

4.9.1 分布偏移的类型
下面介绍一下坐标系中协变量偏移的情况
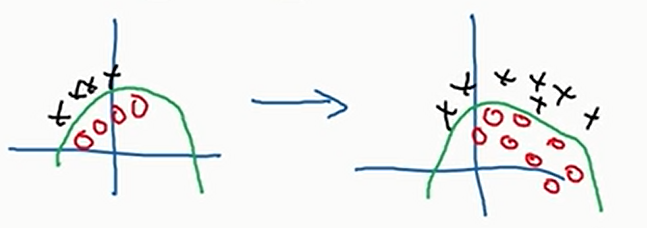
如上图,绿色的曲线是正确的曲线。我们训练的数据是左图,测试的数据是右图。按照左图的数据学习是学不出来绿色曲线的,就会导致右图的数据的准确率很低,这就是协变量偏移
一定要注意,在训练阶段,不要用来自不同分布的训练集和验证集。比如现在从\(8\)个不同地区中采集数据,然后选择其中\(4\)个地区的数据作为训练集,\(4\)个地区的数据作为验证集,这就是一个很坏的想法。正确做法应该是,直接将\(8\)个地区的数据作为一个整体,然后从中划分训练集和验证集
前面讲到,如果训练集和验证集来自不同分布,我们有一个解决方法就是将两者混合成为一个数据集后再划分。但是这种方法存在一个巨大的缺陷,就是我们的验证集中来自两个分部的比例不同,而我们所关注的那个分布所占的比例很少
举个例子,仍然是识别猫咪。假设训练集是从网上下载的高清图片\(20000\)张,但是验证集是业余用户自己拍摄的模糊图片\(1000\)张,那么整合在一起后,假设验证集有\(1000\)张,那么在这\(1000\)张里面,显然模糊图片占很少部分,但是模糊图片才是我们关注的(也就是说我们的目的是对模糊图片是否有猫进行高质量判断),所以这样子就不优秀(可能验证集的评分很高——验证集大部分都是高清图片,但实际上我们的模型对模糊图片的识别能力非常差)
更好的方法:我们不改变训练集和验证集的绝对大小,但是我们将不关心分布的数据全部放到训练集里面,然后再将关注分布的一些数据放到训练集里面,剩下的放到验证集里面。这样虽然分布仍然是不同的,但是影响更小了。这个方法有效的原因就是现在我们的验证集完全是模糊图片了,所以我们的调参方向完全是按照模糊图片去进行的,而训练集也有一部分模糊图片,可以缓解标签偏移的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号