

第十课 从人类反馈中引导强化学习
GPT-1

GPT-2(至少要三个支持是因为网络上的垃圾信息很多,有了支持能够显著减少垃圾信息的量)

GPT-2首次实现了零样本学习。零样本学习是指模型在从未接触过特定任务的训练数据 、无需额外示例 、无需调整参数(梯度更新)的情况下,直接完成任务的能力。例如,用户只需给模型一个自然语言描述的任务(如“将这段英文翻译成中文”),模型就能直接生成结果,而不需要额外的训练(注意,预训练的时候可不是专门按照翻译去训练的)
GPT-3

GPT-3发现少样本学习(也叫上下文学习)效果更好。少样本学习就是在给出任务之前,我们给出几个例子,让模型理解在干什么。由于我们只给了少量的例子,所以叫做“少样本”(注意我们给出的样本是下游任务的少样本,也就是说我们直接拿预训练模型去解决下游任务,在没有微调的情况下给出少样本让其处理);这个过程看起来像是学习(因为模型通过例子明白了要干什么),但是没有进行梯度下降
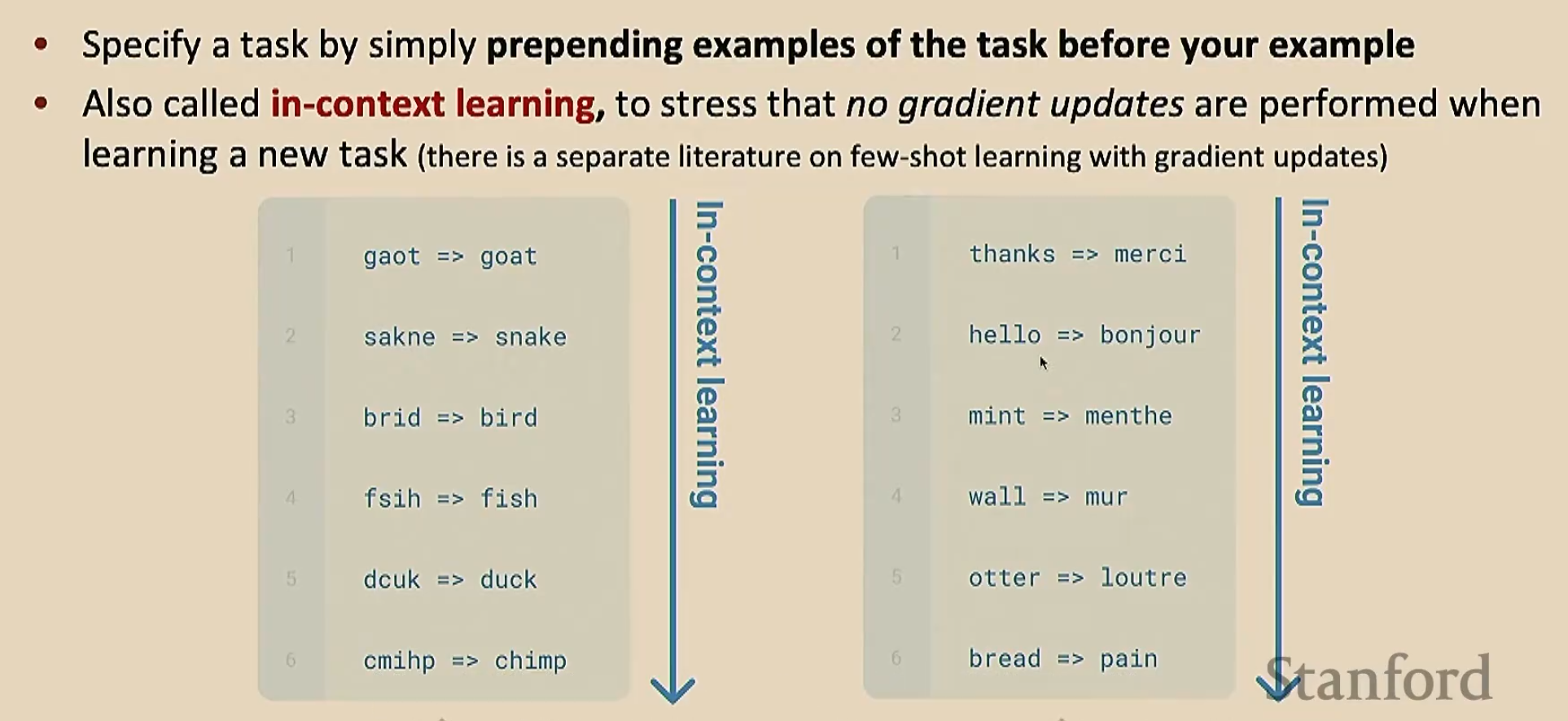
下面是零样本学习和少样本学习的对比
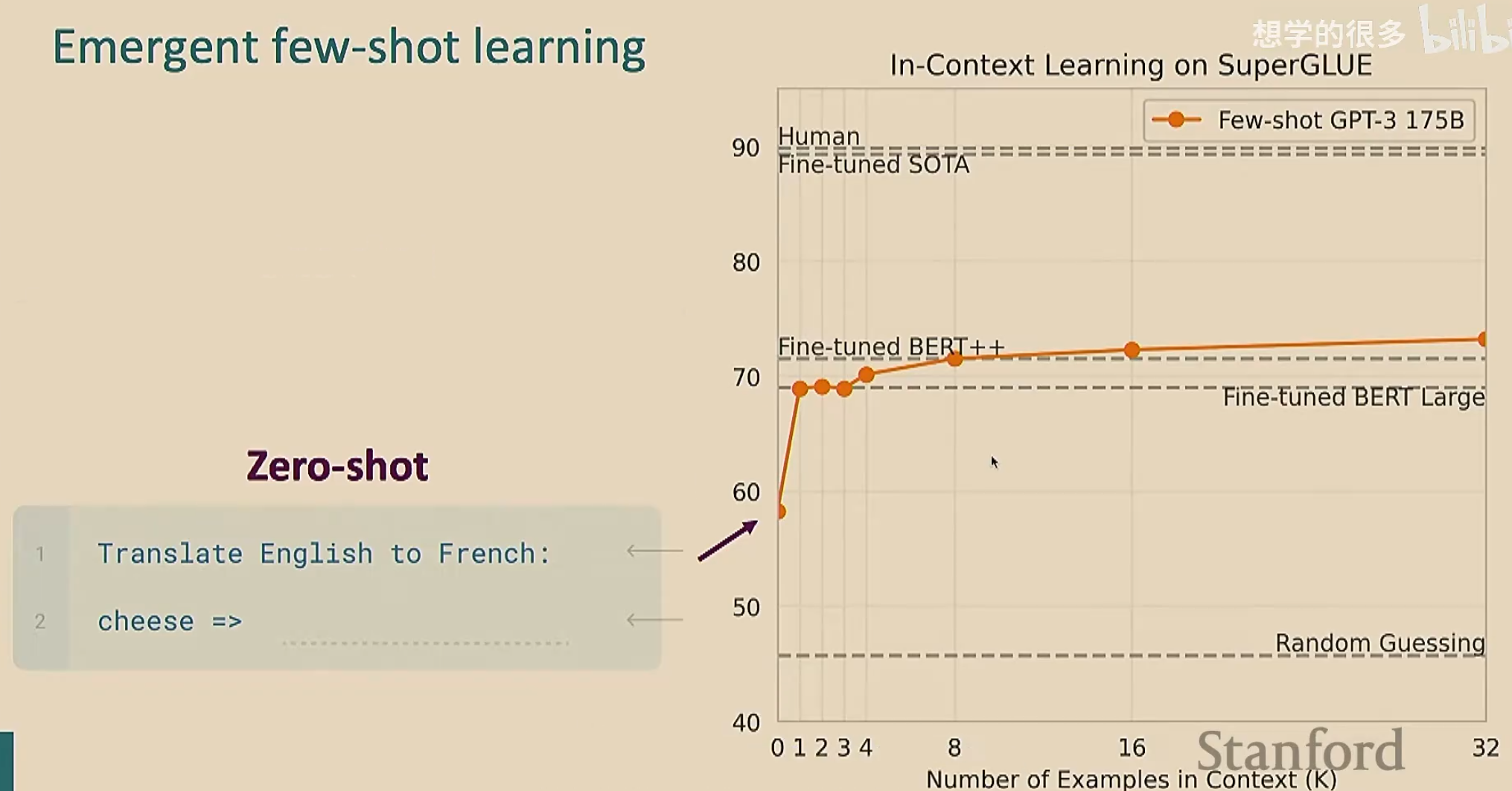
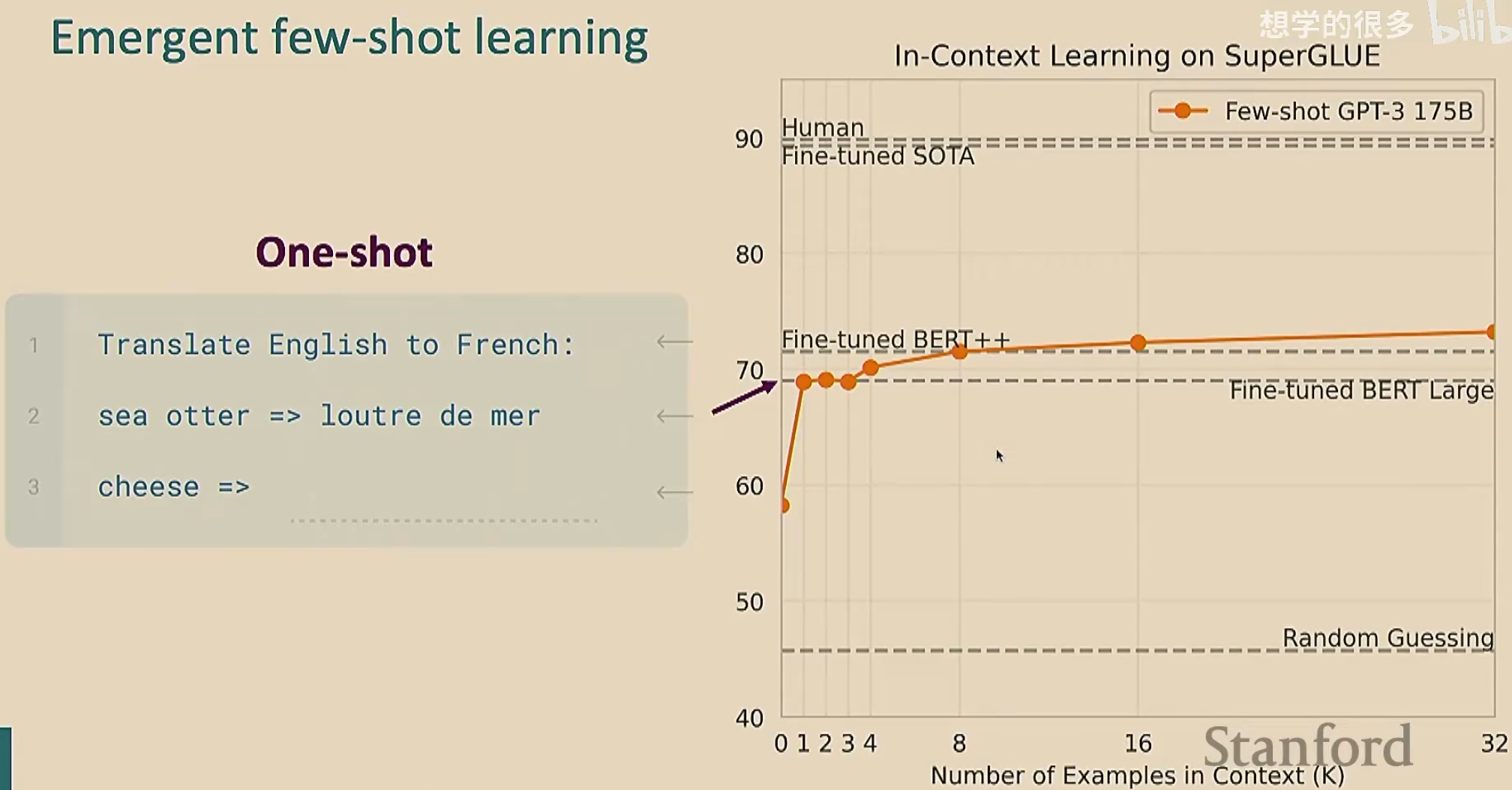
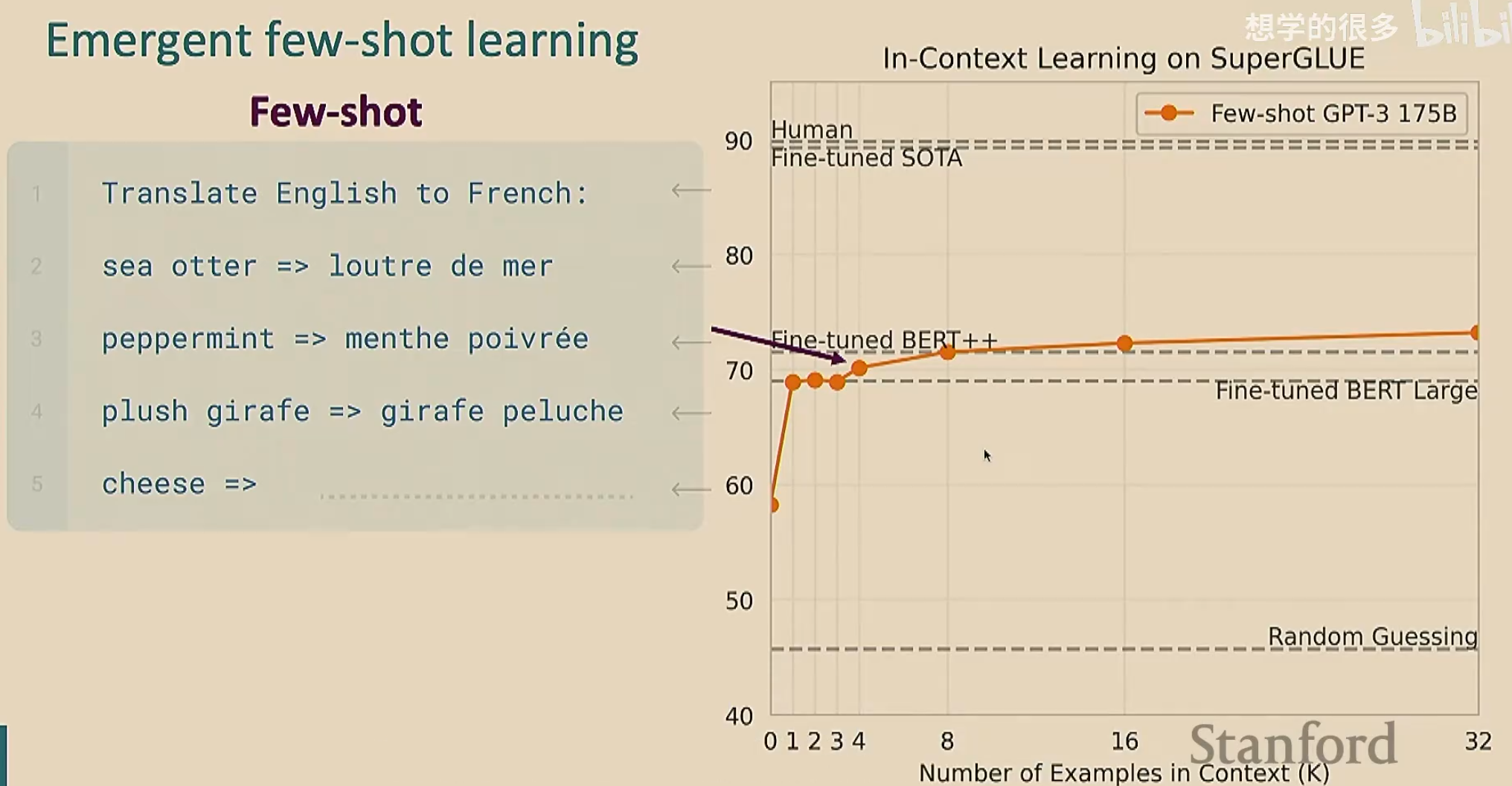
由于我们给出了例子,可能会认为模型是在记忆预训练的文本。为了排除这种情况,我们自创一些奇奇怪怪的不可能在预训练文本中出现的任务,来验证模型是否在学习
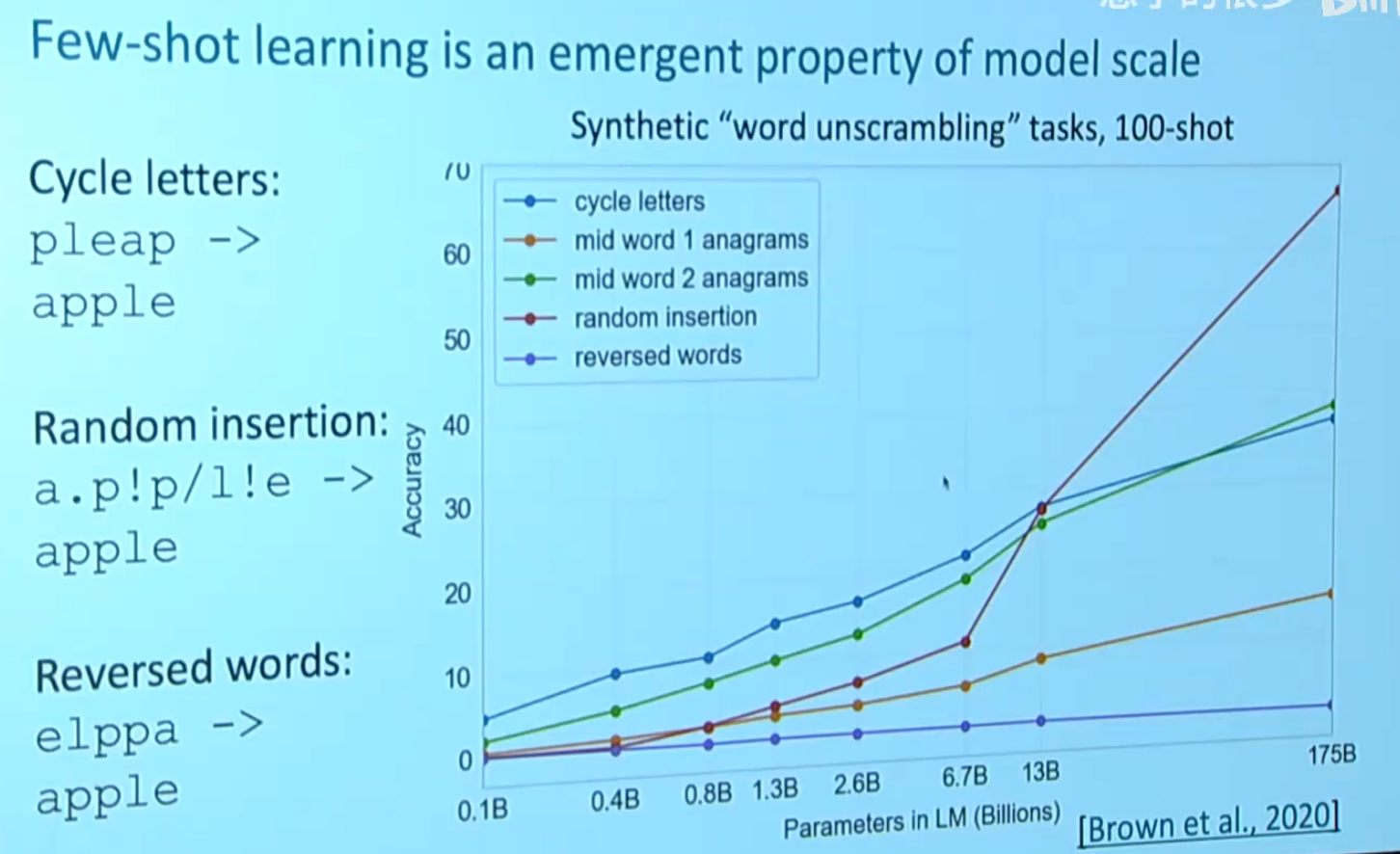
可以看到,GPT-3在反向单词这个任务的表现非常糟糕。模型嘛,总是有点缺点的
最后对比一下传统微调和零/少样本学习

上节课提到了思维链,我们可以来比较一下加不加思维链的效果
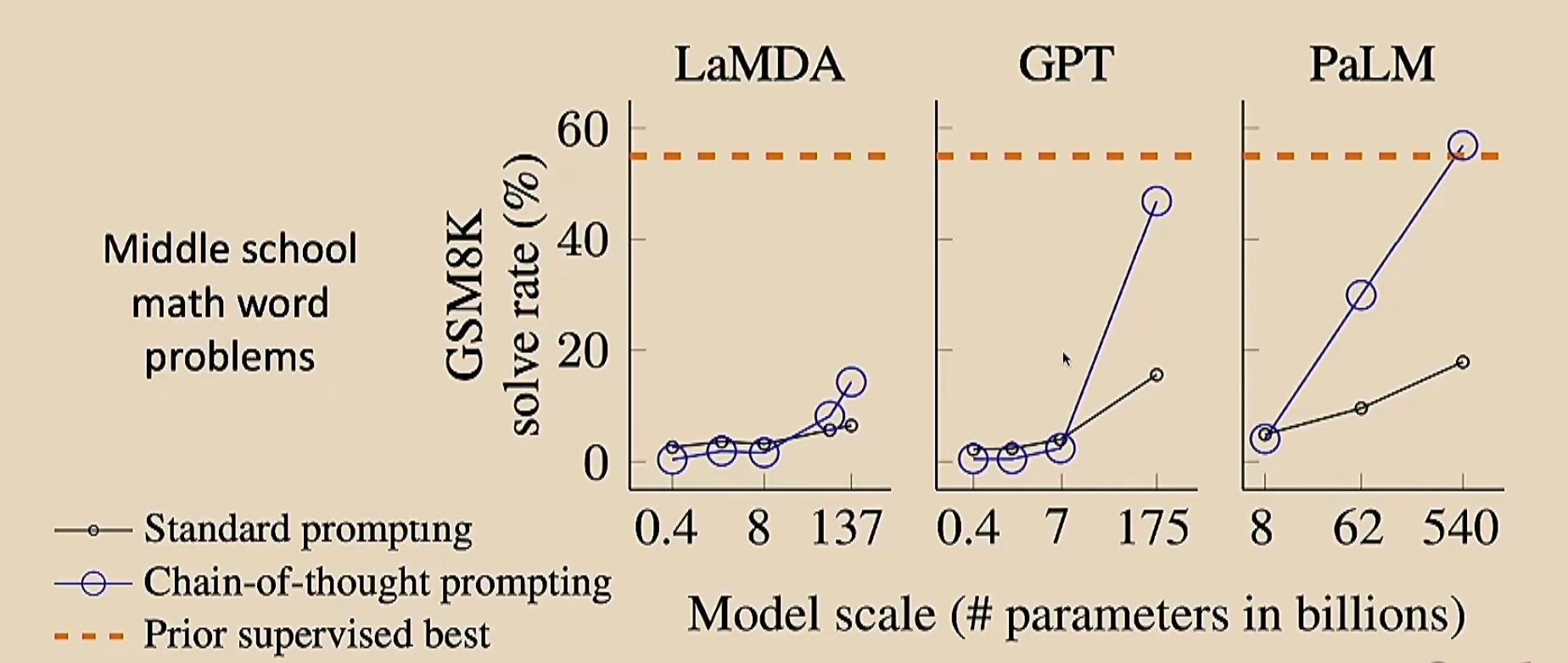
除了手动加思维链,我们还可以让模型自己产生思维链。这是一个非常简单的想法,只需要在标记最开始加入一个类似于让模型自己进行推理的话就好了,如下

黄色是我们加的提示词。下面是一个更清晰的示例

来对比一下手动加的和自动加的的区别

来看一下不同的提示词之间效果的差别

然后看看优缺点

有了这些缺点,我们就要想办法克服。这个时候就用微调吧。但是与之前的微调不一样,我们的下游任务不是单一的,而是多样化的
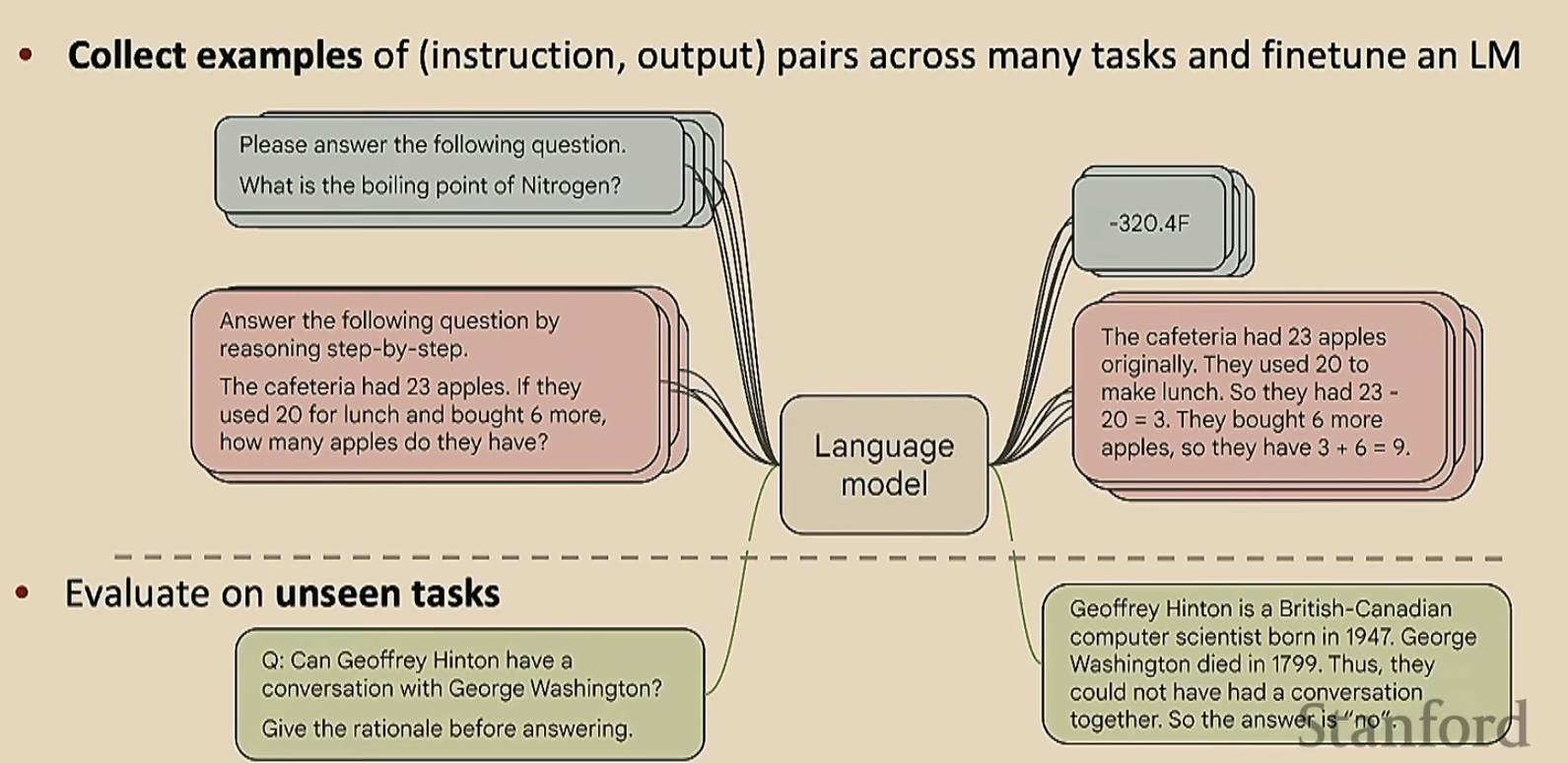
可能有人会说,这跟预训练有什么区别呢?其实没啥区别,但是这里的任务稍微具体一点
那么这种微调有用吗?实际上是有用的
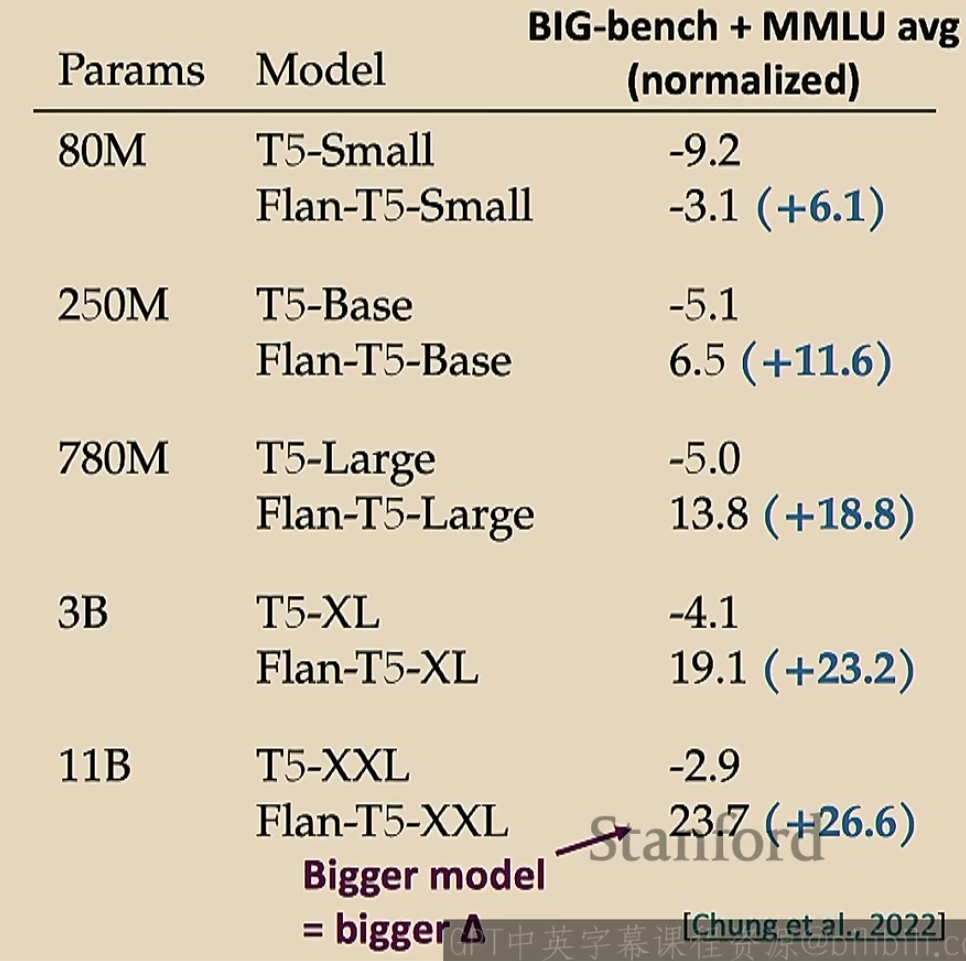
一个简单的例子如下
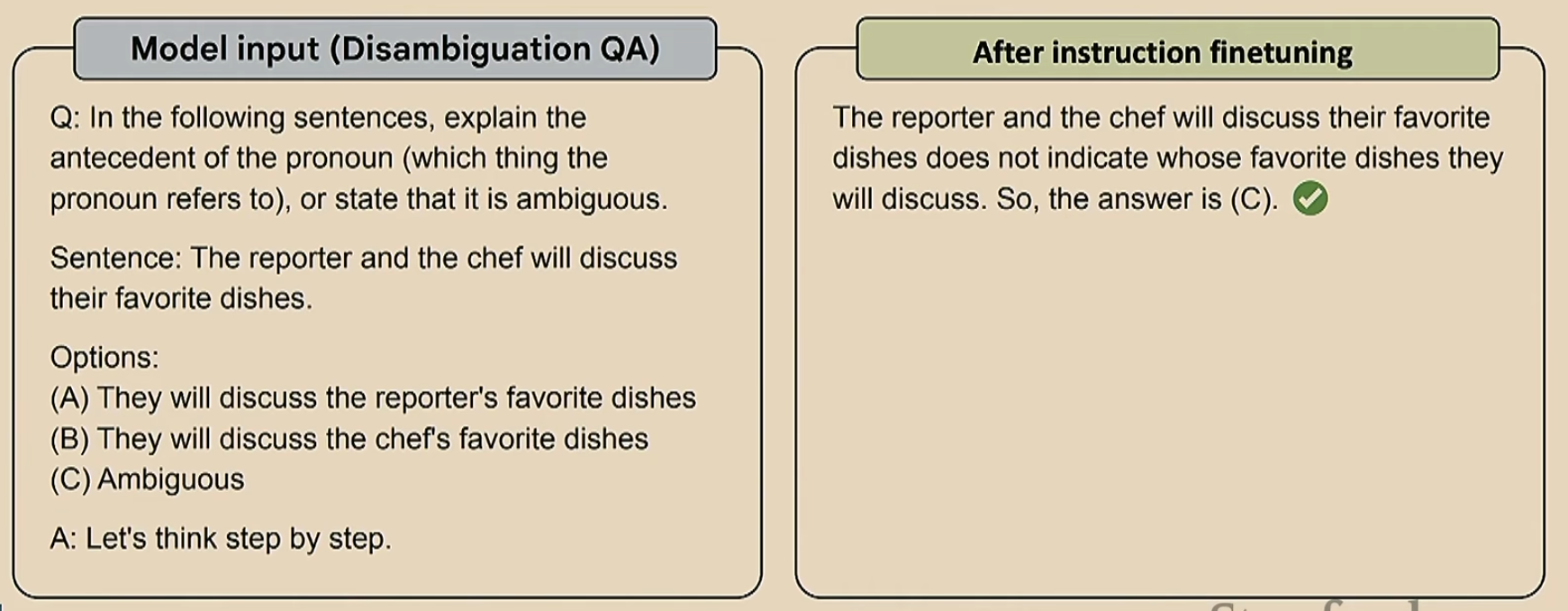
那么微调也是有缺点的,如下

这里的Problem 2就是指,比如右下角那个图,把《阿凡达》预测称一个奇幻电影肯定是错的,但是这个错误没有那么大,然而把《阿凡达》预测成一个音乐剧,这个错误就很大了。这两个错误感觉不应该给相同的惩罚
但最大的问题其实是最后一段,注意为什么我们的语言模型会输出一个fantasy呢(我们想要的是adventure)?这是因为对于模型来说,fantasy是一个概率更大的选项,但是对于我们人类来说,adventure才是一个更好的答案。这就产生了模型与人类的偏离
此时我们就要采取强化学习策略,让模型按照人类的意愿进行优化
我们设计一个评分函数\(R\),将模型的输出进行打分(这个打分是人类按照自己主观意愿打分的)

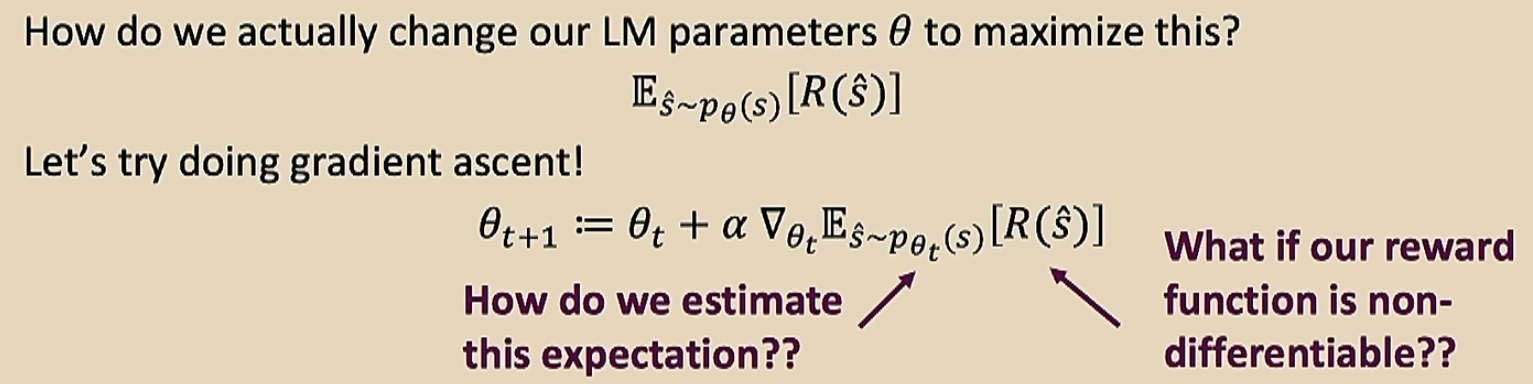



+++/---的意思就是绝对值很大的正/负数。最后这个式子就解决了不可导的问题了,因为我们的训练集大小\(m\)是有限的,所以我们可以将\(R(s_i)\)看做常数了,只用去调整后面那一项即可


那么上面的解决方法有效吗?
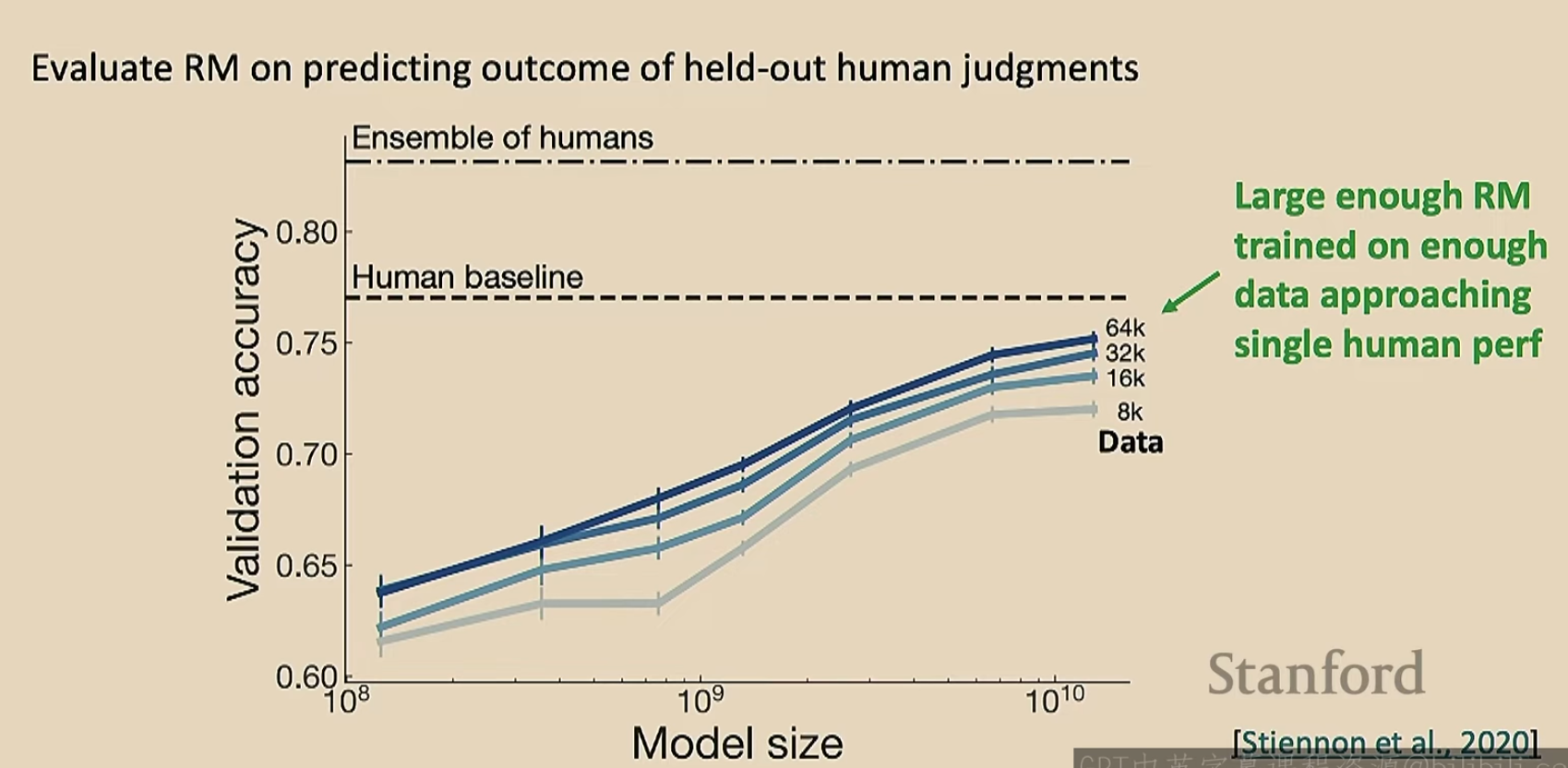

图中的\(p^{RL}_{\theta}(s)\)的初始值就是预训练模型的概率
那么RLHF有效吗?
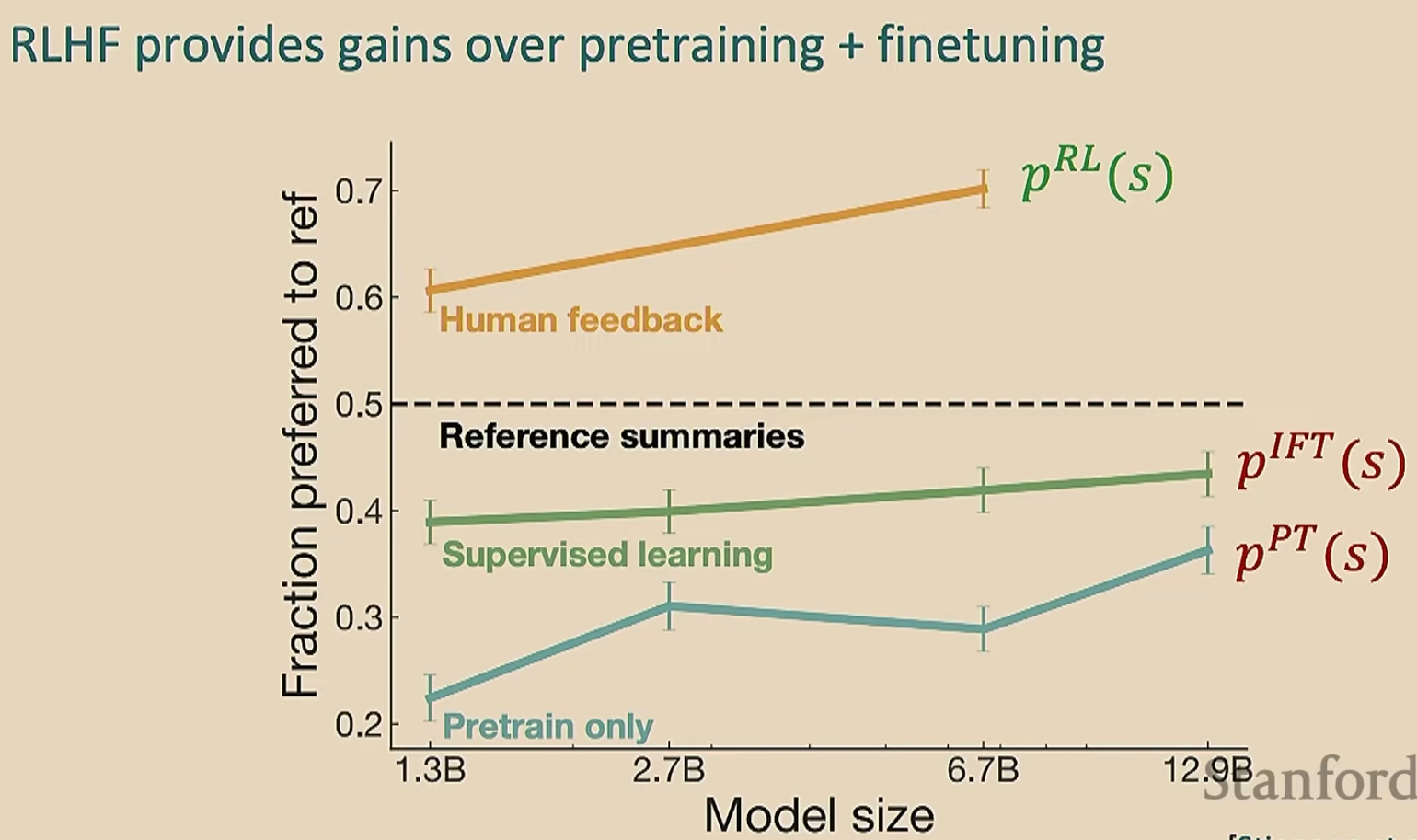
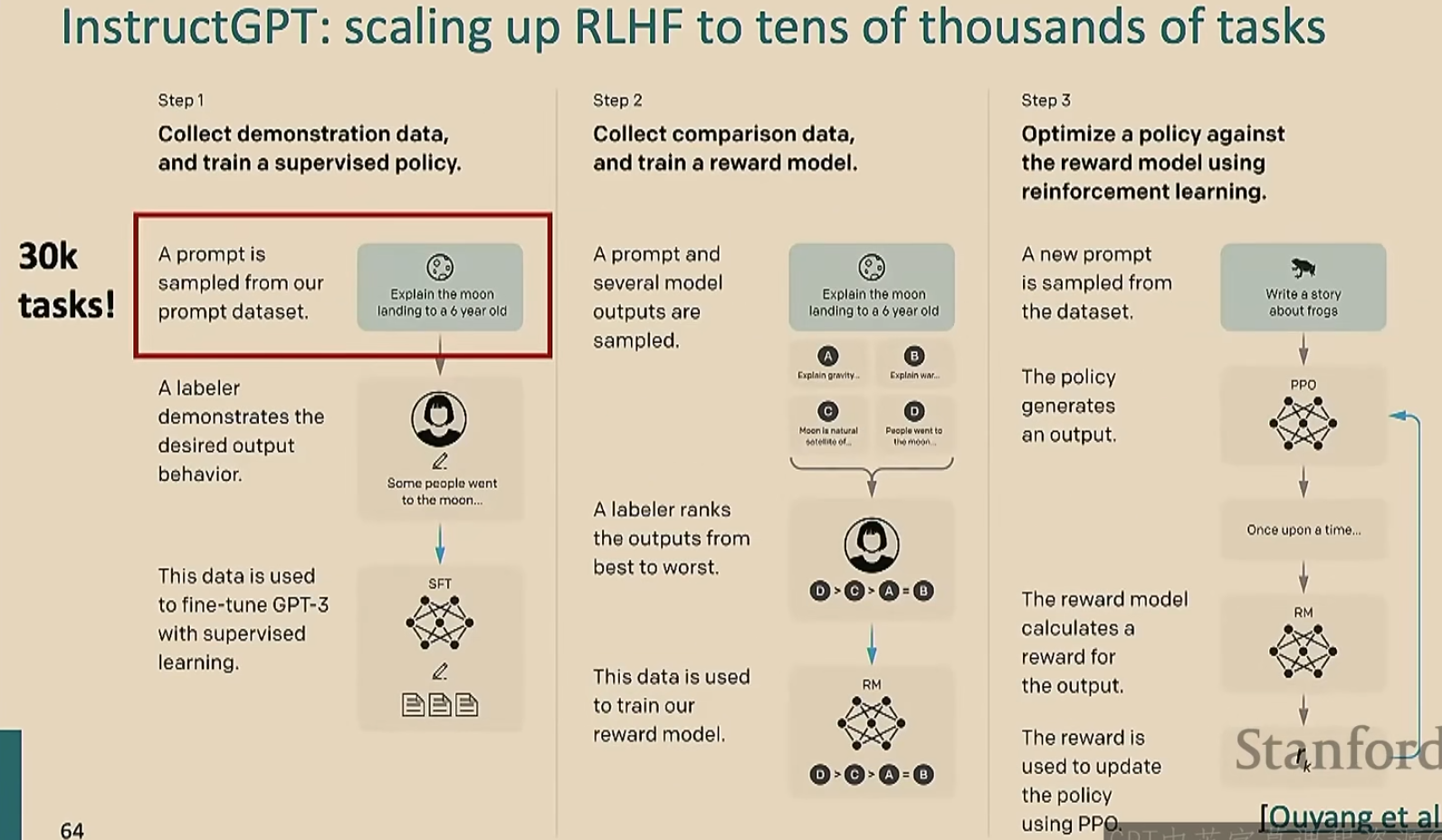
视频00:56:30之后未看,先把前面的理解了来吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号