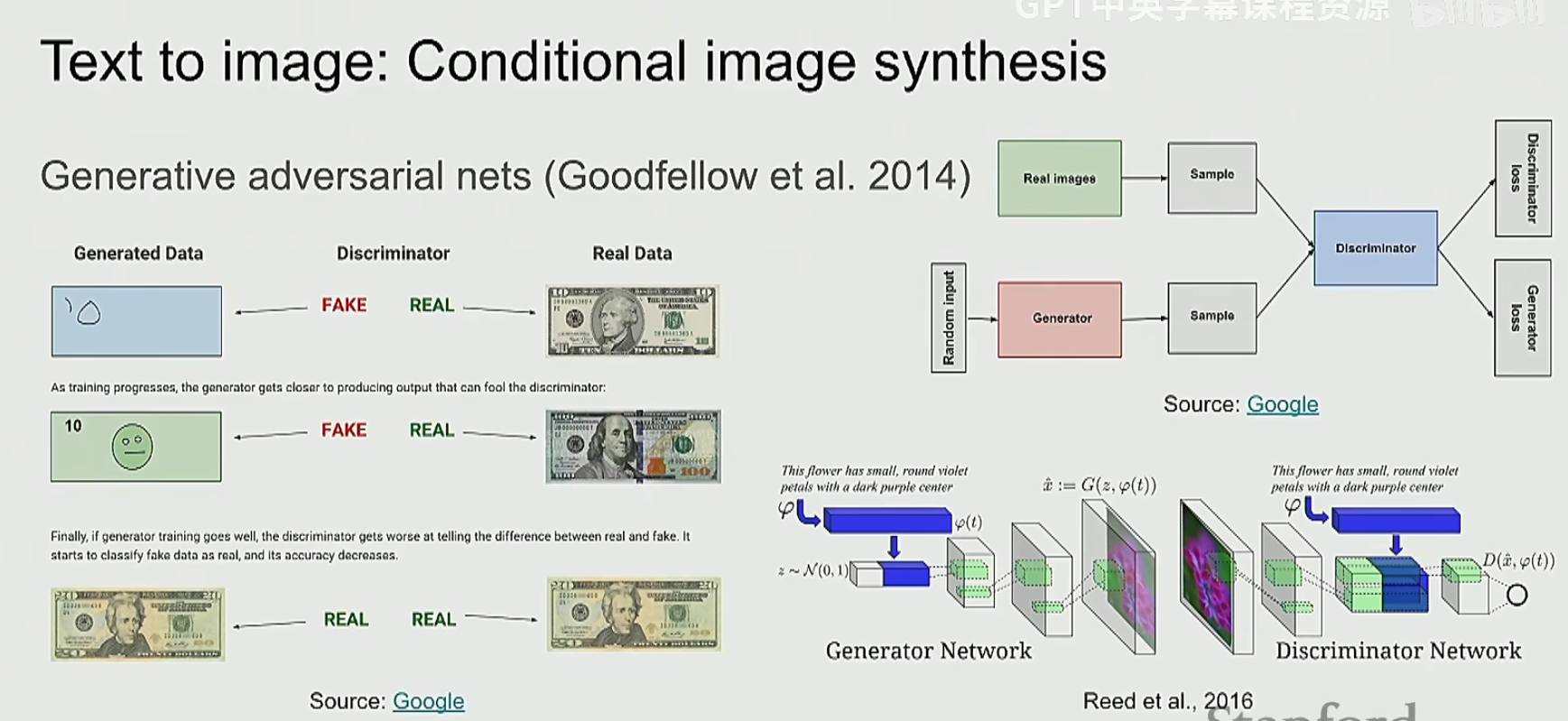
生成对抗网络的基本思想是:有一个生成器和判别器,目标是让生成器产生判别器无法区分的图像(也就是无法判断真假)
接下来准备介绍一些现在的模型。但是在介绍之前,我们要先问一个问题

第一条就是,比如一个视觉模型,可以不看图片直接利用文本回答

这个后面还是没看,感觉没啥用啊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号