第十二课(2024年)基准测试与评估
来看一下讲师认为的理想的开发过程
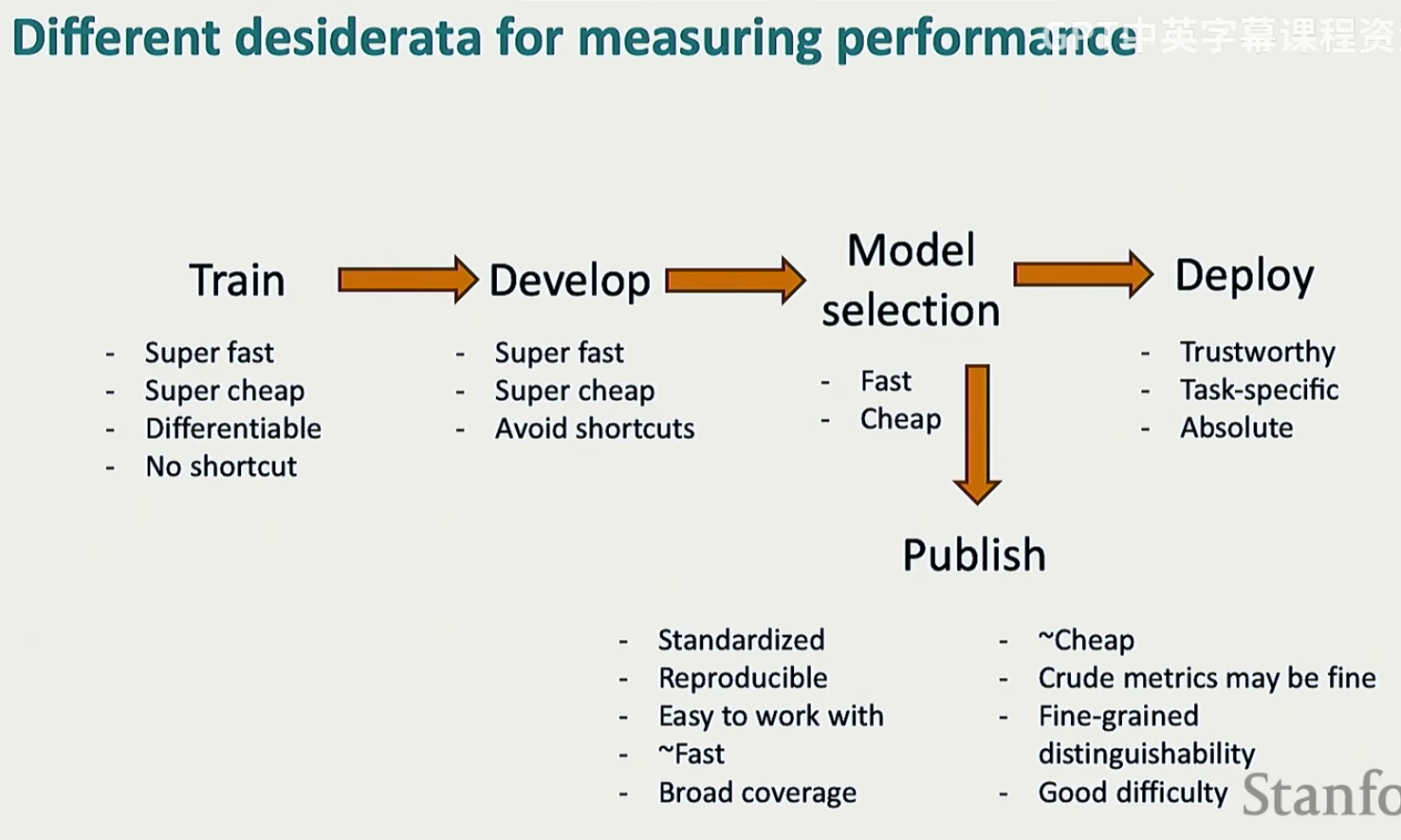
Deploy的Absolute的意思:部署阶段的评测指标是绝对的,之前的阶段都是从若干个模型中选择最好的,但最后一个阶段就只剩下一个模型了,我们必须要让这个模型的准确率达到一个设定的绝对阈值
Publish的Standardized和Reproducible:标准化和可复现性,因为我们还是希望自己的论文可以持续几年的,如果不可以复现的话就没有人引用生命力就很差了;Crude metrics may be fine:指标不完美也没有什么关系,比如现在这个指标可以拿去跟十年之后的使用这个指标的模型做对比;Good difficulty:任务不要太难,否则的话所有方法都将趋于随机猜测;反之所有方法的准确率都很高
一个基准测试的例子
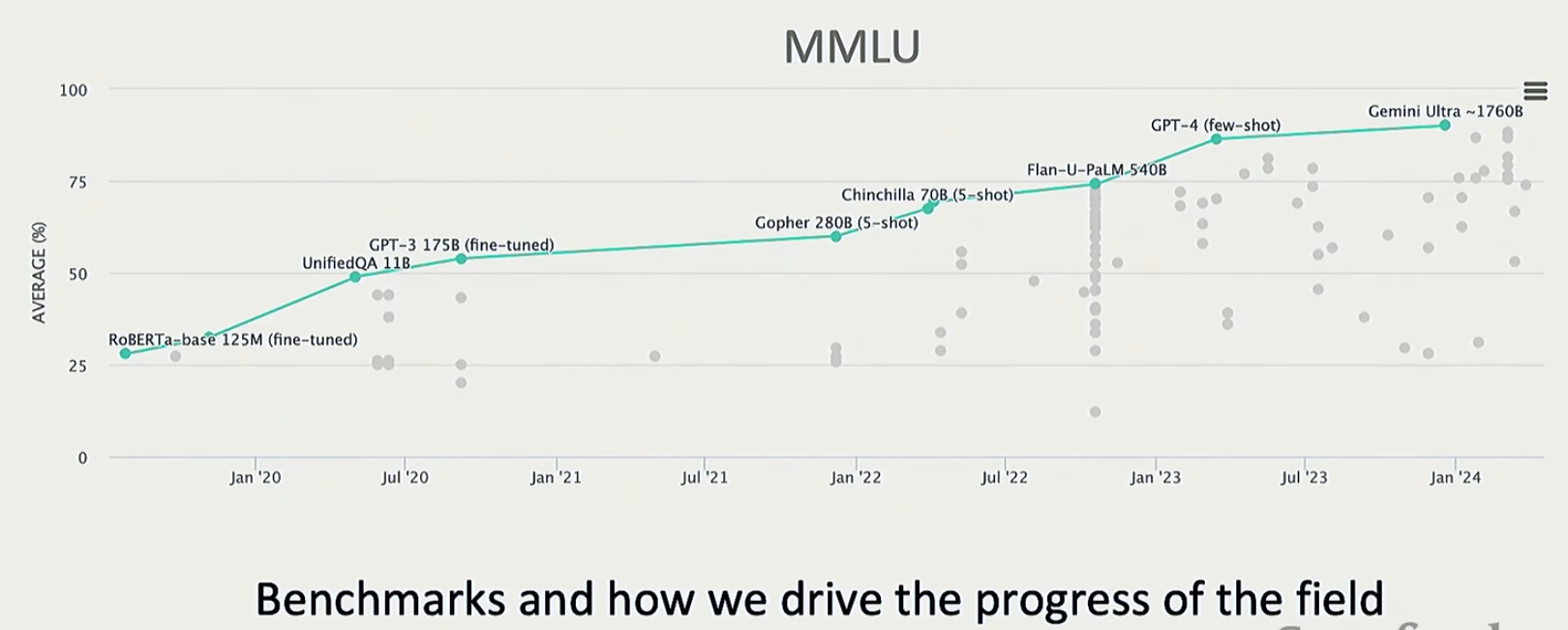
可以看到从随机猜测(这是四选一的选择题)到了接近满分的水平;再强调一下,指标是否完美不重要,我们只需要确认模型在相同指标上的得分越来越高就好了
我们的任务分成两类,各自有各自的评估指标
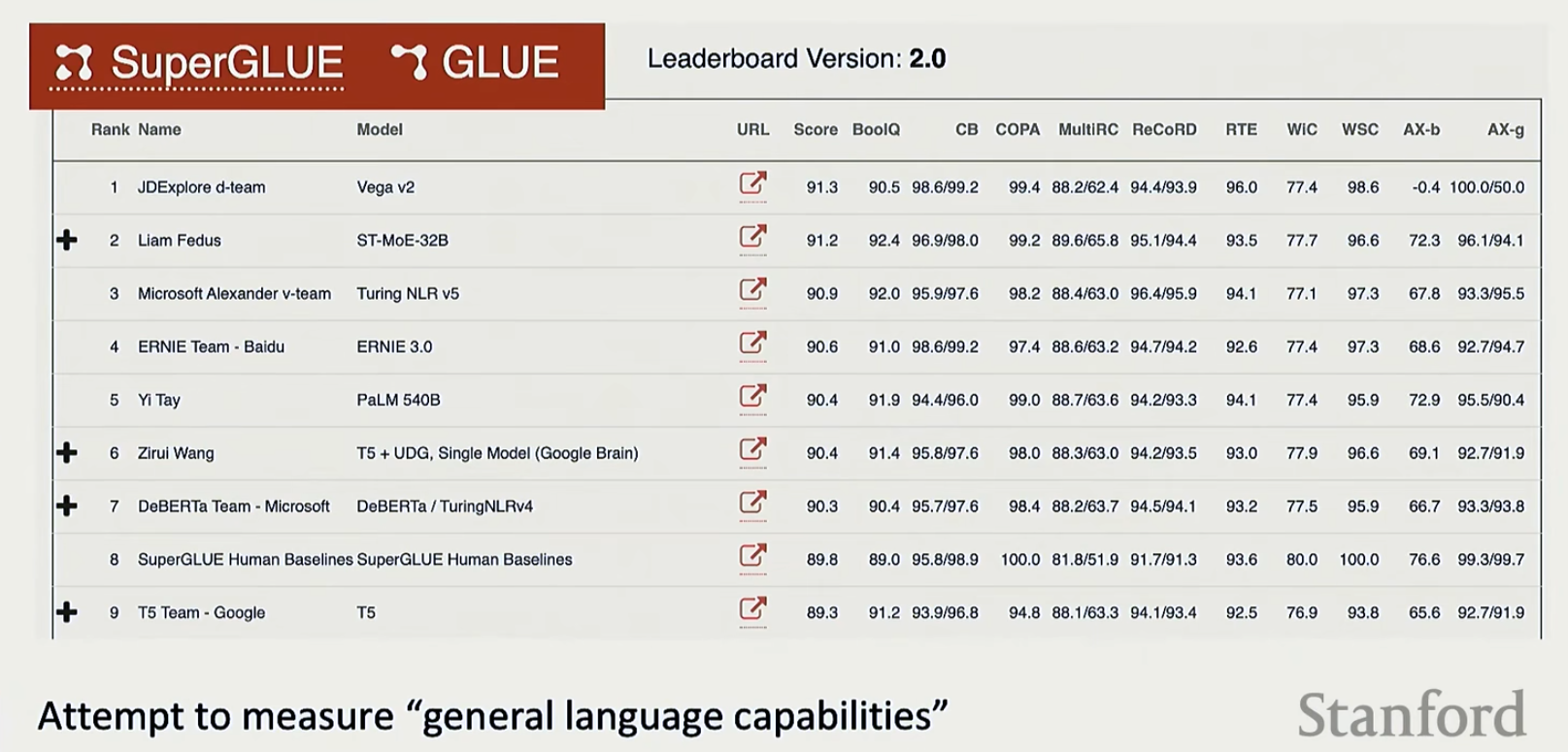
- 非开放性任务:精确率,召回率,\(F1\)分数,ROC,AUC等等。有一个叫SuperGLUE的可以看一下
![image]()
注意他这里的Score是将所有数据集的得分取平均得到的,事实上这种做法是一点也不正确的,因为这些数据是本质不同的数据(比如有些是精确率有些是召回率等等),是不能取平均的
在对非开放性任务做基准测试的时候还要注意一个叫做虚假相关性的东西:模型在训练中可能学到输入文本与标签之间的非因果关联。例如,根据某些关键词或句式(而非语义)进行预测,导致在真实场景中表现不可靠。下面以自然语言推断为例
![image]()
- 开放性任务
![image]()
![image]()
这三种方法具体见第十一课(本节课这个内容从00:20:40开始,还没看)




 浙公网安备 33010602011771号
浙公网安备 33010602011771号